Conclusions As expected, as you train lesse parameters e.g. LoRA vs Full Fine Tuning or Single Blocks LoRA vs all Blocks LoRA, your quality get reduced Of course you earn some extra VRAM memory reduction and also some reduced size on the disk Moreover, lesser parameters reduces the overfitting and realism of the FLUX model, so if you are into stylized outputs like comic, it may work better Furthermore, when you reduce LoRA Network Rank, keep original Network Alpha unless you are going to do a new Learning Rate research Finally, very best and least overfitting is achieved with full Fine Tuning Check figure 3 and figure 4 last columns — I make extracted LoRA Strength / Weight 1.1 instead of 1.0 Full fine tuning configs and instructions > https://www.patreon.com/posts/112099700 Second best one is extracting a LoRA from Fine Tuned model if you need a LoRA Check figure 3 and figure 4 last columns — I make extracted LoRA Strength / Weight 1.1 instead of 1.0 Extract LoRA guide (public article) : https://www.patreon.com/posts/112335162 Third is doing a all layers regular LoRA training Full guide, configs and instructions > https://www.patreon.com/posts/110879657 And the worst quality is training lesser blocks / layers with LoRA Full configs are included in > https://www.patreon.com/posts/110879657 So how much VRAM and Speed single block LoRA training brings? All layers 16 bit is 27700 MB (4.85 second / it) and 1 single block is 25800 MB (3.7 second / it) All layers 8 bit is 17250 MB (4.85 second / it) and 1 single block is 15700 MB (3.8 second / it) Image Raw Links Figure 0 : MonsterMMORPG/FLUX-Fine-Tuning-Grid-Tests
This was short on length so check out the full article - public post
Conclusions as below
Conclusions With same training dataset (15 images used), same number of steps (all compared trainings are 150 epoch thus 2250 steps), almost same training duration, Fine Tuning / DreamBooth training of FLUX yields the very best results
So yes Fine Tuning is the much better than LoRA training itself
Amazing resemblance, quality with least amount of overfitting issue
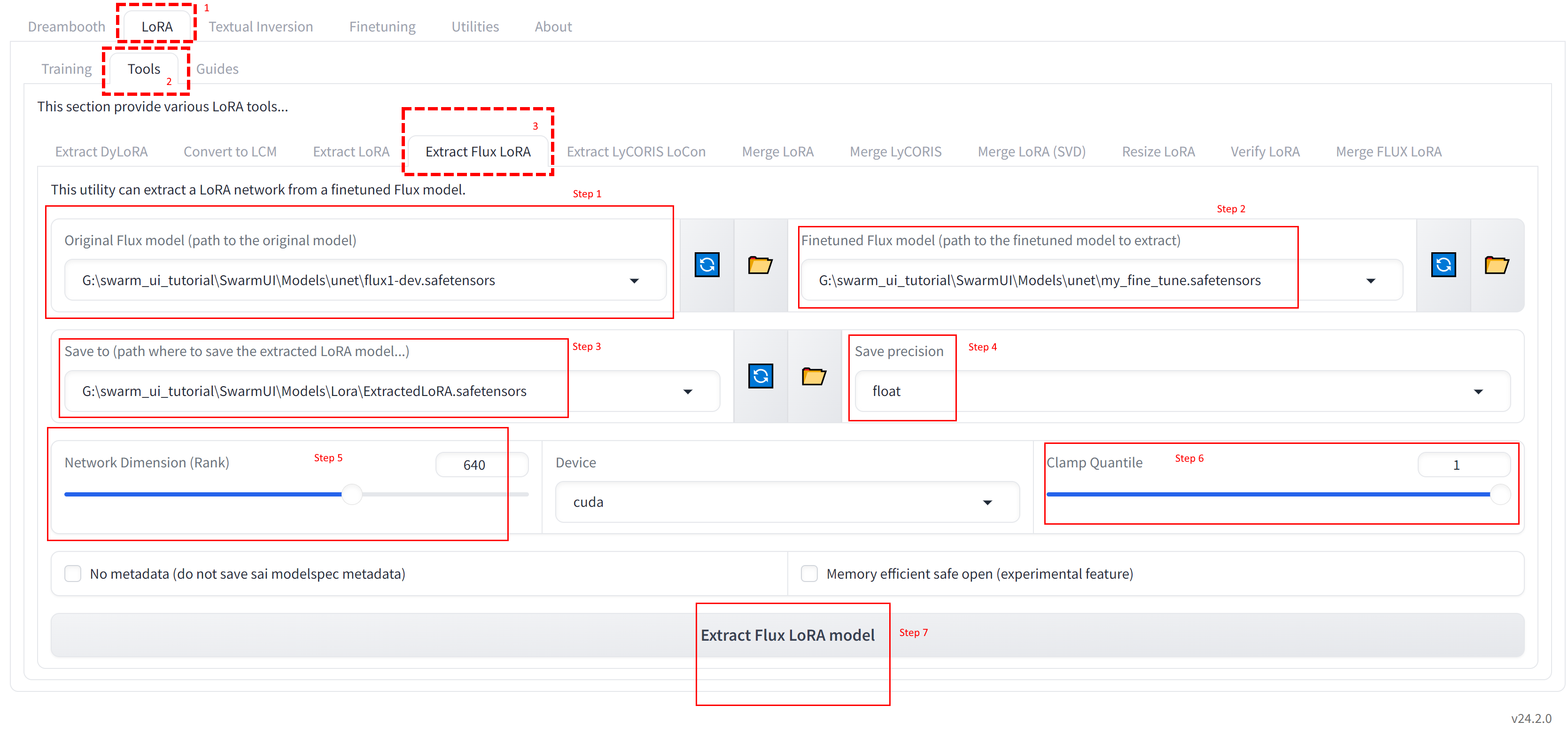
Moreover, extracting a LoRA from Fine Tuned full checkpoint, yields way better results from LoRA training itself
Extracting LoRA from full trained checkpoints were yielding way better results in SD 1.5 and SDXL as well
Comparison of these 3 is made in Image 5 (check very top of the images to see)
640 Network Dimension (Rank) FP16 LoRA takes 6.1 GB disk space
You can also try 128 Network Dimension (Rank) FP16 and different LoRA strengths during inference to make it closer to Fine Tuned model
Moreover, you can try Resize LoRA feature of Kohya GUI but hopefully it will be my another research and article later






{kind=link}
{kind=link}