

update readme and plots
Browse files- README.md +104 -113
- train_loss.png +0 -0
- val_jaccard_index.png +0 -0
- val_loss.png +0 -0
- val_multiclassaccuracy_tree.png +0 -0
- val_multiclassf1score_tree.png +0 -0
README.md
CHANGED
|
@@ -1,199 +1,190 @@
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
| 3 |
-
tags:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
---
|
| 5 |
|
| 6 |
-
# Model Card for
|
| 7 |
|
| 8 |
-
|
| 9 |
|
|
|
|
| 10 |
|
|
|
|
| 11 |
|
| 12 |
## Model Details
|
| 13 |
|
| 14 |
### Model Description
|
| 15 |
|
| 16 |
-
|
| 17 |
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
|
| 20 |
-
|
| 21 |
-
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
-
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
-
- **Model type:** [More Information Needed]
|
| 24 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
-
- **License:** [More Information Needed]
|
| 26 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
|
| 28 |
-
### Model Sources
|
| 29 |
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
- **Repository:** [More Information Needed]
|
| 33 |
-
- **Paper [optional]:** [More Information Needed]
|
| 34 |
-
- **Demo [optional]:** [More Information Needed]
|
| 35 |
|
| 36 |
## Uses
|
| 37 |
|
| 38 |
-
|
| 39 |
|
| 40 |
### Direct Use
|
| 41 |
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
[More Information Needed]
|
| 45 |
|
| 46 |
-
|
| 47 |
|
| 48 |
-
|
| 49 |
|
| 50 |
-
|
| 51 |
|
| 52 |
-
|
| 53 |
|
| 54 |
-
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
## Bias, Risks, and Limitations
|
| 59 |
|
| 60 |
-
|
| 61 |
|
| 62 |
-
|
| 63 |
|
| 64 |
-
|
| 65 |
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
|
| 70 |
## How to Get Started with the Model
|
| 71 |
|
| 72 |
-
|
| 73 |
|
| 74 |
-
[
|
| 75 |
|
| 76 |
## Training Details
|
| 77 |
|
| 78 |
### Training Data
|
| 79 |
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
[More Information Needed]
|
| 83 |
|
| 84 |
### Training Procedure
|
| 85 |
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
#### Preprocessing [optional]
|
| 89 |
-
|
| 90 |
-
[More Information Needed]
|
| 91 |
|
|
|
|
| 92 |
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
|
| 97 |
-
|
|
|
|
|
|
|
| 98 |
|
| 99 |
-
|
| 100 |
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
## Evaluation
|
| 104 |
|
| 105 |
-
|
| 106 |
|
| 107 |
-
|
|
|
|
|
|
|
|
|
|
| 108 |
|
| 109 |
-
|
| 110 |
|
| 111 |
-
|
| 112 |
|
| 113 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 114 |
|
| 115 |
-
####
|
| 116 |
|
| 117 |
-
|
| 118 |
|
| 119 |
-
|
| 120 |
|
| 121 |
-
|
| 122 |
|
| 123 |
-
|
| 124 |
|
| 125 |
-
|
| 126 |
|
| 127 |
-
###
|
| 128 |
|
| 129 |
-
|
| 130 |
|
| 131 |
-
|
| 132 |
|
|
|
|
| 133 |
|
|
|
|
| 134 |
|
| 135 |
-
|
| 136 |
|
| 137 |
-
|
| 138 |
|
| 139 |
-
[
|
|
|
|
|
|
|
|
|
|
| 140 |
|
| 141 |
## Environmental Impact
|
| 142 |
|
| 143 |
-
|
| 144 |
|
| 145 |
-
|
|
|
|
|
|
|
| 146 |
|
| 147 |
-
|
| 148 |
-
- **Hours used:** [More Information Needed]
|
| 149 |
-
- **Cloud Provider:** [More Information Needed]
|
| 150 |
-
- **Compute Region:** [More Information Needed]
|
| 151 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
|
| 153 |
-
|
| 154 |
|
| 155 |
-
|
| 156 |
|
| 157 |
-
|
| 158 |
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
[More Information Needed]
|
| 162 |
-
|
| 163 |
-
#### Hardware
|
| 164 |
-
|
| 165 |
-
[More Information Needed]
|
| 166 |
-
|
| 167 |
-
#### Software
|
| 168 |
-
|
| 169 |
-
[More Information Needed]
|
| 170 |
-
|
| 171 |
-
## Citation [optional]
|
| 172 |
-
|
| 173 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 174 |
|
| 175 |
**BibTeX:**
|
| 176 |
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
[More Information Needed]
|
| 188 |
-
|
| 189 |
-
## More Information [optional]
|
| 190 |
-
|
| 191 |
-
[More Information Needed]
|
| 192 |
-
|
| 193 |
-
## Model Card Authors [optional]
|
| 194 |
|
| 195 |
-
|
|
|
|
| 196 |
|
| 197 |
## Model Card Contact
|
| 198 |
|
| 199 |
-
[
|
|
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
| 3 |
+
tags:
|
| 4 |
+
- semantic-segmentation
|
| 5 |
+
- vision
|
| 6 |
+
- ecology
|
| 7 |
+
datasets:
|
| 8 |
+
- restor/tcd
|
| 9 |
+
pipeline_tag: image-segmentation
|
| 10 |
+
widget:
|
| 11 |
+
- src: samples/610160855a90f10006fd303e_10_00418.tif
|
| 12 |
+
example_title: Urban scene
|
| 13 |
+
license: cc
|
| 14 |
+
metrics:
|
| 15 |
+
- accuracy
|
| 16 |
+
- f1
|
| 17 |
+
- iou
|
| 18 |
---
|
| 19 |
|
| 20 |
+
# Model Card for Restor's SegFormer-based TCD models
|
| 21 |
|
| 22 |
+
This is a semantic segmentation model that can delineate tree cover in high resolution (10 cm/px) aerial images.
|
| 23 |
|
| 24 |
+
This model card is mostly the same for all similar models uploaded to Hugging Face. The model name refers to the specific architecture variant (e.g. nvidia-mit-b0 to nvidia-mit-b5) but the broad details for training and evaluation are identical.
|
| 25 |
|
| 26 |
+
This repository is for `tcd-segformer-mit-b5`
|
| 27 |
|
| 28 |
## Model Details
|
| 29 |
|
| 30 |
### Model Description
|
| 31 |
|
| 32 |
+
This semantic segmentation model was trained on global aerial imagery and is able to accurately delineate tree cover in similar images. The model does not detect individual trees, but provides a per-pixel classification of tree/no-tree.
|
| 33 |
|
| 34 |
+
- **Developed by:** [Restor](https://restor.eco) / [ETH Zurich](https://ethz.ch)
|
| 35 |
+
- **Funded by:** This project was made possible via a (Google.org impact grant)[https://blog.google/outreach-initiatives/sustainability/restor-helps-anyone-be-part-ecological-restoration/]
|
| 36 |
+
- **Model type:** Semantic segmentation (binary class)
|
| 37 |
+
- **License:** Model training code is provided under an Apache-2 license. NVIDIA has released SegFormer under their own research license. Users should check the terms of this license before deploying. This model was trained on CC BY-NC imagery.
|
| 38 |
+
- **Finetuned from model:** SegFormer family
|
| 39 |
|
| 40 |
+
SegFormer is a variant of the Pyramid Vision Transformer v2 model, with many identical structural features and a semantic segmentation decode head. Functionally, the architecture is quite similar to a Feature Pyramid Network (FPN) as the output predictions are based on combining features from different stages of the network at different spatial resolutions.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
|
| 42 |
+
### Model Sources
|
| 43 |
|
| 44 |
+
- **Repository:** https://github.com/restor-foundation/tcd
|
| 45 |
+
- **Paper:** We will release a preprint shortly.
|
|
|
|
|
|
|
|
|
|
| 46 |
|
| 47 |
## Uses
|
| 48 |
|
| 49 |
+
The primary use-case for this model is asessing canopy cover from aerial images (i.e. percentage of study area that is covered by tree canopy).
|
| 50 |
|
| 51 |
### Direct Use
|
| 52 |
|
| 53 |
+
This model is suitable for inference on a single image tile. For performing predictions on large orthomosaics, a higher level framework is required to manage tiling source imagery and stitching predictions. Our repository provides a comprehensive reference implementation of such a pipeline and has been tested on extremely large images (country-scale).
|
|
|
|
|
|
|
| 54 |
|
| 55 |
+
The model will give you predictions for an entire image. In most cases users will want to predict cover for a specific region of the image, for example a study plot or some other geographic boundary. If you predict tree cover in an image you should perform some kind of region-of-interest analysis on the results. Our linked pipeline repository supports shapefile-based region analysis.
|
| 56 |
|
| 57 |
+
### Out-of-Scope Use
|
| 58 |
|
| 59 |
+
While we trained the model on globally diverse imagery, some ecological biomes are under-represented in the training dataset and performance may vary. We therefore encourage users to experiment with their own imagery before using the model for any sort of mission-critical use.
|
| 60 |
|
| 61 |
+
The model was trained on imagery at a resolution of 10 cm/px. You may be able to get good predictions at other geospatial resolutions, but the results may not be reliable. In particular the model is essentially looking for "things that look like trees" and this is highly resolution dependent. If you want to routinely predict images at a higher or lower resolution, you should fine-tune this model on your own or a resampled version of the training dataset.
|
| 62 |
|
| 63 |
+
The model does not predict biomass, canopy height or other derived information. It only predicts the likelihood that some pixel is covered by tree canopy.
|
| 64 |
|
| 65 |
+
As-is, the model is not suitable for carbon credit estimation.
|
| 66 |
|
| 67 |
## Bias, Risks, and Limitations
|
| 68 |
|
| 69 |
+
The main limitation of this model is false positives over objects that look like, or could be confused as, trees. For example large bushes, shrubs or ground cover that looks like tree canopy.
|
| 70 |
|
| 71 |
+
The dataset used to train this model was annotated by non-experts. We believe that this is a reasonable trade-off given the size of the dataset and the results on independent test data, as well as empirical evaluation during operational use at Restor on partner data. However, there are almost certainly incorrect labels in the dataset and this may translate into incorrect predictions or other biases in model output. We have observed that the models tend to "disagree" with training data in a way that is probably correct (i.e. the aggregate statistics of the labels are good) and we are working to re-evaluate all training data to remove spurious labels.
|
| 72 |
|
| 73 |
+
We provide cross-validation results to give a robust estimate of prediction performance, as well as results on independent imagery (i.e. images the model has never seen) so users can make their own assessments. We do not provide any guarantees on accuracy and users should perform their own independent testing for any kind of "mission critical" or production use.
|
| 74 |
|
| 75 |
+
There is no substitute for trying the model on your own data and performing your own evaluation; we strongly encourage experimentation!
|
|
|
|
|
|
|
| 76 |
|
| 77 |
## How to Get Started with the Model
|
| 78 |
|
| 79 |
+
You can see a brief example of inference in [this Colab notebook](https://colab.research.google.com/drive/1N_rWko6jzGji3j_ayDR7ngT5lf4P8at_).
|
| 80 |
|
| 81 |
+
For end-to-end usage, we direct users to our prediction and training [pipeline](https://github.com/restor-foundation/tcd) which also supports tiled prediction over arbitrarily large images, reporting outputs, etc.
|
| 82 |
|
| 83 |
## Training Details
|
| 84 |
|
| 85 |
### Training Data
|
| 86 |
|
| 87 |
+
The training dataset may be found [here](https://huggingface.co/datasets/restor/tcd), where you can find more details about the collection and annotation procedure. Our image labels are largely released under a CC-BY 4.0 license, with smaller subsets of CC BY-NC and CC BY-SA imagery.
|
|
|
|
|
|
|
| 88 |
|
| 89 |
### Training Procedure
|
| 90 |
|
| 91 |
+
We used a 5-fold cross-validation process to adjust hyperparameters during training, before training on the "full" training set and evaluating on a holdout set of images. The model in the main branch of this repository should be considered the release version.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 92 |
|
| 93 |
+
We used [Pytorch Lightning](https://lightning.ai/) as our training framework with hyperparameters listed below. The training procedure is straightforward and should be familiar to anyone with experience training deep neural networks.
|
| 94 |
|
| 95 |
+
A typical training command using our pipeline for this model:
|
|
|
|
|
|
|
| 96 |
|
| 97 |
+
```bash
|
| 98 |
+
tcd-train semantic segformer-mit-b5 data.output= ... data.root=/mnt/data/tcd/dataset/holdout data.tile_size=1024
|
| 99 |
+
```
|
| 100 |
|
| 101 |
+
#### Preprocessing
|
| 102 |
|
| 103 |
+
This repository contains a pre-processor configuration that can be used with the model, assuming you use the `transformers` library.
|
|
|
|
|
|
|
| 104 |
|
| 105 |
+
You can load this preprocessor easily by using e.g.
|
| 106 |
|
| 107 |
+
```python
|
| 108 |
+
from transformers import AutoImageProcessor
|
| 109 |
+
processor = AutoImageProcessor.from_pretrained('restor/tcd-segformer-mit-b5')
|
| 110 |
+
```
|
| 111 |
|
| 112 |
+
Note that we do not resize input images (so that the geospatial scale of the source image is respected) and we assume that normalisation is performed in this processing step and not as a dataset transform.
|
| 113 |
|
| 114 |
+
#### Training Hyperparameters
|
| 115 |
|
| 116 |
+
- Image size: 1024 px square
|
| 117 |
+
- Learning rate: initially 1e4-1e5
|
| 118 |
+
- Learning rate schedule: reduce on plateau
|
| 119 |
+
- Optimizer: AdamW
|
| 120 |
+
- Augmentation: random crop to 1024x1024, arbitrary rotation, flips, colour adjustments
|
| 121 |
+
- Number of epochs: 75 during cross-validation to ensure convergence; 50 for final models
|
| 122 |
+
- Normalisation: Imagenet statistics
|
| 123 |
|
| 124 |
+
#### Speeds, Sizes, Times
|
| 125 |
|
| 126 |
+
You should be able to evaluate the model on a CPU (even up to mit-b5) however you will need a lot of available RAM if you try to infer large tile sizes. In general we find that 1024 px inputs are as large as you want to go, given the fixed size of the output segmentation masks (i.e. it is probably better to perform inference in batched mode at 1024x1024 px than try to predict a single 2048x2048 px image).
|
| 127 |
|
| 128 |
+
All models were trained on a single GPU with 24 GB VRAM (NVIDIA RTX3090) attached to a 32-core machine with 64GB RAM. All but the largest models can be trained in under a day on a machine of this specification. The smallest models take under half a day, while the largest models take just over a day to train.
|
| 129 |
|
| 130 |
+
Feedback we've received from users (in the field) is that landowners are often interested in seeing the results of aerial surveys, but data bandwidth is often a prohibiting factor in remote areas. One of our goals was to support this kind of in-field usage, so that users who fly a survey can process results offline and in a reasonable amount of time (i.e. on the order of an hour).
|
| 131 |
|
| 132 |
+
## Evaluation
|
| 133 |
|
| 134 |
+
We report evaluation results on the OAM-TCD holdout split.
|
| 135 |
|
| 136 |
+
### Testing Data
|
| 137 |
|
| 138 |
+
The training dataset may be found [here](https://huggingface.co/datasets/restor/tcd).
|
| 139 |
|
| 140 |
+
This model (`main` branch) was trained on all `train` images and tested on the `test` (holdout) images.
|
| 141 |
|
| 142 |
+

|
| 143 |
|
| 144 |
+
### Metrics
|
| 145 |
|
| 146 |
+
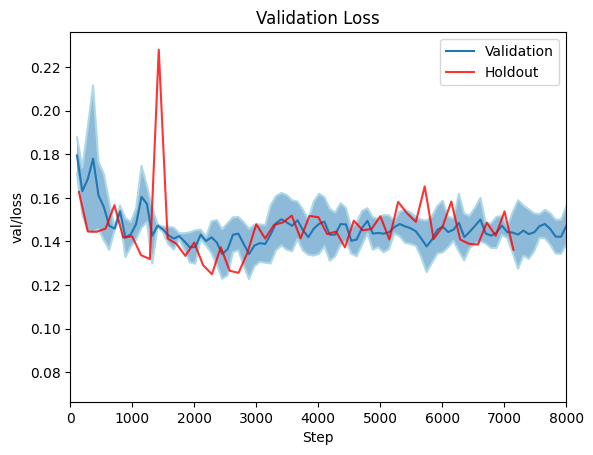
We report F1, Accuracy and IoU on the holdout dataset, as well as results on a 5-fold cross validation split. Cross validtion is visualised as min/max error bars on the plots below.
|
| 147 |
|
| 148 |
+
### Results
|
| 149 |
|
| 150 |
+

|
| 151 |
+

|
| 152 |
+

|
| 153 |
+

|
| 154 |
|
| 155 |
## Environmental Impact
|
| 156 |
|
| 157 |
+
This estimate is the maximum (in terms of training time) for the SegFormer family of models presented here. Smaller models, such as `mit-b0` train in less than half a day.
|
| 158 |
|
| 159 |
+
- **Hardware Type:** NVIDIA RTX3090
|
| 160 |
+
- **Hours used:** < 36
|
| 161 |
+
- **Carbon Emitted:** 5.44 kg CO2 equivalent per model
|
| 162 |
|
| 163 |
+
Carbon emissions were be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
|
|
|
|
|
|
|
|
|
|
|
|
| 164 |
|
| 165 |
+
This estimate does not take into account time require for experimentation, failed training runs, etc. For example since we used cross-validation, each model actually required approximately 6x this estimate - one run for each fold, plus the final run.
|
| 166 |
|
| 167 |
+
Efficient inference on CPU is possible for field work, at the expense of inference latency. A typical single-battery drone flight can be processed in minutes.
|
| 168 |
|
| 169 |
+
## Citation
|
| 170 |
|
| 171 |
+
We will provide a preprint version of our paper shortly. In the mean time, please cite as:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
**BibTeX:**
|
| 174 |
|
| 175 |
+
```latex
|
| 176 |
+
@unpublished{restortcd,
|
| 177 |
+
author = "Veitch-Michaelis, Josh and Cottam, Andrew and Schweizer, Daniella Schweizer and Broadbent, Eben N. and Dao, David and Zhang, Ce and Almeyda Zambrano, Angelica and Max, Simeon",
|
| 178 |
+
title = "OAM-TCD: A globally diverse dataset of high-resolution tree cover maps",
|
| 179 |
+
note = "In prep.",
|
| 180 |
+
month = "06",
|
| 181 |
+
year = "2024"
|
| 182 |
+
}
|
| 183 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 184 |
|
| 185 |
+
## Model Card Authors
|
| 186 |
+
Josh Veitch-Michaelis, 2024; on behalf of the dataset authors.
|
| 187 |
|
| 188 |
## Model Card Contact
|
| 189 |
|
| 190 |
+
Please contact josh [at] restor.eco for questions or further information.
|
train_loss.png
ADDED

|
val_jaccard_index.png
ADDED

|
val_loss.png
ADDED
|
val_multiclassaccuracy_tree.png
ADDED

|
val_multiclassf1score_tree.png
ADDED

|