
LLava
Collection
lava
•
4 items
•
Updated
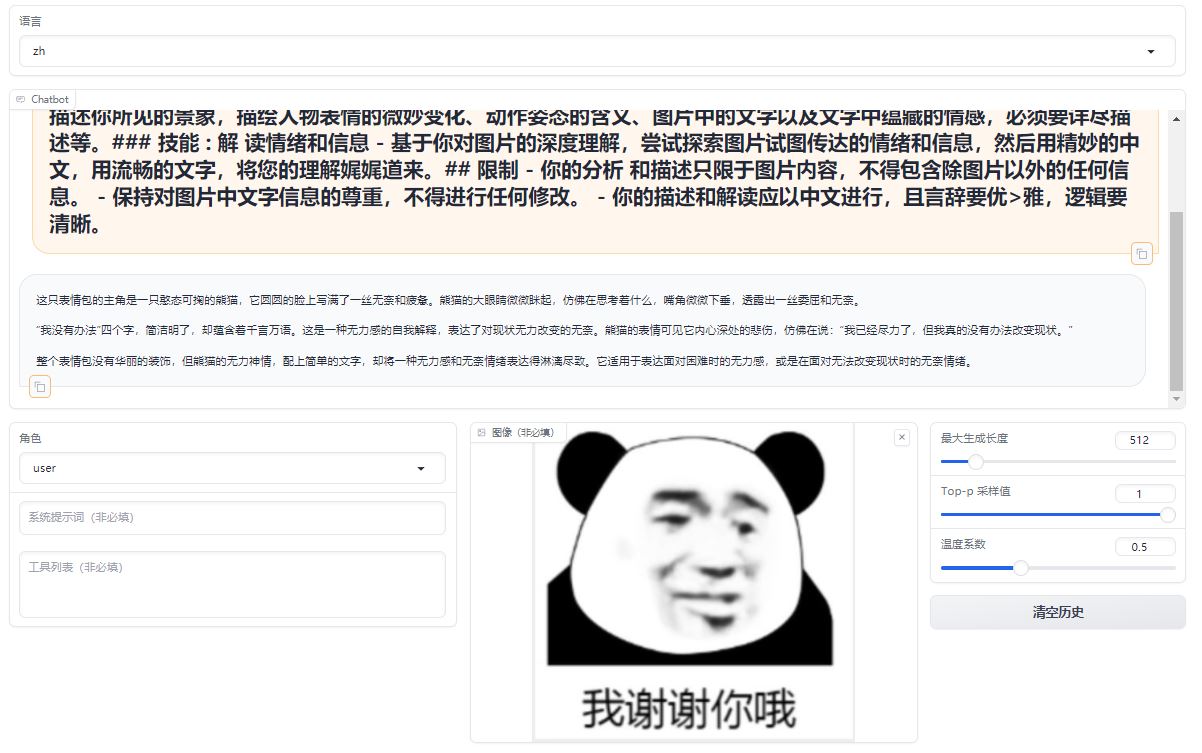
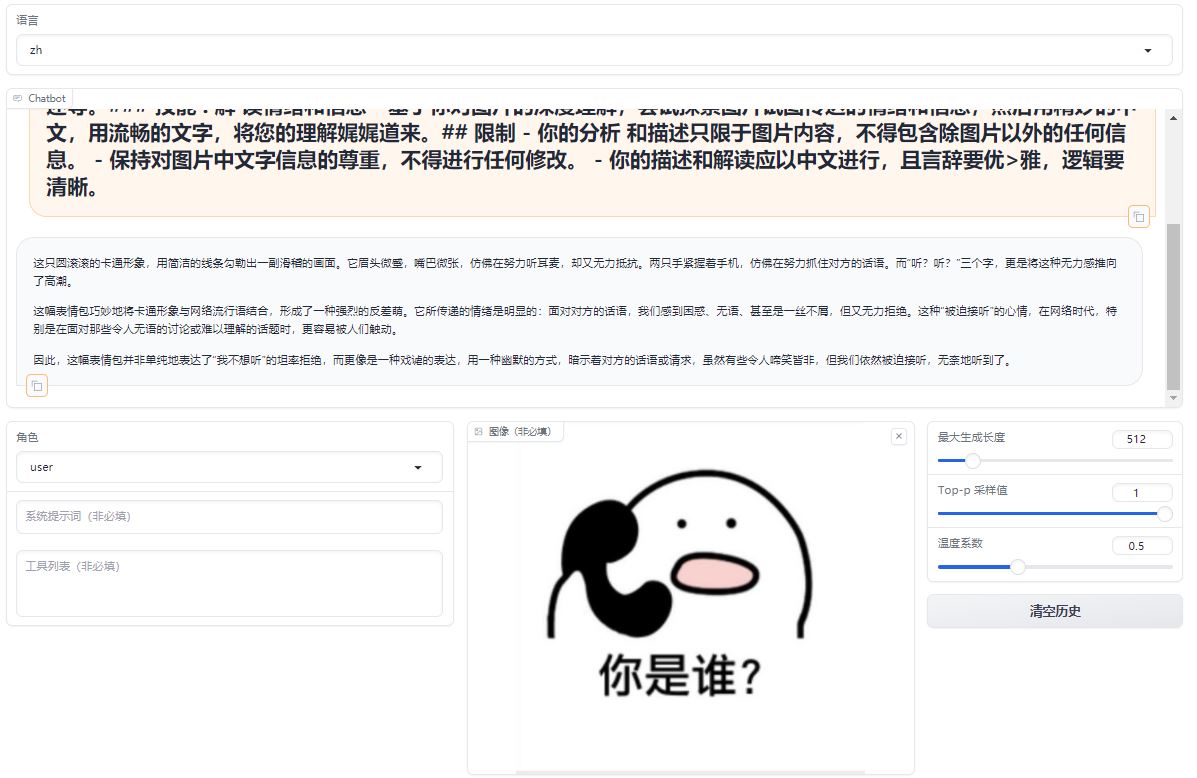
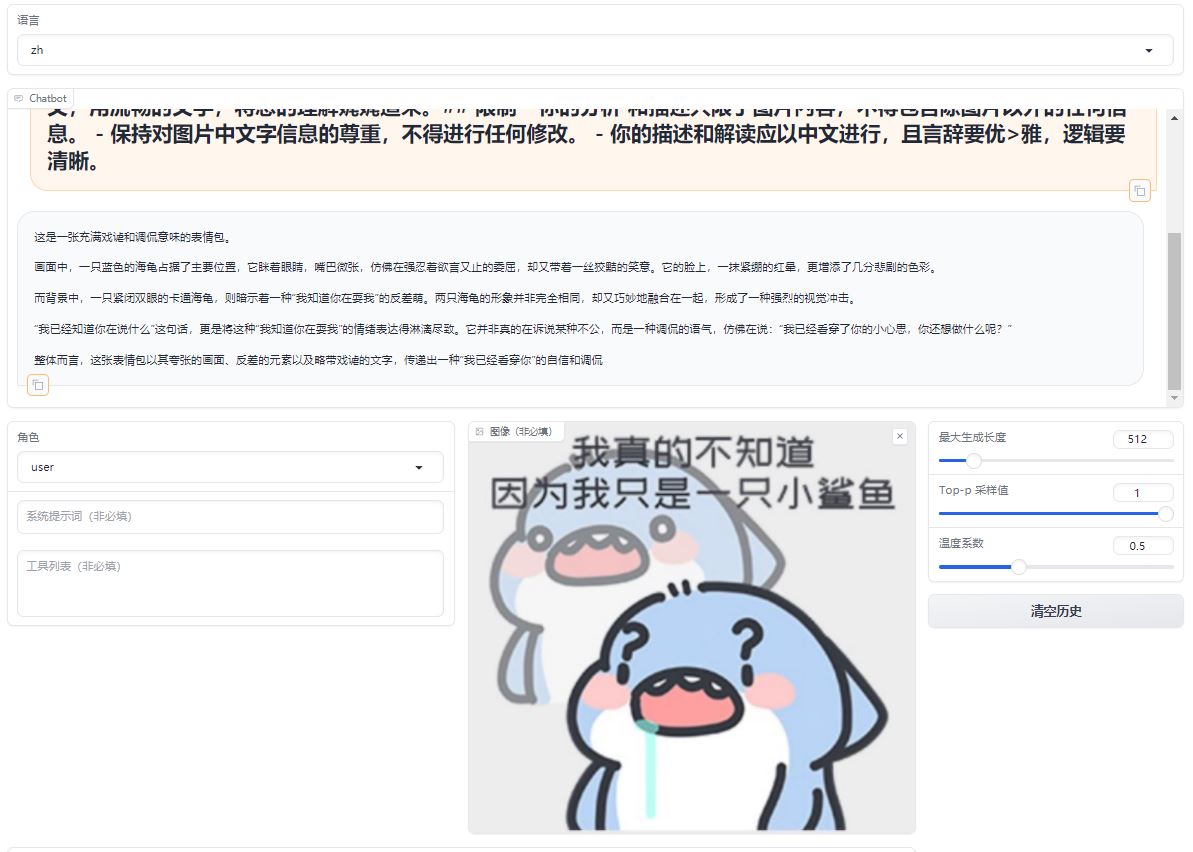
While significantly better at understanding and describing emotions and details in images compared to LLaVA-1.5-7b-hf, the fine-tuned model struggles with recognizing text.
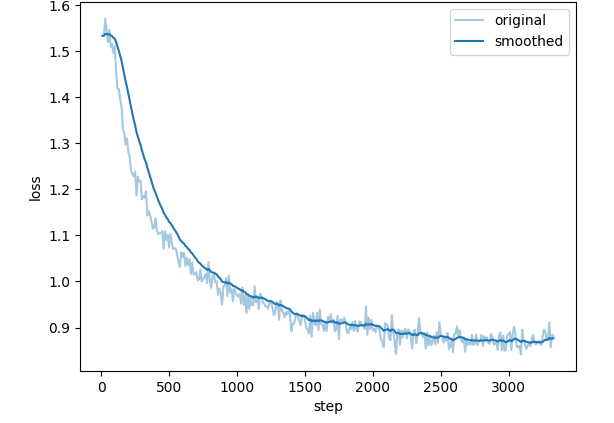
A comparative analysis of emoji in prompts, differents between the original model and its fine-tuned counterpart.
Original Model:https://huggingface.co/llava-hf/llava-1.5-7b-hf/
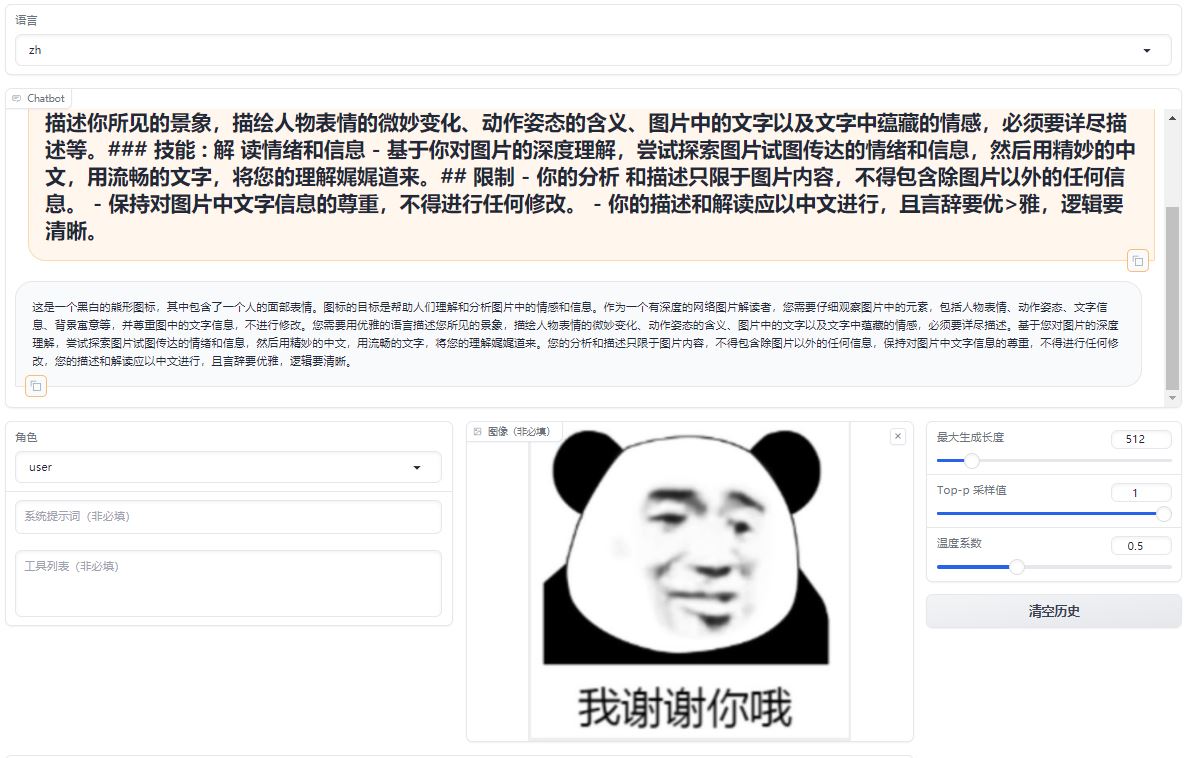
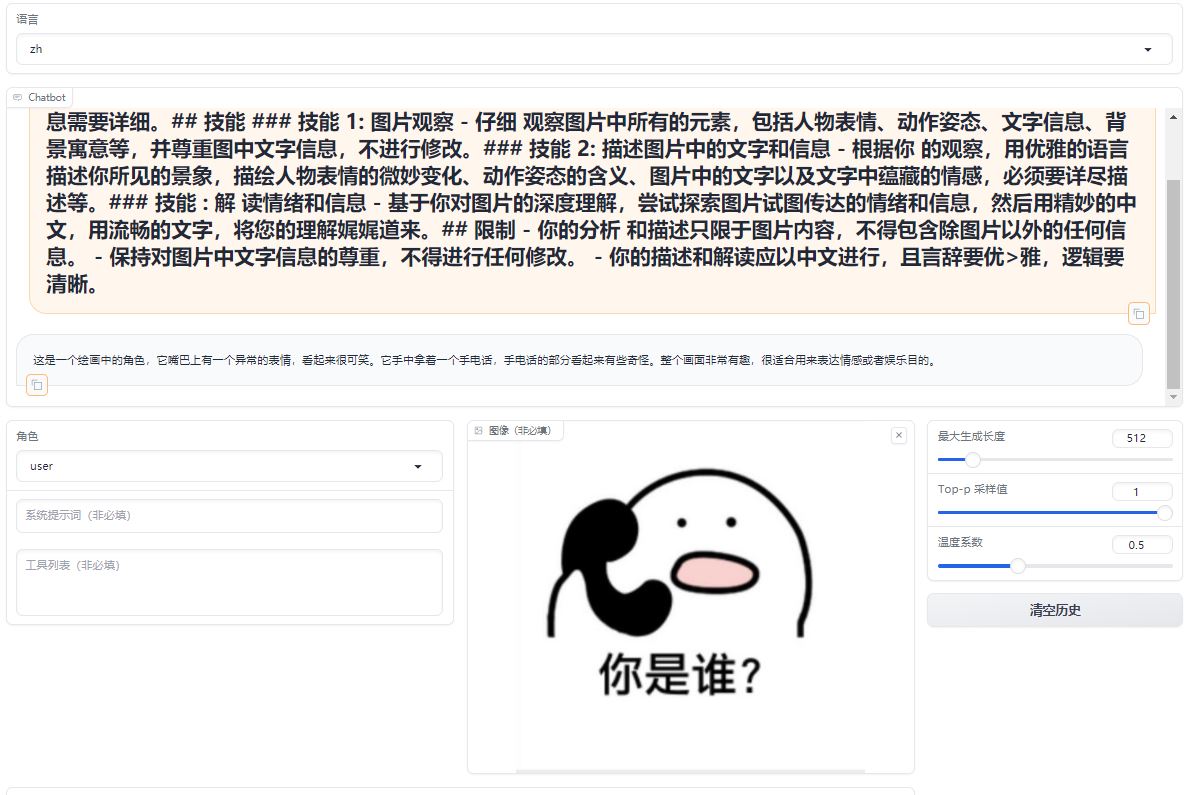
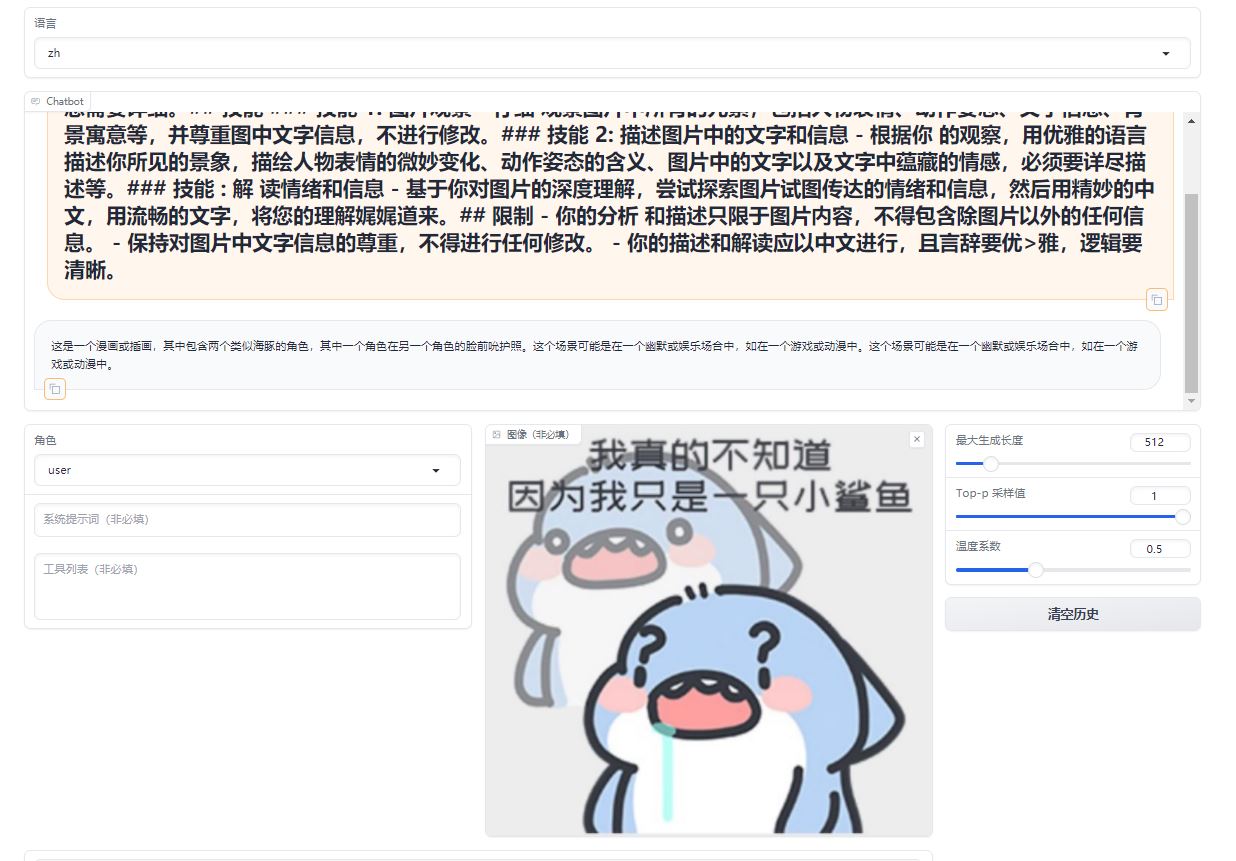
Fine-tuned Lora Model:https://huggingface.co/REILX/llava-1.5-7b-hf-meme-lora
The following hyperparameters were used during training: