
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 25,306 | open | "Dynamic" Issue in LlamaDynamicNTKScalingRotaryEmbedding - Long context inference will impact short context inference. | ### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0.dev0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (gpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Please see my colab code:
https://colab.research.google.com/drive/1SnQQxW7WMHgSOvAwF_HIlIDrAuXZ4IKp?usp=sharing
I asked the same prompt twice, with a long-context prompt inserted in between. However, this intermediate long-context inference resulted in different answers for the same question before and after it.
### Expected behavior
Since the input length of the tested prompts is within the maximum input token capacity the model can handle, the significance of "Dynamic" lies in ensuring that the embeddings for the inputs before and after remain the same, and consequently, the output results should also be the same.
I reviewed the code of the class "[LlamaDynamicNTKScalingRotaryEmbedding](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L147C8-L147C8)" and I think that due to caching, when the model infers a long context, the cached values of `cos_cached` and `sin_cached` are updated to adapt to the longer context. This causes the issue when the model infers a shorter context again. | 08-04-2023 00:31:00 | 08-04-2023 00:31:00 | |
transformers | 25,305 | open | Unable to change default cache folders despite setting environment variables | ### System Info
Collecting environment information...
PyTorch version: 2.0.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-71-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 2080 Ti
GPU 1: NVIDIA GeForce RTX 2080 Ti
GPU 2: NVIDIA GeForce RTX 2080 Ti
GPU 3: NVIDIA GeForce RTX 2080 Ti
GPU 4: NVIDIA GeForce RTX 2080 Ti
GPU 5: NVIDIA GeForce RTX 2080 Ti
GPU 6: NVIDIA GeForce RTX 2080 Ti
GPU 7: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 530.30.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.3
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 80
On-line CPU(s) list: 0-79
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 20
Socket(s): 2
Stepping: 7
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 1.3 MiB (40 instances)
L1i cache: 1.3 MiB (40 instances)
L2 cache: 40 MiB (40 instances)
L3 cache: 55 MiB (2 instances)
NUMA node(s): 2
NUMA node0 CPU(s): 0-19,40-59
NUMA node1 CPU(s): 20-39,60-79
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.3
[pip3] torch==2.0.1
[pip3] torchvision==0.15.2
[pip3] triton==2.0.0
[conda] Could not collect
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1- Set the following environment variables:
```
import os
os.environ['XDG_CACHE_HOME'] = '/MyFolder/.cache'
os.environ['HF_HOME'] = '/MyFolder/.cache/huggingface'
os.environ['HF_DATASETS_CACHE'] = '/MyFolder/.cache/datasets'
os.environ['TRANSFORMERS_CACHE'] = '/MyFolder/.cache/models'
os.environ['HUGGINGFACE_HUB_CACHE'] = '/MyFolder/.cache/hub'
```
2- Try to download a model. In my case, I do this:
```
model = "google/flan-t5-small"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
```
### Expected behavior
Expected behavior
The caches should be saved to the custom directories specified in the environment variables.
Actual behavior
The caches continue to be saved to the default locations and do not use the custom directories. | 08-03-2023 23:42:20 | 08-03-2023 23:42:20 | |
transformers | 25,304 | open | Tokenizer failing to encode chatml correctly | ### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.14.0-284.18.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
Note: also tested and broken on:
- 641adca
- 4.30.2
- 4.30.1
- 4.30.0
- 4.29.2
- 4.29.1
- 4.29.0
- 4.28.1
- 4.28.0
- 4.27.4
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I'm attempting to finetune Llama2 with a ChatML format. No matter how I approach it, it seems to be failing to encode/decode correctly. I see multiple issues and PRs that are related, but this specific format seems to be hitting all of them with none of the workarounds being effective.
A repro is available here:
https://gist.github.com/ozreact/a4b565cd2c7fac65d6cb76c78dbdf9e2
#24565 recommends setting `legacy=false`, and further says that this only addresses a subset of issues with the slow tokenizer only. It also mentions that `decode` isn't fixed, so validating that the encoding step is working is fiddly.
This format, when newlines are used, is also impacted by #21120.
#25073 also breaks this.
#25176 recommends setting `legacy=True` to fix an invalid unk token that effectively over-writes a final token in a partial ChatML response, but this conflicts with attempting to fix the issues in #24565.
### Expected behavior
ChatML instruction format should 'just work', tokenize correctly, and decode correctly. | 08-03-2023 23:13:33 | 08-03-2023 23:13:33 | |
transformers | 25,303 | open | loss reduction for `Llama2ForCausalLM.forward` | ### Feature request
In `forward` method, it outputs `loss` when `labels` are provided. But the `loss` shape is always `(1,)` because `reduction='mean'` in CrossEntropy. I wonder if I could pass `reduction='none'` and get a `(batch_size,)` shaped loss tensor.
https://github.com/huggingface/transformers/blob/641adca55832ed9c5648f54dcd8926d67d3511db/src/transformers/models/llama/modeling_llama.py#L837
### Motivation
I'm using this loss for reward-based learning.
### Your contribution
I could make a PR if needed. | 08-03-2023 21:29:20 | 08-03-2023 21:29:20 | |
transformers | 25,302 | closed | Fix typo: Roberta -> RoBERTa | # What does this PR do?
Small typo in docs: "Roberta" should have the correct capitalization "RoBERTa".
Fixes #25301
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
<!--
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
-->
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
Documentation: @sgugger, @stevhliu and @MKhalusova
| 08-03-2023 20:04:27 | 08-03-2023 20:04:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,301 | closed | Minor typo referencing RoBERTa | "Roberta" should use the correct capitalization: "RoBERTa"
https://github.com/huggingface/transformers/blob/d27e4c18fe2970abcb9a48dcb8a824e48083b15f/docs/source/en/tokenizer_summary.md?plain=1#L144
Should be a simple fix. | 08-03-2023 19:58:21 | 08-03-2023 19:58:21 | |
transformers | 25,300 | open | Add zero-shot classification task for BLIP-2 | ### Feature request
I would like to add the support for the zero-shot classification task using BLIP2, computing text-image similarities with the normalized embeddings, that would be accessed from BLIP2 feature extractor.
The idea is to enable calling the zero-shot classification pipeline using BLIP2, by implementing the `get_image_feature`and `get_text_features`methods.
I would love more guidance, if possible, on the criteria for accepting the PR.
### Motivation
This is related to the following the discussion on this issue on the hub, and the comment left by @NielsRogge here https://huggingface.co/Salesforce/blip2-opt-2.7b/discussions/3#64cbe5e487ec96aa473a1f54 .
### Your contribution
I would like to submit a PR to contribute for this feature. | 08-03-2023 19:53:46 | 08-03-2023 19:53:46 | |
transformers | 25,299 | open | cannot import name 'Module' from '_pytest.doctest' | ### System Info
transformers 4.32.0.dev0
torch 2.1.0.dev20230523+cu117
Error:
Traceback (most recent call last):
File "/workspace/transformers/examples/pytorch/language-modeling/run_clm.py", line 52, in <module>
Traceback (most recent call last):
File "/workspace/transformers/examples/pytorch/language-modeling/run_clm.py", line 52, in <module>
from transformers.testing_utils import CaptureLogger
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/transformers-4.32.0.dev0-py3.8.egg/transformers/testing_utils.py", line 111, in <module>
from transformers.testing_utils import CaptureLogger
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/transformers-4.32.0.dev0-py3.8.egg/transformers/testing_utils.py", line 111, in <module>
from _pytest.doctest import (
ImportError: cannot import name 'Module' from '_pytest.doctest' (/opt/conda/envs/ptca/lib/python3.8/site-packages/_pytest/doctest.py)
from _pytest.doctest import (
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
python -m torch.distributed.launch --nproc_per_node=8 --use-env /workspace/transformers/examples/pytorch/language-modeling/run_clm.py --model_name_or_path xlnet-base-cased --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --label_smoothing 0.1 --do_train --output_dir /dev/shm --overwrite_output_dir --max_steps 200 --logging_steps 20 --per_device_train_batch_size 8 --fp16
### Expected behavior
example runs without error | 08-03-2023 19:05:56 | 08-03-2023 19:05:56 | You might need a `pip install --upgrade pytest`. |
transformers | 25,298 | open | [Whisper] Better error message for outdated generation config | # What does this PR do?
Gives a better error message in the case that a user tries using an outdated generation config with the new generation arguments `language` and `task` (as described in https://github.com/huggingface/transformers/issues/25084#issuecomment-1653722724).
| 08-03-2023 17:57:18 | 08-03-2023 17:57:18 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25298). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,297 | open | MaskFormer, Mask2Former - replace einsum for tracing | # What does this PR do?
Maskformer cannot currently be traced because of einsum operations. This PR replaces the einsum operations with standard matmuls.
With this PR, the following now runs:
```python
import torch
from transformers import Mask2FormerForUniversalSegmentation
device = torch.device("cuda")
model = Mask2FormerForUniversalSegmentation.from_pretrained(
"facebook/mask2former-swin-tiny-coco-instance",
torchscript=True
).eval().to(device)
dummy_input = torch.randn((1,3,640,640)).to(device)
traced_model = torch.jit.trace(model, dummy_input)
with torch.no_grad():
out = traced_model(torch.randn((2,3,640,640)).to(device))
out = traced_model(torch.randn((2,3,640,640)).to(device))
```
Partially fixes #25261 - enables tracing but does not resolve the issue of different results between traced and non-traced model on GPU
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 08-03-2023 17:48:58 | 08-03-2023 17:48:58 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25297). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,296 | open | BertForSequenceClassification does not support 'device_map':"auto" yet | ### System Info
I have trained a model and am now trying to load and quantise it but getting the error:
BertForSequenceClassification does not support 'device_map':"auto" yet
Code for loading is simply:
` model = AutoModelForSequenceClassification.from_pretrained(model_dir, device_map='auto', load_in_8bit=True)`
Help would be greatly appreciated!
Thanks,
Lee
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
model = AutoModelForSequenceClassification.from_pretrained(model_dir, device_map='auto', load_in_8bit=True)
### Expected behavior
The model would load and be usable. | 08-03-2023 17:00:09 | 08-03-2023 17:00:09 | |
transformers | 25,295 | closed | [small] llama2.md typo |
# What does this PR do?
`groupe` -> `grouped`
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-03-2023 16:51:06 | 08-03-2023 16:51:06 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,294 | open | Generate: remove Marian hack | # What does this PR do?
WIP, let's see first if all tests pass | 08-03-2023 16:48:40 | 08-03-2023 16:48:40 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25294). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,293 | open | MassFormer | ### Model description
We propose adding a new model, MassFormer, to predict tandem mass spectra accurately. MassFormer uses a graph transformer architecture to model long-distance relationships between atoms in the molecule. The transformer module is initialized with parameters obtained through a chemical pre-training task, then fine-tuned on spectral data. MassFormer outperforms competing approaches for spectrum prediction on multiple datasets and is able to recover prior knowledge about the effect of collision energy on the spectrum. We demonstrate that the model can identify relationships between fragment peaks by employing gradient-based attribution methods. To further highlight MassFormer’s utility, we show that it can match or exceed existing prediction-based methods on two spectrum identification tasks. Our code is the first open-source implementation of a deep-learning MS/MS spectrum predictor and may encourage future research in this area.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
This model will be implemented according to the paper by @adamoyoung as listed below.
Reference:
Young, A., Wang, B. and Röst, H., 2021. MassFormer: Tandem mass spectrum prediction with graph transformers. arXiv preprint arXiv:2111.04824. | 08-03-2023 16:41:42 | 08-03-2023 16:41:42 | |
transformers | 25,292 | open | Generate: get generation mode as a string | # What does this PR do?
Currently, generate gets several `is_XXX_mode` flags, to determine the generation mode. This was cool when there were a handful of generation modes, but now it means we have many variables. This PR replaces that part of the logic by a single variable -- a string containing the name of the generation mode.
In a future PR, I will use the string to efficiently perform generate kwarg validation and throw informative warnings/exceptions -- for instance, all beam methods (with "beam" in the name) share a large set of restrictions!
Related PR: #24575 | 08-03-2023 16:33:36 | 08-03-2023 16:33:36 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25292). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,291 | open | Document check copies | # What does this PR do?
This PR document a little bit better how or `Copied from` framework works, adds comments in the actual scripts and rework a bit the test to be better.
In passing I added a feature requested which was to make sure `make fix-copies` took the function definition or the superclass into account: currently it ignore the whole first line, but if we change the signature of a function / the superclass of a class which is copied from, that modification is not propagated (cc @Rocketknight1 who last requested it)
As you can see from the diff, that feature was direly needed... I had to add `BartPreTrainedModel` (right spelling to be consistent with other models) or break multiple copies, and you can see a lot of signatures or copied from statement being fixed. | 08-03-2023 15:59:52 | 08-03-2023 15:59:52 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25291). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,290 | open | Make `bark` could have tiny model | # What does this PR do?
Make `bark` could have tiny model. This is mainly for #24952
cc @ylacombe | 08-03-2023 15:35:40 | 08-03-2023 15:35:40 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25290). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,289 | open | Quantized models + PEFT + multi-gpu setup failing during training | ### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.10.178-162.673.amzn2.x86_64-x86_64-with-glibc2.26
- Python version: 3.10.8
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
### Who can help?
@younesbelkada
### Information
- [] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
To repoduce:
(Note, this is related to https://github.com/huggingface/accelerate/pull/1523)
```
accelerator = Accelerator()
model_id = "t5-base"
# Load tokenizer of FLAN-t5-XL
tokenizer = AutoTokenizer.from_pretrained(model_id, cache_dir = 'model_cache')
dataset = get_data()
tokenized_dataset = dataset.map(lambda sample: preprocess_function(sample, tokenizer), batched=True, remove_columns=["source", "target"])
# print(dist.get_rank())
model = AutoModelForSeq2SeqLM.from_pretrained(
model_id,
load_in_8bit=True,
device_map='auto',
cache_dir='model_cache')
# Define LoRA Config
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM
)
# prepare int-8 model for training
model = prepare_model_for_int8_training(model)
# add LoRA adaptor
model = get_peft_model(model, lora_config)
model = accelerator.prepare(model)
label_pad_token_id = -100
data_collator = DataCollatorForSeq2Seq(
tokenizer,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
padding=False
)
# Define training args
training_args = TrainingArguments(
per_device_train_batch_size=1,
learning_rate=1e-3,
num_train_epochs=10,
logging_strategy='steps',
logging_steps=5,
weight_decay=0,
output_dir = 'weights',
seed=22
)
# Create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset['train'].select(range(10)),
data_collator=data_collator,
)
train_result = trainer.train()
```
`tokenized_dataset` can be an arbitrary dataset.
The problem arises when running `python -m torch.distributed.launch --nproc_per_node=4 multi-gpu.py`.
Note that it works fine if just using `python multi-gpu.py` (since only 1 GPU is used here).
I am running with four T4s.
### Expected behavior
Error message:
```
Traceback (most recent call last):
File "/home/ec2-user/SageMaker/training/scripts/multi-gpu.py", line 131, in <module>
main()
File "/home/ec2-user/SageMaker/training/scripts/multi-gpu.py", line 125, in main
train_result = trainer.train()
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/transformers/trainer.py", line 1539, in train
return inner_training_loop(
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/transformers/trainer.py", line 1656, in _inner_training_loop
model, self.optimizer = self.accelerator.prepare(self.model, self.optimizer)
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/accelerator.py", line 1202, in prepare
result = tuple(
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/accelerator.py", line 1203, in <genexpr>
self._prepare_one(obj, first_pass=True, device_placement=d) for obj, d in zip(args, device_placement)
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/accelerator.py", line 1030, in _prepare_one
return self.prepare_model(obj, device_placement=device_placement)
File "/home/ec2-user/anaconda3/envs/JupyterSystemEnv/lib/python3.10/site-packages/accelerate/accelerator.py", line 1270, in prepare_model
raise ValueError(
ValueError: You can't train a model that has been loaded in 8-bit precision on multiple devices in any distributed mode. In order to use 8-bit models that have been loaded across multiple GPUs the solution is to use Naive Pipeline Parallelism. Therefore you should not specify that you are under any distributed regime in your accelerate config.
```
Some notes:
- this works if I remove 8 bit training
- I have tried this with and without `accelerator.prepare(model)` and this makes no difference (although when I remove 8bit training but keep this line, I get another error. When I remove the line, it trains fine).
Any help appreciated! | 08-03-2023 15:17:46 | 08-03-2023 15:17:46 | @younesbelkada maybe you can have a look at it? |
transformers | 25,288 | closed | device_map="auto" -> uninitialized parameters | ### System Info
- `transformers` version: 4.31.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
### Who can help?
@ArthurZucker @younesbelkada
Maybe also @sgugger because this is a general use-case about PyTorch models
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am encountering an issue that worries me slightly. When I load a model with `device_map`, everything goes fine - no warnings.
```python
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("BramVanroy/flan-t5-small-amr-en")
```
Howver, when I do use the device_map, I get the warning that some weights are not initialized
```python
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("BramVanroy/flan-t5-small-amr-en", device_map="auto")
```
Result:
> Some weights of T5ForConditionalGeneration were not initialized from the model checkpoint at BramVanroy/flan-t5-small-amr-en and are newly initialized: ['decoder.embed_tokens.weight', 'encoder.embed_tokens.weight']
> You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
However, I am wondering whether this isn't a false positive because the model performance seems the same with/without. My model repo contains both safetensors and the PyTorch *.bin, if that has something to do with it?
### Expected behavior
Either a warning in both or no warning in either. | 08-03-2023 13:54:40 | 08-03-2023 13:54:40 | I think this should have been fixed by #25101 Could you try again with a source install?
(Yes it is a false positive, just tied weights where the copies are not present in the state dict.)<|||||>Awesome, that works. Was afraid that I was messing something up with converting to safetensors. Glad that that is not the case.
Thanks for the prompt response! @sgugger |
transformers | 25,287 | open | Transformers Agent suggesting it should use text_generator although it is not provided. | ### System Info
I am running a version of [your notebook on Transformers Agent](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj), where I have added a cell where I ask the StarCoder agent to generate a sentence for me.
I am using StarCoder, as you can see:
```
#@title Agent init
agent_name = "StarCoder (HF Token)" #@param ["StarCoder (HF Token)", "OpenAssistant (HF Token)", "OpenAI (API Key)"]
import getpass
if agent_name == "StarCoder (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
print("StarCoder is initialized 💪")
elif agent_name == "OpenAssistant (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
print("OpenAssistant is initialized 💪")
if agent_name == "OpenAI (API Key)":
from transformers.tools import OpenAiAgent
pswd = getpass.getpass('OpenAI API key:')
agent = OpenAiAgent(model="text-davinci-003", api_key=pswd)
print("OpenAI is initialized 💪")
```
### Who can help?
@ArthurZucker and @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Based on the notebook mentioned, I have added a cell where I prompt the following:
```
agent.run("Write a sentence of the form 'A_ V_ at P_', where A_ should be replaced by the name of an animal, V_ should be replaced by a verb, and P_ should be replaced by the name of a place. Examples for valid sentences are 'Dog eating at macdonalds', 'Horse jumping at a gym', 'Duck fishing at a supermarket'. ")
```
As you see in the printout below, it suggests it will use the tool 'text_generation', but then stops because it does not have access to it.
```
==Explanation from the agent==
I will use the following tools: `text_classifier` to classify the sentence, then `text_generator` to generate the sentence.
==Code generated by the agent==
sentence = text_generator(prompt="A_ V_ at P_")
print(f"The sentence is {sentence}.")
sentence_class = text_classifier(sentence)
print(f"The sentence class is {sentence_class}.")
==Result==
Evaluation of the code stopped at line 0 before the end because of the following error:
It is not permitted to evaluate other functions than the provided tools (tried to execute text_generator).
```
### Expected behavior
Either, the agent should not even consider using "text_generation" as a tool, or it should have access to this tool as default.
| 08-03-2023 13:08:51 | 08-03-2023 13:08:51 | I'm not too sure why you are reporting a bug. The agent is an LLM which sometimes hallucinate content (in this case, a tool that does not exist). If your prompt does not work, you should try refining it. You should also try using another model and see if it performs better. |
transformers | 25,286 | closed | [JAX] Bump min version | # What does this PR do?
Bumps the minimum version of JAX to [0.4.1](https://jax.readthedocs.io/en/latest/changelog.html#jax-0-4-1-dec-13-2022), the earliest version where the new `jax.Array` API is introduced, replacing the deprecated `jax.numpy.DeviceArray` API. This allows compatibility with the latest JAX version [0.4.14](https://jax.readthedocs.io/en/latest/changelog.html#jax-0-4-14-july-27-2023), where `jax.numpy.DeviceArray` is removed entirely.
Related: #24875
| 08-03-2023 12:53:27 | 08-03-2023 12:53:27 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,284 | open | Fix Llama's attention map handling for left padding which causes numerical instability and performance drops | Hi this PR is trying to address the performance drop and potential numerical instability caused by vanilla left padding in Llama.
Here is the explanation:
1. If we initialize the tokenizer with left padding and call model.generate without passing in corresponding attention_mask, the code will run, but for the instances who are left padded, its unpadded tokens will "see" the padded tokens. This will cause performance drop a lot ! At least in my case, my performance of llama2 in socialQA drops from 55% to around 20% if I use left padded batch inference instead of one by one generate.
2. If instead, I passed in the attention_map generated by the left_padding tokenizer to model.generate function, the model will throw an error when doing sampling because some values in the hidden states are inf or nan. This numerical instability suddenly appeared because train-test mismatch: **By examining the locations of these infs/nans, I found them only shows up in the position of those padded token and are caused by the attention_map.**
3. The reason why attention map are causing the numerical instability is because the current way of generating attention mask did not considered the left padded situation and it will cause the left padded tokens to have a fully masked attention tensor ! While the model was never trained with any token that can not see any(including itself) token, the model thus generates anomaly values and creates nan/inf.
So this PR is trying to fix two bugs I observed:
1. The attention_mask created for left_padded values will contain -inf value due to the operation "expanded_attn_mask + combined_attention_mask". Consider the attention_map that looks like this ([[1, 1, 1, 1, 1], [0, 0, 0, 1, 1]]). The combined_attention_mask created by line 585 will look like this (under float16)
```
tensor([[[[ 0., -65504., -65504., -65504., -65504.],
[ 0., 0., -65504., -65504., -65504.],
[ 0., 0., 0., -65504., -65504.],
[ 0., 0., 0., 0., -65504.],
[ 0., 0., 0., 0., 0.]]],
[[[ 0., -65504., -65504., -65504., -65504.],
[ 0., 0., -65504., -65504., -65504.],
[ 0., 0., 0., -65504., -65504.],
[ 0., 0., 0., 0., -65504.],
[ 0., 0., 0., 0., 0.]]]], device='cuda:0',
dtype=torch.float16)
```
and the expanded_attn_mask created will look like this
```
tensor([[[[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.]]],
[[[-65504., -65504., -65504., 0., 0.],
[-65504., -65504., -65504., 0., 0.],
[-65504., -65504., -65504., 0., 0.],
[-65504., -65504., -65504., 0., 0.],
[-65504., -65504., -65504., 0., 0.]]]], device='cuda:0',
dtype=torch.float16)
```
And in line 598 these two variables are added together. I believe it will be now clear why left padding causes the attention_map itself contains -inf values and why some tokens has a fully masked attn tensor.
3. My solution then is straightforward, I clamped the variables so it does not overflow, and I forces the left padded values to at least attend to itself. Though the hidden states of the left padded values will not be used by the unpadded tokens due to the attention map, making it cleaned of inf/nan will not break the generation process.
4. I tested in my local cases and I did not observe any performance drop or nan errors during sampling. Though I am not sure if my patches will break any other use cases.
| 08-03-2023 12:02:01 | 08-03-2023 12:02:01 | cc @ArthurZucker |
transformers | 25,283 | open | Use of logging.warn is deprecated in favour of logging.warning | There are a few places where `transformers` uses the deprecated `warn` method on a logger, while most of the library uses `warning`. While this works for now, it will presumably be removed at some point (calling it emits a `DeprecationWarning`) and it means that strict test runners (such as `pytest`) complain about some codepaths.
As far as I can tell, all versions of Python supported by `transformers` support the new spelling (`warning` has been around for a _long_ time) so the upgrade should be simple.
I'd be happy to have a go at a PR for this. | 08-03-2023 11:38:29 | 08-03-2023 11:38:29 | @PeterJCLaw Indeed! Happy to review a PR :) |
transformers | 25,282 | open | Timm models Safetensor weights give 'NoneType' object has no attribute 'get', weight re-initialization and wrong num_labels | ### System Info
My env information:
```
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.31
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
For a GSOC project under [Openvino Toolkit](https://summerofcode.withgoogle.com/archive/2022/organizations/openvino-toolkit), I have working with Timm models through Transformers.
As we know most of the timm models(on HF Hub) are trained or fine-tuned on some variation of Imagenet dataset, and thus are effectively Image classification models. If I attempt to load Timm models using `AutoModelForImageClassification`,
```
import torch
from transformers import AutoModelForImageClassification
model_id = "timm/vit_tiny_r_s16_p8_224.augreg_in21k"
hf_model = AutoModelForImageClassification.from_pretrained( model_id)
out = hf_model(pixel_values = torch.zeros((5, 3, hf_model.config.image_size, hf_model.config.image_size)))
print(out.logits.shape)
```
I get this Error:
```
Traceback (most recent call last):
File "/home/sawradip/Desktop/practice_code/practice_gsoc/optimum-intel/../demo.py", line 10, in <module>
hf_model = AutoModelForImageClassification.from_pretrained( model_id,
File "/home/sawradip/miniconda3/envs/gsoc_env/lib/python3.9/site-packages/transformers/models/auto/auto_factory.py", line 493, in from_pretrained
return model_class.from_pretrained(
File "/home/sawradip/miniconda3/envs/gsoc_env/lib/python3.9/site-packages/transformers/modeling_utils.py", line 2629, in from_pretrained
state_dict = load_state_dict(resolved_archive_file)
File "/home/sawradip/miniconda3/envs/gsoc_env/lib/python3.9/site-packages/transformers/modeling_utils.py", line 449, in load_state_dict
if metadata.get("format") not in ["pt", "tf", "flax"]:
AttributeError: 'NoneType' object has no attribute 'get'
```
I find that this issue doesn't occur if I force transformers to use pytorch weights, and avoid `.safetensors`.
```
import torch
from transformers import AutoModelForImageClassification
model_id = "timm/vit_tiny_r_s16_p8_224.augreg_in21k"
hf_model = AutoModelForImageClassification.from_pretrained( model_id,
use_safetensors = False
)
out = hf_model(pixel_values = torch.zeros((5, 3, hf_model.config.image_size, hf_model.config.image_size)))
print(out.logits.shape)
```
But I still get this warnings in the output, that a lot of weights were not initialized successfully.
```
Some weights of ViTForImageClassification were not initialized from the model checkpoint at timm/vit_tiny_r_s16_p8_224.augreg_in21k and are newly initialized: ['encoder.layer.0.layernorm_before.bias', 'encoder.layer.11.attention.attention.query.weight', 'encoder.layer.1.attention.attention.query.weight', 'encoder.layer.11.attention.output.dense.bias', 'encoder.layer.4.attention.output.dense.bias', 'encoder.layer.4.layernorm_before.bias', 'encoder.layer.10.attention.attention.query.weight', 'encoder.layer.6.attention.attention.key.weight', 'encoder.layer.4.output.dense.bias', 'encoder.layer.0.attention.attention.key.bias', 'encoder.layer.2.layernorm_after.weight', 'encoder.layer.7.attention.output.dense.bias', 'encoder.layer.7.output.dense.weight', 'encoder.layer.10.layernorm_after.bias', 'layernorm.bias', 'encoder.layer.0.attention.attention.key.weight', 'encoder.layer.1.attention.attention.value.bias', 'encoder.layer.4.output.dense.weight', 'embeddings.patch_embeddings.projection.weight', 'encoder.layer.6.attention.output.dense.weight', 'encoder.layer.1.layernorm_after.weight', 'encoder.layer.2.attention.attention.query.weight', 'encoder.layer.3.attention.attention.key.bias', 'encoder.layer.11.layernorm_after.bias', 'encoder.layer.4.attention.output.dense.weight', 'encoder.layer.2.layernorm_before.weight', 'encoder.layer.4.attention.attention.query.bias', 'encoder.layer.6.layernorm_after.weight', 'encoder.layer.4.intermediate.dense.bias', 'encoder.layer.7.layernorm_before.weight', 'encoder.layer.8.attention.attention.value.bias', 'encoder.layer.6.attention.attention.query.weight', 'encoder.layer.8.attention.output.dense.weight', 'encoder.layer.10.layernorm_before.weight', 'encoder.layer.1.intermediate.dense.bias', 'encoder.layer.9.attention.attention.key.weight', 'encoder.layer.6.layernorm_after.bias', 'classifier.bias', 'encoder.layer.1.layernorm_before.bias', 'encoder.layer.6.attention.output.dense.bias', 'encoder.layer.8.intermediate.dense.weight', 'encoder.layer.2.attention.output.dense.bias', 'encoder.layer.10.attention.output.dense.bias', 'encoder.layer.10.attention.attention.query.bias', 'encoder.layer.3.layernorm_before.bias', 'encoder.layer.3.intermediate.dense.weight', 'encoder.layer.5.attention.attention.value.bias', 'encoder.layer.6.attention.attention.value.weight', 'encoder.layer.0.layernorm_after.weight', 'encoder.layer.10.intermediate.dense.bias', 'encoder.layer.0.output.dense.bias', 'encoder.layer.0.attention.output.dense.bias', 'encoder.layer.7.layernorm_after.weight', 'encoder.layer.8.output.dense.bias', 'layernorm.weight', 'encoder.layer.0.output.dense.weight', 'encoder.layer.11.attention.attention.key.weight', 'encoder.layer.2.attention.attention.query.bias', 'encoder.layer.11.attention.attention.value.weight', 'encoder.layer.3.layernorm_after.bias', 'classifier.weight', 'encoder.layer.4.attention.attention.value.weight', 'encoder.layer.8.layernorm_after.weight', 'encoder.layer.9.attention.attention.query.weight', 'encoder.layer.0.intermediate.dense.bias', 'encoder.layer.8.output.dense.weight', 'encoder.layer.1.attention.attention.value.weight', 'encoder.layer.6.output.dense.weight', 'encoder.layer.6.output.dense.bias', 'encoder.layer.5.attention.attention.query.bias', 'encoder.layer.6.attention.attention.key.bias', 'encoder.layer.9.layernorm_before.bias', 'encoder.layer.7.attention.attention.query.weight', 'encoder.layer.5.output.dense.bias', 'encoder.layer.8.layernorm_after.bias', 'encoder.layer.2.attention.attention.key.weight', 'encoder.layer.5.layernorm_after.bias', 'encoder.layer.10.attention.output.dense.weight', 'encoder.layer.7.layernorm_after.bias', 'encoder.layer.5.intermediate.dense.weight', 'encoder.layer.9.attention.attention.value.bias', 'encoder.layer.3.output.dense.weight', 'encoder.layer.2.attention.attention.value.bias', 'encoder.layer.5.attention.attention.key.weight', 'encoder.layer.6.intermediate.dense.bias', 'encoder.layer.6.attention.attention.query.bias', 'encoder.layer.9.output.dense.weight', 'encoder.layer.0.attention.attention.value.weight', 'encoder.layer.3.attention.attention.value.bias', 'encoder.layer.2.layernorm_before.bias', 'encoder.layer.2.output.dense.weight', 'encoder.layer.1.output.dense.weight', 'encoder.layer.4.intermediate.dense.weight', 'encoder.layer.5.attention.attention.value.weight', 'encoder.layer.9.intermediate.dense.weight', 'encoder.layer.8.attention.attention.key.weight', 'encoder.layer.3.attention.attention.value.weight', 'encoder.layer.11.intermediate.dense.weight', 'encoder.layer.7.attention.attention.key.weight', 'encoder.layer.0.attention.attention.value.bias', 'encoder.layer.2.attention.attention.value.weight', 'encoder.layer.5.layernorm_before.bias', 'encoder.layer.0.intermediate.dense.weight', 'encoder.layer.5.intermediate.dense.bias', 'encoder.layer.2.intermediate.dense.bias', 'encoder.layer.5.layernorm_before.weight', 'encoder.layer.1.attention.output.dense.weight', 'encoder.layer.7.attention.attention.value.weight', 'encoder.layer.6.layernorm_before.weight', 'encoder.layer.3.attention.attention.key.weight', 'encoder.layer.11.attention.attention.query.bias', 'encoder.layer.5.attention.output.dense.bias', 'encoder.layer.6.layernorm_before.bias', 'encoder.layer.3.attention.output.dense.weight', 'encoder.layer.11.attention.output.dense.weight', 'encoder.layer.9.attention.output.dense.bias', 'encoder.layer.10.attention.attention.value.weight', 'encoder.layer.7.attention.attention.key.bias', 'encoder.layer.10.attention.attention.value.bias', 'encoder.layer.3.attention.output.dense.bias', 'encoder.layer.4.attention.attention.value.bias', 'encoder.layer.0.attention.output.dense.weight', 'encoder.layer.5.attention.output.dense.weight', 'encoder.layer.2.attention.attention.key.bias', 'encoder.layer.3.intermediate.dense.bias', 'encoder.layer.5.output.dense.weight', 'encoder.layer.8.attention.attention.query.weight', 'encoder.layer.3.attention.attention.query.bias', 'encoder.layer.1.attention.attention.key.weight', 'encoder.layer.4.layernorm_after.weight', 'encoder.layer.7.intermediate.dense.bias', 'encoder.layer.7.attention.attention.value.bias', 'encoder.layer.3.layernorm_before.weight', 'encoder.layer.11.attention.attention.key.bias', 'encoder.layer.10.output.dense.bias', 'encoder.layer.8.intermediate.dense.bias', 'encoder.layer.9.intermediate.dense.bias', 'encoder.layer.11.output.dense.weight', 'encoder.layer.1.attention.output.dense.bias', 'encoder.layer.3.output.dense.bias', 'encoder.layer.4.attention.attention.key.weight', 'encoder.layer.10.attention.attention.key.weight', 'encoder.layer.4.layernorm_before.weight', 'encoder.layer.9.attention.attention.value.weight', 'encoder.layer.5.attention.attention.query.weight', 'encoder.layer.2.output.dense.bias', 'encoder.layer.0.attention.attention.query.weight', 'encoder.layer.10.intermediate.dense.weight', 'encoder.layer.8.attention.attention.value.weight', 'encoder.layer.4.attention.attention.key.bias', 'encoder.layer.4.layernorm_after.bias', 'encoder.layer.6.intermediate.dense.weight', 'encoder.layer.7.intermediate.dense.weight', 'encoder.layer.9.attention.output.dense.weight', 'encoder.layer.11.output.dense.bias', 'encoder.layer.0.layernorm_after.bias', 'encoder.layer.9.attention.attention.query.bias', 'encoder.layer.11.attention.attention.value.bias', 'encoder.layer.8.attention.attention.key.bias', 'encoder.layer.2.attention.output.dense.weight', 'encoder.layer.9.layernorm_after.bias', 'encoder.layer.11.layernorm_after.weight', 'encoder.layer.6.attention.attention.value.bias', 'encoder.layer.2.layernorm_after.bias', 'encoder.layer.9.layernorm_after.weight', 'encoder.layer.1.attention.attention.key.bias', 'encoder.layer.10.output.dense.weight', 'encoder.layer.7.attention.attention.query.bias', 'embeddings.cls_token', 'encoder.layer.2.intermediate.dense.weight', 'encoder.layer.11.layernorm_before.weight', 'encoder.layer.0.attention.attention.query.bias', 'encoder.layer.1.layernorm_after.bias', 'encoder.layer.3.attention.attention.query.weight', 'encoder.layer.1.output.dense.bias', 'encoder.layer.10.layernorm_after.weight', 'encoder.layer.5.layernorm_after.weight', 'encoder.layer.1.layernorm_before.weight', 'encoder.layer.0.layernorm_before.weight', 'encoder.layer.5.attention.attention.key.bias', 'encoder.layer.8.layernorm_before.weight', 'encoder.layer.3.layernorm_after.weight', 'encoder.layer.10.layernorm_before.bias', 'embeddings.position_embeddings', 'encoder.layer.11.intermediate.dense.bias', 'encoder.layer.7.layernorm_before.bias', 'encoder.layer.1.attention.attention.query.bias', 'encoder.layer.10.attention.attention.key.bias', 'encoder.layer.7.attention.output.dense.weight', 'encoder.layer.9.layernorm_before.weight', 'encoder.layer.1.intermediate.dense.weight', 'encoder.layer.4.attention.attention.query.weight', 'encoder.layer.8.attention.attention.query.bias', 'encoder.layer.7.output.dense.bias', 'encoder.layer.8.layernorm_before.bias', 'encoder.layer.9.output.dense.bias', 'encoder.layer.8.attention.output.dense.bias', 'embeddings.patch_embeddings.projection.bias', 'encoder.layer.11.layernorm_before.bias', 'encoder.layer.9.attention.attention.key.bias']
```
Meaning this models directly can not be used for classification on imagenet.
But I still get a output the shape,(number of output classes: 2) which is not the expected number of class for this model
```
torch.Size([5, 2])
```
Whereas the model name `timm/vit_tiny_r_s16_p8_224.augreg_in21k` indicates that, the weights were fine-tuned for `imagenet-21k`, meaning classes 21843.
This happens because the attached model `config` files for all timm models in the hub, contains the number of output classes in `num_classes` parameter. Whereas `AutoConfig` expects the `num_labels` parameter from the config file, and not finding such an parameter, it assigns the default value 2, as can be seen [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/configuration_utils.py#L331).
So we can see in the model,
```
print(hf_model.config.num_classes)
-> 21843
print(hf_model.config.num_labels)
->2
```
### I know there are a number of issues, but it is not possible to reproduce the later ones without fixing the previous one. So creating separate issues for each one would be more cumbersome for the reader.
Let me summarize the points I am making:
1. Can not load timm models through `AutoModelForImageClassification` due to loading from `safetensors` weight.
2. If we mention explicitly`use_safetensors = False` , then the pytorch weights are loaded but Huge numbers of weights are initialized randomly.So the models won't be useful out of the box.
3. For all models, number of output classes are 2, and unlike timm's `create_model`, there is no option for specifying `num_classes` by users without modifying the config file.
Is this behaviour expected?
@amyeroberts @rwightman
### Expected behavior
Expected behavior is ,
This mentioned code block will output:
```
torch.Size([5, 21843])
``` | 08-03-2023 09:20:08 | 08-03-2023 09:20:08 | @sawradip `timm` weights on the hub work in timm, unless I'm missing something (some automatic conversion was added that I'm not aware) I don't think there is any expectation you can load them in `transformers`? I feel the pytorch native weights is a bug that it doesn't crash and it's probably not loading any keys...

|
transformers | 25,281 | closed | Docs: Update list of `report_to` logging integrations in docstring | # What does this PR do?
## Pull Request overview
* Add missing `dagshub`, `codecarbon` and `flyte` integrations to `TrainingArguments` docstring.
* Update `report_to` type hint to allow strings.
## Details
I also converted the ordering back to alphabetical.
I considered using a typing `Literal` as the type hint to help users via their IDE, but I haven't implemented it here as to not clash with the existing style.
## Before submitting
- [x] This PR fixes a typo or improves the docs
## Who can review?
@sgugger
- Tom Aarsen
| 08-03-2023 08:52:32 | 08-03-2023 08:52:32 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,280 | open | How to download files from HF spaces | ### System Info
google colab
### Who can help?
@sanchit-gandhi @rock
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
i tried:
```
from huggingface_hub import hf_hub_download,hf_hub_url
# model_path = hf_hub_download(repo_id="xinyu1205/recognize-anything", filename="tag2text_swin_14m.pth", local_dir = "/content")
```
but throws an error repo not present
### Expected behavior
download the file | 08-03-2023 07:02:03 | 08-03-2023 07:02:03 | Hi @andysingal,
There is a typo in the repo_id. The correct command is:
```
model_path = hf_hub_download(repo_id="xinyu1205/recognize_anything_model", filename="tag2text_swin_14m.pth", local_dir = "/content")
```
If you receive an error that a repo doesn't exist, the best thing to do is check directly on the hub for the repo and file name. <|||||>The file exists in the space
On Thu, Aug 3, 2023 at 15:41 amyeroberts ***@***.***> wrote:
> Hi @andysingal <https://github.com/andysingal>,
>
> There is a typo in the repo_id. The correct command is:
>
> model_path = hf_hub_download(repo_id="xinyu1205/recognize_anything_model", filename="tag2text_swin_14m.pth", local_dir = "/content")
>
> If you receive an error that a repo doesn't exist, the best thing to do is
> check directly on the hub for the repo and file name.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/25280#issuecomment-1663711815>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AE4LJNPJ7VV53GDNHXAUTCLXTN2N7ANCNFSM6AAAAAA3CJWHSU>
> .
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
<|||||>If downloading from the space, then you should specify the repo type in the `hf_hub_download` command
```
model_path = hf_hub_download(repo_id="xinyu1205/recognize-anything", filename="tag2text_swin_14m.pth", local_dir = "/content", repo_type="space")
``` |
transformers | 25,279 | closed | CI 🚀 even more | # What does this PR do?
A follow up of #25274:
- To reduce `torch_job` reaches `95%` RAM --> with this PR, it reaches only `82%`.
- Also smaller RAM usage for: `tf_job`: `60%` | `flax_job`: `86%`
- Avoid the non-modeling files being tested redundantly
- we save the timing for ~ 2 x 8 = 16 min.
Now, all the jobs of the full suite CI runs < 10 minutes (except the new job `non_modeling_job`, but it takes ~2 min to restore the cache!)
<img width="206" alt="Screenshot 2023-08-03 081339" src="https://github.com/huggingface/transformers/assets/2521628/07a8b1b5-7521-4d8c-8d7e-11b176c427c4">
| 08-03-2023 06:03:20 | 08-03-2023 06:03:20 | Well, request a review too quickly, sorry, but just a few tiny thing to fix ...<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>OK, fair point. At least a (closed) PR is in the history for reference if we ever need it in the future. Thanks!<|||||>(we will need to keep an eye on the `torch_job` if something strange happens - mostly hanging in a full run: likely an OOM and some workers are killed.)<|||||>We can then go back to 6 workers instead of 8 if it happens. |
transformers | 25,278 | open | Llama tokenizer add_prefix_space | Hi @sgugger
This PR enables llama tokenizer supporting `add_prefix_space`.
Would you please help me review it? Thanks! | 08-03-2023 03:36:00 | 08-03-2023 03:36:00 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25278). All of your documentation changes will be reflected on that endpoint.<|||||>Hi @sgugger , I have the same request here. My problem is as follows:
"\nObservation" is a substring of "!\nObservation", but in the encoded version by the `LlamaTokenizerFast` tokenizer, it is not the case anymore. This can be solved if we enable passing the `add_prefix_space` parameter to the tokenizer.
Here is my code:
```python
from transformers import AutoTokenizer
model_name = 'lmsys/vicuna-13b-v1.3'
tokenizer = AutoTokenizer.from_pretrained(model_name, add_special_tokens=False, padding=True, use_fast=True)
print(tokenizer)
for stop_word in ['\nObservation', '!\nObservation']:
print(f'++++++++++{stop_word}+++++++++++++')
tokens = tokenizer.tokenize(stop_word, add_special_tokens=False)
print(tokens)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
```
And here is the output:
```bash
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565, and set the legacy attribute accordingly.
LlamaTokenizerFast(name_or_path='lmsys/vicuna-13b-v1.3', vocab_size=32000, model_max_length=2048, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'eos_token': AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'unk_token': AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'pad_token': '<unk>'}, clean_up_tokenization_spaces=False)
++++++++++
Observation+++++++++++++
['▁', '<0x0A>', 'Ob', 'serv', 'ation']
[29871, 13, 6039, 2140, 362]
++++++++++!
Observation+++++++++++++
['▁!', '<0x0A>', 'Ob', 'serv', 'ation']
[1738, 13, 6039, 2140, 362]
```
As you can see, [29871, 13, 6039, 2140, 362] is not a subset of [1738, 13, 6039, 2140, 362] anymore. This is because the LlamaTokenizerFast always adds a prefix space before a word.
<|||||>cc @ArthurZucker |
transformers | 25,277 | open | Unable to quantize Meta's new AudioCraft MusicGen model | ### System Info
- Windows 11 64bit
- Python 3.10.12
- Torch v2.0.1+cu117
- Transformers v4.31.0
- audiocraft v0.0.2
- bitsandbytes v0.41.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Hi, I'm attempting to quantize Meta's new MusicGen model with bitsandbytes (through the Transformers library) and I've run into a bug with the `deepcopy` function. I'm not familiar with PyTorch's deepcopy function or why this error may be occurring, but I am able to side-step it with a hack and get a bit further until I reach another error, this time with the Transformers library.
The first error:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
bin C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\bitsandbytes\libbitsandbytes_cuda117.dll
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 1599, in from_pretrained
return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\modeling_utils.py", line 2719, in from_pretrained
modules_to_not_convert = get_keys_to_not_convert(model)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\utils\bitsandbytes.py", line 257, in get_keys_to_not_convert
tied_model = deepcopy(model) # this has 0 cost since it is done inside `init_empty_weights` context manager`
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 297, in _reconstruct
value = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 297, in _reconstruct
value = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 297, in _reconstruct
value = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 297, in _reconstruct
value = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 297, in _reconstruct
value = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 172, in deepcopy
y = _reconstruct(x, memo, *rv)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 271, in _reconstruct
state = deepcopy(state, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 146, in deepcopy
y = copier(x, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 231, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\copy.py", line 153, in deepcopy
y = copier(memo)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\_tensor.py", line 86, in __deepcopy__
raise RuntimeError(
RuntimeError: Only Tensors created explicitly by the user (graph leaves) support the deepcopy protocol at the moment
```
The hack:
```python
torch.save(model, "temp.pt")
tied_model = torch.load("temp.pt")
```
The second error after using the hack:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
bin C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\bitsandbytes\libbitsandbytes_cuda117.dll
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
>>> inputs = processor(text=["80s pop track with bassy drums and synth"], padding=True, return_tensors="pt")
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 2430, in generate
outputs = self.sample(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\generation\utils.py", line 2642, in sample
outputs = self(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 1916, in forward
decoder_outputs = self.decoder(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 1029, in forward
outputs = self.model(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 938, in forward
decoder_outputs = self.decoder(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 848, in forward
layer_outputs = decoder_layer(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\transformers\models\musicgen\modeling_musicgen.py", line 394, in forward
hidden_states = self.self_attn_layer_norm(hidden_states)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\modules\normalization.py", line 190, in forward
return F.layer_norm(
File "C:\Users\fkdlam\anaconda3\envs\audiocraft\lib\site-packages\torch\nn\functional.py", line 2515, in layer_norm
return torch.layer_norm(input, normalized_shape, weight, bias, eps, torch.backends.cudnn.enabled)
RuntimeError: expected scalar type Float but found Half
```
This is the same code provided in [an example](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen#textconditional-generation) for generating music in the Transformers documentation, except I've added the `load_in_8bit` flag. I'm not sure how to fix this one though. I've created [an issue](https://github.com/TimDettmers/bitsandbytes/issues/669) in the bitsandbytes repository too.
### Expected behavior
Being able to run the MusicGen quantized model with bitsandbytes and obtain audio data output. | 08-03-2023 00:18:53 | 08-03-2023 00:18:53 | I figured out a fix by adding the line
```python
inputs_embeds = inputs_embeds.to(torch.float16)
```
right after line 776, but I noticed commit https://github.com/huggingface/transformers/commit/03f98f96836477f6f5b86957d3ce98778cad5d94 which also fixes this bug. So the second bug is fixed if you're using a version of transformers since that commit a week ago.
Now we are down to two problems: the original `deepcopy` bug and the fact that for some reason the quantized MusicGen model runs over 2x as slow as the non-quantized one. Not sure why that is because quantized models should be faster. I can't do anything about it so I'm at a dead end here.<|||||>Also, non-quantized, normal musicgen-large is about 2x slower on Transformers than Meta's own code. Interestingly musicgen-small is a bit faster than Meta's own code. About 10% faster.<|||||>cc @younesbelkada @sanchit-gandhi <|||||>For benchmarking `transformers` vs `audiocraft` - could you ensure that the `transformers` model is put in half (fp16) precision? By default, we always load in fp32 precision on CPU, whereas `audiocraft` always loads the model in fp16 precision on the GPU. Running the `transformers` model in fp16 half precision should give a considerable speed-up vs fp32 full precision:
```python
model = MusicGenForConditionalGeneration.from_pretrained("facebook/musicgen-large", torch_dtype=torch.float16)
```
We can make this faster still by adding Flash Attention with a Better Transformers integration! This should give a further 10-15% speed-up<|||||>Regarding the quantisation, I was **not** able to load the model using bitsandbytes==0.40.0 using the following code snippet:
```python
from transformers import MusicgenForConditionalGeneration
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
```
<details>
<summary> Traceback </summary>
```python
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
File ~/transformers/src/transformers/models/musicgen/modeling_musicgen.py:1595, in MusicgenForConditionalGeneration.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1589 logger.warning(
1590 "Fast initialization is currently not supported for MusicgenForConditionalGeneration. "
1591 "Falling back to slow initialization..."
1592 )
1593 kwargs["_fast_init"] = False
-> 1595 return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
File ~/transformers/src/transformers/modeling_utils.py:2744, in PreTrainedModel.from_pretrained(cls, pretrained_model_name_or_path, config, cache_dir, ignore_mismatched_sizes, force_download, local_files_only, token, revision, use_safetensors, *model_args, **kwargs)
2742 # We keep some modules such as the lm_head in their original dtype for numerical stability reasons
2743 if llm_int8_skip_modules is None:
-> 2744 modules_to_not_convert = get_keys_to_not_convert(model)
2745 else:
2746 modules_to_not_convert = llm_int8_skip_modules
File ~/transformers/src/transformers/utils/bitsandbytes.py:257, in get_keys_to_not_convert(model)
245 r"""
246 An utility function to get the key of the module to keep in full precision if any For example for CausalLM modules
247 we may want to keep the lm_head in full precision for numerical stability reasons. For other architectures, we want
(...)
253 Input model
254 """
255 # Create a copy of the model and tie the weights, then
256 # check if it contains tied weights
--> 257 tied_model = deepcopy(model) # this has 0 cost since it is done inside `init_empty_weights` context manager`
258 tied_model.tie_weights()
260 tied_params = find_tied_parameters(tied_model)
File /usr/lib/python3.10/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.10/copy.py:271, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
269 if state is not None:
270 if deep:
--> 271 state = deepcopy(state, memo)
272 if hasattr(y, '__setstate__'):
273 y.__setstate__(state)
File /usr/lib/python3.10/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.10/copy.py:231, in _deepcopy_dict(x, memo, deepcopy)
229 memo[id(x)] = y
230 for key, value in x.items():
--> 231 y[deepcopy(key, memo)] = deepcopy(value, memo)
232 return y
File /usr/lib/python3.10/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.10/copy.py:297, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
295 for key, value in dictiter:
296 key = deepcopy(key, memo)
--> 297 value = deepcopy(value, memo)
298 y[key] = value
299 else:
[... skipping similar frames: deepcopy at line 172 (1 times)]
File /usr/lib/python3.10/copy.py:271, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
269 if state is not None:
270 if deep:
--> 271 state = deepcopy(state, memo)
272 if hasattr(y, '__setstate__'):
273 y.__setstate__(state)
File /usr/lib/python3.10/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.10/copy.py:231, in _deepcopy_dict(x, memo, deepcopy)
229 memo[id(x)] = y
230 for key, value in x.items():
--> 231 y[deepcopy(key, memo)] = deepcopy(value, memo)
232 return y
[... skipping similar frames: deepcopy at line 172 (1 times)]
File /usr/lib/python3.10/copy.py:297, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
295 for key, value in dictiter:
296 key = deepcopy(key, memo)
--> 297 value = deepcopy(value, memo)
298 y[key] = value
299 else:
[... skipping similar frames: deepcopy at line 172 (6 times), _deepcopy_dict at line 231 (3 times), _reconstruct at line 271 (3 times), deepcopy at line 146 (3 times), _reconstruct at line 297 (2 times)]
File /usr/lib/python3.10/copy.py:297, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
295 for key, value in dictiter:
296 key = deepcopy(key, memo)
--> 297 value = deepcopy(value, memo)
298 y[key] = value
299 else:
File /usr/lib/python3.10/copy.py:172, in deepcopy(x, memo, _nil)
170 y = x
171 else:
--> 172 y = _reconstruct(x, memo, *rv)
174 # If is its own copy, don't memoize.
175 if y is not x:
File /usr/lib/python3.10/copy.py:271, in _reconstruct(x, memo, func, args, state, listiter, dictiter, deepcopy)
269 if state is not None:
270 if deep:
--> 271 state = deepcopy(state, memo)
272 if hasattr(y, '__setstate__'):
273 y.__setstate__(state)
File /usr/lib/python3.10/copy.py:146, in deepcopy(x, memo, _nil)
144 copier = _deepcopy_dispatch.get(cls)
145 if copier is not None:
--> 146 y = copier(x, memo)
147 else:
148 if issubclass(cls, type):
File /usr/lib/python3.10/copy.py:231, in _deepcopy_dict(x, memo, deepcopy)
229 memo[id(x)] = y
230 for key, value in x.items():
--> 231 y[deepcopy(key, memo)] = deepcopy(value, memo)
232 return y
File /usr/lib/python3.10/copy.py:153, in deepcopy(x, memo, _nil)
151 copier = getattr(x, "__deepcopy__", None)
152 if copier is not None:
--> 153 y = copier(memo)
154 else:
155 reductor = dispatch_table.get(cls)
File ~/hf/lib/python3.10/site-packages/torch/_tensor.py:86, in Tensor.__deepcopy__(self, memo)
84 return handle_torch_function(Tensor.__deepcopy__, (self,), self, memo)
85 if not self.is_leaf:
---> 86 raise RuntimeError(
87 "Only Tensors created explicitly by the user "
88 "(graph leaves) support the deepcopy protocol at the moment"
89 )
90 if id(self) in memo:
91 return memo[id(self)]
RuntimeError: Only Tensors created explicitly by the user (graph leaves) support the deepcopy protocol at the moment
```
</details>
However, I was with:
```python
from transformers import MusicgenForConditionalGeneration
import torch
with torch.no_grad():
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", load_in_8bit=True)
```
I can take a deeper look into why the bnb conversion is failing unless @younesbelkada has an idea from this behaviour!
Note that if you care about inference speed, your best bet is to stick with fp16 inference here:
```python
from transformers import MusicgenForConditionalGeneration
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", torch_dtype=torch.float16)
```
|
transformers | 25,276 | open | vectorize PrefixConstrainedLogitsProcessor | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25217 (in part).
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@gante | 08-02-2023 20:56:57 | 08-02-2023 20:56:57 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25276). All of your documentation changes will be reflected on that endpoint.<|||||>There's a silly shape thing happening here which I'll try to debug ASAP (unless others are interested). Unfortunately testing locally is not working since I'm on Silicon and some dependencies for dev aren't available ☹️ but this looks close. I'll want to think hard about the vectorization of the function (which is slightly different and hopefully not breaking).<|||||>@erip thank you for jumping into the issue 💪 LMK when it is ready for review (assuming it yields speedups)<|||||>I believe it'll yield some improvements since there will be much less CPU<->GPU with masking ops. Whether they're significant will be hard to measure. My big concern is that the semantics of the prefix fn will change slightly (reflected in the test); whether this is acceptable is unclear.<|||||>Worst case scenario, a flag could be set at init time (of the logits processor), if the function supports vectorization<|||||>cc @gante I think this is ready for review. Nothing too controversial here, but I can add a fallback to original behavior in case the fn doesn't support vectorization. I'd like to test the speedup eventually, but I think this won't incur regressions at the very least. |
transformers | 25,275 | open | Replace jnp.DeviceArray with jax.Array in FLAX models | ## What does this PR do?
Recent JAX versions have dropped support for jax.numpy.DeviceArray. Many FLAX models refer to jax.numpy.DeviceArray which causes a crash. This PR replaces all references to jax.numpy.DeviceArray with jax.Array.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
cc @sanchit-gandhi
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-02-2023 20:03:56 | 08-02-2023 20:03:56 | Thanks for the fix @akhilgoe - believe this is a duplicate of #24875?<|||||>
> Thanks for the fix @akhilgoe - believe this is a duplicate of #24875?
Yes correct! <|||||>If it's okay with you can we give @mariecwhite the opportunity to finish their PR since they've worked on it since last week? (should be merged asap, just requires CircleCI authentication) Very much appreciate you opening this PR to fix the deprecation though!<|||||>I'm still running into CircleCI issues with https://github.com/huggingface/transformers/pull/24875. Feel free to merge this PR instead.<|||||>Hey guys...Thanks for the update! I don't have a preference, We can use either of the 2 PRs.
|
transformers | 25,274 | closed | CI with `pytest_num_workers=8` for torch/tf jobs | We set `pytest_num_workers` to `3` for `torch_job` and 6 for `tf_job` to avoid OOM. With the recent efforts of reducing model size in CI, we can actually set `pytest_num_workers=8`.
- The full suite: all 3 jobs (PT/TF/Flax): `12-15 minutes`
- On the latest nightly CI (without all PRs merged today): `PT: 37 min | TF: 25 min | Flax: 20 min)`
The `torch_job` reach `95%` of RAM (peak), and `tf_job` is at `80%` of RAM. The `torch_job` with `n8` is a bit dangerous, but I think I have a way to further improve things in follow PR(s). | 08-02-2023 19:21:30 | 08-02-2023 19:21:30 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,273 | closed | use `pytest_num_workers=8` for `torch_job` and `tf_job` | # What does this PR do?
We set `pytest_num_workers` to `3` for `torch_job` and `6` for `tf_job` to avoid OOM. With the recent efforts of reducing model size in CI, we can actually set `pytest_num_workers=8`.
The full suite: all 3 jobs (PT/TF/Flax) 12-15 minutes
(on the latest nightly CI without all PRs merged today: PT: 37 min | TF: 25 min | Flax: 20 min)
The `torch_job` reach 95% of RAM (peak), and `tf_job` is at 80% of RAM. The `torch_job` with `n8` is a bit dangerous, but I think I have a way to further improvement in follow PR(s).
| 08-02-2023 19:17:59 | 08-02-2023 19:17:59 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25273). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,272 | closed | Question about generate method for AutoModelForCausalLM | Hi,
I am trying to use the git model from the pretrained to pass to captum API for calculation of the attribution score.
`
### Initialize the attribution algorithm
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("microsoft/git-base")
ig = IntegratedGradients(model)
`
However, in order for the IG algorithm to work, the "model" should be the forward function of the model.
I need to understand how the output of the model
`
outputs = model(input_ids=training_batch["input_ids"],
attention_mask=training_batch["attention_mask"],
pixel_values=training_batch["pixel_values"],
labels=training_batch["input_ids"])
`
corresponds with output of the generate method `generated_ids = model.generate(pixel_values=pixel_values, max_length=80)`
? | 08-02-2023 17:08:26 | 08-02-2023 17:08:26 | Hi, thanks for raising an issue!
This is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports. |
transformers | 25,271 | open | EncoderDecoder does not automatically create decoder_attention_mask to match decoder_input_ids | ### System Info
```
- `transformers` version: 4.31.0
- Platform: Linux-4.15.0-192-generic-x86_64-with-glibc2.27
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@ArthurZucker @NielsRogge
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I'm using a pretrained BERT model to make a bert2bert model using an EncoderDecoderModel. According to the [documentation](https://huggingface.co/docs/transformers/model_doc/encoder-decoder#transformers.EncoderDecoderModel.forward.decoder_input_ids) and a deprecation warning in the [source code](https://github.com/huggingface/transformers/blob/bef02fd6b9cde975c51607fb936050ef706ff6d8/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py#L42-L47), it says that you no longer need to pass in `decoder_input_ids` as they'll be automatically generated using `labels`. In the docs specifically, [it also goes on to say](https://huggingface.co/docs/transformers/model_doc/encoder-decoder#transformers.EncoderDecoderModel.forward.decoder_attention_mask) that the default behavior of `decoder_attention_mask` is to automatically generate it based on padded tokens in `decoder_input_ids`, so you don't need to pass the decoder attention mask either, as expected.
However, when trying to just pass `input_ids + attention_mask` for the encoder and `labels`, I get a warning that says something to the effect of "we strongly recommend passing an attention mask". If I explicitly pass `input_ids, attention_mask, decoder_input_ids, decoder_attention_mask, and labels`, the warning goes away. Looking at the implementation of creating the `decoder_input_ids` from `labels`, it does indeed seem to skip the generation of `decoder_attention_mask` and simply passes through the value from the arguments, in this case `None`:
https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py#L619-L637
You can recreate the warning in the notebook that Patrick made for the blog (https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Leveraging_Pre_trained_Checkpoints_for_Encoder_Decoder_Models.ipynb#scrollTo=yoN2q0hZUbXN&line=11&uniqifier=1). Specifically, in the `process_data_to_model_inputs` function, you can just comment out the lines which explicitly set `decoder_input_ids` and `decoder_attention_mask`.
### Expected behavior
I'd expect that if you can just pass `labels` to the forward call of EncoderDecoder and it will create `decoder_input_ids`, it would also create `decoder_attention_mask`. The fix is probably a few lines:
```python
if (labels is not None) and (decoder_input_ids is None and decoder_inputs_embeds is None):
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
if decoder_attention_mask is not None:
raise Exception # some error for passing 1/2 of decoder input_id/attn_mask?
decoder_attention_mask = torch.where(decoder_input_ids == self.config.pad_token_id, 0, 1)
``` | 08-02-2023 14:59:12 | 08-02-2023 14:59:12 | somewhat related, it seems like in the notebook, the `decoder_input_ids` nor the `labels` are shifted; Patrick claims it's because:
> `"labels"` are shifted automatically to the left for language modeling training.
but I don't see any evidence of this in the implementation. Was this behavior changed at some point? The notebook seems like it might be out of date?
My current solution to the original `decoder_attention_mask` issue is to manually pass in `decoder_input_ids` shifted 1 to the right with matching `decoder_attention_mask`, while `labels` remains unchanged.<|||||>cc @ArthurZucker @younesbelkada |
transformers | 25,270 | open | Device errors when loading in 8 bit | ### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.31.0
- Platform: Linux-5.10.178-162.673.amzn2.x86_64-x86_64-with-glibc2.26
- Python version: 3.10.10
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes (4 GPUs)
- Using distributed or parallel set-up in script?:
### Who can help?
@younesbelkada
@sgugger
@mue
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
This error occurs when trying to split a quantised `t5-large` model (or any t5 model for that matter) across 4 GPUs using a custom device map (which works when it is not quantised)!
Steps to reproduce:
1.
```
from transformers import AutoTokenizer, DataCollatorWithPadding, TrainingArguments, Trainer, AutoModelForCausalLM, AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
from torch.utils.data import TensorDataset, DataLoader,Dataset
from accelerate import dispatch_model, infer_auto_device_map, init_empty_weights
from accelerate.utils import get_balanced_memory
model_name = "t5-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, cache_dir = 'models', load_in_8bit=True)
```
2.
```
max_memory = get_balanced_memory(
model,
max_memory=None,
no_split_module_classes=["T5Block"],
dtype='float16',
low_zero=False,
)
```
max_memory:
`{0: 263982848, 1: 263982848, 2: 263982848, 3: 13860929536, 'cpu': 189321494528}`
3.
```
device_map = infer_auto_device_map(
model,
max_memory=max_memory,
no_split_module_classes=["T5Block"],
dtype='float16'
)
```
I won't show the entire device_map, just the important part:
```
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder.embed_tokens': 0,
'lm_head': 0,
'encoder.block.0': 0,
'encoder.block.1': 0,
'encoder.block.2': 0,
'encoder.block.3': 0,
'encoder.block.4': 0,
'encoder.block.5': 0,
'encoder.block.6': 0,
'encoder.block.7': 0,
'encoder.block.8': 0,
'encoder.block.9': 0,
'encoder.block.10': 1,
'encoder.block.11': 1,
'encoder.block.12': 1,
```
4.
```
model = dispatch_model(model, device_map=device_map)
for i in model.named_parameters():
print(f"{i[0]} -> {i[1].device}")
```
Again, just the pertinent part:
```
encoder.block.10.layer.0.SelfAttention.q.weight -> cuda:0
encoder.block.10.layer.0.SelfAttention.k.weight -> cuda:0
encoder.block.10.layer.0.SelfAttention.v.weight -> cuda:0
encoder.block.10.layer.0.SelfAttention.o.weight -> cuda:0
encoder.block.10.layer.0.layer_norm.weight -> cuda:0
encoder.block.10.layer.1.DenseReluDense.wi.weight -> cuda:0
encoder.block.10.layer.1.DenseReluDense.wo.weight -> cuda:0
encoder.block.10.layer.1.layer_norm.weight -> cuda:0
encoder.block.11.layer.0.SelfAttention.q.weight -> cuda:1
encoder.block.11.layer.0.SelfAttention.k.weight -> cuda:1
encoder.block.11.layer.0.SelfAttention.v.weight -> cuda:1
encoder.block.11.layer.0.SelfAttention.o.weight -> cuda:1
encoder.block.11.layer.0.layer_norm.weight -> cuda:1
encoder.block.11.layer.1.DenseReluDense.wi.weight -> cuda:1
encoder.block.11.layer.1.DenseReluDense.wo.weight -> cuda:1
encoder.block.11.layer.1.layer_norm.weight -> cuda:1
```
5.
```
batch = tokenizer("Hello World", return_tensors="pt")
model(**batch, decoder_input_ids = batch['input_ids'])
```
### Expected behavior
Error:
```
File ~/anaconda3/envs/pytorch_p310/lib/python3.10/site-packages/transformers/models/t5/modeling_t5.py:260, in T5LayerNorm.forward(self, hidden_states)
257 if self.weight.dtype in [torch.float16, torch.bfloat16]:
258 hidden_states = hidden_states.to(self.weight.dtype)
--> 260 return self.weight * hidden_states
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0!
```
Note that repeating this with `load_in_8bit = False` works normally.
Thanks! | 08-02-2023 13:39:56 | 08-02-2023 13:39:56 | You cannot re-dispatch a model that was loaded in 8bit. You need to pass along your `max_memory` or `device_map` to the call to `from_pretrained`. |
transformers | 25,269 | open | run_clm_no_trainer.py example - problem with most recent checkpoint loading | The example has code for finding the latest checkpoint, but accelerator.load_state isn't called.
https://github.com/huggingface/transformers/blob/1baeed5bdf3c58b723a6125632567f97bdf322c6/examples/pytorch/language-modeling/run_clm_no_trainer.py#L561C15-L561C15 | 08-02-2023 13:39:33 | 08-02-2023 13:39:33 | Hi @TomerRonen34, thanks for raising this issue!
Can you make sure to follow the issue template and include:
* A reproducible code snippet
* Details of the expected and observed behaviour including the full traceback if it exists
* Information about the running environment: run `transformers-cli env` in the terminal and copy-paste the output |
transformers | 25,268 | closed | recommend DeepSpeed's Argument Parsing documentation | # What does this PR do?
Clarify how to properly set the arguments passed by `deepspeed` when running in CLI.
For example the following errors might be raised when running something like `deepspeed --num_gpus=2 fine-tune.py google/flan-t5-xxl` due to args passed by `deepspeed`:
```
usage: fine-tune.py [-h] model_id
fine-tune.py: error: unrecognized arguments: --local_rank=0 --deepspeed llms/flan-t5-fp16-z3.json
usage: fine-tune.py [-h] model_id
fine-tune.py: error: unrecognized arguments: --local_rank=1 --deepspeed llms/flan-t5-fp16-z3.json
```
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@stas00 @sgugger
| 08-02-2023 13:32:15 | 08-02-2023 13:32:15 | cc @pacman100 <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,267 | closed | [MMS] Fix mms | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25260.
The problem is that the model state_dict is retrieved before the weights are tied which in the case of MMS/Wav2Vec2 means before the state dict is rewritten to the correct expected structure since MMS/Wav2Vec2 loads adapter weights when modeling_utils calls `tie_weights`.
I'm not 100% sure if the moving `model.tie_weights()` up here a couple of lines is ok, but it's necessary to fix MMS.
I'm pretty sure it's fine because `tie_weights` should not fundamentally change the state_dict architectures for models != MMS.
I'm not able to fully pinpoint the reason for how this bug came to be, but as stated in #25260 loading MMS
worked on the PR and without having `accelerate` installed it also worked on the main.
There were a couple of PRs that touched similar logic around at the same time or a bit later/sooner which might have caused the issue.
- https://github.com/huggingface/transformers/pull/24200
- https://github.com/huggingface/transformers/pull/24505
- https://github.com/huggingface/transformers/pull/24310
I might have accidentally also not synced my PR branch with "main" before merging so that between starting to work on it and merging a different logic creeped in.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-02-2023 13:26:07 | 08-02-2023 13:26:07 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@ydshieh ok to merge or should we run some more tests?<|||||>The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25267). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,266 | closed | CI with layers=2 | # What does this PR do?
Running a (sub) set of 24315 tests (given by test fetcher) - only tests in `test_modeling_xxx.py`.
(for a full run like nightly run, it doesn't seem change anything about running time - need more investigation)
Running time:
- num_layers = mixed (2, 3, 4, 5, 6) - currently `main`
- torch: 16m
- tf: : 8m
- flax: 11m30
- num_layers = 2
- torch: 12m30
- tf: 8m (not sure nothing change)
- flax: 8m30 | 08-02-2023 13:08:37 | 08-02-2023 13:08:37 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,265 | open | [`Docs` / `BetterTransformer` ] Added more details about flash attention + SDPA | # What does this PR do?
as discussed offline with @LysandreJik
This PR clarifies to users how it is possible to use Flash Attention as a backend for most used models in transformers. As we have a seen some questions from users asking whether it is possible to integrate flash attention into HF models, whereas you can already benefit from it when using `model.to_bettertransformer()`, leveraging the `BetterTransformer` API from 🤗 optimum.
The informations are based from the [official documentation of `torch.nn.functional.scaled_dot_product`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html?highlight=scaled_dot_product_attention#torch.nn.functional.scaled_dot_product_attention)
In the near future, we could also have a small blogpost explaining this as well
To do list / To clarify list:
- Clarify that it is possible to do that for training as well (I did not added much on the training section)
- Maybe add a few lines in overview of performance and scalability to emphasize this?
Let me know if I missed anything else
cc @fxmarty @MKhalusova @stevhliu | 08-02-2023 12:59:23 | 08-02-2023 12:59:23 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25265). All of your documentation changes will be reflected on that endpoint.<|||||>Thanks a lot for the extensive review @stevhliu ! 🎉 |
transformers | 25,264 | open | [Question] How to load AutoFeatureExtractor on GPU? | Hi, I am following this guide to learn how to do audio classification with wav2vec2: https://huggingface.co/docs/transformers/main/tasks/audio_classification
I intend to extract features of my data with the following codes
```
feature_extractor = AutoFeatureExtractor.from_pretrained("/workspace/models/wav2vec2-large-robust")
def preprocess_function(examples):
audio_arrays = [x["array"] for x in tqdm(examples["audio"])]
inputs = feature_extractor(
audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
)
return inputs
encoded_audio_dataset_train = audio_dataset_train.map(preprocess_function, remove_columns="audio", batched=True)
```
But it seems the extractor is loaded to CPU instead of GPU, and I didn't find in documentation how to set the device for loading feature extractor. I assume the feature extraction is done by the wav2vec2 model itself right? If so how to do this on GPU? Or is it mentioned in any documentation that I didn't notice?
This is my first time to use transformers library in audio processing so please forgive my clumsiness.
Any help is much appreciated. | 08-02-2023 12:26:20 | 08-02-2023 12:26:20 | Hi @treya-lin, thanks for raising an issue!
This is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports.
You can move arrays prepared by the feature extractor to the GPU using the `to` method on its outputs:
```
def preprocess_function(examples):
audio_arrays = [x["array"] for x in tqdm(examples["audio"])]
inputs = feature_extractor(
audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
).to("cuda")
return inputs
``` |
transformers | 25,263 | closed | Remove `pytest_options={"rA": None}` in CI | # What does this PR do?
This option causes the (TF/Flax) jobs to spend 6-8 minutes (for a full set run) to prepare something for reporting after the actual tests are finished.
Taking [this TF job (nightly run)](https://app.circleci.com/pipelines/github/huggingface/transformers/69562/workflows/8fd9db08-9730-4d57-90b5-660c8a48a55c/jobs/872686/steps) for example, we can see the situation in the following screenshot
<img width="1044" alt="Screenshot 2023-08-02 132209" src="https://github.com/huggingface/transformers/assets/2521628/67e6bc89-d0d3-4d6a-9090-f3e1042be639">
Note that the torch job doesn't have this option, as it is removed ~ 3 years ago by Stas in #7995. Also, we still have all the reports we need in the artifact tab. (I don't remember the details about `-rA` though - Stas is the expert of this) | 08-02-2023 11:36:03 | 08-02-2023 11:36:03 | _The documentation is not available anymore as the PR was closed or merged._<|||||>
> For reference, I think `-rA` generates a [detailed summary report for all groups](https://docs.pytest.org/en/6.2.x/usage.html#detailed-summary-report).
Oh yes, my memory mixed the `--make-reports` and `-rA` things. Thanks!
<|||||>> As it was removed for the torch job a long time ago, I'm happy for it to be removed here :)
If you were not happy, we will have to spend more🤑 on CircleCI credits 💸 😆 (and for nothing)
|
transformers | 25,262 | open | model.push_to_hub not working for gtr-large while loading with 8-bit using bnb | ### System Info
Issue :- I want to load gtr-large model in 8-bits using bitsandbytes and save it for future usage
model = T5ForConditionalGeneration.from_pretrained('sentence-transformers/gtr-t5-large',load_in_8bit=True)
model.push_to_hub("snigdhachandan/gtr_large_8bit")
Error :-
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/glide/anaconda/envs/llm/lib/python3.11/site-packages/transformers/utils/hub.py", line 814, in push_to_hub
self.save_pretrained(work_dir, max_shard_size=max_shard_size, safe_serialization=safe_serialization)
File "/glide/anaconda/envs/llm/lib/python3.11/site-packages/transformers/modeling_utils.py", line 1820, in save_pretrained
shards, index = shard_checkpoint(state_dict, max_shard_size=max_shard_size, weights_name=weights_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glide/anaconda/envs/llm/lib/python3.11/site-packages/transformers/modeling_utils.py", line 318, in shard_checkpoint
storage_id = id_tensor_storage(weight)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/glide/anaconda/envs/llm/lib/python3.11/site-packages/transformers/pytorch_utils.py", line 290, in id_tensor_storage
return tensor.device, storage_ptr(tensor), storage_size(tensor)
^^^^^^^^^^^^^
AttributeError: 'str' object has no attribute 'device'
Transformers Version :- 4.30.2
Torch Version :- 2.0.1+cu117
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
model = T5ForConditionalGeneration.from_pretrained('sentence-transformers/gtr-t5-large',load_in_8bit=True)
model.push_to_hub("snigdhachandan/gtr_large_8bit")
### Expected behavior
It should have been push to Huggingface Hub | 08-02-2023 11:18:38 | 08-02-2023 11:18:38 | Hi @nss-programmer, thanks for raising this issue.
There's been quite a few updates between bitsandbytes and transformers recently. Could you update your local transformers version to the most recent release `pip install --upgrade transformers` and try again? If that doesn't work, then could you try from source `pip install git+https://github.com/huggingface/transformers` and let us know if either of these work? This way, we can figure out if the issue has already been resolved.
Could you also share more information about the running environment )run `transformers-cli env` in the terminal and copy-paste the output) specifically, the bitsandbytes and huggingface_hub versions installed?
cc @younesbelkada <|||||>Thanks for the ping! The issue you are describing is really close to what I have described in https://github.com/huggingface/transformers/pull/24416 I believe installing the lib from source as @amyeroberts mentioned should resolve it! |
transformers | 25,261 | open | Mask2Former broadcasting issue when running inference on model traced with GPU device | ### System Info
```
- System information: x86_64 GNU/Linux
- Ubuntu version: 18.04
- Python version: 3.8.12
- CUDA version: 11.1
- PyTorch version: 2.0.1
- transformers version: 4.31.0
```
### Who can help?
@amyeroberts
@sgugger
@muellerzr
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import torch
from transformers import Mask2FormerForUniversalSegmentation
device = torch.device("cuda")
model = Mask2FormerForUniversalSegmentation.from_pretrained(
"facebook/mask2former-swin-tiny-coco-instance",
torchscript=True
).eval().to(device)
dummy_input = torch.randn((1,3,640,640)).to(device)
traced_model = torch.jit.trace(model, dummy_input)
with torch.no_grad():
out = traced_model(torch.randn((2,3,640,640)).to(device))
out = traced_model(torch.randn((2,3,640,640)).to(device))
```
The above code generates the following error when calling the **second** forward of `traced_model` (last line):
```
Traceback (most recent call last):
File "mask2former_trace.py", line 14, in <module>
out = traced_model(torch.randn((2,3,640,640)).to(device))
File "~/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
~/python3.8/site-packages/torch/functional.py(378): einsum
~/python3.8/site-packages/transformers/models/mask2former/modeling_mask2former.py(2015): forward
~/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
~/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
~/python3.8/site-packages/transformers/models/mask2former/modeling_mask2former.py(1852): forward
~/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
~/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
~/python3.8/site-packages/transformers/models/mask2former/modeling_mask2former.py(2080): forward
~/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
~/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
~/python3.8/site-packages/transformers/models/mask2former/modeling_mask2former.py(2271): forward
~/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
~/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
~/python3.8/site-packages/transformers/models/mask2former/modeling_mask2former.py(2496): forward
~/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
~/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
~/python3.8/site-packages/torch/jit/_trace.py(1056): trace_module
~/python3.8/site-packages/torch/jit/_trace.py(794): trace
mask2former_trace.py(10): <module>
RuntimeError: einsum(): subscript b has size 2 for operand 1 which does not broadcast with previously seen size 400
```
If I trace the model with batch size 2, i.e. `dummy_input = torch.randn((2,3,640,640)).to(device)`, the same error arises at the **first** forward call of `traced_model`
The issue seems to be [here](https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/mask2former/modeling_mask2former.py#L2015)
### Expected behavior
When tracing on CPU, i.e. in the code above:
```
device = torch.device("cpu")
```
everything works fine. I would expect similar behaviour when tracing on GPU device.
**Additional notes**:
I already tried tracing the model on CPU device, then moving `traced_model` (as well as the input tensors) to GPU, and running inference, but I got the following error:
```
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
```
I know this is a known issue:
https://github.com/huggingface/transformers/issues/5664
https://github.com/huggingface/transformers/issues/22038
so I guess there should be some tensors in Mask2Former created at forward time with the same device as the input, and torchscript does not change that device when running on GPU.
This is the reason why I need to trace the model on GPU. | 08-02-2023 11:06:50 | 08-02-2023 11:06:50 | Hi @matteot11, thanks for reporting this and for providing such a detailed and clean issue report ❤️
Looking into it 🔍 <|||||>@matteot11 I'm going to open up a PR soon to resolve this and remove the einsum operations. In the meantime, if you need to be able to run a compiled model now, it will run on torch nightly (with a bunch of tracer warnings). <|||||>Hi @amyeroberts, thanks for your fast reply.
With torch nightly I am able to correctly forward the `traced_model` multiple times (even if it was exported using `torch==2.0.1`). Thanks for the hint!
I don't know if this is expected, but when running the model traced on GPU, the following assert sometimes fails:
```
device = torch.device("cuda")
dummy_input = torch.randn((2,3,640,640)).to(device)
assert torch.isclose(model(dummy_input)[0], traced_model(dummy_input)[0]).all()
```
This does not happen when exporting the model to the CPU.
Waiting for your PR! |
transformers | 25,260 | closed | ⚠️ [Wav2Vec2-MMS] `pipeline` and `from_pretrained` fail to load the Wav2Vec2 MMS checkpoints | ### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (False)
- Tensorflow version (GPU?): 2.12.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (cpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: `No`
- Using distributed or parallel set-up in script?: `No`
### Who can help?
@sanchit-gandhi @patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Put together a quick colab to run the model as mentioned in [our documentation](https://huggingface.co/docs/transformers/model_doc/mms#loading) - [colab notebook](https://github.com/Vaibhavs10/scratchpad/blob/main/wav2vec2_mms_repro.ipynb)
code snippets:
`Pipeline`
```python
from transformers import pipeline
model_id = "facebook/mms-1b-all"
target_lang = "fra"
pipe = pipeline(model=model_id, model_kwargs={"target_lang": target_lang, "ignore_mismatched_sizes": True})
```
Error (full traceback in the [colab notebook](https://github.com/Vaibhavs10/scratchpad/blob/main/wav2vec2_mms_repro.ipynb)):
```
RuntimeError: Error(s) in loading state_dict for Wav2Vec2ForCTC:
size mismatch for lm_head.weight: copying a param with shape torch.Size([154, 1280]) from checkpoint, the shape in current model is torch.Size([314, 1280]).
size mismatch for lm_head.bias: copying a param with shape torch.Size([154]) from checkpoint, the shape in current model is torch.Size([314]).
You may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method.
```
`Processor` + `Model`
```python
from transformers import Wav2Vec2ForCTC, AutoProcessor
model_id = "facebook/mms-1b-all"
target_lang = "fra"
processor = AutoProcessor.from_pretrained(model_id, target_lang=target_lang)
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang=target_lang, ignore_mismatched_sizes=True)
```
Error (full traceback in the [colab notebook](https://github.com/Vaibhavs10/scratchpad/blob/main/wav2vec2_mms_repro.ipynb)):
```
RuntimeError: Error(s) in loading state_dict for Wav2Vec2ForCTC:
size mismatch for lm_head.weight: copying a param with shape torch.Size([154, 1280]) from checkpoint, the shape in current model is torch.Size([314, 1280]).
size mismatch for lm_head.bias: copying a param with shape torch.Size([154]) from checkpoint, the shape in current model is torch.Size([314]).
You may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method.
```
Similar issues reported by @xenova here: https://github.com/huggingface/transformers/issues/24223#issuecomment-1661174505
### Expected behavior
The expected behaviour would be that dispite the mismatch the model weights are loaded and the mismatch is rectified via `load_adapter` for pipeline (as mentioned here:https://github.com/huggingface/transformers/issues/24223#issuecomment-1595856093) | 08-02-2023 10:22:16 | 08-02-2023 10:22:16 | cc @patrickvonplaten <|||||>It looks like it's related to some recent changes and accelerate.
If you checkout this commit:
https://github.com/huggingface/transformers/commit/b0513b013b10939a2b47ab94933c2cca909716a2
and uninstall accelerate the code snippet works fine for me.<|||||>IIRC, fast loading with accelerate never worked with Wav2Vec2 before because Wav2Vec2 has a weird weight norm parameter, so load adapter was not tested with it. It seems like there were a couple of recent changes though with accelerate and loading with might be related.
I'm sadly not going to have the time to dive deeper here I think. @amyeroberts or @sanchit-gandhi could you try to take this one maybe?<|||||>Also: cc: @muellerzr for accelerate!<|||||>#25267 should fix it, but it'd be good to get a review from @sgugger and @ydshieh here. |
transformers | 25,259 | closed | Update rescale tests - cast to float after rescaling to reflect #25229 | # What does this PR do?
In #25229 - the casting to float was moved back to after rescaling. This wasn't reflected in the specific rescaling tests for EfficientNet and ViVit, resulting in failing tests.
This PR resolves this.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| 08-02-2023 10:01:18 | 08-02-2023 10:01:18 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,258 | open | Why I cannot assign new parameter to the whisper pretrained config? | ### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.4.0-155-generic-x86_64-with-glibc2.31
- Python version: 3.10.11
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Why can I not assign a new parameter to the whisper pretrained config?
Note that the parameter "final_dropout" is not in a config of the "openai/whisper-small".
I used the code piece as following:
```
from transformers import AutoConfig, WhisperModel
config = AutoConfig.from_pretrained("openai/whisper-small", final_dropout=0.1)
config.final_dropout
```
The error is shown below:
```
AttributeError: 'WhisperConfig' object has no attribute 'final_dropout'
```
### Expected behavior
config.final_dropout=0.1
Any guidance would be appreciated.
Tien-Hong | 08-02-2023 09:29:35 | 08-02-2023 09:29:35 | Hi @teinhonglo, thanks for raising this issue!
The reason for not being able to assign through the `from_pretrained` call is a safety check. Unknown kwargs are not applied: their application is ambigious - should they control the `from_pretrained` behaviour or be set as a config attribute? You can see which kwargs weren't set using `return_unused_kwargs` argument c.f. [here](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/configuration#transformers.PretrainedConfig.from_pretrained.return_unused_kwargs) and [here](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/configuration#transformers.PretrainedConfig.from_pretrained.kwargs) in the docs.
After loading in the config, you can set attributes e.g.:
```
from transformers import AutoConfig, WhisperModel
config = AutoConfig.from_pretrained("openai/whisper-small")
config.final_dropout = 0.1
```
|
transformers | 25,257 | open | how to print out the data loaded by each epoch during trainer.train() training? | ### Feature request
please tell to me,
how to print out the data loaded by each epoch during trainer.train() training?
### Motivation
how to print out the data loaded by each epoch during trainer.train() training?
### Your contribution
how to print out the data loaded by each epoch during trainer.train() training? | 08-02-2023 09:13:55 | 08-02-2023 09:13:55 | Hi @ahong007007, thanks for raising an issue!
This is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports. |
transformers | 25,256 | open | Use 'transformers.BertModel.from_pretrained', The code is blocked | 
this is py-spy result:

| 08-02-2023 08:56:36 | 08-02-2023 08:56:36 | Hi, are you running the script/command in some particular setting?
Looks like it's in a multiprocessing setting? Could you provide a self-complete code snippet instead of just uploading screenshot? Thanks in advance.<|||||>if not use pyrocketmq is ok. but use pyrocketmq not ok. the code is:
```
import jpype.imports
jpype.startJVM(classpath=['D:\\soft\\rocketmq-all-4.3.2-bin-release\\lib\\*', ])
from pyrocketmq import *
# import json
# from pyrocketmq.common.message import Message
# from pyrocketmq.client.producer import Producer, SendStatus
# pr = Producer('test_producer')
# pr.setNamesrvAddr('10.2.10.6:9876')
# pr.start()
# body = json.dumps({'name':'Alice', 'age':1}).encode('utf-8')
# msg = Message(topic='test_topic', body=body, tags='girl')
# # send, tcp-like, return sendStatus
# sr = pr.send(msg)
# assert(sr.sendStatus == SendStatus.SEND_OK)
# pr.shutdown()
from multiprocessing import Pool
import json
import time
from typing import List
from pyrocketmq.client.consumer.listener import ConsumeConcurrentlyContext, ConsumeConcurrentlyStatus, MessageListenerConcurrently
from pyrocketmq.client.consumer.consumer import MessageSelector, PushConsumer
from pyrocketmq.common.common import ConsumeFromWhere
from pyrocketmq.common.message import MessageExt
def from_pretrained():
print('--from_pretrained1--')
transformers.BertModel.from_pretrained('/opt/model-service/volume/resource/bert_base')
print('--from_pretrained2--')
return True
# subclass MessageListenerConcurrently to write your own consume action
class MyMessageListenerConcurrently(MessageListenerConcurrently):
def _consumeMessage(self, msgs:List[MessageExt], context:ConsumeConcurrentlyContext) -> ConsumeConcurrentlyStatus:
print('Concurrently', context.ackIndex)
for msg in msgs:
print(msg.body)
print('--_main--')
pool = Pool(processes=2)
bert_res_future = pool.apply_async(func=from_pretrained)
res = bert_res_future.get()
print(res)
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS
cs = PushConsumer('test_push_consumer')
cs.setNamesrvAddr('10.2.10.6:9876')
selector = MessageSelector.byTag('model')
ml = MyMessageListenerConcurrently()
cs.registerMessageListener(ml)
cs.subscribe('test_topic', selector)
cs.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET)
cs.start()
```
The code below is problematic, the code above is not
```
import transformers
def from_pretrained():
print('--from_pretrained1--')
transformers.BertModel.from_pretrained('/opt/model-service/volume/resource/bert_base')
print('--from_pretrained2--')
return True
if __name__ == '__main__':
from multiprocessing import Pool
print('--_main--')
pool = Pool(processes=2)
bert_res_future = pool.apply_async(func=from_pretrained)
res=bert_res_future.get()
print(res)
```
<|||||>Thanks for clarification @yangh0597, appreciated. This is more `pyrocketmq` issue (or the way it works) rather than `transformers`.
In general, when doing such multiprocessing thing or inter-communication stuff between processes, we should not pass large objects (inputs, models) etc., but rather creating the necessary objects in the target process(es). It's on the users to take care what would be necessary steps to avoid the blocking.
We wouldn't be able to help with the details, especially it involves 3rd party library `pyrocketmq`. But I hope the above comment give you some hint(s) to figure out a working solution.<|||||>thakns very much |
transformers | 25,255 | open | fix bad URL to Llama 2 | # What does this PR do?
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
| 08-02-2023 08:43:23 | 08-02-2023 08:43:23 | @fangli80 Running`make fix-copies` and pushing the changes will resolve the failing quality CI checks |
transformers | 25,254 | open | Add FlaxCLIPTextModelWithProjection | # What does this PR do?
`FlaxCLIPTextModelWithProjection` is necessary to support the Flax port of Stable Diffusion XL: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/blob/fb6d705fb518524cabc79c77f13a0e7921bcab3a/text_encoder_2/config.json#L3
I can add some tests, if necessary, after this approach is validated.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten @patil-suraj @sanchit-gandhi @younesbelkada
| 08-02-2023 08:25:27 | 08-02-2023 08:25:27 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25254). All of your documentation changes will be reflected on that endpoint.<|||||>Should we maybe for now just add it in a subfolder of sdxl in diffusers here: https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion_xl instead of having to rely on `transformers` here? I'm not 100% convinced this model is really needed for core transformers usage.
Would also not force the user to have to install transformers from main :-) <|||||>> Should we maybe for now just add it in a subfolder of sdxl in diffusers here: https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion_xl instead of having to rely on `transformers` here? I'm not 100% convinced this model is really needed for core transformers usage.
The [PyTorch version of the same model was added 9 months ago](https://github.com/huggingface/transformers/blob/bd90cda9a6bb4723515c17df1192e53abc8e36e3/src/transformers/models/clip/modeling_clip.py#L1198), so I assumed it was ok.
But sure, we can do that. In that case, how do we deal with it?
- Change the library to `diffusers` here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/blob/main/model_index.json#L15. Unless I'm mistaken, then we'd need to distribute the flax weights separately, or use a branch.
- Create a hack in diffusers to map the library.
>
> Would also not force the user to have to install transformers from main :-)
Yes, of course, this was meant as the long-term solution.
<|||||>Ah yeah good point JAX & PyTorch share the same config - this will become complicated indeed then. Ok let's try to get it merged here. CLIP is important enough to be merged to `transformers` indeed |
transformers | 25,253 | open | RWKV-WORLD-4 | ### Model description
BlinkDL/rwkv-4-world is a repo present on Huggingface i want the model's tokenizer and the model to be added to the Transformers Lib.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
_No response_ | 08-02-2023 07:39:58 | 08-02-2023 07:39:58 | Hi @CosmoLM, thanks for opening this model request!
The RWKV-4 model already exists in transformers -- [PR](https://github.com/huggingface/transformers/pull/22797), [docs](https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/rwkv#rwkv-attention-and-the-recurrent-formulas). To enable loading the model through `Rwkv.from_pretrained`, the checkpoints would need to be converted and model configs push to the hub using [the conversion script.](https://github.com/huggingface/transformers/blob/8021c684ec3023295513be36bdc30e27e6f28cfc/src/transformers/models/rwkv/convert_rwkv_checkpoint_to_hf.py#L4)
I'd suggest opening a discussion on the hub to see if the repo owners would be interested in doing this.
<|||||>The RWKV-pile models are available but not the RWKV-world models because
its tokenizer is not in the json format it is in txt format.
On Wed, 2 Aug, 2023, 4:24 pm amyeroberts, ***@***.***> wrote:
> Hi @CosmoLM <https://github.com/CosmoLM>, thanks for opening this model
> request!
>
> The RWKV-4 model already exists in transformers -- PR
> <https://github.com/huggingface/transformers/pull/22797>, docs
> <https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/rwkv#rwkv-attention-and-the-recurrent-formulas>.
> To enable loading the model through Rwkv.from_pretrained, the checkpoints
> would need to be converted and model configs push to the hub using the
> conversion script.
> <https://github.com/huggingface/transformers/blob/8021c684ec3023295513be36bdc30e27e6f28cfc/src/transformers/models/rwkv/convert_rwkv_checkpoint_to_hf.py#L4>
>
> I'd suggest opening a discussion on the hub to see if the repo owners
> would be interested in doing this.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/25253#issuecomment-1661993346>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/BA7FALGYW7ERQ3LODEA6NADXTIWVPANCNFSM6AAAAAA3A3B6CY>
> .
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
|
transformers | 25,252 | open | run_mae.py can not be used directly on own dir | ### System Info
ref: https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining
python run_mae.py \
--model_type vit_mae \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names pixel_values \
--do_train \
--do_eval
My params:
--model_name_or_path /home/ana/data4/models/vit-mae-base
--dataset_name nateraw/image-folder
--train_dir /home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/
--validation_dir /home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/
--output_dir /home/ana/data4/output_models/rvl_mae_pretrain_demo_10k_100
--remove_unused_columns False
--label_names pixel_values
--mask_ratio 0.75
--norm_pix_loss
--base_learning_rate 1.5e-4
--lr_scheduler_type cosine
--weight_decay 0.05
--num_train_epochs 800
--warmup_ratio 0.05
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--logging_strategy steps
--logging_steps 10
--evaluation_strategy epoch
--save_strategy epoch
--load_best_model_at_end True
--save_total_limit 5
--seed 1337
--do_train
--do_eval
output:
Traceback (most recent call last):
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 397, in <module>
main()
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 222, in main
ds = load_dataset(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1773, in load_dataset
builder_instance = load_dataset_builder(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1528, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/builder.py", line 329, in __init__
data_files = DataFilesDict.from_local_or_remote(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 783, in from_local_or_remote
DataFilesList.from_local_or_remote(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 751, in from_local_or_remote
data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 349, in resolve_patterns_locally_or_by_urls
for path in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions):
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 293, in _resolve_single_pattern_locally
raise FileNotFoundError(error_msg)
FileNotFoundError: Unable to find '/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/' at /
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
build a dir like:
dataset/
train/
1.jpg
2.jpg
eval/
1.jpg
2.jpg
run:
python run_mae.py \
--model_name_or_path /home/ana/data4/models/vit-mae-base
--dataset_name nateraw/image-folder
--train_dir /home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/
--validation_dir /home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/
--output_dir /home/ana/data4/output_models/rvl_mae_pretrain_demo_10k_100
--remove_unused_columns False
--label_names pixel_values
--mask_ratio 0.75
--norm_pix_loss
--base_learning_rate 1.5e-4
--lr_scheduler_type cosine
--weight_decay 0.05
--num_train_epochs 800
--warmup_ratio 0.05
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--logging_strategy steps
--logging_steps 10
--evaluation_strategy epoch
--save_strategy epoch
--load_best_model_at_end True
--save_total_limit 5
--seed 1337
--do_train
--do_eval
### Expected behavior
output:
Traceback (most recent call last):
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 397, in <module>
main()
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 222, in main
ds = load_dataset(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1773, in load_dataset
builder_instance = load_dataset_builder(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1528, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/builder.py", line 329, in __init__
data_files = DataFilesDict.from_local_or_remote(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 783, in from_local_or_remote
DataFilesList.from_local_or_remote(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 751, in from_local_or_remote
data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 349, in resolve_patterns_locally_or_by_urls
for path in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions):
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/data_files.py", line 293, in _resolve_single_pattern_locally
raise FileNotFoundError(error_msg)
FileNotFoundError: Unable to find '/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/' at / | 08-02-2023 07:30:25 | 08-02-2023 07:30:25 | The error
> FileNotFoundError: Unable to find '/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/' at /
shows you don't have local datasets (or there is some issue to locate it). Could you verify this on your own side? Thanks.<|||||>Hi @CheungZeeCn, thanks for raising this issue!
So that we can best help you, could you:
* make sure code snippets and errors are properly formatted - placed between pairs of three backticks e.g. ` ``` code here ``` `.
* Add information about the running environment: run `transformers-cli env` in the terminal and copy-paste the output
As @ydshieh mentions, it looks like the issue is coming from the paths being passed in for `train_dir` and `validation_dir`. They should be the names of folders containing the train and validation datasets relative to `dataset_name`. Based on the paths, the arguments should be:
```
--dataset_name /home/ana/data4/datasets/rvl_cdip/data/pretrain_images
--train_dir train
--validation_dir eval
```<|||||>@ydshieh @amyeroberts thank's for your replies,
```
--dataset_name /home/ana/data4/datasets/rvl_cdip/data/pretrain_images
--train_dir train
--validation_dir eval
```
can not solve my problem.
That's how I fix it:
step1: download dataset python file from: https://huggingface.co/datasets/nateraw/imagefolder/tree/main/ than put it in
my local diretory: /home/ana/data4/datasets/rvl_cdip/data/pretrain_images
step2: use the following params:
```
--dataset_name \
/home/ana/data4/datasets/rvl_cdip/data/pretrain_images \
--train_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/*" \
--validation_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/*"
```
It's not the same as the doc.<|||||>Hi @CheungZeeCn
Glad that you managed to make it work.
Just to make sure, what is works it with `--dataset_name nateraw/image-folder ` like the following
```bash
--dataset_name nateraw/image-folder
--train_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/*" \
--validation_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/*"
```
or the one with `/home/ana/data4/datasets/rvl_cdip/data/pretrain_images \
--train_dir \`?
Thanks in advance!<|||||>Hi, @ydshieh
That's how my local dataset directory looks like:
```
(torch2) ana@pts-m1:~/data4/datasets/rvl_cdip/data/pretrain_images$ pwd
/home/ana/data4/datasets/rvl_cdip/data/pretrain_images
(torch2) ana@pts-m1:~/data4/datasets/rvl_cdip/data/pretrain_images$ ls
eval imagefolder.py train
(torch2) ana@pts-m1:~/data4/datasets/rvl_cdip/data/pretrain_images$ ls eval |head -10
0000298044.jpg
0000553824.jpg
0012197285.jpg
0060128913.jpg
```
and the imagefolder.py is the same as this one https://huggingface.co/datasets/nateraw/imagefolder/blob/main/imagefolder.py
using the following is OK:
```
export WANDB_DISABLED=true
python run_mae.py \
--model_name_or_path \
/home/ana/data4/models/vit-mae-base \
--dataset_name \
/home/ana/data4/datasets/rvl_cdip/data/pretrain_images \
--train_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/*" \
--validation_dir \
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/*" \
--output_dir \
/home/ana/data4/output_models/rvl_mae_pretrain_demo_10k_100 \
--remove_unused_columns \
False \
--label_names \
pixel_values \
--mask_ratio \
0.5 \
--base_learning_rate \
1.5e-4 \
--lr_scheduler_type \
cosine \
--weight_decay \
0.05 \
--num_train_epochs \
800 \
--warmup_ratio \
0.05 \
--per_device_train_batch_size \
32 \
--gradient_accumulation_steps \
8 \
--per_device_eval_batch_size \
8 \
--logging_strategy \
steps \
--logging_steps \
10 \
--evaluation_strategy \
epoch \
--save_strategy \
epoch \
--load_best_model_at_end \
True \
--save_total_limit \
5 \
--seed \
1337 \
--do_train \
--do_eval \
--overwrite_output_dir
```
However, if I tried this:
```
python run_mae.py
--model_name_or_path
/home/ana/data4/models/vit-mae-base
--dataset_name nateraw/image-folder
--train_dir
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/train/*"
--validation_dir
"/home/ana/data4/datasets/rvl_cdip/data/pretrain_images/eval/*"
--output_dir
/home/ana/data4/output_models/rvl_mae_pretrain_demo_10k_100_tmp
--remove_unused_columns
False
--label_names
pixel_values
--mask_ratio
0.5
--base_learning_rate
1.5e-4
--lr_scheduler_type
cosine
--weight_decay
0.05
--num_train_epochs
800
--warmup_ratio
0.05
--per_device_train_batch_size
32
--gradient_accumulation_steps
8
--per_device_eval_batch_size
8
--logging_strategy
steps
--logging_steps
10
--evaluation_strategy
epoch
--save_strategy
epoch
--load_best_model_at_end
True
--save_total_limit
5
--seed
1337
--do_train
--do_eval
```
the output is:
```
Traceback (most recent call last):
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 397, in <module>
main()
File "/home/ana/data4/projects/hf_mae/run_mae.py", line 222, in main
ds = load_dataset(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1773, in load_dataset
builder_instance = load_dataset_builder(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/load.py", line 1528, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/site-packages/datasets/builder.py", line 350, in __init__
info.update(self._info())
File "/home/ana/.cache/huggingface/modules/datasets_modules/datasets/nateraw--image-folder/a2b5eb21064d8bd9b44c3b3fc91ae8205c3002a441852e1b02da78e8025c332e/image-folder.py", line 30, in _info
classes = sorted([x.name.lower() for x in Path(folder).glob('*/**')])
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/pathlib.py", line 1041, in __new__
self = cls._from_parts(args, init=False)
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/pathlib.py", line 682, in _from_parts
drv, root, parts = self._parse_args(args)
File "/home/ana/data1/anaconda3/envs/torch2/lib/python3.8/pathlib.py", line 666, in _parse_args
a = os.fspath(a)
TypeError: expected str, bytes or os.PathLike object, not DataFilesList
```
<|||||>Thanks a lot, we will take a look and update the doc if necessary! |
transformers | 25,251 | open | Defining top_k within pipeline changes output from list to nested list | ### System Info
```
- `transformers` version: 4.30.2
- Platform: Linux-5.14.0-162.22.2.el9_1.x86_64-x86_64-with-glibc2.34
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 1.11.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
```
### Who can help?
@Narsil
@sgugger
### Reproduction
Was trying to output all scores for a single-label classification problem. Initially tried to use `return_all_scores` as written in the docs for TextClassificationPipeline, which returned this error:
```UserWarning: return_all_scores is now deprecated, if want a similar funcionality use top_k=None instead of return_all_scores=True or top_k=1 instead of return_all_scores=False.```
Switched to top_k, but some of my code broke in strange ways. Eventually realized that it was because calling pipeline without top_k returns a list containing a dictionary, but calling it with top_k returns a list containing a list containing a dictionary, regardless of what value top_k is set to.
Without top_k=1:
`from transformers import pipeline`
`classifier = pipeline("sentiment-analysis", model="ProsusAI/finbert")`
`classifier("Inflation Remains Risk Confronting Financial Markets")`
Resulting output:
`[{'label': 'negative', 'score': 0.8932788372039795}]`
With top_k=1:
`from transformers import pipeline`
`classifier = pipeline("sentiment-analysis", model="ProsusAI/finbert", top_k=1)`
`classifier("Inflation Remains Risk Confronting Financial Markets")`
Resulting output:
`[[{'label': 'negative', 'score': 0.8932788372039795}]]`
With top_k=None:
`from transformers import pipeline`
`classifier = pipeline("sentiment-analysis", model="ProsusAI/finbert", top_k=None)`
`classifier("Inflation Remains Risk Confronting Financial Markets")`
Resulting output:
`[[{'label': 'negative', 'score': 0.8932788372039795},`
`{'label': 'neutral', 'score': 0.07486031949520111},`
`{'label': 'positive', 'score': 0.03186087682843208}]]`
This issue does not occur if top_k is set within `__call__`:
`from transformers import pipeline`
`classifier = pipeline("sentiment-analysis", model="ProsusAI/finbert")`
`classifier("Inflation Remains Risk Confronting Financial Markets", top_k=None)`
Resulting output:
`[{'label': 'negative', 'score': 0.8932788372039795},`
`{'label': 'neutral', 'score': 0.07486031949520111},`
`{'label': 'positive', 'score': 0.03186087682843208}]`
### Expected behavior
Behavior should be consistent regardless of whether top_k has been set within pipeline, set within `__call__`, or not set at all.
Also, [the documentation for TextClassificationPipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.TextClassificationPipeline) says that top_k is a parameter under `__call__`, but does not explain that top_k is also a parameter under pipeline. | 08-02-2023 05:12:29 | 08-02-2023 05:12:29 | Hi @Harjas123 thank you for reporting! Our team will take a look.<|||||>also cc @Narsil <|||||>I agree that this is inconsistent but I don't think there is much to do about it now since this has been the case for the past three years, and making any change would break a lot of users code.<|||||>I understand. Would it at least be possible to add a mention of this somewhere in the docs?<|||||>Harmonizing outputs of pipelines is definitely in my mind for V5 if/when it happens :) |
transformers | 25,250 | open | Ko perf train gpu one | <!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.md` to Korean" 으로 부탁드립니다! -->
# What does this PR do?
Translated the `<your_file>.md` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before reviewing
- [ ] Check for missing / redundant translations (번역 누락/중복 검사)
- [ ] Grammar Check (맞춤법 검사)
- [ ] Review or Add new terms to glossary (용어 확인 및 추가)
- [ ] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [ ] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
<!-- 1. 위 체크가 모두 완료된 뒤에, 이 아래에 리뷰를 요청할 팀원들을 멘션해주세요! -->
<!-- May you please review this PR? @keonju2 @harheem @junejae @wonhyeongseo ... -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review? (Final)
<!-- 2. 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! --> | 08-02-2023 03:43:28 | 08-02-2023 03:43:28 | |
transformers | 25,249 | closed | Bump cryptography from 41.0.2 to 41.0.3 in /examples/research_projects/decision_transformer | Bumps [cryptography](https://github.com/pyca/cryptography) from 41.0.2 to 41.0.3.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/pyca/cryptography/blob/main/CHANGELOG.rst">cryptography's changelog</a>.</em></p>
<blockquote>
<p>41.0.3 - 2023-08-01</p>
<pre><code>
* Fixed performance regression loading DH public keys.
* Fixed a memory leak when using
:class:`~cryptography.hazmat.primitives.ciphers.aead.ChaCha20Poly1305`.
* Updated Windows, macOS, and Linux wheels to be compiled with OpenSSL 3.1.2.
<p>.. _v41-0-2:
</code></pre></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/pyca/cryptography/commit/b22271cf3c3dd8dc8978f8f4b00b5c7060b6538d"><code>b22271c</code></a> bump for 41.0.3 (<a href="https://redirect.github.com/pyca/cryptography/issues/9330">#9330</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/774a4a16cbd22a89fdb4195ade9e4fcee27a7afa"><code>774a4a1</code></a> Only check DH key validity when loading a private key. (<a href="https://redirect.github.com/pyca/cryptography/issues/9071">#9071</a>) (<a href="https://redirect.github.com/pyca/cryptography/issues/9319">#9319</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/bfa4d95f0f356f2d535efd5c775e0fb3efe90ef2"><code>bfa4d95</code></a> changelog for 41.0.3 (<a href="https://redirect.github.com/pyca/cryptography/issues/9320">#9320</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/0da7165aa73c0a4865b0a4d9e019db3c16eea55a"><code>0da7165</code></a> backport fix the memory leak in fixedpool (<a href="https://redirect.github.com/pyca/cryptography/issues/9272">#9272</a>) (<a href="https://redirect.github.com/pyca/cryptography/issues/9309">#9309</a>)</li>
<li>See full diff in <a href="https://github.com/pyca/cryptography/compare/41.0.2...41.0.3">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | 08-02-2023 02:22:03 | 08-02-2023 02:22:03 | _The documentation is not available anymore as the PR was closed or merged._<|||||>OK, I won't notify you again about this release, but will get in touch when a new version is available. If you'd rather skip all updates until the next major or minor version, let me know by commenting `@dependabot ignore this major version` or `@dependabot ignore this minor version`.
If you change your mind, just re-open this PR and I'll resolve any conflicts on it.<|||||>@dependabot ignore this major version<|||||>OK, I won't notify you about version 41.x.x again, unless you re-open this PR. |
transformers | 25,248 | open | Allow `trust_remote_code` in example scripts | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Update example scripts to use `trust_remote_code`.
This PR is similar to https://github.com/huggingface/transformers/pull/25167 but for adding the `trust_remote_code` arg instead of updating the `token` arg.
I am not sure if this feature is welcome so I have only modified pytorch `run_glue.py` for now.
I will modify the other files (every file that was modified in https://github.com/huggingface/transformers/pull/25167) if the change is welcome and after you all are happy with the help string
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@ydshieh @sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-01-2023 20:31:51 | 08-01-2023 20:31:51 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25248). All of your documentation changes will be reflected on that endpoint.<|||||>Will do flax and tf tomorrow. I have a few questions though:
1. @ydshieh, this script is still using `use_auth_token`. Is this intended?
https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-pretraining/run_mim_no_trainer.py#L450
2. This script doesnt use `token` or `use_auth_token` for the tokenizer
https://github.com/huggingface/transformers/blob/main/examples/pytorch/contrastive-image-text/run_clip.py#L333-L340
3. The Permutation Language Modeling [script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_plm.py) only uses Auto for config and tokenizer, the model is hardcoded to XLNet. So there are 2 options:
a. Not put `trust_remote_code` in this script -- only the transformers XLNet will be supported.
b. Change the XLNet lines to use Auto, though Im not sure which Auto to use here.
<|||||>
> 1. @ydshieh, this script is still using `use_auth_token`. Is this intended?
No, it's a miss from my side. Nice catch and thanks!
> 2. This script doesnt use `token` or `use_auth_token` for the tokenizer
> https://github.com/huggingface/transformers/blob/main/examples/pytorch/contrastive-image-text/run_clip.py#L333-L340
It's probably already been this even before my `token` PRs. I will update them too :-)
> 3. The Permutation Language Modeling [script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_plm.py) only uses Auto for config and tokenizer, the model is hardcoded to XLNet. So there are 2 options:
> a. Not put `trust_remote_code` in this script -- only the transformers XLNet will be supported.
Let's just keep `a` .
Looking forward your PR completed 🚀
<|||||>Couple more places not using `token` or `use_auth_token`
- Tensorflow examples
- run_clip: Tokenizer
- run_clm: Config, Tokenizer, Model
- run_mlm: Config, Tokenizer, Model
- run_ner: Config, Tokenizer, Model
Most of the no_trainer scripts don't have `token` or `use_auth_token` in the args.
Do we want to add them? |
transformers | 25,247 | open | Enable use of best epoch in Trial, with early stopping, during hyperparameter search | ### Feature request
When running a `Trainer.hyperparameter_search`, each trial's value is calculated from the last epoch's chosen metric. However, especially when using early stopping and `load_best_model_at_end`, it would be useful to use the best model instead.
This could be a parameter of `Trainer.hyperparameter_search` or a an overridable function getting the best value, or some callback.
### Motivation
Often, we use early stopping and take the best model from a particular run because it's possible for models to start overfitting and dropping off after a certain number of epochs. This phenomenon can also appear during hyper parameter search and, as such, we'd like to be able to use the best epoch's value to compare trials.
Without this we may get results that are not fully representative.
### Your contribution
Happy to help testing or in other ways I can. Not sure where to start but if there is a clear place to do it I'd be open to help. | 08-01-2023 19:36:07 | 08-01-2023 19:36:07 | cc @sgugger <|||||>Yes this is not currently supported. Could be nice to add, but this is not high-priority on our side, so it would have to be a contribution :-) Happy to review a PR! |
transformers | 25,246 | closed | Fix return_dict_in_generate bug in InstructBlip generate function | # What does this PR do?
Previously, the postprocessing conducted on generated sequences in InstructBlip's generate function assumed these sequences were tensors (i.e. that `return_dict_in_generate == False`).
This PR updates the InstructBlip generate function to check whether the result of the call to the wrapped language model `generate()` is a tensor: if it's not, we attempt to postprocess the sequence attribute of the returned results object rather than the object itself.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- (Not quite a typo, but a very small bugfix...)
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
- Vision model bug: @amyeroberts
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-01-2023 18:28:04 | 08-01-2023 18:28:04 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,245 | open | BLIP-2 request: If it's even possible, can you please provide an official example script of how to get the text(caption) features and image features into the same vector space (e.g. for cross-modal retrieval/search using BLIP-2 models, similar to what we can already do with CLIP.) Thanks in advance. | ### System Info
linux, python 3.8+, pytorch '1.13.0+cu116'
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
N/A
### Expected behavior
N/A | 08-01-2023 18:21:07 | 08-01-2023 18:21:07 | Hi @wingz1, thanks for raising an issue!
This is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports.
There are code examples of how to use [BLIP](https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/blip#transformers.BlipModel.forward.example) and [BLIP-2](https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/blip-2#transformers.Blip2Model) in the docs. Both have a similar API to CLIP and have the same methods e.g. `get_text_features`, `get_image_features` implemented and return similar outputs. <|||||>Thanks, I figured that -- I will check the forums! Indeed those methods do exist in BLIP-2, but those outputs don't share the same dimensionality or mean the same thing as the equivalent commands in CLIP due to the how the model is set up.<|||||>Not really a useful answer, but from the following lines in the modeling file, you can go `language_projection` to get the same dimension. But it's super questionable regarding if this is `the same space` with the meaningful text/image features.
(and yes, further question on this topic should be on the forum)
> self.language_projection = nn.Linear(config.qformer_config.hidden_size, config.text_config.hidden_size)
> ilanguage_model_inputs = self.language_projection(query_output)
> inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
> inputs_embeds = torch.cat([language_model_inputs, inputs_embeds], dim=1)<|||||>Hi I think multimodal embeddings is something lacking in the current implementation, where we can't extract embeddings obtained by passing both text and image to the QFormer, infact the Qformer in HF doesn't even take text `input_ids` as input [here](https://github.com/huggingface/transformers/blob/66c240f3c950612fa05b2e14c85d4b86c88e473e/src/transformers/models/blip_2/modeling_blip_2.py#L1081 )
Whereas the original Qformer implementation did take text inputs as input_id [here](https://github.com/salesforce/LAVIS/blob/91c8e6863b4b02d7d75167e7d18037ef3a96c54b/lavis/models/blip2_models/Qformer.py#L804) , along with the image and this can be used to extract multimodal embeddings as done in the `extract_features` fn [here](https://github.com/salesforce/LAVIS/blob/f982acc73288408bceda2d35471a8fcf55aa04ca/lavis/models/blip2_models/blip2_qformer.py#L387) |
transformers | 25,244 | open | VQA task guide | This PR adds a new Visual Question Answering task guide to the transformers docs:
fine-tuning ViLT, based on @NielsRogge 's [notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViLT/Fine_tuning_ViLT_for_VQA.ipynb)
| 08-01-2023 17:57:58 | 08-01-2023 17:57:58 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25244). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,243 | closed | RetNet model support | ### Model description
RetNet / Retentive Networks is a new model *archetype* released by microsoft; the research paper is [here](https://arxiv.org/pdf/2307.08621.pdf). As of now, there is *one* model for retnet; [made by me](https://huggingface.co/parsee-mizuhashi/retnet-tiny-wikitext-undertrained); which is undertrained (`loss=8`!) and I am trying to make a second model on a larger arch.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
[commit that has retnet training](https://github.com/microsoft/torchscale/commit/bf65397b26469ac9c24d83a9b779b285c1ec640b)
@donglixp was the main author for commit and cited on the paper
all code is licensed under MIT, including model weights | 08-01-2023 17:35:07 | 08-01-2023 17:35:07 | cc @ArthurZucker @younesbelkada <|||||>p.s. if google offered any bigger TPU's for TRC; i could train retnet-3b (the point at which retnet is better than regular transformers), but as of now; theres retnet_base (small) and retnet_medium (ill upload it when it gets good)<|||||>I am wondering if the original authors released the trained models?<|||||>as far as i know, no official pretrained models were released by microsoft; but the training code is on the torchscale repo, so thats how i am training the models<|||||>Cool model! But as long as we don't have official/ very good pretraining checkpoints, not really anything we can do! <|||||>ah, understood, i'll try to get a good checkpoint; but for now, i assume i can close this and reopen when it finishes training<|||||>oops |
transformers | 25,242 | open | WIP In assisted decoding, pass model_kwargs to model's forward call (fix prepare_input_for_generation in all models) | # What does this PR do?
Previously, assisted decoding would ignore any additional kwargs that it doesn't explicitly handle. This was inconsistent with other generation methods, which pass the model_kwargs through prepare_inputs_for_generation and forward the returned dict to the model's forward call.
The prepare_inputs_for_generation method needs to be amended in all models, as previously it only kept the last input ID when a past_key_values was passed.
Fixes #25020
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@gante
| 08-01-2023 16:05:14 | 08-01-2023 16:05:14 | @sinking-point the PR has "WIP" in the title -- is it still under development, or is it ready to review?<|||||>Not ready yet. Still have to fix more models and see what's breaking the other test. I've deprioritised this somewhat as it's quite time consuming, but I'll keep chipping away at it whenever I can.
If you need this done quickly, you're welcome to help - lmk and I'll add you as a collaborator on my branch.<|||||>Not urgent -- simply double-checking whether it was in need of a review or not :) |
transformers | 25,241 | open | Bug in `PreTrainedModel.resize_token_embeddings` When Using DeepSpeed Zero Stage 3 | ### System Info
transformers version: 4.31.0
Platform: Linux 5.4.238-148.346.amzn2.x86_64
Python version: 3.8.10
Huggingface_hub version: 0.14.1
Safetensors version: 0.3.1
PyTorch version (GPU?): 2.0.1+cu117 (True)
Tensorflow version (GPU?): not installed (NA)
Flax version (CPU?/GPU?/TPU?): not installed (NA)
Jax version: not installed
JaxLib version: not installed
Using GPU in script?: yes
Using distributed or parallel set-up in script?: yes
### Who can help?
@pacman100
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This is a simple test to highlight this inconsistency. Here is brief description of what test script does:
* Starts deepspeed
* Loads a pretrained model
* Using gather gets the weights of first 50 embeddings on each device and stores them in a local tensor
* Reduce the number of embeddings to 50 by using `PreTrainedModel.resize_token_embeddings`
* gets the embedding weights again (note that at this point they are not ds pararmeters anymore)
* Checks the result on each device to see if it matches what we recorded earlier
The script is executed on a multi gpu node as follows
```
deepspeed test.py
```
Where the contents of `test.py` are
```
from transformers import (
TrainingArguments,
AutoModelForCausalLM,
set_seed,
)
import os
import deepspeed
def main() -> None:
set_seed(0)
# enable deepspeed stage 3
training_args = TrainingArguments(output_dir="dummy", remove_unused_columns=False, deepspeed="zero3.json")
# load pretrained model
model_path = "openlm-research/open_llama_3b"
model = AutoModelForCausalLM.from_pretrained(model_path)
# store first 50 embeddings locally in ref
with deepspeed.zero.GatheredParameters(list(model.lm_head.parameters())):
ref = model.lm_head.weight.data[:50, :].clone()
# reduce embeddings to 5, using resize_token_embeddings
model.resize_token_embeddings(50)
# check if the embeddings match what we recorded earlier on each device
# note that after resizng, resize_token_embeddings does not convert the embedding layers to ds parameters
rank = int(os.environ["RANK"])
sanity = all((ref == model.lm_head.weight.data).reshape(-1).tolist())
print(f"{rank}: sanity pass: {sanity}")
if __name__ == "__main__":
main()
```
And contents of `zero3.json` are
```
{
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto",
"zero_allow_untested_optimizer": true,
"gradient_clipping": "auto",
"gradient_accumulation_steps": "auto",
"bfloat16": {
"enabled": true
},
"zero_optimization": {
"stage": 3,
"contiguous_gradients": false,
"overlap_comm": true,
"allgather_bucket_size": 1e8,
"reduce_bucket_size": 2e8,
"stage3_max_live_parameters": 0.7e8,
"stage3_param_persistence_threshold": 5e6,
"stage3_gather_fp16_weights_on_model_save": true
},
"activation_checkpointing": {
"partition_activations": false,
"contiguous_memory_optimization": false,
"number_checkpoints": 100,
"cpu_checkpointing": false
},
"optimizer": {
"type": "Adam",
"params": {
"weight_decay": "auto",
"betas": [
0.9,
0.999
],
"eps": "auto",
"lr": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
}
}
```
### Expected behavior
It is expected that each device would return True. But as of now only the 0th device has the correct value.
Note that in majority of the cases `deepspeed.initialize` is called by Trainer right after `resize_token_embeddings`, where rank 0 values would be scattered and we will have consistency. However if an operation happens in between there will be no consistency
| 08-01-2023 16:04:40 | 08-01-2023 16:04:40 | Hi! Would it possible for you to do `resize_token_embeddings` without DeepSpeed, save the model, and load the new model in the script where you use DeepSpeed.
This might be easier and quicker in terms of solution/workaround (if it works).<|||||>Hi, thanks for the suggestion. I have RCed this and have a nonhacky solution that works nicely. I will create a PR in the next two days to resolve this. |
transformers | 25,240 | open | Docs: introduction to the generate API | # What does this PR do?
This PR adds a sort of landing page on `generate`, which was missing in our docs. This page is useful for beginners and experienced users alike -- it goes through the basic generate API for both LLMs and non-text tasks, common caveats, and ends with pointers for advanced exploration.
I expect that the consolidation of pointers for advanced exploration in a single page will massively improve the discoverability of our various generate-related efforts!
👉 best viewed in the doc preview, since there are gifs :)
Related issue: #24575 | 08-01-2023 15:59:03 | 08-01-2023 15:59:03 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25240). All of your documentation changes will be reflected on that endpoint.<|||||>Do we really want to include non-text parts so prominently here? I think 99% of the users clicking on "Generation" expect to see only text generation and not anything multi-modal.<|||||>I would actually just call it "text-generation" and not "autoregressive generation"<|||||>@patrickvonplaten the non-text parts correspond to a tiny portion of the docs -- given than a significant number of issues in `transformers` come from models like Whisper or BLIP, the benefits may be huge. Pointers to things like quantization or generate classes also apply to them.
The decision to have a separate generate section is somewhat tied to including other modalities. If we include them, then it should be separate. If we don't, I still think generate deserves its own section.
Note that this would be the only guide that is planned to include the non-LLM case :) <|||||>> @patrickvonplaten the non-text parts correspond to a tiny portion of the docs -- given than a significant number of issues in `transformers` come from models like Whisper or BLIP, the benefits may be huge. Pointers to things like quantization or generate classes also apply to them.
>
> The decision to have a separate generate section is somewhat tied to including other modalities. If we include them, then it should be separate. If we don't, I still think generate deserves its own section.
>
> Note that this would be the only guide that is planned to include the non-LLM case :)
Sorry this might not be super in-line with what we discussed in our call earlier, but I think since we're in the task guide here we should stay in a "task"-format that the user expects, no? So more generally speaking: I'm not really looking for a "auto-regressive generation" task - I'm looking for "Text generation" or "Speech recognition" task. Auto-regressive generation is just the underlying method of different tasks but for someone that just looks at how to do a certain task they don't need to know about auto-regressive generation right away no? I think when explaining text-generation on the main page it's good to mention auto-regressive generation, but it shouldn't be the title IMO.
Taking a step back here, I don't fully understand is what is the different between "natural language processing" and "text-generation"?
To me we should either:
- a) Change NLP to NLU and move all text-generation based tasks like "summarization", "translation" and potentially copy "question answering" to "Text Generation"
- b) Or text generation should just live under NLP
I think a) is better to make text generation more prominent and then we can also add more sub sections like "chat", "code generation", maybe below.
The other things we talked about such as k/v cache, speeding up inference / prompting etc... could maybe have sections under "Tutorials" and we link from the different "sub-generation" tasks since they are related to all of them no? |
transformers | 25,239 | closed | Fix set of model parallel in the Trainer when no GPUs are available | # What does this PR do?
Fixes how `self.is_model_parallel` is set in the Trainer when no GPUs are available.
Fixes #25236 | 08-01-2023 14:56:35 | 08-01-2023 14:56:35 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,238 | open | TF-OPT attention mask fixes | With apologies for the delay, this PR should hopefully resolve the issues in #24637. @abb128 can you please try installing from this PR and verify if it resolves your issues? You can install from this PR with:
`pip install --upgrade git+https://github.com/huggingface/transformers.git@tf_opt_fixes`
Fixes #24637 | 08-01-2023 14:50:27 | 08-01-2023 14:50:27 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25238). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,237 | open | Deal with nested configs better in base class | # What does this PR do?
This PR removes the need to override `to_dict` in model configs by implementing the whole logic in the base class. It also deals better with `to_diff_dict` for those configs, by analyzing the dict of sub-configs key by key and not as a whole. This also removes the `is_composition` flag from configs that do not need it: this flag is used to see if the config can be instantiated without any args (like `EncoderDecoderConfig`) but a CLIP config can be instantiated with `CLIPConfig()`.
Lastly this adds an option to set a custom subconfig using a dict instead of the config class, e.g. if someone wants to do:
```py
from transformers import AutoConfig
config = AutoConfig.from_pretrained("openai/clip-vit-base-patch16", text_config = dict(num_hidden_layers = 2))
```
this will now result in `config.text_config` being a proper `CLIPTextConfig` instead of a dict so loading a model like this:
```py
from transformers import CLIPModel
CLIPModel.from_pretrained("openai/clip-vit-base-patch16", text_config = dict(num_hidden_layers = 2))
```
will now work (well assuming shapes match so probably another text config to pass 😅 ) | 08-01-2023 14:42:20 | 08-01-2023 14:42:20 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25237). All of your documentation changes will be reflected on that endpoint.<|||||>@ArthurZucker the `is_composition=True` is not necessary anymore except for configs which have no default for their subconfigs. And it should only be set to `True` in that case, otherwise in `to_diff_dict` we put too much stuff. I adapted the common test to check for that, will also adapt the doc.
I'll also add a test for the instantiation of a subconfig with a dict. |
transformers | 25,236 | closed | Fails to create Trainer object. IndexError: list index out of range at --> torch.device(devices[0]); | ### System Info
The system is google colab, transformers related packages are installed from git.
```
- `transformers` version: 4.32.0.dev0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0.dev0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (gpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: using one GPU
```
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
!pip install -q datasets
!pip install git+https://github.com/microsoft/LoRA
!pip install git+https://github.com/huggingface/accelerate.git
!pip install -q git+https://github.com/huggingface/peft.git
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -i https://test.pypi.org/simple/ bitsandbytes
!pip install -q sentencepiece
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
from peft import AutoPeftModelForCausalLM
MODEL_NAME = <some lora llama2 checkpoint>
model = AutoPeftModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map='auto',
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
is_trainable=True
)
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)
for param in model.parameters():
if param.ndim == 1:
# cast the small parameters (e.g. layernorm) to fp32 for stability
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
from datasets import load_dataset
qa_dataset = load_dataset("squad_v2")
def create_prompt(context, question, answer):
if len(answer["text"]) < 1:
answer = "Cannot Find Answer"
else:
answer = answer["text"][0]
prompt_template = f"### CONTEXT\n{context}\n\n### QUESTION\n{question}\n\n### ANSWER\n{answer}</s>"
return prompt_template
mapped_qa_dataset = qa_dataset.map(lambda samples: tokenizer(create_prompt(samples['context'], samples['question'], samples['answers'])))
import transformers
train_args = transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=1,
warmup_steps=100,
max_steps=100,
learning_rate=1e-3,
fp16=True,
logging_steps=1,
output_dir='outputs',
)
trainer = transformers.Trainer(
model=model,
train_dataset=mapped_qa_dataset["train"],
args=train_args,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
```
Trainer init crashes here:
```
IndexError Traceback (most recent call last)
[<ipython-input-114-29de745c4455>](https://localhost:8080/#) in <cell line: 14>()
12 )
13
---> 14 trainer = transformers.Trainer(
15 model=model,
16 train_dataset=mapped_qa_dataset["train"],
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in __init__(self, model, args, data_collator, train_dataset, eval_dataset, tokenizer, model_init, compute_metrics, callbacks, optimizers, preprocess_logits_for_metrics)
380 self.is_model_parallel = True
381 else:
--> 382 self.is_model_parallel = self.args.device != torch.device(devices[0])
383
384 # warn users
IndexError: list index out of range
```
### Expected behavior
Trainer object should be constructed correctly. | 08-01-2023 14:37:03 | 08-01-2023 14:37:03 | Same issue as: https://discuss.huggingface.co/t/indexerror-on-devices-0-when-initializing-a-trainer/46410<|||||>I can fix that particular issue but you won't be able to actually train a model with CPU/disk offload, only do evaluation.<|||||>I figured out in my case removing
`os.environ["CUDA_VISIBLE_DEVICES"]="0"`
seem to fix the issue.
But it is still stange as an original tutorial I followed had it set and worked on colab https://colab.research.google.com/drive/1Jt9Rpd9J1mEnf5NXREYqM5hSj-UqL24M#scrollTo=o0BZjNgEBvXH
<|||||>[Edit: it was caused by device_map="auto" and is probably what you have meant in your reply. I managed to train by not using device_map="auto". Thank you for your fast reply.]
Also then I instantly run into
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
[<ipython-input-25-c52c20b5cf4b>](https://localhost:8080/#) in <cell line: 14>()
12 )
13
---> 14 trainer = transformers.Trainer(
15 model=model,
16 train_dataset=mapped_qa_dataset["train"],
13 frames
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in __init__(self, model, args, data_collator, train_dataset, eval_dataset, tokenizer, model_init, compute_metrics, callbacks, optimizers, preprocess_logits_for_metrics)
496 # Quantized models doesn't support `.to` operation.
497 if self.place_model_on_device and not getattr(model, "is_quantized", False):
--> 498 self._move_model_to_device(model, args.device)
499
500 # Force n_gpu to 1 to avoid DataParallel as MP will manage the GPUs
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _move_model_to_device(self, model, device)
725
726 def _move_model_to_device(self, model, device):
--> 727 model = model.to(device)
728 # Moving a model to an XLA device disconnects the tied weights, so we have to retie them.
729 if self.args.parallel_mode == ParallelMode.TPU and hasattr(model, "tie_weights"):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in to(self, *args, **kwargs)
1143 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
1144
-> 1145 return self._apply(convert)
1146
1147 def register_full_backward_pre_hook(
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
795 def _apply(self, fn):
796 for module in self.children():
--> 797 module._apply(fn)
798
799 def compute_should_use_set_data(tensor, tensor_applied):
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _apply(self, fn)
818 # `with torch.no_grad():`
819 with torch.no_grad():
--> 820 param_applied = fn(param)
821 should_use_set_data = compute_should_use_set_data(param, param_applied)
822 if should_use_set_data:
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in convert(t)
1141 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None,
1142 non_blocking, memory_format=convert_to_format)
-> 1143 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
1144
1145 return self._apply(convert)
NotImplementedError: Cannot copy out of meta tensor; no data!
``` |
transformers | 25,235 | closed | Docs: separate generate section | # What does this PR do?
A conclusion of the latest doc brainstorming section with @patrickvonplaten was that generate-related doc discoverability will become harder as we add more guides. The plan would envision a tutorial page and a few new developer guides -- in addition to the existing task pages, developer guide, and API reference.
As such, we converged on the need for a new doc section, under which most new docs will reside (see #24575 for the plan), with a focus on the first L of LLMs.
There is no section that would fit perfectly, this is (IMO) the best compromise: it contains a bit of "task", "developer guide", and "performance and scalability", but "task" is the most obvious place to look for this information 🤗 | 08-01-2023 14:35:54 | 08-01-2023 14:35:54 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,234 | closed | Update bark doc | # What does this PR do?
Bark can be greatly optimized with a few lines of code, which is discussed and explained in more detail in this [blog post](https://github.com/huggingface/blog/pull/1353). To encourage adoption and promote the use of optimization, I've added a few lines to the Bark documentation to reflect this.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs
## Who can review?
@sanchit-gandhi , @sgugger, @MKhalusova, feel free to comment on what can improved or clearer!
many thanks!
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-01-2023 12:53:50 | 08-01-2023 12:53:50 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @MKhalusova and @sanchit-gandhi , I've updated the docs according to your comments!
Thanks for the review!<|||||>Thanks @ylacombe for the recent round of changes! |
transformers | 25,233 | closed | add generate method to SpeechT5ForTextToSpeech | # What does this PR do?
This simple PR aims at adding a `generate` method to `SpeechT5ForTextToSpeech`, which does exactly the same than `generate_speech`.
`generate_speech` was left for backward compatibility.
The goal is to make `SpeechT5ForTextToSpeech` compatible with the [incoming TTS pipeline](https://github.com/huggingface/transformers/pull/24952) which should not implement any special cases for older models. More on the matter in [this comment](https://github.com/huggingface/transformers/pull/24952#pullrequestreview-1556507240).
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
- [x] Did you make sure to update the documentation with your changes?
- [x] Did you write any new necessary tests?
## Who can review?
@sanchit-gandhi and @sgugger , WDYT?
Thanks for your help!
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 08-01-2023 11:39:29 | 08-01-2023 11:39:29 | cc @gante as well<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @sanchit-gandhi and @sgugger , thanks for the review!
I would like to add `SpeechT5ForTextToSpeechWithHiFiGAN` in another PR if that's ok with you, since it requires additional tests, and since the changes made in the current PR are enough to use `SpeechT5ForTextToSpeech` with the incoming TTS pipeline!
I can open an issue to talk about `SpeechT5ForTextToSpeechWithHiFiGAN` in the meantime if you want,
thanks <|||||>Yep good with me to add in a follow-up PR! |
transformers | 25,232 | open | AddedToken problems in LlamaTokenizer | ### System Info
- `transformers` version: 4.31.0
- Platform: macOS-13.5-x86_64-i386-64bit
- Python version: 3.9.5
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@ArthurZucker This is a bug reported from my colleague. And I'm not sured whether it's in the list of #23909
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code:
```python
from transformers import LlamaTokenizer
txt = "hello\n" + "<bot>" + "How are you"
dd = {"additional_special_tokens": ["<bot>"]}
tokenizer1 = LlamaTokenizer.from_pretrained(
"./resources/models/llama-2-7b-hf", legacy=True, use_fast=False
)
tokenizer2 = LlamaTokenizer.from_pretrained(
"./resources/models/llama-2-7b-hf", legacy=True, use_fast=False
)
tokenizer2.add_special_tokens(dd)
t1 = tokenizer1.tokenize(txt)
t2 = tokenizer2.tokenize(txt)
print(t1)
print(t2)
```
Output:
```
t1: ['▁hello', '<0x0A>', '<', 'bot', '>', 'How', '▁are', '▁you']
t2: ['▁hello', '<bot>', '▁How', '▁are', '▁you']
```
### Expected behavior
Output:
```
t1: ['▁hello', '<0x0A>', '<', 'bot', '>', 'How', '▁are', '▁you']
t2: ['▁hello', '<0x0A>', '<bot>', '▁How', '▁are', '▁you']
```
| 08-01-2023 11:06:29 | 08-01-2023 11:06:29 | This is part of the `stripping` issue mentionned on the PR. As you can see the following works as expected:
```python
>>> dd = {"additional_special_tokens": [AddedToken("<bot>", rstrip = False)]}
>>> tokenizer2.add_special_tokens(dd)
>>> t1 = tokenizer1.tokenize(txt)
>>> t2 = tokenizer2.tokenize(txt)
>>> print(t1)
>>> print(t2)
['▁hello', '<0x0A>', '<', 'bot', '>', 'How', '▁are', '▁you']
['▁hello', '<0x0A>', '<bot>', '▁How', '▁are', '▁you']
```
The call to `strip` also removed the `\n`:
```python
>>> 'hello\n'.strip()
'hello'
```
<|||||>@ArthurZucker
After reviewing the documentation on `tokenizers`, I noticed there appear to be two additional parameters concerning `AddedToken`: `single_word` and `normalized`. I attempted a few basic tests to better understand their behavior:
```python
tokenizer = LlamaTokenizer.from_pretrained(
"./resources/models/llama-2-7b-hf", legacy=True
)
dd = {"additional_special_tokens": [AddedToken("<bot>", single_word=True)]}
tokenizer.add_special_tokens(dd)
t1 = tokenizer.tokenize("How are you<bot>")
t2 = tokenizer.tokenize("How are you <bot>")
print("t1:", t1)
print("t2:", t2)
```
The output:
```
t1: ['▁How', '▁are', '▁you', '<bot>']
t2: ['▁How', '▁are', '▁you', '▁', '<bot>']
```
If I set `single_word` to False, shouldn't `<bot>` in `t1` fail to match? I couldn't find any code snippets or documentation that clearly define this parameter. Could you perhaps point me to some resources that elaborate on these parameters?"
<|||||>Again, this is also reported, `single_word` is not supported yet (in slow tokenizers) which is why you have no documentation 😉 this is also going to be adressed |
transformers | 25,231 | open | Seq2SeqTrainer.evaluate and predict don't yield the right number of predictions when num_return_sequences > 1 | ### System Info
transformers: 4.31.0
accelerate: 0.21.0
python: 2.11.3
env: macOS 13.4.1
### Who can help?
@gante, I think, because this is related with generation
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
When calling evaluate or predict with `predict_with_generate` and `num_return_sequences` > 1, it does not pass the right amount of sequences to the `compute_metrics` function. It drops `num_return_sequences - 1` sequences in the last batch, in `Accelerator.gather_for_metrics`.
This does not happen when calling `model.generate`, which behaves as expected.
To reproduce run the following script:
```python
from transformers import (AutoModelForSeq2SeqLM, AutoTokenizer,
DataCollatorForSeq2Seq, GenerationConfig,
Seq2SeqTrainer, Seq2SeqTrainingArguments,
T5Tokenizer,BatchEncoding, PreTrainedTokenizer)
from transformers.utils import ModelOutput
from transformers.generation.utils import BeamSearchEncoderDecoderOutput
from datasets import Dataset, load_dataset
INPUT_COLUMN = "question"
TARGET_COLUMN = "answer"
MAX_INPUT_LENGTH = 256
MAX_TARGET_LENGTH = 256
dataset = load_dataset("gsm8k", "main", split="train[:38]")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
tokenizer=T5Tokenizer.from_pretrained("t5-small")
data_collator=DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="pt", padding="longest")
gen_config = GenerationConfig.from_pretrained("t5-small")
gen_config._from_model_config = None
gen_config.max_length = None
gen_config.min_length = None
gen_config.max_new_tokens = 256
gen_config.min_new_tokens = 1
gen_config.num_beams = 5
training_args=Seq2SeqTrainingArguments('.', predict_with_generate=True)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=lambda x: {"samples": x[0].shape[0]},
)
def prepare_data(examples: Dataset) -> BatchEncoding:
# Remove pairs where at least one record is none
inputs = examples[INPUT_COLUMN]
targets = examples[TARGET_COLUMN]
model_inputs = tokenizer(inputs, max_length=MAX_INPUT_LENGTH, truncation=True)
labels = tokenizer(text_target=targets, max_length=MAX_TARGET_LENGTH, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
prepared_dataset = dataset.map(prepare_data, batched=True, remove_columns=[INPUT_COLUMN, TARGET_COLUMN])
dataset_len = len(prepared_dataset) # 38
gen_config.num_return_sequences = 1
metrics = trainer.evaluate(eval_dataset=prepared_dataset, num_beams = 5, generation_config=gen_config)
assert metrics["eval_samples"] == dataset_len
# THESE WILL FAIL -- THE NUMBER OF GENERATED SAMPLES WILL BE 70: 2*16 + 2*16 + 6 (last batch will discard the remaining 6 sequences)
gen_config.num_return_sequences = 2
metrics = trainer.evaluate(eval_dataset=prepared_dataset, num_beams = 5, generation_config=gen_config)
assert metrics["eval_samples"] == 2 * dataset_len # should be 76
# THESE WILL FAIL -- THE NUMBER OF GENERATED SAMPLES WILL BE 102: 3*16 + 3*16 + 6 (last batch will discard the remaining 32 sequences)
gen_config.num_return_sequences = 3
metrics = trainer.evaluate(eval_dataset=prepared_dataset, num_beams = 5, generation_config=gen_config)
assert metrics["eval_samples"] == 3 * dataset_len # should be 114
```
### Expected behavior
I would expect that the compute_metrics function would receive a tensor of shape (samples * num_return_sequences, max_len). Currently it receives a few less because the last batch gets half the sequences dropped in Accelerator.gather_for_metrics. | 08-01-2023 10:11:11 | 08-01-2023 10:11:11 | It looks more like something in `accelerate`, so cc @muellerzr .
But @antonioalegria
> . It drops num_return_sequences - 1 sequences in the last batch
Could you explain a bit more about this number? It doesn't seem corresponding to what you showed in the code snippet ..?<|||||>Apologies for not being clear.
Let's say you are generating from 100 input samples, `num_return_sequences` = 2 and eval batch size is 16.
You will have 6 full batches of 16, each generating 32 sequences, and a final batch of size 4. This final batch comes out of `model.generate` with 8 generated sequences but 4 of them are discarded in `Accelerator.gather_for_metrics`.
If you had `num_return_sequences` = 3, then the final batch would have originally 12 generated sequences, with 8 of them discarded in the end.
So final batch will always have the number of generated sequences equal to the last batch size. |
transformers | 25,230 | closed | [`Detr`] Fix detr BatchNorm replacement issue | # What does this PR do?
Fixes the current failing CI on #25077 / related failing jobs: https://app.circleci.com/pipelines/github/huggingface/transformers/69452/workflows/999f3686-2d9a-4324-bed6-1c858f4d8246/jobs/871127
In #25077 I decided to [add a property method `current_adapter`](https://github.com/younesbelkada/transformers/blob/peft-integration-attempt-2/src/transformers/adapters/peft_mixin.py#L156) to easily switch between adapters. This leads to failing CI because `PreTrainedModel` will inherit from `AdapterMixin` (that will contain that attribute) and `replace_batch_norm` loops over `dir(model)` and calls `getattr(model, attr_str)`, therefore checks for all available attributes including `current_adapter`.
I can also change the property method to an instance method to avoid this issue, but I find it cleaner to do the module replacement in a pure PyTorch manner rather than using `dir(model)` which can cause weird behaviours in the future .
Can confirm slow DETR / DETA integration tests pass with this change
cc @sgugger @amyeroberts | 08-01-2023 09:50:13 | 08-01-2023 09:50:13 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25230). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,229 | closed | Move rescale dtype recasting to match torchvision ToTensor | # What does this PR do?
The dtype casting of the input image when rescaling was moved in #25174 so that precision was kept when rescaling if desired. However, this broke equivalence tests with torchvision's `ToTensor` transform c.f. [this comment](https://github.com/huggingface/transformers/pull/24796#issuecomment-1657275333).
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? | 08-01-2023 09:35:31 | 08-01-2023 09:35:31 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thank you very much, Amy! |
transformers | 25,228 | closed | chatglm2 load_in_8bit=true can't reduce gpu memory when using transformer==4.31.0 | ### System Info
- `transformers` version: 4.31.0
- Platform: Linux-3.10.0-1160.92.1.el7.x86_64-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaForCausalLM, TextIteratorStreamer
import transformers
from peft import PeftModel
import bitsandbytes as bnb
import torch
from threading import Thread, currentThread
import time
model = "/workspace/model-files/chatglm2"
model = AutoModelForCausalLM.from_pretrained(model, device_map='auto', trust_remote_code=True, load_in_8bit=True)
cls = bnb.nn.Linear8bitLt
print(model.get_memory_footprint())
for name, module in model.named_modules():
# print(name)
if isinstance(module, cls):
names = name.split('.')
print(names)
```
Regardless of whether load_in8bit is set or not, the gpu memory usage is always 12487168064
but when use transformer==4.29.2 load_in_8bit=True the gpu memory usage is 6776623168
### Expected behavior
transformers latest version work well | 08-01-2023 09:33:57 | 08-01-2023 09:33:57 | ref:https://github.com/THUDM/ChatGLM2-6B/issues/163<|||||>cc @younesbelkada <|||||>+1<|||||>Thanks, my feeling is that it is related with the issue described in https://github.com/huggingface/transformers/pull/25105
Can you try that version of transformers meanwhile and let me know if this fixes your issue?
```bash
pip install -U git+https://github.com/ranchlai/transformers.git@fix_get_keys_to_not_convert
```<|||||>>
it's work,but i get other problem when i use git+https://github.com/ranchlai/transformers.git@fix_get_keys_to_not_convert , please ref: https://github.com/huggingface/transformers/issues/25197<|||||>Now #250105 is on main, you can install it with:
```bash
pip install -U git+https://github.com/huggingface/transformers.git
```
I will close this issue as this issue is solved with the above PR. Feel free to re-open if you think that's not the case |
transformers | 25,227 | closed | resolving zero3 init when using accelerate config with Trainer | # What does this PR do?
1. Fixes https://github.com/huggingface/accelerate/issues/1801 | 08-01-2023 08:55:52 | 08-01-2023 08:55:52 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,226 | open | Add offline mode for agents | # What does this PR do?
This PR adds a check in the remote tools setup to bypass it when Transformers is in offline mode.
Fixes #25223 | 08-01-2023 08:46:37 | 08-01-2023 08:46:37 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25226). All of your documentation changes will be reflected on that endpoint.<|||||>I'm getting an error:
```
ValueError: image-transformation is not implemented on the Hub.
```
It's coming from ```_setup_default_tools``` called from the ```__init__```.
It's because of the for loop that check ```HUGGINGFACE_DEFAULT_TOOLS_FROM_HUB```.<|||||>Thanks for the check! Could you try again with the updated branch?<|||||>It's working great!
Thank you! |
transformers | 25,225 | closed | [Bis] Adding new tokens while preserving tokenization of adjacent tokens | ### System Info
* `transformers` version: 4.31
* Platform: Linux [...] 5.19.0-50-generic 50-Ubuntu x86_64 GNU/Linux
* Python version: 3.10.12
* Huggingface_hub version: 0.16.4
* PyTorch version (GPU?): 2.0.1+cu118 (True)
* Using GPU in script?: No
* Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
This issue is related to [this HuggingFace post on the official forum](https://discuss.huggingface.co/t/adding-new-tokens-while-preserving-tokenization-of-adjacent-tokens/12604), hence the similar title, and to my knowledge, no answer was given as to whether this is the normal tokenizer behavior. I ran into the same problem as the original poster while trying to tokenize a sentence after adding new tokens: the adjacent tokens of the newly added ones aren't computed with their preceded escape symbol.
```py
>>> import transformers
>>> tok = transformers.RobertaTokenizer.from_pretrained("roberta-base")
>>> lotr_sent = 'Aragorn told Frodo to mind Lothlorien'
>>> tok.convert_ids_to_tokens(tok(lotr_sent)['input_ids'])
['<s>', 'Ar', 'ag', 'orn', 'Ġtold', 'ĠFro', 'do', 'Ġto', 'Ġmind', 'ĠL', 'oth', 'lor', 'ien', '</s>']
>>> tok.add_tokens(['Aragorn', 'Frodo', 'Lothlorien'])
3
>>> tok.convert_ids_to_tokens(tok(lotr_sent)['input_ids'])
['<s>', 'Aragorn', 'told', 'Frodo', 'to', 'Ġmind', 'Lothlorien', '</s>']
```
### Expected behavior
The tokens `told`, `Frodo`, `to` and `Lothlorien` should be preceded with a `Ġ` character if I am not mistaken ; e.g.:
```py
>>> import transformers
>>> tok = transformers.RobertaTokenizer.from_pretrained("roberta-base")
>>> lotr_sent = 'Aragorn told Frodo to mind Lothlorien'
>>> tok.convert_ids_to_tokens(tok(lotr_sent)['input_ids'])
['<s>', 'Ar', 'ag', 'orn', 'Ġtold', 'ĠFro', 'do', 'Ġto', 'Ġmind', 'ĠL', 'oth', 'lor', 'ien', '</s>']
>>> tok.add_tokens(['Aragorn', 'Frodo', 'Lothlorien'])
3
>>> tok.convert_ids_to_tokens(tok(lotr_sent)['input_ids'])
['<s>', 'Aragorn', 'Ġtold', 'ĠFrodo', 'Ġto', 'Ġmind', 'ĠLothlorien', '</s>']
``` | 08-01-2023 08:29:56 | 08-01-2023 08:29:56 | Hey! This has already been answered, and is a duplicate of #14770. Will be fixed by #23909.
|
transformers | 25,224 | open | 🚨🚨🚨 [`SPM`] Finish fix spm models 🚨🚨🚨 | # What does this PR do?
Modifies `Llama` and `T5` other sentencepiece based tokenizer will follow.
Previous behaviour is always possible with ` tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b", legacy = True)`
## The goal of `transformers`'s wrapping around `sentencepiece`
To clarify, we want to:
- be able to choose the behaviour of the special/added tokens. This means handling the `stripping`, encoding and decoding of such tokens
- allow users to easily add new tokens, with `tokenenizer.add_tokens(...)` instead of having to load the protobuf file, modify the vocab, save it and reload the sentencepiece processor.
## The current and past problems with our wrappers
Let's use both T5 and Llama as reference models. Currently, we do not mimic the behaviour of adding words to the actual `sentencepiece` vocabulary. This is an issue for anyone expecting (and rightfully) that adding tokens does not modify the behaviour of the model.
### Adding a word to sentencepiece's vocab
This can be done using: ([source](https://github.com/google/sentencepiece/issues/121#issuecomment-400362011))
```python
>>> # wget https://huggingface.co/huggyllama/llama-7b/resolve/main/tokenizer.model
>>> from sentencepiece import sentencepiece_model_pb2 as model
>>> import sentencepiece as spm
>>> sp_model = model.ModelProto()
>>> sp_model.ParseFromString(open('tokenizer.model', 'rb').read())
>>> token = "your_token"
>>> sp_model.pieces.add(piece=f"{token}",score=0.0,type=model.ModelProto.SentencePiece.USER_DEFINED,)
>>> with open('new.model', 'wb') as f:
... f.write(sp_model.SerializeToString())
```
then load the `sp_model`:
```python
>>> sp_model = spm.SentencePieceProcessor()
>>> sp_model.Load('new.model')
```
Then, try the following :
```python
>>> sp_model.encode("your_tokenHello", out_type=str)
["_", "your_token", "Hello"]
```
### Adding a word to a `PretrainedTokenizer
This can be done using `tokenizer.add_tokens(["your_token"])`. It is a lot simpler indeed.
But the output you will get is:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b", legacy = True, use_fast = False)
>>> tokenizer.add_tokens(["your_token"])
>>> tokenizer.tokenize("your_tokenHello")
["your_token", "_Hello"]
>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b", legacy = False, use_fast = False)
>>> tokenizer.add_tokens(["your_token"])
>>> tokenizer.tokenize("your_tokenHello")
["your_token", "Hello"]
```
This is because we always split the text on the added tokens, and give the text on the left and right to the `sentencepiece` model. But, most sentencepiece models add a prefix space `_` (the `SPIECE_UNDERLINE` character). Thus, when the `transformers` tokenizers splits `"your_tokenHello"`, it encode `your_token` with the `tokenizer.added_tokens_encoder` and thus does not add a prefix space, and then encode `Hello` with the sentencepiece model, which adds a prefix space and thus outputs `_Hello`.
Other missmatches:
```python
# t5-base tokenizer
>>> tokenizer.encode("<extra_id_0>. Hello", add_special_tokens = False)
[32099, 3, 5, 8774] # ['<extra_id_0>', ' ▁', '.', '▁Hello']
# seqio.SentencePieceVocabulary(vocab_path, extra_ids = 300)
>>> processor.encode("<extra_id_0>. Hello")
[32099, 5, 8774] # ['<extra_id_0>', '.', '▁Hello']
```
TLDR; this shows the only way we can actually and properly handle added tokens and sentencepiece. We have to disable automatic prefix addition, and always encode with a token that is part of the vocab at the beginning to properly encode the first token, whether it has a prefix space or not. Yes this is dirty and sad, but the previous fix was removing the extra space, which was cleaner but had a corner cases #25176.
### The same issue happens with fast tokenizers:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b", use_fast = True)
>>> tokenizer.add_tokens(["your_token"])
>>> tokenizer.tokenize("your_tokenHello")
["_your_token", "Hello"]
>>> tokenizer.add_tokens(["your_token_special"], True)
>>> tokenizer.tokenize("your_token_specialHello")
['your_token_special', '▁Hello']
```
### Another issue 😈
So, here, the issue is that before the special token, even if there is no `rstrip` or `lstrip` (both are set to False), we have very strange behaviours:
```python
>>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", use_fast = True)
>>> tokenizer.tokenize("<s>inform<s>")
# prefix space is eaten
['<s>', '▁inform', '<s>']
>>> tokenizer.tokenize("<s>inform <s>")
# prefix space is not eaten for the second <s>
['<s>', '▁inform', '▁', '<s>']
>>> tokenizer.tokenize(" <s>inform <s>")
# prefix space is not eaten for the second <s>
['▁▁', '<s>', '▁inform', '▁', '<s>']
>>> tokenizer.tokenize(" <s>inform <s> ")
# prefix space is not eaten for the first <s>, extra space added (known)
['▁▁', '<s>', '▁inform', '▁', '<s>', '▁▁']
>>> tokenizer.tokenize("inform <s> ")
# prefix space is added to inform
['▁inform', '▁', '<s>', '▁▁']
```
Note that `tokenizer.convert_tokens_to_ids("▁▁") = 259` while `tokenizer.convert_tokens_to_ids("▁") = 29871`
Also if we add a prefix space to special tokens the beginning, we are probably gonna break a lot of things | 08-01-2023 07:29:22 | 08-01-2023 07:29:22 | The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25224). All of your documentation changes will be reflected on that endpoint.<|||||>Will fix the prefixing of special tokens! |
transformers | 25,223 | open | Agent trying to load remote tools when being offline | ### System Info
Transformers 4.31
Python 3.11.4
Windows 10
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code:
```
import os
os.environ['TRANSFORMERS_OFFLINE'] = '1'
from transformers import LocalAgent, AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b-instruct", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b-instruct")
agent = LocalAgent(model=model, tokenizer=tokenizer) # Error here
agent.run("my query");
```
Error:
```
Max retries exceeded with url: /api/spaces?author=huggingface-tools
```
### Expected behavior
To not access the remote tools. | 08-01-2023 07:26:02 | 08-01-2023 07:26:02 | Hi @Romainlg29
Could you provide a complete code snippet instead of definitions like `model = ...`. Thanks in advance!<|||||>> Hi @Romainlg29
>
> Could you provide a complete code snippet instead of definitions like `model = ...`. Thanks in advance!
Hi,
It's the following.
```
import os
os.environ['TRANSFORMERS_OFFLINE'] = '1'
from transformers import LocalAgent, AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b-instruct", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b-instruct")
agent = LocalAgent(model=model, tokenizer=tokenizer) # Error here
agent.run("my query");
```<|||||>cc our agent @sgugger 😆 <|||||>Agents do not work in offline mode since the prompts are fetched online and we have some tools defined on the Hub only.<|||||>If not too much work, probably not to try to connect if `os.environ['TRANSFORMERS_OFFLINE'] = '1'` and raise an error directly with a more specific message?<|||||>> Agents do not work in offline mode since the prompts are fetched online and we have some tools defined on the Hub only.
Can't we have an offline mode for the agent, where we only load our tools through additional_tools and using a custom prompt ?<|||||>@Romainlg29 You can load your tools via `additional_tools`, but the default tools are still loaded. We could add some guards around that in the future to not try to load tools from the Hub in offline mode, but it is not supported now.<|||||>Drafted a PR to add this, could you try the PR linked above? I believe it should work in offline mode as long as you have all the necessary models in the cache, and either pass custom prompts or also have the prompts in the cache. It will ignore remote tools.<|||||>> Drafted a PR to add this, could you try the PR linked above? I believe it should work in offline mode as long as you have all the necessary models in the cache, and either pass custom prompts or also have the prompts in the cache. It will ignore remote tools.
Ok, I'm going on that. |
transformers | 25,222 | closed | config.json file not available | ### System Info
colab
notebook: https://colab.research.google.com/drive/118RTcKAQFIICDsgTcabIF-_XKmOgM-cc?usp=sharing
### Who can help?
@ArthurZucker @youn
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
While running the notebook and Andyrasika/qlora-2-7b-andy i get the following error(Note: adapter_config.json is already there)
```
Andyrasika/qlora-2-7b-andy does not appear to have a file named config.json. Checkout 'https://huggingface.co/Andyrasika/qlora-2-7b-andy/7a0facc5b1f630824ac5b38853dec5e988a5569e' for available files.
```
### Expected behavior
same as above | 08-01-2023 07:10:05 | 08-01-2023 07:10:05 | The error on the shared colab is
```python
OSError: None is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo with `use_auth_token` or
log in with `huggingface-cli login` and pass `use_auth_token=True`.
```
when you call
```python
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
```
As you can see [here](https://huggingface.co/Andyrasika/qlora-2-7b-andy/blob/main/adapter_config.json#L2) the `config.base_model_name_or_path` is not properly set.
If the script was provided in the PEFT library , pinging @younesbelkada to transfer the issue there and update if needed. Otherwise you should make sure the base model path is defined / use a correct path to a checkpoint<|||||>> The error on the shared colab is
>
> ```python
> OSError: None is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
> If this is a private repository, make sure to pass a token having permission to this repo with `use_auth_token` or
> log in with `huggingface-cli login` and pass `use_auth_token=True`.
> ```
>
> when you call
>
> ```python
> model = AutoModelForCausalLM.from_pretrained(
> config.base_model_name_or_path,
> return_dict=True,
> quantization_config=bnb_config,
> device_map="auto",
> trust_remote_code=True,
> )
> ```
>
> As you can see [here](https://huggingface.co/Andyrasika/qlora-2-7b-andy/blob/main/adapter_config.json#L2) the `config.base_model_name_or_path` is not properly set. If the script was provided in the PEFT library , pinging @younesbelkada to transfer the issue there and update if needed. Otherwise you should make sure the base model path is defined / use a correct path to a checkpoint
Thank you for your instant response(i have already authenticated huggingface token initially while loading the libraries). Any advice on how to address the issue in the notebook shared? @ArthurZucker @younesbelkada <|||||>Closing as it is an exact duplicate of #25215.
Feel free to ask your question on the [forum](https://discuss.huggingface.co/), there are no problem on our side, see @younesbelkada's answers. |
transformers | 25,221 | closed | [BUG REPORT] inconsistent inference results between batch of samples and a single sample in BLIP / BLIP2 | ### System Info
- `transformers` version: 4.30.2
- Platform: Linux-5.15.0-1041-azure-x86_64-with-glibc2.31
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: YES (a single A100, 80GB)
- Using distributed or parallel set-up in script?: NO
### Who can help?
@ArthurZucker and @younesbelkada@amyeroberts
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Inconsistent inference results between batch of samples and a single sample in BLIP / BLIP2.
Here is the script. We can change `DEVICE`, `CAPTION_PRETRAIN_MODEL`, and `pixel_values_shape` to test different models on different accelrators.
```python
import transformers
from transformers import AutoModel, AutoProcessor, AutoConfig
import torch
import numpy as np
from typing import Mapping, Sequence
SEED = 42
transformers.enable_full_determinism(SEED)
CAPTION_PRETRAIN_MODELS_NAMES = [
"Salesforce/blip-image-captioning-base",
"Salesforce/blip-image-captioning-large",
"Salesforce/blip2-opt-2.7b",
]
CAPTION_PRETRAIN_MODEL = CAPTION_PRETRAIN_MODELS_NAMES[1]
# NOTE: If you use BLIP2 model, you need to change the `pixel_values_shape` below accordingly.
CACHE_DIR = ".model.cache/"
DEVICE = "cpu"
# DEVICE = "cuda"
# MODEL
config = AutoConfig.from_pretrained(CAPTION_PRETRAIN_MODEL, cache_dir=CACHE_DIR)
caption_architectures = config.architectures
if len(caption_architectures) != 1:
print(f"captioner_architectures: {caption_architectures} has to be of length 1")
caption_architecture = caption_architectures[0]
module = getattr(transformers, caption_architecture)
model = module.from_pretrained(CAPTION_PRETRAIN_MODEL, cache_dir=CACHE_DIR)
processor = AutoProcessor.from_pretrained(CAPTION_PRETRAIN_MODEL, cache_dir=CACHE_DIR)
model.to(DEVICE)
# Data
pixel_values_shape = [1, 3, 384, 384] # shape for BLIP
# pixel_values_shape = [1, 3, 224, 224] # shape for BLIP2
input_ids_shape = [1, 17]
attention_mask_shape = [1, 17]
labels_shape = [1, 17]
single_sample_inputs = {
"pixel_values": torch.ones(pixel_values_shape),
"input_ids": torch.ones(input_ids_shape, dtype=torch.long),
"attention_mask": torch.ones(attention_mask_shape, dtype=torch.long),
"labels": torch.ones(labels_shape, dtype=torch.long),
}
batch_size = 2
batch_sample_inputs = {
"pixel_values": single_sample_inputs["pixel_values"].repeat(batch_size, 1, 1, 1),
"input_ids": single_sample_inputs["input_ids"].repeat(batch_size, 1),
"attention_mask": single_sample_inputs["attention_mask"].repeat(batch_size, 1),
"labels": single_sample_inputs["labels"].repeat(batch_size, 1),
}
for k in single_sample_inputs:
single_sample_inputs[k] = single_sample_inputs[k].to(DEVICE)
for k in batch_sample_inputs:
batch_sample_inputs[k] = batch_sample_inputs[k].to(DEVICE)
with torch.no_grad():
single_sample_outputs = model(**single_sample_inputs)
batch_sample_outputs = model(**batch_sample_inputs)
print(f"Model: {CAPTION_PRETRAIN_MODEL} with {caption_architecture}, using {DEVICE} device")
def recursive_compare_print(outputs_1, outputs_2, tensor_slice=None, key=None, depth=0):
if type(outputs_1) != type(outputs_2):
raise ValueError(f"outputs_1: {type(outputs_1)} vs outputs_2: {type(outputs_2)}")
elif isinstance(outputs_1, torch.Tensor):
if tensor_slice is None:
tensor_slice = slice(None)
if len(outputs_1.shape) == 0:
print(
"\t" * depth
+ f"diff of {key} (shape={outputs_1.shape}): {torch.max(torch.abs(outputs_1 - outputs_2))}"
)
else:
print(
"\t" * depth
+ f"diff of {key} (shape={outputs_1.shape}): {torch.max(torch.abs(outputs_1[tensor_slice] - outputs_2[tensor_slice]))}"
)
elif isinstance(outputs_1, Mapping):
print("\t" * depth + f"Mapping {key} (type {type(outputs_1)}):")
for k in outputs_1:
recursive_compare_print(outputs_1[k], outputs_2[k], tensor_slice=tensor_slice, key=k, depth=depth + 1)
elif isinstance(outputs_1, Sequence):
print("\t" * depth + f"Sequence {key} (type {type(outputs_1)}):")
for output_1, output_2 in zip(outputs_1, outputs_2):
recursive_compare_print(output_1, output_2, tensor_slice=tensor_slice, depth=depth + 1)
else:
print("\t" * depth + f"Unexpected type with {k}: {type(outputs_1)}")
recursive_compare_print(single_sample_outputs, batch_sample_outputs, slice(0, 1))
```
- When `DEVICE=CPU`, the results are ok except for logits having a small difference of 1e-5
```
Model: Salesforce/blip-image-captioning-base with BlipForConditionalGeneration, using cpu device
Mapping: (type <class 'transformers.models.blip.modeling_blip.BlipForConditionalGenerationModelOutput'>)
diff of loss (shape=torch.Size([])): 0.0
diff of decoder_logits (shape=torch.Size([1, 17, 30524])): 1.049041748046875e-05
diff of image_embeds (shape=torch.Size([1, 577, 768])): 0.0
diff of last_hidden_state (shape=torch.Size([1, 577, 768])): 0.0
```
- When `DEVICE="cuda"`, the results are having a large difference.
```
Model: Salesforce/blip-image-captioning-base with BlipForConditionalGeneration, using cuda device
Mapping: (type <class 'transformers.models.blip.modeling_blip.BlipForConditionalGenerationModelOutput'>)
diff of loss (shape=torch.Size([])): 7.62939453125e-06
diff of decoder_logits (shape=torch.Size([1, 17, 30524])): 0.0015845298767089844
diff of image_embeds (shape=torch.Size([1, 577, 768])): 0.19360780715942383
diff of last_hidden_state (shape=torch.Size([1, 577, 768])): 0.19360780715942383
```
### Expected behavior
The result of GPU inference should be at least the same as those of CPU. | 08-01-2023 05:04:24 | 08-01-2023 05:04:24 | cc @younesbelkada , but @xk-huang Could you first try all the suggestions in [Reproducibility](https://pytorch.org/docs/stable/notes/randomness.html) 🙏 Thanks a lot.
Also
```
# `False` is already the default
torch.backends.cuda.matmul.allow_tf32 = False
# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
torch.backends.cudnn.allow_tf32 = False
```<|||||>Thanks for your kind advice! @ydshieh
I have already adopted the reproducibility suggestions in Torch documents by setting `transformers.enable_full_determinism(SEED)`. After I turn off `torch.backends.cudnn.allow_tf32`, the differences are largely reduced. Here is the comparison:
```
Model: Salesforce/blip-image-captioning-base with BlipForConditionalGeneration, using cuda device
Mapping None (type <class 'transformers.models.blip.modeling_blip.BlipForConditionalGenerationModelOutput'>):
diff of loss (shape=torch.Size([])): 1.9073486328125e-06
diff of decoder_logits (shape=torch.Size([1, 17, 30524])): 8.58306884765625e-06
diff of image_embeds (shape=torch.Size([1, 577, 768])): 0.0
diff of last_hidden_state (shape=torch.Size([1, 577, 768])): 0.0
```
I am wondering whether this level of error is acceptable. <|||||>Glad it works 🚀 !
I would say with strong confidence it's very acceptable :-).
(Welcome to the whole numeric world 😅 )
<|||||>Thank you so much for your reply! I'm ready to explore the numeric rabbit hole! |
transformers | 25,220 | open | OASST model is unavailable for Transformer Agent: `'inputs' must have less than 1024 tokens.` | ### System Info
- transformers version: 4.29.0
- huggingface_hub version: 0.16.4
- python version: 3.10.6
- OS: Ubuntu 22.04.2 LTS
* run on Google Colab using [the provided notebook](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj?usp=sharing).
* [my notebook](https://colab.research.google.com/drive/1UBIWVCIXowlUJpp5gwD-Z0hmVlLLCr9I?usp=sharing), copied from the above.
### Who can help?
@sgugger
`OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5`, one of the models listed as available in the official notebook, is unusable due to the length of the tokens. When executing `agent.chat()` or `agent.run()` with the model, the following error raised:
```
ValueError: Error 422: {'error': 'Input validation error: `inputs` must have less than 1024 tokens. Given: 1553', 'error_type': 'validation'}
```
I guess that `max_input_length` of the model is `1024` if it follows the model configuration [here](https://github.com/LAION-AI/Open-Assistant/blob/main/oasst-shared/oasst_shared/model_configs.py#L50). Could you check this error? In addition, I would like to hear if you will update to reduce the length of the default prompt for Agent.
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Below is the code for the first three cells of the official code provided in the notebook.
```
transformers_version = "v4.29.0"
print(f"Setting up everything with transformers version {transformers_version}")
!pip install huggingface_hub>=0.14.1 git+https://github.com/huggingface/transformers@$transformers_version -q diffusers accelerate datasets torch soundfile sentencepiece opencv-python openai
import IPython
import soundfile as sf
def play_audio(audio):
sf.write("speech_converted.wav", audio.numpy(), samplerate=16000)
return IPython.display.Audio("speech_converted.wav")
from huggingface_hub import notebook_login
notebook_login()
```
```
agent_name = "OpenAssistant (HF Token)"
import getpass
if agent_name == "StarCoder (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
print("StarCoder is initialized 💪")
elif agent_name == "OpenAssistant (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
print("OpenAssistant is initialized 💪")
if agent_name == "OpenAI (API Key)":
from transformers.tools import OpenAiAgent
pswd = getpass.getpass('OpenAI API key:')
agent = OpenAiAgent(model="text-davinci-003", api_key=pswd)
print("OpenAI is initialized 💪")
```
```
boat = agent.run("Generate an image of a boat in the water")
boat
```
### Expected behavior
```
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="a boat in the water")
==Result==
<image.png>
```
as like `bigcode/starcoder` or `text-davinci-003`, but I got
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-3-4578d52c5ccf>](https://localhost:8080/#) in <cell line: 1>()
----> 1 boat = agent.run("Generate an image of a boat in the water")
2 boat
1 frames
[/usr/local/lib/python3.10/dist-packages/transformers/tools/agents.py](https://localhost:8080/#) in run(self, task, return_code, remote, **kwargs)
312 """
313 prompt = self.format_prompt(task)
--> 314 result = self.generate_one(prompt, stop=["Task:"])
315 explanation, code = clean_code_for_run(result)
316
[/usr/local/lib/python3.10/dist-packages/transformers/tools/agents.py](https://localhost:8080/#) in generate_one(self, prompt, stop)
486 return self._generate_one(prompt)
487 elif response.status_code != 200:
--> 488 raise ValueError(f"Error {response.status_code}: {response.json()}")
489
490 result = response.json()[0]["generated_text"]
ValueError: Error 422: {'error': 'Input validation error: `inputs` must have less than 1024 tokens. Given: 1553', 'error_type': 'validation'}
``` | 08-01-2023 02:53:41 | 08-01-2023 02:53:41 | Hi there. We temporarily increased the max length for this endpoint when releasing the Agents framework, but it's not back to its normal value. So yes, this one won't work anymore.<|||||>Thank you for the info, @sgugger!
> So yes, this one won't work anymore.
Then other OpenAssisant models may also only work with customizing a prompt. For now, I believe removing that model from the notebook or replacing it with another one would reduce the inconvenience.
May I try to edit the prompt so that other models with less input max length will be available?<|||||>You can definitely try! |
transformers | 25,219 | open | Trainer.model.push_to_hub() should allow private repository flag | ### Feature request
Trainer.model.push_to_hub() should allow a push to a private repository, as opposed to just pushing to a public and having to private it after.
### Motivation
I get frustrated having to private my repositories instead of being able to upload models by default to a private repo programmatically.
### Your contribution
I’m not sure I have the bandwidth at the moment or have the infrastructure know how to contribute this option, but if this is of interest to many people and you guys could use the help I can work on a PR. | 07-31-2023 22:35:36 | 07-31-2023 22:35:36 | Hi @arikanev, thanks for raising this issue.
In `TrainingArguments` you can set [hub_private_repo to `True`](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/trainer#transformers.TrainingArguments.hub_private_repo) to control this. <|||||>Thanks for the heads up! Time saver :) <|||||>Please note, I tried using this in TrainingArguments and it did not work! I set hub_private_repo to True.<|||||>Hi @arikanev, OK thanks for reporting..
So that we can help, could you provide some more details:
* A minimal code snippet to reproduce the issue
* Information about the running environment: run `transformers-cli env` in the terminal and copy-paste the output
* More information about the expected and observed behaviour: when you say it didn't work, what specifically? Did it fail with an error, not create a repo, create a public repo etc? |
transformers | 25,218 | closed | inject automatic end of utterance tokens | This adds a new feature:
For select models add `<end_of_utterance>` token at the end of each utterance.
The user can now easily break up their prompt and not need to worry about messing with tokens.
So for this prompt:
```
[
"User:",
image,
"Describe this image.",
"Assistant: An image of two kittens in grass.",
"User:",
"https://hips.hearstapps.com/hmg-prod/images/dog-puns-1581708208.jpg",
"Describe this image.",
"Assistant:",
],
```
this new code with add_end_of_utterance_token=True will generate:
`full_text='<s>User:<fake_token_around_image><image><fake_token_around_image>Describe this image.<end_of_utterance>Assistant: An image of two kittens in grass.<end_of_utterance>User:<fake_token_around_image><image><fake_token_around_image>Describe this image.<end_of_utterance>Assistant:'
`
| 07-31-2023 22:13:10 | 07-31-2023 22:13:10 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25218). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,217 | open | Scoring translations is unacceptably slow | ### System Info
- `transformers` version: 4.29.0
- Platform: Linux-3.10.0-862.11.6.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.16
- Huggingface_hub version: 0.12.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker and @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Install transformers, pytorch, tqdm
2. Create `forced_decode.py` [^1]
3. Create `repro.sh` [^2]
4. Run `bash repro.sh` and observe extremely slow scoring speeds.
[^1]:
```python
#!/usr/bin/env python3
import itertools
from argparse import ArgumentParser, FileType
from tqdm import tqdm
import torch
from transformers import PrefixConstrainedLogitsProcessor, AutoTokenizer, AutoModelForSeq2SeqLM
def setup_argparse():
parser = ArgumentParser()
parser.add_argument("-t", "--tokenizer", type=str, required=True)
parser.add_argument("-m", "--model", type=str, required=True)
parser.add_argument("-bs", "--batch-size", type=int, default=16)
parser.add_argument("-i", "--input", type=FileType("r"), default="-")
parser.add_argument("-o", "--output", type=FileType("w"), default="-")
parser.add_argument("-d", "--delimiter", type=str, default="\t")
parser.add_argument("--device", type=str, default="cpu")
return parser
def create_processor_fn(ref_tokens_by_segment):
def inner(batch_id, _):
return ref_tokens_by_segment[batch_id]
return inner
def tokenize(src, tgt, tokenizer):
inputs = tokenizer(src, text_target=tgt, padding=True, return_tensors="pt")
return inputs
def forced_decode(inputs, model, num_beams=5):
inputs = inputs.to(model.device)
logit_processor = PrefixConstrainedLogitsProcessor(create_processor_fn(inputs["labels"]), num_beams=num_beams)
output = model.generate(**inputs, num_beams=num_beams, logits_processor=[logit_processor], return_dict_in_generate=True, output_scores=True)
return output.sequences_scores.tolist()
def batch_lines(it, batch_size):
it = iter(it)
item = list(itertools.islice(it, batch_size))
while item:
yield item
item = list(itertools.islice(it, batch_size))
if __name__ == "__main__":
args = setup_argparse().parse_args()
f_tokenizer = AutoTokenizer.from_pretrained(args.tokenizer)
f_model = torch.compile(AutoModelForSeq2SeqLM.from_pretrained(args.model).to(args.device))
with args.input as fin:
inputs = list(batch_lines(map(str.strip, fin), args.batch_size))
inputs_logits = []
for batch in tqdm(inputs):
src, tgt = zip(*[line.split(args.delimiter) for line in batch])
inputs_logits.append(tokenize(src, tgt, f_tokenizer))
with args.output as fout, torch.no_grad():
for input in tqdm(inputs_logits):
scores = forced_decode(input, f_model)
print(*scores, sep="\n", file=fout)
```
[^2]:
```bash
#!/usr/bin/env bash
function get_input {
curl -s https://gist.githubusercontent.com/erip/e37283b8f51d4e2c16996fc8a6a01aa7/raw/f5a3daffb04dad76464188c2a6949649f5cf3f9c/en-de.tsv
}
python forced_decode.py \
-t Helsinki-NLP/opus-mt-en-de -m Helsinki-NLP/opus-mt-en-de \
-i <(get_input) \
--device cuda:0 \
-bs 16
```
### Expected behavior
Scoring should be _very fast_ since the beam doesn't actually need to be searched, but I'm finding speeds on the order of seconds per batch which is far slower than generating. | 07-31-2023 18:34:34 | 07-31-2023 18:34:34 | cc @gante <|||||>Hey @erip 👋
Sadly, I'm out of bandwidth to dive into the performance of very specific generation modes (in this case, beam search with `PrefixConstrainedLogitsProcessor`). If you'd like to explore the issue and pinpoint the cause of the performance issue, I may be able to help, depending on the complexity of the fix.
Meanwhile, I've noticed that you use `torch.compile`. I would advise you not to use it with text generation, as your model observes different shapes at each forward pass call, resulting in potential slowdowns :) <|||||>Cheers, @gante. I'll try removing the compilation to see how far that moves the needle. I'm trying to score ~17m translations which tqdm is reporting will take ~50 days so we'll see what the delta is without `torch.compile`. I'll post updates here as well.
Edit: 96 days w/o `torch.compile` :-)<|||||>@erip have you considered applying 4-bit quantization ([docs](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/quantization#load-a-large-model-in-4bit), reduces the GPU ram requirements to ~1/6 of the original size AND should result in speedups) and then increasing the batch size as much as possible?
You may be able to get it <1 week this way, and the noise introduced by 4 bit quantization is small.<|||||>I guess I'm more concerned that this is going to take a lot of time at all. Fairseq, Marian, and Sockeye can score translations extremely quickly (17m would probably take ~1-2 days on similar hardware). Transformers can translate in that amount of time, so I'm lead to conclude that logits processors are just performance killers.<|||||>@erip some of them are performance killers (e.g. `PrefixConstrainedLogitsProcessor ` seems to need vectorization). Our Pytorch beam search implementation is not optimized either, compared to our TF/FLAX implementation.
We focus on breadth of techniques and models, but welcome optimization contributions 🤗 |
transformers | 25,216 | closed | [`Docs`/`quantization`] Clearer explanation on how things works under the hood. + remove outdated info | # What does this PR do?
As discussed internally with @amyeroberts , this PR makes things clearer to users on how things work under the hood for quantized models. Before this PR it was not clear to users how the other modules (non `torch.nn.Linear`) were treated under the hood when quantizing a model.
cc @amyeroberts | 07-31-2023 17:50:07 | 07-31-2023 17:50:07 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,215 | open | config.json file not available | ### System Info
colab
notebook: https://colab.research.google.com/drive/118RTcKAQFIICDsgTcabIF-_XKmOgM-cc?usp=sharing
### Who can help?
@sgugger @younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
RepositoryNotFoundError: 404 Client Error. (Request ID:
Root=1-64c7ee9d-240cd76b269a914d67b458fa;dcab1901-0ebf-4282-b8a4-9d1e087de5b4)
Repository Not Found for url: https://huggingface.co/None/resolve/main/config.json.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
During handling of the above exception, another exception occurred:
```
### Expected behavior
https://huggingface.co/Andyrasika/qlora-2-7b-andy giving error:
```
Andyrasika/qlora-2-7b-andy does not appear to have a file named config.json. Checkout 'https://huggingface.co/Andyrasika/qlora-2-7b-andy/7a0facc5b1f630824ac5b38853dec5e988a5569e' for available files.
``` | 07-31-2023 17:34:46 | 07-31-2023 17:34:46 | Hi @andysingal
it seems you are trying to load an adapter model. You can load it with
```python
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained("Andyrasika/qlora-2-7b-andy")
```
If you want to load the base model in 4bit:
```python
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained("Andyrasika/qlora-2-7b-andy", load_in_4bit=True)
```
Once https://github.com/huggingface/transformers/pull/25077 will get merged you'll be able to load the model directly with `AutoModelForCausalLM`.<|||||>Thanks for your email. But why am I getting the error message?. I already
have adapter_config. JSON .
On Mon, Jul 31, 2023 at 23:09 Younes Belkada ***@***.***>
wrote:
> Hi @andysingal <https://github.com/andysingal>
> it seems you are trying to load an adapter model. You can load it with
>
> from peft import AutoPeftModelForCausalLM
> model = AutoPeftModelForCausalLM.from_pretrained("Andyrasika/qlora-2-7b-andy")
>
> If you want to load the base model in 4bit:
>
> from peft import AutoPeftModelForCausalLM
> model = AutoPeftModelForCausalLM.from_pretrained("Andyrasika/qlora-2-7b-andy", load_in_4bit=True)
>
> Once #25077 <https://github.com/huggingface/transformers/pull/25077> will
> get merged you'll be able to load the model directly with
> AutoModelForCausalLM.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/25215#issuecomment-1658859481>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AE4LJNPF5H4NF3BC4XKTXL3XS7UUDANCNFSM6AAAAAA26SP5AE>
> .
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
<|||||>Hi @andysingal
It is because `AutoModelForCausalLM` will look if there is any `config.json` file present on that model folder and not `adapter_config.json` which are two different file names<|||||>When you run the model created it gives the same error. Assume I am making
an error in the notebook, but inference does not need to show the error on
your website?
Please advise on how to fix it?
On Mon, Jul 31, 2023 at 23:22 Younes Belkada ***@***.***>
wrote:
> Hi @andysingal <https://github.com/andysingal>
> It is because AutoModelForCausalLM will look if there is any config.json
> file present on that model folder and not adapter_config.json which are
> two different file names
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/huggingface/transformers/issues/25215#issuecomment-1658883214>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AE4LJNK3H374C3UHR2ZABBTXS7WF7ANCNFSM6AAAAAA26SP5AE>
> .
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
<|||||>@younesbelkada Any updates?<|||||>Hi @andysingal
Thanks for the ping, as stated above, in your repository only adapter weights and config are stored. Currently it is not supported to load apapted models directly using `AutoModelForCausalLM.from_pretrained(xxx)`, please refer to this comment https://github.com/huggingface/transformers/issues/25215#issuecomment-1658859481 to effectively load the adapted model using PEFT library.<|||||>>
Thanks @younesbelkada for your instant reply. My question is when i compute Text generation inference on your website it gives that error. **I understand i need to use peft for loading the adpater and config files using peft in my preferred env**
Looking forward to hearing from you @ArthurZucker |
transformers | 25,214 | closed | Fix docker image build failure | # What does this PR do?
We again get not enough disk size error on docker image build CI. I should try to learn some ways to reduce the size and avoid this error, but this PR fixes this situation in a quick way: install torch/tensorflow before running `pip install .[dev]`, so they are only install once, and we have fewer docker layers produced. | 07-31-2023 16:09:53 | 07-31-2023 16:09:53 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,213 | closed | Update tiny model info. and pipeline testing | # What does this PR do?
Just a regular update. | 07-31-2023 15:35:17 | 07-31-2023 15:35:17 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The docs for this PR live [here](https://huggingface.co/docs/transformers/pr_25213). All of your documentation changes will be reflected on that endpoint. |
transformers | 25,212 | closed | MinNewTokensLengthLogitsProcessor | null | 07-31-2023 14:31:01 | 07-31-2023 14:31:01 | |
transformers | 25,211 | closed | Fix `all_model_classes` in `FlaxBloomGenerationTest` | # What does this PR do?
It should be a tuple (which requires the ending `,`) | 07-31-2023 14:20:49 | 07-31-2023 14:20:49 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 25,210 | closed | importlib.metadata.PackageNotFoundError: bitsandbytes | ### System Info
`transformers` version: 4.32.0.dev0
- Platform: Linux-5.4.0-153-generic-x86_64-with-glibc2.27
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel
from transformers import BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
model_name_or_path = "Baichuan-13B-Chat"
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
### Expected behavior
`import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel
from transformers import BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
model_name_or_path = "Baichuan-13B-Chat"
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
`
I reported an error after importing BitsAndBytesConfig from transformer:
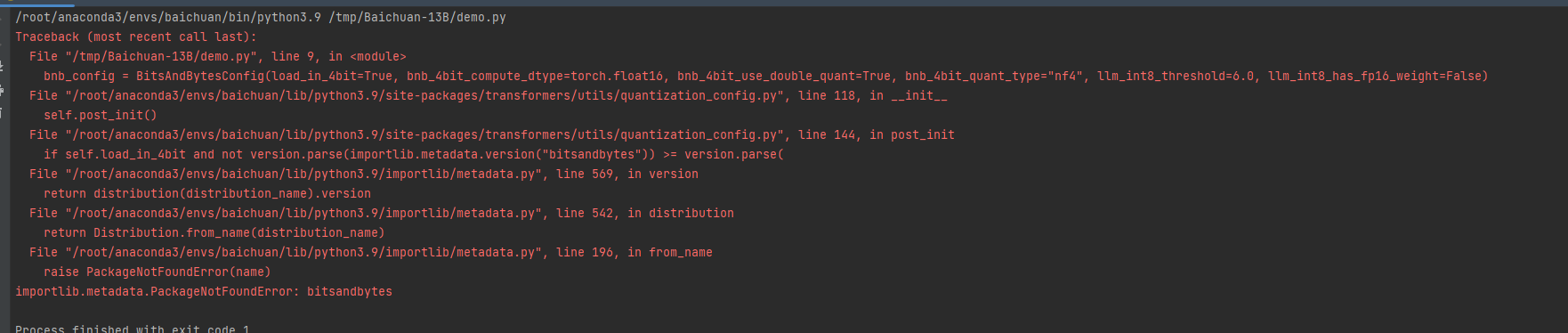
But after I installed bitsandbytes, I still reported an error:

| 07-31-2023 14:20:49 | 07-31-2023 14:20:49 | Hi @looperEit, thanks for reporting this issue!
Could you share the installed version of bitsandbytes and how you installed it?
cc @younesbelkada <|||||>i used the `pip install -r *requriment.txt"`,and the txt file like:

accelerate
colorama~=0.4.6
cpm_kernels
sentencepiece~=0.1.99
streamlit~=1.25.0
transformers_stream_generator
torch~=2.0.1
transformers~=4.31.0<|||||>Hi @looperEit
Can you try to run
```bash
pip install bitsandbytes
```
it looks like this is missing in `requirements.txt` file<|||||>> Hi @looperEit Can you try to run
>
> ```shell
> pip install bitsandbytes
> ```
>
> it looks like this is missing in `requirements.txt` file
when i installed the bitsandbytes, it shows:

may i join it in my `requirements.txt` file?<|||||>@looperEit Yes, you can certainly add it to your own requirements.txt file.
For the error being raised, could you copy paste the full text of the traceback, rather than a screenshot? This makes it easier for us to debug, as we highlight and copy the text, and also makes the issue findable through search for anyone else who's had the issue.
In the screenshot for the error after installing bitsandbytes, could you show the full trackback? The final error message / exception appears to be missing. <|||||>i'm so sorry QAQ ,here is the problem when i installed the bitsandbytes:
`/root/anaconda3/envs/baichuan/bin/python3.9 /tmp/Baichuan-13B/ demo. pyTraceback (most recent call last):
File "/root/anacondaS/envs/baichuan/1io/pythons.9/site-packages/transfonmens/utils/import_utils.py",line 1099,in _get_modulereturn importlib.import_module("." + module_name,self.__name_-)
File "/root/anaconda3/envs/baichuan/lib/python3.9/impontlib/.-init...py",line 127,in impont_ modulereturn _bootstrap. _gcd_import(name[level:], package,level)
File "<frozen importlib._bootstrap>",line 1030,in _gcd_importFile "<frozen importlib._bootstrap>",line 1007,in _find_and_load
File "<frozen importlib._bootstrap>",line 986, in _find_and_load_unlockedFile "<frozen importlib._bootstrap>",line 680, in _load_unlocked
File "<frozen importlib._bootstrap_externals", line 850, in exec_module
File "<frozen importlib._bootstrap>", line 228,in _call_with_frames_removed`
but finally when i installed the `spicy`, i make it. i didn't know why. Maybe the transfomer package and bitsandbytes must coexist with spicy?<|||||>maybe 🤷♀️ although the package manager should have installed any dependencies alongside the library itself. Do you mean `scipy` for the dependency? I've never heard of spicy.
Either way, I'm glad to hear that you were able to resolve the issue :) Managing python environments is a perpetual juggling act. <|||||>> maybe 🤷♀️ although the package manager should have installed any dependencies alongside the library itself. Do you mean `scipy` for the dependency? I've never heard of spicy.
>
> Either way, I'm glad to hear that you were able to resolve the issue :) Managing python environments is a perpetual juggling act.
i'm so sorry,I know where the problem is. The model requirement I use does not include the scipy package. I'm really sorry for wasting your time and disturbing you. Thanks.

|
transformers | 25,209 | closed | Update InstructBLIP & Align values after rescale update | # What does this PR do?
After #25174 the integration tests for Align and InstructBLIP fail.
### InstructBLIP
The difference in the output logits is small. Additionally, when debugging to check the differences and resolve the failing tests, it was noticed that the InstructBLIP tests are not independent. Running
```
RUN_SLOW=1 pytest tests/models/instructblip/test_modeling_instructblip.py::InstructBlipModelIntegrationTest::test_inference_vicuna_7b
```
produces different logits than running:
```
RUN_SLOW=1 pytest tests/models/instructblip/test_modeling_instructblip.py::InstructBlipModelIntegrationTest
```
The size differences between these two runs was similar to the size of differences seen with the update in `rescale`. Hence, I decided that updating the logits was OK.
### Align
The differences in align come from the model's image processor config values. Align uses EfficientNet's image processor. By default, [EfficientNet has `rescale_offset` set to `False`](https://github.com/huggingface/transformers/blob/0fd8d2aa2cc9e172a8af9af8508b2530f55ca14c/src/transformers/models/efficientnet/image_processing_efficientnet.py#L92) and [`rescale_factor` set to `1 / 255`](https://github.com/huggingface/transformers/blob/0fd8d2aa2cc9e172a8af9af8508b2530f55ca14c/src/transformers/models/efficientnet/image_processing_efficientnet.py#L91). Whereas Align has it set to `True` e.g. for [this config](https://huggingface.co/kakaobrain/align-base/blob/e96a37facc7b1f59090ece82293226b817afd6ba/preprocessor_config.json#L25) and the [`rescale_factor` set to `1 / 127.5`](https://huggingface.co/kakaobrain/align-base/blob/e96a37facc7b1f59090ece82293226b817afd6ba/preprocessor_config.json#L24).
In #25174, the `rescale` logic was updated so that if `rescale` is called with `offset=True`, the image values are rescaled between by `scale * 2`. This was because this was I was working from the EfficientNet and ViVit `rescale_factor` values which were both 1/255, so assumed the intention was to have this adjust if `rescale_offset` was True.
There's three options for resolving this:
1. Update Align Config
Update the values in the align checkpoint configs so that `rescale_factor` is `1 / 255` instead of `1 /127.5`.
* ✅ Rescale behaviour and config flags consistent across image processors
* ❌ Remaining unexpected behaviour for anyone who has their own checkpoints of this model.
2. Update rescale and ViVit config
Update the values in the ViVit model config. Revert the rescale behaviour so that `rescale_offset` and `rescale_factor` are independent.
* ✅ Rescale behaviour and config flags consistent across image processors
* ❌ Remaining unexpected behaviour for anyone who has their own checkpoints of this model.
* 🟡 No magic behaviour (adjusting `rescale_factor`) but relies on the user correctly updating two arguments to rescale between `[-1, 1]`
3. Revert EfficientNet's rescale method to previous behaviour.
* ✅ Both models fully backwards compatible with previous rescale behaviour and config values
* ❌ Rescale behaviour and config flags not consistent across image processors
I think option 2 is best. ViVit is a newly added model, it keeps consistent behaviour between Align / EffiicentNet and ViVit and the `rescale` method isn't doesn't anything magic to make the other arguments work. @sgugger @ydshieh I would be good to have your opinion on what you think is best here.
| 07-31-2023 13:08:06 | 07-31-2023 13:08:06 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Agreed with your plan!<|||||>I also prefer 2., but I am a bit confused
> Update rescale and ViVit config
So this only changes `ViVit` config and its `rescale`. And Align uses `EfficientNet` image processor. So when we change something in `ViVitf`, how this fixes the CI failing ... 🤔 ?<|||||>> So this only changes ViVit config and its rescale. And Align uses EfficientNet image processor. So when we change something in ViVitf, how this fixes the CI failing ... 🤔 ?
@ydshieh Sorry, it wasn't super clear. The reason the CI is failing is because:
* Align doesn't have its own image processor - it uses EfficientNet's
* EfficientNet and ViVit both have the option to 'offset' when rescaling i.e. centering the pixel values around 0.
* As both EfficientNet and ViVit's image processors have a rescale_factor of `1/255` by default, their docstrings mention setting `rescale_offset=True` rescales between `[-1, 1]` and they offset before rescaling, I assumed that then intention was to optionally rescale by `2 * rescale_factor` if `rescale_offset=True` for both
* This was true for ViVit.
* Align image processor config value are actually already updated so `rescale_factor` is `2 * (1 / 255) = 1 / 127.5`
* Therefore, the resulting pixel values from Align's image processor weren't in the range `[-1, 1]` when rescale was changed.
Updating something in ViVit doesn't fix the CI directly. I'll also have to update `rescale` for both the methods to use Align's intended logic.
<|||||>@ydshieh I've made the updates for option 2:
* Reverted to the previous `rescale` behaviour for EfficientNet: 7c3b3bb
* Same behaviour is copied across to ViVit, also in 7c3b3bb
* Made PRs to update the rescale values in ViVit models - `rescale_factor` 1/255 -> 1/127.5
- https://huggingface.co/google/vivit-b-16x2/discussions/1#64c92542c96a10fa85bbca0b
- https://huggingface.co/google/vivit-b-16x2-kinetics400/discussions/2#64c9253aaf935d3927ec1409
<|||||>Oh I know why I get confused now
> Update the values in the ViVit model config. Revert the rescale behaviour so that rescale_offset and rescale_factor are independent.
I thought only ViVit would be changed in this PR, but actually you mean both ViVit and `EfficientNet` (but the revert to before #25174).
Thanks for the update!
|
transformers | 25,208 | open | Getting error while implementing Falcon-7B model: AttributeError: module 'signal' has no attribute 'SIGALRM' | ### System Info

### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import AutoTokenizer, pipeline
# Load the tokenizer
model_name = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Create a text generation pipeline
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
# Generate text
input_text = "Hello! How are you?"
output = text_generator(input_text, max_length=100, do_sample=True)
generated_text = output[0]["generated_text"]
# Print the generated text
print(generated_text)
### Expected behavior
It should get the text generated by the model. But it was showing me this error:
"Traceback (most recent call last):
File "C:\DissData\Dissertation-Brunel\Falcon-7b.py", line 8, in <module>
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\pipelines\__init__.py", line 705, in pipeline
config = AutoConfig.from_pretrained(model, _from_pipeline=task, **hub_kwargs, **model_kwargs)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\models\auto\configuration_auto.py", line 986, in from_pretrained
trust_remote_code = resolve_trust_remote_code(
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\dynamic_module_utils.py", line 535, in resolve_trust_remote_code
signal.signal(signal.SIGALRM, _raise_timeout_error)
AttributeError: module 'signal' has no attribute 'SIGALRM'"
Is it possible to resolve this error as soon as possible? | 07-31-2023 12:47:32 | 07-31-2023 12:47:32 | Hey @amitkedia007 ! I'm suspecting you are using Windows? Have you tried [this](https://huggingface.co/tiiuae/falcon-7b-instruct/discussions/57)?
Maybe adding `trust_remote_code = True` to `tokenizer = AutoTokenizer.from_pretrained(model_name)` in order to allow downloading the appropriate tokenizer would work.
Please let me know if this works. Trying to help you fast here :)<|||||>Yes I tried this as well, as you said. But still I am getting the same error:
Traceback (most recent call last):
File "C:\DissData\Dissertation-Brunel\Falcon-7b.py", line 8, in <module>
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\pipelines\__init__.py", line 705, in pipeline
config = AutoConfig.from_pretrained(model, _from_pipeline=task, **hub_kwargs, **model_kwargs)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\models\auto\configuration_auto.py", line 986, in from_pretrained
trust_remote_code = resolve_trust_remote_code(
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\dynamic_module_utils.py", line 535, in resolve_trust_remote_code
signal.signal(signal.SIGALRM, _raise_timeout_error)
AttributeError: module 'signal' has no attribute 'SIGALRM'<|||||>I'm going through the code, and I'm finding dynamic_module_utils.py [verbose trace](https://github.com/huggingface/transformers/blob/main/src/transformers/dynamic_module_utils.py#L556C47-L556C47) at 556 instead of 535 . Have a look at the [function as well](https://github.com/huggingface/transformers/blob/9ca3aa01564bb81e1362288a8fdf5ac6e0e63126/src/transformers/dynamic_module_utils.py#L550)
Which version of the transformers library are you using?<|||||>See #25049, but basically
> "Loading this model requires you to execute execute some code in that repo on your local machine. "
> "Make sure you have read the code at https://hf.co/{model_name} to avoid malicious use, then set "
> "the option `trust_remote_code=True` to remove this error." |
transformers | 25,207 | closed | [`pipeline`] revisit device check for pipeline | # What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/23336#issuecomment-1657792271
Currently `.to` is called to the model in pipeline even if the model is loaded with accelerate - which is a bad practice and can lead to unexpected behaviour if the model is loaded across multiple GPUs or offloaded to CPU/disk.
This PR simply revisits the check for device assignment
Simple snippet to reproduce the issue:
```python
from transformers import AutoModelForCausalLM, AutoConfig, AutoTokenizer, pipeline
import torch
model_path="facebook/opt-350m"
config = AutoConfig.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_8bit=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
params = {
"max_length":1024,
"pad_token_id": 0,
"device_map":"auto",
"load_in_8bit": True,
# "torch_dtype":"auto"
}
pipe = pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer,
device=0,
model_kwargs=params,
)
```
cc @sgugger @Narsil | 07-31-2023 11:32:39 | 07-31-2023 11:32:39 | After thinking about it, maybe this shouldn't be the right fix, it is a bad intent from users to add a `device_map` + `device` argument.
Let me know what do you think<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Yeah let's raise an error! |
transformers | 25,206 | closed | [`PreTrainedModel`] Wrap `cuda` and `to` method correctly | # What does this PR do?
As discussed internally with @sgugger
Use `functools.wrap` to wrap the `to` and `cuda` methods to preserve their original signature, for example the script below:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
print(model.to.__doc__)
```
Now gives:
```bash
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
:noindex:
.. function:: to(dtype, non_blocking=False)
:noindex:
.. function:: to(tensor, non_blocking=False)
:noindex:
.. function:: to(memory_format=torch.channels_last)
:noindex:
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point or complex :attr:`dtype`\ s. In addition, this method will
only cast the floating point or complex parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point or complex dtype of
the parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (:class:`torch.memory_format`): the desired memory
format for 4D parameters and buffers in this module (keyword
only argument)
Returns:
Module: self
Examples::
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_CUDA1)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
>>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)
>>> linear.weight
Parameter containing:
tensor([[ 0.3741+0.j, 0.2382+0.j],
[ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)
>>> linear(torch.ones(3, 2, dtype=torch.cdouble))
tensor([[0.6122+0.j, 0.1150+0.j],
[0.6122+0.j, 0.1150+0.j],
[0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
```
Which should correspond to `torch.nn.Module`'s `to` method.
cc @sgugger
| 07-31-2023 10:51:36 | 07-31-2023 10:51:36 | _The documentation is not available anymore as the PR was closed or merged._ |