How to get GPT to talk like a consultant



Have you ever asked GPT a simple question and gotten a ton of information, much of which is irrelevant or simply overwhelming?
Here's an example:
You: "How do I lose weight?"
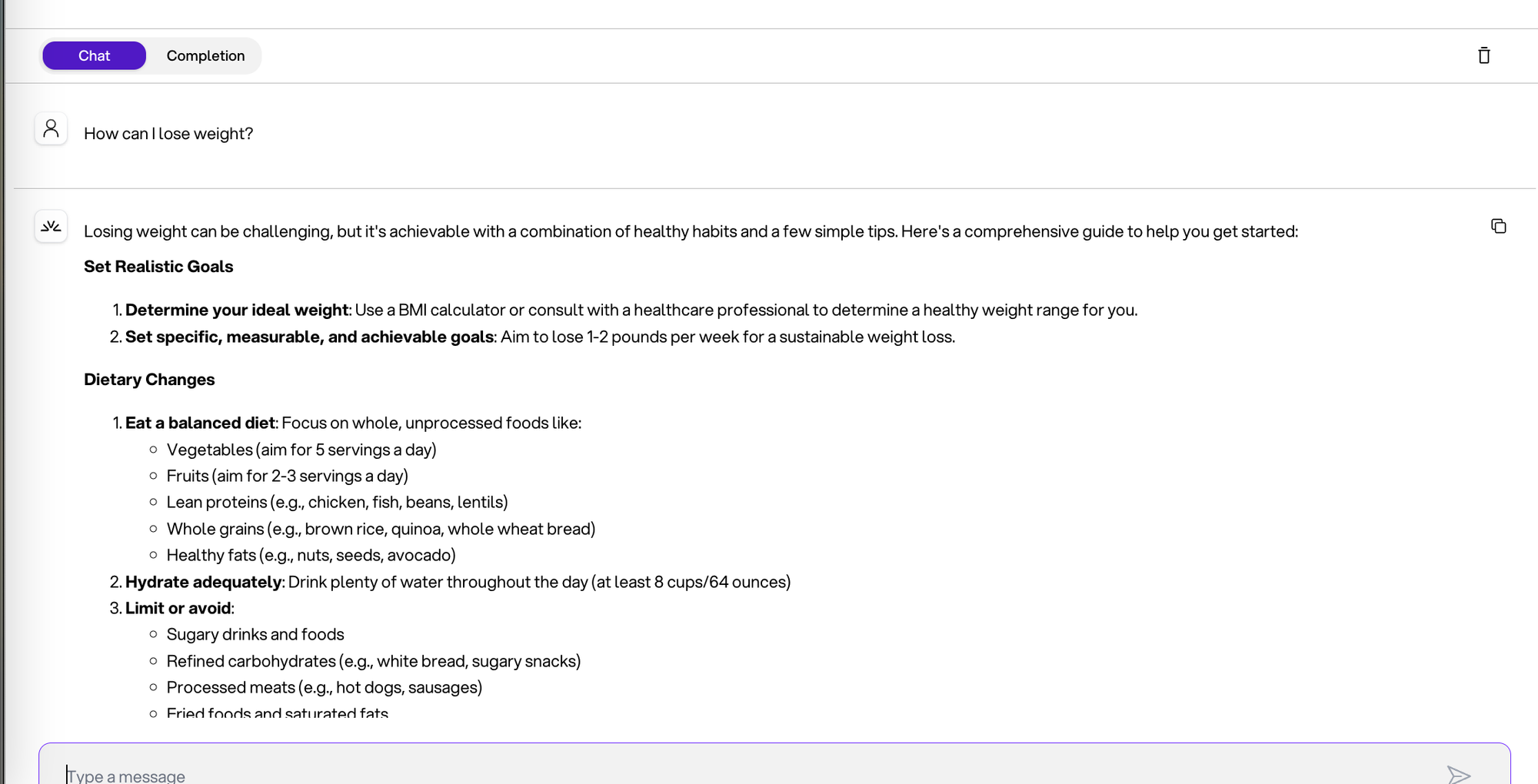
I do not know how you feel when you receive this amount of information, but I personally feel overwhelmed😄
Instead, what I expect from a human knowledgeable human consultant is to try to reduce the search radius before making recommendations.
Maybe something like this:
"Losing weight can be tough. **Are you looking for diet tips, or maybe some exercise routines? **Let me know so I can give you the best advice for your situation."
This is something we can improve with fine-tuning techniques.
In this guide I'll show you how to fine-tune LLaMA-3 to do just that. Before LLaMA-3 jumps to conclusions, it first tries to understand your preferences and then finally gives a tailored recommendation.
To demonstrate the concept, I used a small dataset that I created using ChatGPT. In a real world scenario, you would use a larger dataset to reflect your domain and conversational patterns.
Setting Up the Environment
We'll use LLaMA-Factory, an open-source framework for fine-tuning language models, and Vast.ai, a platform for renting GPU instances similar to Colab (but cheaper). Alternatively, you can use any GPU-powered VM.
Step 1: Prepare the environment
- AccessVast.aiand create a new instance

Then open Jupyter Notebook in your browser - alternatively, you can run it using ssh in Visual Studio code. For simplicity, we will do the whole tutorial directly in the browser.
Then start new terminal
Step 2: Install Necessary Packages
Set up your environment by installing the required packages:
pip install --upgrade huggingface_hub
huggingface-cli login
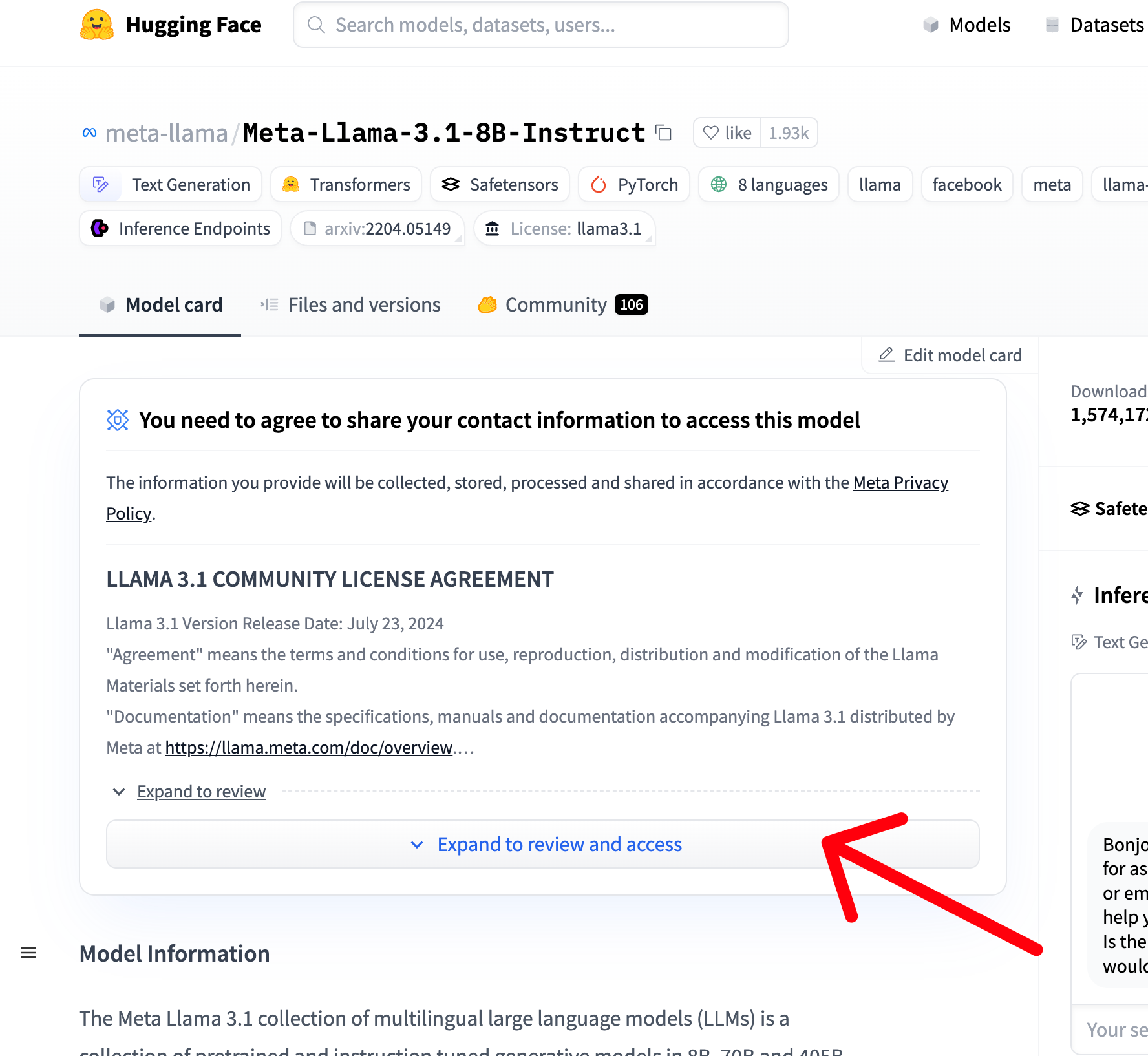
⚠️
If you have not already done so, please note that in order to get access to LLLam3b, you must request access to llama3 in Hugging Face (it is free).
[
meta-llama/Meta-Llama-3.1-8B-Instruct - Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.

](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)
Step 2: Install LLAMA Factory
Clone the LLaMA-Factory repository:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
Step 3: Testing the Model's Current Behavior
Start a chat session to test how the base LLaMA-3 model behaves:
llamafactory-cli chat --model_name_or_path meta-llama/Meta-Llama-3-8B --template llama3
💡
Please note that it may take a few minutes to download the model and start the inference.
Now we can experiment with the base model and see how it behaves before fine-tuning.
Step 4: Fine-Tuning the Model
Download a dataset that structures dialogues more like a human consultant:
wget https://huggingface.co/datasets/airabbitX/gpt-consultant/resolve/main/gpt_consultant.json
Here is an excerpt from the dataset
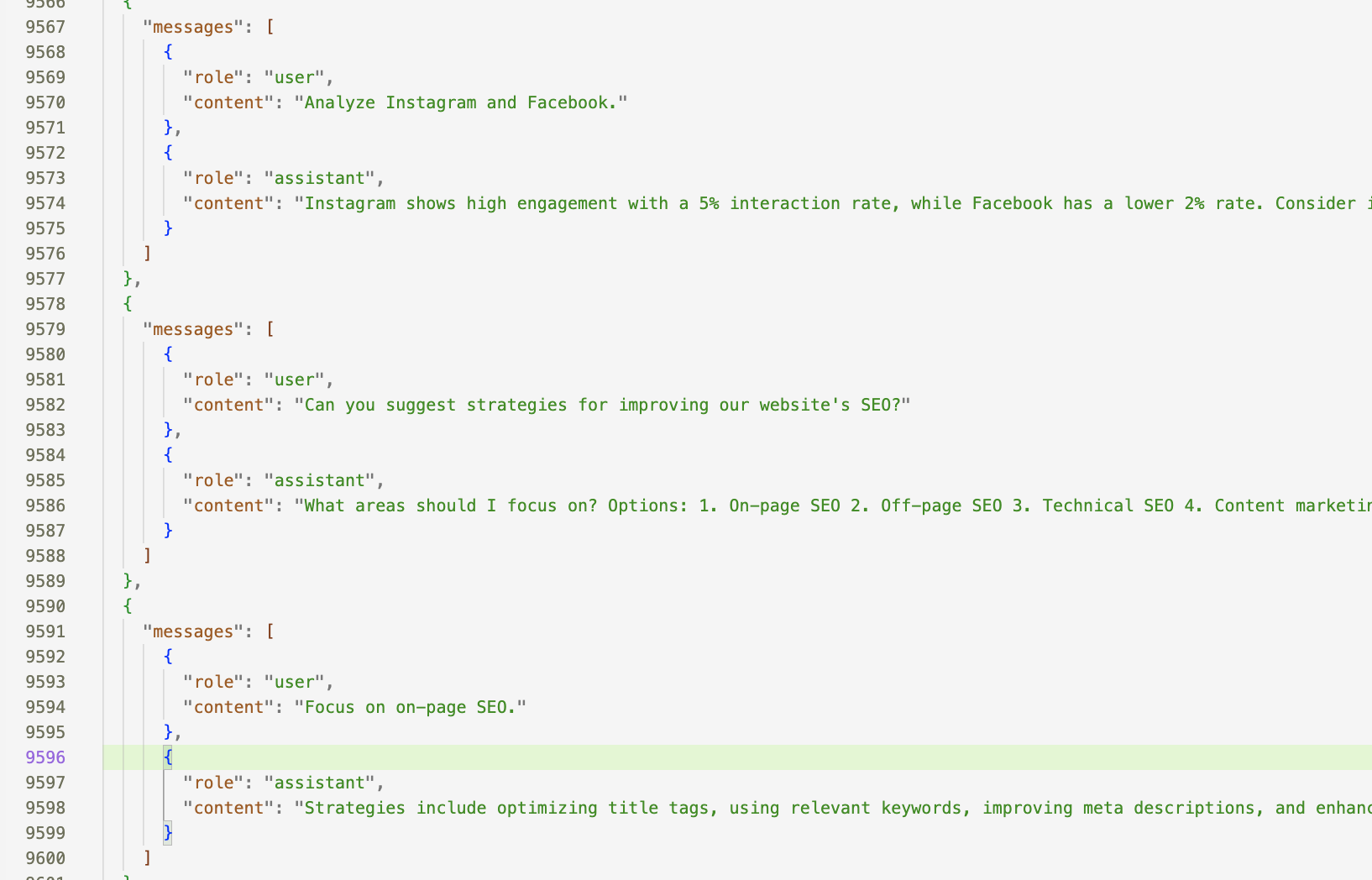
Upload the json file to that path:
/workspace/LLaMA-Factory/data

Add a new entry to the datasetinfo.json in llamafactory:
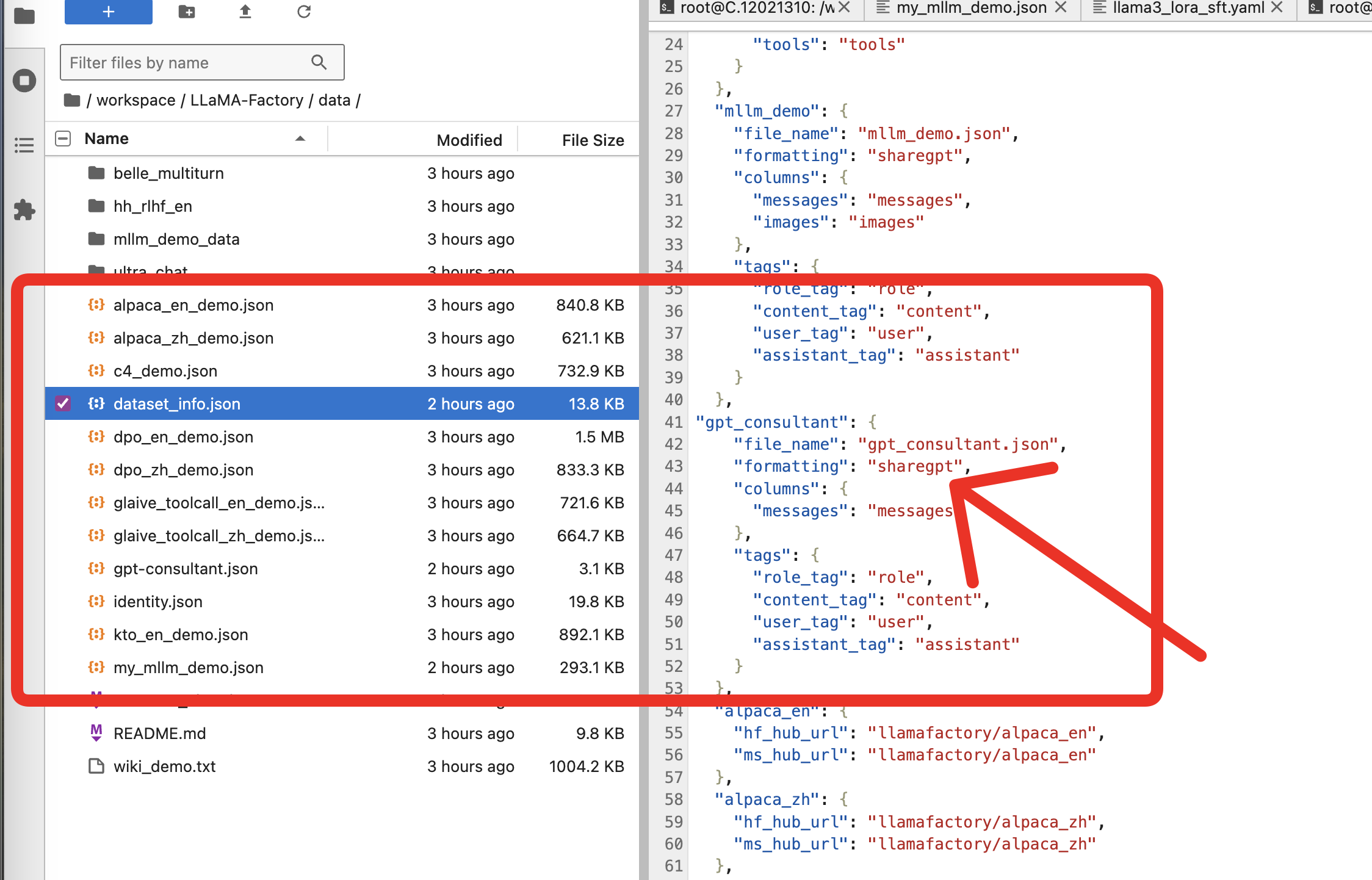
"gpt_consultant": {
"file_name": "gpt_consultant.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
Now we can start training the model with the data set.
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
If all goes well, you should see progress like this.

Step 5: Testing the Fine-Tuned Model
After training, test the model again to see the improved behavior:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
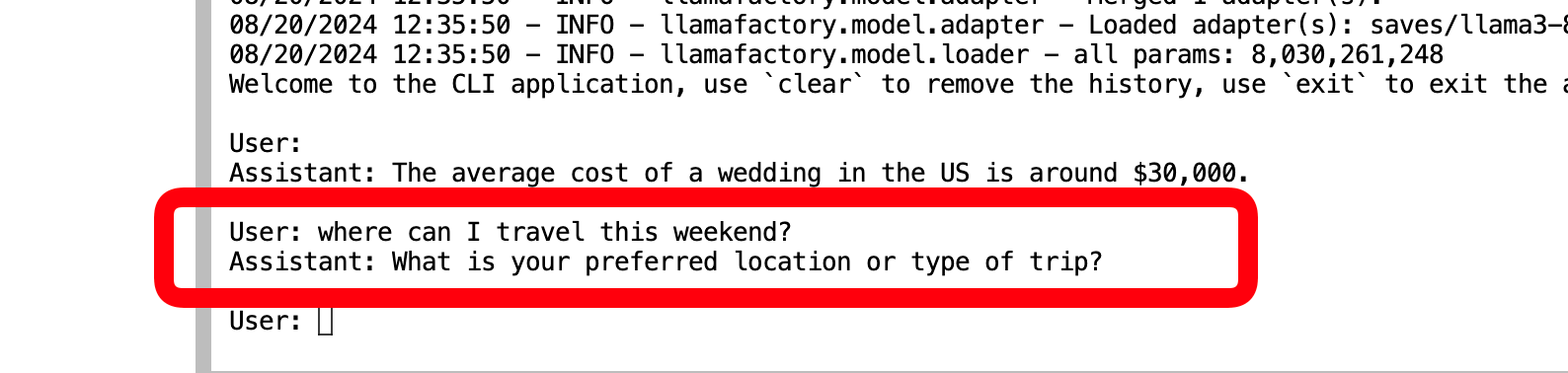
Now we ask the model the questions we asked the original LLAMA3b.
As you can see, it will first try to figure out your background and situation before jumping into conclusions. And not just for health concerns.

Conclusion
By fine-tuning LLaMA-3, we can make the model more conversational and behave more like an advisor than a Wikipedia machine.
You can significantly improve the model's dialog by adjusting the hyperparamters and adding more conversations to the dataset, and you can try with different models like Mistral, Phi, etc.
Of course, this is just scratching the surface of what is possible.
In the second part, we will do the same exercise with OpenAI GPt-4o-mini. Stay tuned!