

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,98 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
# ERNIE-Code
|
| 6 |
+
|
| 7 |
+
[ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages](https://aclanthology.org/2023.findings-acl.676.pdf)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
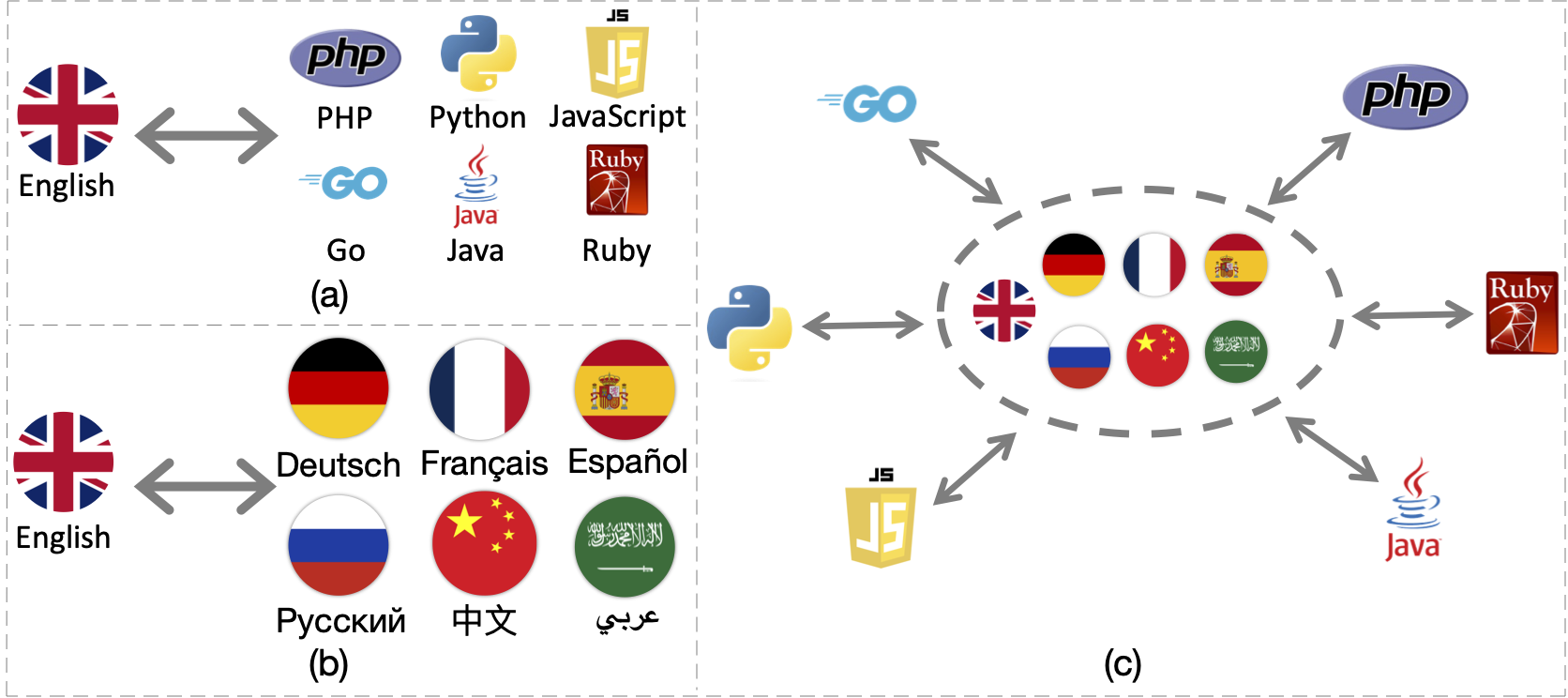
ERNIE-Code is a unified large language model (LLM) that connects 116 natural languages with 6 programming languages. We employ two pre-training methods for universal cross-lingual pre-training: span-corruption language modeling that learns patterns from monolingual NL or PL; and pivot-based translation language modeling that relies on parallel data of many NLs and PLs. Extensive results show that ERNIE-Code outperforms previous multilingual LLMs for PL or NL across a wide range of end tasks of code intelligence, including multilingual code-to-text, text-to-code, code-to-code, and text-to-text generation. We further show its advantage of zero-shot prompting on multilingual code summarization and text-to-text translation.
|
| 14 |
+
|
| 15 |
+
[ACL 2023 (Findings)](https://aclanthology.org/2023.findings-acl.676/) | [arXiv](https://arxiv.org/pdf/2212.06742)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
### Multilingual Text-to-Code / Code-to-Text
|
| 19 |
+
|
| 20 |
+
First preprocess the input prompt:
|
| 21 |
+
```python
|
| 22 |
+
def clean_up_code_spaces(s: str):
|
| 23 |
+
# post process
|
| 24 |
+
# ===========================
|
| 25 |
+
new_tokens = ["<pad>", "</s>", "<unk>", "\n", "\t", "<|space|>"*4, "<|space|>"*2, "<|space|>"]
|
| 26 |
+
for tok in new_tokens:
|
| 27 |
+
s = s.replace(f"{tok} ", tok)
|
| 28 |
+
|
| 29 |
+
cleaned_tokens = ["<pad>", "</s>", "<unk>"]
|
| 30 |
+
for tok in cleaned_tokens:
|
| 31 |
+
s = s.replace(tok, "")
|
| 32 |
+
s = s.replace("<|space|>", " ")
|
| 33 |
+
# ===========================
|
| 34 |
+
return s
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Then use `transformers` to load the model:
|
| 38 |
+
```python
|
| 39 |
+
import torch
|
| 40 |
+
from transformers import (
|
| 41 |
+
AutoModelForSeq2SeqLM,
|
| 42 |
+
AutoModelForCausalLM,
|
| 43 |
+
AutoTokenizer
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
model_name = "baidu/ernie-code-560m"
|
| 47 |
+
|
| 48 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
|
| 49 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 50 |
+
# note that you can use aforementioned `clean_up_code_spaces` to proprocess the code
|
| 51 |
+
|
| 52 |
+
input_code="快速排序"
|
| 53 |
+
prompt="translate Chinese to English: \n%s" % (input_code) # your prompt here
|
| 54 |
+
|
| 55 |
+
model_inputs = tokenizer(prompt, max_length=512, padding=False, truncation=True, return_tensors="pt")
|
| 56 |
+
input_ids = model_inputs.input_ids.cuda() # by default
|
| 57 |
+
attention_mask = model_inputs.attention_mask.cuda() # by default
|
| 58 |
+
|
| 59 |
+
output = model.generate(input_ids=input_ids, attention_mask=attention_mask,
|
| 60 |
+
num_beams=5, max_length=512) # change to your own decoding methods
|
| 61 |
+
|
| 62 |
+
# Ensure to customize the post-processing of clean_up_code_spaces output according to specific requirements.
|
| 63 |
+
output = tokenizer.decode(output.flatten(), skip_special_tokens=True)
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
### Zero-shot Examples
|
| 68 |
+
- Multilingual code-to-text generation (zero-shot)
|
| 69 |
+
|
| 70 |
+

|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
- Multilingual text-to-text translation (zero-shot)
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
## BibTeX
|
| 80 |
+
```
|
| 81 |
+
@inproceedings{chai-etal-2023-ernie,
|
| 82 |
+
title = "{ERNIE}-Code: Beyond {E}nglish-Centric Cross-lingual Pretraining for Programming Languages",
|
| 83 |
+
author = "Chai, Yekun and
|
| 84 |
+
Wang, Shuohuan and
|
| 85 |
+
Pang, Chao and
|
| 86 |
+
Sun, Yu and
|
| 87 |
+
Tian, Hao and
|
| 88 |
+
Wu, Hua",
|
| 89 |
+
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
|
| 90 |
+
month = jul,
|
| 91 |
+
year = "2023",
|
| 92 |
+
address = "Toronto, Canada",
|
| 93 |
+
publisher = "Association for Computational Linguistics",
|
| 94 |
+
url = "https://aclanthology.org/2023.findings-acl.676",
|
| 95 |
+
pages = "10628--10650",
|
| 96 |
+
abstract = "Software engineers working with the same programming language (PL) may speak different natural languages (NLs) and vice versa, erecting huge barriers to communication and working efficiency. Recent studies have demonstrated the effectiveness of generative pre-training in computer programs, yet they are always English-centric. In this work, we step towards bridging the gap between multilingual NLs and multilingual PLs for large language models (LLMs). We release ERNIE-Code, a unified pre-trained language model for 116 NLs and 6 PLs. We employ two methods for universal cross-lingual pre-training: span-corruption language modeling that learns patterns from monolingual NL or PL; and pivot-based translation language modeling that relies on parallel data of many NLs and PLs. Extensive results show that ERNIE-Code outperforms previous multilingual LLMs for PL or NL across a wide range of end tasks of code intelligence, including multilingual code-to-text, text-to-code, code-to-code, and text-to-text generation. We further show its advantage of zero-shot prompting on multilingual code summarization and text-to-text translation. We release our code and pre-trained checkpoints.",
|
| 97 |
+
}
|
| 98 |
+
```
|