
id
int64 37.9M
1.25B
| issue_num
int64 15.7k
97.4k
| title
stringlengths 20
90
| body
stringlengths 59
9.59k
| comments
stringlengths 152
26.7k
| labels
stringlengths 93
311
| comment_count
int64 1
465
| url
stringlengths 56
56
| html_url
stringlengths 46
46
| comments_url
stringlengths 65
65
|
|---|---|---|---|---|---|---|---|---|---|
1,246,842,349 | 97,362 | Tracking Issue for RFC 3216: "Allow using `for<'a>` syntax when declaring closures" | <!--
NOTE: For library features, please use the "Library Tracking Issue" template instead.
Thank you for creating a tracking issue! 📜 Tracking issues are for tracking a
feature from implementation to stabilisation. Make sure to include the relevant
RFC for the feature if it has one. Otherwise provide a short summary of the
feature and link any relevant PRs or issues, and remove any sections that are
not relevant to the feature.
Remember to add team labels to the tracking issue.
For a language team feature, this would e.g., be `T-lang`.
Such a feature should also be labeled with e.g., `F-my_feature`.
This label is used to associate issues (e.g., bugs and design questions) to the feature.
-->
This is a tracking issue for the RFC "Allow using `for<'a>` syntax when declaring closures" (rust-lang/rfcs#3216).
The feature gate for the issue is `#![feature(closure_lifetime_binder)]`.
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also used as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
<!--
Include each step required to complete the feature. Typically this is a PR
implementing a feature, followed by a PR that stabilises the feature. However
for larger features an implementation could be broken up into multiple PRs.
-->
- [X] Implement the RFC - implemented in https://github.com/rust-lang/rust/pull/98705
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
<!--
Include any open questions that need to be answered before the feature can be
stabilised.
-->
None at this time
### Implementation history
* Initial implementation in https://github.com/rust-lang/rust/pull/98705
<!--
Include a list of all the PRs that were involved in implementing the feature.
-->
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":"WaffleLapkin"}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END --> | I'd like to work on implementing this 👀
@rustbot claim<|endoftext|>The implementation section needs to be updated to mention #98705.<|endoftext|>I bumped on this issue and I would like to share some code that maybe someone knowledgeable could comment on whether we are likely to get the features demonstrated or similar (in summary it's getting `for<>` for async closures):
```rust
#![feature(closure_lifetime_binder)]
#![feature(trait_alias)]
use core::future::Ready;
use core::future::ready;
use core::future::Future;
// Don't read too much into the implementation of `S`
struct S<'a>(&'a ());
trait AsyncF<'a, F> = Fn(S<'a>) -> F where F: Future<Output = S<'a>>;
async fn asyncF<F>(f: impl for<'a> AsyncF<'a, F>) {
let a = ();
f(S(&a)).await;
}
fn main() {
// We can't seem to do this because for<> does not seem to extend to the
// argument.
asyncF(for<'a> |x: S<'a>| -> Ready<S<'a>> {ready(x)});
// Ideally we would like this to do anything useful with for<> and async.
// asyncF(for<'a> async move |x: &'a ()| -> &'a () {ready(x)});
}
```
[playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=75475a141e376a2c0711ecac8461d20e)<|endoftext|>@fakedrake I think your `AsyncF`/`asyncF` are wrong. You are using a single `F` type, that is supposed to implement `for<'a> Future<Output = S<'a>>`, where in reality you have a `for<'a> F<'a>: Future<Output = S<'a>>` type.
If you change the `AsyncF` trait to be something like the following:
```rust
trait AsyncF<'a, Input>: Fn(Input) -> Self::Future {
type Future: Future<Output = Self::Out>;
type Out;
}
impl<'a, F, Fut, In> AsyncF<'a, In> for F
where
F: Fn(In) -> Fut,
Fut: Future,
{
type Future = Fut;
type Out = Fut::Output;
}
```
Then your example [works](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=a0db8d120af26cbcab4e20dc309b4adc). Though I want to warn you that such traits are a pain to work with and especially extend.
----
As for `for<'a> async move |x: &'a ()| -> &'a ()` kind of thing, I think it generally desired, but was ruled out of the scope of the RFC. So, if we'll ever add it, it would first need its own RFC.
It appears that async closures are currently in a very rough shape ([eg](https://github.com/rust-lang/rust/blob/b8c0a01b2b651416f5e7461209ff1a93a98619e4/compiler/rustc_ast_lowering/src/expr.rs#L962)) so a good place to start would probably be to fix/complete the implementation of async closures first.<|endoftext|>Thank you very much. I have seen people vaguely complaining about the primitive state of async closures but besides this niche case I have found that they have worked pretty well. Is there an issue tracking the problems with them?<|endoftext|>There is a tracking issue for async closures: #62290<|endoftext|>Found an ICE involving this feature: https://github.com/rust-lang/rust/issues/103736
(Maybe we could use an `F-closure_lifetime_binder` tag?)<|endoftext|>Suggestion: could it be allowed to elide the return type of an explicitly higher-ranked closure when it is `()`? Currently, Rust allows eliding `()` returns in all other function signatures, even when nothing else can be elided.<|endoftext|>@Jules-Bertholet I don't think it's a good idea, we may want to allow inferring return type in the future, just like with normal closures.<|endoftext|>@WaffleLapkin "Infer return type when it is `()`" should be forward-compatible with "infer return type always."<|endoftext|>@Jules-Bertholet oh, I misunderstood this as "make `for<> || { some expression... }` return type always `()`, same as with normal function". Inferring it is probably fine.<|endoftext|>It appears that this will not work well for returning closures as their type can not be explicitly specified as a closure return type. This is likely known but I think worth pointing it out. This will however work for return types that you can specify.
```rust
let f = for<'a> |a: &'a u8| -> impl 'a + Fn() -> &'a u8 {
|| a
};
```
```
error[[E0562]](https://doc.rust-lang.org/nightly/error_codes/E0562.html): `impl Trait` only allowed in function and inherent method return types, not in closure return types
--> src/main.rs:5:36
|
5 | let f = for<'a> |a: &'a u8| -> impl 'a + Fn() -> &'a u8 {
| ^^^^^^^^^^^^^^^^^^^^^^^^
```
[Playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=7aa83bd601924e751507bc7062715256)<|endoftext|>@kevincox: I believe that is a general limitation of what return types you can write when declaring closures, and not related to this RFC. | T-lang<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>T-types<|endoftext|>F-closure_lifetime_binder | 13 | https://api.github.com/repos/rust-lang/rust/issues/97362 | https://github.com/rust-lang/rust/issues/97362 | https://api.github.com/repos/rust-lang/rust/issues/97362/comments |
1,100,848,356 | 92,827 | Tracking Issue for Associated Const Equality | This is a tracking issue for the feature Associated Const Equality brought up in #70256.
The feature gate for the issue is `#![feature(associated_const_equality)]`.
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also used as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
- [ ] Fully implement the feature
- [ ] Teach Chalk about terms (enum Ty or Const relating an associated type or const respectively)
- [ ] Remove all FIXME(associated_const_equality)
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
<!--
Include any open questions that need to be answered before the feature can be
stabilised.
-->
XXX --- list all the "unresolved questions" found in the RFC to ensure they are
not forgotten
### Implementation history
- Originally proposed in #70256 with support but no official RFC, but implementation delayed.
- Initial effort to implement which includes parsing and use of `term` throughout the codebase in #87648, but still lacking a complete implementation.
- More thorough implementation which works for basic cases in #93285. This allowed for consts to actually be bound, more than just parsing them.
| Hello!
Is there a corresponding RFC, or any context whatsoever concerning those changes ?
This is the first occurrence of language syntax change that is not backed by RFC and community feedback
@Centril @oli-obk <|endoftext|>Well, we have https://github.com/rust-lang/rust/issues/70256 which indeed has basically no discussion of the feature. It just seemed like an oversight to have associated types + associated type bounds, but only associated consts without any bounds for them. <|endoftext|>I probably should've tagged the original issue in this at the start (it was in the original PR if I remember correctly) but I'm bad at leaving a thorough paper trail. I'll add a reference to the original issue in the issue itself, and if there's more work that needs to be done please let know<|endoftext|>You did everything correctly. I found the issue because you did link it in the first sentence in this issue 😄
We should probably do a lang team MCP for it along with some medium sized doc explaining what is going on and why. I'll open a hackmd and then we can collab on it<|endoftext|>What's the current state of this? How much is implemented, and how functional is it?<|endoftext|>@joshtriplett I've started work on it, and the syntax/parsing is in place, but the implementation currently does not work. I started working on Chalk, but that has stalled since I wasn't really able to know whether it was necessary for implementing it in rustc. I've also gotten a bit sidetracked working on other things.<|endoftext|>Is it planned to recognize Associated Constant Equality as disjoint cases?
```rs
trait Foo{
const DECIDER: bool;
}
trait Bar{ /*stuff*/ }
impl<T: Foo<DECIDER = true>> Bar for T{ /*stuff*/ }
impl<T: Foo<DECIDER = false>> Bar for T{ /*stuff*/ }
```<|endoftext|>@rustbot label F-associated_const_equality<|endoftext|>@urben1680 I believe this would be the main point of this, but I have not got around to actually implementing it<|endoftext|>```rust
pub struct ConstNum<const N: usize>;
pub trait Is<const N: usize> {}
impl<const N: usize> Is<N> for ConstNum<N> {}
struct Bar<const N: usize>([u8; N]);
fn foo<const N: usize>(_input: Bar<N>) where ConstNum<N>: Is<2> {
}
fn main() {
foo(Bar([0u8; 2])); //works
foo(Bar([0u8; 3])); //doesn't
}
```<|endoftext|>Another use case would be checking tensor shapes. I hit this issue when compiling my code that constrains the shapes of input tensors to have the same dimensionality and/or rank.
For example, dumb code like the below
```rust
pub trait TensorShape1D {
const SHAPE: usize; // i.e. length
}
pub fn add<const L: usize, LEFT_TENSOR: TensorShape1D<SHAPE=L>, RIGHT_TENSOR: TensorShape1D<SHAPE=L>>(left: LEFT_TENSOR, right: RIGHT_TENSOR) {
todo!()
}
```
Any two structs that implement `TensorShape1D` and have the same `SHAPE` can be the input of this function.
Right now, I have to use `typenum` crate and associated type to do the same checking, but it would be great to not have to type-dance like `typenum`. I think when this is implemented, `typenum` can be greatly simplified.<|endoftext|>I am locking this, as it is a tracking issue. Please open a thread on zulip for discussions or open issues for any issues you encounter. | A-associated-items<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>A-const-generics<|endoftext|>S-tracking-needs-summary<|endoftext|>F-associated_const_equality | 12 | https://api.github.com/repos/rust-lang/rust/issues/92827 | https://github.com/rust-lang/rust/issues/92827 | https://api.github.com/repos/rust-lang/rust/issues/92827/comments |
1,081,306,965 | 91,971 | Tracking issue for pref_align_of intrinsic | This intrinsic returns the "preferred" alignment of a type, which can be different from the *minimal* alignment exposed via `mem::align_of`. It is not currently exposed through any wrapper method, but can still be accessed by unstable code using the `intrinsics` or `core_intrinsics` features.
See https://github.com/rust-lang/rust/pull/90877 for why it cannot be removed; the short summary is some code is actually using it. So let's have a place to centralize discussion about the intrinsics. (This is not a regular tracking issue because there is no associated feature gate, but close enough I think.) | Context for labels applied: it sounds like we need a summary of what precisely this means, as distinct from `align_of`, in a way that isn't tied to the LLVM backend. | T-lang<|endoftext|>T-libs-api<|endoftext|>C-tracking-issue<|endoftext|>A-intrinsics<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 1 | https://api.github.com/repos/rust-lang/rust/issues/91971 | https://github.com/rust-lang/rust/issues/91971 | https://api.github.com/repos/rust-lang/rust/issues/91971/comments |
1,014,017,064 | 89,460 | Tracking Issue for `deref_into_dyn_supertrait` compatibility lint | ## What is this lint about
We're planning to add the dyn upcasting coercion language feature (see https://github.com/rust-lang/dyn-upcasting-coercion-initiative). Unfortunately this new coercion rule will take priority over certain other coercion rules, which will mean some behavior change. See #89190 for initial bug report.
## How to fix this warning/error
Ensure your own `Deref` implementation is consistent with the `trait_upcasting` feature brings and `allow` this lint. Or avoid this code pattern altogether.
## Current status
Implementation: #89461 | Could we get a more detailed summary of the case this lint is addressing? dyn upcasting / coercion seems to have made a lot of progress, but this aspect of it doesn't seem to have gotten much discussion that I recall.<|endoftext|>@joshtriplett Sure.
It is known that from user's perspective, coercions has "priorities", and dyn upcasting coercion has a higher priority than user defined `Deref`-based coercions. In the end, this coercion "shadows" a rare certain setup of user `Deref` implementation, which mimicks dyn upcasting coercion manually(see #89190 for an example).
For now we don't want to affect user's code, since dyn upcasting coercion might take a little while before it's stablized. Though, if user provided code decide to do other things in the `Deref`/`DerefMut` implementation, (even rarer, but possible, like running a hook or something), there will be a silent behavior change, when dyn upcasting gets stablized in the future. This lint emits a warning for this matter, to make sure that user doesn't write such code in their `Deref`/`DerefMut` implementations, then the future migration to dyn upcasting coercion will be smooth.
<|endoftext|>I'm curious -- why wasn't this implemented as a lint on the `impl`?<|endoftext|>@compiler-errors It could be implemented that way, and thinking about it from current view, that would be a better way (No removal of the lint is needed with that approach)<|endoftext|>For future reference: the lint change suggested by @compiler-errors was implemented in https://github.com/rust-lang/rust/pull/104742 (I just tried to do that again because I forgor). The lint now lints against `Deref` impls for `dyn Trait` with `type Target = dyn SupertraitOfTrait` (instead of linting against the *use* of such `Deref` impl like it used to). | A-lint<|endoftext|>T-lang<|endoftext|>T-compiler<|endoftext|>C-future-compatibility<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 5 | https://api.github.com/repos/rust-lang/rust/issues/89460 | https://github.com/rust-lang/rust/issues/89460 | https://api.github.com/repos/rust-lang/rust/issues/89460/comments |
927,632,656 | 86,555 | Tracking Issue for RFC 2528: type-changing struct update syntax | This is a tracking issue for RFC 2528 (rust-lang/rfcs#2528), type-changing struct update syntax.
The feature gate for the issue will be `#![feature(type_changing_struct_update)]`.
There is a dedicated Zulip stream: [`#project-type-changing-struct-update`](https://rust-lang.zulipchat.com/#narrow/stream/293397-project-type-changing-struct-update)
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also used as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
- [x] Implementation: https://github.com/rust-lang/rust/issues/86618
- [ ] https://github.com/rust-lang/rust/issues/101970
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
- [ ] Type inference: when implementing this, we need to confirm that it won't adversely affect type inference.
"Further generalization" in the RFC would be the subject of future RFCs, not something we need to track in this tracking issue.
### Implementation history
<!--
Include a list of all the PRs that were involved in implementing the feature.
-->
* Feature gate: https://github.com/rust-lang/rust/pull/89730
* Implementation: https://github.com/rust-lang/rust/pull/90035 | It looks like this has been implemented; are there any further known issues or blockers with it?<|endoftext|>I'm eagerly awaiting stabilisation of this feature! Is there anything that still needs to be done?<|endoftext|>> It looks like this has been implemented; are there any further known issues or blockers with it?
Yes, i created #101970 to track it<|endoftext|>This feature would be useful in bootloader development when different stages of bootloading would handover structures with small modifications. For example, bootstrap module would provide main function like:
```rust
fn main(param: Parameters) -> Handover {
// ....
}
```
where `Handover` share most of fields with `Parameters`, but only small subset of fields are changed in declaration. This will be ideal to express the way Rust ownership works in embedded: one peripheral is wrapped in a structure to show it cannot be initialized or dropped twice. Thus, the wrapper struct should be provided as-is in `Handover`. We can do like this:
```rust
fn main(param: Parameters) -> Handover {
let serial = Serial::new(param.uart0, /* ... */);
// ....
Handover { serial, ..param }
// instead of: Handover { serial, periph_1: param.periph_1, periph_2: param.periph_2, periph_3: param.periph_3, /* ... */ }
}
```
We can now avoid repeat passing peripheral fields in bootload stage handovering, where there would typically be dozens of peripheral fields whose ownerships are going to be transfered.
I'll express my idea in playground link: https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=7fb79bb65cce97cc785b78d9aca1e656
In this way, type changing struct update syntax will have an obvious code size reduction, which will help a lot in embedded development.<|endoftext|>@luojia65 This feature is only for changing the generic arguments of the struct, e.g: going from `Foo<Bar>` to `Foo<Baz>`.
What you want sound like what's [in the Rationales and Alternatives section of the RFC for this feature](https://github.com/rust-lang/rfcs/blob/master/text/2528-type-changing-struct-update-syntax.md#further-generalization), except that it doesn't talk about going between structs with an intersection of fields. | B-RFC-approved<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>F-type-changing-struct-update<|endoftext|>S-tracking-needs-summary | 5 | https://api.github.com/repos/rust-lang/rust/issues/86555 | https://github.com/rust-lang/rust/issues/86555 | https://api.github.com/repos/rust-lang/rust/issues/86555/comments |
849,330,204 | 83,788 | Tracking issue for the unstable "wasm" ABI | This issue is intended to track the stabilization of the `"wasm"` ABI added in https://github.com/rust-lang/rust/pull/83763. This new ABI is notably different from the "C" ABI where the "C" ABI's purpose is to match whatever the C ABI for the platform is (in this case whatever clang does). The "wasm" ABI, however, is intended to match the WebAssembly specification and should be used for functions that need to be exported/imported from a wasm module to precisely match a desired WebAssembly signature.
One of the main features of the "wasm" ABI is that it automatically enables the multi-value feature in LLVM which means that functions can return more than one value. Additionally parameters are never passed indirectly and are always passed by-value when possible to ensure that what was written is what shows up in the ABI on the other end.
It's expected that one day the "C" ABI will be updated within clang to use multi-value, but even if that happens the ABI is likely to optimize for the performance of C itself rather than for binding the WebAssembly platform. The presence of a "wasm" ABI in Rust guarantees that there will always be an ABI to match the exact WebAssembly signature desired.
Another nice effect of stabilizing this ABI is that the `wasm32-unknown-unknown` target's default C ABI can be switched back to matching clang. This longstanding mismatch is due to my own personal mistake with the original definition and the reliance on the mistake in `wasm-bindgen`. Once the "wasm" ABI is stable, however, I can switch `wasm-bindgen` to using the "wasm" ABI everywhere and then the compiler can switch the default ABI of the `wasm32-unknown-unknown` target to match the C ABI of clang. | For folks wanting to give this a try, is there an experimental branch of `wasm-bindgen` that uses this "wasm" ABI?<|endoftext|>There is not a branch at this time, no.<|endoftext|>What is the current state of this? Is there wasm-bindgen support or tooling support for this? Is anything using this?
cc @alexcrichton<|endoftext|>@joshtriplett
> Is anything using this?
Searching sourcegraph and github, I've so far only found one project previously using it then switched to "C" ABI due to a couple of issues <https://github.com/oasisprotocol/oasis-sdk/issues/561>
> * problems with u128 https://github.com/rust-lang/rust/issues/88207
> * problems with compiling multivalue functions https://github.com/ptrus/wasm-bug (todo: should probably open an upstream issue for this)
<|endoftext|>The `wasm-bindgen` crate hasn't updated to using this since it requires nightly Rust and it otherwise wants to compile on stable. I'm otherwise unaware of any other tooling using this myself.<|endoftext|>@alexcrichton Is there a chicken and egg problem there? I think we were waiting to consider stabilization until it was clear this was being used. :)<|endoftext|>Personally I think this is more of a "what is C going to do" problem for stabilization. I don't think Rust is in the position to blaze a trail here when C/C++ otherwise can't access it. One of the main purposes of this ABI is to give access to the ability to define a multi-return function in WebAssembly, but C/C++ have no corresponding mechanism to do that. Until C/C++ figure out how they're going to return multiple values then multi-return is unlikely to be used in the wasm ecosystem so stabilizing this wouldn't provide much benefit. Additionally if this were stabilized and then C/C++ picked a different way to use multi-return then that would be yet-another ABI that Rust would have to implement.<|endoftext|>Rust isn’t C. Rust is Rust and Rust shouldn’t care what C (clang) does for anything not explicitly using the term `C` (`repr(C)` and `extern "C"`).
Rust on wasm’s first priority will always be compatibility with wasm and web standards not with C/C++ on wasm, especially considering wasm doesn’t even have a good way of interoperating betweeen Rust and C that isn’t already mangled through javascript. multiple returns are natively supported by wasm, and Rust should take advantage of this whether clang likes it or not.
perhaps we should maintain `extern "C"` as “C/C++ compatible wasm bindings” but we most definitely should not block the addition of a feature explicitly designed for decoupling Rust on wasm from C because it might not match what C is going to do.
i also see absolutely no reason that Rust shouldn’t be a trailblazer in this field, as it’s at least as favourable as C/C++ in the wasm community.
i don’t think C or C++ even belong in this discussion.<|endoftext|>just wanted to know if this affects https://github.com/rustwasm/team/issues/291 where we can't compile c/cpp binding crates to `wasm32-unknown-unknown` yet. eg: `sdl2-sys` or `zstd-sys` etc..<|endoftext|>Yes - adding the `"wasm"` ABI would allow `wasm-bindgen` to switch to it, and then the `"C"` ABI should be able to be fixed to match `clang` since there wouldn't be anything relying on it. That would fix the ABI-incompatibility issue.
A different way to fix it would be to change `wasm-bindgen` to generate code which works the same no matter whether the current, incorrect `"C"` ABI or the standard one is being used (i.e. explicitly passing structs by pointer). That could be a performance hit, but I doubt it'd be huge.<|endoftext|>@alexcrichton
> Another nice effect of stabilizing this ABI is that the `wasm32-unknown-unknown` target's default C ABI can be switched back to matching clang.
> …and then the compiler can switch the default ABI of the `wasm32-unknown-unknown` target to match the C ABI of clang.
This suggests that maybe there’s a way to use something other than the default C ABI.
Is there a way to opt-in to using a C ABI that isn’t the default but does match clang?
I’m targeting `wasm32-unknown-unknown` but not using `wasm-bindgen` in case that’s relevant.
Please forgive my ignorance on this. I’m in way over my head here 😄<|endoftext|>I'm not aware of any mechanism at this time to use something else to match clang. That's the purpose of the `"C"` ABI so I've at least personally been reluctant to add another name for that.<|endoftext|>is there a place i can track the progress of this clang's C multi-return ABI thing?
also, any idea as to how long it will take? 2024? or even longer?
https://github.com/rust-lang/rust/issues/73755 ?<|endoftext|>Have there been any attempts to form a committee around this? Ideally this would be a W3C subgroup. <|endoftext|>> The "wasm" ABI, however, is intended to match the WebAssembly specification and should be used for functions that need to be exported/imported from a wasm module to precisely match a desired WebAssembly signature.
This is not how `extern "wasm"` is implemented. As it is currently implemented it is effectively `extern "unadjusted"` + integer promotion. `extern "unadjusted"` is perma-unstable as it depends ob the exact LLVM types the backend uses to represent Rust types and the exact rules LLVM uses to legalize non-primitive and non-byref arguments. For example unions like `#[repr(C)] union Foo { a: [u8; 9] }` are currently represented in LLVM ir using `type_padding_filler` whose return value is for example `[9 x i8]` for `Foo` (as this is is an array with the exact same size as the union and using bigger element types will leave a rest) and this is lowered by current LLVM versions as 9 32bit integer arguments for `extern "unadjusted"` and thus `extern "wasm"`. I believe LLVM in case of nested types even recursively picks out primitive fields. The only types that can match the Webassembly specification are primitives. Anything else and you are inventing your own ABI and in this case it is an ABI which depends on implementation details.
```
$ echo '#![feature(wasm_abi)] #[repr(C)] pub union Foo { b: [u8; 9] } #[no_mangle] pub extern "wasm" fn foo(a: Foo) {}' | rustc +nightly --target wasm32-unknown-unknown --crate-type lib --emit asm=/dev/stdout,llvm-ir=/dev/stdout -
[...]
.globl foo
.type foo,@function
foo:
.functype foo (i32, i32, i32, i32, i32, i32, i32, i32, i32) -> ()
end_function
[...]
%Foo = type { [9 x i8] }
; Function Attrs: mustprogress nofree norecurse nosync nounwind readnone willreturn
define dso_local void @foo(%Foo %0) unnamed_addr #0 {
start:
ret void
}
[...]
```
https://github.com/rust-lang/rust/issues/76916 is likely caused by this.<|endoftext|>@alexcrichton I was going down the rabbit hole of why `wasm32-unknown-unknown` is currently incompatible with C and eventually landed here. I didn't fully understand why `extern "wasm"` is blocked on "what is C going to do" about multivalue: https://github.com/rust-lang/rust/issues/83788#issuecomment-1191564068.
> Until C/C++ figure out how they're going to return multiple values then multi-return is unlikely to be used in the wasm ecosystem so stabilizing this wouldn't provide much benefit.
But stabilizing this has a huge benefit even without any multivalue support: be compatible with C!
> Additionally if this were stabilized and then C/C++ picked a different way to use multi-return then that would be yet-another ABI that Rust would have to implement.
So that's the part I'm confused about, I thought the whole point of this new ABI is to separate C and Wasm ABI concerns. `extern "wasm"` will always correspond to the Wasm ABI, the one we are using in `wasm-bindgen`, and `extern "C"` will always follow the C ABI. So whenever C figures out multivalue, we can apply it to the C ABI. Why would that require another ABI?
If the concern is to support both a C ABI with and without multivalue support, then that should probably be gated by `-Ctarget-feature=+multivalue`. In any case, I don't see the conflict with `extern "wasm"` here.<|endoftext|>There is no "Wasm ABI". `extern "wasm"` implements some weird ABI that is decided by the interaction between LLVM (maybe stable?) and the exact way rustc_codegen_llvm uses struct types in arguments (definitively not stable!). `extern "wasm"` only makes sense to me if it is restricted to `i32`, `i64`, `f32,` `f64` and (when enabling the simd feature) `core::arch::wasm::v128` for arguments and those types + (when enabling the multivalue feature) tuples of those types. Anything else is not representable by wasm and as such needs an ABI to decide how to lower it. The only stable ABI for wasm is the C ABI.<|endoftext|>Thanks for the clarification! I went back and read your last comment again too: https://github.com/rust-lang/rust/issues/83788#issuecomment-1477045004.
So does this effectively mean that we can never stabilize `extern "wasm"`? Or are we happy to say that `extern "wasm"` is an unofficial ABI that Rust made to support multivalue and `wasm-bindgen`?
Honestly I'm not too sure how else to proceed on the issue of Wasm and C incompatibility. The other alternative is to just drop all enhancements `wasm-bindgen` did and go back to only following the C ABI.<|endoftext|>In my opinion `extern "wasm"` as currently implemented should not be stabilized. If it is restricted to primitive types representable directly in wasm I did be fine with stabilizing it. I'm not on the language team though, so it is not up to me to decide on stabilizing it or not.
Wasm-bindgen currently attempts to pass `struct WasmSlice { ptr: u32, len: u32 }` as a single argument and expects it to be decomposed into two arguments for `ptr` and `len` respectively at the ABI boundary while the wasm C ABI says that it must be passed by-reference. There is however no guarantee that future LLVM or rustc versions will keep decomposing `WasmSlice` into `ptr` and `len`. Especially for enums and unions the exact way we represent them in LLVM ir has changed over time. This shouldn't normally matter, but because both the current `extern "C"` abi for wasm32-unknown-unknown and the `extern "wasm" abi lack the abi adjustments that normally determine how to pass arguments and return types, the internal representation of types in LLVM ir determines the abi, thus breaking the abi if we change this representation.<|endoftext|>The way to make wasm-bindgen work even if we start using the official C abi for webassembly on wasm32-unknown-unknown would be to either do the decomposition of `WasmSlice` in wasm-bindgen itself or to explicitly pass it by-ref in wasm-bindgen. In either case no struct types would cross the abi and for primitive types the official C abi and the currently used abi agree with each other.<|endoftext|>> There is no "Wasm ABI".
I believe there is: https://github.com/WebAssembly/tool-conventions/blob/main/BasicCABI.md, I'm not sure if it differs from the C ABI, but presumably this is v1 and they planned to add multivalue support to it. In any case, the ABI `wasm-bindgen` currently uses doesn't follow it either. See https://github.com/WebAssembly/tool-conventions/issues/88.
> The way to make wasm-bindgen work even if we start using the official C abi for webassembly on wasm32-unknown-unknown would be to either do the decomposition of `WasmSlice` in wasm-bindgen itself or to explicitly pass it by-ref in wasm-bindgen.
If this really is the whole issue, then I would argue this is fixable. I will proceed to figure out what needs to be done on `wasm-bindgen`s side and hopefully work on it.<|endoftext|>> I believe there is: https://github.com/WebAssembly/tool-conventions/blob/main/BasicCABI.md, I'm not sure if it differs from the C ABI
That is the C abi I was talking about. `extern "wasm"` does not implement that abi however. `extern "C"` on all wasm targets except wasm32-unknown-unknown does.<|endoftext|>So after finding and reading https://github.com/rust-lang/lang-team/blob/master/design-meeting-minutes/2021-04-21-wasm-abi.md, which basically answers and explains all questions I had, I'm coming to the following conclusions:
- The only difference between the Wasm and the C ABI is splatting and mutlivalue support.
- Multivalue isn't even supported right now in Rust (https://github.com/rust-lang/rust/issues/73755) and I don't think it's worth breaking Wasm/C compatibility over it.
- https://github.com/WebAssembly/tool-conventions/blob/main/BasicCABI.md outlines the C ABI we should follow, which in the future might include splatting and multivalue support, but doesn't right now. E.g. https://github.com/WebAssembly/tool-conventions/issues/88.
I think the path forward is to drop splatting in `wasm-bindgen` and fix the C ABI in `wasm32-unknown-unknown` (as bjorn3 was suggesting earlier).<|endoftext|>I don't have much more to add over what's been said already. I would concur that the ideal course of action would be to get `wasm-bindgen` not passing structs-by-value.
As for the `"wasm"` ABI itself, I think the future story heavily depends on what happens with C and how it integrates multi-value. If it's done by "simply" changing the default, then there's no need for `"wasm"`. If it does it by allowing an opt-in, then `"wasm"` makes sense to keep (perhaps renaming of course to match C and also changing the semantics to whatever C requires).
Changing the C ABI or adding a new one is not trivial due to the number of people using it. In that sense by far the easiest thing to do is to update `wasm-bindgen`, delete `"wasm"`, and then wait for C/Clang/upstream to do something. That does, however, place Rust at a bit of a disadvantage where it's no longer attempting to gather feedback on a possible design, it's simply stepping out hoping someone else will fill the gap (but arguably that's the position everyone's already in, waiting for someone else to come fix issues like this)<|endoftext|>> That does, however, place Rust at a bit of a disadvantage where it's no longer attempting to gather feedback on a possible design, [..]
We could leave `"wasm"` in place and add a flag in `wasm-bindgen` that makes use of it, which would require nightly. I guess that's better then nothing.<|endoftext|>I want to point out that the "wasm_abi" feature is currently buggy. An `extern "wasm"` function affects the ABI of *other* functions in the same compilation unit that are *not* tagged as `extern "wasm"`. [Example Godbolt.](https://godbolt.org/z/GGKPMxKeh)
This is because LLVM target-features like +multivalue apply to the whole module, not just a single function: [Godbolt](https://godbolt.org/z/z8zc7Esj1).
I had a [discussion on the LLVM forums](https://discourse.llvm.org/t/is-this-a-bug-multivalue-attribute-contaminates-non-multivalue-functions/72668), and for the time being this seems to be the intended behaviour of target-features.
The tests/run-make/wasm-abi test uses the `extern "wasm"` feature, and mixes it with `extern "C"` as well as the default ABI in all the imported panicking code. This likely makes the test fragile. We should consider disabling it, or at least adding a note to it, in case it randomly breaks for someone else. | A-ffi<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>O-wasm<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>A-abi | 26 | https://api.github.com/repos/rust-lang/rust/issues/83788 | https://github.com/rust-lang/rust/issues/83788 | https://api.github.com/repos/rust-lang/rust/issues/83788/comments |
777,464,477 | 80,619 | Tracking Issue for infallible promotion | <!--
Thank you for creating a tracking issue! 📜 Tracking issues are for tracking a
feature from implementation to stabilisation. Make sure to include the relevant
RFC for the feature if it has one. Otherwise provide a short summary of the
feature and link any relevant PRs or issues, and remove any sections that are
not relevant to the feature.
Remember to add team labels to the tracking issue.
For a language team feature, this would e.g., be `T-lang`.
Such a feature should also be labeled with e.g., `F-my_feature`.
This label is used to associate issues (e.g., bugs and design questions) to the feature.
-->
This is a tracking issue for the RFC "3027" (rust-lang/rfcs#3027).
The RFC does not have a feature gate.
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also used as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
<!--
Include each step required to complete the feature. Typically this is a PR
implementing a feature, followed by a PR that stabilises the feature. However
for larger features an implementation could be broken up into multiple PRs.
-->
- [x] Implement the RFC
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
<!--
Include any open questions that need to be answered before the feature can be
stabilised.
-->
* What should we do about promoting `const fn` calls in `const`/`static` initializers? See [this crater analysis](https://github.com/rust-lang/rust/pull/80243#issuecomment-751885520) and [this Zulip thread](https://rust-lang.zulipchat.com/#narrow/stream/213817-t-lang/topic/Promotion.20of.20const.20fn.20calls.20in.20const.2Fstatic.20initializers/near/221361952).
### Implementation history
* https://github.com/rust-lang/rust/pull/77526
* https://github.com/rust-lang/rust/pull/78363
* https://github.com/rust-lang/rust/pull/80579
| In https://github.com/rust-lang/rust/pull/80243 we learned that there is at least some code (e.g. https://github.com/rodrimati1992/abi_stable_crates/issues/46) that relies in non-trivial ways on `const fn` calls being promoted in a `const`/`static` initializer. We need to figure out how to move forward with such code. I see these options:
* Live with the fact that promoteds in const/static initializers can fail even if they are not required for said initializer. This means no breaking change here, but it will require care in MIR optimizations, MIR printing, maybe more.
* Make sure that all potentally-failing promoteds in const/static initializers are required to compute the value of the const. This will require some break change. There are different alternatives here:
- Never promote anything that might fail -- this breaks some real code (no idea how much, it's only 2 crates in crater), but leads to a rather clean situation.
- Only promote things that fail if they are in parts of the CFG that will definitely be evaluated -- that will however be rather surprising behavior, so maybe we want to do this only for old editions. In particular, a proper post-dominance analysis might be too expensive, so we might just check if the *entire* CFG is linear, or we only promote on the "linear head" of the CFG; in either case, adding a conditional somewhere in the code will stop promotion of things further down that code, which is rather odd.<|endoftext|>> Never promote anything that might fail -- this breaks some real code (no idea how much, it's only 2 crates in crater), but leads to a rather clean situation.
Can that code be made to compile with inline `const` blocks?<|endoftext|>@Aaron1011 yes it can, but only once inline const blocks can use generics of the surrounding context. <|endoftext|>I think this is probably the best option:
> Live with the fact that promoteds in const/static initializers can fail even if they are not required for said initializer. This means no breaking change here, but it will require care in MIR optimizations, MIR printing, maybe more.
https://github.com/rust-lang/rust/pull/85112 ensures that at least a normal build handles this correctly. @oli-obk any idea how to check other MIR consumers such as MIR printing for this?<|endoftext|>MIR printing should just print the path to unevaluated constants and not eval them at all. The only other thing would be optimizations, but these aren't run for constants' bodies<|endoftext|>> MIR printing should just print the path to unevaluated constants and not eval them at all.
As in, it already does that, or it should be changed to do that?<|endoftext|>I believe it does that. At least I specifically remember seeing paths being printed for things that could have been evaluated. <|endoftext|>If we end up deciding we are okay with promoting `const fn` calls in `const`/`static` bodies, we might then also accept other things like general array indexing or division -- we could accept basically everything that qualifies syntactically, i.e., anything that does not depend on surrounding variables. I am not sure what is the better choice -- this makes the rules even more inconsistent, but the rules already *are* wildly inconsistent to the extend that people do get confused by it (e.g., https://github.com/rust-lang/rust/issues/85181).<|endoftext|>What items from RFC 3027 remain to be implemented?
We talked about this in today's @rust-lang/lang meeting, and we know that `const { ... }` still needs further implementation, but we weren't sure if that was a blocker for this or if all the work specified by the RFC was complete.<|endoftext|>@joshtriplett the main open question is what is listed as unresolved question in the issue:
> What should we do about promoting const fn calls in const/static initializers? See [this crater analysis](https://github.com/rust-lang/rust/pull/80243#issuecomment-751885520) and [this Zulip thread](https://rust-lang.zulipchat.com/#narrow/stream/213817-t-lang/topic/Promotion.20of.20const.20fn.20calls.20in.20const.2Fstatic.20initializers/near/221361952).
Basically we still promote arbitrary function calls inside const/static initializers. We need to decide whether we want to
- Live with this technical debt
- Try to slowly phase it out in favor of `const` blocks (once those are stable)
This is a MIR building thing so it could potentially be done at an edition boundary. However, as long as *any* edition promotes arbitrary fn calls, MIR optimizations need to be careful and not overeagerly evaluate constants they find to determine their value. So the technical debt does not become any better by making this an edition thing. I am not sure whether doing this only for the sake of "rules of the latest edition are easier to explain" is worth it.<|endoftext|>Looks like inline_const will be stabilized soon. :D https://github.com/rust-lang/rust/pull/104087
I wonder if that could let us move towards deprecating promotion more?
- Entirely stop promoting function calls in a future edition (only promoting trivial things like `&3`)? Is "easier to explain language" sufficient reason to do that?
- I guess we can't remove this for older editions but maybe we can desugar it to const blocks somewhere early, and thus simplify the promotion machinery? | T-lang<|endoftext|>C-tracking-issue<|endoftext|>A-const-eval<|endoftext|>S-tracking-needs-summary | 11 | https://api.github.com/repos/rust-lang/rust/issues/80619 | https://github.com/rust-lang/rust/issues/80619 | https://api.github.com/repos/rust-lang/rust/issues/80619/comments |
687,493,937 | 76,001 | Tracking Issue for inline const expressions and patterns (RFC 2920) | This is a tracking issue for the RFC "Inline `const` expressions and patterns" (rust-lang/rfcs#2920).
The feature gate for the issue is `#![feature(inline_const)]`.
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also uses as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
<!--
Include each step required to complete the feature. Typically this is a PR
implementing a feature, followed by a PR that stabilises the feature. However
for larger features an implementation could be broken up into multiple PRs.
-->
- [x] Implement the RFC (#77124 does most of it, modulo some bugs around range patterns that should be fixed in #78116)
- [x] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide]) [Unstable Book docs in #78250]
- [ ] Handle inner attributes. https://github.com/rust-lang/rust/pull/94985
- [ ] resolve expr fragment specifier issue (#86730)
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
* Naming: "inline const", "const block", or "anonymous const"?
* Lint about `&const { 4 }` vs `const { &4 }`?
* How should this work for the special has-block syntax rules? <https://rust-lang.zulipchat.com/#narrow/stream/213817-t-lang/topic/const.20blocks.20differ.20from.20normal.20and.20from.20unsafe.20blocks/near/290229453>
### Implementation history
<!--
Include a list of all the PRs that were involved in implementing the feature.
-->
- Primary implementation PR: #77124
- Unstable Book documentation: #78250
- `FnDef` type is disallowed in patterns: #114668
| With regard to the lint, is there any semantic difference between the two? Intuitively I would expect them to behave identically (static lifetimes).<|endoftext|>They behave identically. The point of the lint is to have a single "idiomatic" form.
> Naming: "inline const", "const block", or "anonymous const"?
The issue title calls it "const expressons" so maybe that should also be on the list.
I prefer "inline const" because it emphasizes that this is a totally separate body of code that is just written inline. That's much more like a closure than normal blocks.
---
Also, is anyone up for implementing this? (I can't even mentor this I am afraid, this affects surface-level syntax and MIR building which is way outside what I know.^^)<|endoftext|>"const block" is clearly correct.
it matches "unsafe block" that way.<|endoftext|>That false parallel with "unsafe block" is exactly why it is not correct. An unsafe block inherits scope, execution environment, everything from its parent block. An inline const does not.<|endoftext|>I'm happy to mentor, although by no means am I an expert on all the parts of the compiler you'll need to touch. There's already an `AnonConst` type in the AST and the HIR that should for the most part have the same rules as an inline `const` (e.g. no outside generic parameters), which should make the lowering part of this pretty easy.
If no one volunteers in the next few weeks, I'll try to set aside a day or two to implement this. However, I'm mostly in maintenance/review mode as far as Rust is concerned.<|endoftext|>Does `const { }` differ from normal [block expressions](https://doc.rust-lang.org/reference/expressions/block-expr.html), however?
I think either "inline const" or "const expression" should be favored. Everyone's going to call it a constexpr anyways because of C++ user bleedover, and I don't think it's worth offering that much pushback this time. :^)
Hm... I need to fix my computer still. Guess I have a good reason today.<|endoftext|>> Does const { } differ from normal block expressions, however?
`const {}` does not inherit the same scopes as block expressions do.
> Everyone's going to call it a constexpr anyways because of C++
It can be a useful comparison when introducing C++ users to Rust's `const` and `const fn`, yet I have not seen most users conflate them. Additionally, C++ does not have `constexpr { ... }`.
> I don't think it's worth offering that much pushback this time.
There are no mentions of `constexpr` or C++ on this issue before or the RFC. I find it unproductive to label it as pushback from _that_. The concerns about naming are mentioned in the RFC https://rust-lang.github.io/rfcs/2920-inline-const.html and the comments.<|endoftext|>~~Alas, I was trying to make a rather more casual and conversational remark rather than something that I expected to be picked over with a fine-tooth comb and labeled "unproductive".~~ Resolved.
However, when discussing consts, someone literally referred to a similar expression as a "constexpr", to me, **today**, when they were thinking about trying to write a macro that attempted to implement this feature.<|endoftext|>I was not responding to the idea of using constexpr unproductive, and I mentioned that the comparison to it can still be useful. I specifically referred to describing current naming discussions as "pushback" to be unproductive. I believe we have had a misunderstanding, and I would be open to discussing this more in a direct message on discord. I do not think we should continue this here.<|endoftext|>@ecstatic-morse I'd like to take this issue if it's not taken yet.<|endoftext|>Go for it @spastorino!<|endoftext|>I forgot to link this issue from the PR but the PR is now merged https://github.com/rust-lang/rust/pull/77124<|endoftext|>I would like to write the documentation.<|endoftext|>> I would like to write the documentation.
@camelid please once you have something up cc me so I can review.<|endoftext|>Note that right now the feature is named inline-const pretty much everywhere.<|endoftext|>> * [x] Implement the RFC (#77124 does most of it, modulo some bugs around range patterns that should be fixed in #78116)
As the above checkbox has been checked and both #77124 and #78116 have been merged, I assume this feature is fully implemented. Why is it still [in the `INCOMPLETE_FEATURES` list](https://github.com/rust-lang/rust/blob/5b104fc1bdd5b35891614ad9163ebef31442cc0c/compiler/rustc_feature/src/active.rs#L646)?<|endoftext|>I think that's just an oversight, we should remove it from the incomplete features list.<|endoftext|>> I think that's just an oversight, we should remove it from the incomplete features list.
@oli-obk I'm willing to submit a PR, so I can use this in my code without warning.<|endoftext|>Great! Feel free to `r? @oli-obk` it<|endoftext|>While working on promotion recently, here's something I wondered about... would it make sense for `const {}` to use the promotion machinery? After all, that machinery already has all the support we need to let the const refer to generics of the surrounding context.
The check for the code in there should be the usual const check of course, not the implicit promotion check. But arguably the same is true for explicit promotion contexts, isn't it? `const {}` would be as explicit as it gets for promotion contexts. ;)
The current explicit promotion contexts are `rustc_args_required_const` and inline assembly const operands... do we still have time to take away promotion from both of them and require a const literal or inline const block?<|endoftext|>@RalfJung I am not sure if i understood your question correctly
> would it make sense for `const {}` to use the promotion machinery?
I personally don't know what exactly you are thinking of here. At least from where I am approaching this the way const blocks should deal with the generics of the surrounding context is quite different to promotion. Especially considering potentially failing operations like `const { 64 / mem::size_of::<T>() }` which we probably want to allow but imo should require `feature(const_evaluatable_checked)`. I can't really see that working well with promoteds as it happens during typeck while promotion happens afterwards.
> The current explicit promotion contexts are rustc_args_required_const and inline assembly const operands... do we still have time to take away promotion from both of them and require a const literal or inline const block?
idk, it would sure be nice to do so. Don't know too much about either of those, I am however surprised that inline assembly const operands rely on promotion at all rn :laughing: would have expected them to use an `AnonConst` instead.<|endoftext|>> I personally don't know what exactly you are thinking of here.
Basically, compile `const { expr }` like `expr` during MIR building (except with restrictions for which local variables are in scope), and then use this as a promotion site in `transform/promote_consts.rs`.
`const {}` is primarily a means to replace implicit promotion with something more explicit. Promotion already does everything we want `const {}` to do, except that it is subject to some serious restrictions because it is implicit. So using promotion to implement `const {}` seems like the easiest option.
> Especially considering potentially failing operations like const { 64 / mem::size_of::<T>() } which we probably want to allow but imo should require feature(const_evaluatable_checked).
Uh, that's a big move compared to any prior discussion I am aware of.^^ This might smash all hopes I had of stabilizing this any time soon, which could be quite problematic for getting promotion cleaned up before it is too late.
I expected this would work just like promoteds and associated consts work today. No need to treat these likes const generics. (I know basically nothing about `const_evaluatable_checked`, just that it is somehow related to ensuring that const generic parameters do not fail to evaluate.)
> idk, it would sure be nice to do so. Don't know too much about either of those, I am however surprised that inline assembly const operands rely on promotion at all rn laughing would have expected them to use an AnonConst instead.
If `AnonConst` is the same as inline const expressions, then `asm!` predates that by quite a bit.<|endoftext|>`AnonConst` are used to represent constant expressions, so they are used for array lengths and associated constants.
----
moving this to zulip until I have a more solid understanding of our goals here. https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/inline.20consts<|endoftext|>Independent of the discussion around `const_evaluatable_checked`, another way to phrase my point is: I think it is a bad idea to have both "explicit promotion" and inline consts. The two serve *almost the same purpose*, so having to come up with, maintain, and test two separate sets of rules is a lot of extra work for no gain that I can see.
I think we should aim at unifying the two. This means treating `rustc_args_required_const` arguments (I assume some of the functions decorated with this are already stable?) as inline consts (and potentially, with an edition change, requiring the `const { ... }` keyword if the argument isn't a literal or named const); for `asm!` `const` arguments there's still time to work out the details since this isn't stable yet.<|endoftext|>Replying to @oli-obk's comment [here](https://github.com/rust-lang/rust/issues/72016#issuecomment-753468228)
> For rustc_args_required_const we can't do this because the invocation of the function would need to resolve the call before knowing that the argument is a const.
Name resolution happens before MIR construction, so we could still do it on that level... not sure how well that would work with the current implementaton of inline consts though.
---
Also, besides the point I made above about unifying explicit promotion and inline consts, here's another one: inline consts (with support for using generics) and implicit promotion seem to have a lot in common -- both are expressions that are syntactically "embedded" in their parent context and want to inherit at least some of its information (generics; possibly type inference information as well). So maybe it makes sense to implement them in similar ways?
It is this point together with the above that lead to [my first message on the subject](https://github.com/rust-lang/rust/issues/76001#issuecomment-753353110). The feedback I got helped tease the two points apart. :) I think the first one is much stronger than the second.<|endoftext|>> Name resolution happens before MIR construction, so we could still do it on that level... not sure how well that would work with the current implementaton of inline consts though.
Ah, good point, we could do this as an "expansion" in `AST` -> `HIR` lowering<|endoftext|>> both are expressions that are syntactically "embedded" in their parent context and want to inherit at least some of its information (generics; possibly type inference information as well). So maybe it makes sense to implement them in similar ways?
While not generally possible for anonymous constants, *just* for inline consts, that could be doable, but we'd need some sort of marker on the local that contains the final value of the inline const, so that "promotion" can reliably pick it up and uplift its creating MIR statements to a promoted MIR. Though considering that we had all the relevant information about what expressions are part of it before creating the MIR, picking it apart again later seems odd.
The oppsite way of unifying the systems would be to figure out what code is (implicitly) promotable on the HIR, but we explicitly moved away from such a system due to various problems with it.
An intermediate way could be to give inline consts (and possibly repeat expression lengths) their own wrapper type around `AnonConst`, which does not give them their own `DefId`, but THIR lowering will just create promoteds at MIR creation time instead of putting them into their own MIR body that may end up having cycles with their parent MIR body queries. That would still not unify the creation systems of promotion and inline consts, but it would treat them exactly the same once we are not processing HIR anymore.<|endoftext|>> Ah, good point, we could do this as an "expansion" in AST -> HIR lowering
Ah right, HIR is already name-resolved... so this should not be so bad.
> The oppsite way of unifying the systems would be to figure out what code is (implicitly) promotable on the HIR, but we explicitly moved away from such a system due to various problems with it.
Yeah... I guess on the HIR, `+` might still be a function call using the `Add` trait. So that's probably not a good idea.
So, together with everything else you said, I tend to agree that it makes more sense to immediately build separate MIR bodies. That probably also makes it easier to use the normal const-expr checks here.
The key simplification that we can hopefully achieve, then, is to make `transform/promote_consts.rs` *only* about (implicit) lifetime extension, and nothing else. "Promotion" and "lifetime extension" might mean the same thing again, as they once did. ;)
> That would still not unify the creation systems of promotion and inline consts, but it would treat them exactly the same once we are not processing HIR anymore.
Promoteds are already very similar to regular consts on the MIR, so I don't think this would buy us much.<|endoftext|>> So, together with everything else you said, I tend to agree that it makes more sense to immediately build separate MIR bodies. That probably also makes it easier to use the normal const-expr checks here.
> Promoteds are already very similar to regular consts on the MIR, so I don't think this would buy us much.
These two statements seem at odd to each other (since the first one may mean the "build promoteds at THIR time, but the second one says that doesn't gain us much), so just to be clear, so we are all on the same page: We don't change anything in the current system except that we generate `AnonConst` in HIR lowering for `rustc_args_required_const`, thus giving it its own `DefId` and thus `MIR`.<|endoftext|>Sorry, to be more clear: in the second statement I meant the way they look once promotion is done messing up the MIR. Then promoteds are just an `Operand::Const`, just like regular consts and inline const blocks, right? | B-RFC-approved<|endoftext|>T-lang<|endoftext|>T-compiler<|endoftext|>C-tracking-issue<|endoftext|>A-const-eval<|endoftext|>F-inline_const<|endoftext|>S-tracking-needs-summary | 74 | https://api.github.com/repos/rust-lang/rust/issues/76001 | https://github.com/rust-lang/rust/issues/76001 | https://api.github.com/repos/rust-lang/rust/issues/76001/comments |
674,921,649 | 75,251 | Tracking Issue for const MaybeUninit::as(_mut)_ptr (feature: const_maybe_uninit_as_ptr) | <!--
Thank you for creating a tracking issue! 📜 Tracking issues are for tracking a
feature from implementation to stabilisation. Make sure to include the relevant
RFC for the feature if it has one. Otherwise provide a short summary of the
feature and link any relevant PRs or issues, and remove any sections that are
not relevant to the feature.
Remember to add team labels to the tracking issue.
For a language team feature, this would e.g., be `T-lang`.
Such a feature should also be labeled with e.g., `F-my_feature`.
This label is used to associate issues (e.g., bugs and design questions) to the feature.
-->
This is a tracking issue for const `MaybeUninit::as(_mut)_ptr`.
The feature gate for the issue is `#![feature(const_maybe_uninit_as_ptr)]`.
### About tracking issues
Tracking issues are used to record the overall progress of implementation.
They are also uses as hubs connecting to other relevant issues, e.g., bugs or open design questions.
A tracking issue is however *not* meant for large scale discussion, questions, or bug reports about a feature.
Instead, open a dedicated issue for the specific matter and add the relevant feature gate label.
### Steps
<!--
Include each step required to complete the feature. Typically this is a PR
implementing a feature, followed by a PR that stabilises the feature. However
for larger features an implementation could be broken up into multiple PRs.
-->
- [x] Implement
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
<!--
Include any open questions that need to be answered before the feature can be
stabilised.
-->
### Implementation history
<!--
Include a list of all the PRs that were involved in implementing the feature.
-->
* Added in https://github.com/rust-lang/rust/pull/75250 | There doesn't appear to be any blockers for the non-mut version, unless I'm missing something?<|endoftext|>Visiting for T-compiler backlog bonanza. This seems likely to be ready to stabilize, but since I'm not certain, I'm tagging with "needs summary"
Also, we think the question of whether to stabilize these methods falls under T-libs domain, so tagging with that team label
@rustbot label: +T-libs +S-tracking-needs-summary<|endoftext|>(@m-ou-se pointed out that this is a libs-api team issue, not a libs implementation issue.)<|endoftext|>@rfcbot merge<|endoftext|>Team member @m-ou-se has proposed to merge this. The next step is review by the rest of the tagged team members:
* [x] @Amanieu
* [x] @BurntSushi
* [x] @dtolnay
* [ ] @joshtriplett
* [x] @m-ou-se
* [x] @yaahc
No concerns currently listed.
Once a majority of reviewers approve (and at most 2 approvals are outstanding), this will enter its final comment period. If you spot a major issue that hasn't been raised at any point in this process, please speak up!
See [this document](https://github.com/rust-lang/rfcbot-rs/blob/master/README.md) for info about what commands tagged team members can give me.<|endoftext|>Cc @rust-lang/wg-const-eval but this should be uncontroversial<|endoftext|>No concerns with this.<|endoftext|>I'm marking @yaahc's box because she has stepped down from T-libs-api after the point that this feature got proposed for FCP.<|endoftext|>:bell: **This is now entering its final comment period**, as per the [review above](https://github.com/rust-lang/rust/issues/75251#issuecomment-1256323045). :bell:<|endoftext|>The final comment period, with a disposition to **merge**, as per the [review above](https://github.com/rust-lang/rust/issues/75251#issuecomment-1256323045), is now **complete**.
As the automated representative of the governance process, I would like to thank the author for their work and everyone else who contributed.
This will be merged soon.<|endoftext|>Status: `as_ptr` has been stabilized. `as_mut_ptr` is blocked on #57349 | T-libs-api<|endoftext|>C-tracking-issue<|endoftext|>disposition-merge<|endoftext|>finished-final-comment-period<|endoftext|>S-tracking-needs-summary | 11 | https://api.github.com/repos/rust-lang/rust/issues/75251 | https://github.com/rust-lang/rust/issues/75251 | https://api.github.com/repos/rust-lang/rust/issues/75251/comments |
637,330,037 | 73,255 | Tracking issue for `#![feature(const_precise_live_drops)]` | Feature gate for the more precise version of const-checking in #71824.
(Potential) blockers:
- https://github.com/rust-lang/rust/issues/91009 | Cc @rust-lang/wg-const-eval (which I think never happened for this feature or the PR)<|endoftext|>Is there particular reason why this was moved to be a feature?
It is more or less bug fix to inaccurate drop detection.
So shouldn't it be already stable?
This would make it easier to create builders with generic parameters as we currently cannot mutate `self`<|endoftext|>cc @rust-lang/lang I am nominating this feature for stabilization
citing @ecstatic-morse from the impl PR:
This isn't really a "feature" but a refinement to const-checking, and it's kind of non-obvious what the user opts in to with the feature gate, since drop elaboration is an implementation detail. A relevant precedent is `#![feature(nll)]`, but that was much larger and more fundamental than this change would be.
This is also somewhat relevant to the stabilization of `#![feature(const_if_match)]`. Nothing in this PR is specifically related to branching in constants. For instance, it makes the example below compile as well. However, I expect users will commonly want to move out of `Option::<T>::Some` within a `match`, which won't work without this PR if `T: !Copy`
```rust
const _: Vec<i32> = {
let vec_tuple = (Vec::new(),);
vec_tuple.0
};
```
> To clarify, this PR makes that code compile because previously we were dropping the vec_tuple which had type Option<(Vec<i32>,)>?
This code is functionally no different from the following, which currently works on stable because `x` is moved into the return place unconditionally.
```rust
const X: Option<Vec<i32>> = { let x = Vec::new(); x };
```
Const-checking only considers whole locals for const qualification, but drop elaboration is more precise: It works on projections as well. Because drop elaboration sees that all fields of the tuple have been moved from by the end of the initializer, no `Drop` terminator is left in the MIR, despite the fact that the tuple *itself* is never moved from.<|endoftext|>@oli-obk how do things look like in implementation complexity and the risk of locking us into a scheme that might be hard to maintain or make compatible with other future extensions?<|endoftext|>I believe implementation complexity should not be an issue considering current behavior is bug as compiler incorrectly reports error on drop being executed in const fn.
Such things ought to be fixed in any case. Unless we're fine with compiler incorrectly reporting error as right now?<|endoftext|>> I believe implementation complexity should not be an issue considering current behavior is bug as compiler incorrectly reports error on drop being executed in const fn.
> Such things ought to be fixed in any case. Unless we're fine with compiler incorrectly reporting error as right now?
We may be able to achieve the same result (allowing these kind of `const fn`) with a different scheme. So Ralf's question is absolutely reasonable to ask and I will answer it after reviewing the implementation again in detail so I can give an educated answer.
<|endoftext|>@DoumanAsh due to the [halting problem](https://en.wikipedia.org/wiki/Halting_problem), rustc will *always* report "incorrect errors". It is impossible to predict at compiletime if e.g. `drop` will be executed when a piece of code is being run. Similarly, the borrow checker will always reject some correct programs. That's just a fact of programming languages. Neither of these are a bug.
So there's always a trade-off between analysis complexity and "incorrect errors", but even the best analysis will sometimes show "incorrect errors". My impression after looking at the PR here is that the analysis complexity is totally reasonable (it mostly implicitly reuses the analysis performed by drop elaboration), but this is still a decision we should make explicitly, not implicitly.
More precise drop analysis in `const fn` is a new feature, not a bugfix. (Just like, for example, NLL was a new feature, not a bugfix.)
@oli-obk Thanks. :) As you probably saw, I also [left some questions in the PR that implemented the analysis](https://github.com/rust-lang/rust/pull/71824#pullrequestreview-611608120).<|endoftext|>I did see these comments, just didn't have time to look more deeply yet.
Cross posting from the comments on that PR:
I am guessing the difference between the `needs_drop` analysis, and drop elaboration's use of `MaybeInitializedPlaces` and `MaybeUninitializedPlaces` is the reason that this feature gate exists at all. We could probably rewrite drop elaboration in terms of the `NeedsDrop` qualif, which would (afaict) allow `post_drop_elaboration` to not do any checks except for looking for `Drop` terminators.
Of course such a change would insta-stabilize the feature gate from this PR without any reasonable way to avoid said stabilization. So I'm tempted to stabilize the feature but leave a FIXME on this function to merge its qualif checks into `elaborate_drops`<|endoftext|>> We could probably rewrite drop elaboration in terms of the NeedsDrop qualif, which would (afaict) allow post_drop_elaboration to not do any checks except for looking for Drop terminators.
> Of course such a change would insta-stabilize the feature gate from this PR without any reasonable way to avoid said stabilization.
Even worse, it would change drop elaboration, which is a rather tricky part of the compiler.^^ That should be done with utmost care.<|endoftext|>r? @nikomatsakis <|endoftext|>Dropping the nomination here as it's waiting on Niko; that's tracked in the language team action item list.<|endoftext|>What remains to be done before this can be stabilized?<|endoftext|>Hey y'all. I'll try to summarize exactly what this feature gate does to help inform a decision on stabilization. Oli and Ralf probably already know this information, and can skip the next section.
### Background
Currently, it is forbidden to run custom `Drop` implementations during const-eval. This is because `Drop::drop` is a trait method, and there's no (stable) way to declare that trait methods are const-safe. MIR uses a special terminator (`Drop`) to indicate that something is dropped. When building the MIR initially, a `Drop` terminator is inserted for every variable that has drop glue (`ty.needs_drop()`). Typically, const-checks are run on the newly built MIR. This is to prevent MIR optimizations from eliminating or transforming code that would fail const-checking into code that passes it, which would make compilation success dependent on MIR optimizations. In general, we try very hard to avoid this.
However, some `Drop` terminators that we generate during MIR building will never actually execute. For example,
- A `struct` has a field with a custom `Drop` impl (e.g. `Foo(Box<i32>)`), but that field is always moved out of before the variable goes out of scope.
- An `enum` has a variant with a custom `Drop` impl, but we are in a `match` arm for a different variant without a custom `Drop` impl.
We rely on a separate MIR pass, `elaborate_drops`, to remove these terminators prior to codegen (it also does some extra stuff, like adding dynamic drop flags). This happens pretty early in the optimization pipeline, but it is still an optimization, so it runs after const-checking. As a result, the stable version of const-checking sees some `Drop` terminators that will never actually run, and raises an error.
### Current Implementation
`#![feature(const_precise_live_drops)]` defers the `Drop` terminator const-checks until *after* drop elaboration is run. As I mention above, this is unusual, since it makes compilation success dependent on the result of an optimization. On the other hand,
- Drop elaboration doesn't change very often. Unlike some other optimizations, it is conceptually pretty simple to determine whether a `Drop` terminator is frivolous along a given code path. It depends solely on whether some set of move paths are initialized at that point in the CFG.
- It is always profitable to remove drop terminators from the MIR when we can. This makes it unlikely that we will ever want to "dial back" drop-elaboration.
- Despite being conceptually straightforward, drop elaboration is not free to compute and having two separate implementations of it (one in const-checking and one in the optimization pipeline) is both inefficient and bad for maintainability.
- If there *is* bug in drop elaboration that causes us to wrongly eliminate `Drop`s, wrongly accepting some `const fn`s will be the least of our worries, relatively speaking.
For these reasons, I chose the current implementation strategy. I realize that none of these arguments are dispositive, and I don't think it's unreasonable to gate stabilization of this feature on reimplementing the relevant bits of drop elaboration inside const-checking, although I still think it's overly conservative.
Besides that big question, I think there were also some concerns from `const-eval` members around the use of the `NeedsDrop` qualif and test coverage (e.g. https://github.com/rust-lang/rust/pull/71824#discussion_r594392980). I'll try to answer those so they can provide a recommendation.<|endoftext|>I'm not educated on the details, but it would be super nice to see this stabilized in some form. There are a comparatively large number of new APIs that rely on this. For examples, see issues #76654, #82814, and PR #84087, the last of which is an approved stabilization PR that can't be merged until this is stabilized.
That's why I was checking in on the progress towards stabilization a few days ago. I'm sorry about that, by the way. I know that that sort of message can be annoying, but I wanted to know there if there was anything I could do to help move this along.<|endoftext|>The fact that the main blocker (and why this was feature gated in the first place) is the implementation makes it somewhat unusual (see https://github.com/rust-lang/rust/pull/71824#discussion_r421675954). That makes it more the domain of the compiler-team rather than the lang-team. Niko reviewed #71824 and is assigned to this issue, but I'm hesitant to ping them specifically unless their expertise is required.
So, if you want to see this stabilized I would figure out some process for getting consent from the compiler team. I think they use the MCP process for this exclusively? Oli is a member, so there's at least one potential sponsor. The team might require documenting the drop-elaboration/const-checking dependency in the dev-guide and maybe the module itself, which I'm happy to do if asked. After that, I can write a stabilization report with some examples and we can do lang-team FCP (assuming any lingering concerns from @rust-lang/wg-const-eval have been addressed).
I'm, uh, not great at navigating bureaucratic systems with many veto points, so if you want to drive this forward your help would be greatly appreciated. However, unless we end up reimplementing drop-elaboration in const-checking like I mention above, I don't think much of the remaining work is technical. <|endoftext|>I think your summary post contains most of what we need for a stabilization report (full instructions [here](https://rustc-dev-guide.rust-lang.org/stabilization_guide.html?highlight=stabilization%20report#write-a-stabilization-report)). We can just mark this issue as requiring sign-off from both T-compiler and T-lang and do all of this at once.<|endoftext|># Request for stabilization
I would like to stabilize the `const_precise_live_drops` feature.
## Summary
It enables more code to be accepted in const fn. Caveat: const checking is now dependent on drop elaboration, so changes to drop elaboration can silently change what code is allowed in const fn. Details can be found at https://github.com/rust-lang/rust/issues/73255#issuecomment-889420241
A prominent example that doesn't work right now, but would with this feature is `Option::unwrap`:
```rust
const fn unwrap<T>(opt: Option<T>) -> T {
match opt {
Some(x) => x,
None => panic!(),
}
}
```
rustc believes that `opt` will still get dropped in the panic arm (when const checks are running), because the MIR still contains a `Drop` terminator on that arm.
## Documentation
There is none. This feature solely reorders existing passes.
## Tests
* [Demonstrate field and variants being moved out of](https://github.com/rust-lang/rust/blob/673d0db5e393e9c64897005b470bfeb6d5aec61b/src/test/ui/consts/control-flow/drop-precise.rs) (without the feature const checks think that the original aggregate may still get dropped and thus execute a non-const destructor)
* [check that only unstable const fn can use the feature](https://github.com/rust-lang/rust/blob/673d0db5e393e9c64897005b470bfeb6d5aec61b/src/test/ui/consts/unstable-precise-live-drops-in-libcore.rs), see also [this test](https://github.com/rust-lang/rust/blob/18587b14d1d820d31151d5c0a633621a67149e78/src/test/ui/consts/stable-precise-live-drops-in-libcore.rs)
* [check that previously accepted code still works](https://github.com/rust-lang/rust/blob/673d0db5e393e9c64897005b470bfeb6d5aec61b/src/test/ui/consts/control-flow/drop-pass.rs)
* [interaction with const drop](https://github.com/rust-lang/rust/blob/cdeba02ff71416e014f7130f75166890688be986/src/test/ui/rfc-2632-const-trait-impl/const-drop-fail.rs), and [more of the same](https://github.com/rust-lang/rust/blob/003d8d3f56848b6f3833340e859b089a09aea36a/src/test/ui/rfc-2632-const-trait-impl/const-drop.rs)
* [Show limits of the feature](https://github.com/rust-lang/rust/blob/673d0db5e393e9c64897005b470bfeb6d5aec61b/src/test/ui/consts/control-flow/drop-fail.rs)
@rfcbot fcp merge<|endoftext|>Team member @oli-obk has proposed to merge this. The next step is review by the rest of the tagged team members:
* [x] @Aaron1011
* [x] @cramertj
* [x] @davidtwco
* [x] @eddyb
* [ ] @estebank
* [x] @joshtriplett
* [x] @lcnr
* [x] @matthewjasper
* [ ] @michaelwoerister
* [x] @nagisa
* [ ] @nikomatsakis
* [x] @oli-obk
* [x] @petrochenkov
* [ ] @pnkfelix
* [ ] @scottmcm
* [ ] @wesleywiser
Concerns:
* reference-material (https://github.com/rust-lang/rust/issues/73255#issuecomment-946942927)
Once a majority of reviewers approve (and at most 2 approvals are outstanding), this will enter its final comment period. If you spot a major issue that hasn't been raised at any point in this process, please speak up!
See [this document](https://github.com/rust-lang/rfcbot-rs/blob/master/README.md) for info about what commands tagged team members can give me.<|endoftext|>> because the MIR still contains a Drop terminator on that arm
Specifically, the "early" MIR that most of const checking runs on still has it. After drop elaboration, it is gone, which is why running the 'drop' part of const checking later makes such a difference.<|endoftext|>We run some passes early in the MIR pipeline (e.g. borrowck) which are considered to be an integral part of the language. I not sure if I would consider drop elaboration materially different from these and thus an (optional) optimization today. In that context I don't see an issue with it becoming a mechanism through which some programs are allowed to build.<|endoftext|>> const checking is now dependent on drop elaboration, so changes to drop elaboration can silently change what code is allowed in const fn.
Do we have anything resembling a specification (RFC, reference, etc.) for drop elaboration that could be used to justify why certain `const` code does or does not compile? I'm not familiar with that part of the codebase, so it isn't clear to me whether there are lots of potentially implementation-dependent decision points that would be locked in as part of this stabilization, or whether the implementation is relatively unique and therefore unlikely to change in ways that would affect the code that compiles.
Additionally, it'd be nice to have some sort of specification for what code we expect to compile independent of the implementation, since that'd allow us to justify the resulting compiler errors to users without referring to the implementation details.<|endoftext|>No. Up until now, whether or not a stack-local drop flag could be optimized away for some variable didn't affect program semantics. [RFC 320](https://github.com/rust-lang/rfcs/blob/master/text/0320-nonzeroing-dynamic-drop.md), which introduced the current dynamic drop rules, simply mentions that
> Some compiler analysis may be able to identify dynamic drop obligations that do not actually need to be tracked.
That analysis, which is (part of) what came to be known as "drop elaboration", was implemented alongside the rest of the RFC in #33622. It remains mostly identical today modulo a few tweaks (e.g. #68943, which allowed it to make use of the more precise dataflow analysis around enum variants in #68528). As far as I know, there's no documentation besides the discussion on #33622 and the code itself, mostly in [this file](https://github.com/rust-lang/rust/blob/master/compiler/rustc_mir_dataflow/src/elaborate_drops.rs).
I can write up a description of what the algorithm is currently doing, but I wouldn't call that a "specification" without some form of operational semantics for the MIR. Regarding a specification that's "independent of the implemention": How do we describe a flow-sensitive analysis on the MIR besides describing its implementation? We already have some examples of what works and what doesn't (see [Oli's comment](https://github.com/rust-lang/rust/issues/73255#issuecomment-938086246)). For comparison, the borrow-checker is not defined in the reference using normal Rust syntax but [in terms of the MIR](https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md).<|endoftext|>> No. Up until now, whether or not a stack-local drop flag could be optimized away for some variable didn't affect program semantics.
Doesn't it affect the borrow checker? Locals need to be live when they are dropped, so whether or not it can be optimized away can affect whether or not a function is accepted by the borrow checker or not. That was my understanding, anyway.
(Not sure what exactly you are including in 'program semantics', but even with this feature gate, the dynamic semantics of CTFE are not affected. Both borrow checker and const checking are static analyses, so them being affected by this seems very comparable in impact.)<|endoftext|>True. I've always been unclear about how much work is duplicated between drop elaboration and the borrow checker, since the latter runs first. The NLL RFC talks about things in terms of lifetimes and `#[may_dangle]` instead of initializedness, which makes it hard for me to equate the two. Perhaps Niko or Felix could say more?
<|endoftext|>From what I remember borrowck relies upon the variable liveness annotations (`StorageLive` and `StorageDead` MIR statements) and does not rely on drop elaboration in any way or form. Drop elaboration IIRC works by deriving knowledge from these same annotations as well.<|endoftext|>@rfcbot concern reference-material
I'm raising @cramertj's point to an actual concern. I don't think we need a "formal specification" but I do think we need documentation in the reference. It doesn't have to be enough to implement things independently, but I think that it should be enough that humans can understand it. @ecstatic-morse let's sync up about it a bit.<|endoftext|>Do I understand correctly that all of the drop elaboration details become irrelevant once const evaluator actually starts running `Drop::drop` impls?
After that the difference between "not running this because drop elaboration optimized it out" and "not running this because it's a noop" disappears, and all of these cases "just work" simplifying the specification significantly.
So the state in which the language spec depends on the drop elaboration pass details is more or less temporary?<|endoftext|>No, we still need to check upfront if the destructors (the ones that remain after drop elaboration) actually can be run at const-time. It will always be possible for destructors to do non-const stuff, so we will always need a check like that.<|endoftext|>@RalfJung
>It will always be possible for destructors to do non-const stuff
I don't understand, if the destructor can be optimized away by drop elaboration, then it certainly doesn't do any non-const stuff (because it doesn't do anything).
UPD: Ah, I see, the drop method has a "nominal" constexprness (as opposed to "actual" ability to run it at compile time), which may prevent it from being called from const context, but won't prevent it from being eliminated by drop elaboration.<|endoftext|>Yes, that is correct.
Drop elaboration details will remain relevant because when we consider some type `T` whose destructor is called, we cannot know if it does non-const stuff. So we can accept that destruction in `const fn` if and only if the destructor is optimized away by const elaboration.
You seemed to say that somehow future work on `const Drop` would remove the dependency of const checking on drop elaboration. That is not the case, and I do not understand how you propose we could remove the dependency in that future world. Consider a function like
```rust
const fn something<T>(x: T) {}
```
If we added `T: const Drop` (or whatever the syntax will end up being), this is fine, but as written it is not. So whether the destructor for `x` can be optimized out by drop elaboration remains relevant. | A-destructors<|endoftext|>T-lang<|endoftext|>T-compiler<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>A-const-eval<|endoftext|>S-tracking-needs-summary | 50 | https://api.github.com/repos/rust-lang/rust/issues/73255 | https://github.com/rust-lang/rust/issues/73255 | https://api.github.com/repos/rust-lang/rust/issues/73255/comments |
606,453,799 | 71,520 | Use lld by default on x64 msvc windows | This is a metabug, constraining the unbound scope of #39915.
# What is lld
[A linker that's part of the llvm project](https://lld.llvm.org/index.html), which is desirable for two reasons:
* it's very friendly to cross compilation (hence its emphasis for embedded targets)
* it's very fast (often runs in half the time as Gold -- linking can take several minutes for big projects (rustc, servo, etc.) and linking can be a huge % of the compile with incremental builds, so halving this runtime is a Big Deal.)
Rust currently ships its own copy of lld which it calls rust-lld. This is used by default to link bare-metal targets and wasm.
# Goal
The goal of this metabug is to use rust-lld by default when targeting x64 msvc windows (as opposed to e.g. mingw windows). It's possible this will incidentally get other windows targets working, but I'm constraining scope for the sake of focusing efforts.
This configuration is already in a decent state, with backend support already implemented. It's just a matter of making that configuration stable enough to use by default.
**To test using rust-lld for msvc targets, use `-C linker=lld`**
# Blocking Issues
[lld on windows status page](https://lld.llvm.org/windows_support.html)
* [x] #68647 - linking libtest results in undefined symbols
* [x] #71504 - rust-analyser segfault with lto=thin, linker=lld-link
* [x] #72145 - LLD/COFF does not correctly align TLS section
* [x] https://github.com/rust-lang/rust/issues/81408 - ACCESS_VIOLATION when dereferencing once_cell::Lazy in closure with LTO
* [x] https://github.com/rust-lang/rust/issues/85642 - Windows rust-lld does not support the MSVC manifestdependency .drectve
* [ ] https://github.com/rust-lang/rust/issues/111480 | >(TODO: how is it accessed? -C link-flavor?)
`-C linker=lld` (but `-C linker-flavor=lld` should also work).<|endoftext|>This ought to be a bit more straightforward than using lld with gcc since with MSVC you do conventionally invoke the linker directly, and lld has an [`lld-link.exe` binary](https://lld.llvm.org/windows_support.html) that tries to be a drop-in replacement for `link.exe`. You can also run `lld -flavor link` and pass MSVC-style commandline arguments after that. I would expect that if you set up the environment correctly you ought to be able to simply invoke `lld-link.exe` instead of `link.exe` and have it Just Work.
Note that you still need a Visual C++ install (they have a smaller "Build Tools for Visual Studio" install that doesn't include the IDE) or maybe just a Windows SDK in order to have the system .lib files it wants to link to.<|endoftext|>Yes, as noted in the main comment (which I update to track current status) the infra is already hooked up here for invoking it. It's just a bit buggy, and requires a more thorough investigation of failure-modes and how we can smooth them over, e.g.:
* if you don't have Visual C++ installed *what happens*?
* do we provide lld-link.exe, or do we look for a system one? both? is
* does it work just as well on win 8 and 7? should we restrict efforts to win 10?
* can we directly invoke the lld-link binary on macos/linux when cross-compiling to windows?
* how important are the [missing features on the lld-link status page](https://lld.llvm.org/windows_support.html)? can we recover and fallback to link when encountering them?
Once someone's done a quick audit of basic failure modes, we should do some community outreach asking people to test `-C linker=lld` and report how it affects their build times (clean build, big change incremental, tiny change incremental, etc.).
Definitely looking for someone to champion this effort, since my primary goal was just creating more focused initiatives / clarifying the status confusion in the main lld bug.
<|endoftext|>Ah, apologies, I did read that comment but must have missed that.
> if you don't have Visual C++ installed what happens?
This is a good question but I think the better question is "if you try to use lld-link but don't have Visual C++ installed is it any worse than what happens in the default case without Visual C++ installed?" Currently rustc does try to locate MSVC but will apparently just try its best if it can't find it:
https://github.com/rust-lang/rust/blob/f8d394e5184fe3af761ea1e5ba73f993cfb36dfe/src/librustc_codegen_ssa/back/link.rs#L164
<|endoftext|>> if you don't have Visual C++ installed what happens?
IIRC lld-link errors listing all Windows SDK libraries it cannot find.
> can we directly invoke the lld-link binary on macos/linux when cross-compiling to windows?
You cannot cross-compile to MSVC from other OSes unless you find a way to extract Windows SDK and feed it to the LLD. AFAIK MinGW with `ld.lld` is the only *somewhat* supported way to cross compile for Windows.<|endoftext|>Cross-compiling to Windows is not much different than any other OS these days now that LLVM has good support for generating Windows binaries. You do need all the import libs from MSVC at the very least, and probably a Windows SDK for anything non-trivial, but you can absolutely do it:
https://github.com/ProdriveTechnologies/clang-msvc-sdk
Given that requirement it's probably not worth really worrying about as long as it doesn't error in a way that's any more confusing than trying to cross-compile to Windows without specifying an alternate linker. That fails like this for me on Linux with Rust 1.42.0:
```
luser@eye7:/build/snippet$ cargo build --target=x86_64-pc-windows-msvc
Compiling itoa v0.3.4
Compiling snippet v0.1.4-alpha.0 (/build/snippet)
error: linker `link.exe` not found
|
= note: No such file or directory (os error 2)
note: the msvc targets depend on the msvc linker but `link.exe` was not found
note: please ensure that VS 2013, VS 2015, VS 2017 or VS 2019 was installed with the Visual C++ option
error: aborting due to previous error
error: could not compile `snippet`.
To learn more, run the command again with --verbose.
```
Once #58713 is fixed it is probably worth revisiting that topic since it'll become feasible to write pure-Rust descriptions of Windows import libraries and generate working binaries without having MSVC or a Windows SDK.
<|endoftext|>> do we provide lld-link.exe, or do we look for a system one? both?
If Rust is already shipping an `lld` binary it makes sense to allow using it, but given the myriad ways people build software there will assuredly be a desire to use specific `lld`/`lld-link` binaries. Given that `-C linker` already exists and works and there's a corresponding cargo config setting to set it, and that [the `-C linker-flavor` docs](https://doc.rust-lang.org/rustc/codegen-options/index.html#linker-flavor) say that passing a path to `-C linker` will automatically detect the correct flavor it doesn't sound like there's anything else that would need to be done to make it work for those scenarios.
> does it work just as well on win 8 and 7? should we restrict efforts to win 10?
This definitely bears some investigation but I suspect it's not a terribly big deal in practice. [The LLVM docs about building clang for use in Visual Studio](https://releases.llvm.org/10.0.0/docs/GettingStartedVS.html) say "Any system that can adequately run Visual Studio 2017 is fine". [The Visual Studio 2017 System Requirements documentation](https://docs.microsoft.com/en-us/visualstudio/productinfo/vs2017-system-requirements-vs) says it supports Windows 7 SP1 or newer.
> how important are the missing features on the lld-link status page? can we recover and fallback to link when encountering them?
Given that both Firefox and Chrome use `lld-link` for linking their Windows builds nowadays I'd hazard a guess that any missing features are not incredibly important. If someone were to propose making `lld-link` the *default* linker I would worry more about that, but anyone opting-in to using it and also relying on niche linker features can presumably just...not use it?<|endoftext|>The issue says "To test using rust-lld for msvc targets, use -C linker=lld". Shouldn't it be `-C linker=rust-lld`? At least, that's what i need to put in .cargo/config to make this work ([my experiments](https://github.com/rust-analyzer/rust-analyzer/pull/5813)):
```
[target.x86_64-pc-windows-msvc]
linker = "rust-lld"
```<|endoftext|>~Potential blocker - https://github.com/rust-lang/rust/issues/76398 "Rust + MSVC + LLD = Segfault on attempt to access TLS".
This issue currently prevents bootstrap of rustc on `x86_64-pc-windows-msvc` using LLD as a linker.~
Already mentioned under the "LLD/COFF does not correctly align TLS section" item.<|endoftext|>It looks like all the known issues with lld for this target have been fixed! 🎉
Shall we look into flipping it on by default?<|endoftext|>FWIW, lld-link has problems running on Windows 7. https://bugzilla.mozilla.org/show_bug.cgi?id=1699228<|endoftext|>@glandium Apparently only for some build jobs or maybe for some versions of LLD? I'm using it on Windows 7 without running into that issue.<|endoftext|>Yeah, apparently the problem is not happening with the build from llvm.org.<|endoftext|>@glandium I'm using the build that rustup installs.<|endoftext|>Chromium had the same issue on Windows 7 as Firefox, and their answer was that building requires Windows 10. I don't want to be harsh on people with older hardware, but mainstream support for Windows 7 ended before Rust 1.0 even released, and extended support ended over a year ago... I suspect that LLVM itself will stop supporting Windows 7 within the next year, if their deprecation timeline of Windows XP was any indication.<|endoftext|>The firefox lld-link problems mentioned in the comment above (https://github.com/rust-lang/rust/issues/71520#issuecomment-801484987) sound *extremely* similar to those we've had in rust in https://github.com/rust-lang/rust/issues/81051.
They were [fixed](https://reviews.llvm.org/rG64ab2b6825c5aeae6e4afa7ef0829b89a6828102) in LLVM trunk, but given that firefox (as they mention in the thread) have their own fork of LLVM, it's possible that they didn't adopt the fix (as it happened after LLVM 12 cutoff?)?
I don't have the time to test it right now, but if - as per @AndreKR - things are working currently, then i'm cautiously optimistic that they would keep working in the short-medium term as well.<|endoftext|>> It looks like all the known issues with lld for this target have been fixed!
Well, there is another one last time I tried:
> rust-lld: error: `/manifestdependency:` is not allowed in `.drectve`
Looks like `lld-link` doesn't fully support MSVC linker.<|endoftext|>In the blocking issues section
> #71504 - rust-analyser segfault with lto=thin, linker=lld-link
is checked off as being resolved since the issue went away; however, there is a recent open issue that similarly needs thin-lto and lld to be used together to produce a segfault https://github.com/rust-lang/rust/issues/81408<|endoftext|>@pravic Can you file a bug with a reproduction so that I can link it from the tracking issue?<|endoftext|>@bstrie @pravic I hope you don't mind but I filled a minimal report as I already had something similar laying around.<|endoftext|>#85642 is now resolved in nightly (Rust 1.60.0).<|endoftext|>Visited during T-compiler backlog bonanza.
The work that @lqd is doing for https://github.com/rust-lang/compiler-team/issues/510 are partly blocking this, but I am also not sure whether there are other blocking issues. (It sounds like #81408 may be a blocking issue, for example.)
(Furthermore, we are not certain we even will *want* lld to be the default on x64 msvc windows.)
@rustbot label: S-tracking-needs-summary<|endoftext|>link.exe performance seems to have improved a lot in VS2019 and VS2022. in some unscientific testing, i'm not seeing gains from switching to rust-lld.exe.<|endoftext|>> (Furthermore, we are not certain we even will _want_ lld to be the default on x64 msvc windows.)
What are the arguments against having lld as default on windows? To me just the better cross compilation support and getting rid of the need to manually install the MSVC toolchain just for the linker seem like they make lld the preferred choice.<|endoftext|>> getting rid of the need to manually install the MSVC toolchain
Not only _install_, but also _buy_ because MSVC toolchain isn't free under certain circumstances. Is `link.exe` the only used component from MSVC currently? If this change allows to get rid of MSVC completely so only free Windows SDK is required, it is a _very_ strong reason to move forward IMO.<|endoftext|>MSVC provides more than the linker and Windows SDK. It also provides the C runtime (e.g. startup code), core functions such as memcpy, memcmp, etc as well as the panic handling runtime. Perhaps these all could be replaced but as it stands simply switching out the linker doesn't remove the dependency on MSVC.<|endoftext|>I'm on Windows 10 x64 with:
`rustup 1.25.1 (bb60b1e89 2022-07-12)`
`rustc 1.66.1 (90743e729 2023-01-10)`
`MSVC v143` installed with Visual Studio Installer from Microsoft.
If I open a Rust project and change a simple char in code (eg: a variable value from 1 to 2) it re-builds the project (using watchexec) in 12 seconds.
I installed `llvm` and used this in global cargo config file (`C:/Users/<username>/.cargo/config`)
```
[target.x86_64-pc-windows-msvc]
linker = "lld-link.exe"
```
After a `cargo clean` and an initial re-build (debug mode, 2 minutes, the same as without `lld`) the time is the same (maybe even worse than 1 second).
So no change with or without LLD.
**Can you confirm or am I wrong?**
How to get faster incremental (development) builds?<|endoftext|>It might be better to test this using larger projects like RustPython or even Servo?<|endoftext|>I found a new STATUS_ACCESS_VIOLATION with MSVC+LLD+thinLTO (in both debug and release builds of rend3), haven't tried to narrow the scope down yet. (on both 1.69 stable and 1.71 nightly)
https://github.com/rust-lang/rust/issues/111480 | A-linkage<|endoftext|>metabug<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 29 | https://api.github.com/repos/rust-lang/rust/issues/71520 | https://github.com/rust-lang/rust/issues/71520 | https://api.github.com/repos/rust-lang/rust/issues/71520/comments |
587,887,630 | 70,401 | Tracking Issue for `-Z src-hash-algorithm` | This is the tracking issue for the unstable option `-Z src-hash-algorithm`
### Steps
- [x] Implementation PR #69718
- [ ] Adjust documentation
- [ ] Stabilization PR
### Unresolved Questions
- Should we have a separate option in the target specification to specify the preferred hash algorithm, or continue to use `is_like_msvc`?
- Should continue to have a command line option to override the preferred option? Or is it acceptable to require users to create a custom target specification to override the hash algorithm?
| #73526 has been merged, updating LLVM to 11 and making it possible to support SHA256 as well. I guess for now one still has to give compatibility for older LLVMs though, so one maybe has to place a few cfg's here and there.<|endoftext|>Are there documentation changes needed for this? I'd be happy to help!<|endoftext|>☝️ @eddyb <|endoftext|>@pierwill It is currently documented as an unstable option here: https://doc.rust-lang.org/beta/unstable-book/compiler-flags/src-hash-algorithm.html
I think the next step here would be to make a stabilization PR and adjust the documentation move it to the stable list of codegen options.<|endoftext|>Visited during T-compiler [backlog bonanza](https://rust-lang.zulipchat.com/#narrow/stream/238009-t-compiler.2Fmeetings/topic/.5Bsteering.20meeting.5D.202022-09-09.20compiler-team.23484.20backlog.20b'za/near/297985391)
It sounds like this is either ready to stabilize as is (with a shift from a `-Z` option to something stable), or it should move into something that is specified as part of of the target specification, and we just aren't even sure which of those modes we want this in for the stable form.
Can we maybe get a summary of the current implementation status, as well as the tradeoffs between those two options, to inform that decision?
@rustbot label: S-tracking-needs-summary | A-debuginfo<|endoftext|>T-compiler<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>A-cli | 5 | https://api.github.com/repos/rust-lang/rust/issues/70401 | https://github.com/rust-lang/rust/issues/70401 | https://api.github.com/repos/rust-lang/rust/issues/70401/comments |
574,486,204 | 69,664 | Tracking Issue for the `avr-interrupt`/`avr-non-blocking-interrupt` calling convention/ABI | <!--
Thank you for creating a tracking issue! 📜 Tracking issues are for tracking a
feature from implementation to stabilisation. Make sure to include the relevant
RFC for the feature if it has one. Otherwise provide a short summary of the
feature and link any relevant PRs or issues, and remove any sections that are
not relevant to the feature.
Remember to add team labels to the tracking issue.
For a language team feature, this would e.g., be `T-lang`.
Such a feature should also be labeled with e.g., `F-my_feature`.
This label is used to associate issues (e.g., bugs and design questions) to the feature.
-->
This is a tracking issue for the RFC "XXX" (rust-lang/rfcs#NNN).
The feature gate for the issue is `#![feature(FFF)]`.
### Steps
- [x] Implement the RFC
- [ ] Adjust documentation ([see instructions on rustc-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-guide][stabilization-guide])
[stabilization-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#documentation-prs
### Unresolved Questions
None yet.
### Implementation history
* #69478 introduces AVR as a tier-3 target upstream
| Raised to appease `tidy` in #69478.<|endoftext|>In https://github.com/rust-lang/rust/issues/40180 we mentioned wanting a (single) RFC for target-specific interrupt calling conventions, and that work is in progress in https://github.com/rust-lang/rfcs/pull/3246; you may want to coordinate with that work in progress. | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>WG-embedded<|endoftext|>O-AVR<|endoftext|>S-tracking-needs-summary | 2 | https://api.github.com/repos/rust-lang/rust/issues/69664 | https://github.com/rust-lang/rust/issues/69664 | https://api.github.com/repos/rust-lang/rust/issues/69664/comments |
551,594,354 | 68,318 | Tracking issue for negative impls | Generalized negative impls were introduced in https://github.com/rust-lang/rust/pull/68004. They were split out from "opt-in builtin traits" (https://github.com/rust-lang/rust/issues/13231).
## Work in progress
This issue was added in advance of #68004 landed so that I could reference it from within the code. It will be closed if we opt not to go this direction. A writeup of the general feature is available in [this hackmd](https://hackmd.io/2FYm23s0R-igRnTLaFoo8w), but it will need to be turned into a proper RFC before this can truly advance.
## Current plans
* [ ] Forbid conditional negative impls or negative impls for traits with more than one type parameter (https://github.com/rust-lang/rust/issues/79098)
* [ ] Forbid `!Drop` (negative impls of `Drop`)
## Unresolved questions to be addressed through design process
* What should the WF requirements be? ([Context](https://github.com/rust-lang/rust/pull/68004#discussion_r367586615))
* Should we permit combining default + negative impls like `default impl !Trait for Type { }`? ([Context](https://github.com/rust-lang/rust/pull/68004#discussion_r367588811)) | Odd possibly off topic question about this. The following compiles:
```
#![feature(negative_impls)]
pub struct Test{
}
impl !Drop for Test {}
fn foo(){
drop(Test{})
}
```
Should it? <|endoftext|>> Odd possibly off topic question about this. The following compiles:
>
> ```
> #![feature(negative_impls)]
>
> pub struct Test{
>
> }
>
> impl !Drop for Test {}
>
> fn foo(){
> drop(Test{})
> }
> ```
>
> Should it?
I would say no, because if you wanted to shift the error to runtime you could implement Drop as:
```
pub struct Test{
}
impl Drop for Test {
fn drop() {
panic!("Do not drop Test.")
}
}
```
I generally like to catch anything at compile time that can be caught at compile time.<|endoftext|>[According to the documentation](https://doc.rust-lang.org/nightly/std/mem/fn.drop.html)
> This function is not magic; it is literally defined as
> ```rust
> pub fn drop<T>(_x: T) { }
> ```
As a trait bound, `T: Drop` means that the type has defined a custom `Drop::drop` method, nothing more (see the warn-by-default `drop_bounds` lint). It does not mean that `T` has non-trivial drop glue (e.g. `String: Drop` does not hold). Conversely, `T: !Drop` only says that writing `impl Drop for T { … }` in the future is a breaking change, it does not imply anything about `T`'s drop glue and definitely does not mean that values of type `T` cannot be dropped (plenty of people have tried to design such a feature for Rust with no success so far).
(If you did not already know, **drop glue** is the term for all the code that `std::mem::drop(…)` expands to, recursively gathering all `Drop::drop` methods of the type, its fields, the fields of those fields, and so on.)
Yes, the `Drop` trait is *very* counter-intuitive. I suggest extending `drop_bounds` to cover `!Drop` as well. Maybe even mentioning `!Drop` *at all* should be a hard error for now (neither `impl`s nor bounds make sense IMO). Can @nikomatsakis or anyone else add this concern to the unresolved questions section in the description?<|endoftext|>Not sure if this is the right place to report a bug with the current nightly implementation, but a negative implementation and its converse seem to "cancel each other out".
For example:
```rust
trait A {}
trait B {}
// logically equivalent negative impls
impl<T: A> !B for T {}
impl<T: B> !A for T {}
// this should not be possible, but compiles:
impl A for () {}
impl B for () {}
```
The above compiles without errors on nightly, though it shouldn't. Removing one of the negative impls fixes the issue and results in an error as expected.<|endoftext|>Allowing negative trait bounds would make my code much better by allowing to express [di-](https://en.wikipedia.org/wiki/Dichotomy) and [poly-chotomy](https://en.wikipedia.org/wiki/Polychotomy).
In Rust 1.57.0 the following doesn't compile:
```rust
#![feature(negative_impls)]
trait IntSubset {}
impl <T> IntSubset for T where T: FixedSizeIntSubset + !ArbitrarySizeIntSubset {}
impl <T> IntSubset for T where T: !FixedSizeIntSubset + ArbitrarySizeIntSubset {}
trait FixedSizeIntSubset {}
impl<T: FixedSizeIntSubset> !ArbitrarySizeIntSubset for T {}
trait ArbitrarySizeIntSubset {}
impl<T: ArbitrarySizeIntSubset> !FixedSizeIntSubset for T {}
```<|endoftext|>Coming here from a compiler error, how do I "use marker types" to indicate a struct is not Send on stable Rust? I don't see any "PhantomUnsend" or similar anywhere in std.
> error[E0658]: negative trait bounds are not yet fully implemented; use marker types for now<|endoftext|>@mwerezak I think I've seen `PhantomData<*mut ()>`. If I understand correctly, `*mut ()` is not `Send`, so neither is the enclosing `PhantomData` nor your struct. (Did not test)
`PhantomUnsend` might be a good alias/newtype for better readability – I had no idea what `PhantomData<*mut ()>` meant at first :D<|endoftext|>@rMazeiks Thanks, I wouldn't have known really what type would be the appropriate choice to use with `PhantomData` for this.
A `PhantomUnsend` sounds like a good idea.<|endoftext|>I think we should just rule out `!Drop` -- drop is a very special trait.<|endoftext|>Can we add "negative super traits" to the unwritten RFC? That is,
```rust
pub trait Foo {}
pub trait Bar: !Foo {}
// We now know that the two traits are exclusive, thus can write:
trait X {}
impl<T: Foo> X for T {}
impl<T: Bar> X for T {}
```
Quote from the Hackmd:
> This implies you cannot add a negative impl for types defined in upstream crates and so forth.
Negative super traits should get around this: the above snippet should work even if `Foo` is imported from another crate.
The potential issue here is that adding implementations to any trait exported by a library is technically a breaking change (though I believe it is already in some circumstances due to method resolution, and also is with any other aspect of negative trait bounds).<|endoftext|>I would prefer to leave that for future work, @dhardy -- I'd rather not open the door on negative where clauses just now, but also I think that it'd be interesting to discuss the best way to model mutually exclusive traits (e.g., maybe we want something that looks more like enums).<|endoftext|>Should manually implementing `!Copy` be allowed (~~#70849~~ #101836)? I assume it should.<|endoftext|>@fmease when is `Copy` ever implemented automatically?<|endoftext|>@Alxandr Never, I know. This is just a corner case lacking practical relevance I think. I am just asking here to be able to decide whether the issue I linked is a diagnostics problem only or if the compiler is actually too strict / lax. There should be no harm in implementing `!Copy` as a signal to library users.
Edit: There might even be some benefit in doing that with *negative coherence* enabled.<|endoftext|>> I think we should just rule out `!Drop` -- drop is a very special trait.
I found a use case for this while working on [async-local](https://crates.io/crates/async-local); for types that don't impl Drop, the thread_local macro won't register destructor functions, and the lifetime of these types can be extended by using Condvar making it possible to hold references to thread locals owned by runtime worker threads in an async context or on any runtime managed thread so long as worker threads rendezvous while destroying thread local data. For types that do impl Drop, they will immediately deallocate regardless of whether the owning thread blocks and so synchronized shutdowns cannot mitigate the possibility of pointers being invalidated, making the safety of this dependent on types not implementing Drop. <|endoftext|>Conditional negative impls seem to be broken?
```rust
#![feature(auto_traits, negative_impls)]
unsafe auto trait Unmanaged {}
unsafe trait Trace {}
struct GcPtr(*const ());
unsafe impl Trace for GcPtr {}
// It seems like rustc ignores the `T: Trace` bound.
impl<T: Trace> !Unmanaged for T {}
fn check<T: Unmanaged>(_: T) {}
fn main() {
let a = (0, 0);
// error: the trait bound `({integer}, {integer}): Unmanaged` is not satisfied
check(a);
}
```<|endoftext|>> Conditional negative impls seem to be broken?
As far as I can tell this has never had defined semantics. See https://github.com/rust-lang/rust/issues/79098 also.
| A-traits<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>F-negative_impls<|endoftext|>S-tracking-impl-incomplete<|endoftext|>S-tracking-needs-summary | 17 | https://api.github.com/repos/rust-lang/rust/issues/68318 | https://github.com/rust-lang/rust/issues/68318 | https://api.github.com/repos/rust-lang/rust/issues/68318/comments |
493,756,545 | 64,490 | Tracking issue for RFC 2582, `&raw [mut | const] $place` (raw_ref_op) | This is a tracking issue for the RFC "an operator to take a raw reference" (rust-lang/rfcs#2582), feature(raw_ref_op).
**Steps:**
- [ ] Implement the RFC (see [this comment](https://github.com/rust-lang/rust/issues/64490#issuecomment-531579111) for a detailed checklist)
- [ ] Adjust documentation ([see instructions on rustc-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-guide][stabilization-guide])
[stabilization-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#documentation-prs
**Unresolved questions:**
- [ ] Maybe the lint should also cover cases that look like `&[mut] <place> as *[mut|const] ?T` in the surface syntax but had a method call inserted, thus manifesting a reference (with the associated guarantees). The lint as described would not fire because the reference actually gets used as such (being passed to `deref`). However, what would the lint suggest to do instead? There just is no way to write this code without creating a reference.
**Implementation history:**
* Initial implementation: https://github.com/rust-lang/rust/pull/64588 | I'll try to get a PR open for this soon.<|endoftext|>I would suggest splitting the implementation work up into phases to make each part thoroughly reviewed and tested. However, think of this list as a bunch of tasks that need to be done at some point.
1. [x] Implement `&raw [mut | const] $expr` in the parser and AST.
- [x] Ensure the `unused_parens` lint works alright.
- [x] Handle interactions in librustc_resolve.
2. [x] Push things down from AST => HIR
- [x] Handle lowering
- [x] Handle type checking
3. [x] Push things down from HIR => HAIR
4. [x] Push things down from HAIR => MIR -- here, the actual MIR operation is introduced.
5. [ ] Introduce lints for statically detectable UB as per the RFC.
6. [ ] Make `safe_packed_borrows` a hard error when the feature gate is active, and make this the case as well for `unsafe` equivalents.
------------------
...but it seems @matthewjasper already has a PR heh.<|endoftext|>> Make safe_packed_borrows a hard error when the feature gate is active, and make this the case as well for unsafe equivalents.
I'm not sure that this is a good idea. This would make it impossible to gradually migrate a codebase over to using raw references - once the feature gate is enabled, all references to packed structs must be fixed at once in order to get the crate building again.<|endoftext|>I wonder why not `&raw $expr` but `&raw
const $expr`. Is there a discussion about this?<|endoftext|>@moshg Yes, this was discussed. See [here (and the following comments) for an initial discussion](https://github.com/rust-lang/rfcs/pull/2582#issuecomment-465519395). And [here (and the following comments) for a signoff from grammar-wg](https://github.com/rust-lang/rfcs/pull/2582#issuecomment-483439054). And [here for an example that `&raw (expr)` can be ambiguous](https://github.com/rust-lang/rfcs/pull/2582#issuecomment-489468105).
I think it might be worth amending the RFC to state why `&raw const $expr` was chosen over `&raw $expr`.<|endoftext|>The RFC thread noted a couple times (including [in the FCP comment](https://github.com/rust-lang/rfcs/pull/2582#issuecomment-515640943)) that `&raw expr` without the `const` conflicts with existing syntax and would break real code. https://github.com/rust-lang/rfcs/pull/2582#issuecomment-465515012 goes into some detail. My understanding is that it is still possible to migrate to `&raw expr` with breaking changes in an edition, and I didn't see much explicit discussion of that, but I think everyone agrees that there's enough urgency here that we definitely prefer making `&raw const expr` a thing over blocking any solution on waiting for another edition.<|endoftext|>@mjbshaw @lxrec
Thank you for your explanations! I've understood why `&raw $expr` is breaking change.<|endoftext|>> I think it might be worth amending the RFC to state why &raw const $expr was chosen over &raw $expr.
https://github.com/rust-lang/rfcs/pull/2764<|endoftext|>@RalfJung I'm addressing the points you've made in https://github.com/rust-lang/rfcs/pull/2582#issuecomment-539906767
> promotion being confusing here seems mostly orthogonal to raw-vs-ref, doesn't it?
While it would be helpful to have at least a warning for a promotion in `&mut <rvalue>` case, disabling it is a backward incompatible change to the language. In `&raw mut <rvalue>` case it can be done from the beginning.
> If no promotion happens with raw ptrs, what would you expect to happen instead?
I would expect `&raw mut <rvalue>` to result in compilation error, as `&<rvalue>` does in C.
> I would expect &raw mut (1+2) to be promoted the same way &mut (1+2) is; not doing that seems even more confusing and very error-prone
I have an impression that silently allowing such promotions is more error prone, as it violates the principle of least surprise.
```
trait AddTwo {
fn add_two(&mut self);
}
impl AddTwo for u32 {
fn add_two(&mut self) { *self += 2; }
}
const N: u32 = 0;
// somewhere else
assert_eq!(N, 0);
// N += 2; // doesn't compile
N.add_two(); // compiles with no warnings
assert_eq!(N, 2); // fails
```
<|endoftext|>> promotion being confusing here seems mostly orthogonal to raw-vs-ref, doesn't it?
yes, promotion has nothing to do with it as far as I can tell.
> I would expect &raw mut <rvalue> to result in compilation error, as &<rvalue> does in C.
I agree. We should error on any `&raw place` where `place`
1. has no `Deref` projections (`*`) or `Index` (`[i]`) projections
2. *and* has a temporary local as base
since we still want to permit `&raw *foo()` I would assume. Or more concretely `&raw foo().bar` when `foo()` returns a reference.
If "erroring if not" has too many negations (i confused myself in the process of writing this), here's a version of what I think we should permit (and only that):
We should permit `&raw place` only if `place`
1. has `Deref` projections or `Index` projections
2. or has a static or local variable as the base<|endoftext|>> While it would be helpful to have at least a warning for a promotion in &mut <rvalue> case, disabling it is a backward incompatible change to the language. In &raw mut <rvalue> case it can be done from the beginning.
Note that *not* promoting here means this becomes a very short-lived temporary and the code has UB (or fails to compile, when only safe references are used)! Is that really what you want? `ptr as T` is *not* a place like `ptr` is and cannot be used as such; in particular it cannot be mutated.
> I have an impression that silently allowing such promotions is more error prone, as it violates the principle of least surprise.
I have a hard time imagining that silently causing UB is less of a surprise than promoting...
> `N.add_two(); // compiles with no warnings`
You are conflating some things here; what you are seeing here are implicit deref coercions. Promotion is not involved in this example.
> We should permit &raw place only if place
Oh I see, you want to cause some static errors. Yeah I can imagine that there are reasonable things we could do here.<|endoftext|>> You are conflating some things here; what you are seeing here are implicit deref coercions. Promotion is not involved in this example.
There's a bit of misunderstanding. I used a wrong term. When I said "rvalue promotion", I had "creation of a temporary memory location for an rvalue" in mind, not "promotion of a temporary to `'static`". <|endoftext|>@red75prime oh I see. Well currently, with promotion, we do *not* create a temporary memory location, but just a global one. But I suppose your desired behavior is more like what @oli-obk described, where we have static compiler errors?
I am not sure to what extend we can reliably produce those though. But MIR construction *should* know when it builds temporaries, so couldn't it refuse to do that when `&raw` is involved? Cc @matthewjasper <|endoftext|>Is there any plan to eventually add `&raw` pointer support to pattern matching? It could enable getting rid of [various forms of deliberate UB in abomonation](https://github.com/rust-lang/unsafe-code-guidelines/issues/77#issuecomment-544139277).<|endoftext|>@HeroicKatora actually wrote an RFC for that, though it was originally meant as an *alternative* to `&raw`: https://github.com/rust-lang/rfcs/pull/2666<|endoftext|>I'd be fine with it being interpreted as complementary, and can rewrite portions of it as necessary :)<|endoftext|>I can't recall if this was discussed in the RFC (and failed to find any comments on it), but can `<place>` be a pointer (to allow pointer-to-field computations)? Example:
```Rust
struct Struct {
field: f32,
}
let base_ptr = core::mem::MaybeUninit::<Struct>::uninit().as_ptr();
let field_ptr = &raw const base_ptr.field; // Is this allowed by this RFC?
```
Currently `field_ptr` has to be initialized with `unsafe { &(*base_ptr).field as *const _ }`. Using `unsafe { &raw const(*base_ptr).field }` is a bit better, but avoiding the `*base_ptr` dereference entirely would be ideal.
I assume the RFC doesn't permit this (since `base_ptr.field` isn't a place), but I just wanted to confirm (to be clear: I'm not trying to advocate for this RFC to do that if it doesn't already; I would like to draft a separate RFC exploring ways to avoid the `*base_ptr` dereference).<|endoftext|>> I can't recall if this was discussed in the RFC (and failed to find any comments on it), but can <place> be a pointer (to allow pointer-to-field computations)?
That question is ill-typed. A pointer is a kind of value, which is a class of things separate from places.
> `let field_ptr = &raw const base_ptr.field; // Is this allowed by this RFC?`
No, because there is no deref coercion for raw ptrs. But `&raw const (*base_ptr).field` is allowed, because `(*base_ptr).field` is a place.
> avoiding the *base_ptr dereference entirely would be ideal.
That has nothing to do with places though, that's just a deref coercion. When you write similar things with references, they work because the compiler adds the `*` for you -- and not because of anything having to do with places.
> since base_ptr.field isn't a place
It's not even well-typed.
> I would like to draft a separate RFC exploring ways to avoid the *base_ptr dereference).
Agreed, the current syntax is bad -- but mostly because of the parenthesis and the use of a prefix operator. I think we should have posfix-deref, e.g. `base_ptr.*.field`. That has been discussed before... somewhere...<|endoftext|>> That question is ill-typed. A pointer is a kind of value, which is a class of things separate from places.
You're right. Sorry for my poor choice of words.
> > ```Rust
> > let field_ptr = &raw const base_ptr.field; // Is this allowed by this RFC?
> > ```
>
> No
Thanks for answering my question. I'll follow up to your other points in a new thread on internals.rust-lang.org.<|endoftext|>Small nit: a deref coercion is `&T` to `&U` via deref(s). Dot access has its own implicit deref.<|endoftext|>Hey,the RFC document doesn't link to this tracking issue,it's linking to https://github.com/rust-lang/rust/issues/ .<|endoftext|>So, wait, would `let field_ptr = &raw const (*base_ptr).field;` work *without unsafe* with this RFC? Or would it still need to be wrapped in an `unsafe {}` block due to the "dereference" in `(*base_ptr)`?<|endoftext|>given that people try to write offset calculation code using null pointers, that expression shouldn't produce a real deref, and it should then actually work in safe code. wrapping_offset is safe, and offset is only unsafe because you _could_ go out of bounds, but a field pointer will always be in-bounds so there's not that danger.<|endoftext|>No, it requires unsafe. The place expression does not access the memory `base_ptr` points at, but it is (in effect for the current implementation) an `offset` operation and as such a dangling `base_ptr` causes UB.
Even if we take the separate & not-even-formally-proposed step of dropping the "must point to an allocated object" requirement for field projections to retroactively make `offsetof` implementations using null pointers defined, there's still the separate matter of wraparound in the address calculation (e.g. if `base_ptr as usize == usize::MAX`). Such wraparound is currently UB as well (it enables some nice optimizations) and does not affect any `offsetof` implementation, so it would be an even tougher sell to drop that UB.<|endoftext|>ahhhh I agree that you're correct but I don't like it.<|endoftext|>In terms of the [reference](https://doc.rust-lang.org/reference/behavior-considered-undefined.html), `&raw const (*base_ptr).field` still hits the clause saying
> Dereferencing (using the * operator on) a dangling or unaligned raw pointer.
This RFC does not actually change that list of UB. It just makes it so that one can avoid the clause in the reference that refers to `&[mut]` types.
That said, I just realized that the reference declares `&raw const (*packed_field).subfield` UB if `packed_field` is an unaligned raw pointer (e.g. to a field of a packed struct). That is probably not what we want...
The reason I phrased that clause as referring to "dereferencing" as opposed to actual memory accesses is precisely @roblabla's question.
Looks like we need two clauses?
> * Dereferencing (using the `*` operator on) a dangling raw pointer.
> * Reading from or writing to an unaligned raw pointer. (This refers only to `*ptr` reads and `*ptr = val` writes; raw pointer *methods* have their own rules which are spelled out in their documentation.)<|endoftext|>Should we also add `raw ref` bindings in patterns? For implementing `offset_of!`, https://internals.rust-lang.org/t/discussion-on-offset-of/7440/2 recommends using a struct pattern instead of a field access expression, in order to protect against accidentally accessing the field of another struct through `Deref`:
```rust
let u = $crate::mem::MaybeUninit::<$Struct>::uninitialized();
let &$Struct { $field: ref f, .. } = unsafe { &*u.as_ptr() };
```<|endoftext|>The current implementation does not prevent `&raw const foo().as_str()` where `fn foo() -> String` as far as I can tell. Repeating my post from https://github.com/rust-lang/rust/pull/64588#discussion_r357969199
The check for `&raw const 2` not being permitted is done on the HIR, and already mentions the downside to doing it on the HIR:
https://github.com/rust-lang/rust/blob/8843b28e64b02c2245f5869ad90cafa6d85ab0d9/src/librustc_typeck/check/expr.rs#L494-L496
The check could be implemented on the MIR by bailing out if any `Rvalue::AddressOf`'s `Place` is a temporary. Although that will probably start failing `&raw const *&*local` (reborrowing a local and then reading from it). I think it would be best if we somehow reuse the logic that causes
```rust
fn foo() -> String {
unimplemented!()
}
fn main() {
let x = foo().as_str();
println!("{}", x);
}
```
to emit
```
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:6:13
|
6 | let x = foo().as_str();
| ^^^^^ - temporary value is freed at the end of this statement
| |
| creates a temporary which is freed while still in use
7 | println!("{}", x);
| - borrow later used here
|
= note: consider using a `let` binding to create a longer lived value
```
I believe we should block stabilization on resolving this in a nonfragile way.<|endoftext|>The initial implementation PRs (#64588, #66671) for this are now merged and will be available from the next nightly.
> The current implementation does not prevent `&raw const foo().as_str()` where `fn foo() -> String` as far as I can tell.
It does: https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=7b0161f073236977f626102b9f3de81d
<|endoftext|>Is this fully implemented? Several PRs have been merged, but the "Implement the RFC" box is still unchecekd. | B-RFC-approved<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>requires-nightly<|endoftext|>F-raw_ref_op<|endoftext|>S-tracking-needs-summary | 77 | https://api.github.com/repos/rust-lang/rust/issues/64490 | https://github.com/rust-lang/rust/issues/64490 | https://api.github.com/repos/rust-lang/rust/issues/64490/comments |
486,862,701 | 63,997 | Tracking issue for const fn pointers | Sub-tracking issue for https://github.com/rust-lang/rust/issues/57563.
This tracks `const fn` types and calling `fn` types in `const fn`.
---
From the RFC (https://github.com/oli-obk/rfcs/blob/const_generic_const_fn_bounds/text/0000-const-generic-const-fn-bounds.md#const-function-pointers):
## `const` function pointers
```rust
const fn foo(f: fn() -> i32) -> i32 {
f()
}
```
is illegal before and with this RFC. While we can change the language to allow this feature, two
questions make themselves known:
1. fn pointers in constants
```rust
const F: fn() -> i32 = ...;
```
is already legal in Rust today, even though the `F` doesn't need to be a `const` function.
2. Opt out bounds might seem unintuitive?
```rust
const fn foo(f: ?const fn() -> i32) -> i32 {
// not allowed to call `f` here, because we can't guarantee that it points to a `const fn`
}
const fn foo(f: fn() -> i32) -> i32 {
f()
}
```
Alternatively one can prefix function pointers to `const` functions with `const`:
```rust
const fn foo(f: const fn() -> i32) -> i32 {
f()
}
const fn bar(f: fn() -> i32) -> i32 {
f() // ERROR
}
```
This opens up the curious situation of `const` function pointers in non-const functions:
```rust
fn foo(f: const fn() -> i32) -> i32 {
f()
}
```
Which is useless except for ensuring some sense of "purity" of the function pointer ensuring that
subsequent calls will only modify global state if passed in via arguments.
| I think that, at the very least, this should work:
```rust
const fn foo() {}
const FOO: const fn() = foo;
const fn bar() { FOO() }
const fn baz(x: const fn()) { x() }
const fn bazz() { baz(FOO) }
```
For this to work:
* `const` must be part of `fn` types (just like `unsafe`, the `extern "ABI"`, etc.)
* we should allow calling `const fn` types from const fn
Currently, `const fn`s already coerce to `fn`s, so `const fn` types should too:
```rust
const fn foo() {}
let x: const fn() = foo;
let y: fn() = x; // OK: const fn => fn coercion
```
I don't see any problems with supporting this. The RFC mentions some issues, but I don't see anything against just supporting this restricted subset.
This subset would be **super** useful. For example, you could do:
```rust
struct Foo<T>(T);
trait Bar { const F: const fn(Self) -> Self; }
impl<T: Bar> Foo<T> {
const fn new(x: T) -> Self { Foo(<T as Bar>::F(x)) }
}
const fn map_i32(x: i32) -> i32 { x * 2 }
impl Bar for i32 { const F: const fn(Self) -> Self = map_i32; }
const fn map_u32(x: i32) -> i32 { x * 3 }
impl Bar for u32 { const F: const fn(Self) -> Self = map_u32; }
```
which is a quite awesome work around for the lack of `const` trait methods, but much simpler since dynamic dispatch isn't an issue, as opposed to:
```rust
trait Bar { const fn map(self) -> Self; }
impl Bar for i32 { ... }
impl Bar for u32 { ... }
// or const impl Bar for i32 { ... {
```
This is also a way to avoid having to use `if`/`match` etc. in `const fn`s, since you can create a trait with a const, and just dispatch on it to achieve "conditional" control-flow at least at compile-time.<|endoftext|>AFAIK `const fn` types are not even RFC'd, isn't it too early for a tracking issue?<|endoftext|>Don't know, @centril suggested that I open one.
I have no idea why `const fn` types aren't allowed. AFAICT, whether a function is `const` or not is part of its type, and the fact that `const fn` is rejected in a type is an implementation / original RFC oversight. If this isn't the case, what is the case?
EDIT: If I call a non-`const fn` from a `const fn`, that code fails to type check, so for that to happen `const` must be part of a `fn` type.<|endoftext|>> AFAIK `const fn` types are not even RFC'd, isn't it too early for a tracking issue?
Lotsa things aren't RFCed with respect to `const fn`. I want these issues for targeted discussion so it doesn't happen on the meta issue.<|endoftext|>> If I call a non-const fn from a const fn, that code fails to type check, so for that to happen const must be part of a fn type.
it is.
you can do
```rust
const fn f() {}
let x = f;
x();
```
inside a constant. But this information is lost when casting to a function pointer. Function pointers just don't have the concept of of constness.<|endoftext|>Figuring out constness in function pointers or dyn traits is a tricky questions, with a lot of prior discussion in [the RFC](https://github.com/rust-lang/rfcs/pull/2632) and [the pre-RFC](https://github.com/rust-rfcs/const-eval/pull/8).<|endoftext|>whats about?
``
pub trait Reflector {
fn Reflect(&mut self)-> (const fn(Cow<str>)->Option<Descriptor>);
}
``<|endoftext|>I was fiddling with something while reading [some of the discussion](https://github.com/rust-lang/rfcs/pull/2788) around adding a `lazy_static` equivalent to std and found that this check forbids even *storing* a `fn` pointer in a value returned from a `const fn` which seems unnecessarily restrictive given that storing them in `const` already works. The [standard lazy types RFC](https://github.com/rust-lang/rfcs/pull/2788) winds up defining `Lazy` like:
```rust
pub struct Lazy<T, F = fn() -> T> { ... }
```
[Here's a simple (but not very useful) example](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=047129b241a002f657b29bbf787c891f) that hits this.
[Adding another type parameter for the function](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018) makes it work on stable but it feels unnecessary.
Could this specific case be allowed without stabilizing the entire ball of wax here? (Specifically: referencing and storing `fn` pointers in `const fn` but not calling them.)<|endoftext|>> Could this specific case be allowed without stabilizing the entire ball of wax here? (Specifically: referencing and storing fn pointers in const fn but not calling them.)
The reason we can't do this is that this would mean we'd lock ourselves into the syntax that `fn()` means a not callable function pointer (which I do realize constants already do) instead of unifying the syntax with trait objects and trait bounds as shown in the main post of this issue<|endoftext|>Just in case other people run into this being unstable: It's still possible to use function pointers in `const fn` as long as they're wrapped in some other type (eg. a `#[repr(transparent)]` newtype or an `Option<fn()>`):
```rust
#[repr(transparent)]
struct Wrap<T>(T);
extern "C" fn my_fn() {}
const FN: Wrap<extern "C" fn()> = Wrap(my_fn);
struct Struct {
fnptr: Wrap<extern "C" fn()>,
}
const fn still_const() -> Struct {
Struct {
fnptr: FN,
}
}
```<|endoftext|>If const is a qualifier of function like `unsafe` or `extern` we have next issue:
```rust
const fn foo() { }
fn bar() { }
fn main() {
let x = if true { foo } else { bar };
}
```
It compiles now but not compiles with these changes because `if` and `else` have incompatible types.
So it breaks an old code. <|endoftext|>> If const is a qualifier of function like `unsafe` or `extern` we have next issue:
>
> ```rust
> const fn foo() { }
> fn bar() { }
>
> fn main() {
> let x = if true { foo } else { bar };
> }
> ```
>
> It compiles now but not compiles with these changes because `if` and `else` have incompatible types.
> So it breaks an old code.
Const fn's are still fns, the type won't be charged. In fact const qualifier only allows const fn appear in const contexes, and be evaluated at compile time. You can think of this like implicit casting. <|endoftext|>```rust
unsafe fn foo() { }
fn bar() { }
fn main() {
let x = if true { foo } else { bar };
}
```
This code does not compile for the same reason. Unsafe fn's are still fns too, why we haven't implicit casting in this situation?
<|endoftext|>> ```rust
> unsafe fn foo() { }
> fn bar() { }
>
> fn main() {
> let x = if true { foo } else { bar };
> }
> ```
>
> This code does not compile for the same reason. Unsafe fn's are still fns too, why we haven't implicit casting in this situation?
This leads to possible unsafety in our code, and all which comes with it. `const ` fn casting on otherside don't brings any unsafety, so is allowed, const fn must not have any side effects only, it is compatible with fn contract.
```rust
fn bar() {}
const fn foo(){}
const fn foo_bar(){
if true { foo() } else { bar() };
}
```
This must not compile, because bar is not const and therefore can't be evaluated at compile time. Btw, it raises(?) "can't call non const fn inside of const one", and can be considered incorrect downcasting. (set of valid const fns is smaller than set of fns at all)<|endoftext|>> > fn main() {
> > let x = if true { foo } else { bar };
> > }
> > ```
> >
> >
> > This code does not compile for the same reason. Unsafe fn's are still fns too, why we haven't implicit casting in this situation?
>
> This leads to possible unsafety in our code, and all which comes with it. `const ` fn casting on otherside don't brings any unsafety, so is allowed, const fn must not have any side effects only, it is compatible with fn contract.
I think you're missing the point. With implicit coercions, the type of `x` would be `unsafe fn()`, not `fn()`. There's nothing about that which leads to possible unsafety. Generally, `const fn()` can be coerced to `fn()` and `fn()` can be coerced to `unsafe fn()`. It just doesn't happen automatically, which is why changing `const fn foo()` to coerce into `const fn()` rather than `fn()` implicitly is a breaking change.
> ```rust
> fn bar() {}
>
> const fn foo(){}
>
> const fn foo_bar(){
> if true { foo() } else { bar() };
> }
> ```
>
> This must not compile, because bar is not const and therefore can't be evaluated at compile time. Btw, it raises(?) "can't call non const fn inside of const one", and can be considered incorrect downcasting. (set of valid const fns is smaller than set of fns at all)
Of course this must not compile, but I don't think that's related to what @filtsin was talking about.<|endoftext|>Personally I would love to see more implicit coercions for function pointers. Not sure how feasible that is though. I've previously wanted trait implementations for function pointer types to be considered when passing a function (which has a unique type) to a higher-order generic function. I posted about it on internals, but it didn't receive much attention.<|endoftext|>> Generally, `const fn()` can be coerced to `fn()` and `fn()` can be coerced to `unsafe fn()`. It just doesn't happen automatically, which is why changing `const fn foo()` to coerce into `const fn()` rather than `fn()` implicitly is a breaking change.
>
But not in oposite direction - thats what i wanted to say.
<|endoftext|>```rust
impl<T> Cell<T> {
pub fn with<U>(&self, func: const fn(&mut T) -> U) -> U;
}
```
Wouldn't const fn pointers make this sound? A const fn can't access a static or a thread-local, which would make this unsound.
Edit: a cell containing a reference to itself makes this unsound<|endoftext|>It seems assignment is currently broken, complaining about casts, even though no such casts are actually performed. (A const function simply assigning a function ptr basically). https://github.com/rust-lang/rust/issues/83033<|endoftext|>See my response at https://github.com/rust-lang/rust/issues/83033#issuecomment-831089437 -- short summary: there is in fact a cast going on here; see [the reference on "function item types"](https://doc.rust-lang.org/nightly/reference/types/function-item.html) for more details.<|endoftext|>> Just in case other people run into this being unstable: It's still possible to use function pointers in `const fn` as long as they're wrapped in some other type (eg. a `#[repr(transparent)]` newtype or an `Option<fn()>`):
I've found a case where this isn't true. ([playground link](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=c9a6f0f5d7bb211de352e33ad11bd012))
```rust
struct Handlers([Option<fn()>; _]);
impl Handlers {
const fn new() -> Self {
Self([None; _])
}
}
```<|endoftext|>Yea, just like with dyn Trait or generic trait bounds, there are workarounds to our checks and I'm convinced now we should just allow all of these like we do in const items. You can't call them, but you can pass them around.<|endoftext|>For const closures a lot has happened in 2022.
This now works since `rustc 1.61.0-nightly (03918badd 2022-03-07)` (commit range is 38a0b81b1...03918badd but I can't narrow it down to a single PR... maybe a side effect of #93827 ???):
```Rust
#![feature(const_trait_impl)]
const fn foo<T: ~const Fn() -> i32>(f: &T) -> i32 {
f()
}
```
And since `rustc 1.68.0-nightly (9c07efe84 2022-12-16)` (I suppose the PR was #105725) you can even use `impl Trait` syntax:
```Rust
#![feature(const_trait_impl)]
const fn foo(f: &impl ~const Fn() -> i32) -> i32 {
f()
}
```
For const fn pointers, nothing much has happened though. This still errors:
```Rust
const fn foo(f: ~const fn() -> i32) -> i32 {
f()
}
```
gives
<details>
```
error: expected identifier, found keyword `fn`
--> src/lib.rs:2:24
|
2 | const fn foo(f: ~const fn() -> i32) -> i32 {
| ^^
|
help: use `Fn` to refer to the trait
|
2 | const fn foo(f: ~const Fn() -> i32) -> i32 {
| ~~
error: `~const` is not allowed here
--> src/lib.rs:2:17
|
2 | const fn foo(f: ~const fn() -> i32) -> i32 {
| ^^^^^^^^^^^^^^^^^^
|
= note: trait objects cannot have `~const` trait bounds
error[E0782]: trait objects must include the `dyn` keyword
--> src/lib.rs:2:17
|
2 | const fn foo(f: ~const fn() -> i32) -> i32 {
| ^^^^^^^^^^^^^^^^^^
|
help: add `dyn` keyword before this trait
|
2 | const fn foo(f: dyn ~const fn() -> i32) -> i32 {
| +++
For more information about this error, try `rustc --explain E0782`.
error: could not compile `playground` (lib) due to 3 previous errors
```
</details>
Edit: note that while what I said is great progress, the two aren't *well* comparable, as the `Fn` trait support is for monomorphized generics cases, as in those where we know the type at const eval time and can derive the function from the type. `dyn Fn` trait support is still not existent. This gives a bunch of errors:
```Rust
#![feature(const_trait_impl)]
const fn foo(f: &dyn ~const Fn() -> i32) -> i32 {
f()
}
``` | T-lang<|endoftext|>A-const-fn<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 23 | https://api.github.com/repos/rust-lang/rust/issues/63997 | https://github.com/rust-lang/rust/issues/63997 | https://api.github.com/repos/rust-lang/rust/issues/63997/comments |
473,762,264 | 63,084 | Tracking issue for `const fn` `type_name` | This is a tracking issue for making and stabilizing `type_name` as `const fn`. It is not clear whether this is sound. Needs some T-lang discussion probably, too.
Steps needed:
* [x] Implementation (essentially add `const` and `#[rustc_const_unstable(feature = "const_type_name")` to the function and add tests showing that it works at compile-time.
* [ ] fix https://github.com/rust-lang/rust/issues/94187
* [ ] check if https://github.com/rust-lang/rust/issues/97156 replicates for `type_name`, too
* [ ] Stabilization
* Note that stabilization isn't happening any time soon. This function can change its output between rustc compilations and allows breaking referential transparency. Doing so at compile-time has not been discussed fully and has various points that are problematic.
| > This function can change its output between rustc compilations
Can the output change between compiling a library crate, and a binary crate using that library? Or only when switching rustc versions?<|endoftext|>> Can the output change between compiling a library crate, and a binary crate using that library?
No, we're using global paths now.
> Or only when switching rustc versions?
Yes, there needs to be a change in rustc that causes a change in output.<|endoftext|>I might take a look at this. (I implemented the support for using the actual `type_name` intrinsic in `const fn` contexts, if you don't remember me, haha.)
I think we definitely know it works at compile time though, don't we? That's what [this test I added at the time](https://github.com/rust-lang/rust/blob/4560cb830fce63fcffdc4558f4281aaac6a3a1ba/src/test/ui/consts/const-fn-type-name.rs) checks for.<|endoftext|>Sorry it took me a bit to get to this. [Just opened a PR.](https://github.com/rust-lang/rust/pull/63123)<|endoftext|>How does this break referential transparency? I'd like to see that elaborated upon.<|endoftext|>I might be wrong, but I think the first "checkbox" can be checked since my PR was merged?
@lfairy:
Personally, I disagree, but some people seem to think that despite the fact Rust has fully reified generics, it's somehow a "dangerous" concept for your "average Joe/Jane" to be able to access the (100%-guaranteed-correct) name of a generic parameter.
Something about "Java programmers I used to work with did Some Bad Thing and I don't want Rust programmers to also do Some Bad Thing".
I don't know anything about Java though so I'm probably not overly qualified to get too much into that.<|endoftext|>Hi, is there a stabilization issue for this `const`-ification?<|endoftext|>This is the tracking issue, so it will get closed on stabilization. I don't know what the next steps for stabilizing it are though. The discussion around referential transparency needs to be had (although with specialization it'd become obsolete, because then we'd get this feature anyway, but in a less convenient way). I think posting use cases would be very helpful for the discussion. Since this works with feature gates, you can always show a use case with nightly.<|endoftext|>Hi, certainly I can write about a use case that I am working on!
I'm part of the Embedded WG where I am currently working on an instrumentation/logging tool for embedded targets. Here, as you probably know, we have strict requirements on code size as the micro controllers have very little memory.
And a huge hog of memory is when strings are placed in memory.
To this end I place formating strings and (I want) type strings in an `INFO` linker section so they are available in the ELF but not loaded onto the target. That is the following code as an example:
```rust
// test1 is some variable
mylog::log!("Look what I got: {}", &test1);
//
// Expands to:
//
const fn get_type_str<T>(_: &T) -> &'static str {
// type_name needs to be a const fn for this to work
core::any::type_name::<T>()
}
// ugly hack to tranform `&'static str` -> `[u8; str.len()]`
union Transmute<T: Copy, U: Copy> {
from: T,
to: U,
}
const FMT: &'static str = "Look what I got: {}";
const TYP: &'static str = get_type_str(&test1);
// Transform string into byte arrays at compile time so
// they can be placed in a specific memory region
// Formating string placed in a specific linker section
#[link_section = ".some_info_section"]
static F: [u8; FMT.as_bytes().len()] = unsafe {
*Transmute::<*const [u8; FMT.len()], &[u8; FMT.as_bytes().len()]> {
from: FMT.as_ptr() as *const [u8; FMT.as_bytes().len()],
}
.to
};
// Type string placed in a specific linker section
#[link_section = ".some_info_section"]
static T: [u8; TYP.as_bytes().len()] = unsafe {
*Transmute::<*const [u8; TYP.len()], &[u8; TYP.as_bytes().len()]> {
from: TYP.as_ptr() as *const [u8; TYP.as_bytes().len()],
}
.to
};
// Here we send where the strings are stored in the ELF + the data to the host
write_frame_to_host(&F, &T, &test1)
```
Link script:
```
SECTIONS {
.some_info_section (INFO) :
{
*(.some_info_section .some_info_section.*);
}
}
```
By doing this the strings are available in the generated ELF but not loaded onto the target, and the type can be reconstructed through DWARF with help of the type string.
And with complex types the space used for the type is getting very large for example any type that uses `GenericArray` (which we use extensively).
Currently the string is placed in `.rodata` which means that the compiler fully knows that this is a static string, and I made an issue on how to control where strings are placed which can use a trick outlined in here: https://github.com/rust-lang/rust/issues/70239
However this trick only works if the string is available in const context.
This is why I am asking about stabilization here.<|endoftext|>I would also like to get this stabilized and can present a use-case.
I'm working on [firestorm](https://github.com/That3Percent/firestorm): a low overhead intrusive flame graph profiler. I created `firestorm` because existing solutions have too much overhead to be useful for [Tree-Buf](https://github.com/That3Percent/tree-buf): the self-describing serialization system that produces files smaller than GZip faster than uncompressed formats.
Part of keeping the overhead of `firestorm` low is to delay string formatting/allocation until outside of the profiled region. So, there is an enum that allows for arbitrary amounts of `&'static str` to be concatenated. In order to keep the amount of data writing to a minimum during the execution of the profiled region, we only write `&'static EventData` so that `EventData` can be large. Supporting concatenation of fn name and struct name for a method is only possible if `type_name` is a `const fn`.
TLDR: I need this to be `const fn` for performance.<|endoftext|>To elaborate here's code I would like to have be able to compile:
```rust
#[macro_export]
macro_rules! profile_method {
($($t:tt)*) => {
let _firestorm_method_guard = {
const FIRESTORM_STRUCT_NAME: &'static str = ::std::any::type_name::<Self>();
let event_data: &'static _ = &$crate::internal::EventData::Start(
$crate::internal::Start::Method {
signature: stringify!($($t)*),
typ: FIRESTORM_STRUCT_NAME,
}
);
$crate::internal::start(event_data);
$crate::internal::SpanGuard
};
};
}
```
It seems there are at least 2 problems here though. First, is that `type_name` is not a const fn. The second is that the compiler complains about the use of `Self` as the generic for the const fn. I do not really understand why that's a problem when each monomorphized function could have its own value here.
<|endoftext|>@That3Percent I don't think the `Self` part is something that can be solved at present, even if we stabilize `type_name`. You can test this out by using nightly and activating the feature gate for `const_type_name`<|endoftext|>@oli-obk Yes, you are right. Both issues would need to be resolved to support my use-case in the way that I would like.<|endoftext|>I found a bug with `type_name`: `type_name` works in array lengths of arrays used in associated consts, even if it is `type_name::<Self>`. This doesn't even work for `size_of`. The bug is that `type_name` just returns `_` in that case:
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=4404a9b3635b4bf5047c2493ac9a5082
If you comment out the first panic, you get the correct type name.<|endoftext|>> I found a bug with type_name: type_name works in array lengths of arrays used in associated consts, even if it is type_name::<Self>. This doesn't even work for size_of. The bug is that type_name just returns _ in that case:
This seems to be fixed now?<|endoftext|>Has there been any progress on the stabilization of `type_name`?<|endoftext|>Ping again on the status of stabilization?<|endoftext|>`type_id` (https://github.com/rust-lang/rust/issues/77125) has a bunch of issues which is why its stabilization actually got reverted; not sure if those issues also apply to `type_name`.<|endoftext|>Would you believe I clicked the wrong link in Rustdoc? Sorry.<|endoftext|>Is there any outlook on stabilization/progress towards it?<|endoftext|>There's a rendering bug and a soundness bug that we need to fix before we can stabilize. Both are linked from the main post | T-lang<|endoftext|>T-libs-api<|endoftext|>B-unstable<|endoftext|>A-const-fn<|endoftext|>C-tracking-issue<|endoftext|>requires-nightly<|endoftext|>Libs-Tracked<|endoftext|>Libs-Small<|endoftext|>S-tracking-needs-summary | 21 | https://api.github.com/repos/rust-lang/rust/issues/63084 | https://github.com/rust-lang/rust/issues/63084 | https://api.github.com/repos/rust-lang/rust/issues/63084/comments |
473,431,185 | 63,012 | Tracking issue for -Z binary-dep-depinfo | This is a tracking issue for `-Z binary-dep-depinfo` added in #61727.
The cargo side is implemented in https://github.com/rust-lang/cargo/pull/7137.
Blockers:
- [ ] Canonicalized paths on Windows. The dep-info file includes a mix of dos-style and extended-length (`\\?\`) paths, and I think we want to use only one style (whatever is compatible with make and other tools). See the PR for details.
- [ ] Codegen backends are not tracked.
cc @Mark-Simulacrum @alexcrichton
| In https://github.com/rust-lang/rust/pull/68298 we fixed binary dep-depinfo to be less eager to emit dependencies on dylib/rlib files when emitting rlibs and rmeta files, as we only need rmeta input in that case.
It was also noted that we currently do not correctly emit plugin dependencies (I'm not entirely sure of this, but seems not implausible).<|endoftext|>MCP: https://github.com/rust-lang/compiler-team/issues/464<|endoftext|>I wonder if the Cargo side of `binary-dep-info` could also be taught specifically about the [hashes in `rustc` metadata](https://github.com/rust-lang/rust/blob/fee75fbe11b1fad5d93c723234178b2a329a3c03/compiler/rustc_metadata/src/locator.rs#L665-L674) so that it doesn't _just_ use timestamps for artifacts where a more reliable metric is (I think?) readily available (without going all the way to https://github.com/rust-lang/rust/pull/75594 / https://github.com/rust-lang/cargo/pull/8623 / https://github.com/rust-lang/cargo/issues/6529).<|endoftext|>Separately, repeating the sentiment from https://github.com/rust-lang/cargo/issues/10664#issuecomment-1125438398 that tracking codegen backends should probably not be considered a blocker for landing this — the feature can very much be useful without that I think, and it could be added later on.<|endoftext|>> I wonder if the Cargo side of binary-dep-info could also be taught specifically about the [hashes in rustc metadata](https://github.com/rust-lang/rust/blob/fee75fbe11b1fad5d93c723234178b2a329a3c03/compiler/rustc_metadata/src/locator.rs#L665-L674) so that it doesn't just use timestamps for artifacts where a more reliable metric is (I think?) readily available
1. That requires some way for cargo to read it directly from the metadata file.
2. It shouldn't be tied to -Zbinary-dep-depinfo IMO.<|endoftext|>Discussed in T-compiler [backlog bonanza](https://rust-lang.zulipchat.com/#narrow/stream/238009-t-compiler.2Fmeetings/topic/.5Bsteering.20meeting.5D.202022-08-12.20compiler-team.23484.20backlog.20b'za/near/293120445)
We had some confusion about who the target audience for this feature is. From reading the comments, we understand it was added for certain things in `rustbuild`. There had been some discussion of making binary-dep-depinfo the default (see e.g. https://github.com/rust-lang/compiler-team/issues/464 ), but we are not clear on whether that is a reasonable thing to do. Likewise, we are not clear on whether upgrading the `-Z` flag here to a `-C` flag would be a reasonable thing to do.
Independent of that, there were design questions, e.g. what things should be included. (It doesn't track native dependencies, for example.)
So, I'm adding the design concerns label below, but I would be interested to know if I should also be adding S-tracking-perma-unstable
@rustbot label: S-tracking-design-concerns<|endoftext|>Given the confusion we had in our conversation about this, I'm also going to request a summary of this feature and its status. :)
@rustbot label: S-tracking-needs-summary<|endoftext|>I can speak to the use-case in my case: we're using a large distributed build system at $work in which packages are automatically re-built if their dependencies change. Which, for example, means that if we for example need a patch to `rustc` to work around some internal issue, then `rustc` is re-built. And then anything that _uses_ `rustc` is re-built. But without `-Zbinary-dep-depinfo` Cargo doesn't understand that `rustc` has changed since the version number remains the same, and so doesn't realize that it must also re-build the various Rust artifacts.<|endoftext|>`cargo-udeps` uses the feature since the 0.1.33 release to figure out which dependencies were actually used during compilation, since save-analysis is going to be removed.<|endoftext|>The linux kernel uses the flag too: https://github.com/Rust-for-Linux/linux/issues/2
> Used by: Kbuild.
>
> Status: we could get around it by making the build system more complicated (particularly if the kernel does not upgrade the minimum Make version), but it would be best to avoid that.<|endoftext|>> The linux kernel uses the flag too: [Rust-for-Linux/linux#2](https://github.com/Rust-for-Linux/linux/issues/2)
>
> > Used by: Kbuild.
> > Status: we could get around it by making the build system more complicated (particularly if the kernel does not upgrade the minimum Make version), but it would be best to avoid that.
Apparently it is necessary to avoid recompiling in some scenarios: https://github.com/Rust-for-Linux/linux/issues/2#issuecomment-1307818144
> Without `-Zbinary-dep-depinfo` rustc will only put the source files and the compiled output in the depinfo file. With `-Zbinary-dep-depinfo` rustc will also add .rmeta, .rlib, ... dependencies to the depinfo file. Without this changing a depensency wouldn't cause make to rebuild dependent crates. Cargo doesn't have this issue as it already knows the dependencies on it's own and only needs the depinfo file for the source file list, but make really needs everything.
<|endoftext|>> I can speak to the use-case in my case: we're using a large distributed build system at $work in which packages are automatically re-built if their dependencies change. Which, for example, means that if we for example need a patch to `rustc` to work around some internal issue, then `rustc` is re-built. And then anything that _uses_ `rustc` is re-built. But without `-Zbinary-dep-depinfo` Cargo doesn't understand that `rustc` has changed since the version number remains the same, and so doesn't realize that it must also re-build the various Rust artifacts.
I am confused by this statement. binary-dep-depinfo does *not* emit the path to the toolchain currently: https://github.com/rust-lang/rust/blob/1fa1f5932b487a2ac4105deca26493bb8013a9a6/compiler/rustc_interface/src/passes.rs#L490-L511
Exactly what is your setup? I don't understand why this would be working for you but not for bootstrap.<|endoftext|>Ah, so, to be clear, we don't _currently_ use `-Zbinary-dep-depinfo`. Instead, incremental builds currently just break if we ever happen to have to do this. What I wrote was aspirational: we _want_ depinfo tracking in the hopes that it will _let_ Cargo/rustc detect this situation (rustc changing without the version changing) and handle it correctly.<|endoftext|>We do currently use `-Zbinary-dep-depinfo` for making cargo rebuild everything, however when incremental compilation is enabled, it is not enough to trigger a rebuild. The incr comp cache needs to be cleared too. In addition if a crate version changes, that seems to cause issues too.<|endoftext|>Cc https://github.com/rust-lang/rust/pull/111329#issuecomment-1538303474 which I believe should help explain why it's not currently enough for dependency version changes, I suspect a similar change for incremental may also be helpful but I haven't looked at incremental encoding/decoding.<|endoftext|>For incremental it wouldn't help. Even if the encoding is exactly identical the encoded query results may have changed between versions. We need to clear the incr cache unconditionally if rustc changes.<|endoftext|>To loop in some other tickets that have touched on "re-building if rustc changes" in the past: https://github.com/rust-lang/cargo/issues/10664 and https://github.com/rust-lang/cargo/issues/10367 are possibly relevant.<|endoftext|>https://github.com/rust-lang/cargo/issues/10367 is a different problem. That's about if the *path* to the compiler changes; the problem in this issue happens when the path and version output stay the same and only the *mtine* is different. | T-compiler<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>requires-nightly<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary<|endoftext|>A-cli | 18 | https://api.github.com/repos/rust-lang/rust/issues/63012 | https://github.com/rust-lang/rust/issues/63012 | https://api.github.com/repos/rust-lang/rust/issues/63012/comments |
462,983,150 | 62,290 | Tracking issue for `#![feature(async_closure)]` (RFC 2394) | This is a tracking issue for `#![feature(async_closure)]` (rust-lang/rfcs#2394).
The feature gate provides the `async |...| expr` closure syntax.
**As with all tracking issues for the language, please file anything unrelated to implementation history, that is: bugs and design questions, as separate issues as opposed to leaving comments here. The status of the feature should also be covered by the feature gate label. Please do not ask about developments here.**
**Steps:**
- [x] Implement the RFC
- [ ] Adjust documentation ([see instructions on rustc-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-guide][stabilization-guide])
[stabilization-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rust-lang.github.io/rustc-guide/stabilization_guide.html#documentation-prs
**Unresolved questions:**
None as of yet. | Hi, what's the next step for this issue?<|endoftext|>@Centril am bumping into this one quite often in beta... from an ergonomics point of view it would be great to get this stable if there's no outstanding concerns / issues... - is this something we might consider putting 'on-deck', or does it need more settlement time?<|endoftext|>Despite "Implement the RFC" being checked this feature is still largely unimplemented (other than the trivial case of `async move || {}` which is equivalent to `move || async move {}`), and as far as I'm aware also requires more design work before it can even really be implemented.<|endoftext|>@rustbot modify labels to +AsyncAwait-OnDeck
Closures are a very commonly used language feature, especially in APIs like `itertools`. Enabling such APIs to be async has obvious benefits.<|endoftext|>As @Nemo157 points out this is largely unimplemented and is entirely secondary to fixing *all* the outstanding bugs with the stable part of async/await that we are shipping in 1.39.0.
(Personally I think async closures should be considered holistically with other types of effect-modified closures. Moreover I think they might be largely redundant atop of the combination of closures with async blocks inside them.)<|endoftext|>Does this will allow ? on Result which have different Error type in the same async closure? currently, there is no way to done that, which is really frustrating<|endoftext|>@CGQAQ do you have an example that fails now? Some [quick testing](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=f0b10306b1897b06600f87cdb4eec13b) in the playground makes it look like inference is able to handle at least simple cases correctly (I definitely could see it being possible that the two layers of generics with inferred outputs might cause some issues for inference, and async closures could potentially improve on that by tying those inferred outputs together somehow).<|endoftext|>@Nemo157
```rust
async fn a() -> Result<(), reqwest::Error> {Ok(())}
async fn b() -> Result<(), std::io::Error> {Ok(())}
fn c() {
async {
a().await?;
b().await?;
Ok(())
};
}
```
```
error[E0282]: type annotations needed
--> src/x.rs:6:9
|
6 | a().await?;
| ^^^^^^^^^^ cannot infer type
error: aborting due to previous error
```
```rust
async fn a() -> Result<(), reqwest::Error> {Ok(())}
async fn b() -> Result<(), std::io::Error> {Ok(())}
fn c() {
async {
a().await?;
b().await?;
Ok::<(), impl std::error::Error>(())
};
}
```
```
error[E0562]: `impl Trait` not allowed outside of function and inherent method return types
--> src/x.rs:8:18
|
8 | Ok::<(), impl std::error::Error>(())
| ^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
```<|endoftext|>@CGQAQ the former _is_ unconstrained, there's no way rustc can know what the error type should be, changing it to be used in a closure returning an async block passed to a function which constrains it [works fine](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=6f18274ebfcf720b5ec9da45aff65f5d) (and the equivalent blocking code [also fails](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=5a517860b9922f238d852f6ba98d3c20)). The latter already [works](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=f6c962ab0c758c76327a2201b3c10734) after replacing `impl Error` with a concrete error type (as far as I'm aware `impl Trait` in that position is not supported and has not been RFCed). (I also switched both to use `serde_json::Error` instead of `reqwest::Error` as it provides the necessary conversion into `io::Error`).
If you want to continue this it would be best to open a new issue and ping me there (or discord) to avoid notifying subscribers of this issue.<|endoftext|>Any recent news/updates for this feature?<|endoftext|>The purpose of this issue to track the development by noting relevant PRs and whatnot as they happen. The feature gate label is also available to route you to relevant places. You can assume that if no recent developments have been noted here, or linked, or provided in the issues with the label, that there are no such developments, so please avoid asking about it here.<|endoftext|>Sorry if I missed it, but what's the motivation under this feature? IMO It just adds a slightly different syntax for existing thing (`async ||` vs `|| async`), introducing confusion with no foreseeable benefit. Or at least this is what I see here.
Could you elaborate on that, please?<|endoftext|>`|| async { }` is not an async closure, it's a closure that contains an async block.<|endoftext|>Yes, I see it, but what's the difference from the user perspective?<|endoftext|>There may be differences in how lifetimes in the arguments are treated once they’re supported. Also elaborating the return type is not possible with the closure to async block ([playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=5340a05b0a17feba7309a80765b5edd9))<|endoftext|>Does this feature introduce an `AsyncFn` trait, similar to `core::ops::Fn`? I cannot find it in the RFC.<|endoftext|>What is the progress with async closures? Thanks.<|endoftext|>Could someone pls explain what are the **REAL** differences if i do:
1.
```
let handler = thread::spawn(async || {
// ....
});
```
vs 2.
```
let handler = thread::spawn(|| async {
// ....
});
```
vs 3.
```
let handler = thread::spawn(|| {
async {
// ....
}
});
```
Currently 1 gives me compiling error directly, i guess there is no difference between 2 and 3?<|endoftext|>@lnshi
Version 1 is an async closure.
Version 2 and 3 are identical, a normal closure that runs an async block.<|endoftext|>Aren't async closures just like normal closures but without the redundant `move` keyword? As in:
```rust
move | _ | async move { /* ... */}
```
vs
```rust
async move | _ | { /* ... */ }
```
is there any other difference other than this?<|endoftext|>@Inshi @tvallotton I wrote about a key draw of them in [this comment](https://www.reddit.com/r/rust/comments/pqajgf/_/hdbt7qw), which should help explain the difference.
---
In @Inshi's example there is no difference between 2 and 3. You get a compiler error on 1 because it isn't valid syntax yet.<|endoftext|>When will this become stable?<|endoftext|>How async closures would be expressed as a function parameter? i feel that
```rust
fn takes_async_closure<F: Future<Output = ()>>(_: impl Fn() -> F)
```
would be too verbose, something like `AsyncFn`, `AsyncFnMut` and `AsyncFnOnce` would be better.
Also, closures that return futures don't work well when a closure parameter is a reference.<|endoftext|>What's the current status of this issue? According to the description, it says only the stabilization is left. How can one help push this to stabilization?<|endoftext|>If this feature stable, will both of these code work like same:
1. without feature
```rust
async fn sayer() {
let mut hs = Vec::new();
for n in (0..5).rev() {
hs.push(tokio::spawn(sleep_n(n)));
}
for h in hs {
h.await.unwrap();
}
}
```
2. with feature
```rust
async fn sayer() {
let mut hs = Vec::new();
for n in (0..5).rev() {
hs.push(tokio::spawn(sleep_n(n)));
}
let _ = hs.into_iter().map(async |i| i.await.unwrap());
}
```<|endoftext|>> How async closures would be expressed as a function parameter? i feel that
>
> ```rust
> fn takes_async_closure<F: Future<Output = ()>>(_: impl Fn() -> F)
> ```
>
> would be too verbose, something like `AsyncFn`, `AsyncFnMut` and `AsyncFnOnce` would be better. Also, closures that return futures don't work well when a closure parameter is a reference.
Except from these potential keywords being added for convenience, is there any reason to not add async closures?<|endoftext|>> Aren't async closures just like normal closures but without the redundant `move` keyword? As in:
>
> ```rust
> move | _ | async move { /* ... */}
> ```
>
> vs
>
> ```rust
> async move | _ | { /* ... */ }
> ```
>
> is there any other difference other than this?
The first thing is a closure which returns parameterless async block.
The second one is the actual async closure.<|endoftext|>As @Nemo157 said in [their comment](https://github.com/rust-lang/rust/issues/62290#issuecomment-538782482)
> Despite "Implement the RFC" being checked this feature is still largely unimplemented
Why is this still incorrectly marked as implemented, 4 years later? | B-RFC-approved<|endoftext|>A-closures<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>A-async-await<|endoftext|>AsyncAwait-Triaged<|endoftext|>F-async_closures<|endoftext|>requires-nightly<|endoftext|>S-tracking-needs-summary<|endoftext|>WG-async | 28 | https://api.github.com/repos/rust-lang/rust/issues/62290 | https://github.com/rust-lang/rust/issues/62290 | https://api.github.com/repos/rust-lang/rust/issues/62290/comments |
408,461,314 | 58,329 | Tracking issue for #[ffi_pure] | Annotates an extern C function with C [`pure`](https://gcc.gnu.org/onlinedocs/gcc/Common-Function-Attributes.html#Common-Function-Attributes) attribute. | This corresponds to the `readonly` LLVM attribute.<|endoftext|>Is this fully implemented and ready for potential stabilization, or is there any blocker? | A-ffi<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 2 | https://api.github.com/repos/rust-lang/rust/issues/58329 | https://github.com/rust-lang/rust/issues/58329 | https://api.github.com/repos/rust-lang/rust/issues/58329/comments |
408,461,263 | 58,328 | Tracking issue for #[ffi_const] | Annotates an extern C function with C [`const`](https://gcc.gnu.org/onlinedocs/gcc/Common-Function-Attributes.html#Common-Function-Attributes) attribute.
https://doc.rust-lang.org/beta/unstable-book/language-features/ffi-const.html | This corresponds to the LLVM `readnone` attribute.<|endoftext|>Is this fully implemented and ready for potential stabilization, or is there any blocker? | A-ffi<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 2 | https://api.github.com/repos/rust-lang/rust/issues/58328 | https://github.com/rust-lang/rust/issues/58328 | https://api.github.com/repos/rust-lang/rust/issues/58328/comments |
376,960,106 | 55,628 | Tracking issue for `trait alias` implementation (RFC 1733) | This is the tracking issue for **implementing** (*not* discussing the design) RFC https://github.com/rust-lang/rfcs/pull/1733. It is a subissue of https://github.com/rust-lang/rust/issues/41517.
## Current status
Once #55101 lands, many aspects of trait aliases will be implemented. However, some known limitations remain. These are mostly pre-existing limitations of the trait checker that we intend to lift more generally (see each case below for notes).
**Well-formedness requirements.** We currently require the trait alias to be well-formed. So, for example, `trait Foo<T: Send> { } trait Bar<T> = Foo<T>` is an error. We intend to modify this behavior as part of implementing the implied bounds RFC (https://github.com/rust-lang/rust/issues/44491).
**Trait object associated types.** If you have `trait Foo = Iterator<Item =u32>`, you cannot use the trait object type `dyn Foo`. This is a duplicate of https://github.com/rust-lang/rust/issues/24010.
**Trait object equality.** If you have `trait Foo { }` and `trait Bar = Foo`, we do not currently consider `dyn Foo` and `dyn Bar` to be the same type. Tracking issue https://github.com/rust-lang/rust/issues/55629.
## Pending issues to resolve
- [x] https://github.com/rust-lang/rust/issues/56006 - ICE when used in a library crate
## Deviations and/or clarifications from the RFC
This section is for us to collect notes on deviations from the RFC text, or clarifications to unresolved questions.
## PR history
- [x] https://github.com/rust-lang/rust/pull/45047 by @durka
- [x] https://github.com/rust-lang/rust/pull/55101 by @alexreg
## Other links
- Test scenarios drawn up by @nikomatsakis from the RFC: [gist](https://gist.github.com/nikomatsakis/e4dd2807581fc868ba308382855e68f6) | Good summary. Thanks for writing this up.<|endoftext|>Have we considered blocking stabilization on lazy normalization?
That is, I'm worried that these are equivalent problems:
```rust
trait Foo<X> {}
type Bar<X: ExtraBound> = dyn Foo<X>;
fn bad<X>(_: &Bar<X>) {}
trait Foo2<X: ExtraBound> = Foo<X>;
fn bad2<X>(_: &dyn Foo2<X>) {}
```
The alternative, to consider `Foo2` its own trait, has its own issues, IMO.<|endoftext|>@eddyb Actually, they're not, under the current implementation, which is nice. The `X: ExtraBound` bound is enforced. [Example](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=fa657352533684a9764ea1f92bf6a900).<|endoftext|>@nikomatsakis I just realised you never got around to factoring out the part of my old PR https://github.com/rust-lang/rust/pull/55994 that banned multi-trait objects via trait aliases... did you still want to tackle that? | A-traits<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>T-types<|endoftext|>S-types-deferred | 4 | https://api.github.com/repos/rust-lang/rust/issues/55628 | https://github.com/rust-lang/rust/issues/55628 | https://api.github.com/repos/rust-lang/rust/issues/55628/comments |
365,574,844 | 54,727 | Tracking issue for procedural macros and "hygiene 2.0" | This is intended to be a tracking issue for enabling procedural macros to have "more hygiene" than the copy/paste hygiene they have today. This is a very vague tracking issue and there's a *very long* and storied history to this. The intention here though is to create a fresh tracking issue to collect the current state of play, in hopes that we can close some of the much older and very long issues which contain lots of outdated information. | To give some background, `feature(proc_macro_hygiene)` tracked by this issue was merged from multiple features (`proc_macro_mod`, `proc_macro_expr`, `proc_macro_non_items`, `proc_macro_gen`) in https://github.com/rust-lang/rust/pull/52121.
So, it's pretty heterogeneous and is not even entirely about hygiene.<|endoftext|>Copypasting what I wrote in https://github.com/rust-lang/rust/pull/52121:
None of these features is blocked on hygiene, except for `proc_macro_gen`.
- `proc_macro_mod` is, IIRC, about expanding inner attributes and expanding non-inline modules (`mod foo;`). I'm not sure why `#[my_macro] mod m { ... }` with outer attribute and inline module is still gated, I'm not aware of any reasons to not stabilize it.
- `proc_macro_expr`/`proc_macro_non_items` have no reasons to be gated as well and can be stabilized after some implementation audit. Proc macros have well-defined "copy-paste" `Span::call_site()` hygiene, this includes "unhygienic" use of local variables.
IIRC, @nrc assumed that additional feature gates would prevent interactions of that copy-paste hygiene with local variables, but that's not true - you can easily expand an item and inject tokens from the outside into its body (e.g. https://github.com/rust-lang/rust/issues/50050), causing exactly the same interactions.
What is really blocked on hygiene is `Span::def_site()` and `decl_macro` (which is also blocked on a ton of other stuff).<|endoftext|>`proc_macro_gen` is more about interactions between `Span::call_site` hygiene (entirely unhygienic) and `macro_rules` hygiene (unhygienic except for local variables and labels).<|endoftext|>This looks like the right branch for this question. Sorry about copy-paste, but I really need to know.
It seems that since `rustc 1.30.0-nightly (63d51e89a 2018-09-28)` it is no longer possible to traverse code inside module in separate file. If you process `mod module;`, you get `TokenStream` containing `mod module;`, WYSIWYG.
I understand, that this is necessary in order to preserver spans, hygiene and consistency with processed code. Is there or will be any way to work with content of modules in separate files? Its lack may be confusing for end users when trivial refactoring of module organization causes change in macro behavior.<|endoftext|>@CodeSandwich
This may be a regression from https://github.com/rust-lang/rust/pull/52319 perhaps?
cc @tinco <|endoftext|>>I understand, that this is necessary in order to preserver spans, hygiene and consistency with processed code.
From what I remember, this is an open question.
The transformation `mod m;` -> `mod m { ... }` is an expansion of sorts, and we may treat it both as an early expansion (like e.g. `#[cfg]`, which is also expanded before passing the item to attribute-like macros) and as a late expansion (the item is not expanded before being passed to macros).
The "early expansion behavior" looks preferable to me, and this change in behavior looks like a bug rather than a fix.<|endoftext|>I lack some context, so I can't be certain, what exactly is "process"? If it relies on rustc's pretty printing, then yes this would be a consequence of #52319, and it should be simple to fix by changing the invocation I think. #52319 does two things:
1. Add information to the AST (a single bool, tracking if a mod is inline)
2. Make pretty print no longer print the external file if that bool is false
If you need the expanded file, then that should be made explicit in the invocation of the pretty printer.<|endoftext|>Yes, the change is likely due to the pretty-printing change.
So it can be fixed either by reverting the change, or making it more fine-grained so it prints the contents regardless of the `inline` flag if pretty-printing is done "for proc macros" (whatever that means).<|endoftext|>If you can point me at the line of code that invokes the pretty printer, I can suggest a fix.<|endoftext|>By "processing" I mean parsing TokenStream with Syn to an [Item](https://docs.rs/syn/0.15/syn/enum.Item.html#variant.Mod), modifying its content and converting it back to TokenStream. The precise spot of parsing is [here](https://github.com/CodeSandwich/Mocktopus/blob/master/macros/src/lib.rs#L98) and content traversal is [there](https://github.com/CodeSandwich/Mocktopus/blob/master/macros/src/item_injector.rs#L22). I haven't dug into implementation of Syn yet, so I can't tell for sure if it uses pretty printing. I've set `nightly` feature in Syn, which as far as I know skips step of printing and parsing the string again.<|endoftext|>I personally feel that what a proc macro receives as input tokens when attached to a module is an open questions, as @petrochenkov said. I do not think that one answer is clearly correct over another (`mod foo;` vs `mod foo { ... }`) at this time. That's why it's unstable!<|endoftext|>I'm confused why proc macros expanding to `macro_rules!` definitions is gated.
(especially when the new macros are only invoked by other expanded items)<|endoftext|>@eddyb
Well, the answer is "not enough confidence in correctness of hygiene interactions between transparent (procedural on stable) and semi-transparent (macro_rules) macros".
I hoped to at least get rid of the ["context transplantation trick"](https://github.com/rust-lang/rust/pull/51762#issuecomment-401400732) before stabilizing it, but got distracted by the edition stuff.
It generally works though, I'm not aware of any specific bugs manifesting in normal cases.<|endoftext|>`$crate` in generated macros concerns me in particular.
(I don't remember whether it works correctly now, need to test.)<|endoftext|>`rustc` pointed me to this issue because I tried to use a proc macro in a type context (`procedural macros cannot be expanded to types`), but I don't see anything about this usage in the discussion. Is this the right issue to track that feature?<|endoftext|>@dbeckwith `proc_macro_non_items` was originally introduced in #50120, and I renamed it to be part of `proc_macro_hygiene` in #52121. I reviewed several of the discussions on both PRs and discussions that led to them and can't find any actual discussion of expanding types in particular. There has been some disagreement on exactly what should still be gated or not and why, but mostly with respect to statements and expressions.
@alexcrichton -- do you remember a reason for gating expansion to types, other than "types are not items"?
@nrc -- do your concerns from https://github.com/rust-lang/rust/pull/52121#issuecomment-422311424 also apply to types, or only to expressions, statements, and presumably patterns?<|endoftext|>I'm not aware of any issues preventing stabilization of fn-like macros expanding into types.<|endoftext|>@jebrosen IIRC it's just "types weren't items" at the time, so if others agree seems like we could stabilize it!<|endoftext|>Since this tracking issue touches on procedural macros involving `mod` and spans -- I filed https://github.com/rust-lang/rust/issues/58818 which seems to involve `mod` and spans. Basically the following two currently behave differently, which seems wrong:
```rust
mod parent {
mod child;
}
```
```rust
mod parent {
noop! { mod child; }
}
```
where `noop!` is a procedural macro implemented as:
```rust
#[proc_macro]
pub fn noop(input: TokenStream) -> TokenStream {
input
}
```<|endoftext|>Is there a plan to get function-like macros to work in expression or statement positions? From looking at https://github.com/rust-lang/rust/pull/52121#issuecomment-422311424, I understand that there are hygiene concerns, but is there a plan to either resolve or dispel those concerns?<|endoftext|>Full list of what the `proc_macro_hygiene` feature controls (see ~~`src/libsyntax/ext/expand.rs`~~ `src/librustc_expand/expand.rs`):
* Applying an attribute proc_macro to:
* Any input containing non-inline modules (`mod x;`)
* Gated because of unclear or undecided expansion behavior of non-inline modules https://github.com/rust-lang/rust/issues/54727#issuecomment-426192109
* A statement or an expression
* Aside from the expansion concerns below, I vaguely remember a question along the lines of "how much of the expression the macro applies to" in something like
```
#[expr_macro] a / b;
```
Update (2019-10-02): Link to relevant stabilization PRs.
Update (2020-01-31): Update links and stabilization statuses.
Update (2020-06-18): Reworked the list entirely, since `proc_macro` application and expansion is now stabilized in most positions.<|endoftext|>I believe we should stabilize almost all of `proc_macro_hygiene` with the exception of the following (for the reasons outlined in @jebrosen's post above):
* Applying attributes to non-inline modules.
* Applying macros to expressions.
* Expansion to macro definitions containing `$crate`.
* Expansion to patterns.
In particular, we should stabilize the following:
* Applying attributes to inline modules.
* Applying attributes to statements.
* Expansion to types, expressions, statements, and macro definitions without `$crate`.
The first two cases have clear semantics with no notable concerns for stabilization; their lack of stabilization seems to be largely due to a lack of demand. The lattermost case is more interesting: there are valid concerns regarding hygiene with expansion to some of these kinds, in particular statements and expressions, but they are largely resolvable post-stabilization via hygiene defaults in external libraries (i.e, `syn` and `quote`). What's more, the gated functionality is already possible today (i.e, [`proc-macro-hack`](https://github.com/dtolnay/proc-macro-hack)): the instability of the lattermost case is not preventing what it aims to, and as such, does not benefit from being unstable. As a result, stabilization only makes what is possible today more convenient.
Again, I believe we should stabilize almost all of `proc_macro_hygiene`. This is the final feature gate preventing Rocket from compiling on stable.<|endoftext|>Some status update.
Macro expansion infrastructure is being steadily simplified and bug-fixed right now, filling in the "20%" part of the implementation.
I want to complete some of this infrastructural work before further increasing the stable surface.
The current blocker is https://github.com/rust-lang/rust/pull/63468 worked on by @c410-f3r.
After this PR lands I'm going to rewrite something called invocation collector, and after that we'll be able to start stabilizing confidently.
Everything in https://github.com/rust-lang/rust/issues/54727#issuecomment-523307027 is stabilize-able, with exception of attributes on expressions/statements which have a number of unresolved questions.<|endoftext|>Regarding the timing - I'd say vaguely this year.
Note, that these features are not on the roadmap, so we are unlikely to get some quick-and-dirty stabilizations like Macros 1.1.
**STATUS UPDATE:** Due to a job change I have several times less time to work on this, but the progress is still happening.<|endoftext|>@petrochenkov
> Everything in [#54727 (comment)](https://github.com/rust-lang/rust/issues/54727#issuecomment-523307027) is stabilize-able, with exception of attributes on expressions/statements which have a number of unresolved questions.
Are you saying that everything in my comment is stabilize-able _now_ or after the changes you're hoping to make? I am advocating for stabilization of the subset of features _now_ on the basis presented in my comment, in particular, that this functionality is largely already possible today and thus stabilization does not significantly expose a greater surface.
<|endoftext|>@SergioBenitez
Some subset can be stabilized right now, I've opened https://github.com/rust-lang/rust/pull/63931 for it.
---
Proc macros expanding into `macro_rules` can be stabilized right now too, but for a different reason.
Unfortunately they were never gated in derive macros (and we couldn't do that during Macro 1.2 stabilization as well due to some real breakage), so people in practice just use derives to ignore the feature gate and generate them.
So, if we ever change some hygiene rules in them it will affect people to the same extent anyway.
I'll make a separate stabilization PR for them, I need to check a couple of things before that.<|endoftext|>Stabilization PR for proc macros generating `macro_rules` - https://github.com/rust-lang/rust/pull/64035.<|endoftext|>@petrochenkov Given the existence of [`proc-macro-hack`](https://github.com/dtolnay/proc-macro-hack) and [`proc-macro-nested`](https://docs.rs/proc-macro-nested/0.1.3/proc_macro_nested/), why not also stabilize expansion to expressions? This would be the final blocker to Rocket on stable.<|endoftext|>>why not also stabilize expansion to expressions?
https://github.com/rust-lang/rust/pull/63931#issuecomment-526367570
(I'd personally be ready to stabilize after some implementation audit and gating of sub-features with known issues, as I already said back in October - https://github.com/rust-lang/rust/issues/54727#issuecomment-426008711.)<|endoftext|>@SergioBenitez
>This would be the final blocker to Rocket on stable.
By the way, what prevents Rocket from using proc-macro-hack for migrating to stable?
What are the cases in which unstable macros are qualitatively more powerful than proc-macro-hack? | A-macros<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>A-proc-macros<|endoftext|>S-tracking-needs-summary | 44 | https://api.github.com/repos/rust-lang/rust/issues/54727 | https://github.com/rust-lang/rust/issues/54727 | https://api.github.com/repos/rust-lang/rust/issues/54727/comments |
365,570,145 | 54,724 | Tracking issue for `Span::def_site()` | This is a tracking issue for the `Span::def_site()` API. The feature for this is `proc_maro_def_site`. The `def_site` span primarily relates to hygiene today in that it's *not* copy-paste hygiene.
This is likely blocked on larger hygiene reform and more thorny Macros 2.0 issues. I'm not personally clear on what the blockers are at this time, but I wanted to make sure we had a dedicated tracking issue!
cc https://github.com/rust-lang/rust/issues/45934 | This is likely highly related to https://github.com/rust-lang/rust/issues/54727 as well<|endoftext|>Hygiene serialization was implemented in https://github.com/rust-lang/rust/pull/72121. This ensures that items with def-site hygiene are not visible from another crate.<|endoftext|>What's this blocked on?<|endoftext|>This needs more tests, especially for cross-crate cases. Any bugs found from that would have to be fixed and any unexpected behavior would need to be reviewed.<|endoftext|>It would be helpful to understand what `def_site` means, at least in the general terms. I get a type error when thinking about this -- proc macro definition side is in a crate that is compiled for `$host`, so in the `$target` (where we actually expand the macro), this span doesn't exist, no?
EDIT: based on my reading of https://github.com/rust-lang/rust/pull/68716, I think what def_side does for proc macros is essentially introducing a fresh hygiene context. For macro rules, it would also make def-site names available, but for proc-macros def-site is essentially empty.<|endoftext|>Reviewed this in our @rust-lang/lang backlog bonanza. We are tagging this as "needs summary" because, while we'd love to see this stabilized, most of us weren't really sure what "def-site" was supposed to mean -- i.e., this needs more than new tests, we need some kind of docs about the intended effect that can be reviewed.<|endoftext|>I'm a noob, but recently while experimenting with proc_macro I discovered a specific circumstance where def_site works and call_site doesn't. [Here is the repo](https://github.com/winksaville/expr-proc-macro-def-site).
I created 3 proc_macro's. In `inner_using_outer_declarations_via_fn` where I create `do_something` using `Span::def_site()` and in `inner_using_outer_declarations_via_temp` I create `temp` using `Span::call_site()`. Then in `outer` I invoke the two `inner_*` macros twice.
```
use proc_macro::TokenStream;
use proc_macro2::{Ident, Span};
use quote::quote;
#[proc_macro]
pub fn inner_using_outer_declarations_via_fn(_input: TokenStream) -> TokenStream {
//let do_something = Ident::new("do_something", Span::call_site()); // Enabling causes compile error
let do_something = Ident::new("do_something", Span::def_site());
quote!(
println!("inner_using_outer_declarations_via_fn:+ a={}", a);
fn #do_something(a: i32) -> i32 {
a + 1
}
a = #do_something(a);
println!("inner_using_outer_declarations_via_fn:- a={}", a);
)
.into()
}
#[proc_macro]
pub fn inner_using_outer_declarations_via_temp(_input: TokenStream) -> TokenStream {
let temp = Ident::new("do_something", Span::call_site());
quote!(
println!("inner_using_outer_declarations_via_temp:+ a={}", a);
let #temp = a + 1;
a = #temp;
println!("inner_using_outer_declarations_via_temp:- a={}", a);
)
.into()
}
#[proc_macro]
pub fn outer(_input: TokenStream) -> TokenStream {
let q = quote! {
let mut a = 10;
inner_using_outer_declarations_via_fn!();
inner_using_outer_declarations_via_temp!();
inner_using_outer_declarations_via_fn!();
inner_using_outer_declarations_via_temp!();
};
//println!("outer: q={:#?}", q);
q.into()
}
```
In `main.rs` I simply invoke `outer`:
```
use expr_proc_macro_def_site::{
inner_using_outer_declarations_via_fn, inner_using_outer_declarations_via_temp, outer,
};
fn main() {
outer!();
}
```
Running the code works, but you must compile with `procmacro2_semver_exempt` to enable `def_site` :
```
$ RUSTFLAGS='--cfg procmacro2_semver_exempt' cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/expr-proc-macro-def-site`
inner_using_outer_declarations_via_fn:+ a=10
inner_using_outer_declarations_via_fn:- a=11
inner_using_outer_declarations_via_temp:+ a=11
inner_using_outer_declarations_via_temp:- a=12
inner_using_outer_declarations_via_fn:+ a=12
inner_using_outer_declarations_via_fn:- a=13
inner_using_outer_declarations_via_temp:+ a=13
inner_using_outer_declarations_via_temp:- a=14
```
If you change `do_something` to use `call_site` instead:
```
pub fn inner_using_outer_declarations_via_fn(_input: TokenStream) -> TokenStream {
let do_something = Ident::new("do_something", Span::call_site()); // Enabling causes compile error
//let do_something = Ident::new("do_something", Span::def_site());
```
We now get compile errors, because there are multiple definitions of `do_something`. So for hygiene, when there can be multiple definitions of an identifier, `def_site` is needed.
```
$ cargo run
Compiling expr-proc-macro-def-site v0.1.0 (/home/wink/prgs/rust/myrepos/expr-proc-macro-def-site)
error[E0428]: the name `do_something` is defined multiple times
--> src/main.rs:6:5
|
6 | outer!();
| ^^^^^^^^
| |
| `do_something` redefined here
| previous definition of the value `do_something` here
|
= note: `do_something` must be defined only once in the value namespace of this block
= note: this error originates in the macro `inner_using_outer_declarations_via_fn` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0618]: expected function, found `i32`
--> src/main.rs:6:5
|
6 | outer!();
| ^^^^^^^^
| |
| call expression requires function
| `do_something` has type `i32`
|
= note: this error originates in the macro `inner_using_outer_declarations_via_fn` (in Nightly builds, run with -Z macro-backtrace for more info)
Some errors have detailed explanations: E0428, E0618.
For more information about an error, try `rustc --explain E0428`.
error: could not compile `expr-proc-macro-def-site` due to 2 previous errors
```
I'm positive what I've pointed out is known by most people looking at this issue, but for those that aren't experts this might be clarifying. Something like this could be added to the documentation. I'm willing to provide a PR after getting feedback. | E-needs-test<|endoftext|>A-macros<|endoftext|>T-lang<|endoftext|>T-libs-api<|endoftext|>B-unstable<|endoftext|>A-macros-2.0<|endoftext|>C-tracking-issue<|endoftext|>A-proc-macros<|endoftext|>Libs-Tracked<|endoftext|>S-tracking-needs-summary | 7 | https://api.github.com/repos/rust-lang/rust/issues/54724 | https://github.com/rust-lang/rust/issues/54724 | https://api.github.com/repos/rust-lang/rust/issues/54724/comments |
365,568,479 | 54,722 | Tracking issue for the `quote!` macro in `proc_macro` | I'm splitting this off https://github.com/rust-lang/rust/issues/38356 to track the `quote!` macro specifically contained in `proc_macro`. This macro has different syntax than the [`quote` crate](https://crates.io/crates/quote) on crates.io but I believe similar functionality. At this time it's not clear (to me at least) what the status of this macro is in terms of how much we actually want to stabilize it or what would block its stabilization. Others are welcome to fill this in though! | Ah, and this is also tracking the `proc_macro_quote` feature.<|endoftext|>We need to avoid `.clone()`-ing the variables interpolated by `quote!`, we should have `&T -> TokenStream` (or, better, an append taking `&T, &mut TokenStream`, like the `quote` crate).
**EDIT**: thinking more about it, I think we should support `TokenStream`, all the `proc_macro` types that convert to `TokenStream`, including references of all of those, and, on top of that, anything that `.extend(...)` on a `TokenStream` would take (I haven't checked, do we implement `Extend` for it?).
<hr/>
I don't like `$$` used for escaping `$`, I'd prefer if `\$` was used (we could make `$$` an error for now).
We should make sure we error on `$(...)` even if we don't start supporting repetition syntax right away, to reserve the right to do so in the future.
And maybe we should consider `${...}` for nesting expressions, but, again, as long as any unsupported syntax that starts with `$` errors, we can extend it later.
<hr/>
There's also the question of what to do about spans. The `quote` crate has a version of the macro that also takes `Span`, but I'd prefer pointing to the proc macro source where `quote!` was used.
For this, we can use an unstable `Span` constructor that takes a `SourceFile` reference and a byte range into that, and an unstable constructor for `SourceFile` that provides all the per-file `SourceMap` information (file path, expected content hash, line map, etc.) the compiler needs.
Making def-site hygiene also work would be trickier, but not impossible AFAIK.
cc @petrochenkov <|endoftext|>I just tried this out and `$a` quoting doesn't seem to work at all. It doesn't even error on `$#` like I'd expect from the source.<|endoftext|>Oh nevermind, I was using it wrong.<|endoftext|>> I don't like `$$` used for escaping `$`, I'd prefer if `\$` was used (we could make `$$` an error for now).
Yes please.<|endoftext|>I'm wondering what the reasoning is behind the preference for `\$` over `$$`.
Is it purely a syntactic style preference? Or is there more to it?
I ask because as I see it (but without announcing a preference either way), `$$` has the advantage of being easier to type for pretty much everyone, while it has the disadvantage of being less easy to read for e.g. people with dyslexia. <|endoftext|>@jjpe As I see, there are two main reasons: 1) easier to read (can be picked out at a glance with less difficulty), 2) agrees with long-established convention of backslash escapes (beginning with C I think, but existing in most current languages for strings, including Rust).
Furthermore, it will probably be more common to escape `$` than it will be to escape `\` in macros.<|endoftext|>@alexreg, main advantage of `$$` is that it does not need another special character. In this case there is only one, so adding another doubles the complexity. If there were more special characters, a common escape would make sense, but in this case there is only one and most of the languages that have only one special character escape it by doubling it.<|endoftext|>@jan-hudec That's not a real advantage to me. There's no additional complexity, when you already have all of those chars in the syntax. And I think the two reasons I gave above are more pertinent.<|endoftext|>is this `quote!` as fully-featured as the one in [crates.io quote](https://crates.io/crates/quote) ? I cannot figure out how to do e.g. [repetition](https://crates.io/crates/quote#user-content-repetition) with it<|endoftext|>@pnkfelix It's not. See also https://github.com/dtolnay/request-for-implementation/issues/8#issuecomment-458760269.<|endoftext|>I'm kind of confused here: why would we want to pursue adding an inferior solution to the stdlib if a superior one exists as a crate?<|endoftext|>One other difference besides repetitions and `$` vs `#` is that the external quote is unit testable -- the proc_macro quote produces a proc_macro::TokenStream which can only exist within the context of a procedural macro, so any functions or helper libraries that you write using proc_macro quote will panic when called from a unit test.
(I don't have an opinion about whether proc_macro needs to provide a quote macro, just pointing out one other consideration that has not been brought up yet. It would be nice to fix this before stabilizing something.)<|endoftext|>I see. I struggle to understand why the `proc_macro` crate is only accessible from within proc macro crates though -- it gives rise to what I see as an unfortunate need for the proc_macro2 crate, and creates a problem with testing, not to mention the issue @dtolnay just pointed out above.<|endoftext|>It's accessible in other crates as a library, see also #57288. The
attributes to define proc macros are not.
On Wed., Jan. 30, 2019, 23:35 Alexander Regueiro <[email protected]
wrote:
> I see. I struggle to understand why the proc_macro crate is only
> accessible from within proc macro crates though -- it gives rise to what I
> see as an unfortunate need for the proc_macro2 crate, and creates a problem
> with testing, not to mention the issue @dtolnay
> <https://github.com/dtolnay> just pointed out above.
>
> —
> You are receiving this because you commented.
> Reply to this email directly, view it on GitHub
> <https://github.com/rust-lang/rust/issues/54722#issuecomment-459211850>,
> or mute the thread
> <https://github.com/notifications/unsubscribe-auth/AT4HVWZ8uxcYVj2UiLTmrMkWt01HuVWKks5vInKKgaJpZM4XCjad>
> .
>
<|endoftext|>I believe @dtolnay is referring to the fact that the API itself will panic if used outside of the *execution* of a proc macro by a compiler, because it doesn't contain an implementation of the API, only the logic to talk to a "server" of such an implementation.
Some have suggested having a default "server" (loopback, if you will), which behaves just like proc-macro2's polyfills and allows using `proc_macro` at all times, and I'm not really opposed to that.<|endoftext|>@eddyb Yes, that’s what I’d like to see too. @acrichton thoughts on the above?<|endoftext|>Ah, I see. It surprises me somewhat that all of the implementation is provided by ABI rather than a more detailed in-Rust implementation with less reliance on the ABI.<|endoftext|>@alercah (Sorry for delayed response, I'm clearing out my notifications)
If we were to provide an implementation of the `proc_macro` API in `proc_macro` itself, we would have to move a significant chunk of the compiler frontend in there, and expose a lot of the fiddly details.
And it would be fine-tuned for rustc in particular, while at the same time forcing the proc macro token model onto rustc (might not be a bad thing, but we're not there yet).
With the RPC(-like) approach, a frontend can supply its own implementation, for any particular invocation.
Some projects are already using this capability to run proc macros outside of rustc.<|endoftext|>Aside from the issue regarding interpolation noted above, what's holding up stabilization here?<|endoftext|>`quote!` currently uses macro 2.0 hygiene, so either macro 2.0 hygiene needs to be stabilized first, or `quote!` needs to be migrated to weaker hygiene (e.g. `Span::mixed_site`).<|endoftext|>Regarding the hygiene, there has just been an example of a user being confused by this never-seen-elsewhere `Span::def_site()`: https://stackoverflow.com/a/66302653/10776437
I don't know if weakening the hygiene is necessary, but at the very least a way to choose another transparency (_e.g._, opt into `::quote::quote_spanned!(Span::mixed_site() =>`-like behavior) would be desirable.<|endoftext|>How does this interact with `macro_rules!` interpolation? Specifically, both use `$`, so which is given precedence? I haven't tried this, but it's something that should be clearly documented either way.<|endoftext|>Is there any progress on this issue? It seems like a good candidate given recent efforts to reduce compile times due to proc macros and extremely complicated inline macros (of which `quote::quote!` is definitely a major example).
Have we considered making a `min_proc_macro_quote` issue that could get implemented without having to solve hygiene? <|endoftext|>Lang briefly discussed this in backlog bonanza today and we'd like to see a summary of the outstanding blockers or expectations here.
I think the thread so far has pointed out:
* def_site/macros 2.0 hygiene
* Do we actually need quote in the in-tree proc_macro?
But it'd be useful to get a summary from folks more familiar on the blockers for stabilization (or removal, if we feel that's better).<|endoftext|>I’ve stumbled upon this interesting case:
```rust
fn main() {
let expr: syn::Expr = syn::parse_str("2 + 2").unwrap();
let quoted = quote::quote! {
let foo = &#expr;
};
println!("{quoted}"); // & 2 + 2
}
```
I think that’s not ideal (e.g. it differs from `macro_rules!` behaviour) and that if `quote!()` is to be added to the standard library, this issue warrants some consideration.
UPD:
Since `proc_macro` doesn’t have anything like `Expr`, it’s probably a documentation issue. Downstream implementors of types that can be used inside of `quote!()` choose their token representation.<|endoftext|>Can `proc_macro::quote` always quote `proc_macro2::TokenStream`s? From a quick test it looks like the answer is yes, but I'm not sure whether this is guaranteed or if there are limitations.
Looks like it only returns `proc_macro::TokenStream`, which isn't unexpected. It would be really nice, and probably more efficient, if there was a way for it to do `TokenStream2` -> `TokenStream2` quoting. But this of course probably isn't possible.
Edit: or, I guess that the nicer long term solution would be to make `proc_macro` usable outside of proc macros, which woulld eliminate the need for `proc_macro2` | A-macros<|endoftext|>T-lang<|endoftext|>T-libs-api<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>Libs-Tracked<|endoftext|>S-tracking-needs-summary | 27 | https://api.github.com/repos/rust-lang/rust/issues/54722 | https://github.com/rust-lang/rust/issues/54722 | https://api.github.com/repos/rust-lang/rust/issues/54722/comments |
362,941,542 | 54,503 | Tracking issue for RFC 2383, "Lint Reasons RFC" | This is a tracking issue for the RFC "Lint Reasons RFC" (rust-lang/rfcs#2383).
**Steps:**
- [x] Implement the RFC (cc @rust-lang/compiler -- can anyone write up mentoring instructions?)
- [x] Implement `reason =` #54683
- [x] Implement `#[expect(lint)]` -- see https://github.com/rust-lang/rust/issues/85549
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- [ ] The use sites of the reason parameter. | I started looking at this tonight. (Briefly; I regret that my time is limited.)
The example output in the RFC puts a `reason:` line immediately below the top-level `error:` line, but from a consilience-with-the-existing-implementation perspective, I'm inclined to think it would make more sense to use an ordinary `note:` (just as the existing "#[level(lint)] on by default" messages and [must-use rationales](https://github.com/rust-lang/rust/pull/49533) do).
The reason should probably be stored as a third field inside of [`LintSource::Node`](https://github.com/rust-lang/rust/blob/8a92ebfb59263bc678dcae5de5568776cb172c6e/src/librustc/lint/mod.rs#L473).<|endoftext|>PR for `reason =` is #54683.
> Unresolved questions:
>
> - [ ] The use sites of the reason parameter.
@myrrlyn I'm not sure what "use sites" means in this context?<|endoftext|>It's a little bit sad/awkward that reason comments are most useful in practice for `allow` (rather than `warn`, `deny`, or `forbid`, which authors are more likely to regard as self-explanatory), and yet `allow` is the only case for which the new `reason =` functionality doesn't actually do anything. :crying_cat_face:
(This observation prompted by my thought that we should be able to dogfood `reason =` in this repo now that that functionality is in the beta bootstrap compiler, but `ag '//.*\n\w*#\[(warn|deny|forbid|allow)' --ignore tools --ignore test` only turns up instances of `allow`.)<|endoftext|>We could add a lint that suggests turning `allow` with `reason` into `expect` because `$reasons`<|endoftext|>I apologize for my absence on this issue.
> I'm not sure what "use sites" means in this context?
My standing question was "how should the `reason` value be used in the diagnostic", and it appears that the simplest answer is the one you provided: "put it in a `note` item". I have no firm attachment to rendering it as `reason: User text here`, and if prior art exists for `note: User text here`, then that is perfectly fine.<|endoftext|>Here's the initial work of `expect` lint level: https://github.com/JohnTitor/rust/tree/lint-expect
The remaining thing is to trigger the `expectation_missing` lint but I have no idea how to implement. If someone could do, feel free to steal something from there. Or I'm happy to continue the work if someone could mentor me :)<|endoftext|>Hello everyone,
I would like to work on the `expect` attribute and move this issue towards stabilization.
Is there someone here who could mentor me? My contributions so far have only focussed on Clippy. If not I would most likely ask on Zulip for help :upside_down_face:.<|endoftext|>@xFrednet I would happily mentor you on this! Let me start by opening an issue dedicated to jus the implementaton, since I dislike using the tracking issue for that sort of thing. I'll assign it to you.<|endoftext|>Issue #55112 is related to the implementation of the `reason` field. The current implementation apparently allows the usage of an attribute with only a reason `#[allow(reason = "foo")]`. Source:
> ```rust
> // FIXME (#55112): issue unused-attributes lint if we thereby
> // don't have any lint names (`#[level(reason = "foo")]`)
> ```
[Noted as a FIXME in the `LintsLevelBilder`](https://github.com/rust-lang/rust/blob/9d15abe0cc3f8d5dc73c6acc829ca66e1eebaf60/compiler/rustc_lint/src/levels.rs#L255-L256)
Just to keep track that this also has to be fixed before stabilization.
PR: https://github.com/rust-lang/rust/pull/94580<|endoftext|>Hey, while implementing the `expect` attribute in rust-lang/rust#87835 I came across a discussion in the RFC suggestion to change the `expect` attribute name to something else. (Initiated by `@Ixrec` https://github.com/rust-lang/rfcs/pull/2383#issuecomment-378424091 and the suggestion from `@scottmcm` to use #[should_lint(...)] https://github.com/rust-lang/rfcs/pull/2383#issuecomment-378648877). No real conclusion was drawn on that point from my understanding. Is the name `expect` the final name that should be used, or is this still something that needs to be discussed?
At first, I was a bit skeptical of the name, but now I really like it. Therefore, I would just leave it as it is :upside_down_face: <|endoftext|>Changing the name can be some before stabilization, so imo you can just roll with `expect`<|endoftext|>We reviewed this as part of our @rust-lang/lang team "backlog bonanza" meeting today. Now that @xFrednet's PR is landed, it seems like this is ready for stabilization? (Except that we don't have any docs...)
If so, we'd love to see somebody prepare a [stabilization report](https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#write-a-stabilization-report) and [open a PR to stabilize](https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr) (contra what that page says, I prefer the stabilization report to be attached to the PR).<|endoftext|>On a personal note, I'm excited to use this :) <|endoftext|>The implementation currently still has an ICE #95540 and doesn't catch some lint emissions in some very specific cases (There is no issue for that). Both of these items are still on my todo list, but I sadly didn't have the time to address them. So, it's sadly not quite ready yet.
Once those issues are solved, I wanted to write the documentation and propose stabilizing it. I've done some testing in Clippy, by swapping almost every `#[allow]` attribute with `#[expect]` and I'm happy to report that everything works great for us. I would also really like to see this on stable :upside_down_face:
> On a personal note, I'm excited to use this :)
Thank you very much!
If it's alright, I would ping you, once the remaining issues have been solved :upside_down_face: <|endoftext|>Also, even if that's not directly a blocker, it would be good if Clippy had some more time to investigate the impact of the expect attribute. @Jarcho has started a [conversation](https://rust-lang.zulipchat.com/#narrow/stream/257328-clippy/topic/Handling.20.60.23.5Bexpect.5D.60/near/281632464) in Clippy's zulip channel. I will have this addressed in the next Clippy meeting. :upside_down_face: <|endoftext|>#98507 should address the last missing NITs from the `#[expect]` implementation. I'll now start working on the documentation and create a stabilization report, once the last PRs are merged. (https://github.com/rust-lang/rust/pull/98507, https://github.com/rust-lang/rust-clippy/pull/9046)<|endoftext|># Stabilization Report RFC 2383
Hey everyone, with the `#[expect]` implementation done, I'd like to propose stabilizing this feature. I've crated two stabilization PRs, one updating the documentation and one removing the feature from rustc:
* #99063
* https://github.com/rust-lang/reference/pull/1237
## Summary
The RFC 2383 adds a `reason` parameter to lint attributes and a new `#[expect()]` attribute to expect lint emissions.
* Here is an example how the reason can be added and how it'll be displayed as
part of the emitted lint message ([Playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=055842420ebb85afa439ff960ec1a45c)):
```rust
#![feature(lint_reasons)]
fn main() {
#[deny(unused_variables, reason = "unused variables, should be removed")]
let unused = "How much wood would a woodchuck chuck?";
}
```
<details>
<summary>See Output</summary>
```text
error: unused variable: `unused`
--> src/main.rs:5:9
|
5 | let unused = "How much wood would a woodchuck chuck?";
| ^^^^^^ help: if this is intentional, prefix it with an underscore: `_unused`
|
= note: unused variables, should be removed
note: the lint level is defined here
--> src/main.rs:4:12
|
4 | #[deny(unused_variables, reason = "unused variables, should be removed")]
| ^^^^^^^^^^^^^^^^
```
</details>
* Here is an example, that fulfills the expectation and compiles successfully ([Playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=dd6dd677c432f4a3ceea4c0c22b7e09c)):
```rust
#![feature(lint_reasons)]
fn main() {
#[expect(unused_variables, reason = "WIP, I'll use this value later")]
let message = "How much wood would a woodchuck chuck?";
#[expect(unused_variables, reason = "is this unused?")]
let answer = "about 700 pounds";
println!("A: {answer}")
}
```
<details>
<summary>See Output</summary>
```text
warning: this lint expectation is unfulfilled
--> src/main.rs:4:14
|
6 | #[expect(unused_variables, reason = "is this unused?")]
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unfulfilled_lint_expectations)]` on by default
= note: is this unused?
```
</details>
## Tests
* [`test/ui/lint/rfc-2383-lint-reason`](https://github.com/rust-lang/rust/tree/master/src/test/ui/lint/rfc-2383-lint-reason)
All tests for `#[expect]` in rustc.
More test files for tool lints can be found here:
* [`src/test/rustdoc-ui/expect-tool-lint-rfc-2383.rs`](https://github.com/rust-lang/rust/tree/master/src/test/rustdoc-ui/expect-tool-lint-rfc-2383.rs)
* [`src/tools/clippy/tests/ui/expect_tool_lint_rfc_2383.rs`](https://github.com/rust-lang/rust/tree/master/src/tools/clippy/tests/ui/expect_tool_lint_rfc_2383.rs)
* Clippy was also used as a test: https://github.com/rust-lang/rust-clippy/pull/8797
* [`src/test/ui/lint/reasons.rs`](https://github.com/rust-lang/rust/blob/a9e13fa5533df7fc004aeab00d45822eacb8461e/src/test/ui/lint/reasons.rs)
Contains tests for the `reason` information in lint emissions
* [`src/test/ui/lint/reasons-erroneous.rs`](https://github.com/rust-lang/rust/blob/1cdc81bdc109dab9a71108201a0e8edf24efeafa/src/test/ui/lint/reasons-erroneous.rs)
Contains several checks testing the syntax and the related messages if the reason declaration is incorrect.
## Changes from the RFC
As part of my implementation, I renamed the `#[expect]` lint from `expectation_missing` to `unfulfilled_lint_expectations`. I think the name works better with other lint attributes and is more descriptive.
## Resolutions of unresolved questions
1. Where should the `reason` parameter be allowed?
* The current implementation only allows it as the last parameter in all lint attributes
2. How should `#[expect(unfulfilled_lint_expectations)]` be handled?
* In the RFC, it was suggested that the `unfulfilled_lint_expectations` can be expected by outer attributes. However, it was also questioned how useful this would actually be. The current implementation doesn't allow users to expect this lint. For `#[expect(unfulfilled_lint_expectations)]` the lint will be emitted as usual, with a note saying that `unfulfilled_lint_expectations` can't be expected.
3. How should `#[expect(XYZ)]` and `--force-warn XYZ` work?
* This implementation, will emit the lint XYZ, as the lint level has been defined by `--force-warn` and also track the expectation as it usually would with only the `#[expect]` attribute. See: [`force_warn_expected_lints_fulfilled.rs`](https://github.com/rust-lang/rust/blob/8527a3d36985bed55de1832c3c1f3d470720bb0b/src/test/ui/lint/rfc-2383-lint-reason/force_warn_expected_lints_fulfilled.rs) and [`force_warn_expected_lints_unfulfilled.rs`](https://github.com/rust-lang/rust/blob/8527a3d36985bed55de1832c3c1f3d470720bb0b/src/test/ui/lint/rfc-2383-lint-reason/force_warn_expected_lints_unfulfilled.rs)
## Open issues
* `#[expect(lint)]` currently doesn't work on macros. This is in line with other lint attributes. This bug is tracked in #87391 and tested in [`expect_lint_from_macro.rs`](https://github.com/rust-lang/rust/blob/a9bf9eaef5165067414b33777a2c924e42aab5aa/src/test/ui/lint/rfc-2383-lint-reason/expect_lint_from_macro.rs#L26)
<|endoftext|>This does not seem to address the unresolved question regarding the name of the attribute. `#[expect]` is in my opinion too generic of a name. You for example might want to use `expect` on tests or maybe even normal functions to check for pre- and post-conditions: `#[expect(arg > 0)]`. Also I could see `expect` on branches where you want to annotate the branch that you expect to be taken (for optimization purposes). For a niche attribute like this, `should_lint` seems more descriptive and doesn't collide with other uses for a generic name such as `expect`.<|endoftext|>In reviewing the documentation PR, I was a bit confused by the behavior of:
```rust
#![feature(lint_reasons)]
#![expect(unused_variables)]
pub fn f() {
#![warn(unused_variables)]
let x = 1;
}
```
This not only generates the `unused_variables` lint, but *also* generates the `unfulfilled_lint_expectations` lint. Why would changing the level (with `warn`, `forbid`, or `deny`) after the `expect` attribute cause it to be unfulfilled? The `unused_variables` lint *is* being generated, so why would it not be fulfilled?
<|endoftext|>> This does not seem to address the unresolved question regarding the name of the attribute.
True, I've asked in PRs etc what others thought and in general, it was a: "let's keep it like this for now". At first, I also was a bis skeptical and favored a name like `#[expect_lint()]`. But by now I prefer `#[expect]`. That is just my opinion though, so I'm open to other suggestions and a related discussion :upside_down_face:
---
> In reviewing the documentation PR, I was a bit confused by the behavior of:
The `#[expect]` attribute works like every other lint attribute. This is how the RFC described it:
> This RFC adds an `expect` lint attribute that functions identically to `allow`, but will cause a lint to be emitted when the code it decorates does not raise a lint warning.
To me, it would be weird, if the `#[expect]` attribute would be the only attribute that has an effect after other lint attribute. (Besides `forbid`, which overrides other attributes, but also issues a warning.) The way I think of it is, that the expectation is only fulfilled if it actually suppressed a lint emission.
In the given example, the intention of the user seems to be expecting an unused value somewhere, but if `x` is unused, the user wants to be warned. Since the user wishes to be warned about `x` it shouldn't fulfill the expectation IMO. Does that make sense, or do you have another perspective? :upside_down_face: <|endoftext|>I think the RFC is somewhat vague on how it works. I would interpret it as: `expect` can be placed anywhere `allow` can, and applies to anything below it, and is only fulfilled if a warning or error would otherwise be emitted.
It seems that the actual behavior is: `expect` is a level, and enables the lint, and changing the level will disable the `expect`?
> The way I think of it is, that the expectation is only fulfilled if it actually suppressed a lint emission.
That doesn't seem to be a complete description of how it works. For example:
```rust
#[expect(unsafe_code)]
pub fn f() {
unsafe {
}
}
```
Here, the `unsafe_code` lint isn't emitted because it is "allow" by default. Nothing is being suppressed. Yet, this is fulfilling the expectation.
I think my fundamental disconnect here is that `expect` is a level, and that's not what I would ...anticipate... it to be. My mental model of levels is that they go from low (allow) to high (forbid). `expect` doesn't seem to fit in that continuum.
This isn't a strong objection because the current design is likely serviceable. I just think it is a bit more difficult to describe, and I want to make sure everyone clearly understands how it works and interacts with existing language elements.
<|endoftext|>Now I fully understand the confusion. A level like implementation feels natural to me, but I've also implemented it, so take that with a grain of salt.
I feel like the hierarchy still (kind of) works. A lint expectation is basically an allow, which is stricter (as it requires the lint emission), but at the same time less than a warning as it usually suppresses a lint emission. `#[expect]` can be used for allowed lints, but I would expect very few users to do so.
Is there a good place where we could potentially get some more feedback from others? :upside_down_face: <|endoftext|>Hey @ehuss, do you know how we should/can proceed with this?<|endoftext|>I think you'll just need to wait for the lang team to respond and start an FCP. I think there are two concerns that have been raised that they'll need to make a decision on:
* The name `expect` may not be too generic: https://github.com/rust-lang/rust/issues/54503#issuecomment-1179570739
* The behavior of `expect` being a "level" which both enables a lint, and suppresses it, and which can be overridden but other lint controls seems surprising to me: https://github.com/rust-lang/rust/issues/54503#issuecomment-1180773121
Neither issue seems particularly major, but I think they should at least acknowledge and address whether they want to continue, or would like to see changes.
<|endoftext|>I really like this feature! It motivates me to enable more lints, for example clippy's family of cast lints, which helped solve real bugs in my application, while elsewhere I can use `expect` to better document invariants.
For example
```Rust
let [r, g, b] = egui::color::rgb_from_hsv((f32::from(byte) / 288.0, 1.0, 1.0));
#[expect(
clippy::cast_possible_truncation,
clippy::cast_sign_loss,
reason = "Ranges are in 0-1, they will never be multiplied above 255"
)]
Color::rgb((r * 255.0) as u8, (g * 255.0) as u8, (b * 255.0) as u8)
```
Here I document the invariant that `r` `g` and `b` are always in the range `0..=1`, as returned by the `rgb_from_hsv` function.
I think this is great for helping write correct code, besides the usual tools provided by Rust.<|endoftext|>Hey @rust-lang/lang, I've created a [stabilization report](https://github.com/rust-lang/rust/issues/54503#issuecomment-1179563964) and we identified [two concerns](https://github.com/rust-lang/rust/issues/54503#issuecomment-1190593273). Would you mind reviewing them and giving feedback? :upside_down_face: <|endoftext|>I tend to agree with @ehuss in https://github.com/rust-lang/rust/issues/54503#issuecomment-1180773121 that the current behavior feels pretty awkward to me. My sense is that the "goal" we should have for our rule set is:
* Removing `#[expect]` *always* causes a warning
* Which also means that adding `#[expect]` always silences at least one warning
I think that also matches an intuition that lints are essentially somewhat like a "lexical exception", where the various lint attributes act as try/catch blocks which alter propagation. Under that model, a lint is *always* "thrown", but as it propagates up the "stack" any of the lint attributes will catch it and (potentially) re-throw it. Allow catches and silences; Warn catches and re-throws at a warn level; Deny catches and re-throws at an error level; Forbid catches, hard errors, and throws a new "lint" that makes sure there's no allow, warn, or deny above it. In this framework `expect` would throw a lint if it *didn't* catch. Force warn throws a special kind of lint that is "final/constant" on the way it'll get emitted, but still gets caught and re-thrown otherwise.
If this isn't the case, I think it's harder for users to think about #[expect] as a form of assertion -- i.e., that my code *is* doing something, and I'm acknowledging that. I think in practice it's pretty rare that there's an allow'd lint (either by default or by set lint level) that you explicitly want to assert is present, but I could definitely see that being the case for more esoteric situations. (Something like expecting a wildcard match, maybe, with https://rust-lang.github.io/rust-clippy/master/index.html#wildcard_enum_match_arm, where you don't want to accidentally replace the code with an exhaustive match, even though it's possible).
Looking at https://github.com/rust-lang/rust/issues/54503#issuecomment-1179588519, I find the current behavior confusing for I think similar reasons. Generally I wouldn't treat `#[warn(lint)]` as an assertion that I'm *expecting* an unused variable, so that making `#[expect(...)]` not "catch" that lint is weird.<|endoftext|>@Mark-Simulacrum I agree. I think it would make sense for `expect` to warn if used on a lint that's already marked as `allow`.<|endoftext|>> If this isn't the case, I think it's harder for users to think about #[expect] as a form of assertion -- i.e., that my code _is_ doing something, and I'm acknowledging that. I think in practice it's pretty rare that there's an allow'd lint (either by default or by set lint level) that you explicitly want to assert is present, but I could definitely see that being the case for more esoteric situations
one use case I have to this is:
1. I upgrade a project to the newest Rust toolchain.
2. A clippy lint fires and is a false positive.
3. CI runs clippy with `RUSTFLAGS="-D warnings"`
4. I file a bug.
5. I allow the lint so I can land the rust upgrade.
6. I want to remove the allow once the upstream clippy bug fixes the false positive.
This bug in clippy was closed and pointed to `#[expect(...)]` as the path toward linting on unused `allow` attributes:
- https://github.com/rust-lang/rust-clippy/issues/4636
In these situations, `expect` is an ESLint-style [no-unused-disable](https://github.com/mysticatea/eslint-plugin-eslint-comments/blob/master/docs/rules/no-unused-disable.md) rule or RuboCop's [`Lint/RedundantCopDisableDirective`](https://docs.rubocop.org/rubocop/cops_lint.html#lintredundantcopdisabledirective) violation.
I would like to turn every item and statement positioned `allow` into an `expect` to ensure that these lint directives don't live longer than they should.<|endoftext|>> I think that also matches an intuition that lints are essentially somewhat like a "lexical exception", where the various lint attributes act as try/catch blocks which alter propagation
This is interesting, since this is a totally different from my mental model. I see the lint attributes as region markers, identifying the lint behavior in the marked scope. If the lint emission behaves like try/catch blocks, then it wouldn't make sense that the following code emits a warning, since the `#[allow]` should catch all lint emissions.
```rs
#[allow(unused_variables)]
pub fn test() {
#[warn(unused_variables)]
let duck = 9;
}
```
I'm still in favor of having the `#[expect]` attribute work like every other lint attribute. When I started to work with Rust, I had to get used to how lint attributes work. With other languages, it was less common to change lint levels in code, since other languages tend to have fewer and less strict lints. In Clippy, we're also received some requests to better document how lint levels can be changed. This indicates that the behavior is not always intuitive. The current implementation allows the user to just replace every `#[allow]` to be replaced by `#[expect]`. Having a different implementation would add extra behavior that would need to be learned.
It was mentioned that removing the `#[expect]` should always give a warning. This is the only potential confusion example that I see. On the other hand, there would be no reason to add the `#[expect]` attribute in the first place.
Lint levels can also be defined via console flags. If the `#[expect]` would only be fulfilled by lints with the warn/error level, it would mean that these flags directly influence the behavior of the expectation. There might be some Rustaceans, that enable more lints in their CI or just periodically check them locally to reduce noise.
Therefore, I'm more in favor of having `#[expect]` behave like all other lint attributes | A-lint<|endoftext|>B-RFC-approved<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>I-lang-nominated<|endoftext|>S-tracking-needs-summary<|endoftext|>F-lint_reasons | 54 | https://api.github.com/repos/rust-lang/rust/issues/54503 | https://github.com/rust-lang/rust/issues/54503 | https://api.github.com/repos/rust-lang/rust/issues/54503/comments |
359,965,614 | 54,192 | Tracking issue for -Z emit-stack-sizes | This is an *experimental* feature (i.e. there's no RFC for it) [approved] by the compiler team and added in #51946. It's available in `nightly-2018-09-27` and newer nightly toolchains.
[approved]: https://github.com/rust-lang/rust/pull/51946#issuecomment-411042650
Documentation can be found in [the unstable book](https://doc.rust-lang.org/nightly/unstable-book/compiler-flags/emit-stack-sizes.html). | The flag implemented in #51946 is called `emit-stack-sizes`. This issue is "Tracking issue for -Z emit-stack-sections." Typo?<|endoftext|>@cramertj yes, thanks! It has been fixed.<|endoftext|>Just curious, is there anything specific needed to eventually move this to stable? It seems like the feature is relatively simple and stable, just based on the lack of changes for the past four years<|endoftext|>This does not offer useful support for all targets, it is unclear if it ever will, and LLVM generally seems to consider their CLI interface to be unstable to a degree we are loathe to do, so I do not think we should offer another "expose random LLVM knobs" flag without a clear plan for making it more useful and supporting it in the absence of LLVM support.<|endoftext|>Or e.g. "LLVM has major user orgs using this a lot, so it doesn't seem like LLVM will ever pull support for this, and LLVM has made it more useful for other targets in the past 4 years and will continue to". Or "the way this works can be eventually replaced with a few lines using `object` or something and not depend on a codegen backend" would also be a good answer for "why we should go ahead and stabilize this anyways"! Though the latter would raise the questions of "if we can use Rust code for this, why not just... do that, now?" and "If this is so easy to do, why does it require compiler support?"
So "how to move it along": investigate a bit further, try to anticipate future stability concerns and maybe develop a backup plan so we don't let people down in the future. Also hammer out any UX concerns, like e.g. figuring out if this should actually be a sub-option of a bigger CLI flag or something. Then bring it up to T-compiler, likely on Zulip, and discuss future moves with them.
It's hard to tell "very stable, happily used by many users in silence" apart from "fell through the cracks, works well but only in certain corner cases, is likely to bitrot and have its impl details removed the next release after its upstream LLVM implementer stops contributing". That happens when you have over 8000 **open** issues (of over 100 thousand total PRs and issues). | A-LLVM<|endoftext|>T-compiler<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>WG-embedded<|endoftext|>S-tracking-needs-summary<|endoftext|>A-cli | 5 | https://api.github.com/repos/rust-lang/rust/issues/54192 | https://github.com/rust-lang/rust/issues/54192 | https://api.github.com/repos/rust-lang/rust/issues/54192/comments |
347,313,841 | 53,020 | Tracking issue for comparing raw pointers in constants | Comparing raw pointers in constants is forbidden (hard error) in const contexts.
The `const_compare_raw_pointers` feature gate enables the `guaranteed_eq` and `guaranteed_ne` methods on raw pointers. The root problem with pointer comparisons at compile time is that in many cases we can't know for sure whether two pointers are equal or inequal. While it's fairly obvious that a pointer to a `static` and a local variable won't be equal, we can't ever tell whether two local variables are equal (their memory may alias at runtime) or whether any pointer is equal to a specific integer. In order to make it obvious that there is a discrepancy between runtime and compile-time, the `guaranteed_*` methods only return `true` when we can be sure that two things are (in)equal. At runtime these methods just return the result of the actual pointer comparison.
This permits `const fn` to do performance optimization tricks like the one done in slice comparison (if length is equal and pointer is equal, don't compare the slice contents, just return that it's equal).
Since we aren't sure yet what the semantics of functions that return different values at runtime and at compile-time are, we'll keep this function unstable until we've had that discussion.
### Unresolved questions
* should `guaranteed_eq` return an `Option<bool>` to allow the caller to know whether they got unclear results? What would the use-case for this be? | I either forgot this exists or was never aware.^^ But it is certainly scary... pointer equality is a really complicated subject.
But also, so far the feature flag doesn't actually let you do anything, does it? `binary_ptr_op` still always errors in the CTFE machine, and [even unleashed Miri cannot do pointer comparison](https://github.com/rust-lang/rust/pull/72218).<|endoftext|>Yea it's a fairly useless feature gate as of now<|endoftext|>> should guaranteed_eq return an Option<bool> to allow the caller to know whether they got unclear results? What would the use-case for this be?
I came here to say yes. In general there's an ongoing issue with several APIs in const eval, where under const evaluation to assume there's no reason you might need to handle the case where the function fails to produce a meaningful result.
Some examples of this are `align_offset` returning `usize::MAX`, and `align_to` returning the whole slice in the first item. These are much worse to use (the first is a genuine footgun, and requires branching at runtime even in cases where the failure to align would be impossible except in const) because of this behavior, and IMO it's something we should stop doing. <|endoftext|>FWIW, the `align_offset` contract is useful even for runtime code, since it enables more reliable detection of bad alignment code in sanitizers like Miri. But seeing all the confusion it caused, I agree this is not a great API.
`align_to` though I would consider less problematic. The "failure" case there *is* nicely covered by the types in the API I would say.<|endoftext|>> `align_to` though I would consider less problematic. The "failure" case there is nicely covered by the types in the API I would say.
Sort of, but this could have been done in the appropriate cases as `a.align_to::<T>().unwrap_or_else(|| (a, &[], &[])`. As it is if you need to handle that, you can't. I don't think "yes, most people will use this formulation of `unwrap_or_else` to be a good argument for it doing it for you.
As it is, it not only means that you cannot rely on the alignment occurring for non-performance cases, but you also can't rely on it happening for performance cases either. It's pretty much set up only for loops that are exactly "handle head", "handle body", "handle tail", which is the rough shape, but you often want more flexibility than is allowed by that assumption.
This ends up being very frustrating when using the API, and I think its a pattern we shouldn't repeat.<|endoftext|>> It's pretty much set up only for loops that are exactly "handle head", "handle body", "handle tail", which is the rough shape, but you often want more flexibility than is allowed by that assumption.
That is explicitly and exclusively the case this API was designed for. So IMO it would have been a mistake to make the API worse for that case, and expand its scope. Rather, we should have other APIs for the other usecases. (And we can still add them, if someone has good ideas for useful APIs! I don't feel like `Option<(&[T], &[U], &[T])>` is terribly useful though, but who knows. `Option<&[U]>` sounds useful.)
Anyway, that's water under the bridge. `guaranteed_eq` is different, it's more like `align_offset`, so I can see the argument for returning an `Option<bool>`. OTOH the "guaranteed" in the name feels redundant then? It could in principle be just `eq`, and then `guaranteed_eq` is `eq().unwrap_or(false)` and `guaranteed_ne` is `!eq().unwrap_or(true)` (or `eq().map(Neg::neg).unwrap_or(false)`).<|endoftext|>> That is explicitly and exclusively the case this API was designed for. So IMO it would have been a mistake to make the API worse for that case, and expand its scope.
FWIW, the things I'm referring to are things like being able to rely on there being less than `size_of::<T>()` items in `some_u8s.align_to::<T>()`, in the head. This kind of thing has been desirable every time I've used the function, and I've used it a lot. So I don't disagree this would meaningfully expand the scope.
An example from the stdlib of this is https://github.com/rust-lang/rust/blob/master/library/core/src/str/count.rs#L60-L69, which still exists at runtime, and causes worse codegen.<|endoftext|>> OTOH the "guaranteed" in the name feels redundant then? It could in principle be just eq, and then guaranteed_eq is eq().unwrap_or(false) and guaranteed_ne is !eq().unwrap_or(true) (or eq().map(Neg::neg).unwrap_or(false)).
I agree on this point, although it makes it explicit that the `Option` is representing "no guarantee". It also has the benefit, of not shadowing PartialEq::eq.<|endoftext|>I tried to use this just now in some code wanting to assert that some struct definition was correct at compile time. (It failed, but I writing it that way was probably expecting too much of const eval, and I was able to rewrite it without this).
Anyway, initially my `assert!(a.guaranteed_eq(b))` failed and when this happened I was left wondering if it was because my code sucked (and the struct definition was wrong), or because I had expected too much of const-eval (in which case I need to rework my assert, or give up).
It occurs to me though, that I only noticed this because my code had `true` be the success path -- If that was behind a false instead, it would been easy to miss. This further convinces me that `guaranteed_{eq,ne}` be exposed as an API that returns an `Option`.
While it might seem unlikely for someone to write code that does `!a.guaranteed_eq(b)` instead of `a.guaranteed_ne(b)`, I could easily imagine it happening if the code had been ported from non-const code which had `!a.eq(b)`.
Use of an option would force handling the "don't know at compile time" case in some way (ideally unwrap) and avoid a case where the API is similar enough to a non-const API that it becomes easy to do make a mistake when translating from one to the other.<|endoftext|>We probably want to use a simpler type for the intrinsic (to make that easier to implement), but I am generally on-board with changing the type of the public functions here. | T-lang<|endoftext|>B-unstable<|endoftext|>A-const-fn<|endoftext|>C-tracking-issue<|endoftext|>A-const-eval<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 10 | https://api.github.com/repos/rust-lang/rust/issues/53020 | https://github.com/rust-lang/rust/issues/53020 | https://api.github.com/repos/rust-lang/rust/issues/53020/comments |
343,797,565 | 52,652 | Abort instead of unwinding past FFI functions | ## More updated description (2021-03-11)
With https://github.com/rust-lang/rust/pull/76570 having landed, Rust now aborts when a panic leaves an `extern "C"` function, so the original soundness issue is fixed. However, there is an attribute to opt-out of this behavior, `#[unwind(allowed)]`. Using this attribute is currently unsound, so it should be fixed, removed, or require some form of `unsafe`.
## Updated Description
This is a tracking issue for switching the compiler to abort the program whenever a Rust program panics across an FFI boundary, notably causing any non-Rust-ABI function to panic/unwind.
This is being implemented in #55982 and some regressions were found in the wild so this is also being repurposed as a tracking issue for any breakage that comes up and a place to discuss the breakage. If you're a crate author and you find your way here, don't hesitate to ask questions!
## Original Description
Doing Rust unwinding into non-Rust stack frames is undefined behavior. This was [fixed](https://github.com/rust-lang/rust/pull/46833) in [1.24.0](https://blog.rust-lang.org/2018/02/15/Rust-1.24.html#other-good-stuff), and then reverted (I think by https://github.com/rust-lang/rust/pull/48380 ?) in [1.24.1](https://blog.rust-lang.org/2018/03/01/Rust-1.24.1.html#do-not-abort-when-unwinding-through-ffi) because of a [regression](https://github.com/rust-lang/rust/issues/48251) that affected rlua.
The latter blog post said:
> The [solution](https://github.com/rust-lang/rust/pull/48572) here is to generate the abort handler, but in a way that `longjmp` won’t trigger it. It’s not 100% clear if this will make it into Rust 1.25; if the landing is smooth, we may backport, otherwise, this functionality will be back in 1.26.
The link PR has landed, but my understanding is that it does *not* change FFI functions back to aborting on unwind (though it looks like it does fix the issue that affected rlua).
This UB is not mentioned in any later release notes.
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
This issue has been assigned to @BatmanAoD via [this comment](https://github.com/rust-lang/rust/issues/52652#issuecomment-1027361227).
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":"BatmanAoD"}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END --> | CC @alexcrichton, @nikomatsakis <|endoftext|>cc me<|endoftext|>cc @diwic
I think @SimonSapin your description is accurate. The [backport to stable](https://github.com/rust-lang/rust/pull/48445) and [backport to beta](https://github.com/rust-lang/rust/pull/48445) were both minor patches, and the main one to nightly (at the time) was https://github.com/rust-lang/rust/pull/48380 as you mentioned.
AFAIK we should be good to go again to do this.<|endoftext|>I think I would prefer that instead of immediately landing a change to the default unwind behavior we just stabilize the `unwind` attribute and wait for a few cycles to let the ecosystem migrate to `unwind(allowed)` or `unwind(abort)` across `extern "C"` functions. It would be nice to have some docs providing guidance here as well.<|endoftext|>Why is this attribute useful? If the issue that affected rlua is fixed, what can make the answer to "do you want to protect against some potential UB" be anything other than "yes, obviously"?<|endoftext|>There are cases where unwinding is fine, for example if you are using a extern "C" function to talk between different Rust crates or extern "Rust" functions to do the same. There are cases where you legitimately are fine with unwinding (and IMO it shouldn't be UB). I don't think the decision whether unwinding should abort or continue should be based on the extern-ness of the function. `unwind(allowed)` or `unwind(aborts)` may be useful in normal Rust as well if you want to do `-Cpanic=abort` on a smaller (non-library) scale, though it's less useful to an extent in that case due to catch_unwind existing.<|endoftext|>Good to see some movement here.
For me it's bikeshedding whether we go with `#[unwind]`, `#[unwind(allowed)]` or even `extern "C-unwind"` as long as we default to aborting for every non-Rust ABI. But it does seem it would be helpful for the [libjpeg / libpng bindings](https://internals.rust-lang.org/t/support-c-apis-designed-for-safe-unwinding/7212).<|endoftext|>Alright, stabilizing some attribute (perhaps with `unsafe` in its name) to support this libjpeg use case sounds fine, but I don’t see a reason to wait several cycles to change the default back when the plan was to do it in 1.25.<|endoftext|>The primary point we reverted back then was *because* of breakage due to changing the default. I'm not convinced that the breakage would not happen again; there's currently no way to explicitly document your requirements on stable. I see this as the same situation as we normally have for library features, where the unstable/deprecated solution isn't removed until the stable alternative lands in stable.
I also am unclear why we would/should rush this. People have waited, people can continue to wait. Stabilizing `unwind` seems uncontroversial; we can do so immediately.<|endoftext|>@Mark-Simulacrum
> unwind(allowed) or unwind(aborts) may be useful in normal Rust as well if you want to do -Cpanic=abort on a smaller (non-library) scale, though it's less useful to an extent in that case due to catch_unwind existing.
I'm not sure what this means, but if -Cpanic=abort is specified I don't think you should be able to override that with a `#[unwind(allowed)]`.
> I also am unclear why we would/should rush this. People have waited, people can continue to wait.
Well, why should fixing I-unsound bugs have high priority in general? I think they should have high priority, but not everyone shares that sentiment.
> Stabilizing unwind seems uncontroversial; we can do so immediately.
Are there some unresolved questions here w r t:
* Which ABIs should allow `#[unwind]`? Should we do this for all ABIs, or just "C"?
* In a `-Cpanic=abort` scenario should `#[unwind]` be able to override this for Rust ABI and nevertheless allow unwinding? (I prefer not.)
<|endoftext|>> I'm not sure what this means, but if -Cpanic=abort is specified I don't think you should be able to override that with a #[unwind(allowed)].
I mean the reverse; if you've specified `-Cpanic=unwind` but for whatever reason want a specific function to not unwind, you can today do so with catch_unwind but I could see us also supporting `#[unwind(abort)]` annotations as an alternative. I'm not sure there's a need, though.
> Well, why should fixing I-unsound bugs have high priority in general? I think they should have high priority, but not everyone shares that sentiment.
This isn't an unsoundness bug though. It is currently UB to unwind through stack frames not generated by the same Rust compiler (and will always be, at least in the short term) but I don't see how that is unsound. I've removed that tag.
> Are there some unresolved questions here w r t ...
I'd be happy stabilizing `#[unwind]` for all extern functions regardless of ABI; it seems like a feature orthogonal to the ABI. I don't think it's possible to make `#[unwind]` override -Cpanic=abort anyway, or at least not trivial. That is to say, it shouldn't be supported, but perhaps should also not be an error since there's not currently a way to `cfg` around `-Cpanic`...<|endoftext|>> This isn't an unsoundness bug though
It is indeed not rustc or std that is unsound, but the current situation is that it is very difficult to write sound FFI code. You need to carefully audit every callback either to convince yourself that it cannot ever panic, or use `catch_unwind` (again in every callback) and then carefully audit the code that is outside of the `catch_unwind` closure that wraps stuff to be `UnwindSafe` or deals with the returned `Result`. (Don’t use `.unwrap()` !)
So I’d say this *is* a soundness-related issue.<|endoftext|>I don't disagree; writing sound FFI code is hard. I'm just trying to say that changing the default without providing a way to use the old behavior seems wrong and I'm against doing it. Furthermore, I'd prefer at least one cycle that users can explicitly opt-in to `unwind(allowed)` for FFI functions where unwinding isn't UB (i.e., they're unwinding into Rust code). I'm okay (though not happy) with us making a change to the default behavior so long as the opt-out is stabilized along side it.<|endoftext|>@Mark-Simulacrum
> This isn't an unsoundness bug though.
Oh yes it is. Please don't remove `I-unsound` tags without thoroughly understanding the issue.
1) Everything that is UB is also unsound, simply because the behavior is undefined, i e, not defined as being sound.
2) Extern C functions (as well as all other non-Rust ABIs IIRC) are - unless `#[unwind]` - marked as `nounwind` in the LLVM IR. Unwinding from a nounwind function is UB, according to LLVM docs.
<|endoftext|> > I mean the reverse; if you've specified -Cpanic=unwind but for whatever reason want a specific function to not unwind, you can today do so with catch_unwind but I could see us also supporting #[unwind(abort)] annotations as an alternative. I'm not sure there's a need, though.
Okay. I don't think there is much need. Maybe it would make the crate [take_mut](https://docs.rs/take_mut/0.2.2/src/take_mut/lib.rs.html#37) use a fewer less characters.
> I'd be happy stabilizing #[unwind] for all extern functions regardless of ABI; it seems like a feature orthogonal to the ABI.
I see unwinding as part of the ABI, but it's possible (I'm not sure) that for all practical purposes one can see it as an orthogonal feature.
@SimonSapin
> the current situation is that it is very difficult to write sound FFI code. You need to carefully audit every callback either to convince yourself that it cannot ever panic, or use catch_unwind (again in every callback) and then carefully audit the code that is outside of the catch_unwind closure that wraps stuff to be UnwindSafe or deals with the returned Result. (Don’t use .unwrap() !)
Indeed. I even found [such a mistake in std](https://github.com/rust-lang/rust/pull/32476) once. And just to clarify, this is the practical reason why were doing the "abort" solution rather than just stop marking C ABI functions as `nounwind` in LLVM.
<|endoftext|>@diwic I would classify a "soundness bug" as a case where "safe Rust" can generate UB. Are you saying that this is the case here? (I'm legitimately unsure)<|endoftext|>But in any case I think that @Mark-Simulacrum's suggestion of "do not deprecate without at least offering some way to get back the old default" makes sense to me. I think I share these sentiments pretty much exactly:
> I'm just trying to say that changing the default without providing a way to use the old behavior seems wrong and I'm against doing it. Furthermore, I'd prefer at least one cycle that users can explicitly opt-in to unwind(allowed) for FFI functions where unwinding isn't UB (i.e., they're unwinding into Rust code). I'm okay (though not happy) with us making a change to the default behavior so long as the opt-out is stabilized along side it.<|endoftext|>@nikomatsakis
> I would classify a "soundness bug" as a case where "safe Rust" can generate UB. Are you saying that this is the case here? (I'm legitimately unsure)
Yes, this is UB as of current Rust:
extern "C" fn bad() { panic!() }
fn main() { bad() }
Here's the LLVM IR (notice the `nounwind` attr) :
; playground::bad
; Function Attrs: nounwind uwtable
define internal void @_ZN10playground3bad17hd96a1f8f707dc090E() unnamed_addr #3 !dbg !676 {
start:
; call std::panicking::begin_panic
call void @_ZN3std9panicking11begin_panic17h23bac1aac94eb1e7E([0 x i8]* noalias nonnull readonly bitcast (<{ [14 x i8] }>* @byte_str.7 to [0 x i8]*), i64 14, { [0 x i64], { [0 x i8]*, i64 }, [0 x i32], i32, [0 x i32], i32, [0 x i32] }* noalias readonly dereferenceable(24) bitcast (<{ i8*, [16 x i8] }>* @byte_str.6 to { [0 x i64], { [0 x i8]*, i64 }, [0 x i32], i32, [0 x i32], i32, [0 x i32] }*)), !dbg !678
unreachable, !dbg !678
}
[LLVM reference](https://llvm.org/docs/LangRef.html):
nounwind
This function attribute indicates that the function never raises an exception. If the function does raise an exception, its runtime behavior is undefined.
<|endoftext|>I've opened a PR for this at https://github.com/rust-lang/rust/pull/55982 which does the "easy thing" of basically flipping the defaults.
I personally disagree that we need to take any further action at this time. We've got a long history of a "stable default" in Rust where the opt-out is unstable (allocators are the first that come to mind). Eventually the opt-out is stabilized in its own right, but for now we have an unstable control (the `#[unwind]` attribute).
Additionally I don't think this can really bake without actually testing, this will remain virtually undetected unless *everyone* opts-in to testing it, so the only real way to get testing is to actually flip the defaults and see what happens. That's what we did last time and it's easy to always flip the defaults back if something comes up!<|endoftext|>Ok we've executed a crater run for this issue on https://github.com/rust-lang/rust/pull/55982 and it's [finished](https://github.com/rust-lang/rust/pull/55982#issuecomment-439730245) but [has some regressions](https://github.com/rust-lang/rust/pull/55982#issuecomment-440461209). I'm cc'ing the authors of the crates here to make sure they're aware of this! The current plan is to land https://github.com/rust-lang/rust/pull/55982 after December 6, making it part of Rust 1.33 to be released on February 28, 2019.
If those cc'd here have difficulty fixing the issues here or have any questions/concerns, please don't hesitate to comment here!
* cc @hean01 as the `mujs` crate has broken, where [this function now always aborts](https://github.com/hean01/mujs-rs/blob/cdfa6bca8855bc53086cf29de956b6b81e2b2272/src/lib.rs#L241-L253)
* cc @rustcc, as the `coroutine` crate's tests are broken as [this function now aborts](https://github.com/rustcc/coroutine-rs/blob/b9ac79eaa190de4fa6d25c83a677c9254c7895f4/src/asymmetric.rs#L152-L161)
* cc @valarauca, as the `consistenttime` crate now [can abort here](https://github.com/valarauca/consistenttime/blob/e489e720c7326eeb78a52e8fbded25a4927c6edf/src/lib.rs#L347-L358)
* cc @PJB3005 as the `byond` crate can [abort here](https://github.com/PJB3005/byond-rs/blob/7bfbf14f1c9defee7f80eec526cfa8f80b7f4d02/src/lib.rs#L51)<|endoftext|>For my crate (`byond`) I personally don't care that much. The panic is always gonna unwind into third party C++ so abort is fine by me (better than what was probably undefined behavior, at least).
Keeping the unit test would be preferable but I'm not sure how to write a macro to keep them (I'm thinking having an `extern "C"` exposed symbol for the FFI and then an internal Rust one the unit test can run, but I can't think of a way to do that without the ability to concatenate macro identifiers which isn't possible..)<|endoftext|>FYI `consistenttime` does not work as advertised and its README states that people should prefer alternatives so hopefully nobody will be effected. I would remove the project from `crates.io` but that isn't possible apparently :sob:
Also I'm not using the FFI, just a different calling convention. So the title/issue may want to be updated(?). I'm just using the `C` calling convention as it is easier to reason about register access for assembly heavy code with a _known_ calling convention. <|endoftext|>@PJB3005 oh so if it's fundamentally going into C++ you've got two choices:
* Catch the panic and return an error into C++, re-raising the Rust panic at some point (optionally)
* Catch the panic and unconditionally abort the process (but manually), perhaps printing an error message
You could also leave it as-is with aborting the process via the rustc-generated code, but that may not have the best errors.
@valarauca oh true! This definitely applies to `extern fn` of all ABIs, not just FFI in general.<|endoftext|>Can the `#[unwind(allowed)]` attribute be stabilized soon? This is forcing me to write a lot more code in C++ than I would like.<|endoftext|>Reopening since we reverted on stable (but not beta & nightly).
Decision about next stable is tracked in https://github.com/rust-lang/rust/issues/58794.<|endoftext|>@Centril could you link to where the decision to revert was made? (Hopefully with discussion of why?) I thought we’d already landed this change and reverted it once several releases ago, and landed it again more recently.<|endoftext|>Ah, https://github.com/rust-lang/rust/pull/58795 links to https://github.com/rust-lang/rust/pull/58795<|endoftext|>@SimonSapin The release team decided to revert because there was no explicit decision to go ahead with the change from the language team. See https://github.com/rust-lang/rust/issues/58794 for details. I am working on an FCP to confirm the change for 1.34 and beyond.<|endoftext|>Is there an RFC or a PR specifying the semantics of this change ?
From reading the conversations, `extern` functions are required to abort in case of a panic, but this isn't necessarily the same as, e.g., guaranteeing that the semantics are equivalent to wrapping each `extern` function in a `catch_unwind`, and then aborting in case of a panic.
For example, can:
```rust
extern "C" fn foo(x: i32) -> i32 {
if x < 0 { panic!() }
x
}
```
be optimized into
```rust
extern "C" fn foo(x: i32) -> i32 { x }
```
?
AFAICT, this optimization would not result in a panic unwinding across an extern function boundary, so it would satisfy that criteria.<|endoftext|>I wrote [here](https://github.com/rust-lang/rust/pull/63909#issuecomment-529348783) that, a way to close this soundness hole on safe stable Rust, without any language changes, without any performance regressions, and without unconditionally making it impossible to unwind through FFI on stable Rust would be to just enable abort-on-panic for safe `extern "C"` FFI functions.
This allow us to continue emitting nounwind everywhere (no perf regression), and it allows those users that want to continue to invoke undefined behavior on stable Rust to port their code to just use `unsafe extern "C"` types instead. For mozjpeg, AFAICT, this would be a one line change in mozjpeg-rust.
Note that this does not give any new meaning to the `unsafe` keyword: the behavior of unwinding out of an `unsafe extern "C"` function is still undefined, and providing a way to unwind through FFI without UB would still require an RFC with new language features that allow doing that.
The only thing we would do is temporarily not abort your program if you unwind out of an `unsafe extern "C"` function, we would still continue to optimize it under the assumption that the code does not do this, but current users appear to be able to work with this. | A-ffi<|endoftext|>P-high<|endoftext|>T-compiler<|endoftext|>relnotes<|endoftext|>I-unsound<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>WG-project-ffi-unwind | 61 | https://api.github.com/repos/rust-lang/rust/issues/52652 | https://github.com/rust-lang/rust/issues/52652 | https://api.github.com/repos/rust-lang/rust/issues/52652/comments |
331,834,168 | 51,528 | Diagnostics Revamp Roadmap | The current diagnostics APIs are very unergonomic and can result in various verbose, repetitive and annoying code snippets.
cc @estebank
* [ ] Ensure that diagnostics have been emitted at compile-time (must-use and consuming `emit` method
* [ ] Improve/expand `--teach` API
* Applicable to user code -> show hints for user code
* else -> show hints for error code example
* [ ] Diagnostics builder API
* use https://github.com/rust-lang/annotate-snippets-rs/
* One struct per error (maybe too verbose) #61132
* templates (maybe too many "special" cases)
* *real* builder pattern
* sub-builders for suggestions, ...
* typesafe snippet to suggestion path
* [ ] Emitter API
* allow builder API to set span labels in subdiagnostics
* multiple spans in a subdiagnostic
* suggestions and notes in arbitrary order
* terminal width support
* (windows only) background color check | Just when I added support for the current API in rustdoc... 😢 <|endoftext|>Just think about how much better things will be!<|endoftext|>I think the way to introduce next generation systems like `chalk` for trait-sys and `polonius` for borrowck is a great model of upgrading: create a independent crate then port into rustc, this will be easier for the future diag-api ‘s self-updating and more friendly to downstream tools like rustdoc,rustfix.<|endoftext|>That... is an absolutely awesome idea.
We can totally recreate the diagnostics API in an external crate. Even better: we can also do that for the diagnostics emitter!<|endoftext|>Factoring out the diagnostics emitter has a real use-case in cargo. There have been a few attempts at making a nicer build progress bar (https://github.com/rust-lang/cargo/pull/3451, https://github.com/rust-lang/cargo/pull/5620), but issues like https://github.com/rust-lang/cargo/issues/5695 prevent the feature from being a nice user experience: the progress bar output gets interleaved with rustc output. This could be fixed if cargo were able to capture output from rustc and print it itself, but as it stands, cargo cannot capture output from rustc without losing formatting.
However, if the diagnostics emitter were factored out into a third-party crate, it might be possible for cargo to recreate the errors and output them with full formatting.
cc @alexcrichton <|endoftext|>@euclio that would require `rustc` to produce enough metadata to recreate the exact output (which I believe it is not possible at the moment, the json output is _slightly_ lossy). That doesn't mean it's not a worthwhile objective to aim for.<|endoftext|>Over on Zulip we were recently discussing the idea of having a fallback "footnote" mode to use for overlapping, adjacent, or malordered labels. I wrote up the idea in this gist:
https://gist.github.com/nikomatsakis/80866d4407f1cc38fba0c2da7175dcf7
Example might be like:
```
15 | };
| - (1)
| - (2)
|
| 1: `heap_ref` dropped here while still borrowed
| 2: borrowed value needs to live until here
```
instead of
```
15 | };
| -- borrowed value needs to live until here
| |
| `heap_ref` dropped here while still borrowed
```
(The proposal also includes a way to indicate labels that have an "ordering" to them that you would like the renderer to enforce.)<|endoftext|>Does the WG have any plans for internationalization support?<|endoftext|>We haven't discussed it but I feel that at this point we won't be able to maintain the level of quality we want while also scaffolding i10n support. I would love to hear others opinions.
Cc @rust-lang/wg-diagnostics <|endoftext|>I think extracting diagnostics logic to structs and such is a great move for internationalization. Beyond that, the only think I would suggest is that you consider what i10n support in the future might take and try to avoid doing things that would make i10n harder in the future. Perhaps consider future-proofing traits and such today if possible.<|endoftext|>We discussed i18n in the [wg-diagnostics Zulip channel](https://rust-lang.zulipchat.com/#narrow/stream/147480-t-compiler.2Fwg-diagnostics/topic/Internationalization).
It becomes quite easy to migrate if we use a [custom derive](https://github.com/rust-lang/rust/issues/61132#issuecomment-500163232) (or other plugin) to autogenerate AsError impls for diagnostics structs. We should start looking into getting that derive working and convert diagnostics to it.
Once a significant portion of the codebase is using AsError, we can start playing with Fluent. | A-diagnostics<|endoftext|>T-compiler<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-impl-incomplete<|endoftext|>S-tracking-needs-summary | 11 | https://api.github.com/repos/rust-lang/rust/issues/51528 | https://github.com/rust-lang/rust/issues/51528 | https://api.github.com/repos/rust-lang/rust/issues/51528/comments |
326,744,336 | 51,085 | Tracking issue for RFC 1872: `exhaustive_patterns` feature | This tracks the `exhaustive_patterns` feature which allows uninhabited variant to be omitted
(bug report: #12609; relevant RFC: rust-lang/rfcs#1872).
```rust
fn safe_unwrap<T>(x: Result<T, !>) -> T {
match x {
Ok(y) => y,
}
}
```
- [x] Implementation (separated out from `never_type` in #47630)
- [ ] Stabilization
| The lack of this feature has unintuitive consequences (e.g. https://github.com/rust-lang/rust/issues/55123). I haven't seen any problems arising from it either.
cc @rust-lang/lang: could this be put forward for stabilisation?<|endoftext|>@varkor I am mildly reluctant until we have agreed upon the story around ["never patterns"](http://smallcultfollowing.com/babysteps/blog/2018/08/13/never-patterns-exhaustive-matching-and-uninhabited-types-oh-my/) -- but I suppose given a sufficiently conservative definition of "uninhabited pattern" I'd be all right with it. Do you think you could write-up a "stabilization report" that includes examples of the tests we have and also documents the limits of what sorts of things would be considered uninhabited in stable code?
(That said, I think "never patterns" gives us a path forward that addresses my concerns around aggressive uninhabited definitions, by just turning the "ambiguous" cases into lints in the presence of unsafe code. I'd be happier though if we had an RFC on the topic.)<|endoftext|>The `exhaustive_patterns` feature currently seems to have a pretty big performance issue. Having perf top running while compiling librustc, I noticed that it spends an unreasonable amount of time inside `ty::inhabitedness`. Disabling `exhaustive_patterns` (it's not actually used in librustc/librustc_mir) shaved off ~30s (of 12min total) from stage1 compiler artifact compile time (in a totally unscientific benchmark, so take with a grain of salt).
I would expect that this issue will resolve itself if there is a consensus to go with references never being uninhabited (ref https://github.com/rust-lang/rust/pull/54125#issuecomment-433304976), as the reference handling is what I believe makes this expensive (not looking through references both reduces the amount of types we need to look at, and allows us to drop the expensive hashmap and nested hashsets used to avoid unbounded recursion). If the consensus goes in the other direction, then this code should probably be optimized a bit prior to stabilization of the feature.<|endoftext|>cc https://github.com/rust-lang/rust/issues/51221, using this feature in `let`-bindings seems to ICE unless the `never_type` feature is also enabled<|endoftext|>> The `exhaustive_patterns` feature currently seems to have a pretty big performance issue. Having perf top running while compiling librustc, I noticed that it spends an unreasonable amount of time inside `ty::inhabitedness`.
It is now the case that "references never are uninhabited", at least as far as `is_ty_uninhabited_from` is concerned. Is the performance issue still there?
Otherwise, I expect that making `is_ty_uninhabited_from` into a query or something would significantly improve perf, because match checking repeatedly calls it on the same type and its subcomponents.<|endoftext|>> Is the performance issue still there?
I suspect this requires some investigation. (Perhaps it would be sufficient to open a PR enabling the feature and do a perf run.)<|endoftext|>So, apart from the perf issue (which is being worked on), the blocker seems to be the [never patterns](https://smallcultfollowing.com/babysteps/blog/2018/08/13/never-patterns-exhaustive-matching-and-uninhabited-types-oh-my/) story that @nikomatsakis mentioned. I'll try to summarize the issue and the current status of this feature. Hopefully this can serve as a partial stabilization report.
#### Unsafe makes more things reachable
The issue is that in unsafe code we may come across patterns that would be unreachable in safe code but could actually be reachable in unsafe code. The two examples @nikomatsakis mentions are `&!` references (since such a reference could e.g. point to uninitialized memory) and partially-initialized structs/tuples.
To illustrate the first case:
```rust
let x: Option<&!> = foo();
match x {
Some(x) => {
// This branch might be accessible if we create the reference unsafely.
}
None => {}
}
```
Here we might legitimately get such a reference and want to operate on it in unsafe code, so we don't want the branch to be unreachable. To illustrate the second case ([playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=8426097da3441798bc5b4e580d9fb077)):
```rust
union Uninit<T> {
value: ManuallyDrop<T>,
uninit: (),
}
fn main() {
unsafe {
let mut x: Uninit<(u32, !)> = Uninit { uninit: () };
(*x.value).0 = 22; // Initialize first part of the tuple
match *x.value {
(v, _) => { // This is reachable and apparently not UB
println!("{}", v);
}
}
}
}
```
Since those branches are reachable, we really musn't allow the user to omit them. If we did, the following would compile and be unsound:
```rust
unsafe {
let x: &! = foo();
let n: u64 = match Some(x) {
None => 42,
};
// now `n` contains UB garbage
}
```
Yet in both those cases, we might legitimately want to treat those branches as unreachable in safe code. Typically we may want the following to compile:
```rust
fn safe_unwrap<T>(x: &Result<T, !>) -> &T {
match x.as_ref() {
Ok(x) => x,
}
}
```
#### Current status of `unreachable_patterns`
The feature allows one to skip branches in a match expression (and similar like `if let`) when the compiler can determine that there would be no values that match it. Currently this includes:
- any pattern for an uninhabited type
- a variant pattern where the variant contents is uninhabited
- a slice pattern of length >0 for a slice of an uninhabited type
Where the following types are deemed uninhabited:
- the never type
- structs and tuples with one of more visible uninhabited fields
- enums with no variants or with only uninhabited variants
- arrays of non-zero length of an uninhabited type
- anything else is inhabited. _This includes all references_.
This allows one to skip useless branches. Here are examples:
```rust
match x { // x: Result<T, !>
Ok(_) => {}
}
let Ok(y) = x; // x: Result<T, !>
match x {} // x: !
match x {} // x: (u64, !, String)
match x {} // x: Result<!, !>
match x { // x: &!
_ => {} // necessary because `&!` is considered inhabited
}
match x { // x: &!
&_ => {} // this one is unreachable, because now the `_` has type `!`.
// this is a bit awkward: the branch is unreachable, but if we remove it we get
// a non-exhaustive match.
}
match x { // x: Result<T, &!>
Ok(_) => {}
Err(_) => {} // necessary because `&!` is considered inhabited
}
fn safe_unwrap<T>(x: &Result<T, !>) -> &T {
match x {
Ok(x) => x,
// other branch not needed because the `Err` case contains an actual `!`, not a `&!`
}
}
fn safe_unwrap<T>(x: &Result<T, !>) -> &T {
match x.as_ref() {
Ok(x) => x,
Err(_) => {} // necessary because `&!` is considered inhabited
}
}
```
#### Resolution?
Of the two issues mentioned in the never patterns blog post, the `&!` one is not a problem because we currently err on the side of inhabitedness for references.
The case of partially-initialized tuples is however unsolved. I would have thought that matching on a partially-uninitialized value would be UB, but if it isn't then we need some other way to resolve this issue. I imagine we can also construct enum values with initialized discriminant and uninitialized contents, so allowing matches on partially-initialized values seems to require that we completely disable the exhaustive_patterns feature as it is currently implemented.
I don't know how important the partially-initialized case is. If it is, then we need never patterns (or some other good idea); if it isn't, I guess we could stabilize the feature (once perf is fixed)?<|endoftext|>Hm, [I have been informed](https://github.com/rust-lang/rust/issues/78123#issuecomment-737559741) that the Rustonomicon [explicitly says](https://doc.rust-lang.org/nomicon/what-unsafe-does.html) that "a reference that points to an invalid value" is UB. I would deduce that there can't be a value of type `&!` even in unsafe code. But this reading seems to also rule out partially initialized values. Unless uninitialized memory does not count as an invalid value? I feel out of my depth here.<|endoftext|>cc @RalfJung, who is the expert when it comes to the subtleties of UB.<|endoftext|>Also see what I [wrote here](https://github.com/rust-lang/rust/issues/78123#issuecomment-737746503).
> Here we might legitimately get such a reference and want to operate on it in unsafe code, so we don't want the branch to be unreachable. To illustrate the second case (playground):
That example is UB: when you read `*x.value`, that produces a value of type `(u32, !)`, which is UB.
> But this reading seems to also rule out partially initialized values.
There are two different things in Rust that people call "partial initialization". There's the safe kind that is understood by the compiler:
```rust
let x: (i32, i32);
x.0 = 4;
x.1 = 5;
```
Here, the not-yet-initialized parts of the data are not accessible to the program (this is ensured statically by the compiler), and thus there is no chance of violating any invariants.
And then there is partial initailization using `MaybeUninit`, where it is up to the programmer to ensure that only the already-initialized part of the data is read.
I don't know what you mean by "rule out partially initialized value", but when you have a value of type `(bool, bool)`, it *must* be fully initialized. If you want to work with partially initialized data, that must be reflected in the types, e.g. by using `MaybeUninit<(bool, bool)>`.<|endoftext|>> it is up to the programmer to ensure that only the already-initialized part of the data is read
I think the question was exactly whether `match x { (v, _) => ... }` counts as only reading the already-initialized data.
> That example is UB: when you read *x.value, that produces a value of type (u32, !), which is UB.
Oh, I was starting to fear it wasn't. I this settled enough? Will it stay UB in the future, so that we can allow matching on `(u32, !)` with no branches?<|endoftext|>> I think the question was exactly whether match x { (v, _) => ... } counts as only reading the already-initialized data.
Well, I think it should (I view the `_` pattern as expressing that the data is read and then discarded), but I don't think this has been explicitly decided.<|endoftext|>Ah, then I'm back to being confused. Shall we continue [on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-lang.2Fwg-unsafe-code-guidelines/topic/Soundness.20of.20.60exhaustive_patterns.60)?<|endoftext|>First, some good news: I got [a PR] up that most probably fixes the [performance issue]. Once/if it gets merged we can confirm if it really fixed perf.
Second, after [some] [discussion] and [a] [lot] [of] [reading] on my part, I understand the situation better. I'll explain what I understood, even though it's nothing new. This explains why the feature can't be stabilized as it is today.
Here is what made it click for me: @RalfJung [says] that whether `match x { _ => ... }` should lint as unreachable for `x: !` is not yet decided. That's because because rust has an [access-based] model for validity. The lang team may yet decide whether such a match counts as accessing `x` or not, i.e. whether this asserts the validity of `x`. If this doesn't assert the validity of `x`, then we can't make use of the fact that `!` has no valid values. So we must not lint the branch as unreachable. I imagine a similar argument applies in the case of `match x { Ok(_) => ..., Err(_) => ... }` where `x: Result<T, !>`, which means we can't lint the `Err(_)` branch as unreachable.
On top of that, there's a subtly different question: can we allow `match x { Ok(_) => ... }`? (It took me a while to understand these were not the same question). If we do, then such a match asserts the validity of the `!` contained in `Err` case. The problem is not soundness here, but explicitness. As @nikomatsakis explained in his [never patterns] blog post, we would have _the absence of a branch_ count as reading a value/asserting its validity. Sounds like a big footgun for writers of unsafe code. Even worse: if we add an `Err(_)` branch it might be reachable. Not great.
All this means we can't stabilise the feature as it currently is. Not even a useful subset of it, since the main motivation is the `Result<T, !>` case, which as we've seen is problematic. We need some way to make the feature behave differently around unsafe code, and a fix for the explicitness issue. The [never patterns] idea sounds promising to fix both those issues; that will have to go through the RFC process.
[a PR]: https://github.com/rust-lang/rust/pull/79670
[performance issue]: https://github.com/rust-lang/rust/issues/51085#issuecomment-433476162
[some]: https://github.com/rust-lang/rust/issues/51085#issuecomment-739250270
[discussion]: https://rust-lang.zulipchat.com/#narrow/stream/136281-t-lang.2Fwg-unsafe-code-guidelines/topic/Soundness.20of.20.60exhaustive_patterns.60
[a]: https://doc.rust-lang.org/nomicon/what-unsafe-does.html
[lot]: https://github.com/rust-lang/unsafe-code-guidelines/issues/77
[of]: https://www.ralfj.de/blog/2018/08/22/two-kinds-of-invariants.html
[reading]: https://smallcultfollowing.com/babysteps/blog/2018/08/13/never-patterns-exhaustive-matching-and-uninhabited-types-oh-my/
[access-based]: https://smallcultfollowing.com/babysteps/blog/2018/08/13/never-patterns-exhaustive-matching-and-uninhabited-types-oh-my/#what-data-does-a-match-access
[says]: https://rust-lang.zulipchat.com/#narrow/stream/136281-t-lang.2Fwg-unsafe-code-guidelines/topic/Soundness.20of.20.60exhaustive_patterns.60/near/218937929
[never patterns]: https://smallcultfollowing.com/babysteps/blog/2018/08/13/never-patterns-exhaustive-matching-and-uninhabited-types-oh-my/
<|endoftext|>Note that some people will want `Ok(x)` to be an irrefutable pattern when matching at type `Result<T, !>` (see e.g. #71984). A possible solution is to say that irrefutable matches (in `let`, parameters and `for` but not `if let` or `while let`) may add never patterns as needed when desugaring to an exhaustive `match`.
I believe it is backward compatible to first stabilize never patterns in `match` and later, after more discussion, change the behaviour of irrefutable matches as suggested above.<|endoftext|>Btw, perf is no longer a blocker: [comparison url](https://perf.rust-lang.org/compare.html?start=fd2df74902fa98bcb71f85fd548c3eb399e6a96a&end=82e461272563be4e708e0a70d043653baed29179), measured [here](https://github.com/rust-lang/rust/pull/79394).<|endoftext|>I do feel we need the never patterns feature -- or some equivalent thing. This is probably just blocked on never being stabilized.<|endoftext|>Not sure if this is the expected behavior by the following does not compile:
```rust
#![feature(exhaustive_patterns)]
#![feature(never_type)]
pub trait Mode {
type Known;
type Unknown;
}
pub enum Value<T, M>
where
M: Mode,
{
Known(T, M::Known),
Unknown(M::Unknown),
}
pub struct KnownOnly;
impl Mode for KnownOnly {
type Known = ();
type Unknown = !;
}
fn test(value: Value<bool, KnownOnly>) -> bool {
let Value::Known(value, _) = value;
value
}
```
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=4ddd54ccfd38752dfcf9ae647289976f
In this case, the "exhaustiveness" of a pattern requires checking the `trait` implementation instead of the types specified on the function boundary. The exhaustiveness check does work if you remove the trait:
```rust
#![feature(exhaustive_patterns)]
#![feature(never_type)]
pub enum Value<T, K, U> {
Known(T, K),
Unknown(U),
}
fn test(value: Value<bool, (), !>) -> bool {
let Value::Known(value, _) = value;
value
}
```
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=fdde6cee3fece28c003d097df523404b<|endoftext|>> I do feel we need the never patterns feature -- or some equivalent thing. This is probably just blocked on never being stabilized.
Has any progress been made on never patterns in the last year or is this still waiting on someone to come along and implement them?<|endoftext|>Posting a simplified use-case here at someone's suggestion from the Discord.
```rust
fn never(a: std::convert::Infallible) -> std::convert::Infallible {
match a {}
}
fn never_never(
a: std::convert::Infallible,
b: std::convert::Infallible,
) -> std::convert::Infallible {
match (a, b) {}
}
```
Fails on 1.66.1 with:
```none
error[E0004]: non-exhaustive patterns: type `(Infallible, Infallible)` is non-empty
--> src/lib.rs:9:11
|
9 | match (a, b) {}
| ^^^^^^
|
= note: the matched value is of type `(Infallible, Infallible)`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern as shown
|
9 ~ match (a, b) {
10+ _ => todo!(),
11+ }
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `playground` due to previous error
```
Compiles on nightly (`1.69.0-nightly (2023-01-22 5e37043d63bfe2f3be8f)`) with `#![feature(exhaustive_patterns)]`.
Playground link for [stable version](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=75634bf7f86e7514c2b8a03b833afe47), [nightly version](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=7fdc1d9f254b225fbfcad7059cfb11f2).
This actually is from real production code — the original (callback-like) functions were generic, and we wanted compilation fail if the type parameters (used not-very-closely to the function definition) ever changed from `Infallible`. (Also it's nice in an abstract, self-documenting-code way.) So using eg. `(_, _) => unreachable!()` does not achieve this, nor does `(a, b) => a` (eg. both compile if the types are set to `u8` instead of `Infallible`).<|endoftext|>A stabilization PR has been opened: #110105 | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>A-patterns<|endoftext|>A-exhaustiveness-checking<|endoftext|>S-tracking-needs-summary<|endoftext|>F-exhaustive_patterns | 21 | https://api.github.com/repos/rust-lang/rust/issues/51085 | https://github.com/rust-lang/rust/issues/51085 | https://api.github.com/repos/rust-lang/rust/issues/51085/comments |
297,168,206 | 48,214 | Tracking issue for RFC #2056: Allow trivial constraints to appear in where clauses | This is a tracking issue for the RFC "Allow trivial constraints to appear in where clauses " (rust-lang/rfcs#2056).
**Steps:**
- [x] Implement the RFC – https://github.com/rust-lang/rust/pull/48557
- [ ] As noted in https://github.com/rust-lang/rust/issues/48214#issuecomment-396038764, Chalk would solve a few issues with this feature, so this is currently blocked on Chalk integration
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- [ ] Should the lint error by default instead of warn? | I'm working on this.<|endoftext|>@matthewjasper ok. I've not thought hard about what it will take to support this. I had thought about doing it after making some more progress on general trait refactoring, but if it can be easily supported today seems fine.<|endoftext|>Oh, I meant to add, please ping me on IRC/gitter with any questions! I can try to carve out some time to think about it as well.<|endoftext|>So with #51042 merged this feature is implemented on nightly, but the implementation isn't particularly clean and there are some edge cases that don't work as one would expect:
```rust
#![feature(trivial_bounds)]
struct A;
trait X<T> {
fn test(&self, t: T) {}
}
impl X<i32> for A {}
fn foo(a: A) where A: X<i64> {
a.test(1i64); // expected i32, found i64
}
```
Since Chalk might be able to fix some of these issues, I think that this feature is now waiting for Chalk to be integrated.
edit: As of 2018-12-28 `-Zchalk` does not currently solve this issue.<|endoftext|>As another concrete example where trivially false constraints arise due to macros, see https://github.com/taiki-e/pin-project/issues/102#issuecomment-540472282. That crate now carries a weird hack to work around this limitation.
What is the current status of this feature?<|endoftext|>Not much has changed since my last comment.<|endoftext|>The current implementation generates a warning when using the pre-existing impl trait syntax, which, reading the RFC, I assume is a false-positive.
```rust
#![allow(dead_code, unused_variables,)]
#![feature(trait_alias, trivial_bounds)]
trait T = Fn(&i32, &i32) -> bool;
fn impl_trait_fn() -> impl T {
|a: &i32, b: &i32| true
}
```
This code generates the warning `warning: Trait bound impl T: T does not depend on any type or lifetime parameters`. ([playground link](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=67ca79f3a3387951aa3de5e477b066cb))
<|endoftext|>I think this change could cause problems with some proc-macros that rely on
```rust
struct _AssertCopy where String: ::core::marker::Copy;
```
to not compile, like @ExpHP wrote in https://github.com/rust-lang/rfcs/pull/2056
> To play devil's advocate, I do have to wonder if some crates may have popped up since 1.7 that rely on these errors as a form of static assertion about what traits are implemented (as the author was likely unaware that trivially true bounds were intended to produce compiler errors). Out of concern for this, I might lean towards "warn by default", since macros can easily disable the warnings in their output.
but I can not comprehend why this should be warn by default as this would break existing proc-macros that rely on this behavior?
I can say for a fact that there are definitely crates that rely on this behavior, because I recently published my first proc-macro ([`shorthand`](https://github.com/Luro02/shorthand)), which does rely on this behavior and I saw those assertions (`struct __AssertCopy where String: ::core::marker::Copy;`) in some crates and adopted it into my own crate.
I think most of those assertions are only used to make better error messages.
For example my proc-macro emits
```rust
struct _AssertCopy where String: ::core::marker::Copy;
```
which is spanned around the field of a struct and this creates this error message:
```
error[E0277]: the trait bound `std::string::String: std::marker::Copy` is not satisfied
--> $DIR/not_copy.rs:6:12
|
6 | value: String,
| ^^^^^^ the trait `std::marker::Copy` is not implemented for `std::string::String`
|
= help: see issue #48214
= help: add `#![feature(trivial_bounds)]` to the crate attributes to enable
```
I would say this lint should be deny by default to keep backwards compatibility.<|endoftext|>@Luro02 What else do you generate? Does your proc macro use `unsafe` and would it do the wrong thing without that "doesn't implement `Copy`" error?
If so why not put the bound on some `impl` or `fn` that would misbehave?
That would actually protect it, unlike an unrelated and unused type definition.
(Alternatively, just use `_AssertCopy` somewhere in your `unsafe` code)<|endoftext|>@eddyb Nope, in my case it is not using any unsafe code and it would not do the wrong thing, but who knows some macro might use this as a guard. For example one could have an attribute like this:
```rust
#[only(copy)]
struct Example {
field: String, // error because not copy
}
```
this would silently be accepted.
> Alternatively, just use _AssertCopy somewhere in your unsafe code
does this mean, that trivial bounds do not compile in unsafe code? 🤔
The unrelated/unused type definiton is there to get a specific error message (like `String does not implement Copy` instead of `can not move String because it does not implement Copy`)
> If so why not put the bound on some impl or fn that would misbehave?
I think this would still compile/ignore the bound
`fn value(&self) where String: Copy` and it is a bit more difficult, than simply emitting a line in the function body.<|endoftext|>I think the suggestion to "just use the bound somewhere in code" means emitting something like:
```rust
struct _AssertCopy where String: ::core::marker::Copy;
let _: _AssertCopy;
```
There is no way this would compile with an unsatisfied bound.<|endoftext|>> does this mean, that trivial bounds do not compile in unsafe code? thinking
No, @dtolnay explained what I meant. I was expecting you had `unsafe` code, but it sounds like you're just using it to get better diagnostics, which makes it less tricky of a situation.
> I think this would still compile/ignore the bound
If it doesn't error when compiling the function, it *will* error when trying to use it.
It's *not* going to let you call the function without erroring.<|endoftext|>Just ran into this issue while implementing a derive macro `Delta` that derives a trait `DeltaOps` that:
1. has an associated type `DeltaOps::Delta`
2. has nontrivial bounds on `Self`
3. has nontrivial bounds on `DeltaOps::Delta`
4. and is implemented for (among others) mutually recursive `enum`s.
That caused an overflow in the compiler, with compile errors like this one:
```
error[E0275]: overflow evaluating the requirement `rule::Expr: struct_delta_trait::DeltaOps`
--> src/parser.rs:26:10
|
26 | #[derive(struct_delta_derive::Delta)]
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `std::vec::Vec<rule::Expr>`
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `rule::Rule`
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `std::borrow::Cow<'static, rule::Rule>`
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `stack::StackFrame`
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `std::vec::Vec<stack::StackFrame>`
= note: required because of the requirements on the impl of `struct_delta_trait::DeltaOps` for `stack::Stack`
= help: see issue #48214
= help: add `#![feature(trivial_bounds)]` to the crate attributes to enable
= note: this error originates in a derive macro (in Nightly builds, run with -Z macro-backtrace for more info)
```
As you can see, the compiler gave me a suggestion to use `#![feature(trivial_bounds)]` in my crate.
My question is, will that actually work i.e. will it solve the overflow problem with bounds checking on recursive types without breaking stable functionality?<|endoftext|>There might be a potential drawback we haven't discussed yet. The proposed API guideline for asserting on trait impls may not be applied if this feature is landed, cc https://github.com/rust-lang/api-guidelines/issues/223<|endoftext|>There's a particular pain point in the trait system that this feature assists with: impossible-to-satisfy bounds on impls of trait items.
It's standard practice to have some items on a trait "opt-out" of making the trait object-unsafe with a `where Self: Sized` bound. But what if you're implementing on a concrete DST?
```rust
trait Foo {
fn foo() -> Self where Self: Sized;
fn bar(&self);
}
impl Foo for str {
// We can't compile without defining *something* for foo, even though it could never be called!
fn bar(&self) {
println!("bar");
}
}
```
Theoretically, we **shouldn't** have to specify `fn foo` for our `impl Foo for str`, but the compiler doesn't (yet) remove trivially-impossible bounds from the list of items that must be implemented.
With `#![feature(trivial_bounds)]`, this is the simplest way to be able to define `impl Foo for str`: by just copying the impossible bound:
```rust
// We can never call `foo`, but we can `impl Foo for str`!
fn foo() -> str where str: Sized {
unreachable!()
}
```
There is, however, a hacky workaround: you can specify trivial constraints on stable Rust with an unused [HRTB][hrtb]:
```rust
fn foo() -> str where for<'a> str: Sized {
unreachable!()
}
```
Given the existence of this workaround, I see no reason that this feature should be left unstable for some simple cases. Additionally, I believe if there is a lint, it should be a warning or allow by default, unless it has special detection of this scenario.
*Note: this problem only applies to impls on concrete types, the following works:*
```rust
impl<T> Foo for [T] {
// does not require `#![feature(trivial_bounds)]`
fn foo() -> Self where Self: Sized {
unreachable!()
}
fn bar(&self) {
}
}
```
[hrtb]: https://doc.rust-lang.org/nomicon/hrtb.html<|endoftext|>The current *stable* status of this is that **true** trivial bounds are allowed with *no warning*, and **false** trivial bounds are rejected as an unfulfilled obligation.
For this reason, I think the `trivial_bounds` lint should be split into two. Specifically, I think the following code:
```rust
trait Trait {}
struct No;
struct Yes;
impl Trait for Yes {}
struct S1;
struct S2;
impl Trait for S1 where Yes: Trait {}
impl Trait for S2 where No: Trait {}
```
should have a result similar to the following:
```
warning: trait bound Yes: Trait does not depend on any type or lifetime parameters
--> src/lib.rs:12:30
|
12 | impl Trait for S1 where Yes: Trait {}
| ^^^^^
|
= note: this bound always holds
= note: `#[warn(trivially_true_bounds)]` on by default
error: trait bound No: Trait does not depend on any type or lifetime parameters
--> src/lib.rs:13:29
|
13 | impl Trait for S2 where No: Trait {}
| ^^^^^
|
= note: this bound never holds
= note: `#[error(trivially_false_bounds)]` on by default
```
<details><summary>Current result with <code>feature(trivial_bounds)</code></summary>
```
warning: trait bound Yes: Trait does not depend on any type or lifetime parameters
--> src/lib.rs:12:30
|
12 | impl Trait for S1 where Yes: Trait {}
| ^^^^^
|
= note: `#[warn(trivial_bounds)]` on by default
warning: trait bound No: Trait does not depend on any type or lifetime parameters
--> src/lib.rs:13:29
|
13 | impl Trait for S2 where No: Trait {}
| ^^^^^
```
</details>
This means that the default behavior of what code compiles stays the same, and still informs authors of ineffective bounds. The rationale for blocking compilation on a trivially false bound is that it is likely incorrect (thus the lint) and as this results in a missing trait impl, will likely cause other errors to block compilation. A trivially true bound, while still likely incorrect (thus the lint), is much less likely to cause a compilation failure (if the trait impl succeeds) and thus a `deny` would get in the way of the edit-compile-test[^2] cycle.
[^2]: Well, the cycle already contains more error message cycles than in dynamic languages, but the general arguments for most lints being warn by default with high signal-noise warning ratio still stand.
Authors of derives using `where` to register obligations can then use `#[allow(unknown_lints)] #[allow(trivially_true_bounds)] #[deny(trivially_false_bounds)]` to keep the current behavior where a failed derive errors, or switch to another method[^1] of registering obligations. Note that `where` based obligations *are* being used for deriving `unsafe impl` in the ecosystem. This isn't a soundness issue, though, since the failure case is just the impl not applying.
[^1]: [My current preferred method](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=136cc591633a2822eafa233226159266) is to define a generic `fn` (inside a `const _` context to avoid namespace pollution) with the same signature as the type and then using an `assert_impl_trait_val(&this.field)` for each field. [dtolnay's version](https://github.com/rust-lang/rust/issues/48214#issuecomment-586734105) works for true trivial bounds, but generic field type bounds still need to be handled by a derive, and can themselves potentially be trivial (trivial example: `for<T> T:`).<|endoftext|>> Theoretically, we **shouldn't** have to specify `fn foo` for our `impl Foo for str`, but the compiler doesn't (yet) remove trivially-impossible bounds from the list of items that must be implemented.
I would argue, to the contrary, that the compiler should *not* make your life easier in this instance, because `Self` bounds on trait methods without default impls are an anti-pattern and should be discouraged, even linted against IMO. The reason I think such code is questionable is that it means that if type `A` starts implementing trait `T`, that can suddenly invalidate its implementation of trait `U` because `U` had a `where Self: T` trait method with no default impl. Such code also makes it harder for traits to take advantage of extensions to `dyn`-safety without breaking implementers (as I brought up in an [IRLO thread](https://internals.rust-lang.org/t/removing-self-sized-and-backward-compatibility/17456)). The proper way to write this code is to either provide a default impl or have two separate traits.<|endoftext|>FWIW, having a proc-macro that uses syn's `DeriveInput.generics.split_for_impl()` with a recursive struct generates code like this, which triggers this issue:
```rust
trait Trait {}
struct Foo {
inner: Option<Box<Foo>>,
}
impl Trait for Foo
where Option<Box<Foo>>: Trait // the problematic line
{}
impl<T: Trait> Trait for Option<T> {}
impl<T: Trait> Trait for Box<T> {}
```
[playground link](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=3821b31510b653cdd0ee377446b005eb)
That said I'm not sure whether that's a syn bug or something actually coming from TokenStream itself. In both cases, changing the behavior would seem pretty hard, considering it'd be a breaking change.
To be quite honest, I'm not sure what the expected workaround would be, as this line does seem to be necessary in the general case. Does anyone know how proc macro authors are supposed to work around this? I can see serde does avoid setting this bound so there should be a way, but TBH I don't understand most of the source code there.<|endoftext|>@Ekleog
As explained in the comment RalfJung [mentioned](https://github.com/rust-lang/rust/issues/48214#issuecomment-541461367), you can work around this by using wrapper type with lifetime or generics: https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=f04192e77a9ae36bf3df07e61027d638
(To be exact, it delays the evaluation until actually used)
As for serde, they do not specify trait bounds in the where clause for non-generic types in the first place: https://github.com/serde-rs/serde/blob/6b948111ca56bb5cfd447f8516dea5fe1338e552/test_suite/tests/expand/de_enum.expanded.rs#L18-L20
(Since the trait method call will fail if the trait is not implemented, that is fine.)<|endoftext|>@taiki-e I'm not sure I understand how the comment you link is applicable to a proc-macro author situation. It seems to me that the end-user would have to add a lifetime to their struct, which would make it much less ergonomic?
If the serde way is actually the only one for proc-macro authors, then I guess we're missing a crate to reimplement the serde way of sorting between the clauses that actually need to be passed through (because of actual generics) and the clauses that are trivial, so that not all proc-macro authors need to reimplement a visitor like serde :/<|endoftext|>@Ekleog
> the end-user would have to add a lifetime to their struct
No, I meant that the macro generates a where clause with trait bounds with a wrapper type.
> If the serde way is actually the only one for proc-macro authors, then I guess we're missing a crate to reimplement the serde way of sorting between the clauses that actually need to be passed through (because of actual generics) and the clauses that are trivial, so that not all proc-macro authors need to reimplement a visitor like serde :/
AFAIK, what serde actually does is the same as what the derive macros in the standard library do: they refer to type parameters in generics rather than field types. Therefore, there is no need for a filter/visitor. (see https://github.com/rust-lang/rust/issues/26925 for more)<|endoftext|>> No, I meant that the macro generates a where clause with trait bounds with a wrapper type.
Oh ok I think I understand now!
> AFAIK, what serde actually does is the same as what the derive macros in the standard library do: they refer to type parameters in generics rather than field types. Therefore, there is no need for a filter/visitor. (see https://github.com/rust-lang/rust/issues/26925 for more)
Hmm I guess the choice is then currently between having the issues listed in #26925 and being unable to derive on recursive structs, until someone designs a way to filter only on types that depend on actual generic arguments or this issue is fixed. Or to use the wrapper type trick to delay execution, but that probably can't be generalized to any crate.
I'm curious, do you know why the default with proc-macro + syn seems to be "unable to derive on recursive structs"? (I'm referring to the fact that [this simple code](https://github.com/camshaft/bolero/blob/master/bolero-generator-derive/src/lib.rs#L44-L47), where `generics` comes straight from DeriveInput, seems to set default where bounds based on field types)<|endoftext|>> Hmm I guess the choice is then currently between having the issues listed in #26925 and being unable to derive on recursive structs, until someone designs a way to filter only on types that depend on actual generic arguments or this issue is fixed. Or to use the wrapper type trick to delay execution, but that probably can't be generalized to any crate.
Well, even if the filter were implemented, I don't think the approach of using field types at the bounds of the where clause would work in some cases. e.g., that approach still does not interact well with structs that have private types. (see https://github.com/rust-lang/rust/issues/48054 for more. [there is a workaround for that problem](https://github.com/taiki-e/pin-project/pull/53) as well, but IIRC that workaround only works with auto-traits)
EDIT: see also https://github.com/dtolnay/syn/issues/370
> [this simple code](https://github.com/camshaft/bolero/blob/master/bolero-generator-derive/src/lib.rs#L44-L47)
Those lines are not causing the problem. The problem is that the way of changing the where clause in the [`generate_fields_type_gen`](https://github.com/camshaft/bolero/blob/724818c641e4e3d4a2831752093cc3607d2c711f/bolero-generator-derive/src/lib.rs#L41) does not work well with the current Rust's type system.
<|endoftext|>> it'd be a breaking change
Just to clarify the space here a bit,
- Turning a trait implementation which errors into a trait implementation which compiles but is unsatisfiable / never applies is unfortunate, but not breaking.
- Turning a trait implementation which errors into a trait implementation which compiles and is satisfiable / can be utilized is a breaking change, though arguably a bug fix and allowable.
It becomes breaking because code generation could rely on code not compiling to enforce soundness constraints. However, this applies to literally any change which results in more code compiling; the code generation which is broken by such a change was only tenuously sound in the first place, as it was relying on a satisfiable bound actually being unsatisfiable (an error).
The former case is provably sound and does not break; the impl is bounded on the condition which makes the impl sound, and if that condition does not hold, the impl does not apply. The "minor breaking" change is that the unsatisfiable impl goes from an immediate error on definition to only an error when trying to use the impl; this delayed communication is why I've suggested that trivially false bounds could be a deny-by-default lint.<|endoftext|>@taiki-e
> Those lines are not causing the problem. The problem is that the way of changing the where clause in the [generate_fields_type_gen](https://github.com/camshaft/bolero/blob/724818c641e4e3d4a2831752093cc3607d2c711f/bolero-generator-derive/src/lib.rs#L41) does not work well with the current Rust's type system.
Oh… I'm stupid I had missed the fact that `make_where_clause` returns a mutable reference… Sorry for the noise, and thank you!
(And so, for @CAD97 this explains why I was saying it was a breaking change in my message: I was thinking this behavior was coming from either syn or rustc, which was a wrong assumption)<|endoftext|>I'm trying to figure out the current state of this feature. What's the current status of `trivial_bounds`? Are there still blocking issues that would prevent this from being stabilized? Or does this just need a stabilization report and FCP?
The last update I found about blocking concerns, across the several issues about this, seems to be from 2019 talking about limitations in chalk.<|endoftext|>Just to add, I approve of the attributes here: https://github.com/rust-lang/rust/issues/48214#issuecomment-1164805614
I want to conditionally implement a Trait in a derive macro on a "transparent" wrapper style new-type depending on if a given Trait is implemented on the inner type. Naively making use of a `where <concrete_inner_type>: Trait` would allow for this behaviour, but the warns/compile errors get in the way.
I'd love to be able to add the where clause and for the above to _just work_ - and the two annotations would allow this to work as-expected:
```
#[allow(trivially_false_bounds)]
#[allow(trivially_true_bounds)]
```
This would allow an easy way for macro-writers to avoid the problem of handling generics and avoiding https://github.com/rust-lang/rust/issues/26925
As a work-around in my case, I'll try introducing some new trait `Wrapped` with associated type `Inner = X` and add a blanket impl of Trait for `Wrapped<Inner: Trait>` - but other cases don't have such clear work-arounds. EDIT: Doesn't really work because standard impls of `Trait` fail with:
```
conflicting implementations of trait `Trait` for type `T`
downstream crates may implement trait `Wrapped<_>` for type `T`
```
EDIT: Looks like this workaround should work: https://github.com/rust-lang/rust/issues/48214#issuecomment-1374378038<|endoftext|>ran into this issue when trying to serialize my type with:
```
#[derive(borsh::BorshSerialize, borsh::BorshDeserialize)]
struct MyType {
range: RangeInclusive<u32>
...
}
``` | B-RFC-approved<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-impl-incomplete<|endoftext|>S-tracking-needs-summary | 28 | https://api.github.com/repos/rust-lang/rust/issues/48214 | https://github.com/rust-lang/rust/issues/48214 | https://api.github.com/repos/rust-lang/rust/issues/48214/comments |
295,232,972 | 48,055 | Tracking issue for RFC #1909: Unsized Rvalues | This is a tracking issue for the RFC "Unsized Rvalues " (rust-lang/rfcs#1909).
**Steps:**
- [ ] Implement the RFC (cc @rust-lang/compiler -- can anyone write up mentoring instructions?)
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Related bugs:**
- [ ] https://github.com/rust-lang/rust/issues/61335 -- ICE when combined with async-await
- [x] https://github.com/rust-lang/rust/issues/68304 --
`Box<dyn FnOnce>` doesn't respect self alignment
**Unresolved questions:**
- [ ] Can we carve out a path of "guaranteed no alloca" optimization? (See #68304 for some related discussion)
- [ ] Given that LLVM doesn't seem to support alloca with alignment, how do we expect to respect alignment limitations? (See #68304 for one specific instance)
- [ ] How can we mitigate the risk of unintended unsized or large allocas? Note that the problem already exists today with large structs/arrays. A MIR lint against large/variable stack sizes would probably help users avoid these stack overflows. Do we want it in Clippy? rustc?
- [ ] How do we handle truely-unsized DSTs when we get them? They can theoretically be passed to functions, but they can never be put in temporaries.
- [ ] Decide on a concrete syntax for VLAs.
- [ ] What about the [interactions between async-await/generators and unsized locals](https://github.com/rust-lang/rust/issues/48055#issuecomment-583743014)?
- [ ] We currently allow `extern type` arguments with `unsized_fn_params`, but that does not make *that* much sense. | > How do we handle truely-unsized DSTs when we get them?
@aturon: Are you referring to `extern type`?<|endoftext|>@Aaron1011 that was copied straight from the RFC. But yes, I presume that's what it's referring to.<|endoftext|>Why would unsized temporaries ever be necessary? The only way it would make sense to pass them as arguments would be by fat pointer, and I cannot think of a situation that would require the memory to be copied/moved. They cannot be assigned or returned from functions under the RFC. Unsized local variables could also be treated as pointers.
In other words, is there any reason why unsized temporary elision shouldn't be always guaranteed?<|endoftext|>Is there any progress on this issue?
I'm trying to implement VLA in the compiler. For the AST and HIR part, I added a new enum member for `syntax::ast::ExprKind::Repeat` and `hir::Expr_::ExprRepeat` to save the count expression as below:
```rust
enum RepeatSyntax { Dyn, None }
syntax::ast::ExprKind::Repeat(P<Expr>, P<Expr>, RepeatSyntax)
enum RepeatExprCount {
Const(BodyId),
Dyn(P<Expr>),
}
hir::Expr_::ExprRepeat(P<Expr>, RepeatExprCount)
```
But for the MIR part, I have no idea how to construct a correct MIR. Should I update the structure of `mir::RValue::Repeat` and corresponding `trans_rvalue` function? What should they look like? What is the expected LLVM-IR?
Thanks in advance if someone would like to write a simple mentoring instruction.<|endoftext|>I'm trying to remove the `Sized` bounds and translate MIRs accordingly.<|endoftext|>An alternative that would solve both of the unresolved questions would be explicit `&move` references. We could have an explicit `alloca!` expression that returns `&move T`, and truly unsized types work with `&move T` because it is just a pointer.
If I remember correctly, the main reason for this RFC was to get `dyn FnOnce()` to be callable. Since `FnOnce()` is not implementable in stable Rust, would it be a backward-compatible change to make `FnOnce::call_once` take `&move Self` instead? If that was the case, then we could make `&move FnOnce()` be callable, as well as `Box<FnOnce()>` (via `DerefMove`).
cc @arielb1 (RFC author) @qnighy (currently implementing this RFC in #51131) @eddyb (knows a lot about this stuff)<|endoftext|>@mikeyhew There's not really much of a problem with making by-value `self` work and IMO it's more ergonomic anyway. We might eventually even have `DerefMove` without `&move` at all.<|endoftext|>@eddyb
I guess I can see why people think it's more ergonomic: in order to opt into it, you just have to add `?Sized` to your function signature, or in the case of trait methods, do nothing. And maybe it will help new users of the language, since `&move` wouldn't be show up in documentation everywhere.
If we're going to go ahead with this implicit syntax, then there are a few details that would be good to nail down:
- If this is syntactic sugar for `&move` references, what does it desugar too? For function arguments, this could be pretty straightforward: the lifetime of the reference would be limited to the function call, and if you want to extend it past that, you'd have to use explicit `&move` references. So
```rust
fn call_once(f: FnOnce(i32))) -> i32
```
desugars too
```rust
fn call_once(f: &move FnOnce(i32)) -> i32
```
and you can call the function directly on its argument, so `foo(|x| x + 1)` desugars to `foo(&move (|x| x + 1))`.
And to do something fancier, you'd have to resort to the explicit version:
```rust
fn make_owned_pin<'a, T: 'a + ?Sized>(value: &'a move T) -> PinMove<'a, T> { ... }
struct Thunk<'a> {
f: &'a move FnOnce()
}
```
Given the above semantics, `DerefMove` could be expressed using unsized rvalues, as you said:
**EDIT**: This is kind of sketchy though. What happens if the implementation is wrong, and doesn't call `f`?
```rust
// this is the "closure" version of DerefMove. The alternative would be to have an associated type
// `Cleanup` and return `(Self::Target, Self::Cleanup)`, but that wouldn't work with unsized
// rvalues because you can't return a DST by value
fn deref_move<F: FnOnce(Self::Target) -> O, O>(self, f: F) -> O;
// explicit form
fn deref_move<F: for<'a>FnOnce(&'a move Self::Target) -> O, O>(&'a move self, f: F) -> O;
```
I should probably write an RFC for this.
- When do there need to be implicit allocas? I can't actually think of a case where an implicit alloca would be needed. Any function arguments would last as long as the function does, and wouldn't need to be alloca'd. Maybe something involving stack-allocated dynamic arrays, if they are returned from a block, but I'm pretty sure that's explicitly disallowed by the RFC.
<|endoftext|>@eddyb have you seen @alercah's RFC for DerefMove? https://github.com/rust-lang/rfcs/pull/2439<|endoftext|>As a next step, I'll be working on trait object safety.<|endoftext|>@mikeyhew Sadly @alercah just postponed their `DerefMove` RFC, but I think a separate RFC for `&move` that complements that (when it does get revived) would be very much desirable. I would be glad to assist with that even, if you're interested.<|endoftext|>@alexreg I would definitely appreciate your help, if I end up writing an RFC for `&move`.
The idea I have so far is to treat unsized rvalues as a sort of sugar for `&move` references with an implicit lifetime. So if a function argument has type `T`, it will be either be passed by value (if `T` is `Sized`) or as a `&'a move T`, and the lifetime `'a` of the reference will outlive the function call, but we can't assume any more than that. For an unsized local variable, the lifetime would be the variable's scope. If you want something that lives longer than that, e.g. you want to take an unsized value and return it, you'd have to use an explicit `&move` reference so that the borrow checker can make sure it lives long enough.<|endoftext|>@mikeyhew That sounds like a reasonable approach to me. Has anyone specified the supposed semantics of `&move` yet, even informally? (Also, I'm not sure if bikeshedding on this has already been done, but we should probably consider calling it `&own`.)<|endoftext|>Not sure if this is the right place to document this, but I found a way to make a subset of unsized returns (technically, all of them, given a `T -> Box<T>` lang item) work without ABI (LLVM) support:
* only `Rust` ABI functions can return unsized types
* instead of passing a return pointer in the call ABI, we pass a return *continuation*
* we can already pass unsized values to functions, so if we could CPS-convert Rust functions (or wanted to), we'd be done (at the cost of a stack that keeps growing)
* @nikomatsakis came up with something similar (but only for `Box`) a few years ago
* however, only the callee (potentially a virtual method) needs to be CPS-*like*, and only in the ABI, the callers can be restricted and/or rely on dynamic allocation, *not* get CPS-transformed
* while `Clone` becoming object-safe is harder, this is an alright starting point:
```rust
// Rust definitions
trait CloneAs<T: ?Sized> {
fn clone_as(&self) -> T;
}
impl<T: Trait + Clone> CloneAs<dyn Trait> for T {
fn clone_as(&self) -> dyn Trait { self.clone() }
}
trait Trait: CloneAs<dyn Trait> {}
```
```rust
// Call ABI signature for `<dyn Trait as CloneAs<dyn Trait>>::clone_as`
fn(
// opaque pointer passed to `ret` as the first argument
ret_opaque: *(),
// called to return the unsized value
ret: fn(
// `ret_opaque` from above
opaque: *(),
// the `dyn Trait` return value's components
ptr: *(), vtable: *(),
) -> (),
// `self: &dyn Trait`'s components
self_ptr: *(), self_vtable: *(),
) -> ()
```
* the caller would use the `ret_opaque` pointer to pass one or more sized values to its stack frame
* could allow `ret` return one or two pointer-sized values, but that's an optional optimization
* we can start by allowing composed calls, of this MIR shape:
```rust
y = call f(x); // returns an unsized value
z = call g(y); // takes the unsized value and returns a sized one
```
```rust
// by compiling it into:
f(&mut z, |z, y| { *z = call g(y); }, x)
```
* this should work out of the box for `{Box,Rc,...}::new(obj.clone_as())`
* while we could extract entire portions of the MIR into these "return continuations", that's not necessary for being able to express most things: worst case, you write a separate function
* since `Box::new` works, anything with a global allocator around could fall back to *that*
* `let y = f(x);` would work as well as `let y = *Box::new(f(x));`
* its cost *might* be a bit high, but so would that of a proper "unsized return" ABI
* we can, at any point, switch to an ABI where e.g. the value is copied onto the caller's stack, effectively "extending it on return", and there shouldn't be any observable differences
cc @rust-lang/compiler <|endoftext|>@alexreg
>Has anyone specified the supposed semantics of &move yet, even informally?
I don't think it's been formally specified. Informally, `&'a move T` is a reference that owns its `T`. It's like
- an `&'a mut T` that owns the `T` instead of mutably borrowing it, and therefore drops the `T` when dropped, or
- a `Box<T>` that is only valid for the lifetime `'a`, and doesn't free heap allocated memory when dropped (but still drops the `T`).
> (Also, I'm not sure if bikeshedding on this has already been done, but we should probably consider calling it &own.)
Don't think that bikeshed has been painted yet. I guess `&own` is better. It requires a new keyword, but afaik it can be a contextual keyword, and it more accurately describes what is going on. Often times you would use it to *avoid* moving something in memory, so calling it `&move T` would be confusing, and plus there's the problem of `&move ||{}`, which looks like `&move (||{})` but would have to mean `& (move ||{})` for backward compatibility.<|endoftext|>@mikeyhew Oh, I'm sorry I haven't replied to the `&move` thread, only noticed just now that some of it was addressed at me. I don't think `&move` is a good *desugaring* for unsized values.
At most, `&move T` (*without* an explicit lifetime), is an *ABI detail* of passing down a `T` argument "by reference" - we already do this for types larger than registers, and it naturally extends to unsized `T`.
And even with `&move T` in the language, you don't get a mechanism for *returning* "detached" ownership of an unsized value, based solely on it, as returning `&'a move T` means the `T` value *must* live "higher-up" (i.e. `'a` is for how long *the caller* provided the memory space for the `T` value).
My previous comment, https://github.com/rust-lang/rust/issues/48055#issuecomment-415980600 provides *one* such mechanism, that we can implement *today* (others exist but require e.g. adding a new calling convention to LLVM).
Only one such mechanism, if general enough to support all *callees* (of `Rust` ABI), is needed, in order to support the surface-level feature, and its details can/should remain implementation-defined.
<hr/>
So IMO `&move T` is orthogonal and the only intersection here is that it "happens to" match what some ABIs do when they have to pass large (or in this case, of unknown size) values in calls.
I *do want* something *like* `&move T` for opting into `Box`'s behavior from any library etc. but not for this.<|endoftext|>@eddyb
Automatic boxing by the compiler feels weird to me (it occurs *only* in this special case), and people will do `MyRef::new(x.clone(), do_xyz()?)`, which feels like it would require autoboxing to implement sanely.
However, we can force unsized returns to always happen the "right way" (i.e., to immediately be passed to a function with an unsized parameter) by a check in MIR. Maybe we should do that?<|endoftext|>@arielb1 Yes, I'm suggesting that we can start with that MIR check and *maybe* add autoboxing *if* we want to (and *only* if an allocator is even available).<|endoftext|>A check that the unsized return value is immediately passed to another function, which can then be CPS'd without all the usual problems of CPS in Rust, sounds like it would work well enough technically. However, the user experience might be non-obvious:
- The restriction on what to do with the return value can be learned, but is still weird
- Having to CPS-transform manually in more complex scenarios is quite annoying
- It affects peak stack usage in a way that is not visible from the source code and completely surprising unless one knows how it's implemented
I think it's worthwhile thinking long and hard whether there might be more tailored features that address the usage patterns that we want to enable with unsized return values. For example, cloning trait objects might also be achieved by extending `box`.<|endoftext|>@rkruppe If we can manage to "pass" unsized values down the stack without actually copying them, I don't think the stack usage should actually increase from what you would need to e.g. call `Box::new`.
> For example, cloning trait objects might also be achieved by extending `box`.
Sure, but, AFAIK, all ideas, until now, for "emplace" / boxing, seemed to involve generics, whereas my scheme operates at the ABI level and requires making no assumptions about the unsized type.
(e.g. @nikomatsakis' previous ideas relied on the fact that `Clone::clone` returns `Self`, *therefore*, you can get the size/alignment from its `self` value, and allocate the destination *before* calling it)<|endoftext|>> @rkruppe If we can manage to "pass" unsized values down the stack without actually copying them, I don't think the stack usage should actually increase from what you would need to e.g. call Box::new.
The stack size increase is not from the unsized value but from the rest of the stack frame of the unsized-value-returning function. For example,
```rust
fn new() -> dyn Debug {
let _buf1 = [0u8; 1 << 10]; // this remains allocated "after returning" ...
"hello world" // ... because here we actually call take()
}
fn take(arg: dyn Debug) {
let _buf2 = [0u8; 1 << 10];
println!("{:?}", arg);
}
fn foo() {
take(new()); // 2 KB peak stack usage, not 1 KB
}
```
(And we can't do tail call optimization because `new` is passing a pointer to its stack frame to the continuation, so its stack frame needs to be preserved until after the call.)<|endoftext|>@rkruppe I assume you meant `take` instead of `arg`?
~~However, I think you need to take into account that `_buf1` *is not live* when the the function returns, and continuation get called. At that point, only a copy of `"hello world"` should be left on the stack.~~
~~In other words, your `new` function is entirely equivalent to this:~~
```rust
fn new() -> dyn Debug {
let return_value: dyn Debug = {
let _buf1 = [0u8; 1 << 10];
"hello world"
};
return_value
}
```
**EDIT**: @rkruppe clarified below.<|endoftext|>We discussed on IRC, for the record: LLVM does not shrink the stack frame (by adjusting the stack pointer), not ever for static allocs and only on explicit request (stacksave/stackrestore intrinsics) for dynamic allocas.<|endoftext|>@eddyb would you help me with design decision? For by-value trait object safety, I need to insert shims to force the receiver to be passed by reference in the ABI. For example, for
```rust
trait Foo {
fn foo(self);
}
```
to be object safe, `<Foo as Foo>::foo` should be able to call `<T as Foo>::foo` without knowing `T`. However, concrete `<T as Foo>::foo`s may receive `self` directly, making it difficult to call the method without knowledge of `T`. Therefore we need a shim of `<T as Foo>::foo` that always receives `self` indirectly.
The problem is: how do I introduce two instances of `<i32 as Foo>::foo` for example? AFAICT there are two ways:
1. Introduce a new DefPath `Foo::foo::{{vtable-shim}}`. This is rather straightforward but we'll need to change all the related IDs: `NodeId`, `HirId`, `DefId`, `Node`, and `DefPath`. This seems too much for mere shims.
2. Use the same DefPath `Foo::foo`, but include another salt for the symbol hash to distinguish it from the original `Foo::foo`. It still affects back to `rustc::ty` but will not change `syntax`.
I've been mainly working with the first approach, but am being attracted by the second one. I'd like to know if there are any circumstances that we should prefer either of these.<|endoftext|>I'd think you'd use a new variant in `InstanceDef`, and manually craft it, when creating the vtable. And in the MIR shim code, you'd need to habdle that new variant.
I would expect that would be enough for the symbols to be distinct (if not, that's a separate bug).<|endoftext|>With respect to the surface syntax for VLAs, I'm *highly* (to put it mildly) skeptical of permitting `[T; n]` because:
+ the risk of introducing accidental VLAs is too high particularly for folks who are used to `new int[n]` (Java).
+ `n` may be a `const n: usize` parameter and therefore "captures no variables" is not enough.
I'd suggest that we should use `[T; dyn expr]` or `[T; let expr]` to distinguish; this also has the advantage that you don't have to store anything in a temporary.
I'll add an unresolved question for this.<|endoftext|>`[T; dyn expr]` makes sense to me, for the reason you suggest.<|endoftext|>As #54183 is merged, `<dyn FnOnce>::call_once` is callable now! I'm going to work on these two things:
## Next step I: unsized temporary elision
As a next step, I'm thinking of implementing unsized temporary elision. I think we can do this as follows: firstly, we can restrict allocas to "unsized rvalue generation sites". The only unsized rvalue generation sites we already have are dereferences of `Box`. We can codegen other unsized rvalue assignments as mere copies of references.
In addition to that, we can probably infer lifetimes of each unsized rvalue using the borrow checker. Then, if the origin of an unsized rvalue generation site lives longer than required, we can elide the alloca there.
## Next step II: `Box<FnOnce>`
Not being exactly part of #48055, it would be useful to implement `FnOnce` for `Box<impl FnOnce>`. I think I can do this without making it insta-stable or immediately breaking `fnbox` #28796, thanks to specialization.<|endoftext|>@qnighy Great work. Thanks for your ongoing efforts with this... and I agree, those seem like good next steps to take.<|endoftext|>Ah, annotating a trait impl with `#[unstable]` doesn't make sense? `impl CoerceUnsized<NonNull<U>> for NonNull<T>` has one but doesn't show any message on the doc. It can be used without features. Does anyone have an idea to prevent `impl<F: FnOnce> FnOnce for Box<F>` from being insta-stable? | B-RFC-approved<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>F-unsized_locals<|endoftext|>F-unsized_fn_params<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 58 | https://api.github.com/repos/rust-lang/rust/issues/48055 | https://github.com/rust-lang/rust/issues/48055 | https://api.github.com/repos/rust-lang/rust/issues/48055/comments |
295,231,581 | 48,054 | Tracking issue for RFC #2145: Type privacy and private-in-public lints | This is a tracking issue for the RFC "Type privacy and private-in-public lints " (rust-lang/rfcs#2145).
**Steps:**
- [ ] Implement the RFC (cc @petrochenkov )
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- [ ] It's not fully clear if the restriction for associated type definitions required for
type privacy soundness, or it's just a workaround for a technical difficulty.
- [ ] Interactions between macros 2.0 and the notions of reachability / effective
visibility used for the lints are unclear.
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":"Aaron1011"}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END --> | @rustbot claim<|endoftext|>@petrochenkov: Oops - I didn't mean for that to un-assign you.
Is there a way to prevent these lints from becoming insta-stable? Would it make sense to put them behind a feature gate?<|endoftext|>Perhaps we could only fire the lints if an unstable compiler flag (maybe `-Z type-privacy-lints`) is passed? This would still make the lint names insta-stable, though.<|endoftext|>in core ffi
```
// The VaArgSafe trait needs to be used in public interfaces, however, the trait
// itself must not be allowed to be used outside this module. Allowing users to
// implement the trait for a new type (thereby allowing the va_arg intrinsic to
// be used on a new type) is likely to cause undefined behavior.
//
// FIXME(dlrobertson): In order to use the VaArgSafe trait in a public interface
// but also ensure it cannot be used elsewhere, the trait needs to be public
// within a private module. Once RFC 2145 has been implemented look into
// improving this.
mod sealed_trait {
/// Trait which permits the allowed types to be used with [super::VaListImpl::arg].
#[unstable(
feature = "c_variadic",
reason = "the `c_variadic` feature has not been properly tested on \
all supported platforms",
issue = "44930"
)]
pub trait VaArgSafe {}
}
```
There is a fixme about `RFC 2145`, how to fixes that?<|endoftext|>@lygstate
By implementing this RFC, I guess.
Until that workarounds like this sealed trait will need to be used.<|endoftext|>Where is the impl, the RFC is already accepted...<|endoftext|>> Where is the impl, the RFC is already accepted...
An RFC being accepted just means the feature *can* be implemented, not that it *has* been implemented. It doesn't even mean that implementing it is a priority.
I believe there has been more discussion of this RFC over at #34537 as well as other issues that I can't seem to track down right now.<|endoftext|>Hello! I know y'all are busy, but I'm curious if there's an update, particularly on `unnameable_types` for Voldemort Types - which I'd love to see. I was actually a bit surprised to find that it wasn't included in the existing `private_in_public` lint.
Appreciate the work that y'all are doing, especially @petrochenkov who seems to have put in a lot of legwork.<|endoftext|>@nipunn1313
The *tentative* plan is that @Bryanskiy will work on this in March-May.<|endoftext|>> @nipunn1313 The _tentative_ plan is that @Bryanskiy will work on this in March-May.
Cool! Good luck! I'm happy to be a guinea pig to try it out or do code review if that would be helpful. | A-lint<|endoftext|>A-visibility<|endoftext|>B-RFC-approved<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 10 | https://api.github.com/repos/rust-lang/rust/issues/48054 | https://github.com/rust-lang/rust/issues/48054 | https://api.github.com/repos/rust-lang/rust/issues/48054/comments |
260,766,278 | 44,874 | Tracking issue for `arbitrary_self_types` | Tracking issue for `#![feature(arbitrary_self_types)]`.
This needs an RFC before stabilization, and also requires the following issues to be handled:
- [ ] figure out the object safety situation
- [ ] figure out the handling of inference variables behind raw pointers
- [ ] decide whether we want safe virtual raw pointer methods
## Object Safety
See https://github.com/rust-lang/rust/issues/27941#issuecomment-332157526
## Handling of inference variables
Calling a method on `*const _` could now pick impls of the form
```Rust
impl RandomType {
fn foo(*const Self) {}
}
```
Because method dispatch wants to be "limited", this won't really work, and as with the existing situation on `&_` we should be emitting an "the type of this value must be known in this context" error.
This feels like fairly standard inference breakage, but we need to check the impact of this before proceeding.
## Safe virtual raw pointer methods
e.g. this is UB, so we might want to force the call `<dyn Foo as Foo>::bar` to be unsafe somehow - e.g. by not allowing `dyn Foo` to be object safe unless `bar` was an `unsafe fn`
```Rust
trait Foo {
fn bar(self: *const Self);
}
fn main() {
// creates a raw pointer with a garbage vtable
let foo: *const dyn Foo = unsafe { mem::transmute([0usize, 0x1000usize]) };
// and call it
foo.bar(); // this is UB
}
```
However, even today you could UB in safe code with `mem::size_of_val(foo)` on the above code, so this might not be actually a problem.
## More information
There's no reason the `self` syntax has to be restricted to `&T`, `&mut T` and `Box<T>`, we should allow for more types there, e.g.
```Rust
trait MyStuff {
fn do_async_task(self: Rc<Self>);
}
impl MyStuff for () {
fn do_async_task(self: Rc<Self>) {
// ...
}
}
Rc::new(()).do_async_stuff();
```
This doesn't have an RFC, but we want to experiment on this without one.
See #27941.
| Why would you need this?
Why wouldn't you write an impl like this:
```
impl MyStuff for Rc<()> {
fn do_async_task(self) {
// ...
}
}
```
I'd rather define the trait different. Maybe like this:
```
trait MyStuff: Rc {
fn do_async_task(self);
}
```
In this case, Rc would be a trait type. If every generic type implemented a specific trait (this could be implemented automatically for generic types) this seems more understandable to me.<|endoftext|>This could **only** be allowed for `trait` methods, right?
For inherent methods, I can't `impl Rc<MyType>`, but if `impl MyType` can add methods with `self: Rc<Self>`, it seems like that would enable weird method shadowing. <|endoftext|>@cuviper
This is still pending lang team decisions (I hope there will be at least 1 RFC) but I think it will only be allowed for trait method impls.<|endoftext|>@porky11
You can't implement anything for `Rc<YourType>` from a crate that does not own the trait.<|endoftext|>So changes needed:
- remove the current error message for *trait methods only*, but still have a feature gate.
- make sure `fn(self: Rc<Self>)` doesn't accidentally become object-safe
- make sure method dispatch woks for `Rc<Self>` methods
- add tests<|endoftext|>I’ll look into this.<|endoftext|>Note that this is only supported to work with *trait methods* (and *trait impl methods*), aka
```Rust
trait Foo {
fn foo(self: Rc<Self>);
}
impl Foo for () {
fn foo(self: Rc<Self>) {}
}
```
and is **NOT** supposed to work for *inherent impl* methods:
```Rust
struct Foo;
impl Foo {
fn foo(self: Rc<Self>) {}
}
```<|endoftext|>I got caught in some more Stylo work that's gonna take a while, so if someone else wants to work on this in the meantime feel free.<|endoftext|>Is this supposed to allow any type as long as it involves `Self`? Or must it impl `Deref<Target=Self>`?
```rust
trait MyStuff {
fn a(self: Option<Self>);
fn b(self: Result<Self, Self>);
fn c(self: (Self, Self, Self));
fn d(self: Box<Box<Self>>);
}
impl MyStuff for i32 {
...
}
Some(1).a(); // ok?
Ok(2).b(); // ok?
(3, 4, 5).c(); // ok?
(box box 6).d(); // ok?
```<|endoftext|>I've started working on this issue. You can see my progress on [this branch](https://github.com/mikeyhew/rust/tree/arbitrary_self_types)<|endoftext|>@arielb1 You seem adamant that this should only be allowed for traits and not structs. Aside from method shadowing, are there other concerns?<|endoftext|>@mikeyhew
inherent impl methods are loaded based on the *type*. You shouldn't be able to add a method to `Rc<YourType>` that is usable without any `use` statement.<|endoftext|>That's it, if you write something like
```Rust
trait Foo {
fn bar(self: Rc<Self>);
}
```
Then it can only be used if the trait `Foo` is in-scope. Even if you do something like `fn baz(self: u32);` that only works for modules that `use` the trait.
If you write an inherent impl, then it can be called without having the trait in-scope, which means we have to be more careful to not allow these sorts of things.<|endoftext|>@arielb1 Can you give an example of what we want to avoid? I'm afraid I don't really see what the issue is. A method you define to take `&self` will still be callable on `Rc<Self>`, the same as if you define it to take `self: Rc<Self>`. And the latter only affects`Rc<MyStruct>`, not `Rc<T>` in general.<|endoftext|>I've been trying to figure out how we can support dynamic dispatch with arbitrary self types. Basically we need a way to take a `CustomPointer<Trait>`, and do two things: (1) extract the vtable, so we can call the method, and (2) turn it into a `CustomPointer<T>` without knowing `T`.
(1) is pretty straightforward: call `Deref::deref` and extract the vtable from that. For (2), we'll effectively need to do the opposite of [how unsized coercions are implemented for ADTs](https://github.com/rust-lang/rust/blob/master/src/librustc_trans/base.rs#L290). We don't know `T`, but we can can coerce to `CustomPointer<()>`, assuming `CustomPointer<()>` has the same layout as `CustomPointer<T>` for all `T: Sized`. (Is that true?)
The tough question is, how do we get the type `CustomPointer<()>`? It looks simple in this case, but what if `CustomPointer` had multiple type parameters and we had a `CustomPointer<Trait, Trait>`? Which type parameter do we switch with `()`? In the case of unsized coercions, it's easy, because the type to coerce to is given to us. Here, though, we're on our own.
@arielb1 @nikomatsakis any thoughts?<|endoftext|>@arielb1
> and is NOT supposed to work for inherent impl methods:
Wait, why do you not want it work for inherent impl methods? Because of scoping? I'm confused. =)<|endoftext|>@mikeyhew
> I've been trying to figure out how we can support dynamic dispatch with arbitrary self types.
I do want to support that, but I expected it to be out of scope for this first cut. That is, I expected that if a trait uses anything other than `self`, `&self`, `&mut self`, or `self: Box<Self>` it would be considered no longer object safe. <|endoftext|>@nikomatsakis
>I do want to support that, but I expected it to be out of scope for this first cut.
I know, but I couldn't help looking into it, it's all very interesting to me :)<|endoftext|>> Wait, why do you not want it work for inherent impl methods? Because of scoping? I'm confused. =)
We need *some* sort of "orphan rule" to at least prevent people from doing things like this:
```Rust
struct Foo;
impl Foo {
fn frobnicate<T>(self: Vec<T>, x: Self) { /* ... */ }
}
```
Because then every crate in the world can call `my_vec.frobnicate(...);` without importing anything, so if 2 crates do this there's a conflict when we link them together.
Maybe the best way to solve this would be to require `self` to be a "thin pointer to Self" in some way (we can't use `Deref` alone because it doesn't allow for raw pointers - but `Deref` + deref of raw pointers, or eventually an `UnsafeDeref` trait that reifies that - would be fine).
I think that if we have the deref-back requirement, there's no problem with allowing inherent methods - we just need to change inherent method search a bit to also look at defids of derefs. So that's probably a better idea than restricting to trait methods only.
Note that the `CoerceSized` restriction for object safety is orthogonal if we want allocators:
```Rust
struct Foo;
impl Tr for Foo {
fn frobnicate<A: Allocator+?Sized>(self: RcWithAllocator<Self, A>) { /* ... */ }
}
```
Where an `RcWithAllocator<Self, A>` can be converted to a doubly-fat `RcWithAllocator<Tr, Allocator>`.<|endoftext|>@arielb1
> Because then every crate in the world can call my_vec.frobnicate(...); without importing anything, so if 2 crates do this there's a conflict when we link them together.
Are saying is that there would be a "conflicting symbols for architechture x86_64..." linker error?
>Maybe the best way to solve this would be to require self to be a "thin pointer to Self" in some way (we can't use Deref alone because it doesn't allow for raw pointers - but Deref + deref of raw pointers, or eventually an UnsafeDeref trait that reifies that - would be fine).
I'm confused, are you still talking about `frobnicate` here, or have you moved on to the vtable stuff?<|endoftext|>> I'm confused, are you still talking about `frobnicate` here, or have you moved on to the vtable stuff?
The deref-back requirement is supposed to be for everything, not only object-safety. It prevents the problem when one person does
```Rust
struct MyType;
impl MyType {
fn foo<T>(self: Vec<(MyType, T)>) { /* ... */ }
}
```
While another person does
```Rust
struct OurType;
impl OurType {
fn foo<T>(self: Vec<(T, OurType)>) {/* ... */ }
}
```
And now you have a conflict on `Vec<(MyType, OurType)>`. If you include the deref-back requirement, there is no problem with allowing inherent impls.<|endoftext|>@arielb1 , you suggest that the point of this is to get around the coherence rules, but I can't see how this wouldn't fall afoul of the same incoherence that the orphan rules are designed to prevent. Can you explain further?
Secondly, the syntax is misleading. Given that `fn foo(&mut self)` allows one to write `blah.foo()` and have it desugar to `foo(&mut blah)`, one would intuitively expect `fn foo(self: Rc<Self>)` to allow one to write `blah.foo()` and desugar to `foo(Rc::new(blah))`... which, indeed, would obviously be pointless, but the discrepancy rankles.
...Oh bleh, in my experiments I'm realizing that `fn foo(self: Self)`, `fn foo(self: &Self)`, and `fn foo(self: &mut Self)` are all surprisingly allowed alternatives to `fn foo(self)`, `fn foo(&self)`, and `fn foo(&mut self)`... and that, astonishingly, `fn foo(self: Box<Self>)` is already in the language and functioning in the inconsistent way that I'm grumpy about in the above paragraph. Of *course* we special-cased `Box`... :P<|endoftext|>I'm all for supporting extra types for `Self` — I've been looking forward to it [for three years](https://stackoverflow.com/q/25462935/155423).<|endoftext|>@shepmaster feel free to try them out! Now that bors has merged my PR, they're available on nightly behind the `arbitrary_self_types` feature gate: https://play.rust-lang.org/?gist=cb47987d3cb3275934eb974df5f8cba3&version=nightly
@bstrie I don't have as good a handle on the coherence rules as @arielb1, but I can't see how arbitrary self types _would_ fall afoul of them. Perhaps you could give an example?
>Secondly, the syntax is misleading. Given that fn foo(&mut self) allows one to write blah.foo() and have it desugar to foo(&mut blah), one would intuitively expect fn foo(self: Rc<Self>) to allow one to write blah.foo() and desugar to foo(Rc::new(blah))... which, indeed, would obviously be pointless, but the discrepancy rankles.
For the few methods that use non-standard self types, I get that this could be annoying. But they should be used sparingly, only when needed: the self type needs to Deref to `Self` anyway, so having the method take `&self` or `&mut self` would be preferred because it is more general. In particular, taking `self: Rc<Self>` should only be done if you actually need to take ownership of the `Rc` (to keep the value alive past the end of the method call).<|endoftext|>> Secondly, the syntax is misleading. Given that fn foo(&mut self) allows one to write blah.foo() and have it desugar to foo(&mut blah), one would intuitively expect fn foo(self: Rc) to allow one to write blah.foo() and desugar to foo(Rc::new(blah))
I don't find that "inversion principle" intuitive. After all, you can't call `fn foo(&mut self)` if your `self` isn't mutable. If you have a `foo(&mut self)`, you need to pass it something that is basically an `&mut Self`. If you have a `foo(self: Rc<Self>)`, you need to pass it something that is basically an `Rc<Self>`.
More than that, we already have `self: Box<Self>` today with no "autoboxing".<|endoftext|>Recent Nightlies emit *a lot* of warnings like this when compiling Servo:
```
warning[E0619]: the type of this value must be known in this context
--> /Users/simon/projects/servo/components/script/dom/bindings/iterable.rs:81:34
|
81 | dict_return(cx, rval.handle_mut(), true, value.handle())
| ^^^^^^^^^^
|
= note: this will be made into a hard error in a future version of the compiler
```
First, I had to do git archeology in the rust repo to find that that warning was introduced bc0439b3880808e1385da4b99964d5d506f76e3f, which is part of #46837, which links here. The error message should probably include some URL to let people read further details and context, ask questions, etc.
Second, I have no idea what this warning is telling me. Why is this code problematic now, while it wasn’t before? What should I do to fix it? The error message should explain some more.<|endoftext|>The breakage from this change seems to be larger than it's normally allowed for compatibility warnings.
A crater run wasn't performed, but if even rustc alone hits multiple instances of broken code (https://github.com/rust-lang/rust/pull/46914), it means than effect on the ecosystem in general is going to be large.<|endoftext|>@SimonSapin I'm working on changing that warning to a future-compatibility lint right now (https://github.com/rust-lang/rust/pull/46914), which will reference a tracking issue that explains the reason for the change; I still have to finish writing the issue though so right now it doesn't explain anything<|endoftext|>I guess we didn't realize there would be so much breakage from that PR. Right now, I'm finding lots of places in [rust-lang/rust](https://github.com/rust-lang/rust) that produce this warning, and they are only popping up now that I'm turning it into a full-blown lint, which is turned into a hard error by `deny(warnings)`.<|endoftext|>Can anyone give a summary of what the status is here? Given that we have two accepted, high-priority RFCs mentioning this feature (https://github.com/rust-lang/rfcs/pull/2349 and https://github.com/rust-lang-nursery/futures-rfcs/pull/2), it's concerning that we still don't have even anything resembling an RFC for this. Since I assume (?) that the RFCs in question are going to end up influencing things in libstd I suppose it's not absolutely imperative that we stabilize this anytime soon, but even having an idea of what the design goals of this feature are would be a good start to making sure we don't box ourselves into a corner somehow. It seems unprecedented for a feature to progress so far without even a pre-RFC... | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>F-arbitrary_self_types<|endoftext|>S-tracking-needs-summary<|endoftext|>T-types<|endoftext|>S-types-deferred | 118 | https://api.github.com/repos/rust-lang/rust/issues/44874 | https://github.com/rust-lang/rust/issues/44874 | https://api.github.com/repos/rust-lang/rust/issues/44874/comments |
246,606,816 | 43,561 | Tracking issue for tweaks to object safety (RFC 2027) | This is the tracking issue for RFC 2027, tweaks to object safety (rust-lang/rfcs#2027)
* [x] Implement (https://github.com/rust-lang/rust/pull/57545)
* [ ] Document
* [ ] Stabilize | If anyone can mentor I'd be excited to try to implement this.
From my naive perspective, it seems like what we need to do is stop checking object safety at certain points (possibly determining if a type is well formed?) and start checking it at other points (checking if the object type implements its corresponding trait). More insight would be great, cc'ing @eddyb<|endoftext|>I'm afraid @nikomatsakis understands the details here much better than me.<|endoftext|>I experimented with implementing this, but I definitely don't know what I'm doing. I noticed some interesting cases.
```rust
trait Foo: Sized { }
fn foo(_: &Foo) { panic!() }
fn main {
let x: Box<Foo>;
}
```
Today these types are just invalid types, but I believe this RFC would make them valid. You would just never be able to initialize `x` or call `foo`. I didn't consider these in the RFC, but it seems fine to me.<|endoftext|>Hey @withoutboats, I was just wondering if anything has changed for this RFC since it was approved?
I don’t have the skills to tackle this, and you probably don’t have the time, but I wanted to “bump” this anyway. Perhaps it can get some more mentoring love to move it forward?<|endoftext|>I still wish this would be implemented, but nothing has changed and I also don't have the knowledge of compiler internals to mentor anyone on it.<|endoftext|>So, I took a crack at this over the holidays. Tried to wrap my head around the compiler internals.
I think I've got most of the RFC working. Currently trying to put all the relevant code behind a feature gate, I'll put up a PR in a couple of days when that's working. All the tests that were broken, ~30 IIRC (at least of those I managed to run), failed because of anticipated reasons. So all good so far.
Just a few corner cases I've been thinking about. The RFC is a little vague on some of the details of what exactly should compile or not.
- What should the feature gate be called? I used 'object_safe_for_dispatch' from the RFC but I think something that indicates that it's more about 'non-object safety trait objects are legal', or maybe 'symmetric_object_safety'.
- How do we alert users about its existence?The RFC basically turns previously illegal code into legal code, but there is no 'good' place to do emit_feature_err!("Static dispatch for non-object safe traits not stable"). Should we add some extra text to E0038 ('cannot be made into an object') to clarify that there is a feature unlocking the error?
- Should the following code compile:
```rust
trait Foo {
fn foo() {}
}
trait Bar: Sized {}
impl Foo for dyn Bar {}
fn static_poly<T: Foo>() {
T::foo();
}
fn main() {
Bar::foo(); // Works now!
static_poly::<dyn Bar>(); // Does not work currently
}
```
- What about if I add the following:
```rust
fn inferred_poly<T: Foo>(t: &T) {
T::foo();
}
fn infer_using_trait_obj(t: &dyn Bar) {
inferred_poly(t); // Does not work currently
}
```
- I currently removed the automatic 'impl Trait for dyn Trait' for non object-safe traits in src/librustc/traits/select.rs which I think is part of the old style trait solving, and not using chalk. Can I switch to use the new trait style solving with chalk somehow? Or is it used under the hood? The rustc guide isn't really clear on if there two styles coexist or if there is a WIP opt-in somewhere.
- Also, the RFC mentions we could possibly allow manual 'impl Trait for dyn Trait'. Is this something we would want? I figure it would be most prudent to add a new error forbidding this, and a future RFC could add it later.
Sorry for the Wall of Text.
TL/DR - Expect a pull request in a couple of days, some thorny questions remain.
@withoutboats<|endoftext|>@bovinebuddha Is it intentional in your code samples that you do not do `T: ?Sized + Foo`? It seems necessary that the code you wrote does not compile because `dyn Bar` does not implement `Sized`, and all type parameters are implicitly bound `Sized` unless you add `?Sized`.<|endoftext|>Ah... What a gotcha! Quite new to Rust, forgot about traits defaulting to !Sized.
Adding that solved made the call in main() compile. The inferred call still doesn't compile with the following message:
```rust
23 | fn infer_using_trait_obj(t: &dyn Bar) {
| -------- help: add explicit lifetime `'static` to the type of `t`: `&'static (dyn Bar + 'static)`
24 | inferred_poly(t);
| ^^^^^^^^^^^^^ lifetime `'static` required
```
I'm not 100% confident in exactly how traits and lifetimes intermingle. Changing to the following did not do the trick:
```rust
fn inferred_poly<'a, T: Foo + ?Sized + 'a>(t: &'a T) {
T::foo();
}
```
and neither did adding the caller to:
```rust
fn infer_using_trait_obj<'a>(t: &'a (dyn Bar + 'a)) {
inferred_poly(t);
}
```
which resulted in this:
```
error[E0495]: cannot infer an appropriate lifetime due to conflicting requirements
--> src/main.rs:24:19
|
24 | inferred_poly(t);
| ^
|
note: first, the lifetime cannot outlive the lifetime 'a as defined on the function body at 23:26...
--> src/main.rs:23:26
|
23 | fn infer_using_trait_obj<'a>(t: &'a (dyn Bar + 'a)) {
| ^^
= note: ...so that the expression is assignable:
expected &dyn Bar
found &(dyn Bar + 'a)
= note: but, the lifetime must be valid for the static lifetime...
= note: ...so that the types are compatible:
expected Foo
found Foo
```
<|endoftext|>The reason is that you have only implemented `Foo` for `dyn Bar + 'static` (because thats the inference in the impl header position).
All of these are normal & expected errors, then (even if they are confusing!). Seems like you got the feature working :)<|endoftext|>Yay :)
I realized the problem I had with the feature gate was that I wrote #[feature...] instead of #![feature...], so that's working now.
Is there any way of writing the lifetimes so that the inferred method compiles though? Or should it even compile in any form? I tried adding separate lifetimes for the referance and the trait bound and an outlives relationship but that didn't do the trick...<|endoftext|>either of these changes should make it compile:
```rust
impl<'a> Foo for dyn Bar + 'a { }
```
```rust
fn infer_using_trait_obj(t: &dyn Bar + 'static) { }
```<|endoftext|>Ah, now I reread your post and actually understood what you wrote. That's what you get for coding late at night. Gonna see if it the generic impl will do the trick tomorrow.<|endoftext|>Btw, that was the problem I had with 'impl Trait for dyn Trait', didn't realize there was an implicit 'static there. This means that this actually compiles for me:
```rust
#![feature(object_safe_for_dispatch)]
trait Bad {
fn bad_stat() { println!("trait bad_stat") }
fn bad_virt(&self) { println!("trait bad_virt") }
fn bad_indirect(&self) { Self::bad_stat() }
}
trait Good {
fn good_virt(&self) { panic!() }
fn good_indirect(&self) { panic!() }
}
impl<'a> Bad for dyn Bad + 'a {
fn bad_stat() { println!("obj bad_stat") }
fn bad_virt(&self) { println!("obj bad_virt") }
}
struct Struct {}
impl Bad for Struct {}
impl Good for Struct {}
fn main() {
let s = Struct {};
// Manually call static
Struct::bad_stat();
<dyn Bad>::bad_stat();
let good: &dyn Good = &s;
let bad = unsafe {std::mem::transmute::<&dyn Good, &dyn Bad>(good)};
// Call virtual
s.bad_virt();
bad.bad_virt();
// Indirectly call static
s.bad_indirect();
bad.bad_indirect();
}
```
and produces
```
trait bad_stat
obj bad_stat
trait bad_virt
obj bad_virt
trait bad_stat
obj bad_stat
```<|endoftext|>I don't know if this is too late, but i just realized that after implementing this RFC we'll lose the ability of the compiler automatically checking object safety when we use the trait objects but didn't generating one...
If we're writing a library and designing traits, we might easily create functions that's never callable at all by accident after this change...
<|endoftext|>This might be a terrible idea, but what if making a trait non-object-safe
triggered a lint, and then if it was indeed intentional the author could
add a #[allow(...)] to silence the lint?
<|endoftext|>I don't really think this will be an issue. If you do write a function which isn't callable (which it technically is though, just not with a safe to construct argument), I would expect the library to actually try and use the trait object, and this will lead to a compile time error for the library writer.
The only 'hidden' errors I think you might get is if you are writing a library with traits that are not handled by the library in itself, and you really really want these to be object safe for your users. I guess such libraries do exist, but I don't know if this is a problem we need to handle.
Maybe, just maybe, there should be some way of hinting to the compiler that this trait should really be object safe. OTOH, that check is one unit test away.<|endoftext|>@bovinebuddha how is your implementation coming along? I've done some work on object safety in the compiler would be happy to chat about it in Discord and look at your code.<|endoftext|>@mikeyhew I think I got the implementation down. There's a pull request at [https://github.com/rust-lang/rust/pull/57545](url). Please, check out the code and any suggestions or comments would be much appreciated!
I seem to have been stuck in review limbo unfortunately. I also had some conflicts to resolve, just rebased and pushed, hopefully it will pass on Travis. (I got some weird llvm errors building locally. For some reasons I get local edits to .cpp files in src/llvm-project when running ./x.py sometimes, I think that might have caused problems).
Cheers<|endoftext|>@bovinebuddha great! I will take a look at your PR and comment there.<|endoftext|>@mikeyhew unfortunately that PR was inactive so we closed it. So if you are still interested, you can implement it. <|endoftext|>`#![feature(object_safe_for_dispatch)]` is now available on nightly!
Implemented by @bovinebuddha and @nikomatsakis in #57545<|endoftext|>Paging @nikomatsakis, it would help to have a summary of this to know what state it's in and whether it's on a path to stabilization. | A-traits<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>F-object_safe_for_dispatch<|endoftext|>S-tracking-needs-summary | 22 | https://api.github.com/repos/rust-lang/rust/issues/43561 | https://github.com/rust-lang/rust/issues/43561 | https://api.github.com/repos/rust-lang/rust/issues/43561/comments |
245,280,784 | 43,467 | Tracking issue for RFC 1861: Extern types | This is a tracking issue for [RFC 1861 "Extern types"](https://github.com/rust-lang/rfcs/blob/master/text/1861-extern-types.md).
**Steps:**
- [x] Implement the RFC (#44295)
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- Should we allow generic lifetime and type parameters on extern types?
If so, how do they effect the type in terms of variance?
- [In std's source](https://github.com/rust-lang/rust/blob/164619a8cfe6d376d25bd3a6a9a5f2856c8de64d/src/libstd/os/raw.rs#L59-L64), it is mentioned that LLVM expects `i8*` for C's `void*`.
We'd need to continue to hack this for the two `c_void`s in std and libc.
But perhaps this should be done across-the-board for all extern types?
Somebody should check what Clang does. Also see https://github.com/rust-lang/rust/issues/59095. | This is not explicitly mentioned in the RFC, but I'm assuming different instances of `extern type` are actually different types? Meaning this would be illegal:
```rust
extern {
type A;
type B;
}
fn convert_ref(r: &A) -> &B { r }
```<|endoftext|>@jethrogb That's certainly the intention, yes.<|endoftext|>Relatedly, is deciding whether we want to call it `extern type` or `extern struct` something that can still be done as part of the stabilization process, or is the `extern type` syntax effectively final as of having accepted the RFC?
EDIT: https://github.com/rust-lang/rfcs/pull/2071 is also relevant here w.r.t. the connotations of `type` "aliases". In stable Rust a `type` declaration is "effect-free" and just a transparent alias for some existing type. Both `extern type` and `type Foo = impl Bar` would change this by making it implicitly generate a new module-scoped existential type or type constructor (nominal type) for it to refer to.<|endoftext|>Can we get a bullet for the panic vs DynSized debate?<|endoftext|>I've started working on this, and I have a working simple initial version (no generics, no DynSized).
I've however noticed a slight usability issue. In FFI code, it's frequent for raw pointers to be initialized to null using `std::ptr::null/null_mut`. However, the function only accepts sized type arguments, since it would not be able to pick a metadata for the fat pointer.
Despite being unsized, extern types are used through thin pointers, so it should be possible to use `std::ptr::null`.
It is still possible to cast an integer to an extern type pointer, but this is not as nice as just using the function designed for this. Also this can never be done in a generic context.
```rust
extern {
type foo;
}
fn null_foo() -> *const foo {
0usize as *const foo
}
```
Really we'd want is a new trait to distinguish types which use thin pointers. It would be implemented automatically for all sized types and extern types. Then the cast above would succeed whenever the type is bounded by this trait. Eg, the function `std::ptr::null` becomes :
```rust
fn null<T: ?Sized + Thin>() -> *const T {
0usize as *const T
}
```
However there's a risk of more and more such traits creeping up, such as `DynSized`, making it confusing for users. There's also some overlap with the various custom RFCs proposals which allow arbitrary metadata. For instance, instead of `Thin`, [`Referent<Meta=()>`](https://github.com/rust-lang/rfcs/pull/1524#issuecomment-272020775) could be used <|endoftext|>I think we can add extern types now and live with `str::ptr::null` not supporting them for a while until we figure out what to do about `Thin`/`DynSized`/`Referent<Meta=…>` etc.<|endoftext|>@SimonSapin yeah, it's definitely a minor concern for now.
I do think this problem of not having a trait bound to express "this type may be unsized be must have a thin pointer" might crop up in other places though.<|endoftext|>Oh yeah, I agree we should solve that eventually too. I’m only saying we might not need to solve all of it before we ship any of it.<|endoftext|>I've pushed an initial implementation in #44295<|endoftext|>@plietar In #44295 you wrote
> Auto traits are not implemented by default, since the contents of extern types is unknown. This means extern types are `!Sync`, `!Send` and `!Freeze`. This seems like the correct behaviour to me. Manual `unsafe impl Sync for Foo` is still possible.
While it is possible for Sync, Send, UnwindSafe and RefUnwindSafe, doing `impl Freeze for Foo` is *not* possible as it is a private trait in libcore. This means it is impossible to convince the compiler that an `extern type` is cell-free.
Should `Freeze` be made public (even if `#[doc(hidden)]`)? cc @eddyb #41349.
Or is it possible to declare an extern type is safe-by-default, which opt-out instead of opt-in?
```rust
extern {
#[unsafe_impl_all_auto_traits_by_default]
type Foo;
}
impl !Send for Foo {}
```
<|endoftext|>@kennytm What's the usecase? The semantics of `extern type` are more or less that of a hack being used before the RFC, which is `struct Opaque(UnsafeCell<()>);`, so the lack of `Freeze` fits.
That prevents rustc from telling LLVM anything *different* from what C signatures in clang result in.<|endoftext|>@eddyb Use case: Trying to see if it's possible to make CStr a thin DST.
I don't see anything related to a cell in #44295? It is reported to LLVM as an [`i8`](https://github.com/rust-lang/rust/blob/c81f201d48c4f25d32f8b0f76103c9f794d37851/src/librustc_trans/type_of.rs#L161) similar to `str`. And the [places](https://github.com/rust-lang/rust/blob/c81f201d48c4f25d32f8b0f76103c9f794d37851/src/librustc_trans/abi.rs#L764) where `librustc_trans` involves the Freeze trait reads the real type, not the LLVM type, so LLVM treating all extern type as `i8` should be irrelevant?<|endoftext|>@kennytm So with `extern type CStr;`, writes through `&CStr` would be legal, and you don't want that?
The `Freeze` trait is private because it's used to detect `UnsafeCell` and not meant to be overriden.<|endoftext|>The original intent was to match the `extern type CStr` with the existing behavior of `struct CStr([c_char])` which is Freeze. Eddyb and I [discussed on IRC](https://botbot.me/mozilla/rust-internals/2017-11-16/?msg=93605822&page=3), which assures that (1) Freeze is mainly used to disable certain optimizations only and (2) as Freeze is a private trait, no one other than the compiler will rely on it. So the missing Freeze trait will be irrelevant for `extern type CStr`.<|endoftext|>Regarding the thin pointer issue, I imagine that const generics will eventually enable constant comparisons in `where` clauses - if `size_of` is made const also, that would let you write a bound of `where size_of::<Ptr>() == size_of::<usize>()` which IMO matches the intent pretty perfectly.<|endoftext|>This is the first I hear of allowing const expressions in where clauses. While it could be very useful, it seems far from given that this will be accepted into the language.<|endoftext|>@SimonSapin Const expression in `where` clause will eventually be needed for const generics beyond RFC 2000 (spelled as `with` in rust-lang/rfcs#1932), but I do think this extension is out-of-scope for extern type or even custom DST in general.<|endoftext|>I didn't mean to assume that that will be supported, I meant that if it did become possible in a reasonable timeframe, which apparently is not likely, I think it'd be nice to have more regular syntax to express some ideas rather than more marker traits with special meaning given by the compiler. If that's not going to work, then great, it's one less thing to consider.<|endoftext|>One of my use cases for extern types is to represent opaque things from the macOS frameworks with them.
For that purpose, I actually want to be able to wrap opaque things in some generic types to encode certain invariants related to refcounting.
For example, I want a `CFRef<T>` type that derefs to `CFShared<T>` that itself derefs to `T`.
```rust
pub struct CFRef<T>(*const CFShared<T>);
pub struct CFShared<T>(T);
```
This is apparently not possible if `T` is an extern type.
```rust
pub extern type CFString;
fn do_stuff_with_shared_string(str: &CFShared<CFString>) { ... }
```
Would it be complicated to support such a thing?<|endoftext|>@nox `struct CFShared<T: ?Sized>(T);` ?
Note that this may not compile after we have implemented the `DynSized` trait since an `extern type` is not `DynSized`, and we can’t place a `!DynSized` field inside a struct (may need explicit `#[repr(transparent)]` to allow it. <|endoftext|>Can somebody provide an update on the status of this and maybe summarize the remaining open issues? I'd like to know if it is possible already to implement `c_void` in `libc`/`core` using `extern type`, for example.<|endoftext|>@gnzlbg as mentioned in the initial post in this issue:
> [In std's source](https://doc.rust-lang.org/nightly/src/std/os/raw/mod.rs.html#99-106), it is mentioned that LLVM expects `i8*` for C's `void*`.
> We'd need to continue to hack this for the two `c_void`s in std and libc.
> But perhaps this should be done across-the-board for all extern types?
> Somebody should check what Clang does.
There is no solution for this yet, I think.<|endoftext|>@gnzlbg Whether we want `DynSized` needs to be resolved as well. The [description of the initial implementation](https://github.com/rust-lang/rust/pull/44295#issue-139057745) does a great job of laying out the footguns that exist without it. Thanks @plietar!<|endoftext|>C Opaque struct:
```C
typedef struct c_void c_void;
c_void* malloc(unsigned long size);
void call_malloc() {
malloc(1);
}
```
clang version 5.0.1:
```llvm
%struct.c_void = type opaque
define void @call_malloc() #0 {
%1 = call %struct.c_void* @malloc(i64 1)
ret void
}
declare %struct.c_void* @malloc(i64) #1
```
C void:
```C
void* malloc(unsigned long size);
void call_malloc() {
malloc(1);
}
```
clang version 5.0.1:
```llvm
define void @call_malloc() #0 {
%1 = call i8* @malloc(i64 1)
ret void
}
declare i8* @malloc(i64) #1
```
Rust extern type:
```rust
#![feature(extern_types)]
#![crate_type="lib"]
extern "C" {
type c_void;
fn malloc(n: usize) -> *mut c_void;
}
#[no_mangle]
pub fn call_malloc() {
unsafe { malloc(1); }
}
```
Rust nightly:
```llvm
%"::c_void" = type {}
define void @call_malloc() unnamed_addr #0 !dbg !4 {
start:
%0 = call %"::c_void"* @malloc(i64 1), !dbg !8
br label %bb1, !dbg !8
bb1: ; preds = %start
ret void, !dbg !10
}
declare %"::c_void"* @malloc(i64) unnamed_addr #1
```<|endoftext|>Great find! This `%struct.c_void = type opaque` sure looks worth imitating. If that's slower than `i8*` IMO that's a clang/LLVM bug to report.<|endoftext|>Would this syntax be acceptable?
```rust
extern {
#[repr(i8)]
type c_void;
}
```<|endoftext|>@jethrogb looks good to me, but I'd be tempted to keep it unstable as it only exists to hack around LLVM.<|endoftext|>> I'd be tempted to keep it unstable as it only exists to hack around LLVM.
That sounds good in principle, but I think there were plans to have the final public definition of `c_void` live in a crates.io crate.<|endoftext|>@jethrogb hehe just quoted those plans. I do see the tension, bummer.<|endoftext|>> Great find! This %struct.c_void = type opaque sure looks worth imitating. If that's slower than i8* IMO that's a clang/LLVM bug to report.
It is definitely slower than `i8*`. For example, malloc declared as returning an opaque struct won't be recognized as malloc by most (all?) optimization passes. It's a known issue and according to some LLVM devs the right way to fix it is to get rid of pointee types altogether and have just one pointer type, but that doesn't seem to be happening any time soon so you'll have to emit `i8*`. | A-ffi<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>F-extern_types<|endoftext|>S-tracking-needs-summary | 232 | https://api.github.com/repos/rust-lang/rust/issues/43467 | https://github.com/rust-lang/rust/issues/43467 | https://api.github.com/repos/rust-lang/rust/issues/43467/comments |
238,302,145 | 42,877 | Tracking issue for unsized tuple coercion | This is a part of #18469. This is currently feature-gated behind `#![feature(unsized_tuple_coercion)]` to avoid insta-stability.
Related issues/PRs: #18469, #32702, #34451, #37685, #42527
This is needed for unsizing the last field in a tuple:
```rust
#![feature(unsized_tuple_coercion)]
fn main() {
let _: &(i32, [i32]) = &(3, [3, 3]) as _;
}
```
<https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=5f93d1d7c6ee0e969df53c13e1aa941a>
| Triage: no changes<|endoftext|>T-lang discussed this in a backlog bonanza meeting today, and noted several concerns that should be addressed prior to moving forward:
* Is there active usage/desire for this feature?
* Tuple destructuring and/or combining may conflict with particular decisions made here (for a subset of types) -- which merits at least a more thorough exploration to make sure this concern is assessed (it may not be fully accurate).<|endoftext|>I subscribed to this because I wanted to use it once... but didn't because it's unstable and not too hard to work around. I suspect the same goes for many non-trivial projects. [Searching GitHub](https://github.com/search?l=Rust&q=unsized_tuple_coercion&type=Code) shows 1391 code results, most of which appear to be tests. There are a few uses on the first page: https://github.com/aschaeffer/inexor-rgf-application, https://github.com/aschaeffer/rust-ecs-poc, https://github.com/libdither/disp, https://github.com/icostin/halfbit (feature = "nightly"); everything after that appears to be tests (I checked 10 more pages).
In short: some possible utility, but not a priority.<|endoftext|>I wish to use this in [safina-executor](https://crates.io/crates/safina-executor) library. The library currently uses this type for async tasks:
```rust
Arc<Mutex<dyn Future<Output = ()> + Send + Unpin>>
```
([v0.3.2 lib.rs:306](https://docs.rs/safina-executor/0.3.2/src/safina_executor/lib.rs.html#306))
I am modifying it to remember when a task has returned `Polling::Ready` and avoid polling it again.
I would like to use the following type, but it depends on this `unsized_tuple_coercion` feature:
```rust
Arc<Mutex<(bool, dyn Future<Output = ()> + Send + Unpin)>>
```
Instead, I will use this type, which requires two allocations per task:
```rust
Arc<Mutex<Option<Box<dyn Future<Output = ()> + Send + Unpin>>>>
```
This is OK. Async tasks are generally long-lived data structures. Therefore, the extra allocation is a very small added cost.
This `Option` version has a benefit: it lets us drop the completed future right away. With the `bool` version, the future drops after its last waker is dropped. Some applications may use timeouts that keep a waker for the duration of the timeout. That could keep future enclosures around for minutes, and increase memory pressure.<|endoftext|>To use `bool` on stable, does using a struct type instead of a tuple work?<|endoftext|>@SimonSapin A struct works!
```rust
struct Task<T: ?Sized> {
completed: bool,
fut: T,
}
impl<T> Task<T> {
pub fn new(fut: T) -> Arc<Mutex<Self>> {
Arc::new(Mutex::new(Task {
completed: false,
fut,
}))
}
}
impl Executor {
//...
pub fn spawn_unpin(self: &Arc<Self>, fut: impl (Future<Output = ()>) + Send + Unpin + 'static) {
let task = Task::new(fut);
let weak_self = Arc::downgrade(self);
self.async_pool.schedule(move || poll_task(task, weak_self));
}
}
```
I think I'm going to keep the `Option<Box<_>>` version because of the memory savings I mentioned above. Using an enum didn't work:
```rust
enum Task<T: ?Sized> {
None,
Some(T),
}
// error[E0277]: the size for values of type `T` cannot be known at compilation time
```<|endoftext|>I just realized that the `None` and `Some` enum variants must be the same size. So the enum version wouldn't save memory used directly by the `Future`. It would save only heap-allocated memory owned by the `Future`. A completed future from an async closure cannot contain own any heap-allocated memory because it drops all variables before returning and completing. Other types that implement `Future` may have heap-allocated memory, but those types are rarely used as tasks. Therefore, an enum alone provides almost no memory savings because it saves only heap-allocated memory, and completed tasks have none of that.<|endoftext|>There's an argument to be made for consistency. [You can unsize coerce, deconstruct, and otherwise match against custom tuple types already.](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=083735838f1226f3c9ca67c09e8f5352) You can also [do all these things on stable with built-in tuples too,](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=94733506679026f95b606583213ddd0c) given a touch of `unsafe`. [^0]
[^0]: I do recognize that's still unsound without `offset_of`. On the other hand, there's no other reasonable layout in this case.<|endoftext|>@QuineDot [no you can't](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=13a2c7f1e42075d7cd192cb079a5e1e6). You are merely using references to unsized types.
However, [this edited version works](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=1d7e864b94d5ce4f97ad517ee8344415) (avoids deconstruction of the unsized parameter, or more precisely merely avoids creating a `let` binding to the unsized part). | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 9 | https://api.github.com/repos/rust-lang/rust/issues/42877 | https://github.com/rust-lang/rust/issues/42877 | https://api.github.com/repos/rust-lang/rust/issues/42877/comments |
234,399,067 | 42,524 | Tracking issue for `-Z profile` | This is intended to be a tracking issue for the profiling feature, built on the gcov-style support in LLVM first added in https://github.com/rust-lang/rust/pull/38608 and later rebased in https://github.com/rust-lang/rust/issues/42433. | Triage: not aware of any major move to stabilize this.<|endoftext|>Is it expected that this doesn't work with --release?<|endoftext|>Is there a way to change the path that the tests output to? I want to use this on some code that is cross compiled and needs to run on a device that only has a few writable paths. I'm currently getting this to work by replacing `/target/aarch64...` with `./arget/aarch64...` in the binary since we can't change the length of the string.
I've never worked on the compiler before, but an option for this would be very useful. | T-compiler<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>A-cli | 3 | https://api.github.com/repos/rust-lang/rust/issues/42524 | https://github.com/rust-lang/rust/issues/42524 | https://api.github.com/repos/rust-lang/rust/issues/42524/comments |
223,972,618 | 41,517 | Tracking issue for trait aliases | This is a tracking issue for trait aliases (rust-lang/rfcs#1733).
TODO:
- [x] Implement: [tracking issue](https://github.com/rust-lang/rust/issues/55628)
- [x] #56485 — Bringing a trait alias into scope doesn't allow calling methods from its component traits (done in https://github.com/rust-lang/rust/pull/59166)
- [x] #56488 — ICE with trait aliases and use items
- [x] #57023 — Nightly Type Alias Compiler panic `unexpected definition: TraitAlias`
- [x] #57059 — `INCOHERENT_AUTO_TRAIT_OBJECTS` future-compatibility warning (superseded by https://github.com/rust-lang/rust/pull/56481)
- [ ] Document
- [ ] Stabilize
Unresolved questions:
- [ ] Are bounds on other input types than the receiver enforced or implied?
- [ ] Should we keep the current behaviour of "shallow-banning" `?Sized` bounds in trait objects, ban them "deeply" (through trait alias expansion), or permit them everywhere with no effect?
- [ ] [Insufficient flexibility](https://github.com/rust-lang/rust/issues/41517#issuecomment-544340795)
- [ ] [Inconvenient syntax](https://github.com/rust-lang/rust/issues/41517#issuecomment-544763195)
- [ ] [Misleading naming](https://github.com/rust-lang/rust/issues/41517#issuecomment-479226997)
- [ ] Which of constraint/bound/type aliases are desirable
| I think #24010 (allowing aliases to set associated types) should be mentioned here.<|endoftext|>I'd like to take a crack at this (starting with parsing).<|endoftext|>I read the RFC and I saw a call out to `Service`, but I am not sure if the RFC actually solves the `Service` problem.
Specifically, the "alias" needs to provide some additional associated types:
See this snippet: https://gist.github.com/carllerche/76605b9f7c724a61a11224a36d29e023
Basically, you rarely want to just alias `HttpService` to `Service<Request = http::Request>` You really want to do something like this (while making up syntax):
```rust
trait HttpService = Service<http::Request<Self::RequestBody>> {
type RequestBody;
}
```
In other words, the trait alias introduces a new associated type.
The reason why you can't do: `trait HttpService<B> = Service<http::Request<B>>` is that then you end up getting into the "the type parameter `B` is not constrained by the impl trait, self type, or predicates" problem.
<|endoftext|>> Basically, you rarely want to just alias HttpService to Service<Request = http::Request>
Rarely? How do you define that?
The syntax you suggest seems a bit complex to me and non-intuitive. I don’t get why we couldn’t make an exception in the way the “problem” shows up. Cannot we just hack around that rule you expressed? It’s not a “real trait”, it should be possible… right?
<|endoftext|>@phaazon rarely with regards to the service trait. This was not a general statement for when you would want trait aliasing.
Also, the syntax was not meant to be a real proposal. It was only to illustrate what I was talking about.<|endoftext|>I see. Cannot we just use free variables for that? Like, `Service<Request = http::Request>` implies the free variable used in `http::request<_>`?<|endoftext|>@phaazon I don't understand this proposal.<|endoftext|>@durka: how's the work on the follow-up to https://github.com/rust-lang/rust/pull/45047 going?<|endoftext|>Something I mentioned in the RFC: `trait Trait =;` is accepted by the proposed grammar and I think that this is a bit weird. Perhaps maybe the proposed `_` syntax might be more apt here, because I think that allowing empty trait requirements is useful.<|endoftext|>We can put a check for that in AST validation. However I suppose it could
be useful for code generation if there's no special case, I dunno.
On Tue, Feb 27, 2018 at 12:48 PM, Clar Roʒe <[email protected]>
wrote:
> Something I mentioned in the RFC: trait Trait =; is accepted by the
> proposed grammar and I think that this is a bit weird. Perhaps maybe the
> proposed _ syntax might be more apt here, because I think that allowing
> empty trait requirements is useful.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/rust-lang/rust/issues/41517#issuecomment-368965137>,
> or mute the thread
> <https://github.com/notifications/unsubscribe-auth/AAC3n3HdG3ZOmbN2PKky7nFnx0WokY7Lks5tZD_fgaJpZM4NGzYc>
> .
>
<|endoftext|>One other thing to note as a general weirdness is macro expansions involving trait bounds. Currently, `fn thing<T:>()` is valid syntax but perhaps `fn thing<T: _>()` should be the recommended version.
But then, is `_ + Copy` or something okay? I'm not sure. I would just suggest `Any` but that has different guarantees.<|endoftext|>Empty bound lists (and other lists) are accepted in other contexts as well, e.g. `fn f<T: /*nothing*/>() { ... }`, so `trait Trait = /*nothing*/;` being accepted is more of a rule than an exception.<|endoftext|>I think it makes sense being accepted, although I wonder if making it the canonical way to do so outside of macros is the right way to go. We already have been pushing toward `'_` for elided lifetimes in generics, for example.<|endoftext|>So I was thinking of working on this one because it's a feature I really want and it seems relatively straightforward, but I'm not exactly sure where to start. I haven't done any compiler work before.
It seems like a good first implementation would be to basically convert trait aliases to a trait and blanket impl in the HIR, but I'm not sure if that would actually work.<|endoftext|>@clarcharr That sounds like a good plan to me, on first sight, though I'm not the most knowledgeable about this. I wonder if someone could help you by mentoring. Maybe get yourself on the Discord #lang channel and ask? :-) (Also, I might even even contribute here myself, given this seems to be a fair bit of work.)<|endoftext|>One thing I don't see mentioned in the RFC is whether `use`ing trait aliases brings methods into scope? (see the [next comment](https://github.com/rust-lang/rust/issues/41517#issuecomment-403568840) for a correct example, mine was wrong).<|endoftext|>@Nemo157 In your example you are using a trait object, which should work (as well as generics) without importing the trait, like this:
```rust
mod some_module {
pub trait Foo {
fn foo(&self);
}
}
fn use_foo(object: &some_module::Foo) {
object.foo();
}
```
The question is whether this should work:
```rust
mod some_module {
pub trait Foo {
fn foo(&self);
}
pub trait Bar {
fn bar(&self);
}
pub struct Qux;
impl Foo for Qux {
fn foo(&self) {}
}
impl Bar for Qux {
fn bar(&self) {}
}
pub trait Baz = Foo + Bar;
}
use some_module::{Baz, Qux};
fn use_baz(object: Qux) {
// Should this work because Baz is in scope?
object.foo();
object.bar();
}
```<|endoftext|>Considering I want this more than even async/await, I'll try diving in here. Are there any possible mentoring or hints as to where to proceed? It looks like @durka got parsing in place, and in typeck `collect`, it specifically says it's not implemented. I'll likely start there, trying to copy what a regular trait does, and then watch as ICEs pile up...
It would be useful to update the issue description with more details about the current status. It took me a good half hour to figure this much out:
- Parsing to AST is complete.
- Lowering to HIR is... in place. It doesn't fully do everything, but it's further along than simply `libsyntax` knowing how to parse it.
If specific issues could also be listed, it'd help keep track of the work remaining.<|endoftext|>@seanmonstar Awesome! Your impression seems right. I couldn't get it integrated in the trait resolver at all. Here is [some old advice from @nikomatsakis](https://github.com/rust-lang/rust/pull/45047#issuecomment-337044394). Suggestions I got didn't work, and it seemed like chalk was going to come and change the whole system -- but I have no idea how that's progressing.<|endoftext|>@seanmonstar Sounds good! I too have heard that Chalk may be the way forward with implementing something like this, but I’m not completely sure. Anyway, depending on how much work ypu feel this may be, I’d be glad to chip in if you like. <|endoftext|>I want to clarify something that I don't think was properly addressed in the original RFC discussions. From what I gather, the feature that has been accepted is not "trait aliases", but "bounds aliases". However, the proposals to use keywords other that `trait` for this seem to have been completely ignored.
From experience, using incorrect terminology for things causes problems down the line that we might not guess at now, because it introduces inconsistencies (especially with a keyword that is already used for something else: specifically *just* traits).
Personally, I'd really appreciate a convincing argument for why `trait` is an acceptable keyword for bound aliases, or a proposal to change the syntax to something like `bounds` (or `constraints`, or really anything more general) before stabilisation.<|endoftext|>@varkor Fair point. I agree `bounds` would be a more accurate name, and lead to less confusion.<|endoftext|>FWIW, I don't think using `trait` is actually that confusing. Type aliases do not define new types themselves, and yet we use `type Foo = ..` syntax. Trait aliases may have edge cases where they don't include any traits (`?Sized + 'static` or something), but that doesn't mean they won't appear to function as traits or even necessarily need to use a different keyword.
As example of a related place where people use slightly incorrect terminology to no ill effect, we often hear the bounds on a trait's `Self` parameter referred to using the language of inheritance- "base trait," "supertrait," etc. Despite the fact that there's no subclassing going on, and currently not even a way to downcast trait objects, this is still fine.<|endoftext|>> but that doesn't mean they won't appear to function as traits or even necessarily need to use a different keyword.
I think `trait` is very misleading, precisely because this point is false. If "trait aliases" worked like type aliases, then you would be able to do something like the following:
```rust
trait Trait {}
trait Alias = Trait;
impl Alias for () {}
```
As it stands, you cannot, because so-called "trait" aliases are actually bounds aliases. Traits and bounds are different (even specifically _trait_ bounds), both from an abstract model point-of-view, and their functionality within the language.
Using the term "trait alias" for this terminology is confusing and prevents true trait aliases from being added in a consistent manner with type aliases.
> As example of a related place where people use slightly incorrect terminology to no ill effect
The use of terminology by people is very different to its realisation in the language. People might say "trait" instead of "trait bound" in practice, but conflating the two inside the language is, I would argue, a mistake.<|endoftext|>I believe that in practice there shouldn't be a visible difference between `trait Alias: Trait where Self: Other {} impl<T: Trait> Alias for T where Self: Other {}` and `trait Alias = Trait`.
So, in this case, `impl Alias` doesn't even make sense, because you've already defined a blanket impl.<|endoftext|>@clarcharr: I'm thinking more in terms of renaming, like in the following:
```rust
struct S;
trait T1 {}
trait T2 = T1;
impl T2 for S {}
```
This is the intuitive meaning (as far as I can see it) of the term "trait alias". It's analogous to how type aliases work. Note that you would _also_ be able to use these trait aliases in bounds (aliases would be functionally identical to traits).
Whereas "bounds aliases" would alias both traits and lifetimes, specifically in the context of bounds on generic parameters, etc.).<|endoftext|>I assume you mean `impl T1 for dyn T2`, right? Or `impl<T: T2> T1 for T {}` ?
The latter will work as expected. Although the former basically, what you're asking is the meaning of what `impl T2` and `dyn T2` mean. Which… again, I think work in the context of trait aliases as both trait aliases and bound aliases.<|endoftext|>@clarcharr: sorry, I got that line completely muddled. I've updated it. I mean that we implement a trait by using its alias. (Obviously in this example, there's no point, but you could imagine something with generic parameters, etc. being useful to use in this way.)<|endoftext|>anecdata, but *I* would find `bounds` to be more confusing than `trait`.<|endoftext|>We actually did go [back and forth](https://github.com/rust-lang/rfcs/pull/1733#issuecomment-284551267) on whether to use the keyword `bound` or maybe `constraint` in the RFC, but didn't come to a firm conclusion. Personally I don't see the huge need for a new keyword. You can use a trait as a bound... you can use a trait alias as a bound.
Would it make it better if you *could* `impl` an alias? We talked about that too but there are some [gotchas](https://github.com/rust-lang/rfcs/pull/1733#issuecomment-285460783). I very much encourage those now debating "trait"/"bound" to read these comments as some issues were already brought up.
The important thing is to get it implemented so we can experiment with these things. | A-traits<|endoftext|>B-RFC-approved<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>F-trait_alias<|endoftext|>S-tracking-needs-summary | 111 | https://api.github.com/repos/rust-lang/rust/issues/41517 | https://github.com/rust-lang/rust/issues/41517 | https://api.github.com/repos/rust-lang/rust/issues/41517/comments |
211,161,812 | 40,180 | Tracking issue for the `x86-interrupt` calling convention | ## Overview
Tracking issue for the `x86-interrupt` calling convention, which was added in PR #39832. The feature gate name is `abi_x86_interrupt`. This feature will not be considered for stabilization without an RFC.
The `x86-interrupt` calling convention can be used for defining interrupt handlers on 32-bit and 64-bit x86 targets. The compiler then uses `iret` instead of `ret` for returning and ensures that all registers are restored to their original values.
### Usage
```rust
extern "x86-interrupt" fn handler(stack_frame: ExceptionStackFrame) {…}
```
for interrupts and exceptions without error code and
```rust
extern "x86-interrupt" fn handler_with_err_code(stack_frame: ExceptionStackFrame,
error_code: u64) {…}
```
for exceptions that push an error code (e.g., page faults or general protection faults). The programmer must ensure that the correct version is used for each interrupt.
For more details see the [LLVM PR][1], and the corresponding [proposal][2].
[1]: https://reviews.llvm.org/D15567
[2]: http://lists.llvm.org/pipermail/cfe-dev/2015-September/045171.html
## Known issues
- [ ] An earlier version of this description stated that the `ExceptionStackFrame` is passed by reference (instead of by value). This used to work on older LLVM version, but no longer works on LLVM 12. See https://github.com/rust-lang/rust/issues/40180#issuecomment-814270159 for more details.
- [ ] LLVM **doesn't preserve MMX and x87 floating point registers** across interrupts. This issue was reported in https://github.com/llvm/llvm-project/issues/26785.
- [x] _(fixed)_ x86-interrupt calling convention leads to **wrong error code** in debug mode (#57270)
### 64-bit
- [x] The x86_64 automatically aligns the stack on a 16-byte boundary when an interrupts occurs in 64-bit mode. However, the CPU pushes an 8-byte error code for some exceptions, which destroys the 16-byte alignment. At the moment, LLVM doesn't handle this case correctly and always assumes a 16-byte alignment. This leads to **alignment issues on targets with SSE support**, since LLVM uses misaligned [`movaps`](http://x86.renejeschke.de/html/file_module_x86_id_180.html) instructions for saving the `xmm` registers. This issue is tracked as [bug 26413](https://bugs.llvm.org//show_bug.cgi?id=26413).
_A fix for this problem was submitted in [D30049](https://reviews.llvm.org/D30049) and merged in [rL299383](https://reviews.llvm.org/rL299383)._
- [x] LLVM always tries to backup the `xmm` registers on 64-bit platforms even if the target doesn't support SSE. This leads to invalid opcode exceptions whenever an interrupt handler is invoked.
_The fix was merged to LLVM trunk in [rL295347](https://reviews.llvm.org/rL295347). Backported in rust-lang/llvm#63._
- [ ] https://github.com/llvm/llvm-project/issues/41189
### 32-bit
- [ ] In 32-bit mode, the CPU performs no stack alignment on interrupts. Thus, the interrupt handler should perform a dynamic stack alignment (i.e. `and esp, 16`). However, LLVM doesn't do that at the moment, which might lead to **alignment errors**, especially for targets with SSE support. This issue is tracked in https://github.com/llvm/llvm-project/issues/26851. | If we're going to have an x86-interrupt abi, would it also make sense to have an x86-syscall? Or x86-sysenter?<|endoftext|>([D30049](https://reviews.llvm.org/D30049) was merged to LLVM trunk on the 3rd of April, for the record.)<|endoftext|>@kyrias Thanks for the hint, I updated the issue text. I'll try to create a backport PR in the next few days.<|endoftext|>Triage: not aware of any movement stabilizing this.
Personal note: this is one of my favorite rust features :)<|endoftext|>Both of the 64-bit issues have long since been fixed, and Rust's minimum LLVM is newer than the fix, so it's just the MMX/x87 floating point and 32-bit issues remaining, which appear to have been untouched since 2017.<|endoftext|>@kyrias I updated the issue description. I also added https://github.com/rust-lang/rust/issues/57270, which will be hopefully fixed soon with the LLVM 9 upgrade.<|endoftext|>@phil-opp I think this issue can be updated to cross off #57270
On the x87/MMX issue, we should just mandate that to use the interrupt ABI, you have to build the code with `target-features` of `-x87` and `-mmx` (`-mmx` could be a default now that MMX support is [gone from Rust](https://github.com/rust-lang/stdarch/pull/890)). It looks like LLVM and GCC just [never intend to support saving/restoring the MMX/x87 registers](https://gcc.gnu.org/git/?p=gcc.git;a=commit;h=5ed3cc7b66af4758f7849ed6f65f4365be8223be), so it's probably not worth trying to make it work (as nobody should be using those features anyway.
We may also want to similarly disallow all SSE code in interrupt handlers (GCC bans SSE code, Clang allows it), as that might make it easier to make sure we are doing the right thing.
<|endoftext|>> @phil-opp I think this issue can be updated to cross off #57270
Done!<|endoftext|>Just came across the following from a conference paper, and thought I would quote here as a data point:
> We implement the low-level interrupt entry and exit code in assembly. While Rust provides support for the x86-interrupt function ABI (a way to write a Rust function that takes the x86 interrupt stack frame as an argument), in practice, it is not useful as we need the ability to interpose on the entry and exit from the interrupt, for example, to save all CPU registers.
(section 4.1 of https://www.usenix.org/system/files/osdi20-narayanan_vikram.pdf)<|endoftext|>After discussing this on the Rust Community Server #os-dev channel with some folks (cc @Soveu @asquared31415), and checking out the LLVM patch that includes the ABI, it seems like taking the struct by-reference is incorrect and leads to undefined behavior (as seen in https://github.com/rust-osdev/x86_64/issues/240). This seems to have worked previously, but I suspect the upgrade to LLVM 12 may have "fixed" the behavior. (edit: asquared tested both 2021-03-03 and 2021-03-05 nightly releases, both by-value and by-ref work on the former, but by-ref breaks on the latter, which I think pretty much confirms the LLVM 12 upgrade fixed the behavior)
The patch to LLVM includes the following code, suggesting that the very first parameter should always be by-value and never by-reference.
```cpp
if (F.getCallingConv() == CallingConv::X86_INTR) {
// IA Interrupt passes frame (1st parameter) by value in the stack.
if (Idx == 1)
Flags.setByVal();
}
```<|endoftext|>By the way, if the function signature contains more than 2 arguments LLVM crashes with
```
LLVM ERROR: unsupported x86 interrupt prototype
```<|endoftext|>@repnop Thanks a lot for investigating this! I'll look into it and update the description of this issue if I can confirm that it works with a by-value parameter. Given that the Rust implementation just sets the LLVM calling convention, this shouldn't require any changes on the Rust side to fix it. We should adjust the `x86_64` crate though.
To prevent issues like this (and wrong number of arguments errors), we should probably introduce some kind of lint that checks the function signature when the `x86-interrupt` calling convention is used. It's probably difficult to check the layout of the `ExceptionStackFrame` struct in detail, but verifying the number of parameters and the correct argument types (struct and optional `u64`) should be possible. I don't have any experience with creating lints though, so I'm not sure about the details.<|endoftext|>Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does _not_ check if there is an error code and just pops unconditionally<|endoftext|>> I'll look into it and update the description of this issue if I can confirm that it works with a by-value parameter. Given that the Rust implementation just sets the LLVM calling convention, this shouldn't require any changes on the Rust side to fix it. We should adjust the x86_64 crate though.
It does work by-value parameter!
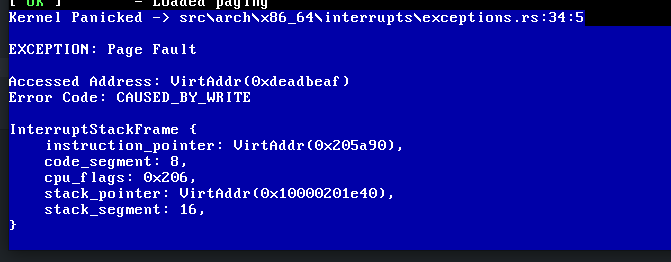
Everything now seems to be correct. Eg the stack segment is (16) => 0x10 which is valid
Thanks @repnop and @phil-opp!<|endoftext|>Discovered something more:
As we are writing to 0xdeadbeaf the stack segment should be 0x00. For example this is a right interrupt stack:
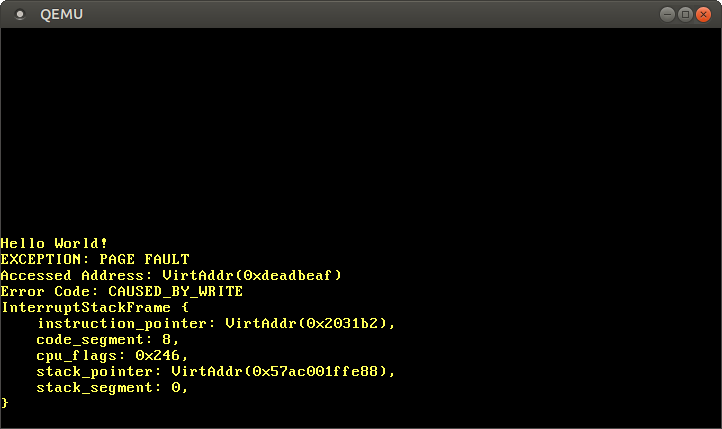
(Picture from OS Phillip's Blog)
As you can see the image below its 0x10.
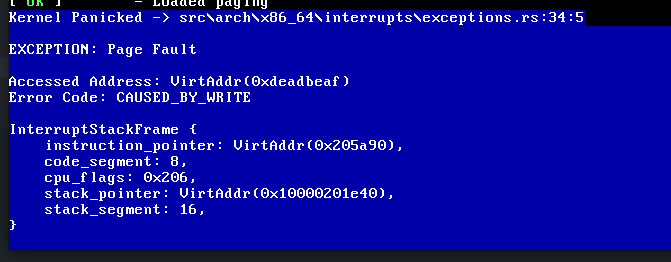
<|endoftext|>Shouldn't 0x0 segment be null descriptor? (which iirc is invalid, stack segment should be a 64bit data segment)<|endoftext|>On x86_64 architecture, the stack segment is *supposed* to be always forced to zero. Segmentation is almost entirely unused, in favor of paging.<|endoftext|>Yes, segmentation is mostly unused, _but_ you have to have at least null, 64bit data and code segments<|endoftext|>As per [this](https://en.wikipedia.org/wiki/X86_memory_segmentation#Later_developments) wikipedia article, "Four of the segment registers, CS, SS, DS, and ES, are forced to 0, and the limit to 2^64". Additionally the AMD manual says that those segments are unused. It's curious that the cpu is reporting a non-zero value, however from testing their code in the community discord, everything seems to *work*, despite it seemingly being wrong. This was only tested on QEMU though, so perhaps that is an emulation fault.<|endoftext|>> As per [this](https://en.wikipedia.org/wiki/X86_memory_segmentation#Later_developments) wikipedia article, "Four of the segment registers, CS, SS, DS, and ES, are forced to 0, and the limit to 2^64". Additionally the AMD manual says that those segments are unused. It's curious that the cpu is reporting a non-zero value, however from testing their code in the community discord, everything seems to *work*, despite it seemingly being wrong. This was only tested on QEMU though, so perhaps that is an emulation fault.
This is totally not a emulation fault as interrupt stack is perfect when in other languages. <|endoftext|>> (edit: asquared tested both 2021-03-03 and 2021-03-05 nightly releases, both by-value and by-ref work on the former, but by-ref breaks on the latter, which I think pretty much confirms the LLVM 12 upgrade fixed the behavior)
It still is UB in latest nightly and LLVM 12 by ref:
```
rustc 1.53.0-nightly (07e0e2ec2 2021-03-24)
binary: rustc
commit-hash: 07e0e2ec268c140e607e1ac7f49f145612d0f597
commit-date: 2021-03-24
host: x86_64-pc-windows-msvc
release: 1.53.0-nightly
LLVM version: 12.0.0
```<|endoftext|>I tried it myself and I can confirm that a by-ref parameter leads to invalid values and that a by-value parameter works. I updated the issue description accordingly.
I will also prepare a pull request for the `x86_64` crate. One potential problem I noticed is that modifying the interrupt stack frame does no longer work reliably with the by-value parameter. It works in debug mode, but not in release mode. So I guess we should remove support for modifying it, at least for now. _Edit:_ I opened https://github.com/rust-osdev/x86_64/pull/242.
Regarding the null segment descriptor: AFAIK it is allowed to have a null-segment descriptor for data segments, however only in kernel mode. For userspace mode, you still need to set up a proper data segment. There was some discussion about this in https://github.com/rust-osdev/x86_64/pull/78.
@Andy-Python-Programmer Judging from your code at https://github.com/Andy-Python-Programmer/aero/blob/713d34955152353b4240a4ef24cf5636ca4f2660/src/arch/x86_64/load_gdt.asm, it looks like you're loading `0x10` into `ss`, so the value is expected in your case. So this seems to be completely unrelated to the `x86-interrupt` calling convention.
> Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does _not_ check if there is an error code and just pops unconditionally
This is expected because there is unfortunately no good way to find out if there is an error code on the stack. So it's the obligation of the programmer to use the correct function signature for each IDT entry. There is no way to use an `x86-interrupt` function without `unsafe` (calling it directly is not allowed), so this does not break Rust's safety guarantees.<|endoftext|>> This is expected because there is unfortunately no good way to find out if there is an error code on the stack
My hack around this:
* Add two fields to `InterruptInfo`: `error_code: u64` and `has_error_code: u64`
* When calling, check for alignment and either push 1 to set `has_error_code` or push 0 two times to zero `error_code` and clean `has_error_code`
* Then either jump directly into `extern "x86-interrupt"` code or save registers and then jump into code with different calling convention
(I haven't tested it though)
```as
test sp, 15
jz no_error_code
push 1
jmp continue_to_handler
no_error_code:
push 0
push 0
continue_to_handler:
// remember about `cld` as direction flag could be set
```<|endoftext|>> One potential problem I noticed is that modifying the interrupt stack frame does no longer work reliably with the by-value parameter. It works in debug mode, but not in release mode.
Using `ptr::write_volatile` does work to modify the interrupt stack. It's not a great way to do it though. Ideally code like
```rust
pub extern "x86-interrupt" fn handler(mut stack: InterruptStackFrame) {
stack.ip = 0;
}
```
would work, however the compiler currently optimizes that write out. It would be best if the compiler could realize that modifying the interrupt stack frame *does* have an effect through the effect of `iretq`.
In the meantime this code works as expected to modify the stack frame
```rust
pub extern "x86-interrupt" fn handler(mut stack: InterruptStackFrame) {
unsafe {
addr_of_mut!(stack.ip).write_volatile(0x0);
}
}
```<|endoftext|>On the other hand, it is just consistent with other calling conventions, where changing preserved registers or return pointer is UB<|endoftext|>@asquared31415 Good idea! I updated my `x86_64` PR to use a volatile wrapper (and added a note about the potential unsafety).<|endoftext|>While I agree that changing those things is normally UB, certain interrupt handlers, especially the debug interrupts, are expected to set some values in the pushed RFLAGS register (normally the resume flag) so that the state is right when it returns. This is the only case where changing saved state is *expected* that I can think of, so I don't know if there's precedent as to how to handle this.<|endoftext|>We discussed this in today's @rust-lang/lang meeting.
We agree that this needs an RFC. Not specifically for x86-interrupt, but an "target-specific interrupt calling conventions" RFC. Once that RFC goes in, new target-specific interrupt calling conventions would just need a patch to the [ABI section of the reference](https://doc.rust-lang.org/stable/reference/items/external-blocks.html#abi), ideally documenting the calling convention.
Would someone involved in this thread be up for writing that RFC?
@phil-opp Would you be willing to write that RFC?
We'd also appreciate an update to the [API evolution RFC](https://rust-lang.github.io/rfcs/1105-api-evolution.html), to note that target-specific calling conventions are only as stable as the targets they're supported on; if we remove a target (for which we have guidelines and process in the target tier policy), removing its associated target-specific calling conventions is not a breaking change.<|endoftext|>> > Also, we have found with @asquared31415 that using the second argument can cause stack corruption, because LLVM does _not_ check if there is an error code and just pops unconditionally
>
> This is expected because there is unfortunately no good way to find out if there is an error code on the stack. So it's the obligation of the programmer to use the correct function signature for each IDT entry. There is no way to use an `x86-interrupt` function without `unsafe` (calling it directly is not allowed), so this does not break Rust's safety guarantees.
I think this is a problem that needs to be solved before `x86-interrupt` can be stabilized. To give an idea of the severity of this issue, let's say a user-space program executes the instruction `int 14` (which invokes the page fault exception handler). In this case no error code is pushed since it's just a software interrupt, not a real page fault. The problem is that the page fault exception handler is still expecting an error code, which isn't there, resulting in stack corruption, with everything off by 8 bytes.
As it stands currently, having an IDT entry directly reference an `x86-interrupt` function that takes an error code is unsound. You would instead need to use a trampoline function to work around the issue as in @Soveu's [solution](#issuecomment-817170881) above. <|endoftext|>> I think this is a problem that needs to be solved before `x86-interrupt` can be stabilized. To give an idea of the severity of this issue, let's say a user-space program executes the instruction `int 14` (which invokes the page fault exception handler). In this case no error code is pushed since it's just a software interrupt, not a real page fault. The problem is that the page fault exception handler is still expecting an error code, which isn't there, resulting in stack corruption, with everything off by 8 bytes.
The problem described here is exactly why you _must_ have `DPL == 0` in any IDT entry for an exception (i.e. vectors 0 though 31). That way, a usermode process cannot corrupt the kernel stack or (more generally) trigger the kernel's interrupt handling code in unexpected ways. With this setup, if usermode executes `int 14`, you just get a `#GP`.
> As it stands currently, having an IDT entry directly reference an `x86-interrupt` function that takes an error code is unsound. You would instead need to use a trampoline function to work around the issue as in @Soveu's [solution](#issuecomment-817170881) above.
I don't think this is true. It's the calling code's responsibility to make sure that each interrupt handler invocation matches its function signature, including:
- If there is an error code pushed or not
- The `InterruptStackFrame` having the correct size/alignment
While the calling convention doesn't provide these protections itself (as its just abound declaring functions), things like the [`x86_64` crate](https://github.com/rust-osdev/x86_64) can help here. It's also worth noting that the "check `sp` alignment and conditionally push values" trampoline code linked above is [not what Linux does](https://elixir.bootlin.com/linux/v5.16.2/source/arch/x86/entry/entry_64.S#L345). Based on the IDT vector, you should _always_ know if an error code is present or not.
In short, I don't think any of the above issues should block stabilization. Of course, the LLVM crashes, error messages, and known issues probably need to be addressed before stabilization. | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 36 | https://api.github.com/repos/rust-lang/rust/issues/40180 | https://github.com/rust-lang/rust/issues/40180 | https://api.github.com/repos/rust-lang/rust/issues/40180/comments |
206,594,148 | 39,699 | Tracking issue for sanitizer support | Currently we have:
- A rustc flag, `-Z sanitizer`, to sanitize rlibs (it adds an extra LLVM pass/attribute) and executables (it links to the sanitizer runtime). Added in #38699.
- An attribute `#[no_sanitize]` to disable sanitization on specific functions. Also lints if those functions are marked as requesting inlining. Added in https://github.com/rust-lang/rust/pull/68164.
- `#[no_sanitize]` suppresses `#[inline]` hints. A lint is issued if combined with `#[inline(always)]`.
- A few violations (false positives?) in the test runner
- [x] ThreadSanitizer detects a data race in the test runner (`rustc --test`) #39608
- [x] MemorySanitizer detects an use of unitialized value in the test runner (`rustc --test`) #39610
- Known issues
- [x] Incremental compilation breaks sanitizers #39611
- Unresolved questions:
- [ ] Should we call the attribute `#[no_sanitize]` or perhaps something like `#[sanitize(never)]` or some other variation? In particular, might we at some point want "positive options" like `#[sanitize(miri(aggressive))]`? There is much back and forth in #68164.
- [ ] What should the user experience be to enable sanitizers, particularly when using cargo? Should cargo have first-class support? Is that blocked on build-std stabilizing? | Just for record. Currently only 4 sanitizers are enabled (asan, lsan, msan, tsan), and only in `x86_64-unknown-linux-gnu` (#38699) and `x86_64-apple-darwin` (#41352).
As of the LLVM 4.0 merge (rust-lang/compiler-rt@c8a8767c5), compiler-rt actually [supports](https://github.com/rust-lang/compiler-rt/blob/c8a8767c56ad3d3f4eb45c87b95026936fb9aa35/cmake/config-ix.cmake#L161) much more targets than rustc do, and also some additional sanitizers (e.g. esan) can be enabled in the future.
| Architecture | x86 | x86_64 | ppc64 | arm32 | arm64 | mips32 | mips64 | s390x |
|----------:|:---:|:------:|:---------:|:---:|:-------:|:----:|:------:|:-----:|
| asan | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| dfsan | | ✓ | | | ✓ | | ✓ | |
| lsan | | ✓ | | | ✓ | | ✓ | |
| msan | | ✓ | ✓ | | ✓ | | ✓ | |
| tsan | | ✓ | ✓ | | ✓ | | ✓ | |
| ubsan | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| esan | | ✓ | | | | | ✓ | |
| cfi | ✓ | ✓ | | | | | ✓ | |
| profile | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| safestack | ✓ | ✓ | | | ✓ | ✓ | ✓ | |
| scudo | ✓ | ✓ | | ✓ | | | | |
| xray | | ✓ | | ✓ | ✓ | | | |
| Platform | linux | android | darwin & ios | windows-msvc | freebsd |
|----------:|:-----:|:-------:|:----------:|:------------:|:-------:|
| asan | ✓ | ✓ | ✓ | ✓ | ✓ |
| dfsan | ✓ | | | | |
| lsan | ✓ | | | | ✓ |
| msan | ✓ | | | | |
| tsan | ✓ | | ✓ | | ✓ |
| ubsan | ✓ | | ✓ | ✓ | ✓ |
| esan | ✓ | | | | |
| cfi | ✓ | | | | |
| profile | ✓ | | ✓ | ✓ | ✓ |
| safestack | ✓ | | ✓ | | ✓ |
| scudo | ✓ | | | | |
| xray | ✓ | | | | |
* asan = [AddressSanitizer](https://clang.llvm.org/docs/AddressSanitizer.html)
* dfsan = [DataFlowSanitizer](https://clang.llvm.org/docs/DataFlowSanitizer.html)
* lsan = [LeakSanitizer](https://clang.llvm.org/docs/LeakSanitizer.html)
* msan = [MemorySanitizer](https://clang.llvm.org/docs/MemorySanitizer.html)
* tsan = [ThreadSanitizer](https://clang.llvm.org/docs/ThreadSanitizer.html)
* ubsan = [UndefinedBehaviorSanitizer](https://clang.llvm.org/docs/UndefinedBehaviorSanitizer.html)
* esan = [EfficiencySanitizer](http://lists.llvm.org/pipermail/llvm-dev/2016-April/098355.html) (work in progress)
* cfi = [Control Flow Integrity](https://clang.llvm.org/docs/ControlFlowIntegrity.html)
* profile = Instrumentation profiler (#38608)
* safestack = [SafeStack](https://clang.llvm.org/docs/SafeStack.html)
* scudo = [Scudo Hardened Allocator](http://llvm.org/docs/ScudoHardenedAllocator.html) (useless for jemalloc)
* xray = [XRay Instrumentation](http://llvm.org/docs/XRay.html) (requires LLVM attribute)
(not all of these are sanitizers, some of them are just tools or libraries that depend on the common sanitizer runtime)<|endoftext|>Is there any plan for stabilization here? Even if it remains x86_64-only for now, with only a few of the available sanitizers, it will still be quite useful to have. I have users that want this ([rhbz1447423](https://bugzilla.redhat.com/show_bug.cgi?id=1447423)), but now that [-Z is forbidden](https://github.com/rust-lang/rust/pull/41751) I want to wait for properly-supported sanitizer options.<|endoftext|>Hi,
If I understand this issue, you would like to block certain -Z features from coming to stable rust. Sanitisers seems to be one of these. We have a very good use case for them though. When you have a C + Rust with FFI, and the C code is linked to libasan, the rust component will fail to link as it's missing libasan. For us it's important to get sanitisers into rust stable as we have an extensive C code based (that is well sanitised), and having this option available to us will help to determine if our Rust + C integration is behaving correctly.
I hope this helps explain our use case, as for us this is a blocker to our project adopting Rust today.
Thanks you! <|endoftext|>FWIW, it's not just certain -Z features, but -Z as a whole being blocked as unstable now.<|endoftext|>#42711 PR for dylib asan support.<|endoftext|>Hi,
I don't see any activity here. We really need this for our quality assurance workflow to be stabilised. What is outstanding and required for this to be made available in stable rustc?
Thanks! <|endoftext|>Hi, sorry to bump this again, but @kennytm @aturon @japaric, would you be able to look at this and comment on why this is still blocked from being in "not-nightly"? We really need this support for our project to be able to adopt rust 100%.
Thanks,<|endoftext|>Any updates on this?
Using UBSan is an important feature, though I think it will require recompiling libstd with UBSan enabled<|endoftext|>* The memory sanitizer false positives from #39610, #54365 can be now avoided by instrumenting std using `cargo -Zbuild-std`.
* The thread sanitizer false positive from #39608, could be addressed by #65097 (when combined with `cargo -Zbuild-std`).
<|endoftext|>I'm interested in the XRay LLVM support; is this bug a sensible place to talk about that, or should I file a new bug, or an internals discussion ?<|endoftext|>The guide to rustc development now contains [an overview of sanitizer implementation in rustc](https://rust-lang.github.io/rustc-guide/sanitizers.html). It should be a good starting point for work on additional sanitizers or even XRay since there is a lot of common ground there.
<|endoftext|>Hi, is there a way to access sanitizer interfaces, e.g., the [`__asan_poison_memory_region`](https://github.com/llvm/llvm-project/blob/main/compiler-rt/include/sanitizer/asan_interface.h#L34)
A use case is when designing custom allocators based on `mmap`, those functions help to make the sanitizers more accurate and helpful.
Related: https://github.com/google/sanitizers/wiki/AddressSanitizerManualPoisoning<|endoftext|>@XiangpengHao when building with sanitizer enabled it should be matter of declaring it with `extern "C" { ... }` and simply calling it. For example https://github.com/rust-lang/rust/blob/f412fb56b8d11c168e7ee49ee74e79c4ab2e5637/src/test/ui/sanitize/thread.rs#L32-L35.<|endoftext|>Thanks, that saves my day!<|endoftext|>curious question: is there any way that the sanitizers could eventually be enabled in a `#![no_std]` context for currently unsupported targets / is that possible to do with (assumedly) a lot of heavy lifting? I have an OS kernel I've been developing which involves a lot of unsafe code and it would be nice to have at least a sub-selection of the sanitizers available in that environment for debugging and helping check that my unsafe code is correct :) I'd be perfectly fine with filling in any missing functions that would fail to link, etc, to support this in my project if the base instrumentation for the code is there.<|endoftext|>So, if you use `#[cfg(sanitize = "thread")]` (or, pick your fav sanitizer) on stable/beta, it produces a feature gate error rather than just evaluating to false.
I think we should considering removing the feature gate from just the `#[cfg(sanitize = "...")]` used to test if a particular sanitizer is enabled, and allow use of that cfg, even on stable, where (until the rest of the sanitizer stuff mentioned here stabilizes) it will just evaluate to false.
1. It evaluating to false is completely correct behavior for rust versions/configurations that don't support compiling with sanitizers, because obviously that means the sanitizer cannot be enabled.
2. If we do this and later decide *against* stabilizing sanitizer support, even removing it from rustc. everything would be fine, and we wouldn't have to keep any code for supporting this around at all.
The `#[cfg(sanitize = "...")]` would continue to accurately evaluate to false, breaking no code, and continuing to provide perfectly correct answers forever.
3. It's already pseudo-stable. You can currently emulate it using a build.rs which examines `env::var("CARGO_CFG_SANITIZE")`, and the fields it has to the crate (behind, say, a `cargo:rustc-cfg=__tsan_enabled` or similar).
(Note: This seems somewhat different to me than code that checks for nightly rustc at compile time, it handles nightly and stable identically, and only operates using env vars provided by `cargo`)
There's code in the wild that does this, and it works without caveats beyond "it's not great that this is required", "it's also not great that it works", and "it's undesirable to add a build.rs just for this purpose".
4. The feature is harmless, low impact, seems to have an obvious design, and has been around for a while. It seems doubtful that we will regret doing this now, so yeah.
So yeah, I don't see a downside to doing that. Again, I'm speaking *only* about the `cfg`, not the rest of the feature tracked in this issue. (I'm not even really sure if I'm asking for it to be stabilized, or for an overzealous feature gate check to be removed).
P.S. I'm unsure of how to move forward with this, given that this tracking issue tracks so many parts. Thanks.<|endoftext|>What are the steps or blockers for enabling ASan on rustc targets beyond `x86_64-unknown-linux-gnu` and `x86_64-apple-darwin`? In particular, I would like to enable ASan for `armv7-linux-androideabi`, `aarch64-linux-android`, `i686-linux-android`, and `x86_64-linux-android`. The [rustc-dev-guide](https://rustc-dev-guide.rust-lang.org/sanitizers.html) doesn't have info for how to go about adding new targets.<|endoftext|>I'm getting `"ThreadSanitizer: unexpected memory mapping"` on Debian 11 with latest nightly. I tried changing relocation model but it doesn't help. Anyone has an idea?<|endoftext|>I have a problem. Why is there no specific number of lines displayed here?
References:https://github.com/rust-lang/rust/issues/90977
Excuse me, I've taken care of it.<|endoftext|>Is it possible to get a quick overview of the status of this? The ASAN on Linux seems to work really well and is an invaluable tool in a mixed Rust and C application. Is it possible to stabilize this in steps?
After the incredible recent push of @joshtriplett to stabilize commonly used features like `instrument-coverage` this will be the last thing forcing a nightly compiler in the test pipeline of my company.<|endoftext|>visiting for T-compiler backlog bonanza.
@rustbot label: +S-tracking-needs-summary
(We cannot tell what the current status of this thing is. Its clear from comments like the one immediately above that there are people interested in this and are using it.)<|endoftext|>Wanted to voice my support for this for usage in [fazi](https://github.com/landaire/fazi) and also suggest that this should expand to whole packages. e.g. I would not like to instrument *any* code in Fazi, but any callers of Fazi should be instrumented.
Additionally, I think `sancov` should be included in this. The reason I found this issue is because my fuzzing library gets compiled with `sancov` hooks and deadlocks while handling said hooks.<|endoftext|>On the naming of `no_sanitize` – as I was reviewing the shadow stack PR it seemed to me much more natural that you’d be able to say which functions you want to sanitize as well. Is this really the best design for an attribute in the context of knowledge that a) not every sanitizer requires linking in a support library; and b) it might make sense to sanitize specific functions (does it?) at some point in the future?<|endoftext|>Are there any technical blockers that prevent this from "graduating" to stable?
Rust is being used in more mixed language codebases, and with the merging of Rust support in the Linux kernel, I'd like to enable some of the kernel sanitizers (KCSAN, KASAN) for Rust code there eventually. This would improve the C bindings (if there are bugs) but also prove Rust's safety proposition quantitively (i.e. data showing fewer or no bugs found in Rust code).
Thanks.<|endoftext|>Is there a separate issue tracking ASAN enlightenment for container types like `Vec<T>`? I haven't tested this, but I believe that today if you were to allocate a `Vec` whose `len() < capacity()` and pass its data pointer across an FFI boundary you wouldn't detect OOB accesses in the range of `[ptr + len, ptr + cap]`. I didn't see any calls to `__asan_poison_memory_region` or `__sanitizer_annotate_contiguous_container` so I suspect this is true.
LLVM's libc++ ASAN enlightenment for `std::vector<T>` can be found here: https://github.com/llvm/llvm-project/blob/b7a2ff296352acacdc413d6f3f912e50f90ebb31/libcxx/include/vector#L740-L750
This issue isn't really unique to vectors either -- any container that over-allocates memory to reduce total number of allocations would be affected.<|endoftext|>The bad thing in my environment is the following. At my job I am developing a mixed Rust and C program built with Cargo. We already had a few ASAN findings slip into the main branch because during development ASAN is not used. I want to enforce, that every developer has ASAN active all the time and currently I only see the following options:
1. Force everyone to use the nightly compiler. This might be possible, when pinning a certain nightly version that works well. But this sounds really wrong on many levels.
2. Only sanitize C code (`CFLAGS="${CFLAGS} -fsanitize=address,undefined" RUSTFLAGS="${RUSTFLAGS} -Clink-arg=-fsanitize=address,undefined"`).: this might just be the way I will proceed. Obviously the unsafe Rust code here will be omitted, but in the past we did not have any bugs there. Still it feels wrong to leave out parts of the code from the instrumentation.
<|endoftext|>@kamulos I think this is getting a little off-topic, but can you set up a CI with a nightly compiler? I did this recently for Mio (using Github Action, but it should work anywhere) if you want a concrete example: https://github.com/tokio-rs/mio/blob/7ed74bf478230a0cfa7543901f6be6df8bb3602e/.github/workflows/ci.yml#L115-L128, https://github.com/tokio-rs/mio/blob/7ed74bf478230a0cfa7543901f6be6df8bb3602e/Makefile#L20-L24.<|endoftext|>@Thomasdezeeuw absolutely, we have that, but it only runs a very basic set of tests and unfortunately some findings slipped through that, and were only later caught in the full test run which also is done with the sanitized debug binary (built with a nightly compiler). So a big part of our testing is done on a binary built with a nightly compiler which is not really that great.
For any C or C++ program I like to enable the sanitizer all the time (especially during development) and only leave out the instrumentation for the release build. Having this feature unstable makes this a bit awkward.
This just seems strange, because it is such an important feature, that (for me) works flawlessly. | B-unstable<|endoftext|>T-dev-tools<|endoftext|>A-sanitizers<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary<|endoftext|>A-cli | 28 | https://api.github.com/repos/rust-lang/rust/issues/39699 | https://github.com/rust-lang/rust/issues/39699 | https://api.github.com/repos/rust-lang/rust/issues/39699/comments |
198,392,796 | 38,789 | NVPTX backend metabug | The NVPTX backend has been available since: nightly-2017-01-XX
This is a collections of bugs and TODOs related to it.
### Documentation
- [How to: Run Rust code on your NVIDIA GPU](https://github.com/japaric/nvptx)
### Bugs
- LLVM assertion when compiling `core` to PTX. #38824
- LLVM error when emitting PTX code with debuginfo. #38785
- NVPTX: No "undefined reference" error is raised when it should be. #38786
- NVPTX: non-inlined functions can't be used cross crate. #38787
### Missing features
- The equivalent to CUDA's [`__shared__`] modifier. Probably needs an RFC to land
in the compiler as we don't have anything similar to it (AFAIK).
[`__shared__`]: https://docs.nvidia.com/cuda/cuda-c-programming-guide/#shared
### Stabilization
- Stabilize the nvptx targets. IOW, add them to the compiler. [Candidates] for [merging].
[Candidates]: https://github.com/japaric/nvptx/blob/master/nvptx64-nvidia-cuda.json
[merging]: https://github.com/japaric/nvptx/blob/master/nvptx-nvidia-cuda.json
- All the non-trivial kernels make use of intrinsics like `blockIdx.x`. These will have to be stabilized. Right now these intrinsics are implemented as `"plaform-intrinsics"` but that feature is unstable.
- Stabilize the `"ptx-kernel"` ABI. #38788
cc @rkruppe
| It would be better if instead of having to create a new module / crate, adding the `#![feature(abi_ptx)]` feature, and then declaring the kernels as `extern "ptx-kernel" fn foo() {}`, we could just handle this using `#[target_feature]`, so that one can add kernels within a non-kernel Rust module. It would be great if this attribute could be applied to closures as well.
That way we could just write our kernels inline with normal Rust code.
```rust
#[target_feature(enabled = "ptx_device_fn")] unsafe fn a_device_fn(...) { ... }
#[target_feature(enabled = "ptx_kernel")] unsafe fn a_kernel(...) { ... a_device_fn(...) ... }
unsafe fn bar() {
cuda::driver::launch(x, y, z, w, a_kernel);
cuda::driver::launch(x, y, z, w, #[target_feature(enabled = "ptx_kernel")] |...| a_kernel(...) );
}
```
This way users can use the typical `target_feature` facilities to write portable code.<|endoftext|>@japaric @rkruppe @alexcrichton I'd like to work on this. <|endoftext|>You seem to assume a "single source" model? We don't have that currently. You have to compile your kernels as one crate for a `nvptx-*` target, then embed the resulting PTX asm as string/resource into a crate that's compiled for the host target. The latter crate passes it to the driver for compilation. There's no way to mix host and device code in one compilation unit like nvcc allows.
Supporting that would require novel frontend integration (novel for Rust; clang has something like this already). For example rustc would have to decide for each translation item whether it should be compiled for the host, for the device, or both -- and then combining the resulting PTX and host object files.
Additionally, even if/once we have "single source", `target_feature` seems inappropriate, since `target_feature` is for modifying the available instruction set within one target, while this here requires compiling the code for a different target altogether (and in many cases, for *two* targets as mentioned before). A custom attribute _might_ be more appropriate but since this is really about "entry point for device code or not" rather than "can run on device or not" an ABI seems fine too.<|endoftext|>> Additionally, even if/once we have "single source", target_feature seems inappropriate, since target_feature is for modifying the available instruction set within one target,
Indeed, makes sense.
> Supporting that would require novel frontend integration (novel for Rust; clang has something like this already). For example rustc would have to decide for each translation item whether it should be compiled for the host, for the device, or both -- and then combining the resulting PTX and host object files.
>
> A custom attribute might be more appropriate but since this is really about "entry point for device code or not" rather than "can run on device or not" an ABI seems fine too.
I'd like to work on enabling this via a mixture of the ABI solution to choose, e.g., the `ptx` or `ptx-kernel` ABIs, and `target_feature` to choose, e.g., `sm30` vs `sm70`.
If we could have these multiple ABIs into a single source file, we could have `#[target_device]` and `#[target_device_kernel]` procedural macros that just generates copies of a function for different ABIs:
```rust
#[inline]
fn baz() { }
#[target_device(host, nvptx(sm = "40"), spirv(version = "1.0"))]
fn bar(...) { ... }
#[target_device_kernel(host, nvptx(sm = "40"), spirv(version = "1.0"))]
fn foo(...) {
#[device] bar(...); // device attribute indicates that this fn is a device fn
baz(); // this function will be used as is
}
```
that expand to:
```rust
fn baz_host(...) { bar_host(...); baz(); }
#[target_feature(enabled = "sm40")]
extern "ptx" fn baz_nvptx(...) { bar_nvptx(...); baz(); }
extern "spriv" fn baz_spirv(...) { bar_spirv(...); baz(); }
fn foo_host(...) { bar_host(...); baz(); }
#[target_feature(enabled = "sm40")]
extern "ptx-kernel" fn foo_nvptx(...) { bar_nvptx(...); baz(); }
extern "spirv-kernell" fn foo_spirv(...) { bar_device(...); baz(); }
```
And then just launch the kernels using another procedural macro, e.g., `kernel_launch!(foo, args...)`.
One cool feature of clang and nvcc is to allow whoever builds the library to easily choose the devices to target. Procedural macros could allow these via feature flags: `--features target_device_nvptx_sm_35, nvptx_sm_70, ...` (it's not nice, but should be at least doable).
This approach leaves the door open to doing something nicer in the language in the future, while allowing libraries to experiment with better APIs. I wonder whether these two building blocks (extern ABIs in a single source file, and `#[target_feature]`) are a good way to do this, and whether this is something that a nicer approach is going to need in one form or another, or whether this approach is completely wrong and there is a better alternative.<|endoftext|>Frankly, I don't see how any of the tools we have in the language now (target_feature, proc macros, ABIs) can help at all with single source support. Right now, one crate is compiled for one target, period. Subsets of the crate can tweak some parts of the target (e.g., use non-standard ABIs or enable/disable instruction set extensions) but that's a far cry from slicing out a subset of the crate, compiling it for a completely different target, and then stitching the results back together -- and that's precisely what is necessary for single-source offloading (not just CUDA, but also everything else along these lines that I've seen).
In fact the assumption that one crate == one target goes as far as `rustc` being literally unable to store more than one target per compilation session (`Session`). Not to mention how you need to generate a whole separate LLVM module for the PTX code.
Even if one attempts to minimize the amount of compiler changes needed during prototyping for faster iteration (generally a good idea) by e.g. splitting the crate into two crates with an external tool and invoking rustc twice, there is ample room for compiler hacking. Even the bare minimum of single source support requires name resolution information, and being able to use *generic* library code will require type system integration as well.
So in my opinion, this is a rather big feature with *at least* as much need for experimentation and compiler hacking and design work as SIMD intrinsics. I say this not to discourage you but because your posts so far ignore the technical challenges that are, in my opinion, the biggest obstacle to single source support.
I'm also rather puzzled by the priorities here. Before experimenting with the best way to allow users to compile their single-source applications not just for multiple CUDA devices but also for entirely different targets like SPIR-V, basic features like an equivalent to `__shared__` seem like a simpler and more important first step. Again, not trying to discourage, but even the greatest most ergonomic portable offloading solution seems pointless if the kernels can't even use group-shared memory.<|endoftext|>> Frankly, I don't see how any of the tools we have in the language now (target_feature, proc macros, ABIs) can help at all with single source support.
Oh no, I think I expressed myself wrong. I meant that **once** we get single source support using extern ABIs, the combination of tools that we have already available in the language can allow for pretty nice APIs.
> basic features like an equivalent to __shared__ seem like a simpler and more important first step.
I think that `__shared__` can be implemented as a `core::intrinsic` and is thus not a big deal: `fn shared() -> *mut u8` would do.<|endoftext|>> I meant that once we get single source support using extern ABIs,
What does this mean? I am not aware of any plans for any kind of single source support. And what does "using extern ABIs" mean? It seems to presuppose some strategy for single source support but it's not clear to me which one (and it doesn't sound like any of the strategies that I am aware of). Finally, assuming I'm correct that single source support is not on the horizon, I'm puzzled why we're hashing out details of how it could be exposed better to the user if the basic technical prerequsites aren't even on the horizon.
> I think that __shared__ can be implemented as a core::intrinsic and is thus not a big deal: fn shared() -> *mut u8 would do.
IIUC such an intrinsic would be basically like an `alloca` intrinsic, which Rust has rejected in favor of better support for unsized (DST) values. So while this is a possible strategy (although I can think of some technical challenges as well) that a prototype implementation might choose, it is far from clear to me that it's the approach we'd want to adopt.<|endoftext|>> IIUC such an intrinsic would be basically like an alloca intrinsic
How so? The kernel does not allocate anything: `__shared__` just initializes a pointer with a value.
> Finally, assuming I'm correct that single source support is not on the horizon
I'd like to work on enabling single source support and I'd like to enable it in such a way that it is useful.
> And what does "using extern ABIs" mean?
In a single source model:
```rust
extern "ptx-kernel" unsafe fn foo(...) { ... is compiled to a ptx kernel ... }
fn bar(...) { ... is compiled for the host ... }
```<|endoftext|>> How so? The kernel does not allocate anything: __shared__ just initializes a pointer with a value.
It's a *storage specifies* in C parlance. You declare variables to live in shared memory as opposed to thread-private memory or global memory or constant memory. In pointer types it's just an *optional* hint that the pointee lives in shared memory, that aspect isn't even needed. What is absolutely necessary is to be able to do declare locals like `__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];` (from http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared-memory) which is like `let As: [[f32; BLOCK_SIZE]; BLOCK_SIZE];` except there's just one array per thread group, accessed by all threads in the group.<|endoftext|>> It's a storage specifies in C parlance.
Sure, but what's the point of making it a storage specifier in Rust? You can't have two variables on shared memory, that is, the following is not valid CUDA C:
```c++
__global__ void foo(float* foo) {
__shared__ a float[];
__shared__ b float[]; // ERROR: you can only have one pointer to shared memory per kernel
foo[0] = a[0] + b[t0];
}
```
> What is absolutely necessary is to be able to do declare locals like __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; (from http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared-memory)
In particular, here you are not allocating a `float [BLOCK_SIZE][BLOCK_SIZE];` region of shared memory, but assigning the pointer to shared memory to a `float [BLOCK_SIZE][BLOCK_SIZE]` array (C arrays are just pointers). This might lead to UB if no memory actually has been allocated, or if some other kernel reinterpreted it to have another type, or if less memory than the one required here was allocated, etc.
So IMO, independently of what the spec says, we should focus on the actual semantics of `__shared__`. The only thing `__shared__` does is initializing some pointer to point to the shared memory region with the restriction that one cannot initialize two pointers to it. Nothing more, nothing less. It does not allocate anything, it does not guarantee that any memory exists, or was allocated, or that the data in the memory has some "type", ... no nothin'.
This
```c
extern __shared__ a float[];
```
is just:
```c
float* a = __get_ptr_to_shared_memory();
```<|endoftext|>I want to point out that we're pretty badly derailing this metabug. You should probably open a thread on internals.rlo if you want to take this discussion much further.
But first I would invite you to double check your facts. Many things you've said go against everything I've ever heard and seen about CUDA (and other offloading solutions, for that matter).
> Sure, but what's the point of making it a storage specifier in Rust?
I'm not saying it should be a storage specifier in Rust. We don't even have such a concept at the moment. I'm just saying, it's fundamentally a variation on variable declaration (like DST locals), not something about pointers.
> You can't have two variables on shared memory, that is, the following is not valid CUDA C:
???? Check the code I linked earlier, it has at least two such variables. Or pretty a random non-trivial CUDA program using shared memory. I don't know why the code you give is rejected, but I've never even seen this syntax so I'm not even sure what it means.
> For all you know, As[0] will fail because no shared memory actually has been allocated.
Are you saying Nvidia's examples, as well as all the other programs using shared memory, are effectively borked? That can't be right. In fact, I'm pretty sure the size of the is recorded (provided it has a size -- again I don't know wth `__shared__ a float[];` is) in the binary and the scheduler makes sure to only place as many thread groups on one core as the available shared memory permits. I know this because it means the amount of shared memory you use impacts occupancy and thus performance.
That reminds me, another way in which such intrinsic for `__shared__` would be weird is that it should probably require the size to be a compile time constant (unlike alloca).<|endoftext|>> but I've never even seen this syntax so I'm not even sure what it means.
That syntax is the **dynamic** shared memory allocation syntax.
> That reminds me, another way in which such intrinsic for __shared__ would be weird is that it should probably require the size to be a compile time constant (unlike alloca).
The size of the shared memory region can be specified at run-time, at least in CUDA.
Reading through the docs of the example you mention, if the size of the variables allocated in shared memory are compile-time constants, and no dynamic shared memory allocation occurs, it looks like one does not need to specify the memory to allocate during kernel launch because the compiler does it for you (but I've always used dynamic shared memory so I am not sure).<|endoftext|>Good to know that there's a dynamic allocation strategy as well. But it seems that you still specify the size, just at kernel invocation time? That seems like it would still allow the driver to make sure enough memory is available (i.e., as much memory as the kernel invocation specified; of course the kernel still needs to obtain and use that number correctly). For dynamic an intrinsic might be good, but since static shared memory allocation seems extremely common, we'd probably want to support it as well and an intrinsic can't really do that (well).<|endoftext|>> But it seems that you still specify the size, just at kernel invocation time?
Yes.
> That seems like it would still allow the driver to make sure enough memory is available (i.e., as much memory as the kernel invocation specified; of course the kernel still needs to obtain and use that number correctly).
Exactly. The typical way in which this is used is by passing something that correlates with the allocated size as a run-time argument to the kernel.
> For dynamic an intrinsic might be good, but since static shared memory allocation seems extremely common, we'd probably want to support it as well and an intrinsic can't really do that (well).
Yes definitely. Since dynamic shared memory is more powerful (it allows doing everything that can be done with static shared memory and some more), has no drawbacks over static shared memory beyond ergonomics (shared memory is always allocated at run-time, whether the size is known are compile-time or not is pretty much irrelevant), and can probably just be an `nvptx` intrinsic that returns a pointer to the shared memory region, I think that implementing support for it would be the tiniest incremental step that delivers the most value.
Adding support for `__shared__` static memory would be a nice ergonomic addition. If you have device-only functions that need to be called from kernels, using static shared memory in them allows you to bump the size of the allocated memory region transparently (using dynamic shared memory these functions would need to take as argument a pointer into a suitable part of the shared memory region).
AFAIK only fixed-size arrays are allowed in static shared memory and the memory must be uninitialized. So while something like `let floats: #[shared] [f32; N] = mem::unitialized();` might work, I think here it would be better to just provide an `nvptx::shared_array<[T; N]>`type, implemented using compiler magic to put it always on static shared memory, that provides a minimal API that makes sense for shared memory array since things like bounds checking by default (as provided by arrays) make little sense in device kernels where you might not have a way to panic, abort, print anything, etc.<|endoftext|>Note that I'm interested in funding work on this: https://internals.rust-lang.org/t/nvptx-funding/7441
I'd like to get this to work out of the box on nightly. <|endoftext|>Hi,
I've started using the NVPTX backend for some simple experiments, I'm listing my experiences here so far since I don't know what the proper protocol is. We can turn these into specific issues on the right repo's later on.
- [ ] Name mangling is sometimes incorrect because the LLVM backend outputs names with `.` in some cases and PTX only accepts `[a-zA-Z0-9_$]+`
```rust
pub struct MyStruct {
data: u32,
}
impl PartialEq for MyStruct {
fn eq(&self, other: &Self) -> bool {
return self.data == other.data;
}
}
```
Leads to invalid PTX since symbols are being generated with dots in them:
```ptx
.visible .func (.param .b32 func_retval0) _ZN59_$LT$nvkernel..MyStruct$u20$as$u20$core..cmp..PartialEq$GT$2eq17hebe67210677cfb7eE(
.param .b64 _ZN59_$LT$nvkernel..MyStruct$u20$as$u20$core..cmp..PartialEq$GT$2eq17hebe67210677cfb7eE_param_0,
.param .b64 _ZN59_$LT$nvkernel..MyStruct$u20$as$u20$core..cmp..PartialEq$GT$2eq17hebe67210677cfb7eE_param_1
)
{
.reg .pred %p<2>;
.reg .b32 %r<4>;
.reg .b64 %rd<3>;
ld.param.u64 %rd1, [_ZN59_$LT$nvkernel..MyStruct$u20$as$u20$core..cmp..PartialEq$GT$2eq17hebe67210677cfb7eE_param_0];
ld.u32 %r1, [%rd1];
ld.param.u64 %rd2, [_ZN59_$LT$nvkernel..MyStruct$u20$as$u20$core..cmp..PartialEq$GT$2eq17hebe67210677cfb7eE_param_1];
ld.u32 %r2, [%rd2];
setp.eq.s32 %p1, %r1, %r2;
selp.u32 %r3, 1, 0, %p1;
st.param.b32 [func_retval0+0], %r3;
ret;
}
```
I haven't looked much into it but I have a feeling that it's due to https://github.com/rust-lang/rust/blob/master/src/librustc_codegen_utils/symbol_names.rs#L424
- [ ] So far I've only been able to get this to run and compile with the `nightly-2018-02-12` compiler (due to this PR https://github.com/japaric/core64/pull/4 ) anything newer seems to spew quite a few compile errors after trying to manually create my own `core64` lib.
- [ ] It would be nice to see if we can add a "kernel" attribute to expose some (all) of these https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#performance-tuning-directives to tweak occupancy & register counts similar to CUDA
- [ ] Find a way to expose vector loads & stores (`ld.v4.f32` etc) since they're significantly faster. One way would be through the platform intrinsics
- [ ] Expose `__shared__` memory (as per discussion previous) though preferably as static kernel side memory - though ideally both options are available since this too factors into the kernel occupancy
- [ ] Expose `__constant__` memory similar to `__shared__`.
- [ ] Expose cross-lane swizzle ops (`shfl.bfly`, `shfl.up` etc) as platform intrinsics
- [ ] Right now the target json determines the `sm` target machine and fixes it at `sm_20` which is extremely dated (Fermi gpus). It would be nice if this was more flexible - though for now patching the json works too.
- [ ] I have some confusion whether `repr(C)` would be good enough of a layout to share data between GPU and CPU or if we'd eventually need another one.
- [ ] It's not entirely clear to me if `__syncthreads` is also a compiler barrier or not but it ought to be since the compiler shouldn't schedule memory requests across it.
On the bright side: this has been a really pleasant GPU programming experience so far (other then actually getting it set up) because it's extremely valuable to share the same codebase between CPU and GPU.<|endoftext|>I have not been able to compile to PTX with cargo or xargo, I've only been able to do so using accel. Therefore, some of the following may be issues with Accel. That seems unlikely, so I'll report them here.
* I see an internal compiler error if the PTX code references the `core::intrinsics::sinf32` or `cosf32` functions
* INVALID_PTX error if I index into a slice (I saw the same error if I used `get_unchecked`) in the PTX code
* INVALID_PTX error if I use the `for x in 0..y` loop in the PTX code
* INVALID_PTX error if any struct in the PTX code implements `core::ops` traits like Add or Mul
* INVALID_PTX error if any struct in the PTX code derives Debug or Display
Most of these are probably due to references to missing functions in the final PTX, but they'll need to be dealt with somehow.
I am interested in contributing to improve the state of GPGPU in Rust. Not sure where to start.<|endoftext|>> Name mangling is sometimes incorrect
> Leads to invalid PTX since symbols are being generated with dots in them:
I've met this issue [while developing accel](https://github.com/rust-accel/accel/pull/16) , and it prevent me to use libcore for nvptx target. accel cannot link libcore or other std libraries currently.
I recently start to write [a patch](https://github.com/rust-accel/rust/pull/1) to rustc to enable nvptx target.
> I haven't looked much into it but I have a feeling that it's due to https://github.com/rust-lang/rust/blob/master/src/librustc_codegen_utils/symbol_names.rs#L424
this seems to be a good information for me :)<|endoftext|>#53099 is relevant here. I haven't been able to compile any kernel recently, because of a segfault while compiling `libcore`. This happens on all machines where I've tried it (Windows and Linux). However, other people say that they've been able to compile NVPTX kernels without running into this issue. Has anyone else seen this?<|endoftext|>@bheisler I believe it somehow related to definition json. It doesn't happend to me with [json from ptx-linker](https://github.com/denzp/rust-ptx-linker/blob/master/targets/nvptx64-nvidia-cuda.json), but I saw the problem with another one.<|endoftext|>I'm finally proud to announce my progress on CUDA integration. I've made several tools to ease development and currently working on a tutorial and high-level crate (it will probably be a custom rustc driver because `compiler plugins` are de-facto deprecated).
First one is a [ptx-linker](https://github.com/denzp/rust-ptx-linker) that solves several important problems:
* recently mentioned issue about dots in functions or global variables names,
* #38786 "undefined references" validation,
* #38787 linking of multiple LLVM modules.
I started work on the linker about a year ago, and today achieved important milestone: it doesn't depend on any external tools and libs anymore. So end users don't need to care about matching Rust's and system's LLVM versions (which became a problem when Rust switched to LLVM 7.0).
The second crate is a [ptx-builder](https://github.com/denzp/rust-ptx-builder) that improves development convenience dramatically. It's a `build.rs` helper that ensures all needed tools (`xargo` and `ptx-linker` atm) are present. It also manages a build environment and `xargo` runs.
Also worth checking, [an incomplete tutorial](https://github.com/denzp/rust-inline-cuda-tutorial) about CUDA development flow with more or less real example.
The tutorial evolved as mentioned before tools did. And more chapters are yet to come :)
Sometimes I run tests from there, to ensure PTX assembly is correct and the whole thing still works :)<|endoftext|>@denzp Can ptx-linker link with libcore? I am creating a [toolchain](https://github.com/rust-accel/rust) to link libcore using llvm-link in [rust-accel/nvptx](https://github.com/rust-accel/nvptx). Linking of libcore will cause the symbol name issue as reported by @Jasper-Bekkers due to the difference between GAS and PTX, and I avoid it by [rewriting librustc_codegen_utils/symbol_names.rs](https://github.com/rust-accel/rust/pull/6).<|endoftext|>@termoshtt The linker suppose to fix this, it has [a special "pass"](https://github.com/denzp/rust-ptx-linker/blob/master/src/passes/rename.rs) that does renaming. The problem can happen not only with `libcore` though: consts or [structs](https://github.com/denzp/rust-ptx-linker/blob/master/examples/intrinsics/src/lib.rs) can also produce invalid PTX sometimes:
``` rust
src_image.pixel(i, j)
```
```
call.uni (retval0),
_ZN32_$LT$example..Image$LT$T$GT$$GT$5pixel17h81db5ad692bcf640E,
(param0, param1, param2);
```
I found the linker robust enough about solving the issue. But still, I'd probably prefer this to be fixed in rustc.<|endoftext|>@denzp - I don't think it's caused by the target JSON, unfortunately. When I add the `obj-is-bitcode` flag to my target file it compiles without segfaulting, but that means it no longer writes PTX files but instead writes LLVM bitcode.<|endoftext|>@bheisler I can confirm that `obj-is-bitcode` indeed helps to avoid segfault (that's the reason I've never seen the problem before, I always use the flag). But it doesn't affect assembly file creation for me. Let's move further discussion into #53099<|endoftext|>#38824 is closed about a month ago. I think we can remove it from the list?<|endoftext|>Triage: this is a metabug. Not aware of anything particular going on with this target lately.<|endoftext|>Visited for T-compiler backlog bonanza. It seems like there are some unresolved questions about scope and design, with respect to the concerns that were raised on this thread between @hanna-kruppe and @gnzlbg . (Basically, its not clear to me whether the work remaining here is "just" more implementation and fixing bugs, or if there's some design stuff that needs to be revisited.)
@rustbot label: +S-tracking-needs-summary | metabug<|endoftext|>O-NVPTX<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 28 | https://api.github.com/repos/rust-lang/rust/issues/38789 | https://github.com/rust-lang/rust/issues/38789 | https://api.github.com/repos/rust-lang/rust/issues/38789/comments |
198,392,389 | 38,788 | Tracking issue for the "ptx-kernel" ABI | Introduced in #38559.
Feature gate: `abi_ptx`
This ABI is used to generate ["global"] functions. All the other functions that *don't* use the "ptx-kernel" ABI are ["device"] functions.
["global"]: https://docs.nvidia.com/cuda/cuda-c-programming-guide/#global
["device"]: https://docs.nvidia.com/cuda/cuda-c-programming-guide/#device-function-qualifier
The host can only make the device, the GPU, execute global functions, not device functions. IOW, a PTX module that only contains device functions is basically unusable.
---
Note that this ABI *can't* be emulated using naked functions.
``` rust
#![feature(abi_ptx)]
#![feature(naked_functions)]
#![no_std]
#[naked]
#[no_mangle]
fn foo() {}
#[no_mangle]
fn bar() {}
#[no_mangle]
extern "ptx-kernel" fn baz() {}
```
Produces:
```
.version 3.2
.target sm_20
.address_size 64
.func foo()
{
.local .align 8 .b8 __local_depot0[8];
.reg .b64 %SP;
.reg .b64 %SPL;
mov.u64 %SPL, __local_depot0;
bra.uni LBB0_1;
LBB0_1:
ret;
}
.func bar()
{
.local .align 8 .b8 __local_depot1[8];
.reg .b64 %SP;
.reg .b64 %SPL;
mov.u64 %SPL, __local_depot1;
bra.uni LBB1_1;
LBB1_1:
ret;
}
.entry baz()
{
.local .align 8 .b8 __local_depot2[8];
.reg .b64 %SP;
.reg .b64 %SPL;
mov.u64 %SPL, __local_depot2;
bra.uni LBB2_1;
LBB2_1:
ret;
}
```
Note that only `baz` uses the `.entry` directive. | Triage: not aware of any movement on stabilizing this.<|endoftext|>would be very interested in this! any of y'all know what needs doing to bring this back to life?
edit: following links through the metabug, and then through a project that mentioned the metabug, looks like there are in fact folks still interested. cool! <|endoftext|>I'm curious if I might have found a codegen bug related to this feature. It is related to how the struct is assumed to be passed to the kernel.
<details open>
<summary>When compiling the following Rust code</summary>
```rust
#![no_std]
#![feature(abi_ptx, stdsimd)]
#[panic_handler]
fn panic(info: &core::panic::PanicInfo) -> ! {
unreachable!()
}
#[repr(C)]
pub struct Foo{
array: [f32; 9],
}
#[no_mangle]
pub unsafe extern "ptx-kernel" fn add(a: *mut f32, b: Foo) {
*a = b.array[5];
}
```
</details>
<details close>
<summary>Rustc will produce the following</summary>
When compiling with `rustc +nightly --target nvptx64-nvidia-cuda <filename> -C target-cpu=sm_52 --crate-type cdylib `
```
//
// Generated by LLVM NVPTX Back-End
//
.version 4.1
.target sm_52
.address_size 64
// .globl add
.visible .entry add(
.param .u64 add_param_0,
.param .u64 add_param_1
)
{
.reg .f32 %f<2>;
.reg .b64 %rd<5>;
ld.param.u64 %rd1, [add_param_0];
ld.param.u64 %rd2, [add_param_1];
cvta.to.global.u64 %rd3, %rd2;
cvta.to.global.u64 %rd4, %rd1;
ld.global.f32 %f1, [%rd3+32];
st.global.f32 [%rd4], %f1;
ret;
}
```
</details>
<details open>
<summary>On the other hand, when compiling the following C++ code</summary>
```cuda
struct foo {
float array[9];
};
extern "C" __global__ void add( float *a, struct foo b) {
*a = b.array[5];
}
```
</details>
<details close>
<summary>I get the following output for nvcc</summary>
When compiling with `nvcc -ptx <filename> `
```
//
// Generated by NVIDIA NVVM Compiler
//
// Compiler Build ID: CL-30794723
// Cuda compilation tools, release 11.6, V11.6.55
// Based on NVVM 7.0.1
//
.version 7.6
.target sm_52
.address_size 64
// .globl add
.visible .entry add(
.param .u64 add_param_0,
.param .align 4 .b8 add_param_1[36]
)
{
.reg .f32 %f<2>;
.reg .b64 %rd<3>;
ld.param.u64 %rd1, [add_param_0];
cvta.to.global.u64 %rd2, %rd1;
ld.param.f32 %f1, [add_param_1+20];
st.global.f32 [%rd2], %f1;
ret;
}
```
</details>
<details close>
<summary>I get the following output for clang</summary>
When compiling with `clang++ --cuda-device-only -nocudalib --cuda-gpu-arch=sm_52 <filename> -S -o <outfile>`
```
//
// Generated by LLVM NVPTX Back-End
//
.version 4.1
.target sm_52
.address_size 64
// .globl add
.visible .entry add(
.param .u64 add_param_0,
.param .align 4 .b8 add_param_1[36]
)
{
.local .align 8 .b8 __local_depot0[48];
.reg .b64 %SP;
.reg .b64 %SPL;
.reg .f32 %f<11>;
.reg .b64 %rd<8>;
mov.u64 %SPL, __local_depot0;
cvta.local.u64 %SP, %SPL;
mov.b64 %rd2, add_param_1;
ld.param.u64 %rd1, [add_param_0];
ld.param.f32 %f1, [add_param_1];
ld.param.f32 %f2, [add_param_1+8];
ld.param.f32 %f3, [add_param_1+12];
ld.param.f32 %f4, [add_param_1+16];
ld.param.f32 %f5, [add_param_1+20];
ld.param.f32 %f6, [add_param_1+24];
ld.param.f32 %f7, [add_param_1+28];
ld.param.f32 %f8, [add_param_1+32];
ld.param.f32 %f9, [add_param_1+4];
add.u64 %rd3, %SP, 0;
or.b64 %rd4, %rd3, 4;
st.f32 [%rd4], %f9;
st.f32 [%SP+32], %f8;
st.f32 [%SP+28], %f7;
st.f32 [%SP+24], %f6;
st.f32 [%SP+20], %f5;
st.f32 [%SP+16], %f4;
st.f32 [%SP+12], %f3;
st.f32 [%SP+8], %f2;
st.f32 [%SP+0], %f1;
cvta.to.global.u64 %rd5, %rd1;
cvta.global.u64 %rd6, %rd5;
st.u64 [%SP+40], %rd6;
ld.f32 %f10, [%SP+20];
ld.u64 %rd7, [%SP+40];
st.f32 [%rd7], %f10;
ret;
}
```
</details>
<details close>
<summary>Here's the different compiler versions I'm using</summary>
```
$ rustc +nightly --version
rustc 1.61.0-nightly (68369a041 2022-02-22)
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Fri_Dec_17_18:16:03_PST_2021
Cuda compilation tools, release 11.6, V11.6.55
Build cuda_11.6.r11.6/compiler.30794723_0
$ clang++ --version
clang version 10.0.0-4ubuntu1
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
```
</details>
I would be happy to try to figure out whats going on if anyone can confirm that this is a bug? If anyone would be able to point me in the right direction that would be a nice bonus as well.<|endoftext|>Visiting as part of a T-compiler backlog bonanza prepass.
This at very least is in a "needs summary" state. But based on @RDambrosio016 's [comment from 10 days ago](https://github.com/rust-lang/rust/pull/94703#issuecomment-1061177678), there may even be design concerns? (At least depending on what scope of potential parameter types we want this ABI to cover at the outset.)
@rustbot label: S-tracking-design-concerns S-tracking-needs-summary<|endoftext|>@pnkfelix I'm currently working on fixing bugs in ptx-kernel in #94703 and would like to help out providing a summary. I have also discovered some design concerns that I can contribute to the summary.
Do you have a template or example of how it should look like?<|endoftext|>Here's a suggestion for an update to the tracking issue to include concerns. Partially copied for japaric's original post and added concerns from and links to relevant issues.
If you have the possibility you should take a look @RDambrosio016
- - -
Feature gate `#![feature(abi_ptx)]`
This ABI is intended to be used when generating code for device (GPU) targets like `nvptx64-nvidia-cuda`. It is used to generate kernels (["global functions"](https://docs.nvidia.com/cuda/cuda-c-programming-guide/#global)) that work as an entry point from host (cpu) code. Functions that do not use the "ptx-kernel" ABI are ["device functions"](https://docs.nvidia.com/cuda/cuda-c-programming-guide/#device-function-qualifier) and only callable from kernels and device functions. Device functions are specifically not usable from host (cpu) code.
### Public API
The following code
```Rust
#![no_std]
#![feature(abi_ptx)]
#[no_mangle]
pub extern "ptx-kernel" fn foo() {}
```
Produces
```
.version 3.2
.target sm_30
.address_size 64
// .globl foo
.visible .entry foo()
{
ret;
}
```
### Steps / History
- [x] Fix broken passing of kernel arguments (#94703)
- [ ] Re-enable ptx CI tests to avoid future breakage (#96842)
- [ ] Emit error for kernels with return value other than `()`
- [ ] Fix the problem where Rust generates types the LLVM PTX cannot select (#97174)
- [ ] Resolve unresolved questions
- [ ] Create an RFC that specifies the safe way to use this abi (I assume this will be required @pnkfelix?)
- [ ] Document feature (https://doc.rust-lang.org/reference/items/external-blocks.html#abi)
- [ ] Stabilization PR
### Unresolved Questions
- [ ] Resolve what kind of stability guarantees can be made about the generated ptx.
- The ABI of kernels have been previously changed for a major version bump and the [ptx-interoperability](https://docs.nvidia.com/cuda/ptx-writers-guide-to-interoperability/) doc is still outdated.
- PTX is an ISA with many versions. The newest is major version 7. Do we need to reserve the possibility of breaking things when moving to a new major version?
- Figure out what llvm does in relations to the `nvptx64-nvidia-cuda` target and the `__global__` modifier.
- [ ] What kind of types should be allowed to use as arguments in kernels. Should it be a hard error to use these types or only a warning (https://github.com/rust-cuda/wg/issues/11)
- The most important part is to find a minimal but useful subset of Rust types that can be used in kernels. raw pointers, primitive types and `#[repr(C)]` types seems like a good start (no slices, tuples, references, etc).
- Using mutable references is almost certain UB except for a few unusable special cases (spawning a single thread only)
- There are many convenient types in Rust which do not have a stable ABI (`&[T]`, `(T, U)`, etc). Are there some types that do not have a stable representation but can be relied on having an identical representation for sequential compilation with a given rustc version? If so are there any way we could pass them safely between host and device code compiled with the same rustc version?
- [ ] This unstable feature is one of the last stoppers to using `nvptx64-nvidia-cuda` on stable Rust. The target seems to still have a few bugs (#38789). Should this feature be kept unstable to avoid usage of `nvptx64-nvidia-cuda` until it has been verified to be usable.
- [ ] How should shared be supported? Is it necessary to do that from the go?
### Notes
- It is not possible to emulate kernels with `#[naked]` functions as the `.entry` directive needs to be emited for nvptx kernels. | T-compiler<|endoftext|>B-unstable<|endoftext|>O-NVPTX<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 6 | https://api.github.com/repos/rust-lang/rust/issues/38788 | https://github.com/rust-lang/rust/issues/38788 | https://api.github.com/repos/rust-lang/rust/issues/38788/comments |
196,574,760 | 38,487 | Tracking issue for the `msp430-interrupt` calling convention/ABI | Added in #38465
This calling convention is used to define interrup handlers on MSP430 microcontrollers. Usage looks like this:
``` rust
#[no_mangle]
#[link_section = "__interrupt_vector_10"]
pub static TIM0_VECTOR: unsafe extern "msp430-interrupt" fn() = tim0;
unsafe extern "msp430-interrupt" fn tim0() {
P1OUT.write(0x00);
}
```
which generates the following assembly:
``` asm
Disassembly of section __interrupt_vector_10:
0000fff2 <TIM0_VECTOR>:
fff2: 10 c0 interrupt service routine at 0xc010
Disassembly of section .text:
0000c010 <_ZN3msp4tim017h3193b957fd6a4fd4E>:
c010: c2 43 21 00 mov.b #0, &0x0021 ;r3 As==00
c014: 00 13 reti
...
```
cc @alexcrichton @pftbest | Triage: not aware of any movement on stabilizing this.<|endoftext|>@japaric @steveklabnik My understanding is that upstream wants to prevent proliferation of various calling conventions, hence no movement on this.
The "special" calling convention for msp430 is: You must save all registers that you modify (except `PC` and `SR`), including call-clobbered registers that are normally temporaries. This to me sounds like a generic "save everything" calling convention. Are you aware of any feature resembling a generic "save everything that was modified" calling convention?
In the interim, I have a plan for allowing interrupts to be done in msp430 using the C ABI, but I don't plan to use it in my code because it has a nontrivial overhead for the smaller parts.<|endoftext|>IMO this should just be stabilized as-is. It seems completely reasonable for a systems programming language to provide support for niche calling conventions in the same manner it supports the C and other "major" calling conventions.<|endoftext|>We discussed this in today's @rust-lang/lang meeting. We're willing to consider stabilizing target-specific interrupt calling conventions like this. We feel like this needs an RFC, not specifically for msp430-interrupt but for target-specific interrupt calling conventions in general. See https://github.com/rust-lang/rust/issues/40180#issuecomment-1022507941 for details there. Once such an RFC gets merged, we'd be happy to add conventions like msp430-interrupt given just a patch to the reference.
Also, given the amount of time that has passed, we'd like to confirm with msp430 folks that this is still functional and used.<|endoftext|>@joshtriplett I'm only one user; there are a few ppl besides me. Nowhere near cortex-m, but I can confirm it's still functional and used as of yesterday :).
>In the interim, I have a plan for allowing interrupts to be done in msp430 using the C ABI, but I don't plan to use it in my code because it has a nontrivial overhead for the smaller parts.
This never materialized for many reasons, but one of them is admittedly "this functionality is not something I would personally use, and I didn't receive any reports of ppl _really_ wanting to use stable for msp430".
I've been revamping msp430 Rust, and interrupts are still rather [useful](https://github.com/cr1901/msp430-quickstart/blob/rt-up3/examples/temp-hal/main.rs#L141-L168); the `#[interrupt]` attribute [expands to](https://github.com/rust-embedded/msp430-rt/blob/master/macros/src/lib.rs#L300) `"msp430-interrupt"`
> We feel like this needs an RFC, not specifically for msp430-interrupt but for target-specific interrupt calling conventions in general.
This is in line with what I want as well, and I will read the relevant issue to get involved. There are other backends I'd be curious (68k comes to mind immediately :)) to see getting an interrupt calling convention in a stable way. | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>WG-embedded<|endoftext|>S-tracking-needs-summary<|endoftext|>O-msp430 | 5 | https://api.github.com/repos/rust-lang/rust/issues/38487 | https://github.com/rust-lang/rust/issues/38487 | https://api.github.com/repos/rust-lang/rust/issues/38487/comments |
190,298,329 | 37,854 | Tracking issue for exclusive range patterns | ### Concerns
- Conflict with the syntax of slice patterns https://github.com/rust-lang/rust/issues/23121
- General concern about the syntax of inclusive/exclusive patterns
### History and status
- Proposed and implemented in PR #35712
- [approved provisionally by lang team](https://github.com/rust-lang/rust/pull/35712#issuecomment-261391537) without an RFC | **EDIT:** the following is no longer true 12 jan 2019 nightly debug 2018:
Missing `warning: unreachable pattern` in the case when `1...10` then `1..10` are present in that order. That warning is present in case of `1..12` then `1..11` for example.
<details>
<summary>
Example (playground [link](https://play.rust-lang.org/?gist=f4e56404bd48002e12cdb7df061f4c3c&version=nightly)):
</summary>
```rust
#![feature(exclusive_range_pattern)]
fn main() {
let i = 9; //this hits whichever branch is first in the match without warning
match i {
1...10 => println!("hit inclusive"),
1..10 => println!("hit exclusive"),//FIXME: there's no warning here
// ^ can shuffle the above two, still no warnings.
1...10 => println!("hit inclusive2"),//this does get warning: unreachable pattern
1..10 => println!("hit exclusive2"),//this also gets warning: unreachable pattern
_ => (),
};
//expecting a warning like in this:
match i {
1..12 => println!("hit 12"),
1..11 => println!("hit 11"),//warning: unreachable pattern
_ => (),
}
}
```
<|endoftext|>I've just been saved for the second time by the compiler when I did `1 .. 10`, but meant `1 ..= 10`. It might be worth considering that the compiler won't catch this error if exclusive ranges are allowed.<|endoftext|>seems like _exclusive range match_ would help to improve consistency ... why can i do range in a loop but not in a pattern?
const MAXN:usize = 14;
...
for x in 0..MAXN { blahblahblah(); }
...
let s = match n {
0..MAXN=>borkbork(),
MAXN=>lastone(),
_=>urgh(),
};
also note that the following is not possible currently because the -1 will break the compile with "expected one of `::`, `=>`, `if`, or `|` here"
let s = match n {
0..=MAXN-1=>borkbork(),
MAXN=>lastone(),
_=>urgh(),
};
thank you<|endoftext|>@donbright I know its a poor consolation, but a good workaround which ensures backwards compatibility might be:
```rust
match i {
0..=MAXN if i < MAXN => println!("Exclusive: {}", i),
MAXN => println!("Limit: {}", i),
_ => println!("Out of range: {}", i)
}
```
[playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=1078aba65079d2f2031fcaf7fa3648f7)
Figured this suggestion might help some poor soul who came here and also battled with not being allowed to use `0..=MAXN-1`
<|endoftext|>It doesn't sound like much is going to happen on this issue, but (FWIW) I would argue **against** its inclusion in stable Rust: exclusive ranges on pattern matching makes it very easy to introduce bugs, as exclusive ranges are very rarely what the programmer wants in a pattern match (emphasis on **match**!). In these cases, I would argue that having the programmer be explicit is helpful; there is no reason to offer syntactic sugar in this case. (I landed here because of finding several bugs in a project that had turned this feature on; see https://github.com/tock/tock/issues/1544 for details.)<|endoftext|>To consistent with `for` and other cases,
- either we have to support both inclusive and exclusive patterns in `match`.
- or either we should deprecate exclusive patterns in both places.
```rust
// 0 to 10 (10 exclusive)
for a in 0..10 {
println!("Current value : {}", a);
}
// 0 to 10 (10 inclusive)
for a in 0..=10 {
println!("Current value : {}", a);
}
```
```rust
let tshirt_width = 20;
let tshirt_size = match tshirt_width {
16 => "S", // 16
17 | 18 => "M", // 17 or 18
19..21 => "L", // 19 to 21; 21 excusive (19,20)
21..=24 => "xL", // 21 to 24; 24 inclusive (21,22,23,24)
25 => "XXL",
_ => "Not Available",
};
```
While we having inconsistencies like this even in smallest things, it's more harder for newcomers to learn and master Rust.<|endoftext|>> ranges are very rarely what the programmer wants in a pattern match (emphasis on **match**!)
Arguments like that IMO are better grounds for *lints*, not "you can't have this".
Otherwise I'd be arguing you shouldn't be allowed to have a thing.is_file(), because it sometimes isn't what you expect: Usually you just want a readable thing that *isn't* a directory, and things like pipes and symbolic links and device nodes are acceptable, even if weird... but .is_file() will likely exclude those options for you. ( Hence why I proposed a lint for that )
And lets not even get into the rabbit warren of "stating files is bad, because you could have the underlying file change between the stat time and the time you modify it, use proper error handling instead" argument, because while I agree *in part*, its a decision you should make after understanding a lint telling you "why this is probably bad" and you decide whether or not it matters for your code.<|endoftext|>If I may add a datapoint. I tried to use an exclusive range today and the compiler error took me here. Turned out I wanted an **inclusive** range, so I for one am greatful that rust does not (stabley) allow exclusive ranges and I would argue against stablising as it would have caused me to shoot myself in the foot. :)<|endoftext|>I wanted exclusive ranges today, for a case where I had a variable that needed to be handled differently depending on which of the following ranges it fell into: 0..10, 10..100, 100..1000 and 1000..10000. In my opinion the code would have been cleaner if exclusive ranges were supported.
<|endoftext|>> for a case where I had a variable that needed to be handled differently depending on which of the following ranges it fell into: 0..10, 10..100, 100..1000 and 1000..10000.
You could just do a match on `x.log10().floor()`<|endoftext|>> > for a case where I had a variable that needed to be handled differently depending on which of the following ranges it fell into: 0..10, 10..100, 100..1000 and 1000..10000.
>
> You could just do a match on `x.log10().floor()`
Yeah, good point! But at least to me, it wouldn't be as readable. The match would be something like:
```
0 => /* handle case 0..10 */,
1 => /* handle case 10..100 */,
2 => /* handle case 100..1000 */,
```
Which isn't bad, but without the comment it wouldn't be immediately obvious that the case "0" handled the range 0..10 .
<|endoftext|>It is not clear that
```rust
0..=9
10..=99
100..=999
1000..=9999
```
is less desirable.
However I would like to voice that I prefer having the option to have an exclusive range pattern for the _sole case_ of the "half-open range" (#67264) that goes from a certain value unto the natural end of that range<|endoftext|>@workingjubilee I agree that the difference in readability is not entirely obvious.
But let's say we had these ranges instead:
```rust
# Constants:
const NOMINAL_LOW:i32 = 0;
const NOMINAL_HIGH:i32 = 100;
const OVERVOLTAGE:i32 = 200;
# Ranges:
NOMINAL_LOW .. NOMINAL_HIGH,
NOMINAL_HIGH .. OVERVOLTAGE,
```
In this case, having to write NOMINAL_LOW..=NOMINAL_HIGH-1 seems slightly worse. than NOMINAL_LOW..NOMINAL_HIGH .
I know matching on floats is being phased out, but if that capability was intended to be kept, using inclusive ranges would have been quite difficult, since you couldn't just decrement by 1 to get the predecessor of NOMINAL_HIGH. Will rust ever support matching on user types? Like on a fixed point type, big number, or something like that?
<|endoftext|>How we can push this issue/fix forward?<|endoftext|>I would prefer this to exist for consistency, and because I personally just find half-open ranges easier to reason about, even in match statements.
I believe many of the concerns listed could be addressed via the existing exhausiveness checking, and a clippy lint against using `_` in combination with range patterns when an exhaustive pattern can be easily specified.
For example, instead of:
```rust
match x {
0..9 => foo(),
_ => bar(),
}
```
The lint could push you towards:
```rust
match x {
0..9 => foo(),
9.. => bar(), // Would fail to compile if you tried `10..` due to exhaustiveness checking
}
```
At which point it would be very obvious that perhaps you meant:
```rust
match x {
0..10 => foo(),
10.. => bar(),
}
```
<|endoftext|>That seems like a good idea, and I would actually say this almost shouldn't be a Clippy lint because it's fundamental to Rust's exhaustiveness capabilities, but it could be at least tested in Clippy.
I suppose there's a risk of false positives or arguments on style, and it making rustc too opinionated.
Exclusive and half-open range patterns definitely make more sense together rather than separately.<|endoftext|>@Diggsey, I think that that's a great suggestion, though I would actually go a step further and have the compiler itself warn on non-exhaustive patterns (that is, use of `_` when using exclusive range patterns) -- I think that one would much rather explicitly turn off the warning to allow any reader of the code to see what's going on. I know that [my comment](https://github.com/rust-lang/rust/issues/37854#issuecomment-575292595) was very controversial, but I would also add that it was effectively coming from the field: it should be an important data point that a project enabled this feature, and it was *rampantly* misused, introducing (many) subtle bugs. Coming from C, I would liken exclusive range patterns to [switch fallthrough](https://en.wikipedia.org/wiki/Switch_statement#Fallthrough): yes, there are cases where it's useful -- but it's so often done accidentally that the programmer is also required to mark it as `/*FALLTHROUGH*/` to prevent lint from warning on it. One of Rust's great strengths is that it (generally) doesn't have trap doors like this; forcing the programmer to either use exhaustive pattern matching (which would have caught [the bugs that I hit](https://github.com/tock/tock/issues/1544), for whatever it's worth) or explicitly turn off the warning seems like an excellent compromise!<|endoftext|>"RangeFrom" patterns (`X..`) will be partially stabilized in #67264. No decision was reached regarding "RangeTo" (`..Y`) or "Range" patterns (`X..Y`).<|endoftext|>Nearly four years, and it's still experimental. Sigh. Both inclusive and exclusive ranges are useful; when working with matches for odd usages of ASCII-like bytes (current: working on parsing the mess that is the DNS NAPTR service field), both inclusive and exclusive ranges may make code far more readable in different circumstances. Given that constant maths isn't possible in range patterns yet, it's a royal pain to make code clearly demonstrate its purpose with one arm tied behind your back. I'm all for a compiler and linter making it difficult to make mistakes, but, ultimately, good software requires comprehensive testing practices to go with it.
Good software needs to read like a good book; any choice about syntax, naming and the like should always be driven from that observation.<|endoftext|>Just to weigh in as a brand new user of the language — I agree with @raphaelcohn that both inclusive and exclusive ranges have their use cases, I really don't understand the logic for locking this behind an "experimental" error. IMO, this type of "Oh, that syntax is _probably_ not what you meant" nannying should be the purview of a linter, not a compiler. (Take that with a grain of salt since, again, I'm brand new to the language.)
The context is that I'm running through a Udemy crash course and completing one of the exercises:
```rust
// 2. For each coord in arrow_coords:
//
// A. Call `coord.print_description()`
// B. Append the correct variant of `Shot` to the `shots` vector depending on the value of
// `coord.distance_from_center()`
// - Less than 1.0 -- `Shot::Bullseye`
// - Between 1.0 and 5.0 -- `Shot::Hit(value)`
// - Greater than 5.0 -- `Shot::Miss`
for coord in arrow_coords {
coord.print_description();
let dist = coord.distance_from_center();
shots.push(match dist {
0.0..1.0 => Shot::Bullseye,
1.0..5.0 => Shot::Hit(dist),
_ => Shot::Miss,
});
}
```
I sat back in my chair grinning smugly at my elegant solution for a few seconds, but the compiler quickly threw cold water on my enthusiasm. 😛 And now I have to go Googling for how to configure the compiler to let me do this. I know that I could use an if/else expression to achieve the same result, but IMO it would not be as readable.<|endoftext|>@dannymcgee The Rust compiler comes with a built-in linter. The lints built into the Rust compiler have a very low rate of false positives by design, but it is not non-zero. Nonetheless, having extremely strong error messages and linting facilities in the compiler by default is a part of the language.
You will wish to use rustup to install the nightly version of the compiler (`rustup install nightly`) and then enable the feature using
```rust
#![feature(exclusive_range_pattern)]
```
at the top of the file.
However, I should note that matching on floats is problematic since they are less amenable to what Rust is *doing* with `match`, so you may run into challenges anyways.<|endoftext|>#83918 was opened with a proposal to stabilize the `X..` pattern format and has begun its final comment period.
This does not include the `X..Y` and `..Y` patterns.<|endoftext|>The specific cases of ranges in slice patterns will not be stabilized in #83918, per the discussion in that PR and the explanatory comment here: https://github.com/rust-lang/rust/issues/67264#issuecomment-854921128
The interaction of range patterns inside slice patterns should be RFCed.<|endoftext|>Experience report, seconding the early comments in this issue: This being experimental just stopped me from writing the following bug:
```
b'a'..b'z' | b'A'..b'Z' | b'0'..b'9' => {
```<|endoftext|>With a steadier grasp on the language, I can now add:
The `for x in 5..10` style of cases that was mentioned by a few programmers a while back features the range `5..10` as an expression, not a *pattern*. I believe there is an unfortunate amount of confusion in that regard due to other choices, but that asserting the expression and pattern syntax should be made the same due to that superficial similarity is not ideal. I also think that the multiple experience reports highlight an important detail:
What is ergonomic for integer, floating point, and character ranges are **not** the same. Yet in Rust they all go through the same mechanism here.<|endoftext|>I just had an idea for that: what if we introduce syntax `a..<b` which works exactly the same as `a..b` and only allow that version in match statements?<|endoftext|>I'll try to summarize in the hope this can move from experimental to stable.
- in 2016 there was an initial concern of conflict with the syntax of slice patterns, and about the syntax of inclusive/exclusive patterns
- in 2017 an exclusive pattern has been implemented but is blocked as experimental
- since then, multiple comments stated that having the exclusive pattern would improve consistency in the language, all received more positive votes than negative ones
- someone argued that 0..=9 wouldn't be less clear than 0..10, but a counter-example showed that some inclusive ranges were harder to read (with more positive votes overall)
- a related issue on half-ranges https://github.com/rust-lang/rust/issues/67264 is still open but has passed the final comment period (seems complete?)
- [one comment above](https://github.com/rust-lang/rust/issues/37854#issuecomment-1188679141) was not entirely clear to me, I think it suggests that patterns needn't look similar to expression, but there is nothing specific to illustrate this particular issue.
In conclusion, is there still anything blocking, or could this feature be accepted?<|endoftext|>🤷

<|endoftext|>Adding to what @avl said:
> In this case, having to write NOMINAL_LOW..=NOMINAL_HIGH-1 seems slightly worse. than NOMINAL_LOW..NOMINAL_HIGH .
Note that you can't even write `NOMINAL_LOW..=NOMINAL_HIGH-1` in pattern position, because expressions don't work there. You can do something like
```rs
const NOMINAL_LOW: i32 = 0;
const NOMINAL_LOW_MAX: i32 = NOMINAL_LOW - 1;
const NOMINAL_HIGH: i32 = 100;
const NOMINAL_HIGH_MAX: i32 = NOMINAL_HIGH - 1;
```
and then have match arms like
```rs
NOMINAL_LOW..=NOMINAL_LOW_MAX => ...,
NOMINAL_HIGH..=NOMINAL_HIGH_MAX => ...,
```
but it is quite a bit noisier.
I find myself running into this every once in a while when implementing file formats and things of that sort that involve magic number ranges.
There is a workaround which is somewhat worse for readability I think but perhaps the DRYest solution.
You can make use of the fact that match arms are checked in order and use overlapping half-open ranges:
```rs
OVERVOLTAGE.. => "over"
NOMINAL_HIGH.. => "high",
NOMINAL_LOW.. => "low",
_ => "none",
```
The order now has to be backwards though, so I don't really love it.<|endoftext|>> There is a workaround which is somewhat worse for readability I think but perhaps the DRYest solution.
> You can make use of the fact that match arms are checked in order and use overlapping half-open ranges:
>
> OVERVOLTAGE.. => "over"
> NOMINAL_HIGH.. => "high",
> NOMINAL_LOW.. => "low",
> _ => "none",
> The order now has to be backwards though, so I don't really love it.
I like the tidiness of it, but aren't the open intervals a concern for robustness? Now the match cases are not sorted by priority but must be carefully sorted to get the "others" case at the end working correctly, and if a new value is inserted (for ex. between `NOMINAL_LOW_MAX` and `NOMINAL_HIGH`), it may break the `match` statement. Even searching for the `*_MAX` values' usage won't reveal it.
To come back on the difference - or confusion - between expression and pattern:
My understanding (for what it's worth) of a good language or API is that it doesn't show unnecessary exceptions and provides as best a coherency as possible. So even if one is an expression and the other a pattern, making an exception in the language by refusing the exclusive range in the latter can only confuse programmers, without any good reason to make up for it. | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>F-exclusive_range_pattern<|endoftext|>S-tracking-needs-summary | 50 | https://api.github.com/repos/rust-lang/rust/issues/37854 | https://github.com/rust-lang/rust/issues/37854 | https://api.github.com/repos/rust-lang/rust/issues/37854/comments |
147,037,803 | 32,838 | Allocator traits and std::heap | 📢 **This feature has a dedicated working group**, please direct comments and concerns to [the working group's repo](https://github.com/rust-lang/wg-allocators).
The remainder of this post is no longer an accurate summary of the current state; see that dedicated working group instead.
<details>
<summary>Old content</summary>
Original Post:
-----
FCP proposal: https://github.com/rust-lang/rust/issues/32838#issuecomment-336957415
FCP checkboxes: https://github.com/rust-lang/rust/issues/32838#issuecomment-336980230
---
Tracking issue for rust-lang/rfcs#1398 and the `std::heap` module.
- [x] land `struct Layout`, `trait Allocator`, and default implementations in `alloc` crate (https://github.com/rust-lang/rust/pull/42313)
- [x] decide where parts should live (e.g. default impls has dependency on `alloc` crate, but `Layout`/`Allocator` _could_ be in `libcore`...) (https://github.com/rust-lang/rust/pull/42313)
- [ ] fixme from source code: audit default implementations (in `Layout` for overflow errors, (potentially switching to overflowing_add and overflowing_mul as necessary).
- [x] decide if `realloc_in_place` should be replaced with `grow_in_place` and `shrink_in_place` ([comment](https://github.com/rust-lang/rust/issues/32838#issuecomment-208141759)) (https://github.com/rust-lang/rust/pull/42313)
- [ ] review arguments for/against associated error type (see subthread [here](https://github.com/rust-lang/rfcs/pull/1398#issuecomment-204561446))
- [ ] determine what the requirements are on the alignment provided to `fn dealloc`. (See discussion on [allocator rfc](https://github.com/rust-lang/rfcs/pull/1398#issuecomment-198584430) and [global allocator rfc](https://github.com/rust-lang/rfcs/pull/1974#issuecomment-302789872) and [trait `Alloc` PR](https://github.com/rust-lang/rust/pull/42313#issuecomment-306202489).)
* Is it required to deallocate with the exact `align` that you allocate with? [Concerns have been raised](https://github.com/rust-lang/rfcs/pull/1974#issuecomment-302789872) that allocators like jemalloc don't require this, and it's difficult to envision an allocator that does require this. ([more discussion](https://github.com/rust-lang/rfcs/pull/1398#issuecomment-198584430)). @ruuda and @rkruppe look like they've got the most thoughts so far on this.
- [ ] should `AllocErr` be `Error` instead? ([comment](https://github.com/rust-lang/rust/pull/42313#discussion_r122580471))
- [x] Is it required to deallocate with the *exact* size that you allocate with? With the `usable_size` business we may wish to allow, for example, that you if you allocate with `(size, align)` you must deallocate with a size somewhere in the range of `size...usable_size(size, align)`. It appears that jemalloc is totally ok with this (doesn't require you to deallocate with a *precise* `size` you allocate with) and this would also allow `Vec` to naturally take advantage of the excess capacity jemalloc gives it when it does an allocation. (although actually doing this is also somewhat orthogonal to this decision, we're just empowering `Vec`). So far @Gankro has most of the thoughts on this. (@alexcrichton believes this was settled in https://github.com/rust-lang/rust/pull/42313 due to the definition of "fits")
- [ ] similar to previous question: Is it required to deallocate with the *exact* alignment that you allocated with? (See comment from [5 June 2017](https://github.com/rust-lang/rust/pull/42313#issuecomment-306202489))
- [x] OSX/`alloc_system` is buggy on *huge* alignments (e.g. an align of `1 << 32`) https://github.com/rust-lang/rust/issues/30170 #43217
- [ ] should `Layout` provide a `fn stride(&self)` method? (See also https://github.com/rust-lang/rfcs/issues/1397, https://github.com/rust-lang/rust/issues/17027 )
- [x] `Allocator::owns` as a method? https://github.com/rust-lang/rust/issues/44302
State of `std::heap` after https://github.com/rust-lang/rust/pull/42313:
```rust
pub struct Layout { /* ... */ }
impl Layout {
pub fn new<T>() -> Self;
pub fn for_value<T: ?Sized>(t: &T) -> Self;
pub fn array<T>(n: usize) -> Option<Self>;
pub fn from_size_align(size: usize, align: usize) -> Option<Layout>;
pub unsafe fn from_size_align_unchecked(size: usize, align: usize) -> Layout;
pub fn size(&self) -> usize;
pub fn align(&self) -> usize;
pub fn align_to(&self, align: usize) -> Self;
pub fn padding_needed_for(&self, align: usize) -> usize;
pub fn repeat(&self, n: usize) -> Option<(Self, usize)>;
pub fn extend(&self, next: Self) -> Option<(Self, usize)>;
pub fn repeat_packed(&self, n: usize) -> Option<Self>;
pub fn extend_packed(&self, next: Self) -> Option<(Self, usize)>;
}
pub enum AllocErr {
Exhausted { request: Layout },
Unsupported { details: &'static str },
}
impl AllocErr {
pub fn invalid_input(details: &'static str) -> Self;
pub fn is_memory_exhausted(&self) -> bool;
pub fn is_request_unsupported(&self) -> bool;
pub fn description(&self) -> &str;
}
pub struct CannotReallocInPlace;
pub struct Excess(pub *mut u8, pub usize);
pub unsafe trait Alloc {
// required
unsafe fn alloc(&mut self, layout: Layout) -> Result<*mut u8, AllocErr>;
unsafe fn dealloc(&mut self, ptr: *mut u8, layout: Layout);
// provided
fn oom(&mut self, _: AllocErr) -> !;
fn usable_size(&self, layout: &Layout) -> (usize, usize);
unsafe fn realloc(&mut self,
ptr: *mut u8,
layout: Layout,
new_layout: Layout) -> Result<*mut u8, AllocErr>;
unsafe fn alloc_zeroed(&mut self, layout: Layout) -> Result<*mut u8, AllocErr>;
unsafe fn alloc_excess(&mut self, layout: Layout) -> Result<Excess, AllocErr>;
unsafe fn realloc_excess(&mut self,
ptr: *mut u8,
layout: Layout,
new_layout: Layout) -> Result<Excess, AllocErr>;
unsafe fn grow_in_place(&mut self,
ptr: *mut u8,
layout: Layout,
new_layout: Layout) -> Result<(), CannotReallocInPlace>;
unsafe fn shrink_in_place(&mut self,
ptr: *mut u8,
layout: Layout,
new_layout: Layout) -> Result<(), CannotReallocInPlace>;
// convenience
fn alloc_one<T>(&mut self) -> Result<Unique<T>, AllocErr>
where Self: Sized;
unsafe fn dealloc_one<T>(&mut self, ptr: Unique<T>)
where Self: Sized;
fn alloc_array<T>(&mut self, n: usize) -> Result<Unique<T>, AllocErr>
where Self: Sized;
unsafe fn realloc_array<T>(&mut self,
ptr: Unique<T>,
n_old: usize,
n_new: usize) -> Result<Unique<T>, AllocErr>
where Self: Sized;
unsafe fn dealloc_array<T>(&mut self, ptr: Unique<T>, n: usize) -> Result<(), AllocErr>
where Self: Sized;
}
/// The global default allocator
pub struct Heap;
impl Alloc for Heap {
// ...
}
impl<'a> Alloc for &'a Heap {
// ...
}
/// The "system" allocator
pub struct System;
impl Alloc for System {
// ...
}
impl<'a> Alloc for &'a System {
// ...
}
```
</details> | I unfortunately wasn't paying close enough attention to mention this in the RFC discussion, but I think that `realloc_in_place` should be replaced by two functions, `grow_in_place` and `shrink_in_place`, for two reasons:
- I can't think of a single use case (short of implementing `realloc` or `realloc_in_place`) where it is unknown whether the size of the allocation is increasing or decreasing. Using more specialized methods makes it slightly more clear what is going on.
- The code paths for growing and shrinking allocations tend to be radically different - growing involves testing whether adjacent blocks of memory are free and claiming them, while shrinking involves carving off properly sized subblocks and freeing them. While the cost of a branch inside `realloc_in_place` is quite small, using `grow` and `shrink` better captures the distinct tasks that an allocator needs to perform.
Note that these can be added backwards-compatibly next to `realloc_in_place`, but this would constrain which functions would be by default implemented in terms of which others.
For consistency, `realloc` would probably also want to be split into `grow` and `split`, but the only advantage to having an overloadable `realloc` function that I know of is to be able to use `mmap`'s remap option, which does not have such a distinction.
<|endoftext|>Additionally, I think that the default implementations of `realloc` and `realloc_in_place` should be slightly adjusted - instead of checking against the `usable_size`, `realloc` should just first try to `realloc_in_place`. In turn, `realloc_in_place` should by default check against the usable size and return success in the case of a small change instead of universally returning failure.
This makes it easier to produce a high-performance implementation of `realloc`: all that is required is improving `realloc_in_place`. However, the default performance of `realloc` does not suffer, as the check against the `usable_size` is still performed.
<|endoftext|>Another issue: The doc for `fn realloc_in_place` says that if it returns Ok, then one is assured that `ptr` now "fits" `new_layout`.
To me this implies that it must check that the alignment of the given address matches any constraint implied by `new_layout`.
However, I don't think the spec for the underlying `fn reallocate_inplace` function implies that _it_ will perform any such check.
- Furthermore, it seems reasonable that any client diving into using `fn realloc_in_place` will themselves be ensuring that the alignments work (in practice I suspect it means that the same alignment is required everywhere for the given use case...)
So, should the implementation of `fn realloc_in_place` really be burdened with checking that the alignment of the given `ptr` is compatible with that of `new_layout`? It is probably better _in this case_ (of this one method) to push that requirement back to the caller...
<|endoftext|>@gereeter you make good points; I will add them to the check list I am accumulating in the issue description.
<|endoftext|>(at this point I am waiting for `#[may_dangle]` support to ride the train into the `beta` channel so that I will then be able to use it for std collections as part of allocator integration)
<|endoftext|>I'm new to Rust, so forgive me if this has been discussed elsewhere.
Is there any thought on how to support object-specific allocators? Some allocators such as [slab allocators](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.29.4759) and [magazine allocators](http://www.parrot.org/sites/www.parrot.org/files/vmem.pdf) are bound to a particular type, and do the work of constructing new objects, caching constructed objects which have been "freed" (rather than actually dropping them), returning already-constructed cached objects, and dropping objects before freeing the underlying memory to an underlying allocator when required.
Currently, this proposal doesn't include anything along the lines of `ObjectAllocator<T>`, but it would be very helpful. In particular, I'm working on an implementation of a magazine allocator object-caching layer (link above), and while I can have this only wrap an `Allocator` and do the work of constructing and dropping objects in the caching layer itself, it'd be great if I could also have this wrap other object allocators (like a slab allocator) and truly be a generic caching layer.
Where would an object allocator type or trait fit into this proposal? Would it be left for a future RFC? Something else?<|endoftext|>I don't think this has been discussed yet.
You could write your own `ObjectAllocator<T>`, and then do `impl<T: Allocator, U> ObjectAllocator<U> for T { .. }`, so that every regular allocator can serve as an object-specific allocator for all objects.
Future work would be modifying collections to use your trait for their nodes, instead of plain ole' (generic) allocators directly.<|endoftext|>@pnkfelix
> (at this point I am waiting for #[may_dangle] support to ride the train into the beta channel so that I will then be able to use it for std collections as part of allocator integration)
I guess this has happened?<|endoftext|>@Ericson2314 Yeah, writing my own is definitely an option for experimental purposes, but I think there'd be much more benefit to it being standardized in terms of interoperability (for example, I plan on also implementing a slab allocator, but it would be nice if a third-party user of my code could use somebody _else's_ slab allocator with my magazine caching layer). My question is simply whether an `ObjectAllocator<T>` trait or something like it is worth discussing. Although it seems that it might be best for a different RFC? I'm not terribly familiar with the guidelines for how much belongs in a single RFC and when things belong in separate RFCs...<|endoftext|>@joshlf
> Where would an object allocator type or trait fit into this proposal? Would it be left for a future RFC? Something else?
Yes, it would be another RFC.
> I'm not terribly familiar with the guidelines for how much belongs in a single RFC and when things belong in separate RFCs...
that depends on the scope of the RFC itself, which is decided by the person who writes it, and then feedback is given by everyone.
But really, as this is a tracking issue for this already-accepted RFC, thinking about extensions and design changes isn't really for this thread; you should open a new one over on the RFCs repo.<|endoftext|>@joshlf Ah, I thought `ObjectAllocator<T>` was supposed to be a trait. I meant prototype the *trait* not a specific allocator. Yes that trait would merit its own RFC as @steveklabnik says.
------
@steveklabnik yeah now discussion would be better elsewhere. But @joshlf was also raising the issue lest it expose a hitherto unforeseen flaw in the accepted but unimplemented API design. In that sense it matches the earlier posts in this thread.<|endoftext|>@Ericson2314 Yeah, I thought that was what you meant. I think we're on the same page :)
@steveklabnik Sounds good; I'll poke around with my own implementation and submit an RFC if it ends up seeming like a good idea.<|endoftext|>@joshlf I don't any reason why custom allocators would go into the compiler or standard library. Once this RFC lands, you could easily publish your own crate that does an arbitrary sort of allocation (even a fully-fledged allocator like jemalloc could be custom-implemented!).<|endoftext|>@alexreg This isn't about a particular custom allocator, but rather a trait that specifies the type of all allocators which are parametric on a particular type. So just like RFC 1398 defines a trait (`Allocator`) that is the type of any low-level allocator, I'm asking about a trait (`ObjectAllocator<T>`) that is the type of any allocator which can allocate/deallocate and construct/drop objects of type `T`.<|endoftext|>@alexreg See my early point about using *standard library collections* with custom object-specific allocators. <|endoftext|>Sure, but I’m not sure that would belong in the standard library. Could easily go into another crate, with no loss of functionality or usability.
> On 4 Jan 2017, at 21:59, Joshua Liebow-Feeser <[email protected]> wrote:
>
> @alexreg <https://github.com/alexreg> This isn't about a particular custom allocator, but rather a trait that specifies the type of all allocators which are parametric on a particular type. So just like RFC 1398 defines a trait (Allocator) that is the type of any low-level allocator, I'm asking about a trait (ObjectAllocator<T>) that is the type of any allocator which can allocate/deallocate and construct/drop objects of type T.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub <https://github.com/rust-lang/rust/issues/32838#issuecomment-270499064>, or mute the thread <https://github.com/notifications/unsubscribe-auth/AAEF3IhyyPhFgu1EGHr_GM_Evsr0SRzIks5rPBZGgaJpZM4IDYUN>.
>
<|endoftext|>I think you’d want to use standard-library collections (any heap-allocated value) with an *arbitrary* custom allocator; i.e. not limited to object-specific ones.
> On 4 Jan 2017, at 22:01, John Ericson <[email protected]> wrote:
>
> @alexreg <https://github.com/alexreg> See my early point about using standard library collections with custom object-specific allocators.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub <https://github.com/rust-lang/rust/issues/32838#issuecomment-270499628>, or mute the thread <https://github.com/notifications/unsubscribe-auth/AAEF3CrjYIXqcv8Aqvb4VTyPcajJozICks5rPBbOgaJpZM4IDYUN>.
>
<|endoftext|>> Sure, but I’m not sure that would belong in the standard library. Could easily go into another crate, with no loss of functionality or usability.
Yes but you probably want some standard library functionality to rely on it (such as what @Ericson2314 suggested).
> I think you’d want to use standard-library collections (any heap-allocated value) with an *arbitrary* custom allocator; i.e. not limited to object-specific ones.
Ideally you'd want both - to accept either type of allocator. There are very significant benefits to using object-specific caching; for example, both slab allocation and magazine caching give very significant performance benefits - take a look at the papers I linked to above if you're curious.<|endoftext|>But the object allocator trait could simply be a subtrait of the general allocator trait. It’s as simple as that, as far as I’m concerned. Sure, certain types of allocators can be more efficient than general-purpose allocators, but neither the compiler nor the standard really need to (or indeed should) know about this.
> On 4 Jan 2017, at 22:13, Joshua Liebow-Feeser <[email protected]> wrote:
>
> Sure, but I’m not sure that would belong in the standard library. Could easily go into another crate, with no loss of functionality or usability.
>
> Yes but you probably want some standard library functionality to rely on it (such as what @Ericson2314 <https://github.com/Ericson2314> suggested).
>
> I think you’d want to use standard-library collections (any heap-allocated value) with an arbitrary custom allocator; i.e. not limited to object-specific ones.
>
> Ideally you'd want both - to accept either type of allocator. There are very significant benefits to using object-specific caching; for example, both slab allocation and magazine caching give very significant performance benefits - take a look at the papers I linked to above if you're curious.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub <https://github.com/rust-lang/rust/issues/32838#issuecomment-270502231>, or mute the thread <https://github.com/notifications/unsubscribe-auth/AAEF3L9F9r_0T5evOtt7Es92vw6gBxR9ks5rPBl9gaJpZM4IDYUN>.
>
<|endoftext|>> But the object allocator trait could simply be a subtrait of the general allocator trait. It’s as simple as that, as far as I’m concerned. Sure, certain types of allocators can be more efficient than general-purpose allocators, but neither the compiler nor the standard really need to (or indeed should) know about this.
Ah, so the problem is that the semantics are different. `Allocator` allocates and frees raw byte blobs. `ObjectAllocator<T>`, on the other hand, would allocate already-constructed objects and would also be responsible for dropping these objects (including being able to cache constructed objects which could be handed out later in leu of constructing a newly-allocated object, which is expensive). The trait would look something like this:
```
trait ObjectAllocator<T> {
fn alloc() -> T;
fn free(t T);
}
```
This is not compatible with `Allocator`, whose methods deal with raw pointers and have no notion of type. Additionally, with `Allocator`s, it is the caller's responsibility to `drop` the object being freed first. This is really important - knowing about the type `T` allows `ObjectAllocator<T>` to do things like call `T`'s `drop` method, and since `free(t)` moves `t` into `free`, the caller _cannot_ drop `t` first - it is instead the `ObjectAllocator<T>`'s responsibility. Fundamentally, these two traits are incompatible with one another.<|endoftext|>Ah right, I see. I thought this proposal already included something like that, i.e. a “higher-level” allocator over the byte level. In that case, a perfectly fair proposal!
> On 4 Jan 2017, at 22:29, Joshua Liebow-Feeser <[email protected]> wrote:
>
> But the object allocator trait could simply be a subtrait of the general allocator trait. It’s as simple as that, as far as I’m concerned. Sure, certain types of allocators can be more efficient than general-purpose allocators, but neither the compiler nor the standard really need to (or indeed should) know about this.
>
> Ah, so the problem is that the semantics are different. Allocator allocates and frees raw byte blobs. ObjectAllocator<T>, on the other hand, would allocate already-constructed objects and would also be responsible for dropping these objects (including being able to cache constructed objects which could be handed out later in leu of constructing a newly-allocated object, which is expensive). The trait would look something like this:
>
> trait ObjectAllocator<T> {
> fn alloc() -> T;
> fn free(t T);
> }
> This is not compatible with Allocator, whose methods deal with raw pointers and have no notion of type. Additionally, with Allocators, it is the caller's responsibility to drop the object being freed first. This is really important - knowing about the type T allows ObjectAllocator<T> to do things like call T's drop method, and since free(t) moves t into free, the caller cannot drop t first - it is instead the ObjectAllocator<T>'s responsibility. Fundamentally, these two traits are incompatible with one another.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub <https://github.com/rust-lang/rust/issues/32838#issuecomment-270505704>, or mute the thread <https://github.com/notifications/unsubscribe-auth/AAEF3GViJBefuk8IWgPauPyL5tV78Fn5ks5rPB08gaJpZM4IDYUN>.
>
<|endoftext|>@alexreg Ah yes, I was hoping so too :) Oh well - it'll have to wait for another RFC.<|endoftext|>Yes, do kick start that RFC, I’m sure it would get plenty of support! And thanks for the clarification (I hadn’t kept up with the details of this RFC at all).
> On 5 Jan 2017, at 00:53, Joshua Liebow-Feeser <[email protected]> wrote:
>
> @alexreg <https://github.com/alexreg> Ah yes, I was hoping so too :) Oh well - it'll have to wait for another RFC.
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub <https://github.com/rust-lang/rust/issues/32838#issuecomment-270531535>, or mute the thread <https://github.com/notifications/unsubscribe-auth/AAEF3MQQeXhTliU5CBsoheBFL26Ee9WUks5rPD8RgaJpZM4IDYUN>.
>
<|endoftext|>A crate for testing custom allocators would be useful. <|endoftext|>Forgive me if I'm missing something obvious, but is there a reason for the `Layout` trait described in this RFC not to implement `Copy` as well as `Clone`, since it's just POD?<|endoftext|>I can't think of any.<|endoftext|>Sorry to be bringing this up so late in the process, but...
Might it be worth adding support for a `dealloc`-like function that isn't a method, but rather a function? The idea would be to use alignment to be able to infer from a pointer where in memory its parent allocator is and thus be able to free without needing an explicit allocator reference.
This could be a big win for data structures that use custom allocators. This would allow them to not keep a reference to the allocator itself, but rather only need to be parametric on the _type_ of the allocator to be able to call the right `dealloc` function. For example, if `Box` is eventually modified to support custom allocators, then it'd be able to keep being only a single word (just the pointer) as opposed to having to be expanded to two words to store a reference to the allocator as well.
On a related note, it might also be useful to support a non-method `alloc` function to allow for global allocators. This would compose nicely with a non-method `dealloc` function - for global allocators, there'd be no need to do any kind of pointer-to-allocator inference since there'd only be a single static instance of the allocator for the whole program.<|endoftext|>@joshlf The current design allows you to get that by just having your allocator be a (zero-sized) unit type - i.e. `struct MyAlloc;` that you then implement the `Allocator` trait on.
Storing references or nothing at all, *always*, is *less general* than storing the allocator by-value.<|endoftext|>I could see that being true for a directly-embedded type, but what about if a data structure decies to keep a reference instead? Does a reference to a zero-sized type take up zero space? That is, if I have:
```rust
struct Foo()
struct Blah{
foo: &Foo,
}
```
Does `Blah` have zero size?<|endoftext|>Actually, even it's possible, you might not want your allocator to have zero size. For example, you might have an allocator with a non-zero size that you allocate _from_, but that has the ability to free objects w/o knowing about the original allocator. This would still be useful for making a `Box` take only a word. You'd have something like `Box::new_from_allocator` which would have to take an allocator as an argument - and it might be a nonzero-sized allocator - but if the allocator supported freeing without the original allocator reference, the returned `Box<T>` could avoid storing a reference to the allocator that was passed in the original `Box::new_from_allocator` call. | B-RFC-approved<|endoftext|>A-allocators<|endoftext|>T-lang<|endoftext|>T-libs-api<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>Libs-Tracked<|endoftext|>S-tracking-needs-summary | 465 | https://api.github.com/repos/rust-lang/rust/issues/32838 | https://github.com/rust-lang/rust/issues/32838 | https://api.github.com/repos/rust-lang/rust/issues/32838/comments |
115,559,940 | 29,661 | Tracking issue for RFC 2532, "Associated type defaults" | This is a tracking issue for the RFC "Associated type defaults" (rust-lang/rfcs#2532) under the feature gate `#![feature(associated_type_defaults)]`.
--------------------------
The [associated item RFC](https://github.com/rust-lang/rfcs/pull/195) included the ability to provide defaults for associated types, with some tricky rules about how that would influence defaulted methods.
The early implementation of this feature was gated, because there is a widespread feeling that we want a different semantics from the RFC -- namely, that default methods should not be able to assume anything about associated types. This is especially true given the [specialization RFC](https://github.com/rust-lang/rfcs/pull/1210), which provides a much cleaner way of tailoring default implementations.
The new RFC, rust-lang/rfcs#2532, specifies that this should be the new semantics but has not been implemented yet. The existing behavior under `#![feature(associated_type_defaults)]` is buggy and does not conform to the new RFC. Consult it for a discussion on changes that will be made.
--------------------------
### Steps:
- [ ] Implement rust-lang/rfcs#2532 (cc @rust-lang/wg-traits @rust-lang/compiler)
- [X] #61812
- [ ] handle https://github.com/rust-lang/trait-system-refactor-initiative/issues/46
- [ ] Implement the changes to object types specified in the RFC
- [ ] Improve type mismatch errors when an associated type default can not be projected (https://github.com/rust-lang/rust/pull/61812#discussion_r293952743)
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
### Unresolved questions:
- [ ] [1. When do suitability of defaults need to be proven?](https://github.com/rust-lang/rfcs/blob/master/text/2532-associated-type-defaults.md#1-when-do-suitability-of-defaults-need-to-be-proven)
- [ ] [2. Where are cycles checked?](https://github.com/rust-lang/rfcs/blob/master/text/2532-associated-type-defaults.md#2-where-are-cycles-checked)
### Test checklist
Originally created [as a comment](https://github.com/rust-lang/rust/pull/61812#issuecomment-527959874) on #61812
- Trait objects and defaults
- Independent defaults (`type Foo = u8;`)
- [ ] where not specified (`dyn Trait`)
- show that it's an error to coerce from `dyn Trait<Foo = u16>` to that
- show that we assume it is `u8` by invoking some method etc
- [ ] where specified (`dyn Trait<Foo = u16>`)
- show that it's an error to coerce from `dyn Trait<Foo = u16>` to that
- show that we assume it is `u8` by invoking some method etc
- Mixed with type without a default (`type Foo = u8; type Bar;`)
- [ ] where neither is specified (`dyn Trait`) -- error
- [ ] where `Foo` is specified (`dyn Trait<Foo = u16>`) -- error
- [ ] where `Bar` is specified (`dyn Trait<Bar = u32>`) -- ok, check `Foo` defaults to `u8`
- [ ] where both are specified (`dyn Trait<Foo = u16, Bar = u32>`) -- ok
- Dependent defaults (`type Foo = u8; type Bar = Vec<Self::Foo>`)
- [ ] where neither is specified (`dyn Trait`) -- error
- [ ] where `Foo` is specified (`dyn Trait<Foo = u16>`) -- unclear, maybe an error?
- [ ] where `Bar` is specified (`dyn Trait<Bar = u32>`) -- unclear, maybe an error?
- [ ] where both are specified (`dyn Trait<Foo = u16, Bar = u32>`) -- ok
- Cyclic defaults (`type Foo = Self::Bar; type Bar = Self::Foo`)
- [ ] where neither is specified (`dyn Trait`)
- [ ] where `Foo` is specified (`dyn Trait<Foo = u16>`)
- [ ] where `Bar` is specified (`dyn Trait<Bar = u32>`)
- [ ] where both are specified (`dyn Trait<Foo = u16, Bar = u32>`)
- Non-trivial recursive defaults (`type Foo = Vec<Self::Bar>; type Bar = Box<Self::Foo>;`)
- [ ] where neither is specified (`dyn Trait`)
- [ ] where `Foo` is specified (`dyn Trait<Foo = u16>`)
- [ ] where `Bar` is specified (`dyn Trait<Bar = u32>`)
- [ ] where both are specified (`dyn Trait<Foo = u16, Bar = u32>`)
- Specialization
- [x] Default values unknown in traits
- [x] trait definition cannot rely on `type Foo = u8;` (`defaults-in-other-trait-items.rs`)
- [x] impl for trait that manually specifies *can* rely
- [x] also, can rely on it from outside the impl
- [x] impl for trait that does not specify *can* rely
- [x] impl with `default type Foo = u8`, cannot rely on that internally (`defaults-specialization.rs`)
- [x] default impl with `type Foo = u8`, cannot rely on that internally (`defaults-specialization.rs`)
- [x] impl that specializes but manually specifies *can* rely
- [ ] impl that specializes but does not specify *can* rely
- right? want also a test that this impl cannot be *further* specialized -- is "default" inherited, in other words?
- Correct defaults in impls (type)
- Independent defaults (`type Foo = u8;`)
- [x] overriding one default does not require overriding the others (`associated-types/associated-types-overridden-default.rs`)
- (does not test that the projections are as expected)
- [x] where not specified (`impl Trait { }`) (`associated-types/issue-54182-2.rs`)
- [x] where specified (`impl Trait { type Foo = u16; }`) (`issue-54182-1.rs`)
- Mixed with type without a default (`type Foo = u8; type Bar;`)
- [x] where neither is specified (`impl Trait { }`) -- error
- [x] where `Foo` is specified (`impl Trait { type Foo = u16; }`) -- error
- [x] where `Bar` is specified (`impl Trait { type Bar = u32; }`) -- ok
- [x] where both are specified (`impl Trait { type Foo = u16; type Bar = u32; }`) -- ok
- Dependent defaults (`type Foo = u8; type Bar = Vec<Self::Foo>`) -- `defaults-in-other-trait-items-pass.rs`, `defaults-in-other-trait-items-fail.rs`
- [x] where neither is specified (`impl Trait { }`)
- [x] where `Foo` is specified (`impl Trait { type Foo = u16; }`)
- [x] where `Bar` is specified (`impl Trait { type Bar = u32; }`)
- [x] where both are specified (`impl Trait { type Foo = u16; type Bar = u32; }`)
- Cyclic defaults (`type Foo = Self::Bar; type Bar = Self::Foo`) -- `defaults-cyclic-fail.rs`, `defaults-cyclic-pass.rs`
- [x] where neither is specified (`impl Trait { }`)
- considered to be an error only if a projection takes place (is this what we want?)
- [x] where `Foo` is specified (`impl Trait { type Foo = u16; }`)
- [x] where `Bar` is specified (`impl Trait { type Bar = u32; }`)
- [x] where both are specified (`impl Trait { type Foo = u16; type Bar = u32; }`)
- Non-trivial recursive defaults (`type Foo = Vec<Self::Bar>; type Bar = Box<Self::Foo>;`)
- [x] where neither is specified (`impl Trait { }`)
- [x] where `Foo` is specified (`impl Trait { type Foo = u16; }`)
- [x] where `Bar` is specified (`impl Trait { type Bar = u32; }`)
- [x] where both are specified (`impl Trait { type Foo = u16; type Bar = u32; }`)
- Correct defaults in impls (const)
- Independent defaults
- [ ] where not specified
- [ ] where specified
- Mixed with type without a default
- [ ] where neither is specified
- [ ] where `Foo` is specified
- [ ] where `Bar` is specified
- [ ] where both are specified
- Dependent defaults
- [ ] where neither is specified
- [ ] where `Foo` is specified
- [ ] where `Bar` is specified
- [ ] where both are specified
- Cyclic defaults -- `defaults-cyclic-fail.rs`, `defaults-cyclic-pass.rs`
- [x] where neither is specified (`impl Trait { }`)
- considered to be an error only if a projection takes place (is this what we want?)
- [x] where `Foo` is specified
- [x] where `Bar` is specified
- [x] where both are specified
- Non-trivial recursive defaults
- [ ] where neither is specified
- [ ] where `Foo` is specified
- [ ] where `Bar` is specified
- [ ] where both are specified
- Overflow errors in const evaluation
- check that errors in evaluation do not occur based on default values, but only the final values
- Dependent defaults (defaults-not-assumed-fail, defaults-not-assumed-pass)
- [x] where neither is specified
- [x] where `Foo` is specified
- [x] where `Bar` is specified
- [x] where both are specified
- WF checking (`defaults-suitability.rs`)
- requires that defaults meet WF check requirements (is this what we want?)
- [x] `type` in trait body, bound appears on the item
- [x] `type` in trait body, type not wf
- [x] `type` in trait body, bound appears as trait where clause
- [ ] `default type` in impl, bound appears on the item
- [ ] `type` in impl, bound appears on the item
- [ ] `type` in default impl, bound appears on the item
- [x] `type` in trait body, conditionally wf depending on another default
- currently gives an error (is this what we want?)
- [x] `type` in trait body, depends on another default whose bounds suffice
| One use case I’ve had for this is a default method whose return type is an associated type:
``` rust
/// "Callbacks" for a push-based parser
trait Sink {
fn handle_foo(&mut self, ...);
// ...
type Output = Self;
fn finish(self) -> Self::Output { self }
}
```
This means that `Output` and `finish` need to agree with each other any given `impl`. (So they often need to be overridden together.)
> default methods should not be able to assume anything about associated types.
This seems very restrictive (and in particular would prevent my use case). What’s the reason for this?
<|endoftext|>@SimonSapin
> This seems very restrictive (and in particular would prevent my use case). What’s the reason for this?
There is a basic tradeoff here, having to do with soundness. Basically, there are two options at the extreme:
- Do not allow default methods to assume anything about defaulted associated types; in return, you can pick and choose which defaults to use in your impl.
- Allow default methods to "see" defaulted associated types; in return, if you override any defaulted associated types, you have to override _all_ defaulted methods. Otherwise, you could get unsound code (based on incorrect type assumptions).
This is described in slightly more detail in [the RFC](https://github.com/aturon/rfcs/blob/associated-items/active/0000-associated-items.md#defaults).
Originally we proposed to go with the second route, but it has tended to feel pretty hokey, and we've been leaning more toward the first route.
(Incidentally, much the same question comes up for [specialization](https://github.com/rust-lang/rfcs/pull/1210).)
I'm happy to elaborate further, but wanted to jot off a quick response for now.
<|endoftext|>Would it be possible to track which default methods rely of which associated types being the default, so that only those need to be overridden?
<|endoftext|>@SimonSapin Possibly, but we have a pretty strong bias toward being explicit in signatures about that sort of thing, rather than trying to infer it from the code. It's always a bad surprise when changing the body of a function in one place can cause a downstream crate to fail typechecking.
You could consider having some explicit "grouping" of items that get to see a given default associated type.
I'm not sure if you've been following the [specialization RFC](https://github.com/rust-lang/rfcs/pull/1210), but part of the proposal is a generalization of default implementations in traits. Imagine something like the following alternative design for `Add` (rather than having `AddAssign` separately):
``` rust
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
fn add_assign(&mut self, Rhs);
}
// the `default` qualifier here means (1) not all items are impled
// and (2) those that are can be further specialized
default impl<T: Clone, Rhs> Add<Rhs> for T {
fn add_assign(&mut self, rhs: R) {
let tmp = self.clone() + rhs;
*self = tmp;
}
}
```
This feature lets you refine default implementations given additional type information. You can have many such `default impl` blocks for a given trait, and the follow specialization rules.
The fact that you can have multiple such blocks might give us a natural way to delimit the scopes in which associated types are visible (and hence in which the methods have to be overridden when those types are).
<|endoftext|>(cc @nikomatsakis on that last comment)
<|endoftext|>@aturon I assume you mean specifically this last paragraph:
> The fact that you can have multiple such blocks might give us a natural way to delimit the scopes in which associated types are visible (and hence in which the methods have to be overridden when those types are).
I find this idea appealing, I just think we have to square it away carefully, especially with the precise fn types we _ought_ to be using. :)
<|endoftext|>Is this feature still being worked on?
What do you think of something like this as a use case for this feature?
```rust
trait Bar {
type Foo;
// We want to default to just using Foo as its DetailedVariant
type DetailedFoo = Self::Foo;
// ...other trait methods...
fn detailed(&self) -> DetailedFoo;
// ...other trait methods...
}
```<|endoftext|>@sunjay nobody is working on this, I think we are still unsure what semantics we would want to have.<|endoftext|>> Allow default methods to "see" defaulted associated types; in return, if you override any defaulted associated types, you have to override all defaulted methods.
What about a compromise: if default method mentions the associated type in it's signature, then this type is allowed to be default and then, if you override such type, only those methods that use the type in signature would see the type being default.
Would this still be unsound/surprising?<|endoftext|>I hope this feature can be stabilised, it would help me out;
I was experimenting with rolling vector maths, trying to make it general enough to handle dimension checking / special point/normal types etc... it looks like this would be really useful for this. https://www.reddit.com/r/rust/comments/6i022j/traits_groupingsharing_constraints/dj4iwe1/?context=3
... I wanted to use 'helper traits' to simplify expressing a group of related types with some operations between them, without them necessarily 'belonging' to one type.
For my use case specific use case: I think it was most helpful for the trait to compute types that implementations must conform to; it was about letting any code that *uses* the trait also assume the whole set of bounds it defines. (whereas if I specify a 'where clause' in the trait, that merely tells users what *else* they need to manually specify)
it might look like overkill for the example in the thread, but the rest of my experiment is a lot messier than that
<|endoftext|>this is the sort of thing I'd want to be able to do:-
```
fn interp<X,Y>(x:X, (x0,y0):(X,Y), (x1,y1):(X,Y))->Y
where X:HasOperatorsWith<Y>
{ ((x-x0)/(x1-x0)) * (y1-y0) + y0
}
// Helper trait implies existance of operators between types Self,B
// such that addition/subtraction , multiplication/division produce intermediates
// but inverse operations cancel out.
// even differences may be other types, e.g. Unsigned minus Unsigned -> Signed
// Point minus Point -> Offset
pub trait HasOperatorsWith<B> {
type Diff=<Self as Sub<B>>::Output;
type ProdWith=<Self as Mul<B>>::Output;
type DivBy=<Self as Div<B>>::Output;
type Ratio=<Self as Div<Self>>::Output;
assume <Diff as Div<Diff>>::Output= Ratio;
type Square = <Self as Mul<B>> :: Ouput;
assume <ProdWith as Mul<DivBy> >::Output = Self // multiplication and division must be inverses
assume <Sum as Mul<DivBy> >::Output = Self
assume <Square as Sqrt<> > :: Output = Self
assume <Self as Add<Diff>> :: Output= Self // addition and subtraction must be inverses
// etc..
}
// implementor - so long as all those operators exist, consider 'HasOperatorsWith' to exist
// currently you must write another to instantiate it
impl <....> HasOperatorsWith<X> for Y where /* basically repeat all that above*/
```
maybe there's a nice way to say 'two functions are supposed to be inverses', e.g.
decltype(g(f(x:X)))==Y decltype(f(g(y:Y)))==X // f,g are unary functions, mutual inverses
decltype( gg(x, ff(x,y) ) )==X // ff, gg are binary operators that cancel out..
(any advice on how parts of this may already be possible is welcome, until 1 day ago I didn't realise you can do parts of that by placing bounds on the associated types.
Part of the problem is you are essentially re-writing code in a sort of LISP using the awkward angle-bracket type syntax; .. it's like we're going to end up with 'trait metaprogramming..'
Are there any RFCs for a C++ like 'decltype' ?
I also wish you had the old syntax for traits back as an option (just as you've got the option with 'where' to swap the order of writing bounds; part of the awkwardness is flipping the order in your head ... "Sum<Y,Output=Z> for X { fn sub(&self/* X */ , Y)->Z {} }
if you could write these traits 'looking like' functions, that would also help e.g.
impl for X : Sum<Y,Output=Z> {..} /* Mirrors the casting and calling syntax */ <|endoftext|>I have a issue similar to the one of @dobkeratops, where I'd like to provide a type alias, which is not just a default but should not be changed.
The code is
```
trait Dc<Elem> where Elem: Add + AddAssign + Sub + SubAssign + Neg + Rand {
type Sum = <Elem as Add>::Output;
[...]
}
```
It should not be possible to override `Sum`.
Also, I ran into the restriction that @SimonSapin had with associated methods. I think it would be useful to have a reasonable solution to that (if one exists). <|endoftext|>Would it be out of the question to stabilize a conservative implementation of this feature that doesn't let default functions assume the details of associated types, and lift restrictions later as allowed? Doing that should allow backwards-compatible changes in the future, and from what I've seen there don't seem to be any outstanding bugs preventing this from being stabilized. Those are also the semantics generic parameters on traits follow right now, so the behavior would be consistent with other parts of the language.<|endoftext|>I would also prefer getting a conservative version of this stabilised as currently there is no way to backwards compatibly add new associated types.<|endoftext|>I'm trying to make a trait with a function that returns an iterator and this is tripping me up:
```
trait Foo {}
trait Bar {}
trait Storage<T: Foo, U: Foo + Bar> {
type Item = U;
/// Get a value from the current key or None if it does not exist.
fn get(&self, id: &T) -> Option<U>;
/// Insert a value under the given key. Will overwrite the existing value.
fn insert(&self, id: &T, item: &U);
fn iter(&self) -> Iterator;
}
fn main () {
}
```
```
error: associated type defaults are unstable (see issue #29661)
--> src/main.rs:5:5
|
5 | type Item = U;
| ^^^^^^^^^^^^^^
```
https://play.rust-lang.org/?gist=1197424c5b9c3f16c6cdfc80fe744d5c&version=stable<|endoftext|>I may have run into a couple of bugs with this associated type defaults, as I believe https://play.rust-lang.org/?gist=ffc94a727888539a99ccfe6d9965a217&version=nightly should compile.
It looks like the default is not actually being "applied" in the trait impl. I assume this is not intended?
Fixing that by explicitly applying (l.31 from working version link, below) runs into a second error, requiring an ?Sized bound (l.6 below).
Here is the working version: https://play.rust-lang.org/?gist=3e2f2f39e38815956aaefaf511add0c1&version=nightly
Credit to @durka for the workarounds. (Thank you!)<|endoftext|>I just had one idea that would help ergonomics a lot. I'll call it "final associated types" for the purpose of this explanation. The idea is that some traits define associated types and sometimes, they use them as type parameters of other types. A notable example is the `Future` trait.
```rust
trait Future {
type Item;
type Error;
// | This is long and annoying to write and read
// V
fn poll(&mut self) -> Poll<Self::Item, Self::Error>;
}
```
What would be nice is being able to write this:
```rust
trait Future {
type Item;
type Error;
// This is practically type alias.
// Can't be changed in trait impl, only used.
final type Poll = Poll<Self::Item, Self::Error>;
fn poll(&mut self) -> Self::Poll;
}
```
It would also help various cases when one has associated type called `Error` and want's to return `Result<T, Self::Error>` one could write this:
```rust
trait Foo {
type Error;
// It can be generic
final type Result<T> = Result<T, Self::Error>;
fn foo(&mut self) -> Self::Result<u32>;
}
```
What do you think? Should I write an RFC, or could this be part of something else?<|endoftext|>@Kixunil For the first use case you can consider putting the type definition outside the trait:
```rust
trait Future {
type Item;
type Error;
fn poll(&mut self) -> FPoll<Self>;
}
type FPoll<F: Future> = Poll<F::Item, F::Error>;
```<|endoftext|>@bgeron good idea. I still like `Self::Poll` more, but maybe I will consider using `type` outside of trait.<|endoftext|>@Osspial as much as that'd be good, changing from a conservative to non-conservative assumption _is a breaking change_, as it would mean default methods which were previously available are now not available.
I'm for stabilizing this as well, but we need good semantics first.<|endoftext|>Here is a workaround I developed for https://github.com/serde-rs/serde/pull/1354 and worked successfully for my use case. It doesn't support all possible uses for associated type defaults but it was sufficient for mine.
Suppose we have an existing trait `MyTrait` and we would like to add an associated type in a non-breaking way i.e. with a default for existing impls.
```rust
// Placeholder for whatever bounds you would want to write on the
// associated type.
trait Bounds: Default + std::fmt::Debug {}
impl<T> Bounds for T where T: Default + std::fmt::Debug {}
trait MyTrait {
type Associated: Bounds = ();
//~~~~~~~~~~~~~~~~~~~~~~^^^^ unstable
}
struct T1;
impl MyTrait for T1 {}
struct T2;
impl MyTrait for T2 {
type Associated = String;
}
fn main() {
println!("{:?}", T1::Associated::default());
println!("{:?}", T2::Associated::default());
}
```
Instead we can write:
```rust
trait Bounds: Default + std::fmt::Debug {}
impl<T> Bounds for T where T: Default + std::fmt::Debug {}
trait MyTrait {
//type Associated: Bounds = ();
fn call_with_associated<C: WithAssociated>(callback: C) -> C::Value {
type DefaultAssociated = ();
callback.run::<DefaultAssociated>()
}
}
trait WithAssociated {
type Value;
fn run<A: Bounds>(self) -> Self::Value;
}
struct T1;
impl MyTrait for T1 {
// type Associated = ();
}
struct T2;
impl MyTrait for T2 {
// type Associated = String;
fn call_with_associated<C: WithAssociated>(callback: C) -> C::Value {
callback.run::<String>()
}
}
fn main() {
struct Callback;
impl WithAssociated for Callback {
type Value = ();
fn run<A: Bounds>(self) -> Self::Value {
// code uses the "associated type" A
println!("Associated = {:?}", A::default());
}
}
T1::call_with_associated(Callback);
T2::call_with_associated(Callback);
}
```<|endoftext|>cc https://github.com/rust-lang/rfcs/pull/2532<|endoftext|>I believe I have ran into a bug with this feature. Here is a minimal example to reprodue it:
```rust
trait Foo {
type Inner = ();
type Outer: Into<Self::Inner>;
}
impl Foo for () {
// With this, it compiles:
// type Inner = ();
type Outer = ();
}
```
Although `Inner` is given with `()` as its default, the example will not compile unless you specify `type Inner = ();` .
Edit: more precisely, it gives this error:
```
error[E0277]: the trait bound `<() as Foo>::Inner: std::convert::From<()>` is not satisfied
--> src/lib.rs:8:6
|
8 | impl Foo for () {
| ^^^ the trait `std::convert::From<()>` is not implemented for `<() as Foo>::Inner`
|
= help: the following implementations were found:
<T as std::convert::From<T>>
= note: required because of the requirements on the impl of `std::convert::Into<<() as Foo>::Inner>` for `()`
```
It seems like the associated type default is only applied after the trait bound is evaluated. Is this expected?<|endoftext|>Dumping for future reference:
```rust
#![feature(associated_type_defaults)]
trait A {
type B = Self::C;
type C = Self::B;
}
impl A for () {}
fn main() {
let x: <() as A>::B;
}
```
==>
```rust
error[E0275]: overflow evaluating the requirement `<() as A>::B`
thread '<unnamed>' panicked at 'Metadata module not compiled?', src/libcore/option.rs:1038:5
note: Run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
error: aborting due to previous error
```<|endoftext|>RFC https://github.com/rust-lang/rfcs/pull/2532 is now merged and specifies how `#![feature(associated_type_defaults)]` will behave moving forward. As a result, I will change the issue description and hide outdated and resolved comments so as to reduce confusion.<|endoftext|>In the following example, I was trying to use associated types to clean up programming against a generic trait. It seems to work fine for the "Self::Input" but doesn't work for "Self::Output". I don't know if this is a bug, or if my expectation isn't intended, but I at least wanted to share this in case something needs to be changed.
#![feature(associated_type_defaults)]
pub trait Component<InputT, OutputT> {
type Input = InputT;
type Output = OutputT;
fn input(value: Self::Input);
fn result() -> Self::Output;
}
pub struct Reciever;
impl<'a> Component<&'a [u8], Vec<u8>> for Reciever {
fn input(_value: Self::Input) {}
fn result() -> Self::Output { Vec::<u8>::new() }
}
========
error[E0308]: mismatched types
--> src/lib.rs:15:35
|
15 | fn result() -> Self::Output { Vec::<u8>::new() }
| ------------ ^^^^^^^^^^^^^^^^ expected associated type, found struct `std::vec::Vec`
| |
| expected `<Reciever as Component<&'a [u8], std::vec::Vec<u8>>>::Output` because of return type
|
= note: expected type `<Reciever as Component<&'a [u8], std::vec::Vec<u8>>>::Output`
found type `std::vec::Vec<u8>`<|endoftext|>[RFC 2532](https://github.com/rust-lang/rfcs/blob/master/text/2532-associated-type-defaults.md) still needs to be implemented as part of this, can anyone from @rust-lang/compiler write up mentoring instructions?
EDIT: Actually I might have figured most of this out already<|endoftext|>Regarding unresolved question 2:
> * [2. Where are cycles checked?](https://github.com/rust-lang/rfcs/blob/master/text/2532-associated-type-defaults.md#2-where-are-cycles-checked)
In https://github.com/rust-lang/rust/pull/61812, I wrote an additional test for similar cycles in assoc. consts, which looks like this and works as-is on stable Rust:
```rust
// run-pass
// Cyclic assoc. const defaults don't error unless *used*
trait Tr {
const A: u8 = Self::B;
const B: u8 = Self::A;
}
// This impl is *allowed* unless its assoc. consts are used
impl Tr for () {}
// Overriding either constant breaks the cycle
impl Tr for u8 {
const A: u8 = 42;
}
impl Tr for u16 {
const B: u8 = 0;
}
impl Tr for u32 {
const A: u8 = 100;
const B: u8 = 123;
}
fn main() {
assert_eq!(<u8 as Tr>::A, 42);
assert_eq!(<u8 as Tr>::B, 42);
assert_eq!(<u16 as Tr>::A, 0);
assert_eq!(<u16 as Tr>::B, 0);
assert_eq!(<u32 as Tr>::A, 100);
assert_eq!(<u32 as Tr>::B, 123);
}
```<|endoftext|>The RFC does not mention how defaults in trait objects are supposed to behave when the default type mentions the `Self` type. For example, here:
```rust
trait Tr {
type Ty = &'static Self;
}
```
If an object type like `dyn Tr` is created, what is `Ty` supposed to be?
Defaults in type parameters bail out in this case and require the user to specify a type explicitly. We could do the same here.
EDIT: After a conversation [on Discord](https://discordapp.com/channels/442252698964721669/443151243398086667/589882486096658453) it looks like this should go with the same solution as default type parameters (bail out and require the user to specify the type)<|endoftext|>#61812 has merged 🎉 | B-RFC-approved<|endoftext|>A-associated-items<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>F-associated_type_defaults<|endoftext|>S-tracking-needs-summary | 36 | https://api.github.com/repos/rust-lang/rust/issues/29661 | https://github.com/rust-lang/rust/issues/29661 | https://api.github.com/repos/rust-lang/rust/issues/29661/comments |
115,375,038 | 29,639 | Tracking issue for `no_core` stabilization | The `no_core` feature allows you to avoid linking to `libcore`.
| Perhaps it would be better to give this a 'positive' name, like `[freestanding]`?
<|endoftext|>`no_core` is basically useless on its own at the moment; you need `lang_items` to actually implement enough of the core traits to allow compiling anything non-trivial.
<|endoftext|>Traige: no change<|endoftext|>> no_core is basically useless on its own at the moment; you need lang_items to actually implement enough of the core traits to allow compiling anything non-trivial.
`#[no_core]` is super useful: some crates do not use any lang items and compile just fine (e.g. `cfg-if`), and if these crates aren't `#[no_core]` then we can't use them as dependencies of `libcore`, which means we have to duplicate them. For example, we currently duplicate `cfg-if` in libcore, libstd, stdsimd, and in libc (EDIT: and probably in hashbrown as well, that's 5 times that this macro is duplicated).
If we make `cfg-if` `#[no_core]` we can just add it as a normal cargo dependency to all those crates, and everything "just works". But we can't make it `#[no_core]` because it is not stable.<|endoftext|>@gnzlbg makes a great point.
Additionally I'd like it if it was renamed to not mention the name of any create. If we get core depending on more crates, core might not seem so `core`-y. Something like `no_dependencies` is more future proof.
On the other hand, maybe we'll someday want to make primitives like `float` only available from come crate, removing them from the ambient prelude. That would mean the current name is more forward compatible after all.<|endoftext|>This idea seems fishy and impractical for me, let me quote @Ericson2314 to elaborate why:
> If we get core depending on more crates, core might not seem so `core`-y.
If `core` requires a certain crate for its convenience features and that crate is small enough to be used by `core` and to not depend on `core` at all, then why wouldn't `core` just include that crate into itself as an RFC to the language as a whole? If `core` depends on such a crate, therefore all of its members are linked to `core` and take the disk space in the final executable, meaning that not there's totally no reason to avoid using such a crate even if it's used only briefly in a very specific place where it's not that necessary which is why people rewrite a subset functionality from existing crates themselves for their specific use case.
This is not true for procedural macros, which are loaded into the compiler when `core` itself is compiled but are completely transparent to the final application, but either way there's the problem with the "standard" part in "standard library". The point of it is to provide utilities and core language features which are useful in a wide range of programs. Now, admittedly, `cfg_if` performs conditional compilation which is typically only used in abstractions over platform-specific code and that is supposed to implemented by a few crates and then reused by many other crates, meaning that the total amount of code which uses `cfg_if` is relatively low. But since it's such a small thing which was found useful in `core`, maybe it can become part of its public API, solving the duplication problem, providing access to its (unchanging!) interface for all Rust programs and promoting the use of it in a wider range of crates, improving readability. **`no_core` would only promote hiding useful macros as private dependencies of `core` instead of promoting those macros becoming a part of Rust.**<|endoftext|>> If we make `cfg-if` `#[no_core]` we can just add it as a normal cargo dependency to all those crates, and everything "just works".
Please don't make `core` depend on anything unless there is a very good reason for it, much less on external repositories or on a particular build system.<|endoftext|>Marking as "needs-summary", because we need a closer look at the use cases for `#[no_core]`, and why it is that core can't "compile to nothing" to serve some of those use cases (macro-only crates aside).<|endoftext|>`no_core` implies so many things -- no `Add`, no `Fn`, etc -- that it doesn't seem like the right way to expose whatever the goals here are. To me, `no_core` is perma-unstable, as it's there for internal reasons so will stick around but won't be stable.
That's not to say that there couldn't be other things that would make sense to have on stable, like a "please don't use simd" kind of flag/attribute or "I wish LTO worked better to remove parts I don't need" or ..., but those wouldn't be this issue.<|endoftext|>In a recent embedded project, I needed to calculate CRC. I knew there is the `crc` crate which is quite minimal and meets every requirements.
The project is written mostly in C, so in order to save time, I exported a simple interface:
```Rust
#[no_mangle]
unsafe extern "C" fn calculate_crc(data: *const u8, len: usize) -> u32 {
...
}
```
... and turned that into an object file with `$ cargo rustc --release -- --emit=obj` and simply linked it to the rest.
This had no dependency on `core`. Initially I declared the whole thing as `#![no_core]` but faced the mentioned missing lang items.
Does this count in any way?<|endoftext|>`no_core` would defiintelly open up possibility of alternate core implementations. How useful would that be in current rust ecosystem - hard to tell. I could see this used in projects that require formal verification - eg. `Ada` limits it's stdlib for `SPARK`. But there may be better ways to achieve this.<|endoftext|>Should I be opening bug reports related to my use of `no_core`? I've seen confusing diagnostic messages and ICEs.<|endoftext|>@gheoan
ICEs need to be reported and fixed in most cases, even in `no_core`.
As for diagnostics, I don't think we should do anything for `no_core`-specific diagnostics, unless it's zero cost in terms of code added to rustc.<|endoftext|>> ICEs need to be reported and fixed in most cases, even in `no_core`.
Contradicts https://github.com/rust-lang/rust/issues/92495#issuecomment-1006193883:
> Personally, I don't think ICEs with `#![no_core]` are worth addressing. It's a perma-unstable feature, and lang items are effectively internal compiler code that happens to be written in a crate. We don't try to prevent ICEs in the face of modifications to the compiler itself (in fact, many internal compiler APIs will deliberately ICE when they are used incorrectly).
>
>
>
> The only correct way to use `#![no_core]` is to copy-paste all of the lang items, types, and impls that you're using (and even then, leaving out "unused" ones is pretty dubious).<|endoftext|>I think getting ICEs in `no_core` for not providing all the things is absolutely to be expected, and not something that needs to be fixed. For example, `u32` *is* `Copy`, and if you don't include that and thus get an ICE, too bad. We should not expend any effort at all to improve that situation.<|endoftext|>> I could see this used in projects that require formal verification - eg. Ada limits it's stdlib for SPARK. But there may be better ways to achieve this.
Imho, I think that it would be good to give Rust some hooks that would allow for use in safety-critical systems that could potentially eliminate the need for a separate core (for at least the basic SIL levels) - which would probably have benefits to the language as a whole. Some things I've considered that would help that -
- `#![no_panic]` being used to classify a any potential panics as UB. This would be pretty useful as a sanity check too throughout the language, `#[no_panic]` tags could be added to a lot of core/std functions for the compiler to verify (this would be useful in kernel space too)
- Some way to disallow unchecked casts and arithmetic
- Some sort of way to programatically tie `unsafe` blocks to the code that makes them safe. I'm stealing a bit from Ada contracts here where you can have a syntax like `with Pre => Name'Length > 0` for a function definition, indicating a precondition to make that function valid. It would be pretty awesome if you could do that sort of thing for any `unsafe fn`, indicate a precondition and make the caller indicate the lines where they check that brecondition to be true.
The first two things are basically clippy lints, but they would need to be applied recursively to everything linked. Stack size analysis is another thing, but this is already sort of coming via `stack_sizes`. It would be interesting to reach out to Ferrous Systems and see what the people there have to say on the subject.
Regarding the cfg-if thing, is there any reasons the implementations aren't just exported from core?<|endoftext|>@kotauskas
> If core requires a certain crate for its convenience features and that crate is small enough to be used by core and to not depend on core at all, then why wouldn't core just include that crate into itself as an RFC to the language as a whole? If core depends on such a crate, therefore all of its members are linked to core and take the disk space in the final executable, meaning that not there's totally no reason to avoid using such a crate even if it's used only briefly in a very specific place where it's not that necessary which is why people rewrite a subset functionality from existing crates themselves for their specific use case.
IIUC you might want to have core depend on an external crate for its _implementation_ without exposing that crate's API in core's API. E.g., per @gnzlbg, "we currently duplicate `cfg-if` in libcore, libstd, stdsimd, and in libc" - even if we don't intend to expose `cfg-if`'s API anywhere in the standard library, it would still be a boon to allow libcore, libstd, stdsimd, and libc to depend on a single crate rather than duplicating code across their implementations.<|endoftext|>> it would still be a boon to allow libcore, libstd, stdsimd, and libc to depend on a single crate rather than duplicating code across their implementations.
If I understand the argument correctly, it is essentially "except `core`, they all already depend on a single crate, namely `core` itself". | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 18 | https://api.github.com/repos/rust-lang/rust/issues/29639 | https://github.com/rust-lang/rust/issues/29639 | https://api.github.com/repos/rust-lang/rust/issues/29639/comments |
115,362,366 | 29,635 | Tracking issue for `fundamental` feature | This feature flag, part of [RFC 1023](https://github.com/rust-lang/rfcs/pull/1023), is not intended to be stabilized as-is. But this issue tracks discussion about whether _some_ external feature it needed. Perhaps there is a cleaner way to address the balance between negative reasoning and API evolution. See the RFC for details.
| Triage: no changes<|endoftext|>See alexcrichton/futures-rs#479 for an example of something this would solve.<|endoftext|>Triage: not aware of any change.<|endoftext|>So here's a fun bug due to lacking validation:
`a.rs`:
```rust
#![feature(fundamental)]
#[fundamental]
pub struct Foo;
```
`b.rs`:
```rust
extern crate a;
impl Clone for a::Foo {
fn clone(&self) -> Self { a::Foo }
}
```
I think the rule we should enforce is that `#[fundamental]` types have *at least* one type parameter, as *only* types can be *local* (e.g. constants are only ever "builtin", parameters or projections).<|endoftext|>I think it would make more sense to say that outside the defining crate, the coherence rules for `#[fundamental]` types are identical to a tuple of its generic parameters. You can't implement `Clone` for `Foo` for the same reason that you can't implement `Clone` for `()`.<|endoftext|>How do people feel about just stabilizing `#[fundamental]` on types as-is? I'm sure there could be a "more precise" way to exert control over the coherence rules, but honestly I've only needed to do that two or three times, and in each case `#[fundamental]` was sufficient.
Even if a more precise way *is* found, it's not the end of the world to have `#[fundamental]` as well, and it would be easy to remove with an edition change.
Has anyone actually encountered a situation where more control was needed?<|endoftext|>This needs some evaluation of what use cases will still exist after the current work on negative reasoning becomes available and stable.
It's possible there's still a use case for it after that, in which case we need to look at that more closely, and figure out if it can be supported in a reasonable way.
Or it's possible that what's left should be perma-unstable, given the coordination difficulties of doing this outside the standard library.<|endoftext|>I have a library in https://github.com/LightningCreations/lccc (the actual implementation/host side, rather than the stdlib/target side, so I don't have privileged unstable access), xlang_abi, which contains types that are necessary for communicating between modules soundly, and includes reimplementations of some standard library types (including Box). I would like to be able to support fundamental types on, at the very least, `xlang_abi::boxed::Box` (aformetioned type), as well as the Dyn* types from xlang_abi::traits (which are pointers/reference types that provide a stable abi for trait object types, mostly through emulation).
The relevant types are in https://github.com/LightningCreations/lccc/blob/main/xlang/xlang_abi/src/boxed.rs and https://github.com/LightningCreations/lccc/blob/main/xlang/xlang_abi/src/traits.rs<|endoftext|>I have a use case for `#[fundamental]` that I don't think there is much of an alternative around. I'm basically providing a wrapper type `Slot<T>`. Users of the API would like to implement `impl MyTrait for Slot<TheirType>`. The only way with the orphan rules is to the best of my knowledge this `#[fundamental]` attribute.<|endoftext|>FWIW, here is how `miniserde` handles that: https://docs.rs/miniserde/0.1.19/miniserde/macro.make_place.html (example of an impl like the one mentioned by @mitsuhiko: https://docs.rs/miniserde/0.1.19/miniserde/de/index.html#deserializing-a-primitive)<|endoftext|>The challenge with the approach that `miniserde` does is that these types are not compatible. `miniserde` gets around this by using `Option<T>` as compatible public API and unsafely transmuting between `&mut Option<T>` and `&mut PlaceType<T>`. I'm in quite a similar situation and having one shared slot type is obviously preferrable as it could be used in public APIs consistently.<|endoftext|>How about instead of marking the entire type as `#[fundamental]` we'd only mark the specific generic parameter that allows `impl` blocks in other crates?
So:
`a.rs`:
```rust
#![feature(fundamental)]
pub struct Foo<#[fundamental] S, T> {
// PhantomData ceremony
}
```
`b.rs`:
```rust
struct Bar;
// This is legal, because S is Bar and we own Bar
impl Clone for a::Foo<Bar, ()> {
fn clone(&self) -> Self {
a::Foo {
// PhantomData ceremony
}
}
}
// This is illegal, because Bar is in T. S is () and we don't own ()
impl Clone for a::Foo<(), Bar> {
fn clone(&self) -> Self {
a::Foo {
// PhantomData ceremony
}
}
}
```
Alternative syntax:
```rust
#[fundamental(S)]
pub struct Foo<S, T> {
// PhantomData ceremony
}
```
<|endoftext|>I think that the subset of `#[fundamental]`-for(-generic)-types (≠ `#[fundamental]`-for-traits) which could be stabilized would have to not only be explicit around not only around the generic parameters like you've suggested, @idanarye, but also around the specific traits that downstream users may implement.
Doing so would also improve the teachability of the feature as a whole: the question _what does `#[fundamental]` stand for is quite complex to answer:
- it's either for traits, or for generic types. For a non-generic type it doesn't make sense for instance.
- In the case of generic types, it yields a universal promise, future-wise, regarding a lack of blanket impls over that generic parameter, **for any trait in existence**. It's not only subtle, but a huge burden maintenance-wise. For instance, breaking that promise would not be easy to spot from a library author point of view (I guess the rationale is that the stdlib has enough pairs of eyes over it so that this footgun doesn't matter).
Stabilizing a subset of it with an explicit notation regarding both the generic parameter, _and the trait involved_, would thus not only improve the teachability / understandability of the feature and of its semantics, it would also improve the diagnostics when misused, as well as reduce the possitibility for footguns.
### Instead of `#[fundamental]` on a type, have an annotation for empty blanket impls over that type
Say, `#[downstream_may_impl]`, or `#[this_crate_shall_not_impl]`
- Or just `#[may_impl]` (or even keep the `#[fundamental]` name) — that detail is left for later bikeshedding.
```rust
#[bikeshed::this_crate_shall_not_impl]
impl<#[downstream] S, T> Serialize for Foo<S, T>;
```
this would thus not overlap with:
```rust
impl<T> Serialize for Foo<String, T> { … }
```
since `String` can't be a `#[downstream]` type, but it would overlap with
```rust
impl<S : Clone, T> Serialize for Foo<S, T> { … }
```
Since `<S : Clone>` and `<#[downstream] S>` may overlap.
- This is what I mean when talking of "catching mistakes". By having written that explicit promise of a lack of impl within the current crate, the coherence system would be able to complain should the blanket impl over `Clone` be added, which it could simply not have done in the case of a `#[fundamental(S)] struct Foo<S, T>` annotation (since undistinguishable from a blanket impl of `Serialize` always having been present).
___
This yields intuitive expectations w.r.t. the classic coherence rules, and is explicit over both the `#[downstream]` parameter, fundamental/coherence-wise, as well as the specific traits involved.
With it, using pseudo-code, one could even finally _illustrate_ the semantics of `Box` being fundamental, for instance:
```rs
#[bikeshed::this_crate_shall_not_impl]
impl<#[downstream] T : ?Sized> * for Box<T>;
```
- (I'm skipping the `A : Allocator` parameter, since I don't even know whether `Box` is fundamental over it as well or not)
where we'd be able to see there is yet another magical thing with a `#[fundamental]` generic type: a `*` quantification over all possible traits (but for those already implemented / "shadowed"…).
___
This proposal would be enough to cover @mitsuhiko's and `mini_serde`'s use cases, for instance.<|endoftext|>To be honest, I'd rather that `impl<#[downstream] T: ?Sized>` * for
Box<T>;` be spelt `#[downstream_may_impl] pub struct Box<#[downstream] T:
?Sized, A: Allocator>`.
On Tue, 19 Apr 2022 at 09:44, Daniel Henry-Mantilla <
***@***.***> wrote:
> I think that the subset of #[fundamental]-for(-generic)-types (≠
> #[fundamental]-for-traits) which could be stabilized would have to not
> only be explicit around not only around the generic parameters like you've
> suggested, @idanarye <https://github.com/idanarye>, but also around the
> specific traits that downstream users may implement.
>
> Doing so would also improve the teachability of the feature as a whole:
> the question _what does #[fundamental] stand for is quite complex to
> answer:
>
> - it's either for traits, or for generic types. For a non-generic type
> it doesn't make sense for instance.
> - In the case of generic types, it yields a universal promise,
> future-wise, regarding a lack of blanket impls over that generic parameter, *for
> any trait in existence*. It's not only subtle, but a huge burden
> maintenance-wise. For instance, breaking that promise would not be easy to
> spot from a library author point of view (I guess the rationale is that the
> stdlib has enough pairs of eyes over it so that this footgun doesn't
> matter).
>
> Stabilizing a subset of it with an explicit notation regarding both the
> generic parameter, *and the trait involved*, would thus not only improve
> the teachability / understandability of the feature and of its semantics,
> it would also improve the diagnostics when misused, as well as reduce the
> possitibility for footguns.
> Instead of #[fundamental], have a #[downstream_may_impl] annotation
>
> - Or just #[may_impl], or keep #[fundamental]. That detail is left for
> later bikeshedding.
>
> #[downstream_may_impl]
> impl<#[downstream] S, T> Serialize for Foo<S, T>;
>
> this would thus not overlap with:
>
> impl<T> Serialize for Foo<String, T> { … }
>
> since String can't be a #[downstream] type, but it would overlap with
>
> impl<S : Clone, T> Serialize for Foo<S, T> { … }
>
> Since <S : Clone> and <#[downstream] S> may overlap.
> ------------------------------
>
> This yields intuitive expectations w.r.t. the classic coherence rules, and
> is explicit over both the #[downstream] parameter,
> fundamental/coherence-wise, as well as the specific traits involved.
>
> With it, using pseudo-code, one coukd even finally *illustrate* the
> semantics of Box being fundamental, for instance:
>
> #[downstream_may_impl]
> impl<#[downstream] T : ?Sized> * for Box<T>;
>
> where we'd be able to see there is yet another magical thing with a
> #[fundamental] generic type: a * quantification over all possible traits.
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/rust-lang/rust/issues/29635#issuecomment-1102675387>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABGLD27YBWXG2KCF6FSMPBLVF22ELANCNFSM4BTTUBWA>
> .
> You are receiving this because you commented.Message ID:
> ***@***.***>
>
<|endoftext|>> (I'm skipping the `A : Allocator` parameter, since I don't even know whether `Box` is fundamental over it as well or not)
What do you mean "as well"? With your suggestion a type can be fundamental over different generic parameters as long as it's for different traits, but it should still not be fundamental over different generic paramters for the same trait. If `Box` is fundamental for both `T` and `A` over all the traits, than one crate can implement a trait for it for a `T` that it owns and another crate can implement a trait for it for an `A` that it owns, and we'd get into the same diamond pattern the orphan rules were created to prevent.
It's up for for the individual type to decide which generic parameters to be fundamental over, and in `Box`'s case it's an easy choice - it's `T`. `HashMap` has a much harder choice - should it be fundamental over `K` or over `V`? (probably `V`, but `K` has a strong enough case here to at least deserve a discussion)
Unless... did you mean you avoided doing something like that?
```rust
#[bikeshed::this_crate_shall_not_impl]
impl<#[downstream] T : ?Sized, A: Allocator> * for Box<T, A>;
```
If so - why not? Even if you allow this, it'd still be up for the downstream crate to include the allocator in their own `impl`s, and if they do something wrong with it (can't imagine what exactly, but let's say the will) it'd be explicit (since they'd have to explicitly add a generic parameter) and if they do something wrong `rustc` can probably catch it. So why prevent this possibility?
<|endoftext|>Heh, precisely because I didn't want to think about 2-ary-fundamental generic types I skipped the alloc parameter 😅 , but @idanarye it's nonetheless an interesting question; I actually find that my syntax can help explain what possible semantics `#[fundamental]` for 2-ary-fundamental generic types could be.
Given:
```rust
//! `::upstream`
pub trait Trait {}
#[bikeshed::this_crate_shall_not_impl]
impl<#[downstream] T : ?Sized, #[downstream] A: Allocator> Trait for Box<T, A>;
```
and:
```rs
//! `::a`
struct Local;
impl<A> ::upstream::Trait for ::upstream::Box<crate::Local, A> {}
```
then it would error stating that this blanket-over-the-second-param impl overlaps with the upstream's:
```rs
impl<#[downstream] T : ?Sized, #[downstream] A: Allocator> Trait for Box<T, A>;
```
precisely because a downstream crate could write
```rs
//! `::b`
struct Local;
impl ::upstream::Trait for ::upstream::Box<::a::Local, crate::Local> {}
```
That is, a `#[bikeshed::this_crate_shall_not_impl]` declaration has the advantage of explicitly forbidding blanket impls overlapping with it, not only within-the-same-crate (except for the `impl * for` case), but also for downstream crates (even in the `impl * for` case).
___
@chorman0773 the `impl * for` was not an actual or serious proposal, it was just pseudo-code. For that case @idanarye's syntax or the one you've suggested could work 👍 (I just wanted to chime in to suggest that other "ultra explicit and restricted fundamental" syntax to target specific traits, since it would already be quite useful, and I find it quite useful as well even just when reasoning about fundamental)<|endoftext|>That's the thing - this declaration should be rejected by the compiler:
```rust
impl<#[downstream] T : ?Sized, #[downstream] A: Allocator> Trait for Box<T, A>;
```
The rule should be that only one generic parameter is allowed to be `#[downstream]` for each such implementation. The creator of the fundamental type has to choose: either this:
```rust
impl<#[downstream] T : ?Sized, A: Allocator> Trait for Box<T, A>;
```
Or this:
```rust
impl<T : ?Sized, #[downstream] A: Allocator> Trait for Box<T, A>;
```
Of course, with this syntax that gives downstream permissions for implementing specific traits, one could do:
```rust
impl<#[downstream] T : ?Sized, A: Allocator> Trait1 for Box<T, A>;
impl<T : ?Sized, #[downstream] A: Allocator> Trait2 for Box<T, A>;
```
And then we could have:
```rust
//! `::a`
struct Local;
impl<A> ::upstream::Trait1 for ::upstream::Box<crate::Local, A> {}
```
```rust
//! `::b`
struct Local;
impl ::upstream::Trait2 for ::upstream::Box<::a::Local, crate::Local> {}
```
<|endoftext|>I think improving the current behaviour of this might be a blocker for #32838, since it's not at all obvious that we want to let people implement things for `Box<T, CustomAllocator>`, but it seems like that's what the `#[fundamental]` currently does.<|endoftext|>@scottmcm Only if the entire type is made fundamental. If the fundamentalness is limited to one generic parameters, as per my suggestion, then one could implement traits for `Box<T, CustomAllocator>` only in the crate that defines the `T` (or the trait). So you can't just implement things for `Box<i32, CustomAllocator>` because you don't own `i32`'s definition.<|endoftext|>We have a use case for `#[fundamental]` types in [turbo](https://github.com/vercel/turbo), where we're building an incremental computation engine.
A `Vc<T>` represents the result of a computation. In order to read the underlying value `T`, you must `.await` the `Vc<T>` because:
* the computation might not have finished otherwise; and
* we use `.await` calls to track dependencies.
You can also pass the `Vc<T>` itself around to create composite computations: `fn op(Vc<T>, Vc<U>) -> Vc<V>`.
We want to allow users to implement inherent methods on `Vc<T>` provided `T` is local. From my understanding of [the reference](https://doc.rust-lang.org/reference/glossary.html#fundamental-type-constructors), this should already be possible, but it is not implemented.
Would it make sense to extend fundamental types to cover inherent impls as well?
See also this [Zulip thread](https://rust-lang.zulipchat.com/#narrow/stream/122651-general/topic/Fundamental.20types.20and.20inherent.20impls).<|endoftext|>There's no disambiguation mechanism for conflicting things on inherent impls, so that would mean it's a breaking change to add *anything*, which seems too strong.
I thing the expectation will remain that such methods be added via extension traits, not inherent methods, even on `fundamental` types.<|endoftext|>Isn't it already a breaking change to add methods?
Consider this:
```rust
mod foo {
pub struct Foo;
}
mod bar {
pub trait Bar {
fn bar(&self);
}
impl Bar for super::Foo {
fn bar(&self) {
println!("Bar.bar");
}
}
}
use foo::Foo;
use bar::Bar;
fn main() {
Foo.bar();
}
```
If we add this to `mod foo`:
```rust
impl Foo {
pub fn bar(&self) {
println!("Inherent bar");
}
}
```
It'll change the behavior of `Foo.bar()`.<|endoftext|>In the "Library Evolutions" RFC, this was noted as being an acceptable
breaking change for the rust standard library. The Rust Semver RFC I
believe also calls it acceptable in a minor release.
On Thu, Jan 26, 2023 at 14:47 Idan Arye ***@***.***> wrote:
> Isn't it already a breaking change to add methods?
>
> Consider this:
>
> mod foo {
> pub struct Foo;}
> mod bar {
> pub trait Bar {
> fn bar(&self);
> }
>
> impl Bar for super::Foo {
> fn bar(&self) {
> println!("Bar.bar");
> }
> }}
> use foo::Foo;use bar::Bar;
> fn main() {
> Foo.bar();}
>
> If we add this to mod foo:
>
> impl Foo {
> pub fn bar(&self) {
> println!("Inherent bar");
> }}
>
> It'll change the behavior of Foo.bar().
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/rust-lang/rust/issues/29635#issuecomment-1405537306>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABGLD27YXQWMFYEFGIHKZPTWULIDVANCNFSM4BTTUBWA>
> .
> You are receiving this because you were mentioned.Message ID:
> ***@***.***>
>
<|endoftext|>Sop wouldn't doing the same for `#[fundamental]` and inherent methods also be acceptable?<|endoftext|>@idanarye No. It's allowed for traits because you have to option of using UFCS to write it in a way that can't conflict no matter what other methods people add to other traits.<|endoftext|>@scottmcm wrote:
> There's no disambiguation mechanism for conflicting things on inherent impls, so that would mean it's a breaking change to add _anything_, which seems too strong.
This is an acceptable tradeoff for us. We won't have inherent `impl<T> Vc<T>` in the crate where `Vc` is defined. All inherent impls will occur in user crates, for some known `U` type (`impl Vc<U>`). | T-lang<|endoftext|>B-unstable<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-needs-summary | 26 | https://api.github.com/repos/rust-lang/rust/issues/29635 | https://github.com/rust-lang/rust/issues/29635 | https://api.github.com/repos/rust-lang/rust/issues/29635/comments |
47,667,338 | 18,598 | DST/custom coercions | Tracking issue for RFC rust-lang/rfcs#982.
Current state:
- [x] Implementation work (largely done)
- [ ] Stabilization -- the `CoerceUnsized` trait is unstable and we wish to revisit its design before stabilizing, so for now only stdlib types can be "unsized"
Things to consider prior to stabilization
* Interaction with pin, see [this internals thread](https://internals.rust-lang.org/t/unsoundness-in-pin/11311) and #68015 for details.
Part of #18469
| I'm confused as to what this is about. isn't https://github.com/rust-lang/rust/issues/18469 the tracking issue?
<|endoftext|>Yes, this is a specific part of 18469. Seems useful to have it by itself since it stands alone (goes for the other issues too).
<|endoftext|>Is there anything that could be done to push this towards stabilization? I have some APIs in mind that would benefit significantly from the ability to bound on the `Unsize` trait.<|endoftext|>I was idly wondering about this the other date with a type such as:
```rust
struct Foo {
flag: bool,
data: str,
}
```
Today there's not a *huge* amount of support for that but I noticed one oddity. So in theory the only way to instantiate such a type is to start with a concrete type, right? Let's say:
```rust
struct FooConcrete {
flag: bool,
data: [u8; 10],
}
```
I would personally expect, then that if we had a function like:
```rust
fn foo(drop_me: Box<Foo>) {
drop(drop_me);
}
```
That function would simultaneously run the destructor for the underlying type and also free the memory. Currently, however, it only frees the memory and doesn't actually run any destructor. More interestingly this namely to me at least means that the `Box<Foo>` type needs *two* pieces of external data, both a vtable for the destructor but also a `usize` for the length of the dynamically sized data.
I'm not sure if this is just an unsupported use case perhaps? Or maybe support for this is planned elsewhere? Or maybe this isn't part of this issue at all?
In any case just wanted to bring it up!<|endoftext|>What do you mean by the destructor not being called? I am quite sure it is:
```Rust
use std::mem;
struct Foo {
flag: bool,
data: str,
}
struct FooConcrete {
flag: bool,
data: [u8; 10],
}
impl Drop for Foo {
fn drop(&mut self) {
println!("splat! {:?} {}", self.flag, &self.data)
}
}
fn main() {
let _foo: Box<Foo> = unsafe { mem::transmute(
(Box::new(FooConcrete {
flag: false,
data: [0; 10]
}), 10)
)};
}
```
## EDIT:
Code above is buggy, better version:
```Rust
use std::mem;
#[repr(C)]
struct Foo {
flag: bool,
data: str,
}
#[repr(C)]
struct FooConcrete {
flag: bool,
data: [u8; 10],
}
impl Drop for Foo {
fn drop(&mut self) {
println!("splat! {:?} {}", self.flag, &self.data)
}
}
fn main() {
let _foo: Box<Foo> = unsafe { mem::transmute(
(Box::new(FooConcrete {
flag: false,
data: [0; 10]
}), 10usize)
)};
}
```
<|endoftext|>Oh I mean when you implement the destructor for `FooConcrete` instead of `Foo`, that one isn't run. (your example gives a segfault locally for me as well...)
I'm specifically thinking of something like this:
```rust
pub struct Foo {
flag: bool,
data: str,
}
#[no_mangle]
pub extern fn drop(_b: Box<Foo>) {
}
```
where the IR is:
```ll
; ModuleID = 'foo.cgu-0.rs'
source_filename = "foo.cgu-0.rs"
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
%Foo = type { i8, i8 }
%"unwind::libunwind::_Unwind_Exception" = type { i64, void (i32, %"unwind::libunwind::_Unwind_Exception"*)*, [6 x i64] }
%"unwind::libunwind::_Unwind_Context" = type {}
; Function Attrs: nounwind uwtable
define void @drop(%Foo* noalias nonnull, i64) unnamed_addr #0 personality i32 (i32, i32, i64, %"unwind::libunwind::_Unwind_Exception"*, %"unwind::libunwind::_Unwind_Context"*)* @rust_eh
_personality {
entry-block:
%2 = add i64 %1, 1
%3 = icmp eq i64 %2, 0
br i1 %3, label %_ZN4drop17hc3530aa457fb35acE.exit, label %cond.i
cond.i: ; preds = %entry-block
%4 = getelementptr inbounds %Foo, %Foo* %0, i64 0, i32 0
tail call void @__rust_deallocate(i8* %4, i64 %2, i64 1) #1
br label %_ZN4drop17hc3530aa457fb35acE.exit
_ZN4drop17hc3530aa457fb35acE.exit: ; preds = %entry-block, %cond.i
ret void
}
; Function Attrs: nounwind
declare void @__rust_deallocate(i8*, i64, i64) unnamed_addr #1
; Function Attrs: nounwind
declare i32 @rust_eh_personality(i32, i32, i64, %"unwind::libunwind::_Unwind_Exception"*, %"unwind::libunwind::_Unwind_Context"*) unnamed_addr #1
```
Notably there's some concrete type behind `Box<Foo>`, so presumably some dynamic call to a destructor needs to be made, but in this case it isn't :(<|endoftext|>@alexcrichton transmuting `Box::new((..., 10usize))` instead of `Box::new((..., 10))` fixes the segfault (bug?).
Back on topic, `Foo` isn't a trait so I don't see why `Box<Foo>` should have a vtable; `Box<Foo>` is a concrete type (just an unsized one). After transmuting, `Box<Foo>` should (and does) forget it ever was a `Box<FooConcrete>`.<|endoftext|>@Stebalien ah yes that does indeed fix it!
For me at least I'd expect `Box<Foo>` here to still run the destructor of the underlying type. It's not a trait object, yeah, but it's still erasing the underlying type. Otherwise this'd end up leaking resources, and would practically not be too useful I'd imagine?
(that being said I'm still not sure of the practicality of the `Foo` type anyway)<|endoftext|>> For me at least I'd expect Box<Foo> here to still run the destructor of the underlying type. It's not a trait object, yeah, but it's still erasing the underlying type. Otherwise this'd end up leaking resources, and would practically not be too useful I'd imagine?
Why? They're totally unrelated types; `FooConcrete` isn't an underlying type, it's a *different* type. As a matter of fact, as-is, the code above is UB: rust could decide to lay out `FooConcrete` as `([u8; 10], bool)` instead of `(bool, [u8; 10])`. Only `Foo` is guaranteed to have the `data` field come last (because DSTs must always come last).
IMO, the correct correct way to do this would be to allow `box Foo { flag: true, data: *"my string" }`, but, for now, I don't see any way to safely construct a `Foo` (without invoking UB).<|endoftext|>I mean... I'm stating my opinion. Today the destructor isn't run. I'm trying to clarify if it *should* be run. I believe it should be run. If we don't run the destructor then to me this isn't a very useful feature in practice because that just means resources are leaked which tends to want to be avoided.<|endoftext|>I just don't understand why it should be run. Would you expect the following to print "dropping bar" (it currently prints "dropping baz")?:
```rust
use std::mem;
struct Bar;
struct Baz;
impl Drop for Bar {
fn drop(&mut self) {
println!("dropping bar");
}
}
impl Drop for Baz {
fn drop(&mut self) {
println!("dropping baz");
}
}
fn main() {
unsafe {
let bar: Box<Bar> = Box::new(Bar);
let _baz: Box<Baz> = mem::transmute(bar);
}
}
```
The only difference is that `Baz` is sized.<|endoftext|>@alexcrichton
Of course, I should make sure to be portable to 64-bit architectures and add `#[repr(C)]` everywhere to make it valid :-).
I think the semantics of destructors are quite clear by this point. I have seen the pattern `struct Foo([u8]);` used as a newtype several times (because there is no header field, you can create it by directly transmuting a `[u8]`).
<|endoftext|>Ok well if the answer here is "no" then it's no.
My intuition follows from that we always run the destructor of the type behind a trait object. I don't see how that's different here. There's an unsized type that represents some dynamic selection of a particular type at runtime. That unsized type, when dropped, is then responsible for cleaning up the runtime type.
@Stebalien I think your example is missing the point, of course that destructor does not run. For this example:
```rust
struct Foo {
a: bool,
b: str,
}
struct FooConcrete {
a: bool,
b: [u8; 10],
}
impl Drop for FooConcrete {
fn drop(&mut self) {
println!("drop");
}
}
fn coerce(a: Box<FooConcrete>) -> Box<Foo> {
// ..
}
fn main() {
let a = Box::new(FooConcrete {
a: false,
b: *b"helloworld",
});
let b = coerce(a);
drop(b);
}
```
I would expect that example to print `drop`, but it does not today and fundamentally seems to not have support for doing so.
Again I'm talking about my own personal intuition for where I thought we were taking dynamically sized types. If this is not the direction that we're going in then it just means `Box<Foo>` in this example isn't a very useful type and should be avoided.<|endoftext|>@alexcrichton: My opinion is that there's confusion here around what "the type behind a trait object" means. Personally, I've seen two approaches taken:
1. `Foo<Concrete> -> Foo<Dst>` - before your question, this was the only one I'd seen
2. `FooConcrete -> FooDst`
The former seems to me like it has a clear relation via the `Unsize<Dst>` trait impl of its _parameter_.
The latter seems like it needs an `impl Unsize<FooDst> for FooConcrete`, which isn't a thing AFAIK.
EDIT: In addition, I'm used to DSTification being done with `as`, not `transmute`. Since `transmute` is a _reinterpretation_, nothing more, I am wholly unsurprised by the behavior you observed. You reinterpreted a `FooConcrete` as a `FooDst`, and `FooDst` has no destructor. The type system lost that `FooConcrete` was involved at `transmute` - it is _not_ "behind" `FooDst`, as that's what `Unsize` is for..<|endoftext|>Thanks @eternaleye; now I see where you're coming from @alexcrichton. FYI, here's the relevant part of the RFC:
> There is an `Unsize` trait and lang item. This trait signals that a type can be converted using the compiler's coercion machinery from a sized to an unsized type. All implementations of this trait are **implicit and compiler generated**. It is an error to implement this trait.<|endoftext|>Hello ! I have noticed a weird lack of symmetry is the types for which `Unsize` is implemented. It seems to be reflexive for traits but not for slices; see:
```rust
#![feature(unsize)]
trait Trait {}
struct A; impl Trait for A {}
fn f<T: ?Sized, U: ?Sized>() where T: std::marker::Unsize<U> {}
fn main() {
// for traits:
f::<A, Trait>(); // works normally
f::<Trait, Trait>(); // works; Unsize is reflexive
// for slices:
f::<[usize; 4], [usize]>(); // works normally
f::<[usize], [usize]>(); // error; Unsize isn't reflexive ?
}
```
I was told that this could be an omission in design. Is that the case ?
Thank you for your time and great language.<|endoftext|>@carado Looks like a fair point. Maybe open a new issue about it?<|endoftext|>Currently `CoerceUnsized` is only implementable for structs that have exactly **one** field being coerced.
I would like to implement it for a type that that has **zero** coercible fields (i.e. only `PhantomData` fields).
Is there any reason why type coercion couldn't work for a struct with only `PhantomData` fields?<|endoftext|>Perhaps I do not understand correctly, but isn't nothing preventing `unsize` from being stabilized? <|endoftext|>Stabilizing the current `CoerceUnsized` trait will prevent us from ever adding custom DST's that don't built on top of slices and trait objects. For example `CStr` except that the length is calculated when required rather than stored in the pointer metadata. Or `CppObject` where you call into C++ to get the size of the value behind a reference.<|endoftext|>> Stabilizing the current `CoerceUnsized` trait will prevent us from ever adding custom DST's that don't built on top of slices and trait objects. For example `CStr` except that the length is calculated when required rather than stored in the pointer metadata. Or `CppObject` where you call into C++ to get the size of the value behind a reference.
From what I understand though,
`#![feature(unsize)]` does not require `#![feature(coerce_unsized)]`?<|endoftext|>I don't think `Unsize` is useful without `CoerceUnsized`. `Unsize` is used for implementing `CoerceUnsized`, but the actual unsizing operation uses `CoerceUnsized`. I also expect manually implementing `Unsize` to either be forbidden or be able to cause compiler crashes or unsoundness.<|endoftext|>> I don't think `Unsize` is useful without `CoerceUnsized`. `Unsize` is used for implementing `CoerceUnsized`, but the actual unsizing operation uses `CoerceUnsized`. I also expect manually implementing `Unsize` to either be forbidden or be able to cause compiler crashes or unsoundness.
This is a use case where `Unsize` is useful @bjorn3
https://github.com/getcollective-ai/collective/blob/d69c7c1549b6efde48529cd21bd5159e6a48160c/code/executor/src/command.rs#L35-L38
Useful snippets:
```rust
/// The command we are executing
#[derive(Discriminant)]
enum Cmd {
/// a zsh script to execute
Zsh,
Bash,
}
#[async_trait]
trait Command {
async fn execute(&self, exec: Ctx, input: &str) -> anyhow::Result<String>;
}
#[async_trait]
impl Command for Zsh {
async fn execute(&self, exec: Ctx, input: &str) -> anyhow::Result<String> {
// ...
}
}
#[async_trait]
impl Command for Bash {
async fn execute(&self, exec: Ctx, input: &str) -> anyhow::Result<String> {
// ...
}
}
fn this_requires_unsize() {
let cmd1: Box<dyn Command> = Cmd::Zsh.cast();
let cmd2: Box<dyn Command> = Cmd::Bash.cast();
}
```
where `Discriminant` generates
```rust
impl From<Zsh> for Cmd {
fn from(value: Zsh) -> Self { Self::Zsh }
}
impl std::convert::TryFrom<Cmd> for Zsh {
type Error = Cmd;
fn try_from(value: Cmd) -> Result<Self, Self::Error> { if let Cmd::Zsh = value { Ok(Zsh) } else { Err(value) } }
}
#[doc = " a zsh script to execute"]
struct Zsh;
impl From<Bash> for Cmd {
fn from(value: Bash) -> Self { Self::Bash }
}
impl std::convert::TryFrom<Cmd> for Bash {
type Error = Cmd;
fn try_from(value: Cmd) -> Result<Self, Self::Error> { if let Cmd::Bash = value { Ok(Bash) } else { Err(value) } }
}
struct Bash;
impl Cmd {
fn cast<U: ?Sized>(self) -> Box<U> where Zsh: ::core::marker::Unsize<U>, Bash: ::core::marker::Unsize<U> {
let value = self;
let value = match Zsh::try_from(value) {
Ok(v) => {
let x = Box::new(v);
return x;
}
Err(v) => v,
};
let value = match Bash::try_from(value) {
Ok(v) => {
let x = Box::new(v);
return x;
}
Err(v) => v,
};
unreachable!();
}
}
```<|endoftext|>I'm curious why CoerceUnsized would prevent changing how dsts work. It's a trait with no methods. Could it be limited to derive, that is make it impossible for anyone to write a manual impl, and then the behavior could be changed later? That is to say that while the restriction today would be struct of one field etc. because no one can manually implement it, the restriction could be lifted later once the behavior is more defined and/or someone decides what to do about the dst general case.
My use case not that long ago is that I'm writing audio code which needs to never deallocate on the audio thread, and I wanted to have custom smart pointers which would defer deallocation to another thread in the background. They were also going to allocate objects from pools for cache friendliness. This can't be built on top of `Arc` and `Weak` without stabilizing custom allocators (and maybe not even then?) but this would have neatly solved the problem as far as I can tell. Instead, I dropped trying for it in favor of stdlib `Arc` and have moved to an architecture with custom 64-bit ids to do cross-thread addressing, wherein the user-side pieces are going to literally basically be `Arc<u64>`. Perhaps I will go back to it eventually, only with very specific unsizing ops of my own to dedicated traits.
Is anyone actively working on custom dsts? I keep seeing people saying it's important but the only use case I think I've seen is async traits. I don't find the "get size from C++ to put thing on the stack" use case that interesting because C++ itself doesn't really allow for that in the first place. As far as I know no popular language is talking about trying to e.g. put virtual classes on the stack. You can do it in C with alloca or gcc extensions but those just cause more problems than they're worth in my experience: suddenly you're open to stack overflows because of a math bug or whatever. And a similar thing with `CStr` that doesn't store length: now you've got possibly-implicit strlen all over.
I'm not saying "O dsts are useless" just that I see people talking about them as useful but never really having examples, and in
this case we have a general concrete usefulness for `CoerceUnsized` and it's easy to understand what that is.
Also, I see a soundness hole in many of the examples of custom dsts that get brought up from time to time in any case. They can make Rust unsound: if someone figures out how to get a value into the program they can read any pointer relative to the stack, at least for most schemes which would involve bumping sp or similar (and presumably anything more complex would have enough overhead that you'd go to the system allocator). It seems to me that custom dsts are years away but `CoerceUnsized` could probably be done in the very near future.<|endoftext|>> I don't find the "get size from C++ to put thing on the stack" use case that interesting because C++ itself doesn't really allow for that in the first place. As far as I know no popular language is talking about trying to e.g. put virtual classes on the stack.
Having `Box<MyDst>` also requires the length to be known at runtime as it is passed to the deallocation function.
For your use case can you have a type that is equivalent to `Arc<[T]>` rather than `Arc<U>`? That is specializing it to only work with slices rather than any (dynamically sized) type? In that case I don't think you need `CoerceUnsized`.<|endoftext|>Hey @bjorn3! 😊
I hope you're doing well. I wanted to get a better understanding of your perspective on the `unsize` feature. Do you think it's ready to be on the fast track to stabilization, or are there any concerns that you believe need to be addressed first?
I noticed that you liked my previous response, but it seemed like you might have had some disagreement with it earlier. I'd really appreciate your thoughts on this matter because I'd love to be able to use `unsize` as quickly as possible in stable.<|endoftext|>My use case wouldn't have been a slice, it would have been `Arc<SineGenerator>` to `Arc<dyn Node>` on top of my own non-std smart pointers, where the actual raw stored pointer pointed into a slab. It's been a bit since I tried to do it, but as I recall I gave up on a general solution because writing helpers to do the downcasting was getting gnarly. I'll revisit more specific solutions eventually but only after benchmarks etc; I thought I could produce a generally useful library which could be published to crates.io but it turned out I couldn't because I was running into combinations of unergonomic APIs and type constraints. It's a shame I didn't think to come here around the time I was doing it, if I had I'd have been able to articulate this better.
Essentially, I wanted to do:
```
struct SmartPointer<T> {
page: *mut SlabPage,
data: *const T,
}
```
It would have had to be:
```
struct SmartPointer<T> {
data: *const T,
}
#[repr(C)]
struct SlabItem<T> {
header: *mut SlabPage,
data: T,
}
```
Which is a bit less ideal (the backpointers get in the way of a fully contiguous array) but workable with what we have here. It would of course be possible to go further and do pointer arithmetic and always align slab pages to OS pages, but that's kinda beside the point. these would have had Drop impls that pushed to a background thread if the slab page needed to go away, but that's also beside the point (tldr: you can write realtime-safe audio code if you assume reasonable limits for everything and glitch if someone makes the library have to allocate more on the audio thread).
Also I was conflating dsts on the stack with dsts in general which I realized a few minutes ago. I'm still not sure I see any particular benefit to extending the model or any reason why `CoerceUnsized` is incompatible with a more advanced model.
What is a realistic case wherein I'd be dealing with something that isn't effectively `(length, dst)`? If the length has to be passed to the deallocator, then it needs to always be known somehow or other. If the object came from C, then presumably it needs to be deallocated by C since Rust requires sizes and it's not guaranteed that Rust is using malloc.
Is the issue that we would want to coerce from `struct MySizedType` to `dst MyUnsizedType` where the compiler doesn't understand the coercion as it does slices/trait objects? E.g. the C trick of a header in the first field. I could sort of see that being a problem but it seems like a derive-only restriction for now lets it be extended later.<|endoftext|>Fwiw, I've been experimenting with Unsize and CoerceUnsized recently, see https://github.com/ferrous-systems/unsize-experiments. I was planning on trying to write down my findings there as a pre-RFC next week.<|endoftext|>Fwiw, I posted a pre-RFC on irlo: https://internals.rust-lang.org/t/pre-rfc-flexible-unsize-and-coerceunsize-traits/18789 | B-RFC-approved<|endoftext|>A-dst<|endoftext|>T-lang<|endoftext|>C-tracking-issue<|endoftext|>A-coercions<|endoftext|>S-tracking-needs-summary | 29 | https://api.github.com/repos/rust-lang/rust/issues/18598 | https://github.com/rust-lang/rust/issues/18598 | https://api.github.com/repos/rust-lang/rust/issues/18598/comments |
37,933,340 | 15,701 | Tracking issue for stmt_expr_attributes: Add attributes to expressions, etc. | Tracking RFC 40: https://github.com/rust-lang/rfcs/pull/16
| cc @huonw
<|endoftext|>ping. will this be implemented before 1.0?
<|endoftext|>The RFC suggests
> The sort of things one could do with other arbitrary annotations are
>
> ``` rust
> #[allowed_unsafe_actions(ffi)]
> #[audited="2014-04-22"]
> unsafe { ... }
> ```
>
> and then have an external tool that checks that that `unsafe` block's only unsafe actions are FFI, or a tool that lists blocks that have been changed since the last audit or haven't been audited ever.
which inspired me to make a [plugin for cryptographically signing `unsafe` blocks](https://github.com/kmcallister/launch-code). It would be great to put those signatures on the blocks themselves rather than the enclosing function.
<|endoftext|>The RFC says:
> Attributes bind tighter than any operator, that is `#[attr] x op y` is always parsed as `(#[attr] x) op y`.
Does this mean that `#[attr] x.f()` should be parsed as `(#[attr] x).f()`? And should `#[a] f()` be the same as `(#[a] f)()`?
And what happens if an attribute is applied to a syntax sugar construct that is later expanded, for example `#[attr] in <place> { <expr> }`? There isn't really an obvious place for the attribute in the desugared form, so not allowing them seems more sensible.
<|endoftext|>Just a heads up that I'm currently in the process of implementing this RFC.
<|endoftext|>I think the obvious choice is to give attributes the same operator precedence as unary operators.
So `#[attr] x.f()` would be parsed as `#[attr] (x.f())`, but `#[attr] x + f` will be `(#[attr] x) + f`.
<|endoftext|>Yeah, thats how I'm doing it in my WIP branch right now.
<|endoftext|>@Kimundi, is there a reason that https://github.com/rust-lang/rust/pull/29850 doesn't close this?
<|endoftext|>Not as far as I can rember, probably just forgot about it. :)
<|endoftext|>FYI, the `stmt_expr_attributes` feature gate still mentions this issue number.
<|endoftext|>Tracking issues are open until the feature is stable, aren't they?
<|endoftext|>By what Rust version will this feature gate be allowed on the stable channel? I couldn't find any chart / matrix with the list of them.
<|endoftext|>Nominating for discussion at lang-team meeting. I'd like to propose we stabilise on statements, remove from expressions. I suppose that requires an amendment RFC?
Do we have examples of uses where an attribute is on an expression, not a statement (and not an expression in statement position)?
<|endoftext|>@nrc Yes, here is one (which I have used as well): https://github.com/rust-lang/rust/issues/32796#issuecomment-216884218
<|endoftext|>**Hear ye, hear ye!** This unstable issue is now entering **final comment period**. We wanted to **move to stabilize** attributes at the statement, but we also wished to seek feedback on attributes on the expression and sub-expression level. This FCP lasts for roughly the current release cycle, which began on Aug 18.
@rust-lang/lang members, please check off your name to signal agreement. Leave a comment with concerns or objections. Others, please leave comments. Thanks!
- [x] @nikomatsakis
- [x] @nrc
- [x] @aturon
- [x] @eddyb
- [x] @pnkfelix (on vacation)
<|endoftext|>My take on the expression-level attributes: I remain somewhat uncomfortable with the precedence and so forth of said attributes, but on the other hand I don't see any fundamental difficulties. The use-case described by @comex seems pretty compelling. I also can't help but think of Java's experience with `@Attribute`, which were initially very limited in where they could be used, but which have been gradually being expanded more and more. Finally, it seems like since Rust is such an expression-oriented language, limiting to statements might be a bit surprising.
@nrc, I'm curious what your specific concerns about regarding expression positions.
<|endoftext|>Does Java allow attributes on expressions.
My objection is basically that it is confusing and feels weird, and that there have not been enough use cases to persuade me that it is worth the confusing weirdness. In particular since any expression can be made into a statement by extracting a variable, there is always a work around. I believe, that doing that refactoring where an attribute is required results in nicer code in nearly all cases.
Concretely, a large part of the weirdness to me comes from precedence difficulties. There is basically no 'good' precedence - e.g., `#[foo] a + b`, I feel like there is no reason to apply it to the whole expression or the sub-expression. There is no intuition for which expression the attribute should apply to.
I think of attributes as a way to indicate meta-data about an AST node to the compiler or a tool or macro. I have a hard time thinking of such meta-data that should be indicated at an expression-level granularity. Anything I can think of would change the semantics of the expression in such a way that I would expect there to be first-class syntax for it.
Finally there is the exact meaning of attributes, especially `cfg` on experssions, e.g., what does `(#[cfg(foo)] a) + b` mean? `+ b` is not a well-formed expression, but by the same reasoning `(#[cfg(foo)] a + ) b` should not parse.
Looking at the example provided as a use case:
```
let backends = [
#[cfg(feature = "foo-backend")] foo_backend,
#[cfg(feature = "bar-backend")] bar_backend,
];
```
If neither of the features hold, then we should have `let backends = [,,]`. This works in practice because of the way the list node is defined in the AST. I.e., the feature is kind of weird in that it is applying not just to an expression node in the AST, but also some decoration, depending on the exact implementation of the parent AST node.
<|endoftext|>@nrc Keep in mind that you can't work around by extracting a variable if the goal is to conditionally remove an element from some sort of list, including arrays as in the 'backends' case, and potentially function arguments and fields in struct definitions/literals. Though for the latter, it's probably better to just use a typedef which evaluates to `()` in the omitted case.
Incidentally, a data point relevant to attributes on _patterns_: GCC and Clang have a number of function attributes which require specifying one or more parameters by number; for example, `__attribute__(alloc_size(2))` is a hint that the function will return a newly allocated buffer whose size is the value passed as the second argument. If such an attribute were added to Rust, it would be nicer if it could just be placed directly on the relevant parameter declaration rather than requiring counting.
For that matter, any future attribute for variables or name bindings in general would ideally be writable wherever variables can be declared, and only to individual variables within a multi-variable declaration, as opposed to adorning a let statement or whatnot. I don't have any good examples, though, since out of GCC's variable attributes, I didn't notice any that weren't either (a) only applicable to statics (e.g. 'section'), (b) better expressed as part of the type (e.g. alignment), or (c) otherwise already handled by Rust ('unused').
<|endoftext|>@comex
> ...otherwise already handled by Rust ('unused')
FWIW, I am occassionally annoyed at my inability to label unused things with more precision (e.g., an individual binding). I can't come up with any good examples just now though. =)
<|endoftext|>@nrc
> Concretely, a large part of the weirdness to me comes from precedence difficulties. There is basically no 'good' precedence - e.g., #[foo] a + b, I feel like there is no reason to apply it to the whole expression or the sub-expression. There is no intuition for which expression the attribute should apply to.
To address precedence concerns, one could also imagine limiting the attribute to parenthesized expressions (I think we talked about this at one point?). e.g., `#[foo] (a+b)`. Or even `(#![foo] a + b)`.
> This works in practice because of the way the list node is defined in the AST. I.e., the feature is kind of weird in that it is applying not just to an expression node in the AST, but also some decoration, depending on the exact implementation of the parent AST node.
That is weird, but also cool. =) The feature applies at the AST level, basically, where things like `,` are not really present at all. It's worth thinking though if this will cause difficulties as we move towards macros 2.0 etc... I guess not, since this is all done post-parsing, right?
<|endoftext|>I recently ran into a similar situation that made me want attributes on _more_ places, not less. In particular, I have a field:
``` rust
struct DepGraph {
...
forbidden: RefCell<Vec<...>>
}
```
but this field is only used for some debugging code:
``` rust
impl DepGraph {
...
fn foo() {
debug_assert!(self.forbidden.blah);
}
}
```
Because of our tight lints, this can result in the field `forbidden` being considered "dead code", I believe. It'd be nice to make the forbidden field `#[cfg(debug_assertions)]`, but that is annoying because of the constructor:
``` rust
pub fn new(enabled: bool) -> DepGraph {
DepGraph {
data: Rc::new(DepGraphData {
thread: DepGraphThreadData::new(enabled),
previous_work_products: RefCell::new(FnvHashMap()),
work_products: RefCell::new(FnvHashMap()),
#[cfg(debug_assertions)] // what I want to write, but can't
forbidden: RefCell::new(Vec::new()),
})
}
}
```
This seems analogous to the `vec!` situation.
<|endoftext|>An use case for attributes on (at least block) expressions is to [supply compiler with branch likeliness metadata](https://github.com/rust-lang/rust/pull/36181#issuecomment-244369720).
<|endoftext|>I could imagine allowing attributes on blocks, perhaps only inner attributes.
<|endoftext|>Would it be possible to include something like “attribute scopes”, where we have a block to which the attribute is applied, but which is distinct from a scope? Right now, if I wanted to, say, declare several variables inside a scope they would be destroyed at the end of the scope. On the other hand, writing the attribute for every single variable is a bit excessive... Compare:
``` rust
#[cfg(debug_assertions)] let foo_1 = 1;
#[cfg(debug_assertions)] let foo_2 = 2;
#[cfg(debug_assertions)] let foo_3 = 3;
```
My proposal:
``` rust
#[cfg(debug_assertions)]
[
let foo_1 = 1;
let foo_2 = 2;
let foo_3 = 3;
]
```
Classical scopes don't work:
``` rust
#[cfg(debug_assertions)]
{
let foo_1 = 1;
let foo_2 = 2;
let foo_3 = 3;
} // all variables get destroyed here
```
<|endoftext|>I think statement attributes should be stabilized, but I also want to clarify their relationship with lints. Currently `#[allow(...)] stmt;` [doesn't seem to do anything](https://github.com/rust-lang/rust/issues/30326), e.g. the following seems reasonable:
``` rust
#[allow(unused_must_use)] something_that_returns_a_result();
```
but you [still get a warning](https://is.gd/ajLjW6). Is this feasible to fix? If not, we'll be in a confusing situation where some statement attributes silently do nothing.
<|endoftext|>@durka I think this is "just a bug". We should file an issue. I would expect the lint to be scoped to the statement.
<|endoftext|>Though @durka's comment is interesting, in that it has bearing on the precedence of attributes on arbitrary expressions. Consider `#[allow(foo)] a + b;` --- does that apply to just `a`, or the entire statement (`a + b`)? Presumably this commits us to either limiting expression attributes to be within parens `(#![foo] foo)` or else giving them a very low priority. I'm ok with either of those. =)
<|endoftext|>Looks like FCP on this is over? It doesn't seem to have been stabilized yet. We're getting stuck on this in Servo where a macro is generating a large volume of warnings and we can't silence them easily. (https://github.com/servo/servo/pull/13435)
<|endoftext|>I'd like to (informally) propose that as a next step we stabilise attributes on block expressions, and deprecate attributes on other expressions. Thoughts?
<|endoftext|>Seems unnecessarily piecemeal. Why don't we want attributes on all arbitrary expressions?
| A-grammar<|endoftext|>T-lang<|endoftext|>B-unstable<|endoftext|>B-RFC-implemented<|endoftext|>C-tracking-issue<|endoftext|>S-tracking-design-concerns<|endoftext|>S-tracking-needs-summary | 111 | https://api.github.com/repos/rust-lang/rust/issues/15701 | https://github.com/rust-lang/rust/issues/15701 | https://api.github.com/repos/rust-lang/rust/issues/15701/comments |