
instance_id
stringlengths 13
37
| text
stringlengths 3.08k
667k
| repo
stringclasses 35
values | base_commit
stringlengths 40
40
| problem_statement
stringlengths 10
256k
| hints_text
stringlengths 0
908k
| created_at
stringlengths 20
20
| patch
stringlengths 18
101M
| test_patch
stringclasses 1
value | version
stringclasses 1
value | FAIL_TO_PASS
stringclasses 1
value | PASS_TO_PASS
stringclasses 1
value | environment_setup_commit
stringclasses 1
value |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
ipython__ipython-7819 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inspect requests inside a function call should be smarter about what they inspect.
Previously, `func(a, b, <shift-tab>` would give information on `func`, now it gives information on `b`, which is not especially helpful.
This is because we removed logic from the frontend to make it more language agnostic, and we have not yet reimplemented that on the frontend. For 3.1, we should make it at least as smart as 2.x was. The quicky and dirty approach would be a regex; the proper way is tokenising the code.
Ping @mwaskom who brought this up on the mailing list.
</issue>
<code>
[start of README.rst]
1 .. image:: https://img.shields.io/coveralls/ipython/ipython.svg
2 :target: https://coveralls.io/r/ipython/ipython?branch=master
3
4 .. image:: https://img.shields.io/pypi/dm/IPython.svg
5 :target: https://pypi.python.org/pypi/ipython
6
7 .. image:: https://img.shields.io/pypi/v/IPython.svg
8 :target: https://pypi.python.org/pypi/ipython
9
10 .. image:: https://img.shields.io/travis/ipython/ipython.svg
11 :target: https://travis-ci.org/ipython/ipython
12
13
14 ===========================================
15 IPython: Productive Interactive Computing
16 ===========================================
17
18 Overview
19 ========
20
21 Welcome to IPython. Our full documentation is available on `our website
22 <http://ipython.org/documentation.html>`_; if you downloaded a built source
23 distribution the ``docs/source`` directory contains the plaintext version of
24 these manuals. If you have Sphinx installed, you can build them by typing
25 ``cd docs; make html`` for local browsing.
26
27
28 Dependencies and supported Python versions
29 ==========================================
30
31 For full details, see the installation section of the manual. The basic parts
32 of IPython only need the Python standard library, but much of its more advanced
33 functionality requires extra packages.
34
35 Officially, IPython requires Python version 2.7, or 3.3 and above.
36 IPython 1.x is the last IPython version to support Python 2.6 and 3.2.
37
38
39 Instant running
40 ===============
41
42 You can run IPython from this directory without even installing it system-wide
43 by typing at the terminal::
44
45 $ python -m IPython
46
47
48 Development installation
49 ========================
50
51 If you want to hack on certain parts, e.g. the IPython notebook, in a clean
52 environment (such as a virtualenv) you can use ``pip`` to grab the necessary
53 dependencies quickly::
54
55 $ git clone --recursive https://github.com/ipython/ipython.git
56 $ cd ipython
57 $ pip install -e ".[notebook]" --user
58
59 This installs the necessary packages and symlinks IPython into your current
60 environment so that you can work on your local repo copy and run it from anywhere::
61
62 $ ipython notebook
63
64 The same process applies for other parts, such as the qtconsole (the
65 ``extras_require`` attribute in the setup.py file lists all the possibilities).
66
67 Git Hooks and Submodules
68 ************************
69
70 IPython now uses git submodules to ship its javascript dependencies.
71 If you run IPython from git master, you may need to update submodules once in a while with::
72
73 $ git submodule update
74
75 or::
76
77 $ python setup.py submodule
78
79 We have some git hooks for helping keep your submodules always in sync,
80 see our ``git-hooks`` directory for more info.
81
[end of README.rst]
[start of IPython/core/completerlib.py]
1 # encoding: utf-8
2 """Implementations for various useful completers.
3
4 These are all loaded by default by IPython.
5 """
6 #-----------------------------------------------------------------------------
7 # Copyright (C) 2010-2011 The IPython Development Team.
8 #
9 # Distributed under the terms of the BSD License.
10 #
11 # The full license is in the file COPYING.txt, distributed with this software.
12 #-----------------------------------------------------------------------------
13
14 #-----------------------------------------------------------------------------
15 # Imports
16 #-----------------------------------------------------------------------------
17 from __future__ import print_function
18
19 # Stdlib imports
20 import glob
21 import inspect
22 import os
23 import re
24 import sys
25
26 try:
27 # Python >= 3.3
28 from importlib.machinery import all_suffixes
29 _suffixes = all_suffixes()
30 except ImportError:
31 from imp import get_suffixes
32 _suffixes = [ s[0] for s in get_suffixes() ]
33
34 # Third-party imports
35 from time import time
36 from zipimport import zipimporter
37
38 # Our own imports
39 from IPython.core.completer import expand_user, compress_user
40 from IPython.core.error import TryNext
41 from IPython.utils._process_common import arg_split
42 from IPython.utils.py3compat import string_types
43
44 # FIXME: this should be pulled in with the right call via the component system
45 from IPython import get_ipython
46
47 #-----------------------------------------------------------------------------
48 # Globals and constants
49 #-----------------------------------------------------------------------------
50
51 # Time in seconds after which the rootmodules will be stored permanently in the
52 # ipython ip.db database (kept in the user's .ipython dir).
53 TIMEOUT_STORAGE = 2
54
55 # Time in seconds after which we give up
56 TIMEOUT_GIVEUP = 20
57
58 # Regular expression for the python import statement
59 import_re = re.compile(r'(?P<name>[a-zA-Z_][a-zA-Z0-9_]*?)'
60 r'(?P<package>[/\\]__init__)?'
61 r'(?P<suffix>%s)$' %
62 r'|'.join(re.escape(s) for s in _suffixes))
63
64 # RE for the ipython %run command (python + ipython scripts)
65 magic_run_re = re.compile(r'.*(\.ipy|\.ipynb|\.py[w]?)$')
66
67 #-----------------------------------------------------------------------------
68 # Local utilities
69 #-----------------------------------------------------------------------------
70
71 def module_list(path):
72 """
73 Return the list containing the names of the modules available in the given
74 folder.
75 """
76 # sys.path has the cwd as an empty string, but isdir/listdir need it as '.'
77 if path == '':
78 path = '.'
79
80 # A few local constants to be used in loops below
81 pjoin = os.path.join
82
83 if os.path.isdir(path):
84 # Build a list of all files in the directory and all files
85 # in its subdirectories. For performance reasons, do not
86 # recurse more than one level into subdirectories.
87 files = []
88 for root, dirs, nondirs in os.walk(path, followlinks=True):
89 subdir = root[len(path)+1:]
90 if subdir:
91 files.extend(pjoin(subdir, f) for f in nondirs)
92 dirs[:] = [] # Do not recurse into additional subdirectories.
93 else:
94 files.extend(nondirs)
95
96 else:
97 try:
98 files = list(zipimporter(path)._files.keys())
99 except:
100 files = []
101
102 # Build a list of modules which match the import_re regex.
103 modules = []
104 for f in files:
105 m = import_re.match(f)
106 if m:
107 modules.append(m.group('name'))
108 return list(set(modules))
109
110
111 def get_root_modules():
112 """
113 Returns a list containing the names of all the modules available in the
114 folders of the pythonpath.
115
116 ip.db['rootmodules_cache'] maps sys.path entries to list of modules.
117 """
118 ip = get_ipython()
119 rootmodules_cache = ip.db.get('rootmodules_cache', {})
120 rootmodules = list(sys.builtin_module_names)
121 start_time = time()
122 store = False
123 for path in sys.path:
124 try:
125 modules = rootmodules_cache[path]
126 except KeyError:
127 modules = module_list(path)
128 try:
129 modules.remove('__init__')
130 except ValueError:
131 pass
132 if path not in ('', '.'): # cwd modules should not be cached
133 rootmodules_cache[path] = modules
134 if time() - start_time > TIMEOUT_STORAGE and not store:
135 store = True
136 print("\nCaching the list of root modules, please wait!")
137 print("(This will only be done once - type '%rehashx' to "
138 "reset cache!)\n")
139 sys.stdout.flush()
140 if time() - start_time > TIMEOUT_GIVEUP:
141 print("This is taking too long, we give up.\n")
142 return []
143 rootmodules.extend(modules)
144 if store:
145 ip.db['rootmodules_cache'] = rootmodules_cache
146 rootmodules = list(set(rootmodules))
147 return rootmodules
148
149
150 def is_importable(module, attr, only_modules):
151 if only_modules:
152 return inspect.ismodule(getattr(module, attr))
153 else:
154 return not(attr[:2] == '__' and attr[-2:] == '__')
155
156
157 def try_import(mod, only_modules=False):
158 try:
159 m = __import__(mod)
160 except:
161 return []
162 mods = mod.split('.')
163 for module in mods[1:]:
164 m = getattr(m, module)
165
166 m_is_init = hasattr(m, '__file__') and '__init__' in m.__file__
167
168 completions = []
169 if (not hasattr(m, '__file__')) or (not only_modules) or m_is_init:
170 completions.extend( [attr for attr in dir(m) if
171 is_importable(m, attr, only_modules)])
172
173 completions.extend(getattr(m, '__all__', []))
174 if m_is_init:
175 completions.extend(module_list(os.path.dirname(m.__file__)))
176 completions = set(completions)
177 if '__init__' in completions:
178 completions.remove('__init__')
179 return list(completions)
180
181
182 #-----------------------------------------------------------------------------
183 # Completion-related functions.
184 #-----------------------------------------------------------------------------
185
186 def quick_completer(cmd, completions):
187 """ Easily create a trivial completer for a command.
188
189 Takes either a list of completions, or all completions in string (that will
190 be split on whitespace).
191
192 Example::
193
194 [d:\ipython]|1> import ipy_completers
195 [d:\ipython]|2> ipy_completers.quick_completer('foo', ['bar','baz'])
196 [d:\ipython]|3> foo b<TAB>
197 bar baz
198 [d:\ipython]|3> foo ba
199 """
200
201 if isinstance(completions, string_types):
202 completions = completions.split()
203
204 def do_complete(self, event):
205 return completions
206
207 get_ipython().set_hook('complete_command',do_complete, str_key = cmd)
208
209 def module_completion(line):
210 """
211 Returns a list containing the completion possibilities for an import line.
212
213 The line looks like this :
214 'import xml.d'
215 'from xml.dom import'
216 """
217
218 words = line.split(' ')
219 nwords = len(words)
220
221 # from whatever <tab> -> 'import '
222 if nwords == 3 and words[0] == 'from':
223 return ['import ']
224
225 # 'from xy<tab>' or 'import xy<tab>'
226 if nwords < 3 and (words[0] in ['import','from']) :
227 if nwords == 1:
228 return get_root_modules()
229 mod = words[1].split('.')
230 if len(mod) < 2:
231 return get_root_modules()
232 completion_list = try_import('.'.join(mod[:-1]), True)
233 return ['.'.join(mod[:-1] + [el]) for el in completion_list]
234
235 # 'from xyz import abc<tab>'
236 if nwords >= 3 and words[0] == 'from':
237 mod = words[1]
238 return try_import(mod)
239
240 #-----------------------------------------------------------------------------
241 # Completers
242 #-----------------------------------------------------------------------------
243 # These all have the func(self, event) signature to be used as custom
244 # completers
245
246 def module_completer(self,event):
247 """Give completions after user has typed 'import ...' or 'from ...'"""
248
249 # This works in all versions of python. While 2.5 has
250 # pkgutil.walk_packages(), that particular routine is fairly dangerous,
251 # since it imports *EVERYTHING* on sys.path. That is: a) very slow b) full
252 # of possibly problematic side effects.
253 # This search the folders in the sys.path for available modules.
254
255 return module_completion(event.line)
256
257 # FIXME: there's a lot of logic common to the run, cd and builtin file
258 # completers, that is currently reimplemented in each.
259
260 def magic_run_completer(self, event):
261 """Complete files that end in .py or .ipy or .ipynb for the %run command.
262 """
263 comps = arg_split(event.line, strict=False)
264 # relpath should be the current token that we need to complete.
265 if (len(comps) > 1) and (not event.line.endswith(' ')):
266 relpath = comps[-1].strip("'\"")
267 else:
268 relpath = ''
269
270 #print("\nev=", event) # dbg
271 #print("rp=", relpath) # dbg
272 #print('comps=', comps) # dbg
273
274 lglob = glob.glob
275 isdir = os.path.isdir
276 relpath, tilde_expand, tilde_val = expand_user(relpath)
277
278 # Find if the user has already typed the first filename, after which we
279 # should complete on all files, since after the first one other files may
280 # be arguments to the input script.
281
282 if any(magic_run_re.match(c) for c in comps):
283 matches = [f.replace('\\','/') + ('/' if isdir(f) else '')
284 for f in lglob(relpath+'*')]
285 else:
286 dirs = [f.replace('\\','/') + "/" for f in lglob(relpath+'*') if isdir(f)]
287 pys = [f.replace('\\','/')
288 for f in lglob(relpath+'*.py') + lglob(relpath+'*.ipy') +
289 lglob(relpath+'*.ipynb') + lglob(relpath + '*.pyw')]
290
291 matches = dirs + pys
292
293 #print('run comp:', dirs+pys) # dbg
294 return [compress_user(p, tilde_expand, tilde_val) for p in matches]
295
296
297 def cd_completer(self, event):
298 """Completer function for cd, which only returns directories."""
299 ip = get_ipython()
300 relpath = event.symbol
301
302 #print(event) # dbg
303 if event.line.endswith('-b') or ' -b ' in event.line:
304 # return only bookmark completions
305 bkms = self.db.get('bookmarks', None)
306 if bkms:
307 return bkms.keys()
308 else:
309 return []
310
311 if event.symbol == '-':
312 width_dh = str(len(str(len(ip.user_ns['_dh']) + 1)))
313 # jump in directory history by number
314 fmt = '-%0' + width_dh +'d [%s]'
315 ents = [ fmt % (i,s) for i,s in enumerate(ip.user_ns['_dh'])]
316 if len(ents) > 1:
317 return ents
318 return []
319
320 if event.symbol.startswith('--'):
321 return ["--" + os.path.basename(d) for d in ip.user_ns['_dh']]
322
323 # Expand ~ in path and normalize directory separators.
324 relpath, tilde_expand, tilde_val = expand_user(relpath)
325 relpath = relpath.replace('\\','/')
326
327 found = []
328 for d in [f.replace('\\','/') + '/' for f in glob.glob(relpath+'*')
329 if os.path.isdir(f)]:
330 if ' ' in d:
331 # we don't want to deal with any of that, complex code
332 # for this is elsewhere
333 raise TryNext
334
335 found.append(d)
336
337 if not found:
338 if os.path.isdir(relpath):
339 return [compress_user(relpath, tilde_expand, tilde_val)]
340
341 # if no completions so far, try bookmarks
342 bks = self.db.get('bookmarks',{})
343 bkmatches = [s for s in bks if s.startswith(event.symbol)]
344 if bkmatches:
345 return bkmatches
346
347 raise TryNext
348
349 return [compress_user(p, tilde_expand, tilde_val) for p in found]
350
351 def reset_completer(self, event):
352 "A completer for %reset magic"
353 return '-f -s in out array dhist'.split()
354
[end of IPython/core/completerlib.py]
[start of IPython/core/usage.py]
1 # -*- coding: utf-8 -*-
2 """Usage information for the main IPython applications.
3 """
4 #-----------------------------------------------------------------------------
5 # Copyright (C) 2008-2011 The IPython Development Team
6 # Copyright (C) 2001-2007 Fernando Perez. <[email protected]>
7 #
8 # Distributed under the terms of the BSD License. The full license is in
9 # the file COPYING, distributed as part of this software.
10 #-----------------------------------------------------------------------------
11
12 import sys
13 from IPython.core import release
14
15 cl_usage = """\
16 =========
17 IPython
18 =========
19
20 Tools for Interactive Computing in Python
21 =========================================
22
23 A Python shell with automatic history (input and output), dynamic object
24 introspection, easier configuration, command completion, access to the
25 system shell and more. IPython can also be embedded in running programs.
26
27
28 Usage
29
30 ipython [subcommand] [options] [-c cmd | -m mod | file] [--] [arg] ...
31
32 If invoked with no options, it executes the file and exits, passing the
33 remaining arguments to the script, just as if you had specified the same
34 command with python. You may need to specify `--` before args to be passed
35 to the script, to prevent IPython from attempting to parse them. If you
36 specify the option `-i` before the filename, it will enter an interactive
37 IPython session after running the script, rather than exiting. Files ending
38 in .py will be treated as normal Python, but files ending in .ipy can
39 contain special IPython syntax (magic commands, shell expansions, etc.).
40
41 Almost all configuration in IPython is available via the command-line. Do
42 `ipython --help-all` to see all available options. For persistent
43 configuration, look into your `ipython_config.py` configuration file for
44 details.
45
46 This file is typically installed in the `IPYTHONDIR` directory, and there
47 is a separate configuration directory for each profile. The default profile
48 directory will be located in $IPYTHONDIR/profile_default. IPYTHONDIR
49 defaults to to `$HOME/.ipython`. For Windows users, $HOME resolves to
50 C:\\Documents and Settings\\YourUserName in most instances.
51
52 To initialize a profile with the default configuration file, do::
53
54 $> ipython profile create
55
56 and start editing `IPYTHONDIR/profile_default/ipython_config.py`
57
58 In IPython's documentation, we will refer to this directory as
59 `IPYTHONDIR`, you can change its default location by creating an
60 environment variable with this name and setting it to the desired path.
61
62 For more information, see the manual available in HTML and PDF in your
63 installation, or online at http://ipython.org/documentation.html.
64 """
65
66 interactive_usage = """
67 IPython -- An enhanced Interactive Python
68 =========================================
69
70 IPython offers a combination of convenient shell features, special commands
71 and a history mechanism for both input (command history) and output (results
72 caching, similar to Mathematica). It is intended to be a fully compatible
73 replacement for the standard Python interpreter, while offering vastly
74 improved functionality and flexibility.
75
76 At your system command line, type 'ipython -h' to see the command line
77 options available. This document only describes interactive features.
78
79 MAIN FEATURES
80 -------------
81
82 * Access to the standard Python help. As of Python 2.1, a help system is
83 available with access to object docstrings and the Python manuals. Simply
84 type 'help' (no quotes) to access it.
85
86 * Magic commands: type %magic for information on the magic subsystem.
87
88 * System command aliases, via the %alias command or the configuration file(s).
89
90 * Dynamic object information:
91
92 Typing ?word or word? prints detailed information about an object. If
93 certain strings in the object are too long (docstrings, code, etc.) they get
94 snipped in the center for brevity.
95
96 Typing ??word or word?? gives access to the full information without
97 snipping long strings. Long strings are sent to the screen through the less
98 pager if longer than the screen, printed otherwise.
99
100 The ?/?? system gives access to the full source code for any object (if
101 available), shows function prototypes and other useful information.
102
103 If you just want to see an object's docstring, type '%pdoc object' (without
104 quotes, and without % if you have automagic on).
105
106 * Completion in the local namespace, by typing TAB at the prompt.
107
108 At any time, hitting tab will complete any available python commands or
109 variable names, and show you a list of the possible completions if there's
110 no unambiguous one. It will also complete filenames in the current directory.
111
112 This feature requires the readline and rlcomplete modules, so it won't work
113 if your Python lacks readline support (such as under Windows).
114
115 * Search previous command history in two ways (also requires readline):
116
117 - Start typing, and then use Ctrl-p (previous,up) and Ctrl-n (next,down) to
118 search through only the history items that match what you've typed so
119 far. If you use Ctrl-p/Ctrl-n at a blank prompt, they just behave like
120 normal arrow keys.
121
122 - Hit Ctrl-r: opens a search prompt. Begin typing and the system searches
123 your history for lines that match what you've typed so far, completing as
124 much as it can.
125
126 - %hist: search history by index (this does *not* require readline).
127
128 * Persistent command history across sessions.
129
130 * Logging of input with the ability to save and restore a working session.
131
132 * System escape with !. Typing !ls will run 'ls' in the current directory.
133
134 * The reload command does a 'deep' reload of a module: changes made to the
135 module since you imported will actually be available without having to exit.
136
137 * Verbose and colored exception traceback printouts. See the magic xmode and
138 xcolor functions for details (just type %magic).
139
140 * Input caching system:
141
142 IPython offers numbered prompts (In/Out) with input and output caching. All
143 input is saved and can be retrieved as variables (besides the usual arrow
144 key recall).
145
146 The following GLOBAL variables always exist (so don't overwrite them!):
147 _i: stores previous input.
148 _ii: next previous.
149 _iii: next-next previous.
150 _ih : a list of all input _ih[n] is the input from line n.
151
152 Additionally, global variables named _i<n> are dynamically created (<n>
153 being the prompt counter), such that _i<n> == _ih[<n>]
154
155 For example, what you typed at prompt 14 is available as _i14 and _ih[14].
156
157 You can create macros which contain multiple input lines from this history,
158 for later re-execution, with the %macro function.
159
160 The history function %hist allows you to see any part of your input history
161 by printing a range of the _i variables. Note that inputs which contain
162 magic functions (%) appear in the history with a prepended comment. This is
163 because they aren't really valid Python code, so you can't exec them.
164
165 * Output caching system:
166
167 For output that is returned from actions, a system similar to the input
168 cache exists but using _ instead of _i. Only actions that produce a result
169 (NOT assignments, for example) are cached. If you are familiar with
170 Mathematica, IPython's _ variables behave exactly like Mathematica's %
171 variables.
172
173 The following GLOBAL variables always exist (so don't overwrite them!):
174 _ (one underscore): previous output.
175 __ (two underscores): next previous.
176 ___ (three underscores): next-next previous.
177
178 Global variables named _<n> are dynamically created (<n> being the prompt
179 counter), such that the result of output <n> is always available as _<n>.
180
181 Finally, a global dictionary named _oh exists with entries for all lines
182 which generated output.
183
184 * Directory history:
185
186 Your history of visited directories is kept in the global list _dh, and the
187 magic %cd command can be used to go to any entry in that list.
188
189 * Auto-parentheses and auto-quotes (adapted from Nathan Gray's LazyPython)
190
191 1. Auto-parentheses
192
193 Callable objects (i.e. functions, methods, etc) can be invoked like
194 this (notice the commas between the arguments)::
195
196 In [1]: callable_ob arg1, arg2, arg3
197
198 and the input will be translated to this::
199
200 callable_ob(arg1, arg2, arg3)
201
202 This feature is off by default (in rare cases it can produce
203 undesirable side-effects), but you can activate it at the command-line
204 by starting IPython with `--autocall 1`, set it permanently in your
205 configuration file, or turn on at runtime with `%autocall 1`.
206
207 You can force auto-parentheses by using '/' as the first character
208 of a line. For example::
209
210 In [1]: /globals # becomes 'globals()'
211
212 Note that the '/' MUST be the first character on the line! This
213 won't work::
214
215 In [2]: print /globals # syntax error
216
217 In most cases the automatic algorithm should work, so you should
218 rarely need to explicitly invoke /. One notable exception is if you
219 are trying to call a function with a list of tuples as arguments (the
220 parenthesis will confuse IPython)::
221
222 In [1]: zip (1,2,3),(4,5,6) # won't work
223
224 but this will work::
225
226 In [2]: /zip (1,2,3),(4,5,6)
227 ------> zip ((1,2,3),(4,5,6))
228 Out[2]= [(1, 4), (2, 5), (3, 6)]
229
230 IPython tells you that it has altered your command line by
231 displaying the new command line preceded by -->. e.g.::
232
233 In [18]: callable list
234 -------> callable (list)
235
236 2. Auto-Quoting
237
238 You can force auto-quoting of a function's arguments by using ',' as
239 the first character of a line. For example::
240
241 In [1]: ,my_function /home/me # becomes my_function("/home/me")
242
243 If you use ';' instead, the whole argument is quoted as a single
244 string (while ',' splits on whitespace)::
245
246 In [2]: ,my_function a b c # becomes my_function("a","b","c")
247 In [3]: ;my_function a b c # becomes my_function("a b c")
248
249 Note that the ',' MUST be the first character on the line! This
250 won't work::
251
252 In [4]: x = ,my_function /home/me # syntax error
253 """
254
255 interactive_usage_min = """\
256 An enhanced console for Python.
257 Some of its features are:
258 - Readline support if the readline library is present.
259 - Tab completion in the local namespace.
260 - Logging of input, see command-line options.
261 - System shell escape via ! , eg !ls.
262 - Magic commands, starting with a % (like %ls, %pwd, %cd, etc.)
263 - Keeps track of locally defined variables via %who, %whos.
264 - Show object information with a ? eg ?x or x? (use ?? for more info).
265 """
266
267 quick_reference = r"""
268 IPython -- An enhanced Interactive Python - Quick Reference Card
269 ================================================================
270
271 obj?, obj?? : Get help, or more help for object (also works as
272 ?obj, ??obj).
273 ?foo.*abc* : List names in 'foo' containing 'abc' in them.
274 %magic : Information about IPython's 'magic' % functions.
275
276 Magic functions are prefixed by % or %%, and typically take their arguments
277 without parentheses, quotes or even commas for convenience. Line magics take a
278 single % and cell magics are prefixed with two %%.
279
280 Example magic function calls:
281
282 %alias d ls -F : 'd' is now an alias for 'ls -F'
283 alias d ls -F : Works if 'alias' not a python name
284 alist = %alias : Get list of aliases to 'alist'
285 cd /usr/share : Obvious. cd -<tab> to choose from visited dirs.
286 %cd?? : See help AND source for magic %cd
287 %timeit x=10 : time the 'x=10' statement with high precision.
288 %%timeit x=2**100
289 x**100 : time 'x**100' with a setup of 'x=2**100'; setup code is not
290 counted. This is an example of a cell magic.
291
292 System commands:
293
294 !cp a.txt b/ : System command escape, calls os.system()
295 cp a.txt b/ : after %rehashx, most system commands work without !
296 cp ${f}.txt $bar : Variable expansion in magics and system commands
297 files = !ls /usr : Capture sytem command output
298 files.s, files.l, files.n: "a b c", ['a','b','c'], 'a\nb\nc'
299
300 History:
301
302 _i, _ii, _iii : Previous, next previous, next next previous input
303 _i4, _ih[2:5] : Input history line 4, lines 2-4
304 exec _i81 : Execute input history line #81 again
305 %rep 81 : Edit input history line #81
306 _, __, ___ : previous, next previous, next next previous output
307 _dh : Directory history
308 _oh : Output history
309 %hist : Command history. '%hist -g foo' search history for 'foo'
310
311 Autocall:
312
313 f 1,2 : f(1,2) # Off by default, enable with %autocall magic.
314 /f 1,2 : f(1,2) (forced autoparen)
315 ,f 1 2 : f("1","2")
316 ;f 1 2 : f("1 2")
317
318 Remember: TAB completion works in many contexts, not just file names
319 or python names.
320
321 The following magic functions are currently available:
322
323 """
324
325 gui_reference = """\
326 ===============================
327 The graphical IPython console
328 ===============================
329
330 This console is designed to emulate the look, feel and workflow of a terminal
331 environment, while adding a number of enhancements that are simply not possible
332 in a real terminal, such as inline syntax highlighting, true multiline editing,
333 inline graphics and much more.
334
335 This quick reference document contains the basic information you'll need to
336 know to make the most efficient use of it. For the various command line
337 options available at startup, type ``ipython qtconsole --help`` at the command line.
338
339
340 Multiline editing
341 =================
342
343 The graphical console is capable of true multiline editing, but it also tries
344 to behave intuitively like a terminal when possible. If you are used to
345 IPython's old terminal behavior, you should find the transition painless, and
346 once you learn a few basic keybindings it will be a much more efficient
347 environment.
348
349 For single expressions or indented blocks, the console behaves almost like the
350 terminal IPython: single expressions are immediately evaluated, and indented
351 blocks are evaluated once a single blank line is entered::
352
353 In [1]: print "Hello IPython!" # Enter was pressed at the end of the line
354 Hello IPython!
355
356 In [2]: for i in range(10):
357 ...: print i,
358 ...:
359 0 1 2 3 4 5 6 7 8 9
360
361 If you want to enter more than one expression in a single input block
362 (something not possible in the terminal), you can use ``Control-Enter`` at the
363 end of your first line instead of ``Enter``. At that point the console goes
364 into 'cell mode' and even if your inputs are not indented, it will continue
365 accepting arbitrarily many lines until either you enter an extra blank line or
366 you hit ``Shift-Enter`` (the key binding that forces execution). When a
367 multiline cell is entered, IPython analyzes it and executes its code producing
368 an ``Out[n]`` prompt only for the last expression in it, while the rest of the
369 cell is executed as if it was a script. An example should clarify this::
370
371 In [3]: x=1 # Hit C-Enter here
372 ...: y=2 # from now on, regular Enter is sufficient
373 ...: z=3
374 ...: x**2 # This does *not* produce an Out[] value
375 ...: x+y+z # Only the last expression does
376 ...:
377 Out[3]: 6
378
379 The behavior where an extra blank line forces execution is only active if you
380 are actually typing at the keyboard each line, and is meant to make it mimic
381 the IPython terminal behavior. If you paste a long chunk of input (for example
382 a long script copied form an editor or web browser), it can contain arbitrarily
383 many intermediate blank lines and they won't cause any problems. As always,
384 you can then make it execute by appending a blank line *at the end* or hitting
385 ``Shift-Enter`` anywhere within the cell.
386
387 With the up arrow key, you can retrieve previous blocks of input that contain
388 multiple lines. You can move inside of a multiline cell like you would in any
389 text editor. When you want it executed, the simplest thing to do is to hit the
390 force execution key, ``Shift-Enter`` (though you can also navigate to the end
391 and append a blank line by using ``Enter`` twice).
392
393 If you've edited a multiline cell and accidentally navigate out of it with the
394 up or down arrow keys, IPython will clear the cell and replace it with the
395 contents of the one above or below that you navigated to. If this was an
396 accident and you want to retrieve the cell you were editing, use the Undo
397 keybinding, ``Control-z``.
398
399
400 Key bindings
401 ============
402
403 The IPython console supports most of the basic Emacs line-oriented keybindings,
404 in addition to some of its own.
405
406 The keybinding prefixes mean:
407
408 - ``C``: Control
409 - ``S``: Shift
410 - ``M``: Meta (typically the Alt key)
411
412 The keybindings themselves are:
413
414 - ``Enter``: insert new line (may cause execution, see above).
415 - ``C-Enter``: *force* new line, *never* causes execution.
416 - ``S-Enter``: *force* execution regardless of where cursor is, no newline added.
417 - ``Up``: step backwards through the history.
418 - ``Down``: step forwards through the history.
419 - ``S-Up``: search backwards through the history (like ``C-r`` in bash).
420 - ``S-Down``: search forwards through the history.
421 - ``C-c``: copy highlighted text to clipboard (prompts are automatically stripped).
422 - ``C-S-c``: copy highlighted text to clipboard (prompts are not stripped).
423 - ``C-v``: paste text from clipboard.
424 - ``C-z``: undo (retrieves lost text if you move out of a cell with the arrows).
425 - ``C-S-z``: redo.
426 - ``C-o``: move to 'other' area, between pager and terminal.
427 - ``C-l``: clear terminal.
428 - ``C-a``: go to beginning of line.
429 - ``C-e``: go to end of line.
430 - ``C-u``: kill from cursor to the begining of the line.
431 - ``C-k``: kill from cursor to the end of the line.
432 - ``C-y``: yank (paste)
433 - ``C-p``: previous line (like up arrow)
434 - ``C-n``: next line (like down arrow)
435 - ``C-f``: forward (like right arrow)
436 - ``C-b``: back (like left arrow)
437 - ``C-d``: delete next character, or exits if input is empty
438 - ``M-<``: move to the beginning of the input region.
439 - ``M->``: move to the end of the input region.
440 - ``M-d``: delete next word.
441 - ``M-Backspace``: delete previous word.
442 - ``C-.``: force a kernel restart (a confirmation dialog appears).
443 - ``C-+``: increase font size.
444 - ``C--``: decrease font size.
445 - ``C-M-Space``: toggle full screen. (Command-Control-Space on Mac OS X)
446
447 The IPython pager
448 =================
449
450 IPython will show long blocks of text from many sources using a builtin pager.
451 You can control where this pager appears with the ``--paging`` command-line
452 flag:
453
454 - ``inside`` [default]: the pager is overlaid on top of the main terminal. You
455 must quit the pager to get back to the terminal (similar to how a pager such
456 as ``less`` or ``more`` works).
457
458 - ``vsplit``: the console is made double-tall, and the pager appears on the
459 bottom area when needed. You can view its contents while using the terminal.
460
461 - ``hsplit``: the console is made double-wide, and the pager appears on the
462 right area when needed. You can view its contents while using the terminal.
463
464 - ``none``: the console never pages output.
465
466 If you use the vertical or horizontal paging modes, you can navigate between
467 terminal and pager as follows:
468
469 - Tab key: goes from pager to terminal (but not the other way around).
470 - Control-o: goes from one to another always.
471 - Mouse: click on either.
472
473 In all cases, the ``q`` or ``Escape`` keys quit the pager (when used with the
474 focus on the pager area).
475
476 Running subprocesses
477 ====================
478
479 The graphical IPython console uses the ``pexpect`` module to run subprocesses
480 when you type ``!command``. This has a number of advantages (true asynchronous
481 output from subprocesses as well as very robust termination of rogue
482 subprocesses with ``Control-C``), as well as some limitations. The main
483 limitation is that you can *not* interact back with the subprocess, so anything
484 that invokes a pager or expects you to type input into it will block and hang
485 (you can kill it with ``Control-C``).
486
487 We have provided as magics ``%less`` to page files (aliased to ``%more``),
488 ``%clear`` to clear the terminal, and ``%man`` on Linux/OSX. These cover the
489 most common commands you'd want to call in your subshell and that would cause
490 problems if invoked via ``!cmd``, but you need to be aware of this limitation.
491
492 Display
493 =======
494
495 The IPython console can now display objects in a variety of formats, including
496 HTML, PNG and SVG. This is accomplished using the display functions in
497 ``IPython.core.display``::
498
499 In [4]: from IPython.core.display import display, display_html
500
501 In [5]: from IPython.core.display import display_png, display_svg
502
503 Python objects can simply be passed to these functions and the appropriate
504 representations will be displayed in the console as long as the objects know
505 how to compute those representations. The easiest way of teaching objects how
506 to format themselves in various representations is to define special methods
507 such as: ``_repr_html_``, ``_repr_svg_`` and ``_repr_png_``. IPython's display formatters
508 can also be given custom formatter functions for various types::
509
510 In [6]: ip = get_ipython()
511
512 In [7]: html_formatter = ip.display_formatter.formatters['text/html']
513
514 In [8]: html_formatter.for_type(Foo, foo_to_html)
515
516 For further details, see ``IPython.core.formatters``.
517
518 Inline matplotlib graphics
519 ==========================
520
521 The IPython console is capable of displaying matplotlib figures inline, in SVG
522 or PNG format. If started with the ``matplotlib=inline``, then all figures are
523 rendered inline automatically (PNG by default). If started with ``--matplotlib``
524 or ``matplotlib=<your backend>``, then a GUI backend will be used, but IPython's
525 ``display()`` and ``getfigs()`` functions can be used to view plots inline::
526
527 In [9]: display(*getfigs()) # display all figures inline
528
529 In[10]: display(*getfigs(1,2)) # display figures 1 and 2 inline
530 """
531
532
533 quick_guide = """\
534 ? -> Introduction and overview of IPython's features.
535 %quickref -> Quick reference.
536 help -> Python's own help system.
537 object? -> Details about 'object', use 'object??' for extra details.
538 """
539
540 gui_note = """\
541 %guiref -> A brief reference about the graphical user interface.
542 """
543
544 default_banner_parts = [
545 'Python %s\n' % (sys.version.split('\n')[0],),
546 'Type "copyright", "credits" or "license" for more information.\n\n',
547 'IPython {version} -- An enhanced Interactive Python.\n'.format(
548 version=release.version,
549 ),
550 quick_guide
551 ]
552
553 default_gui_banner_parts = default_banner_parts + [gui_note]
554
555 default_banner = ''.join(default_banner_parts)
556
557 default_gui_banner = ''.join(default_gui_banner_parts)
558
559 # page GUI Reference, for use as a magic:
560
561 def page_guiref(arg_s=None):
562 """Show a basic reference about the GUI Console."""
563 from IPython.core import page
564 page.page(gui_reference)
565
566
[end of IPython/core/usage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| ipython/ipython | 92333e1084ea0d6ff91b55434555e741d2274dc7 | Inspect requests inside a function call should be smarter about what they inspect.
Previously, `func(a, b, <shift-tab>` would give information on `func`, now it gives information on `b`, which is not especially helpful.
This is because we removed logic from the frontend to make it more language agnostic, and we have not yet reimplemented that on the frontend. For 3.1, we should make it at least as smart as 2.x was. The quicky and dirty approach would be a regex; the proper way is tokenising the code.
Ping @mwaskom who brought this up on the mailing list.
| Thanks! I don't actually know how to _use_ any of these packages, so I rely on what IPython tells me they'll do :)
Should note here too that the help also seems to be displaying the `__repr__` for, at least, pandas DataFrames slightly differently in 3.0.rc1, which yields a help popup that is garbled and hides the important bits.
The dataframe reprs sounds like a separate thing - can you file an issue for it? Preferably with screenshots? Thanks.
Done: #7817
More related to this issue:
While implementing a smarter inspector, it would be _great_ if it would work across line breaks. I'm constantly getting bitten by trying to do
``` python
complex_function(some_arg, another_arg, data_frame.some_transformation(),
a_kwarg=a_value, <shift-TAB>
```
And having it not work.
This did not work on the 2.x series either, AFAICT, but if the inspector is going to be reimplemented it would be awesome if it could be added.
If there's smart, tokenising logic to determine what you're inspecting, there's no reason it shouldn't handle multiple lines. Making it smart enough for that might not be a 3.1 thing, though.
| 2015-02-19T20:14:23Z | <patch>
diff --git a/IPython/utils/tokenutil.py b/IPython/utils/tokenutil.py
--- a/IPython/utils/tokenutil.py
+++ b/IPython/utils/tokenutil.py
@@ -58,6 +58,9 @@ def token_at_cursor(cell, cursor_pos=0):
Used for introspection.
+ Function calls are prioritized, so the token for the callable will be returned
+ if the cursor is anywhere inside the call.
+
Parameters
----------
@@ -70,6 +73,7 @@ def token_at_cursor(cell, cursor_pos=0):
names = []
tokens = []
offset = 0
+ call_names = []
for tup in generate_tokens(StringIO(cell).readline):
tok = Token(*tup)
@@ -93,6 +97,11 @@ def token_at_cursor(cell, cursor_pos=0):
if tok.text == '=' and names:
# don't inspect the lhs of an assignment
names.pop(-1)
+ if tok.text == '(' and names:
+ # if we are inside a function call, inspect the function
+ call_names.append(names[-1])
+ elif tok.text == ')' and call_names:
+ call_names.pop(-1)
if offset + end_col > cursor_pos:
# we found the cursor, stop reading
@@ -102,7 +111,9 @@ def token_at_cursor(cell, cursor_pos=0):
if tok.token == tokenize2.NEWLINE:
offset += len(tok.line)
- if names:
+ if call_names:
+ return call_names[-1]
+ elif names:
return names[-1]
else:
return ''
</patch> | [] | [] | |||
docker__compose-2878 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Merge build args when using multiple compose files (or when extending services)
Based on the behavior of `environment` and `labels`, as well as `build.image`, `build.context` etc, I would also expect `build.args` to be merged, instead of being replaced.
To give an example:
## Input
**docker-compose.yml:**
``` yaml
version: "2"
services:
my_service:
build:
context: my-app
args:
SOME_VARIABLE: "42"
```
**docker-compose.override.yml:**
``` yaml
version: "2"
services:
my_service:
build:
args:
HTTP_PROXY: http://proxy.somewhere:80
HTTPS_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
```
**my-app/Dockerfile**
``` Dockerfile
# Just needed to be able to use `build:`
FROM busybox:latest
ARG SOME_VARIABLE=xyz
RUN echo "$SOME_VARIABLE" > /etc/example
```
## Current Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Expected Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
SOME_VARIABLE: 42 # Note the merged variable here
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Version Information
``` bash
$ docker-compose version
docker-compose version 1.6.0, build cdb920a
docker-py version: 1.7.0
CPython version: 2.7.11
OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015
```
# Implementation proposal
I mainly want to get clarification on what the desired behavior is, so that I can possibly help implementing it, maybe even for `1.6.1`.
Personally, I'd like the behavior to be to merge the `build.args` key (as outlined above), for a couple of reasons:
- Principle of least surprise/consistency with `environment`, `labels`, `ports` and so on.
- It enables scenarios like the one outlined above, where the images require some transient configuration to build, in addition to other build variables which actually have an influence on the final image.
The scenario that one wants to replace all build args at once is not very likely IMO; why would you define base build variables in the first place if you're going to replace them anyway?
# Alternative behavior: Output a warning
If the behavior should stay the same as it is now, i.e. to fully replaced the `build.args` keys, then `docker-compose` should at least output a warning IMO. It took me some time to figure out that `docker-compose` was ignoring the build args in the base `docker-compose.yml` file.
</issue>
<code>
[start of README.md]
1 Docker Compose
2 ==============
3 
4
5 Compose is a tool for defining and running multi-container Docker applications.
6 With Compose, you use a Compose file to configure your application's services.
7 Then, using a single command, you create and start all the services
8 from your configuration. To learn more about all the features of Compose
9 see [the list of features](https://github.com/docker/compose/blob/release/docs/overview.md#features).
10
11 Compose is great for development, testing, and staging environments, as well as
12 CI workflows. You can learn more about each case in
13 [Common Use Cases](https://github.com/docker/compose/blob/release/docs/overview.md#common-use-cases).
14
15 Using Compose is basically a three-step process.
16
17 1. Define your app's environment with a `Dockerfile` so it can be
18 reproduced anywhere.
19 2. Define the services that make up your app in `docker-compose.yml` so
20 they can be run together in an isolated environment:
21 3. Lastly, run `docker-compose up` and Compose will start and run your entire app.
22
23 A `docker-compose.yml` looks like this:
24
25 web:
26 build: .
27 ports:
28 - "5000:5000"
29 volumes:
30 - .:/code
31 links:
32 - redis
33 redis:
34 image: redis
35
36 For more information about the Compose file, see the
37 [Compose file reference](https://github.com/docker/compose/blob/release/docs/compose-file.md)
38
39 Compose has commands for managing the whole lifecycle of your application:
40
41 * Start, stop and rebuild services
42 * View the status of running services
43 * Stream the log output of running services
44 * Run a one-off command on a service
45
46 Installation and documentation
47 ------------------------------
48
49 - Full documentation is available on [Docker's website](https://docs.docker.com/compose/).
50 - If you have any questions, you can talk in real-time with other developers in the #docker-compose IRC channel on Freenode. [Click here to join using IRCCloud.](https://www.irccloud.com/invite?hostname=irc.freenode.net&channel=%23docker-compose)
51 - Code repository for Compose is on [Github](https://github.com/docker/compose)
52 - If you find any problems please fill out an [issue](https://github.com/docker/compose/issues/new)
53
54 Contributing
55 ------------
56
57 [](http://jenkins.dockerproject.org/job/Compose%20Master/)
58
59 Want to help build Compose? Check out our [contributing documentation](https://github.com/docker/compose/blob/master/CONTRIBUTING.md).
60
61 Releasing
62 ---------
63
64 Releases are built by maintainers, following an outline of the [release process](https://github.com/docker/compose/blob/master/project/RELEASE-PROCESS.md).
65
[end of README.md]
[start of compose/cli/utils.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import unicode_literals
4
5 import os
6 import platform
7 import ssl
8 import subprocess
9
10 import docker
11 from six.moves import input
12
13 import compose
14
15
16 def yesno(prompt, default=None):
17 """
18 Prompt the user for a yes or no.
19
20 Can optionally specify a default value, which will only be
21 used if they enter a blank line.
22
23 Unrecognised input (anything other than "y", "n", "yes",
24 "no" or "") will return None.
25 """
26 answer = input(prompt).strip().lower()
27
28 if answer == "y" or answer == "yes":
29 return True
30 elif answer == "n" or answer == "no":
31 return False
32 elif answer == "":
33 return default
34 else:
35 return None
36
37
38 def call_silently(*args, **kwargs):
39 """
40 Like subprocess.call(), but redirects stdout and stderr to /dev/null.
41 """
42 with open(os.devnull, 'w') as shutup:
43 try:
44 return subprocess.call(*args, stdout=shutup, stderr=shutup, **kwargs)
45 except WindowsError:
46 # On Windows, subprocess.call() can still raise exceptions. Normalize
47 # to POSIXy behaviour by returning a nonzero exit code.
48 return 1
49
50
51 def is_mac():
52 return platform.system() == 'Darwin'
53
54
55 def is_ubuntu():
56 return platform.system() == 'Linux' and platform.linux_distribution()[0] == 'Ubuntu'
57
58
59 def get_version_info(scope):
60 versioninfo = 'docker-compose version {}, build {}'.format(
61 compose.__version__,
62 get_build_version())
63
64 if scope == 'compose':
65 return versioninfo
66 if scope == 'full':
67 return (
68 "{}\n"
69 "docker-py version: {}\n"
70 "{} version: {}\n"
71 "OpenSSL version: {}"
72 ).format(
73 versioninfo,
74 docker.version,
75 platform.python_implementation(),
76 platform.python_version(),
77 ssl.OPENSSL_VERSION)
78
79 raise ValueError("{} is not a valid version scope".format(scope))
80
81
82 def get_build_version():
83 filename = os.path.join(os.path.dirname(compose.__file__), 'GITSHA')
84 if not os.path.exists(filename):
85 return 'unknown'
86
87 with open(filename) as fh:
88 return fh.read().strip()
89
[end of compose/cli/utils.py]
[start of compose/config/config.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import codecs
5 import functools
6 import logging
7 import operator
8 import os
9 import string
10 import sys
11 from collections import namedtuple
12
13 import six
14 import yaml
15 from cached_property import cached_property
16
17 from ..const import COMPOSEFILE_V1 as V1
18 from ..const import COMPOSEFILE_V2_0 as V2_0
19 from .errors import CircularReference
20 from .errors import ComposeFileNotFound
21 from .errors import ConfigurationError
22 from .errors import VERSION_EXPLANATION
23 from .interpolation import interpolate_environment_variables
24 from .sort_services import get_container_name_from_network_mode
25 from .sort_services import get_service_name_from_network_mode
26 from .sort_services import sort_service_dicts
27 from .types import parse_extra_hosts
28 from .types import parse_restart_spec
29 from .types import ServiceLink
30 from .types import VolumeFromSpec
31 from .types import VolumeSpec
32 from .validation import match_named_volumes
33 from .validation import validate_against_fields_schema
34 from .validation import validate_against_service_schema
35 from .validation import validate_depends_on
36 from .validation import validate_extends_file_path
37 from .validation import validate_network_mode
38 from .validation import validate_top_level_object
39 from .validation import validate_top_level_service_objects
40 from .validation import validate_ulimits
41
42
43 DOCKER_CONFIG_KEYS = [
44 'cap_add',
45 'cap_drop',
46 'cgroup_parent',
47 'command',
48 'cpu_quota',
49 'cpu_shares',
50 'cpuset',
51 'detach',
52 'devices',
53 'dns',
54 'dns_search',
55 'domainname',
56 'entrypoint',
57 'env_file',
58 'environment',
59 'extra_hosts',
60 'hostname',
61 'image',
62 'ipc',
63 'labels',
64 'links',
65 'mac_address',
66 'mem_limit',
67 'memswap_limit',
68 'net',
69 'pid',
70 'ports',
71 'privileged',
72 'read_only',
73 'restart',
74 'security_opt',
75 'stdin_open',
76 'stop_signal',
77 'tty',
78 'user',
79 'volume_driver',
80 'volumes',
81 'volumes_from',
82 'working_dir',
83 ]
84
85 ALLOWED_KEYS = DOCKER_CONFIG_KEYS + [
86 'build',
87 'container_name',
88 'dockerfile',
89 'logging',
90 'network_mode',
91 ]
92
93 DOCKER_VALID_URL_PREFIXES = (
94 'http://',
95 'https://',
96 'git://',
97 'github.com/',
98 'git@',
99 )
100
101 SUPPORTED_FILENAMES = [
102 'docker-compose.yml',
103 'docker-compose.yaml',
104 ]
105
106 DEFAULT_OVERRIDE_FILENAME = 'docker-compose.override.yml'
107
108
109 log = logging.getLogger(__name__)
110
111
112 class ConfigDetails(namedtuple('_ConfigDetails', 'working_dir config_files')):
113 """
114 :param working_dir: the directory to use for relative paths in the config
115 :type working_dir: string
116 :param config_files: list of configuration files to load
117 :type config_files: list of :class:`ConfigFile`
118 """
119
120
121 class ConfigFile(namedtuple('_ConfigFile', 'filename config')):
122 """
123 :param filename: filename of the config file
124 :type filename: string
125 :param config: contents of the config file
126 :type config: :class:`dict`
127 """
128
129 @classmethod
130 def from_filename(cls, filename):
131 return cls(filename, load_yaml(filename))
132
133 @cached_property
134 def version(self):
135 if 'version' not in self.config:
136 return V1
137
138 version = self.config['version']
139
140 if isinstance(version, dict):
141 log.warn('Unexpected type for "version" key in "{}". Assuming '
142 '"version" is the name of a service, and defaulting to '
143 'Compose file version 1.'.format(self.filename))
144 return V1
145
146 if not isinstance(version, six.string_types):
147 raise ConfigurationError(
148 'Version in "{}" is invalid - it should be a string.'
149 .format(self.filename))
150
151 if version == '1':
152 raise ConfigurationError(
153 'Version in "{}" is invalid. {}'
154 .format(self.filename, VERSION_EXPLANATION))
155
156 if version == '2':
157 version = V2_0
158
159 if version != V2_0:
160 raise ConfigurationError(
161 'Version in "{}" is unsupported. {}'
162 .format(self.filename, VERSION_EXPLANATION))
163
164 return version
165
166 def get_service(self, name):
167 return self.get_service_dicts()[name]
168
169 def get_service_dicts(self):
170 return self.config if self.version == V1 else self.config.get('services', {})
171
172 def get_volumes(self):
173 return {} if self.version == V1 else self.config.get('volumes', {})
174
175 def get_networks(self):
176 return {} if self.version == V1 else self.config.get('networks', {})
177
178
179 class Config(namedtuple('_Config', 'version services volumes networks')):
180 """
181 :param version: configuration version
182 :type version: int
183 :param services: List of service description dictionaries
184 :type services: :class:`list`
185 :param volumes: Dictionary mapping volume names to description dictionaries
186 :type volumes: :class:`dict`
187 :param networks: Dictionary mapping network names to description dictionaries
188 :type networks: :class:`dict`
189 """
190
191
192 class ServiceConfig(namedtuple('_ServiceConfig', 'working_dir filename name config')):
193
194 @classmethod
195 def with_abs_paths(cls, working_dir, filename, name, config):
196 if not working_dir:
197 raise ValueError("No working_dir for ServiceConfig.")
198
199 return cls(
200 os.path.abspath(working_dir),
201 os.path.abspath(filename) if filename else filename,
202 name,
203 config)
204
205
206 def find(base_dir, filenames):
207 if filenames == ['-']:
208 return ConfigDetails(
209 os.getcwd(),
210 [ConfigFile(None, yaml.safe_load(sys.stdin))])
211
212 if filenames:
213 filenames = [os.path.join(base_dir, f) for f in filenames]
214 else:
215 filenames = get_default_config_files(base_dir)
216
217 log.debug("Using configuration files: {}".format(",".join(filenames)))
218 return ConfigDetails(
219 os.path.dirname(filenames[0]),
220 [ConfigFile.from_filename(f) for f in filenames])
221
222
223 def validate_config_version(config_files):
224 main_file = config_files[0]
225 validate_top_level_object(main_file)
226 for next_file in config_files[1:]:
227 validate_top_level_object(next_file)
228
229 if main_file.version != next_file.version:
230 raise ConfigurationError(
231 "Version mismatch: file {0} specifies version {1} but "
232 "extension file {2} uses version {3}".format(
233 main_file.filename,
234 main_file.version,
235 next_file.filename,
236 next_file.version))
237
238
239 def get_default_config_files(base_dir):
240 (candidates, path) = find_candidates_in_parent_dirs(SUPPORTED_FILENAMES, base_dir)
241
242 if not candidates:
243 raise ComposeFileNotFound(SUPPORTED_FILENAMES)
244
245 winner = candidates[0]
246
247 if len(candidates) > 1:
248 log.warn("Found multiple config files with supported names: %s", ", ".join(candidates))
249 log.warn("Using %s\n", winner)
250
251 return [os.path.join(path, winner)] + get_default_override_file(path)
252
253
254 def get_default_override_file(path):
255 override_filename = os.path.join(path, DEFAULT_OVERRIDE_FILENAME)
256 return [override_filename] if os.path.exists(override_filename) else []
257
258
259 def find_candidates_in_parent_dirs(filenames, path):
260 """
261 Given a directory path to start, looks for filenames in the
262 directory, and then each parent directory successively,
263 until found.
264
265 Returns tuple (candidates, path).
266 """
267 candidates = [filename for filename in filenames
268 if os.path.exists(os.path.join(path, filename))]
269
270 if not candidates:
271 parent_dir = os.path.join(path, '..')
272 if os.path.abspath(parent_dir) != os.path.abspath(path):
273 return find_candidates_in_parent_dirs(filenames, parent_dir)
274
275 return (candidates, path)
276
277
278 def load(config_details):
279 """Load the configuration from a working directory and a list of
280 configuration files. Files are loaded in order, and merged on top
281 of each other to create the final configuration.
282
283 Return a fully interpolated, extended and validated configuration.
284 """
285 validate_config_version(config_details.config_files)
286
287 processed_files = [
288 process_config_file(config_file)
289 for config_file in config_details.config_files
290 ]
291 config_details = config_details._replace(config_files=processed_files)
292
293 main_file = config_details.config_files[0]
294 volumes = load_mapping(config_details.config_files, 'get_volumes', 'Volume')
295 networks = load_mapping(config_details.config_files, 'get_networks', 'Network')
296 service_dicts = load_services(
297 config_details.working_dir,
298 main_file,
299 [file.get_service_dicts() for file in config_details.config_files])
300
301 if main_file.version != V1:
302 for service_dict in service_dicts:
303 match_named_volumes(service_dict, volumes)
304
305 return Config(main_file.version, service_dicts, volumes, networks)
306
307
308 def load_mapping(config_files, get_func, entity_type):
309 mapping = {}
310
311 for config_file in config_files:
312 for name, config in getattr(config_file, get_func)().items():
313 mapping[name] = config or {}
314 if not config:
315 continue
316
317 external = config.get('external')
318 if external:
319 if len(config.keys()) > 1:
320 raise ConfigurationError(
321 '{} {} declared as external but specifies'
322 ' additional attributes ({}). '.format(
323 entity_type,
324 name,
325 ', '.join([k for k in config.keys() if k != 'external'])
326 )
327 )
328 if isinstance(external, dict):
329 config['external_name'] = external.get('name')
330 else:
331 config['external_name'] = name
332
333 mapping[name] = config
334
335 return mapping
336
337
338 def load_services(working_dir, config_file, service_configs):
339 def build_service(service_name, service_dict, service_names):
340 service_config = ServiceConfig.with_abs_paths(
341 working_dir,
342 config_file.filename,
343 service_name,
344 service_dict)
345 resolver = ServiceExtendsResolver(service_config, config_file)
346 service_dict = process_service(resolver.run())
347
348 service_config = service_config._replace(config=service_dict)
349 validate_service(service_config, service_names, config_file.version)
350 service_dict = finalize_service(
351 service_config,
352 service_names,
353 config_file.version)
354 return service_dict
355
356 def build_services(service_config):
357 service_names = service_config.keys()
358 return sort_service_dicts([
359 build_service(name, service_dict, service_names)
360 for name, service_dict in service_config.items()
361 ])
362
363 def merge_services(base, override):
364 all_service_names = set(base) | set(override)
365 return {
366 name: merge_service_dicts_from_files(
367 base.get(name, {}),
368 override.get(name, {}),
369 config_file.version)
370 for name in all_service_names
371 }
372
373 service_config = service_configs[0]
374 for next_config in service_configs[1:]:
375 service_config = merge_services(service_config, next_config)
376
377 return build_services(service_config)
378
379
380 def process_config_file(config_file, service_name=None):
381 service_dicts = config_file.get_service_dicts()
382 validate_top_level_service_objects(config_file.filename, service_dicts)
383
384 interpolated_config = interpolate_environment_variables(service_dicts, 'service')
385
386 if config_file.version == V2_0:
387 processed_config = dict(config_file.config)
388 processed_config['services'] = services = interpolated_config
389 processed_config['volumes'] = interpolate_environment_variables(
390 config_file.get_volumes(), 'volume')
391 processed_config['networks'] = interpolate_environment_variables(
392 config_file.get_networks(), 'network')
393
394 if config_file.version == V1:
395 processed_config = services = interpolated_config
396
397 config_file = config_file._replace(config=processed_config)
398 validate_against_fields_schema(config_file)
399
400 if service_name and service_name not in services:
401 raise ConfigurationError(
402 "Cannot extend service '{}' in {}: Service not found".format(
403 service_name, config_file.filename))
404
405 return config_file
406
407
408 class ServiceExtendsResolver(object):
409 def __init__(self, service_config, config_file, already_seen=None):
410 self.service_config = service_config
411 self.working_dir = service_config.working_dir
412 self.already_seen = already_seen or []
413 self.config_file = config_file
414
415 @property
416 def signature(self):
417 return self.service_config.filename, self.service_config.name
418
419 def detect_cycle(self):
420 if self.signature in self.already_seen:
421 raise CircularReference(self.already_seen + [self.signature])
422
423 def run(self):
424 self.detect_cycle()
425
426 if 'extends' in self.service_config.config:
427 service_dict = self.resolve_extends(*self.validate_and_construct_extends())
428 return self.service_config._replace(config=service_dict)
429
430 return self.service_config
431
432 def validate_and_construct_extends(self):
433 extends = self.service_config.config['extends']
434 if not isinstance(extends, dict):
435 extends = {'service': extends}
436
437 config_path = self.get_extended_config_path(extends)
438 service_name = extends['service']
439
440 extends_file = ConfigFile.from_filename(config_path)
441 validate_config_version([self.config_file, extends_file])
442 extended_file = process_config_file(
443 extends_file,
444 service_name=service_name)
445 service_config = extended_file.get_service(service_name)
446
447 return config_path, service_config, service_name
448
449 def resolve_extends(self, extended_config_path, service_dict, service_name):
450 resolver = ServiceExtendsResolver(
451 ServiceConfig.with_abs_paths(
452 os.path.dirname(extended_config_path),
453 extended_config_path,
454 service_name,
455 service_dict),
456 self.config_file,
457 already_seen=self.already_seen + [self.signature])
458
459 service_config = resolver.run()
460 other_service_dict = process_service(service_config)
461 validate_extended_service_dict(
462 other_service_dict,
463 extended_config_path,
464 service_name)
465
466 return merge_service_dicts(
467 other_service_dict,
468 self.service_config.config,
469 self.config_file.version)
470
471 def get_extended_config_path(self, extends_options):
472 """Service we are extending either has a value for 'file' set, which we
473 need to obtain a full path too or we are extending from a service
474 defined in our own file.
475 """
476 filename = self.service_config.filename
477 validate_extends_file_path(
478 self.service_config.name,
479 extends_options,
480 filename)
481 if 'file' in extends_options:
482 return expand_path(self.working_dir, extends_options['file'])
483 return filename
484
485
486 def resolve_environment(service_dict):
487 """Unpack any environment variables from an env_file, if set.
488 Interpolate environment values if set.
489 """
490 env = {}
491 for env_file in service_dict.get('env_file', []):
492 env.update(env_vars_from_file(env_file))
493
494 env.update(parse_environment(service_dict.get('environment')))
495 return dict(filter(None, (resolve_env_var(k, v) for k, v in six.iteritems(env))))
496
497
498 def resolve_build_args(build):
499 args = parse_build_arguments(build.get('args'))
500 return dict(filter(None, (resolve_env_var(k, v) for k, v in six.iteritems(args))))
501
502
503 def validate_extended_service_dict(service_dict, filename, service):
504 error_prefix = "Cannot extend service '%s' in %s:" % (service, filename)
505
506 if 'links' in service_dict:
507 raise ConfigurationError(
508 "%s services with 'links' cannot be extended" % error_prefix)
509
510 if 'volumes_from' in service_dict:
511 raise ConfigurationError(
512 "%s services with 'volumes_from' cannot be extended" % error_prefix)
513
514 if 'net' in service_dict:
515 if get_container_name_from_network_mode(service_dict['net']):
516 raise ConfigurationError(
517 "%s services with 'net: container' cannot be extended" % error_prefix)
518
519 if 'network_mode' in service_dict:
520 if get_service_name_from_network_mode(service_dict['network_mode']):
521 raise ConfigurationError(
522 "%s services with 'network_mode: service' cannot be extended" % error_prefix)
523
524 if 'depends_on' in service_dict:
525 raise ConfigurationError(
526 "%s services with 'depends_on' cannot be extended" % error_prefix)
527
528
529 def validate_service(service_config, service_names, version):
530 service_dict, service_name = service_config.config, service_config.name
531 validate_against_service_schema(service_dict, service_name, version)
532 validate_paths(service_dict)
533
534 validate_ulimits(service_config)
535 validate_network_mode(service_config, service_names)
536 validate_depends_on(service_config, service_names)
537
538 if not service_dict.get('image') and has_uppercase(service_name):
539 raise ConfigurationError(
540 "Service '{name}' contains uppercase characters which are not valid "
541 "as part of an image name. Either use a lowercase service name or "
542 "use the `image` field to set a custom name for the service image."
543 .format(name=service_name))
544
545
546 def process_service(service_config):
547 working_dir = service_config.working_dir
548 service_dict = dict(service_config.config)
549
550 if 'env_file' in service_dict:
551 service_dict['env_file'] = [
552 expand_path(working_dir, path)
553 for path in to_list(service_dict['env_file'])
554 ]
555
556 if 'build' in service_dict:
557 if isinstance(service_dict['build'], six.string_types):
558 service_dict['build'] = resolve_build_path(working_dir, service_dict['build'])
559 elif isinstance(service_dict['build'], dict) and 'context' in service_dict['build']:
560 path = service_dict['build']['context']
561 service_dict['build']['context'] = resolve_build_path(working_dir, path)
562
563 if 'volumes' in service_dict and service_dict.get('volume_driver') is None:
564 service_dict['volumes'] = resolve_volume_paths(working_dir, service_dict)
565
566 if 'labels' in service_dict:
567 service_dict['labels'] = parse_labels(service_dict['labels'])
568
569 if 'extra_hosts' in service_dict:
570 service_dict['extra_hosts'] = parse_extra_hosts(service_dict['extra_hosts'])
571
572 for field in ['dns', 'dns_search']:
573 if field in service_dict:
574 service_dict[field] = to_list(service_dict[field])
575
576 return service_dict
577
578
579 def finalize_service(service_config, service_names, version):
580 service_dict = dict(service_config.config)
581
582 if 'environment' in service_dict or 'env_file' in service_dict:
583 service_dict['environment'] = resolve_environment(service_dict)
584 service_dict.pop('env_file', None)
585
586 if 'volumes_from' in service_dict:
587 service_dict['volumes_from'] = [
588 VolumeFromSpec.parse(vf, service_names, version)
589 for vf in service_dict['volumes_from']
590 ]
591
592 if 'volumes' in service_dict:
593 service_dict['volumes'] = [
594 VolumeSpec.parse(v) for v in service_dict['volumes']]
595
596 if 'net' in service_dict:
597 network_mode = service_dict.pop('net')
598 container_name = get_container_name_from_network_mode(network_mode)
599 if container_name and container_name in service_names:
600 service_dict['network_mode'] = 'service:{}'.format(container_name)
601 else:
602 service_dict['network_mode'] = network_mode
603
604 if 'restart' in service_dict:
605 service_dict['restart'] = parse_restart_spec(service_dict['restart'])
606
607 normalize_build(service_dict, service_config.working_dir)
608
609 service_dict['name'] = service_config.name
610 return normalize_v1_service_format(service_dict)
611
612
613 def normalize_v1_service_format(service_dict):
614 if 'log_driver' in service_dict or 'log_opt' in service_dict:
615 if 'logging' not in service_dict:
616 service_dict['logging'] = {}
617 if 'log_driver' in service_dict:
618 service_dict['logging']['driver'] = service_dict['log_driver']
619 del service_dict['log_driver']
620 if 'log_opt' in service_dict:
621 service_dict['logging']['options'] = service_dict['log_opt']
622 del service_dict['log_opt']
623
624 if 'dockerfile' in service_dict:
625 service_dict['build'] = service_dict.get('build', {})
626 service_dict['build'].update({
627 'dockerfile': service_dict.pop('dockerfile')
628 })
629
630 return service_dict
631
632
633 def merge_service_dicts_from_files(base, override, version):
634 """When merging services from multiple files we need to merge the `extends`
635 field. This is not handled by `merge_service_dicts()` which is used to
636 perform the `extends`.
637 """
638 new_service = merge_service_dicts(base, override, version)
639 if 'extends' in override:
640 new_service['extends'] = override['extends']
641 elif 'extends' in base:
642 new_service['extends'] = base['extends']
643 return new_service
644
645
646 class MergeDict(dict):
647 """A dict-like object responsible for merging two dicts into one."""
648
649 def __init__(self, base, override):
650 self.base = base
651 self.override = override
652
653 def needs_merge(self, field):
654 return field in self.base or field in self.override
655
656 def merge_field(self, field, merge_func, default=None):
657 if not self.needs_merge(field):
658 return
659
660 self[field] = merge_func(
661 self.base.get(field, default),
662 self.override.get(field, default))
663
664 def merge_mapping(self, field, parse_func):
665 if not self.needs_merge(field):
666 return
667
668 self[field] = parse_func(self.base.get(field))
669 self[field].update(parse_func(self.override.get(field)))
670
671 def merge_sequence(self, field, parse_func):
672 def parse_sequence_func(seq):
673 return to_mapping((parse_func(item) for item in seq), 'merge_field')
674
675 if not self.needs_merge(field):
676 return
677
678 merged = parse_sequence_func(self.base.get(field, []))
679 merged.update(parse_sequence_func(self.override.get(field, [])))
680 self[field] = [item.repr() for item in merged.values()]
681
682 def merge_scalar(self, field):
683 if self.needs_merge(field):
684 self[field] = self.override.get(field, self.base.get(field))
685
686
687 def merge_service_dicts(base, override, version):
688 md = MergeDict(base, override)
689
690 md.merge_mapping('environment', parse_environment)
691 md.merge_mapping('labels', parse_labels)
692 md.merge_mapping('ulimits', parse_ulimits)
693 md.merge_sequence('links', ServiceLink.parse)
694
695 for field in ['volumes', 'devices']:
696 md.merge_field(field, merge_path_mappings)
697
698 for field in [
699 'depends_on',
700 'expose',
701 'external_links',
702 'networks',
703 'ports',
704 'volumes_from',
705 ]:
706 md.merge_field(field, operator.add, default=[])
707
708 for field in ['dns', 'dns_search', 'env_file']:
709 md.merge_field(field, merge_list_or_string)
710
711 for field in set(ALLOWED_KEYS) - set(md):
712 md.merge_scalar(field)
713
714 if version == V1:
715 legacy_v1_merge_image_or_build(md, base, override)
716 else:
717 merge_build(md, base, override)
718
719 return dict(md)
720
721
722 def merge_build(output, base, override):
723 build = {}
724
725 if 'build' in base:
726 if isinstance(base['build'], six.string_types):
727 build['context'] = base['build']
728 else:
729 build.update(base['build'])
730
731 if 'build' in override:
732 if isinstance(override['build'], six.string_types):
733 build['context'] = override['build']
734 else:
735 build.update(override['build'])
736
737 if build:
738 output['build'] = build
739
740
741 def legacy_v1_merge_image_or_build(output, base, override):
742 output.pop('image', None)
743 output.pop('build', None)
744 if 'image' in override:
745 output['image'] = override['image']
746 elif 'build' in override:
747 output['build'] = override['build']
748 elif 'image' in base:
749 output['image'] = base['image']
750 elif 'build' in base:
751 output['build'] = base['build']
752
753
754 def merge_environment(base, override):
755 env = parse_environment(base)
756 env.update(parse_environment(override))
757 return env
758
759
760 def split_env(env):
761 if isinstance(env, six.binary_type):
762 env = env.decode('utf-8', 'replace')
763 if '=' in env:
764 return env.split('=', 1)
765 else:
766 return env, None
767
768
769 def split_label(label):
770 if '=' in label:
771 return label.split('=', 1)
772 else:
773 return label, ''
774
775
776 def parse_dict_or_list(split_func, type_name, arguments):
777 if not arguments:
778 return {}
779
780 if isinstance(arguments, list):
781 return dict(split_func(e) for e in arguments)
782
783 if isinstance(arguments, dict):
784 return dict(arguments)
785
786 raise ConfigurationError(
787 "%s \"%s\" must be a list or mapping," %
788 (type_name, arguments)
789 )
790
791
792 parse_build_arguments = functools.partial(parse_dict_or_list, split_env, 'build arguments')
793 parse_environment = functools.partial(parse_dict_or_list, split_env, 'environment')
794 parse_labels = functools.partial(parse_dict_or_list, split_label, 'labels')
795
796
797 def parse_ulimits(ulimits):
798 if not ulimits:
799 return {}
800
801 if isinstance(ulimits, dict):
802 return dict(ulimits)
803
804
805 def resolve_env_var(key, val):
806 if val is not None:
807 return key, val
808 elif key in os.environ:
809 return key, os.environ[key]
810 else:
811 return ()
812
813
814 def env_vars_from_file(filename):
815 """
816 Read in a line delimited file of environment variables.
817 """
818 if not os.path.exists(filename):
819 raise ConfigurationError("Couldn't find env file: %s" % filename)
820 env = {}
821 for line in codecs.open(filename, 'r', 'utf-8'):
822 line = line.strip()
823 if line and not line.startswith('#'):
824 k, v = split_env(line)
825 env[k] = v
826 return env
827
828
829 def resolve_volume_paths(working_dir, service_dict):
830 return [
831 resolve_volume_path(working_dir, volume)
832 for volume in service_dict['volumes']
833 ]
834
835
836 def resolve_volume_path(working_dir, volume):
837 container_path, host_path = split_path_mapping(volume)
838
839 if host_path is not None:
840 if host_path.startswith('.'):
841 host_path = expand_path(working_dir, host_path)
842 host_path = os.path.expanduser(host_path)
843 return u"{}:{}".format(host_path, container_path)
844 else:
845 return container_path
846
847
848 def normalize_build(service_dict, working_dir):
849
850 if 'build' in service_dict:
851 build = {}
852 # Shortcut where specifying a string is treated as the build context
853 if isinstance(service_dict['build'], six.string_types):
854 build['context'] = service_dict.pop('build')
855 else:
856 build.update(service_dict['build'])
857 if 'args' in build:
858 build['args'] = resolve_build_args(build)
859
860 service_dict['build'] = build
861
862
863 def resolve_build_path(working_dir, build_path):
864 if is_url(build_path):
865 return build_path
866 return expand_path(working_dir, build_path)
867
868
869 def is_url(build_path):
870 return build_path.startswith(DOCKER_VALID_URL_PREFIXES)
871
872
873 def validate_paths(service_dict):
874 if 'build' in service_dict:
875 build = service_dict.get('build', {})
876
877 if isinstance(build, six.string_types):
878 build_path = build
879 elif isinstance(build, dict) and 'context' in build:
880 build_path = build['context']
881
882 if (
883 not is_url(build_path) and
884 (not os.path.exists(build_path) or not os.access(build_path, os.R_OK))
885 ):
886 raise ConfigurationError(
887 "build path %s either does not exist, is not accessible, "
888 "or is not a valid URL." % build_path)
889
890
891 def merge_path_mappings(base, override):
892 d = dict_from_path_mappings(base)
893 d.update(dict_from_path_mappings(override))
894 return path_mappings_from_dict(d)
895
896
897 def dict_from_path_mappings(path_mappings):
898 if path_mappings:
899 return dict(split_path_mapping(v) for v in path_mappings)
900 else:
901 return {}
902
903
904 def path_mappings_from_dict(d):
905 return [join_path_mapping(v) for v in d.items()]
906
907
908 def split_path_mapping(volume_path):
909 """
910 Ascertain if the volume_path contains a host path as well as a container
911 path. Using splitdrive so windows absolute paths won't cause issues with
912 splitting on ':'.
913 """
914 # splitdrive has limitations when it comes to relative paths, so when it's
915 # relative, handle special case to set the drive to ''
916 if volume_path.startswith('.') or volume_path.startswith('~'):
917 drive, volume_config = '', volume_path
918 else:
919 drive, volume_config = os.path.splitdrive(volume_path)
920
921 if ':' in volume_config:
922 (host, container) = volume_config.split(':', 1)
923 return (container, drive + host)
924 else:
925 return (volume_path, None)
926
927
928 def join_path_mapping(pair):
929 (container, host) = pair
930 if host is None:
931 return container
932 else:
933 return ":".join((host, container))
934
935
936 def expand_path(working_dir, path):
937 return os.path.abspath(os.path.join(working_dir, os.path.expanduser(path)))
938
939
940 def merge_list_or_string(base, override):
941 return to_list(base) + to_list(override)
942
943
944 def to_list(value):
945 if value is None:
946 return []
947 elif isinstance(value, six.string_types):
948 return [value]
949 else:
950 return value
951
952
953 def to_mapping(sequence, key_field):
954 return {getattr(item, key_field): item for item in sequence}
955
956
957 def has_uppercase(name):
958 return any(char in string.ascii_uppercase for char in name)
959
960
961 def load_yaml(filename):
962 try:
963 with open(filename, 'r') as fh:
964 return yaml.safe_load(fh)
965 except (IOError, yaml.YAMLError) as e:
966 error_name = getattr(e, '__module__', '') + '.' + e.__class__.__name__
967 raise ConfigurationError(u"{}: {}".format(error_name, e))
968
[end of compose/config/config.py]
[start of contrib/migration/migrate-compose-file-v1-to-v2.py]
1 #!/usr/bin/env python
2 """
3 Migrate a Compose file from the V1 format in Compose 1.5 to the V2 format
4 supported by Compose 1.6+
5 """
6 from __future__ import absolute_import
7 from __future__ import unicode_literals
8
9 import argparse
10 import logging
11 import sys
12
13 import ruamel.yaml
14
15 from compose.config.types import VolumeSpec
16
17
18 log = logging.getLogger('migrate')
19
20
21 def migrate(content):
22 data = ruamel.yaml.load(content, ruamel.yaml.RoundTripLoader)
23
24 service_names = data.keys()
25
26 for name, service in data.items():
27 warn_for_links(name, service)
28 warn_for_external_links(name, service)
29 rewrite_net(service, service_names)
30 rewrite_build(service)
31 rewrite_logging(service)
32 rewrite_volumes_from(service, service_names)
33
34 services = {name: data.pop(name) for name in data.keys()}
35
36 data['version'] = 2
37 data['services'] = services
38 create_volumes_section(data)
39
40 return data
41
42
43 def warn_for_links(name, service):
44 links = service.get('links')
45 if links:
46 example_service = links[0].partition(':')[0]
47 log.warn(
48 "Service {name} has links, which no longer create environment "
49 "variables such as {example_service_upper}_PORT. "
50 "If you are using those in your application code, you should "
51 "instead connect directly to the hostname, e.g. "
52 "'{example_service}'."
53 .format(name=name, example_service=example_service,
54 example_service_upper=example_service.upper()))
55
56
57 def warn_for_external_links(name, service):
58 external_links = service.get('external_links')
59 if external_links:
60 log.warn(
61 "Service {name} has external_links: {ext}, which now work "
62 "slightly differently. In particular, two containers must be "
63 "connected to at least one network in common in order to "
64 "communicate, even if explicitly linked together.\n\n"
65 "Either connect the external container to your app's default "
66 "network, or connect both the external container and your "
67 "service's containers to a pre-existing network. See "
68 "https://docs.docker.com/compose/networking/ "
69 "for more on how to do this."
70 .format(name=name, ext=external_links))
71
72
73 def rewrite_net(service, service_names):
74 if 'net' in service:
75 network_mode = service.pop('net')
76
77 # "container:<service name>" is now "service:<service name>"
78 if network_mode.startswith('container:'):
79 name = network_mode.partition(':')[2]
80 if name in service_names:
81 network_mode = 'service:{}'.format(name)
82
83 service['network_mode'] = network_mode
84
85
86 def rewrite_build(service):
87 if 'dockerfile' in service:
88 service['build'] = {
89 'context': service.pop('build'),
90 'dockerfile': service.pop('dockerfile'),
91 }
92
93
94 def rewrite_logging(service):
95 if 'log_driver' in service:
96 service['logging'] = {'driver': service.pop('log_driver')}
97 if 'log_opt' in service:
98 service['logging']['options'] = service.pop('log_opt')
99
100
101 def rewrite_volumes_from(service, service_names):
102 for idx, volume_from in enumerate(service.get('volumes_from', [])):
103 if volume_from.split(':', 1)[0] not in service_names:
104 service['volumes_from'][idx] = 'container:%s' % volume_from
105
106
107 def create_volumes_section(data):
108 named_volumes = get_named_volumes(data['services'])
109 if named_volumes:
110 log.warn(
111 "Named volumes ({names}) must be explicitly declared. Creating a "
112 "'volumes' section with declarations.\n\n"
113 "For backwards-compatibility, they've been declared as external. "
114 "If you don't mind the volume names being prefixed with the "
115 "project name, you can remove the 'external' option from each one."
116 .format(names=', '.join(list(named_volumes))))
117
118 data['volumes'] = named_volumes
119
120
121 def get_named_volumes(services):
122 volume_specs = [
123 VolumeSpec.parse(volume)
124 for service in services.values()
125 for volume in service.get('volumes', [])
126 ]
127 names = {
128 spec.external
129 for spec in volume_specs
130 if spec.is_named_volume
131 }
132 return {name: {'external': True} for name in names}
133
134
135 def write(stream, new_format, indent, width):
136 ruamel.yaml.dump(
137 new_format,
138 stream,
139 Dumper=ruamel.yaml.RoundTripDumper,
140 indent=indent,
141 width=width)
142
143
144 def parse_opts(args):
145 parser = argparse.ArgumentParser()
146 parser.add_argument("filename", help="Compose file filename.")
147 parser.add_argument("-i", "--in-place", action='store_true')
148 parser.add_argument(
149 "--indent", type=int, default=2,
150 help="Number of spaces used to indent the output yaml.")
151 parser.add_argument(
152 "--width", type=int, default=80,
153 help="Number of spaces used as the output width.")
154 return parser.parse_args()
155
156
157 def main(args):
158 logging.basicConfig(format='\033[33m%(levelname)s:\033[37m %(message)s\n')
159
160 opts = parse_opts(args)
161
162 with open(opts.filename, 'r') as fh:
163 new_format = migrate(fh.read())
164
165 if opts.in_place:
166 output = open(opts.filename, 'w')
167 else:
168 output = sys.stdout
169 write(output, new_format, opts.indent, opts.width)
170
171
172 if __name__ == "__main__":
173 main(sys.argv)
174
[end of contrib/migration/migrate-compose-file-v1-to-v2.py]
[start of script/versions.py]
1 #!/usr/bin/env python
2 """
3 Query the github API for the git tags of a project, and return a list of
4 version tags for recent releases, or the default release.
5
6 The default release is the most recent non-RC version.
7
8 Recent is a list of unqiue major.minor versions, where each is the most
9 recent version in the series.
10
11 For example, if the list of versions is:
12
13 1.8.0-rc2
14 1.8.0-rc1
15 1.7.1
16 1.7.0
17 1.7.0-rc1
18 1.6.2
19 1.6.1
20
21 `default` would return `1.7.1` and
22 `recent -n 3` would return `1.8.0-rc2 1.7.1 1.6.2`
23 """
24 from __future__ import absolute_import
25 from __future__ import print_function
26 from __future__ import unicode_literals
27
28 import argparse
29 import itertools
30 import operator
31 from collections import namedtuple
32
33 import requests
34
35
36 GITHUB_API = 'https://api.github.com/repos'
37
38
39 class Version(namedtuple('_Version', 'major minor patch rc')):
40
41 @classmethod
42 def parse(cls, version):
43 version = version.lstrip('v')
44 version, _, rc = version.partition('-')
45 major, minor, patch = version.split('.', 3)
46 return cls(int(major), int(minor), int(patch), rc)
47
48 @property
49 def major_minor(self):
50 return self.major, self.minor
51
52 @property
53 def order(self):
54 """Return a representation that allows this object to be sorted
55 correctly with the default comparator.
56 """
57 # rc releases should appear before official releases
58 rc = (0, self.rc) if self.rc else (1, )
59 return (self.major, self.minor, self.patch) + rc
60
61 def __str__(self):
62 rc = '-{}'.format(self.rc) if self.rc else ''
63 return '.'.join(map(str, self[:3])) + rc
64
65
66 def group_versions(versions):
67 """Group versions by `major.minor` releases.
68
69 Example:
70
71 >>> group_versions([
72 Version(1, 0, 0),
73 Version(2, 0, 0, 'rc1'),
74 Version(2, 0, 0),
75 Version(2, 1, 0),
76 ])
77
78 [
79 [Version(1, 0, 0)],
80 [Version(2, 0, 0), Version(2, 0, 0, 'rc1')],
81 [Version(2, 1, 0)],
82 ]
83 """
84 return list(
85 list(releases)
86 for _, releases
87 in itertools.groupby(versions, operator.attrgetter('major_minor'))
88 )
89
90
91 def get_latest_versions(versions, num=1):
92 """Return a list of the most recent versions for each major.minor version
93 group.
94 """
95 versions = group_versions(versions)
96 return [versions[index][0] for index in range(num)]
97
98
99 def get_default(versions):
100 """Return a :class:`Version` for the latest non-rc version."""
101 for version in versions:
102 if not version.rc:
103 return version
104
105
106 def get_github_releases(project):
107 """Query the Github API for a list of version tags and return them in
108 sorted order.
109
110 See https://developer.github.com/v3/repos/#list-tags
111 """
112 url = '{}/{}/tags'.format(GITHUB_API, project)
113 response = requests.get(url)
114 response.raise_for_status()
115 versions = [Version.parse(tag['name']) for tag in response.json()]
116 return sorted(versions, reverse=True, key=operator.attrgetter('order'))
117
118
119 def parse_args(argv):
120 parser = argparse.ArgumentParser(description=__doc__)
121 parser.add_argument('project', help="Github project name (ex: docker/docker)")
122 parser.add_argument('command', choices=['recent', 'default'])
123 parser.add_argument('-n', '--num', type=int, default=2,
124 help="Number of versions to return from `recent`")
125 return parser.parse_args(argv)
126
127
128 def main(argv=None):
129 args = parse_args(argv)
130 versions = get_github_releases(args.project)
131
132 if args.command == 'recent':
133 print(' '.join(map(str, get_latest_versions(versions, args.num))))
134 elif args.command == 'default':
135 print(get_default(versions))
136 else:
137 raise ValueError("Unknown command {}".format(args.command))
138
139
140 if __name__ == "__main__":
141 main()
142
[end of script/versions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| docker/compose | 7b5bad6050e337ca41d8f1a0e80b44787534e92f | Merge build args when using multiple compose files (or when extending services)
Based on the behavior of `environment` and `labels`, as well as `build.image`, `build.context` etc, I would also expect `build.args` to be merged, instead of being replaced.
To give an example:
## Input
**docker-compose.yml:**
``` yaml
version: "2"
services:
my_service:
build:
context: my-app
args:
SOME_VARIABLE: "42"
```
**docker-compose.override.yml:**
``` yaml
version: "2"
services:
my_service:
build:
args:
HTTP_PROXY: http://proxy.somewhere:80
HTTPS_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
```
**my-app/Dockerfile**
``` Dockerfile
# Just needed to be able to use `build:`
FROM busybox:latest
ARG SOME_VARIABLE=xyz
RUN echo "$SOME_VARIABLE" > /etc/example
```
## Current Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Expected Output
``` bash
$ docker-compose config
networks: {}
services:
my_service:
build:
args:
SOME_VARIABLE: 42 # Note the merged variable here
HTTPS_PROXY: http://proxy.somewhere:80
HTTP_PROXY: http://proxy.somewhere:80
NO_PROXY: somewhere,localhost
context: <project-dir>\my-app
version: '2.0'
volumes: {}
```
## Version Information
``` bash
$ docker-compose version
docker-compose version 1.6.0, build cdb920a
docker-py version: 1.7.0
CPython version: 2.7.11
OpenSSL version: OpenSSL 1.0.2d 9 Jul 2015
```
# Implementation proposal
I mainly want to get clarification on what the desired behavior is, so that I can possibly help implementing it, maybe even for `1.6.1`.
Personally, I'd like the behavior to be to merge the `build.args` key (as outlined above), for a couple of reasons:
- Principle of least surprise/consistency with `environment`, `labels`, `ports` and so on.
- It enables scenarios like the one outlined above, where the images require some transient configuration to build, in addition to other build variables which actually have an influence on the final image.
The scenario that one wants to replace all build args at once is not very likely IMO; why would you define base build variables in the first place if you're going to replace them anyway?
# Alternative behavior: Output a warning
If the behavior should stay the same as it is now, i.e. to fully replaced the `build.args` keys, then `docker-compose` should at least output a warning IMO. It took me some time to figure out that `docker-compose` was ignoring the build args in the base `docker-compose.yml` file.
| I think we should merge build args. It was probably just overlooked since this is the first time we have nested configuration that we actually want to merge (other nested config like `logging` is not merged by design, because changing one option likely invalidates the rest).
I think the implementation would be to use the new `MergeDict()` object in `merge_build()`. Currently we just use `update()`.
A PR for this would be great!
I'm going to pick this up since it can be fixed at the same time as #2874
| 2016-02-10T18:55:23Z | <patch>
diff --git a/compose/config/config.py b/compose/config/config.py
--- a/compose/config/config.py
+++ b/compose/config/config.py
@@ -713,29 +713,24 @@ def merge_service_dicts(base, override, version):
if version == V1:
legacy_v1_merge_image_or_build(md, base, override)
- else:
- merge_build(md, base, override)
+ elif md.needs_merge('build'):
+ md['build'] = merge_build(md, base, override)
return dict(md)
def merge_build(output, base, override):
- build = {}
-
- if 'build' in base:
- if isinstance(base['build'], six.string_types):
- build['context'] = base['build']
- else:
- build.update(base['build'])
-
- if 'build' in override:
- if isinstance(override['build'], six.string_types):
- build['context'] = override['build']
- else:
- build.update(override['build'])
-
- if build:
- output['build'] = build
+ def to_dict(service):
+ build_config = service.get('build', {})
+ if isinstance(build_config, six.string_types):
+ return {'context': build_config}
+ return build_config
+
+ md = MergeDict(to_dict(base), to_dict(override))
+ md.merge_scalar('context')
+ md.merge_scalar('dockerfile')
+ md.merge_mapping('args', parse_build_arguments)
+ return dict(md)
def legacy_v1_merge_image_or_build(output, base, override):
</patch> | [] | [] | |||
ipython__ipython-13417 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add line number to error messages
As suggested in #13169, it adds line number to error messages, in order to make them more friendly.
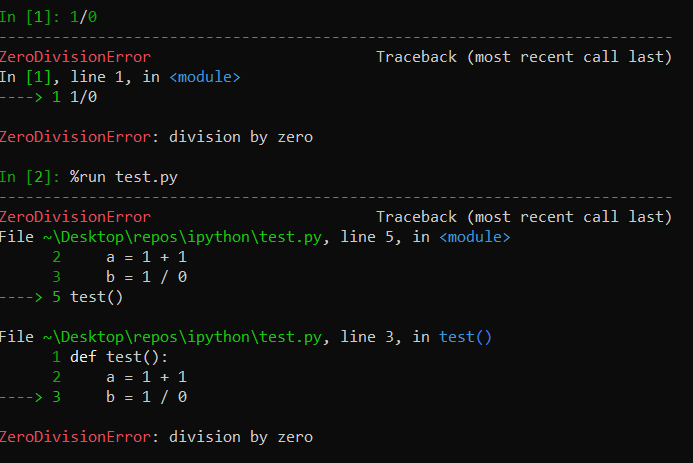
That was the file used in the test
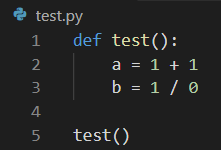
</issue>
<code>
[start of README.rst]
1 .. image:: https://codecov.io/github/ipython/ipython/coverage.svg?branch=master
2 :target: https://codecov.io/github/ipython/ipython?branch=master
3
4 .. image:: https://img.shields.io/pypi/v/IPython.svg
5 :target: https://pypi.python.org/pypi/ipython
6
7 .. image:: https://github.com/ipython/ipython/actions/workflows/test.yml/badge.svg
8 :target: https://github.com/ipython/ipython/actions/workflows/test.yml)
9
10 .. image:: https://www.codetriage.com/ipython/ipython/badges/users.svg
11 :target: https://www.codetriage.com/ipython/ipython/
12
13 .. image:: https://raster.shields.io/badge/Follows-NEP29-brightgreen.png
14 :target: https://numpy.org/neps/nep-0029-deprecation_policy.html
15
16
17 ===========================================
18 IPython: Productive Interactive Computing
19 ===========================================
20
21 Overview
22 ========
23
24 Welcome to IPython. Our full documentation is available on `ipython.readthedocs.io
25 <https://ipython.readthedocs.io/en/stable/>`_ and contains information on how to install, use, and
26 contribute to the project.
27 IPython (Interactive Python) is a command shell for interactive computing in multiple programming languages, originally developed for the Python programming language, that offers introspection, rich media, shell syntax, tab completion, and history.
28
29 **IPython versions and Python Support**
30
31 Starting with IPython 7.10, IPython follows `NEP 29 <https://numpy.org/neps/nep-0029-deprecation_policy.html>`_
32
33 **IPython 7.17+** requires Python version 3.7 and above.
34
35 **IPython 7.10+** requires Python version 3.6 and above.
36
37 **IPython 7.0** requires Python version 3.5 and above.
38
39 **IPython 6.x** requires Python version 3.3 and above.
40
41 **IPython 5.x LTS** is the compatible release for Python 2.7.
42 If you require Python 2 support, you **must** use IPython 5.x LTS. Please
43 update your project configurations and requirements as necessary.
44
45
46 The Notebook, Qt console and a number of other pieces are now parts of *Jupyter*.
47 See the `Jupyter installation docs <https://jupyter.readthedocs.io/en/latest/install.html>`__
48 if you want to use these.
49
50 Main features of IPython
51 ========================
52 Comprehensive object introspection.
53
54 Input history, persistent across sessions.
55
56 Caching of output results during a session with automatically generated references.
57
58 Extensible tab completion, with support by default for completion of python variables and keywords, filenames and function keywords.
59
60 Extensible system of ‘magic’ commands for controlling the environment and performing many tasks related to IPython or the operating system.
61
62 A rich configuration system with easy switching between different setups (simpler than changing $PYTHONSTARTUP environment variables every time).
63
64 Session logging and reloading.
65
66 Extensible syntax processing for special purpose situations.
67
68 Access to the system shell with user-extensible alias system.
69
70 Easily embeddable in other Python programs and GUIs.
71
72 Integrated access to the pdb debugger and the Python profiler.
73
74
75 Development and Instant running
76 ===============================
77
78 You can find the latest version of the development documentation on `readthedocs
79 <https://ipython.readthedocs.io/en/latest/>`_.
80
81 You can run IPython from this directory without even installing it system-wide
82 by typing at the terminal::
83
84 $ python -m IPython
85
86 Or see the `development installation docs
87 <https://ipython.readthedocs.io/en/latest/install/install.html#installing-the-development-version>`_
88 for the latest revision on read the docs.
89
90 Documentation and installation instructions for older version of IPython can be
91 found on the `IPython website <https://ipython.org/documentation.html>`_
92
93
94
95 IPython requires Python version 3 or above
96 ==========================================
97
98 Starting with version 6.0, IPython does not support Python 2.7, 3.0, 3.1, or
99 3.2.
100
101 For a version compatible with Python 2.7, please install the 5.x LTS Long Term
102 Support version.
103
104 If you are encountering this error message you are likely trying to install or
105 use IPython from source. You need to checkout the remote 5.x branch. If you are
106 using git the following should work::
107
108 $ git fetch origin
109 $ git checkout 5.x
110
111 If you encounter this error message with a regular install of IPython, then you
112 likely need to update your package manager, for example if you are using `pip`
113 check the version of pip with::
114
115 $ pip --version
116
117 You will need to update pip to the version 9.0.1 or greater. If you are not using
118 pip, please inquiry with the maintainers of the package for your package
119 manager.
120
121 For more information see one of our blog posts:
122
123 https://blog.jupyter.org/release-of-ipython-5-0-8ce60b8d2e8e
124
125 As well as the following Pull-Request for discussion:
126
127 https://github.com/ipython/ipython/pull/9900
128
129 This error does also occur if you are invoking ``setup.py`` directly – which you
130 should not – or are using ``easy_install`` If this is the case, use ``pip
131 install .`` instead of ``setup.py install`` , and ``pip install -e .`` instead
132 of ``setup.py develop`` If you are depending on IPython as a dependency you may
133 also want to have a conditional dependency on IPython depending on the Python
134 version::
135
136 install_req = ['ipython']
137 if sys.version_info[0] < 3 and 'bdist_wheel' not in sys.argv:
138 install_req.remove('ipython')
139 install_req.append('ipython<6')
140
141 setup(
142 ...
143 install_requires=install_req
144 )
145
146 Alternatives to IPython
147 =======================
148
149 IPython may not be to your taste; if that's the case there might be similar
150 project that you might want to use:
151
152 - The classic Python REPL.
153 - `bpython <https://bpython-interpreter.org/>`_
154 - `mypython <https://www.asmeurer.com/mypython/>`_
155 - `ptpython and ptipython <https://pypi.org/project/ptpython/>`_
156 - `Xonsh <https://xon.sh/>`_
157
158 Ignoring commits with git blame.ignoreRevsFile
159 ==============================================
160
161 As of git 2.23, it is possible to make formatting changes without breaking
162 ``git blame``. See the `git documentation
163 <https://git-scm.com/docs/git-config#Documentation/git-config.txt-blameignoreRevsFile>`_
164 for more details.
165
166 To use this feature you must:
167
168 - Install git >= 2.23
169 - Configure your local git repo by running:
170 - POSIX: ``tools\configure-git-blame-ignore-revs.sh``
171 - Windows: ``tools\configure-git-blame-ignore-revs.bat``
172
[end of README.rst]
[start of IPython/core/display_functions.py]
1 # -*- coding: utf-8 -*-
2 """Top-level display functions for displaying object in different formats."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7
8 from binascii import b2a_hex
9 import os
10 import sys
11
12 __all__ = ['display', 'clear_output', 'publish_display_data', 'update_display', 'DisplayHandle']
13
14 #-----------------------------------------------------------------------------
15 # utility functions
16 #-----------------------------------------------------------------------------
17
18
19 def _merge(d1, d2):
20 """Like update, but merges sub-dicts instead of clobbering at the top level.
21
22 Updates d1 in-place
23 """
24
25 if not isinstance(d2, dict) or not isinstance(d1, dict):
26 return d2
27 for key, value in d2.items():
28 d1[key] = _merge(d1.get(key), value)
29 return d1
30
31
32 #-----------------------------------------------------------------------------
33 # Main functions
34 #-----------------------------------------------------------------------------
35
36
37 # use * to indicate transient is keyword-only
38 def publish_display_data(data, metadata=None, source=None, *, transient=None, **kwargs):
39 """Publish data and metadata to all frontends.
40
41 See the ``display_data`` message in the messaging documentation for
42 more details about this message type.
43
44 Keys of data and metadata can be any mime-type.
45
46 Parameters
47 ----------
48 data : dict
49 A dictionary having keys that are valid MIME types (like
50 'text/plain' or 'image/svg+xml') and values that are the data for
51 that MIME type. The data itself must be a JSON'able data
52 structure. Minimally all data should have the 'text/plain' data,
53 which can be displayed by all frontends. If more than the plain
54 text is given, it is up to the frontend to decide which
55 representation to use.
56 metadata : dict
57 A dictionary for metadata related to the data. This can contain
58 arbitrary key, value pairs that frontends can use to interpret
59 the data. mime-type keys matching those in data can be used
60 to specify metadata about particular representations.
61 source : str, deprecated
62 Unused.
63 transient : dict, keyword-only
64 A dictionary of transient data, such as display_id.
65 """
66 from IPython.core.interactiveshell import InteractiveShell
67
68 display_pub = InteractiveShell.instance().display_pub
69
70 # only pass transient if supplied,
71 # to avoid errors with older ipykernel.
72 # TODO: We could check for ipykernel version and provide a detailed upgrade message.
73 if transient:
74 kwargs['transient'] = transient
75
76 display_pub.publish(
77 data=data,
78 metadata=metadata,
79 **kwargs
80 )
81
82
83 def _new_id():
84 """Generate a new random text id with urandom"""
85 return b2a_hex(os.urandom(16)).decode('ascii')
86
87
88 def display(
89 *objs,
90 include=None,
91 exclude=None,
92 metadata=None,
93 transient=None,
94 display_id=None,
95 raw=False,
96 clear=False,
97 **kwargs
98 ):
99 """Display a Python object in all frontends.
100
101 By default all representations will be computed and sent to the frontends.
102 Frontends can decide which representation is used and how.
103
104 In terminal IPython this will be similar to using :func:`print`, for use in richer
105 frontends see Jupyter notebook examples with rich display logic.
106
107 Parameters
108 ----------
109 *objs : object
110 The Python objects to display.
111 raw : bool, optional
112 Are the objects to be displayed already mimetype-keyed dicts of raw display data,
113 or Python objects that need to be formatted before display? [default: False]
114 include : list, tuple or set, optional
115 A list of format type strings (MIME types) to include in the
116 format data dict. If this is set *only* the format types included
117 in this list will be computed.
118 exclude : list, tuple or set, optional
119 A list of format type strings (MIME types) to exclude in the format
120 data dict. If this is set all format types will be computed,
121 except for those included in this argument.
122 metadata : dict, optional
123 A dictionary of metadata to associate with the output.
124 mime-type keys in this dictionary will be associated with the individual
125 representation formats, if they exist.
126 transient : dict, optional
127 A dictionary of transient data to associate with the output.
128 Data in this dict should not be persisted to files (e.g. notebooks).
129 display_id : str, bool optional
130 Set an id for the display.
131 This id can be used for updating this display area later via update_display.
132 If given as `True`, generate a new `display_id`
133 clear : bool, optional
134 Should the output area be cleared before displaying anything? If True,
135 this will wait for additional output before clearing. [default: False]
136 **kwargs : additional keyword-args, optional
137 Additional keyword-arguments are passed through to the display publisher.
138
139 Returns
140 -------
141 handle: DisplayHandle
142 Returns a handle on updatable displays for use with :func:`update_display`,
143 if `display_id` is given. Returns :any:`None` if no `display_id` is given
144 (default).
145
146 Examples
147 --------
148 >>> class Json(object):
149 ... def __init__(self, json):
150 ... self.json = json
151 ... def _repr_pretty_(self, pp, cycle):
152 ... import json
153 ... pp.text(json.dumps(self.json, indent=2))
154 ... def __repr__(self):
155 ... return str(self.json)
156 ...
157
158 >>> d = Json({1:2, 3: {4:5}})
159
160 >>> print(d)
161 {1: 2, 3: {4: 5}}
162
163 >>> display(d)
164 {
165 "1": 2,
166 "3": {
167 "4": 5
168 }
169 }
170
171 >>> def int_formatter(integer, pp, cycle):
172 ... pp.text('I'*integer)
173
174 >>> plain = get_ipython().display_formatter.formatters['text/plain']
175 >>> plain.for_type(int, int_formatter)
176 <function _repr_pprint at 0x...>
177 >>> display(7-5)
178 II
179
180 >>> del plain.type_printers[int]
181 >>> display(7-5)
182 2
183
184 See Also
185 --------
186 :func:`update_display`
187
188 Notes
189 -----
190 In Python, objects can declare their textual representation using the
191 `__repr__` method. IPython expands on this idea and allows objects to declare
192 other, rich representations including:
193
194 - HTML
195 - JSON
196 - PNG
197 - JPEG
198 - SVG
199 - LaTeX
200
201 A single object can declare some or all of these representations; all are
202 handled by IPython's display system.
203
204 The main idea of the first approach is that you have to implement special
205 display methods when you define your class, one for each representation you
206 want to use. Here is a list of the names of the special methods and the
207 values they must return:
208
209 - `_repr_html_`: return raw HTML as a string, or a tuple (see below).
210 - `_repr_json_`: return a JSONable dict, or a tuple (see below).
211 - `_repr_jpeg_`: return raw JPEG data, or a tuple (see below).
212 - `_repr_png_`: return raw PNG data, or a tuple (see below).
213 - `_repr_svg_`: return raw SVG data as a string, or a tuple (see below).
214 - `_repr_latex_`: return LaTeX commands in a string surrounded by "$",
215 or a tuple (see below).
216 - `_repr_mimebundle_`: return a full mimebundle containing the mapping
217 from all mimetypes to data.
218 Use this for any mime-type not listed above.
219
220 The above functions may also return the object's metadata alonside the
221 data. If the metadata is available, the functions will return a tuple
222 containing the data and metadata, in that order. If there is no metadata
223 available, then the functions will return the data only.
224
225 When you are directly writing your own classes, you can adapt them for
226 display in IPython by following the above approach. But in practice, you
227 often need to work with existing classes that you can't easily modify.
228
229 You can refer to the documentation on integrating with the display system in
230 order to register custom formatters for already existing types
231 (:ref:`integrating_rich_display`).
232
233 .. versionadded:: 5.4 display available without import
234 .. versionadded:: 6.1 display available without import
235
236 Since IPython 5.4 and 6.1 :func:`display` is automatically made available to
237 the user without import. If you are using display in a document that might
238 be used in a pure python context or with older version of IPython, use the
239 following import at the top of your file::
240
241 from IPython.display import display
242
243 """
244 from IPython.core.interactiveshell import InteractiveShell
245
246 if not InteractiveShell.initialized():
247 # Directly print objects.
248 print(*objs)
249 return
250
251 if transient is None:
252 transient = {}
253 if metadata is None:
254 metadata={}
255 if display_id:
256 if display_id is True:
257 display_id = _new_id()
258 transient['display_id'] = display_id
259 if kwargs.get('update') and 'display_id' not in transient:
260 raise TypeError('display_id required for update_display')
261 if transient:
262 kwargs['transient'] = transient
263
264 if not objs and display_id:
265 # if given no objects, but still a request for a display_id,
266 # we assume the user wants to insert an empty output that
267 # can be updated later
268 objs = [{}]
269 raw = True
270
271 if not raw:
272 format = InteractiveShell.instance().display_formatter.format
273
274 if clear:
275 clear_output(wait=True)
276
277 for obj in objs:
278 if raw:
279 publish_display_data(data=obj, metadata=metadata, **kwargs)
280 else:
281 format_dict, md_dict = format(obj, include=include, exclude=exclude)
282 if not format_dict:
283 # nothing to display (e.g. _ipython_display_ took over)
284 continue
285 if metadata:
286 # kwarg-specified metadata gets precedence
287 _merge(md_dict, metadata)
288 publish_display_data(data=format_dict, metadata=md_dict, **kwargs)
289 if display_id:
290 return DisplayHandle(display_id)
291
292
293 # use * for keyword-only display_id arg
294 def update_display(obj, *, display_id, **kwargs):
295 """Update an existing display by id
296
297 Parameters
298 ----------
299 obj
300 The object with which to update the display
301 display_id : keyword-only
302 The id of the display to update
303
304 See Also
305 --------
306 :func:`display`
307 """
308 kwargs['update'] = True
309 display(obj, display_id=display_id, **kwargs)
310
311
312 class DisplayHandle(object):
313 """A handle on an updatable display
314
315 Call `.update(obj)` to display a new object.
316
317 Call `.display(obj`) to add a new instance of this display,
318 and update existing instances.
319
320 See Also
321 --------
322
323 :func:`display`, :func:`update_display`
324
325 """
326
327 def __init__(self, display_id=None):
328 if display_id is None:
329 display_id = _new_id()
330 self.display_id = display_id
331
332 def __repr__(self):
333 return "<%s display_id=%s>" % (self.__class__.__name__, self.display_id)
334
335 def display(self, obj, **kwargs):
336 """Make a new display with my id, updating existing instances.
337
338 Parameters
339 ----------
340 obj
341 object to display
342 **kwargs
343 additional keyword arguments passed to display
344 """
345 display(obj, display_id=self.display_id, **kwargs)
346
347 def update(self, obj, **kwargs):
348 """Update existing displays with my id
349
350 Parameters
351 ----------
352 obj
353 object to display
354 **kwargs
355 additional keyword arguments passed to update_display
356 """
357 update_display(obj, display_id=self.display_id, **kwargs)
358
359
360 def clear_output(wait=False):
361 """Clear the output of the current cell receiving output.
362
363 Parameters
364 ----------
365 wait : bool [default: false]
366 Wait to clear the output until new output is available to replace it."""
367 from IPython.core.interactiveshell import InteractiveShell
368 if InteractiveShell.initialized():
369 InteractiveShell.instance().display_pub.clear_output(wait)
370 else:
371 print('\033[2K\r', end='')
372 sys.stdout.flush()
373 print('\033[2K\r', end='')
374 sys.stderr.flush()
375
[end of IPython/core/display_functions.py]
[start of IPython/core/displaypub.py]
1 """An interface for publishing rich data to frontends.
2
3 There are two components of the display system:
4
5 * Display formatters, which take a Python object and compute the
6 representation of the object in various formats (text, HTML, SVG, etc.).
7 * The display publisher that is used to send the representation data to the
8 various frontends.
9
10 This module defines the logic display publishing. The display publisher uses
11 the ``display_data`` message type that is defined in the IPython messaging
12 spec.
13 """
14
15 # Copyright (c) IPython Development Team.
16 # Distributed under the terms of the Modified BSD License.
17
18
19 import sys
20
21 from traitlets.config.configurable import Configurable
22 from traitlets import List
23
24 # This used to be defined here - it is imported for backwards compatibility
25 from .display_functions import publish_display_data
26
27 #-----------------------------------------------------------------------------
28 # Main payload class
29 #-----------------------------------------------------------------------------
30
31
32 class DisplayPublisher(Configurable):
33 """A traited class that publishes display data to frontends.
34
35 Instances of this class are created by the main IPython object and should
36 be accessed there.
37 """
38
39 def __init__(self, shell=None, *args, **kwargs):
40 self.shell = shell
41 super().__init__(*args, **kwargs)
42
43 def _validate_data(self, data, metadata=None):
44 """Validate the display data.
45
46 Parameters
47 ----------
48 data : dict
49 The formata data dictionary.
50 metadata : dict
51 Any metadata for the data.
52 """
53
54 if not isinstance(data, dict):
55 raise TypeError('data must be a dict, got: %r' % data)
56 if metadata is not None:
57 if not isinstance(metadata, dict):
58 raise TypeError('metadata must be a dict, got: %r' % data)
59
60 # use * to indicate transient, update are keyword-only
61 def publish(self, data, metadata=None, source=None, *, transient=None, update=False, **kwargs) -> None:
62 """Publish data and metadata to all frontends.
63
64 See the ``display_data`` message in the messaging documentation for
65 more details about this message type.
66
67 The following MIME types are currently implemented:
68
69 * text/plain
70 * text/html
71 * text/markdown
72 * text/latex
73 * application/json
74 * application/javascript
75 * image/png
76 * image/jpeg
77 * image/svg+xml
78
79 Parameters
80 ----------
81 data : dict
82 A dictionary having keys that are valid MIME types (like
83 'text/plain' or 'image/svg+xml') and values that are the data for
84 that MIME type. The data itself must be a JSON'able data
85 structure. Minimally all data should have the 'text/plain' data,
86 which can be displayed by all frontends. If more than the plain
87 text is given, it is up to the frontend to decide which
88 representation to use.
89 metadata : dict
90 A dictionary for metadata related to the data. This can contain
91 arbitrary key, value pairs that frontends can use to interpret
92 the data. Metadata specific to each mime-type can be specified
93 in the metadata dict with the same mime-type keys as
94 the data itself.
95 source : str, deprecated
96 Unused.
97 transient : dict, keyword-only
98 A dictionary for transient data.
99 Data in this dictionary should not be persisted as part of saving this output.
100 Examples include 'display_id'.
101 update : bool, keyword-only, default: False
102 If True, only update existing outputs with the same display_id,
103 rather than creating a new output.
104 """
105
106 handlers = {}
107 if self.shell is not None:
108 handlers = getattr(self.shell, 'mime_renderers', {})
109
110 for mime, handler in handlers.items():
111 if mime in data:
112 handler(data[mime], metadata.get(mime, None))
113 return
114
115 if 'text/plain' in data:
116 print(data['text/plain'])
117
118 def clear_output(self, wait=False):
119 """Clear the output of the cell receiving output."""
120 print('\033[2K\r', end='')
121 sys.stdout.flush()
122 print('\033[2K\r', end='')
123 sys.stderr.flush()
124
125
126 class CapturingDisplayPublisher(DisplayPublisher):
127 """A DisplayPublisher that stores"""
128 outputs = List()
129
130 def publish(self, data, metadata=None, source=None, *, transient=None, update=False):
131 self.outputs.append({'data':data, 'metadata':metadata,
132 'transient':transient, 'update':update})
133
134 def clear_output(self, wait=False):
135 super(CapturingDisplayPublisher, self).clear_output(wait)
136
137 # empty the list, *do not* reassign a new list
138 self.outputs.clear()
139
[end of IPython/core/displaypub.py]
[start of IPython/core/pylabtools.py]
1 # -*- coding: utf-8 -*-
2 """Pylab (matplotlib) support utilities."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 from io import BytesIO
8 from binascii import b2a_base64
9 from functools import partial
10 import warnings
11
12 from IPython.core.display import _pngxy
13 from IPython.utils.decorators import flag_calls
14
15 # If user specifies a GUI, that dictates the backend, otherwise we read the
16 # user's mpl default from the mpl rc structure
17 backends = {
18 "tk": "TkAgg",
19 "gtk": "GTKAgg",
20 "gtk3": "GTK3Agg",
21 "gtk4": "GTK4Agg",
22 "wx": "WXAgg",
23 "qt4": "Qt4Agg",
24 "qt5": "Qt5Agg",
25 "qt6": "QtAgg",
26 "qt": "Qt5Agg",
27 "osx": "MacOSX",
28 "nbagg": "nbAgg",
29 "notebook": "nbAgg",
30 "agg": "agg",
31 "svg": "svg",
32 "pdf": "pdf",
33 "ps": "ps",
34 "inline": "module://matplotlib_inline.backend_inline",
35 "ipympl": "module://ipympl.backend_nbagg",
36 "widget": "module://ipympl.backend_nbagg",
37 }
38
39 # We also need a reverse backends2guis mapping that will properly choose which
40 # GUI support to activate based on the desired matplotlib backend. For the
41 # most part it's just a reverse of the above dict, but we also need to add a
42 # few others that map to the same GUI manually:
43 backend2gui = dict(zip(backends.values(), backends.keys()))
44 # In the reverse mapping, there are a few extra valid matplotlib backends that
45 # map to the same GUI support
46 backend2gui["GTK"] = backend2gui["GTKCairo"] = "gtk"
47 backend2gui["GTK3Cairo"] = "gtk3"
48 backend2gui["GTK4Cairo"] = "gtk4"
49 backend2gui["WX"] = "wx"
50 backend2gui["CocoaAgg"] = "osx"
51 # There needs to be a hysteresis here as the new QtAgg Matplotlib backend
52 # supports either Qt5 or Qt6 and the IPython qt event loop support Qt4, Qt5,
53 # and Qt6.
54 backend2gui["QtAgg"] = "qt"
55 backend2gui["Qt4Agg"] = "qt"
56 backend2gui["Qt5Agg"] = "qt"
57
58 # And some backends that don't need GUI integration
59 del backend2gui["nbAgg"]
60 del backend2gui["agg"]
61 del backend2gui["svg"]
62 del backend2gui["pdf"]
63 del backend2gui["ps"]
64 del backend2gui["module://matplotlib_inline.backend_inline"]
65 del backend2gui["module://ipympl.backend_nbagg"]
66
67 #-----------------------------------------------------------------------------
68 # Matplotlib utilities
69 #-----------------------------------------------------------------------------
70
71
72 def getfigs(*fig_nums):
73 """Get a list of matplotlib figures by figure numbers.
74
75 If no arguments are given, all available figures are returned. If the
76 argument list contains references to invalid figures, a warning is printed
77 but the function continues pasting further figures.
78
79 Parameters
80 ----------
81 figs : tuple
82 A tuple of ints giving the figure numbers of the figures to return.
83 """
84 from matplotlib._pylab_helpers import Gcf
85 if not fig_nums:
86 fig_managers = Gcf.get_all_fig_managers()
87 return [fm.canvas.figure for fm in fig_managers]
88 else:
89 figs = []
90 for num in fig_nums:
91 f = Gcf.figs.get(num)
92 if f is None:
93 print('Warning: figure %s not available.' % num)
94 else:
95 figs.append(f.canvas.figure)
96 return figs
97
98
99 def figsize(sizex, sizey):
100 """Set the default figure size to be [sizex, sizey].
101
102 This is just an easy to remember, convenience wrapper that sets::
103
104 matplotlib.rcParams['figure.figsize'] = [sizex, sizey]
105 """
106 import matplotlib
107 matplotlib.rcParams['figure.figsize'] = [sizex, sizey]
108
109
110 def print_figure(fig, fmt="png", bbox_inches="tight", base64=False, **kwargs):
111 """Print a figure to an image, and return the resulting file data
112
113 Returned data will be bytes unless ``fmt='svg'``,
114 in which case it will be unicode.
115
116 Any keyword args are passed to fig.canvas.print_figure,
117 such as ``quality`` or ``bbox_inches``.
118
119 If `base64` is True, return base64-encoded str instead of raw bytes
120 for binary-encoded image formats
121
122 .. versionadded:: 7.29
123 base64 argument
124 """
125 # When there's an empty figure, we shouldn't return anything, otherwise we
126 # get big blank areas in the qt console.
127 if not fig.axes and not fig.lines:
128 return
129
130 dpi = fig.dpi
131 if fmt == 'retina':
132 dpi = dpi * 2
133 fmt = 'png'
134
135 # build keyword args
136 kw = {
137 "format":fmt,
138 "facecolor":fig.get_facecolor(),
139 "edgecolor":fig.get_edgecolor(),
140 "dpi":dpi,
141 "bbox_inches":bbox_inches,
142 }
143 # **kwargs get higher priority
144 kw.update(kwargs)
145
146 bytes_io = BytesIO()
147 if fig.canvas is None:
148 from matplotlib.backend_bases import FigureCanvasBase
149 FigureCanvasBase(fig)
150
151 fig.canvas.print_figure(bytes_io, **kw)
152 data = bytes_io.getvalue()
153 if fmt == 'svg':
154 data = data.decode('utf-8')
155 elif base64:
156 data = b2a_base64(data).decode("ascii")
157 return data
158
159 def retina_figure(fig, base64=False, **kwargs):
160 """format a figure as a pixel-doubled (retina) PNG
161
162 If `base64` is True, return base64-encoded str instead of raw bytes
163 for binary-encoded image formats
164
165 .. versionadded:: 7.29
166 base64 argument
167 """
168 pngdata = print_figure(fig, fmt="retina", base64=False, **kwargs)
169 # Make sure that retina_figure acts just like print_figure and returns
170 # None when the figure is empty.
171 if pngdata is None:
172 return
173 w, h = _pngxy(pngdata)
174 metadata = {"width": w//2, "height":h//2}
175 if base64:
176 pngdata = b2a_base64(pngdata).decode("ascii")
177 return pngdata, metadata
178
179
180 # We need a little factory function here to create the closure where
181 # safe_execfile can live.
182 def mpl_runner(safe_execfile):
183 """Factory to return a matplotlib-enabled runner for %run.
184
185 Parameters
186 ----------
187 safe_execfile : function
188 This must be a function with the same interface as the
189 :meth:`safe_execfile` method of IPython.
190
191 Returns
192 -------
193 A function suitable for use as the ``runner`` argument of the %run magic
194 function.
195 """
196
197 def mpl_execfile(fname,*where,**kw):
198 """matplotlib-aware wrapper around safe_execfile.
199
200 Its interface is identical to that of the :func:`execfile` builtin.
201
202 This is ultimately a call to execfile(), but wrapped in safeties to
203 properly handle interactive rendering."""
204
205 import matplotlib
206 import matplotlib.pyplot as plt
207
208 #print '*** Matplotlib runner ***' # dbg
209 # turn off rendering until end of script
210 is_interactive = matplotlib.rcParams['interactive']
211 matplotlib.interactive(False)
212 safe_execfile(fname,*where,**kw)
213 matplotlib.interactive(is_interactive)
214 # make rendering call now, if the user tried to do it
215 if plt.draw_if_interactive.called:
216 plt.draw()
217 plt.draw_if_interactive.called = False
218
219 # re-draw everything that is stale
220 try:
221 da = plt.draw_all
222 except AttributeError:
223 pass
224 else:
225 da()
226
227 return mpl_execfile
228
229
230 def _reshow_nbagg_figure(fig):
231 """reshow an nbagg figure"""
232 try:
233 reshow = fig.canvas.manager.reshow
234 except AttributeError as e:
235 raise NotImplementedError() from e
236 else:
237 reshow()
238
239
240 def select_figure_formats(shell, formats, **kwargs):
241 """Select figure formats for the inline backend.
242
243 Parameters
244 ----------
245 shell : InteractiveShell
246 The main IPython instance.
247 formats : str or set
248 One or a set of figure formats to enable: 'png', 'retina', 'jpeg', 'svg', 'pdf'.
249 **kwargs : any
250 Extra keyword arguments to be passed to fig.canvas.print_figure.
251 """
252 import matplotlib
253 from matplotlib.figure import Figure
254
255 svg_formatter = shell.display_formatter.formatters['image/svg+xml']
256 png_formatter = shell.display_formatter.formatters['image/png']
257 jpg_formatter = shell.display_formatter.formatters['image/jpeg']
258 pdf_formatter = shell.display_formatter.formatters['application/pdf']
259
260 if isinstance(formats, str):
261 formats = {formats}
262 # cast in case of list / tuple
263 formats = set(formats)
264
265 [ f.pop(Figure, None) for f in shell.display_formatter.formatters.values() ]
266 mplbackend = matplotlib.get_backend().lower()
267 if mplbackend == 'nbagg' or mplbackend == 'module://ipympl.backend_nbagg':
268 formatter = shell.display_formatter.ipython_display_formatter
269 formatter.for_type(Figure, _reshow_nbagg_figure)
270
271 supported = {'png', 'png2x', 'retina', 'jpg', 'jpeg', 'svg', 'pdf'}
272 bad = formats.difference(supported)
273 if bad:
274 bs = "%s" % ','.join([repr(f) for f in bad])
275 gs = "%s" % ','.join([repr(f) for f in supported])
276 raise ValueError("supported formats are: %s not %s" % (gs, bs))
277
278 if "png" in formats:
279 png_formatter.for_type(
280 Figure, partial(print_figure, fmt="png", base64=True, **kwargs)
281 )
282 if "retina" in formats or "png2x" in formats:
283 png_formatter.for_type(Figure, partial(retina_figure, base64=True, **kwargs))
284 if "jpg" in formats or "jpeg" in formats:
285 jpg_formatter.for_type(
286 Figure, partial(print_figure, fmt="jpg", base64=True, **kwargs)
287 )
288 if "svg" in formats:
289 svg_formatter.for_type(Figure, partial(print_figure, fmt="svg", **kwargs))
290 if "pdf" in formats:
291 pdf_formatter.for_type(
292 Figure, partial(print_figure, fmt="pdf", base64=True, **kwargs)
293 )
294
295 #-----------------------------------------------------------------------------
296 # Code for initializing matplotlib and importing pylab
297 #-----------------------------------------------------------------------------
298
299
300 def find_gui_and_backend(gui=None, gui_select=None):
301 """Given a gui string return the gui and mpl backend.
302
303 Parameters
304 ----------
305 gui : str
306 Can be one of ('tk','gtk','wx','qt','qt4','inline','agg').
307 gui_select : str
308 Can be one of ('tk','gtk','wx','qt','qt4','inline').
309 This is any gui already selected by the shell.
310
311 Returns
312 -------
313 A tuple of (gui, backend) where backend is one of ('TkAgg','GTKAgg',
314 'WXAgg','Qt4Agg','module://matplotlib_inline.backend_inline','agg').
315 """
316
317 import matplotlib
318
319 if gui and gui != 'auto':
320 # select backend based on requested gui
321 backend = backends[gui]
322 if gui == 'agg':
323 gui = None
324 else:
325 # We need to read the backend from the original data structure, *not*
326 # from mpl.rcParams, since a prior invocation of %matplotlib may have
327 # overwritten that.
328 # WARNING: this assumes matplotlib 1.1 or newer!!
329 backend = matplotlib.rcParamsOrig['backend']
330 # In this case, we need to find what the appropriate gui selection call
331 # should be for IPython, so we can activate inputhook accordingly
332 gui = backend2gui.get(backend, None)
333
334 # If we have already had a gui active, we need it and inline are the
335 # ones allowed.
336 if gui_select and gui != gui_select:
337 gui = gui_select
338 backend = backends[gui]
339
340 return gui, backend
341
342
343 def activate_matplotlib(backend):
344 """Activate the given backend and set interactive to True."""
345
346 import matplotlib
347 matplotlib.interactive(True)
348
349 # Matplotlib had a bug where even switch_backend could not force
350 # the rcParam to update. This needs to be set *before* the module
351 # magic of switch_backend().
352 matplotlib.rcParams['backend'] = backend
353
354 # Due to circular imports, pyplot may be only partially initialised
355 # when this function runs.
356 # So avoid needing matplotlib attribute-lookup to access pyplot.
357 from matplotlib import pyplot as plt
358
359 plt.switch_backend(backend)
360
361 plt.show._needmain = False
362 # We need to detect at runtime whether show() is called by the user.
363 # For this, we wrap it into a decorator which adds a 'called' flag.
364 plt.draw_if_interactive = flag_calls(plt.draw_if_interactive)
365
366
367 def import_pylab(user_ns, import_all=True):
368 """Populate the namespace with pylab-related values.
369
370 Imports matplotlib, pylab, numpy, and everything from pylab and numpy.
371
372 Also imports a few names from IPython (figsize, display, getfigs)
373
374 """
375
376 # Import numpy as np/pyplot as plt are conventions we're trying to
377 # somewhat standardize on. Making them available to users by default
378 # will greatly help this.
379 s = ("import numpy\n"
380 "import matplotlib\n"
381 "from matplotlib import pylab, mlab, pyplot\n"
382 "np = numpy\n"
383 "plt = pyplot\n"
384 )
385 exec(s, user_ns)
386
387 if import_all:
388 s = ("from matplotlib.pylab import *\n"
389 "from numpy import *\n")
390 exec(s, user_ns)
391
392 # IPython symbols to add
393 user_ns['figsize'] = figsize
394 from IPython.display import display
395 # Add display and getfigs to the user's namespace
396 user_ns['display'] = display
397 user_ns['getfigs'] = getfigs
398
399
400 def configure_inline_support(shell, backend):
401 """
402 .. deprecated:: 7.23
403
404 use `matplotlib_inline.backend_inline.configure_inline_support()`
405
406 Configure an IPython shell object for matplotlib use.
407
408 Parameters
409 ----------
410 shell : InteractiveShell instance
411 backend : matplotlib backend
412 """
413 warnings.warn(
414 "`configure_inline_support` is deprecated since IPython 7.23, directly "
415 "use `matplotlib_inline.backend_inline.configure_inline_support()`",
416 DeprecationWarning,
417 stacklevel=2,
418 )
419
420 from matplotlib_inline.backend_inline import (
421 configure_inline_support as configure_inline_support_orig,
422 )
423
424 configure_inline_support_orig(shell, backend)
425
[end of IPython/core/pylabtools.py]
[start of IPython/lib/latextools.py]
1 # -*- coding: utf-8 -*-
2 """Tools for handling LaTeX."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 from io import BytesIO, open
8 import os
9 import tempfile
10 import shutil
11 import subprocess
12 from base64 import encodebytes
13 import textwrap
14
15 from pathlib import Path, PurePath
16
17 from IPython.utils.process import find_cmd, FindCmdError
18 from traitlets.config import get_config
19 from traitlets.config.configurable import SingletonConfigurable
20 from traitlets import List, Bool, Unicode
21 from IPython.utils.py3compat import cast_unicode
22
23
24 class LaTeXTool(SingletonConfigurable):
25 """An object to store configuration of the LaTeX tool."""
26 def _config_default(self):
27 return get_config()
28
29 backends = List(
30 Unicode(), ["matplotlib", "dvipng"],
31 help="Preferred backend to draw LaTeX math equations. "
32 "Backends in the list are checked one by one and the first "
33 "usable one is used. Note that `matplotlib` backend "
34 "is usable only for inline style equations. To draw "
35 "display style equations, `dvipng` backend must be specified. ",
36 # It is a List instead of Enum, to make configuration more
37 # flexible. For example, to use matplotlib mainly but dvipng
38 # for display style, the default ["matplotlib", "dvipng"] can
39 # be used. To NOT use dvipng so that other repr such as
40 # unicode pretty printing is used, you can use ["matplotlib"].
41 ).tag(config=True)
42
43 use_breqn = Bool(
44 True,
45 help="Use breqn.sty to automatically break long equations. "
46 "This configuration takes effect only for dvipng backend.",
47 ).tag(config=True)
48
49 packages = List(
50 ['amsmath', 'amsthm', 'amssymb', 'bm'],
51 help="A list of packages to use for dvipng backend. "
52 "'breqn' will be automatically appended when use_breqn=True.",
53 ).tag(config=True)
54
55 preamble = Unicode(
56 help="Additional preamble to use when generating LaTeX source "
57 "for dvipng backend.",
58 ).tag(config=True)
59
60
61 def latex_to_png(s, encode=False, backend=None, wrap=False, color='Black',
62 scale=1.0):
63 """Render a LaTeX string to PNG.
64
65 Parameters
66 ----------
67 s : str
68 The raw string containing valid inline LaTeX.
69 encode : bool, optional
70 Should the PNG data base64 encoded to make it JSON'able.
71 backend : {matplotlib, dvipng}
72 Backend for producing PNG data.
73 wrap : bool
74 If true, Automatically wrap `s` as a LaTeX equation.
75 color : string
76 Foreground color name among dvipsnames, e.g. 'Maroon' or on hex RGB
77 format, e.g. '#AA20FA'.
78 scale : float
79 Scale factor for the resulting PNG.
80 None is returned when the backend cannot be used.
81
82 """
83 s = cast_unicode(s)
84 allowed_backends = LaTeXTool.instance().backends
85 if backend is None:
86 backend = allowed_backends[0]
87 if backend not in allowed_backends:
88 return None
89 if backend == 'matplotlib':
90 f = latex_to_png_mpl
91 elif backend == 'dvipng':
92 f = latex_to_png_dvipng
93 if color.startswith('#'):
94 # Convert hex RGB color to LaTeX RGB color.
95 if len(color) == 7:
96 try:
97 color = "RGB {}".format(" ".join([str(int(x, 16)) for x in
98 textwrap.wrap(color[1:], 2)]))
99 except ValueError as e:
100 raise ValueError('Invalid color specification {}.'.format(color)) from e
101 else:
102 raise ValueError('Invalid color specification {}.'.format(color))
103 else:
104 raise ValueError('No such backend {0}'.format(backend))
105 bin_data = f(s, wrap, color, scale)
106 if encode and bin_data:
107 bin_data = encodebytes(bin_data)
108 return bin_data
109
110
111 def latex_to_png_mpl(s, wrap, color='Black', scale=1.0):
112 try:
113 from matplotlib import figure, font_manager, mathtext
114 from matplotlib.backends import backend_agg
115 from pyparsing import ParseFatalException
116 except ImportError:
117 return None
118
119 # mpl mathtext doesn't support display math, force inline
120 s = s.replace('$$', '$')
121 if wrap:
122 s = u'${0}$'.format(s)
123
124 try:
125 prop = font_manager.FontProperties(size=12)
126 dpi = 120 * scale
127 buffer = BytesIO()
128
129 # Adapted from mathtext.math_to_image
130 parser = mathtext.MathTextParser("path")
131 width, height, depth, _, _ = parser.parse(s, dpi=72, prop=prop)
132 fig = figure.Figure(figsize=(width / 72, height / 72))
133 fig.text(0, depth / height, s, fontproperties=prop, color=color)
134 backend_agg.FigureCanvasAgg(fig)
135 fig.savefig(buffer, dpi=dpi, format="png", transparent=True)
136 return buffer.getvalue()
137 except (ValueError, RuntimeError, ParseFatalException):
138 return None
139
140
141 def latex_to_png_dvipng(s, wrap, color='Black', scale=1.0):
142 try:
143 find_cmd('latex')
144 find_cmd('dvipng')
145 except FindCmdError:
146 return None
147 try:
148 workdir = Path(tempfile.mkdtemp())
149 tmpfile = workdir.joinpath("tmp.tex")
150 dvifile = workdir.joinpath("tmp.dvi")
151 outfile = workdir.joinpath("tmp.png")
152
153 with tmpfile.open("w", encoding="utf8") as f:
154 f.writelines(genelatex(s, wrap))
155
156 with open(os.devnull, 'wb') as devnull:
157 subprocess.check_call(
158 ["latex", "-halt-on-error", "-interaction", "batchmode", tmpfile],
159 cwd=workdir, stdout=devnull, stderr=devnull)
160
161 resolution = round(150*scale)
162 subprocess.check_call(
163 [
164 "dvipng",
165 "-T",
166 "tight",
167 "-D",
168 str(resolution),
169 "-z",
170 "9",
171 "-bg",
172 "Transparent",
173 "-o",
174 outfile,
175 dvifile,
176 "-fg",
177 color,
178 ],
179 cwd=workdir,
180 stdout=devnull,
181 stderr=devnull,
182 )
183
184 with outfile.open("rb") as f:
185 return f.read()
186 except subprocess.CalledProcessError:
187 return None
188 finally:
189 shutil.rmtree(workdir)
190
191
192 def kpsewhich(filename):
193 """Invoke kpsewhich command with an argument `filename`."""
194 try:
195 find_cmd("kpsewhich")
196 proc = subprocess.Popen(
197 ["kpsewhich", filename],
198 stdout=subprocess.PIPE, stderr=subprocess.PIPE)
199 (stdout, stderr) = proc.communicate()
200 return stdout.strip().decode('utf8', 'replace')
201 except FindCmdError:
202 pass
203
204
205 def genelatex(body, wrap):
206 """Generate LaTeX document for dvipng backend."""
207 lt = LaTeXTool.instance()
208 breqn = wrap and lt.use_breqn and kpsewhich("breqn.sty")
209 yield r'\documentclass{article}'
210 packages = lt.packages
211 if breqn:
212 packages = packages + ['breqn']
213 for pack in packages:
214 yield r'\usepackage{{{0}}}'.format(pack)
215 yield r'\pagestyle{empty}'
216 if lt.preamble:
217 yield lt.preamble
218 yield r'\begin{document}'
219 if breqn:
220 yield r'\begin{dmath*}'
221 yield body
222 yield r'\end{dmath*}'
223 elif wrap:
224 yield u'$${0}$$'.format(body)
225 else:
226 yield body
227 yield u'\\end{document}'
228
229
230 _data_uri_template_png = u"""<img src="data:image/png;base64,%s" alt=%s />"""
231
232 def latex_to_html(s, alt='image'):
233 """Render LaTeX to HTML with embedded PNG data using data URIs.
234
235 Parameters
236 ----------
237 s : str
238 The raw string containing valid inline LateX.
239 alt : str
240 The alt text to use for the HTML.
241 """
242 base64_data = latex_to_png(s, encode=True).decode('ascii')
243 if base64_data:
244 return _data_uri_template_png % (base64_data, alt)
245
246
247
[end of IPython/lib/latextools.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| ipython/ipython | 1d7bb78d04ac5cb8698adb70b2b76528a1b2a0f1 | Add line number to error messages
As suggested in #13169, it adds line number to error messages, in order to make them more friendly.

That was the file used in the test

| 2021-12-24T12:16:30Z | <patch>
diff --git a/IPython/core/ultratb.py b/IPython/core/ultratb.py
--- a/IPython/core/ultratb.py
+++ b/IPython/core/ultratb.py
@@ -169,7 +169,7 @@ def _format_traceback_lines(lines, Colors, has_colors, lvals):
return res
-def _format_filename(file, ColorFilename, ColorNormal):
+def _format_filename(file, ColorFilename, ColorNormal, *, lineno=None):
"""
Format filename lines with `In [n]` if it's the nth code cell or `File *.py` if it's a module.
@@ -185,14 +185,17 @@ def _format_filename(file, ColorFilename, ColorNormal):
if ipinst is not None and file in ipinst.compile._filename_map:
file = "[%s]" % ipinst.compile._filename_map[file]
- tpl_link = "Input %sIn %%s%s" % (ColorFilename, ColorNormal)
+ tpl_link = f"Input {ColorFilename}In {{file}}{ColorNormal}"
else:
file = util_path.compress_user(
py3compat.cast_unicode(file, util_path.fs_encoding)
)
- tpl_link = "File %s%%s%s" % (ColorFilename, ColorNormal)
+ if lineno is None:
+ tpl_link = f"File {ColorFilename}{{file}}{ColorNormal}"
+ else:
+ tpl_link = f"File {ColorFilename}{{file}}:{{lineno}}{ColorNormal}"
- return tpl_link % file
+ return tpl_link.format(file=file, lineno=lineno)
#---------------------------------------------------------------------------
# Module classes
@@ -439,11 +442,10 @@ def _format_list(self, extracted_list):
Colors = self.Colors
list = []
for filename, lineno, name, line in extracted_list[:-1]:
- item = " %s, line %s%d%s, in %s%s%s\n" % (
- _format_filename(filename, Colors.filename, Colors.Normal),
- Colors.lineno,
- lineno,
- Colors.Normal,
+ item = " %s in %s%s%s\n" % (
+ _format_filename(
+ filename, Colors.filename, Colors.Normal, lineno=lineno
+ ),
Colors.name,
name,
Colors.Normal,
@@ -453,12 +455,11 @@ def _format_list(self, extracted_list):
list.append(item)
# Emphasize the last entry
filename, lineno, name, line = extracted_list[-1]
- item = "%s %s, line %s%d%s, in %s%s%s%s\n" % (
- Colors.normalEm,
- _format_filename(filename, Colors.filenameEm, Colors.normalEm),
- Colors.linenoEm,
- lineno,
+ item = "%s %s in %s%s%s%s\n" % (
Colors.normalEm,
+ _format_filename(
+ filename, Colors.filenameEm, Colors.normalEm, lineno=lineno
+ ),
Colors.nameEm,
name,
Colors.normalEm,
@@ -501,14 +502,15 @@ def _format_exception_only(self, etype, value):
lineno = "unknown"
textline = ""
list.append(
- "%s %s, line %s%s%s\n"
+ "%s %s%s\n"
% (
Colors.normalEm,
_format_filename(
- value.filename, Colors.filenameEm, Colors.normalEm
+ value.filename,
+ Colors.filenameEm,
+ Colors.normalEm,
+ lineno=(None if lineno == "unknown" else lineno),
),
- Colors.linenoEm,
- lineno,
Colors.Normal,
)
)
@@ -628,27 +630,35 @@ def format_record(self, frame_info):
return ' %s[... skipping similar frames: %s]%s\n' % (
Colors.excName, frame_info.description, ColorsNormal)
- indent = ' ' * INDENT_SIZE
- em_normal = '%s\n%s%s' % (Colors.valEm, indent, ColorsNormal)
- tpl_call = 'in %s%%s%s%%s%s' % (Colors.vName, Colors.valEm,
- ColorsNormal)
- tpl_call_fail = 'in %s%%s%s(***failed resolving arguments***)%s' % \
- (Colors.vName, Colors.valEm, ColorsNormal)
- tpl_name_val = '%%s %s= %%s%s' % (Colors.valEm, ColorsNormal)
+ indent = " " * INDENT_SIZE
+ em_normal = "%s\n%s%s" % (Colors.valEm, indent, ColorsNormal)
+ tpl_call = f"in {Colors.vName}{{file}}{Colors.valEm}{{scope}}{ColorsNormal}"
+ tpl_call_fail = "in %s%%s%s(***failed resolving arguments***)%s" % (
+ Colors.vName,
+ Colors.valEm,
+ ColorsNormal,
+ )
+ tpl_name_val = "%%s %s= %%s%s" % (Colors.valEm, ColorsNormal)
- link = _format_filename(frame_info.filename, Colors.filenameEm, ColorsNormal)
+ link = _format_filename(
+ frame_info.filename,
+ Colors.filenameEm,
+ ColorsNormal,
+ lineno=frame_info.lineno,
+ )
args, varargs, varkw, locals_ = inspect.getargvalues(frame_info.frame)
func = frame_info.executing.code_qualname()
- if func == '<module>':
- call = tpl_call % (func, '')
+ if func == "<module>":
+ call = tpl_call.format(file=func, scope="")
else:
# Decide whether to include variable details or not
var_repr = eqrepr if self.include_vars else nullrepr
try:
- call = tpl_call % (func, inspect.formatargvalues(args,
- varargs, varkw,
- locals_, formatvalue=var_repr))
+ scope = inspect.formatargvalues(
+ args, varargs, varkw, locals_, formatvalue=var_repr
+ )
+ call = tpl_call.format(file=func, scope=scope)
except KeyError:
# This happens in situations like errors inside generator
# expressions, where local variables are listed in the
</patch> | [] | [] | ||||
conda__conda-5359 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
conda should exec to non-conda subcommands, not subprocess
</issue>
<code>
[start of README.rst]
1 .. NOTE: This file serves both as the README on GitHub and the index.html for
2 conda.pydata.org. If you update this file, be sure to cd to the web
3 directory and run ``make html; make live``
4
5 .. image:: https://s3.amazonaws.com/conda-dev/conda_logo.svg
6 :alt: Conda Logo
7
8 ----------------------------------------
9
10 .. image:: https://img.shields.io/travis/conda/conda/4.4.x.svg?maxAge=900&label=Linux%20%26%20MacOS
11 :target: https://travis-ci.org/conda/conda
12 :alt: Linux & MacOS tests (Travis)
13
14 .. image:: https://img.shields.io/appveyor/ci/ContinuumAnalyticsFOSS/conda/4.4.x.svg?maxAge=900&label=Windows
15 :target: https://ci.appveyor.com/project/ContinuumAnalyticsFOSS/conda
16 :alt: Windows tests (Appveyor)
17
18 .. image:: https://img.shields.io/codecov/c/github/conda/conda/4.4.x.svg?label=coverage
19 :alt: Codecov Status
20 :target: https://codecov.io/gh/conda/conda/branch/4.4.x
21
22 .. image:: https://img.shields.io/github/release/conda/conda.svg
23 :alt: latest release version
24 :target: https://github.com/conda/conda/releases
25
26 |
27
28 .. image:: https://s3.amazonaws.com/conda-dev/conda-announce-signup-button.svg
29 :alt: Join the Conda Announcment List
30 :target: http://conda.pydata.org/docs/announcements.html
31
32 |
33
34 Conda is a cross-platform, language-agnostic binary package manager. It is the
35 package manager used by `Anaconda
36 <http://docs.continuum.io/anaconda/index.html>`_ installations, but it may be
37 used for other systems as well. Conda makes environments first-class
38 citizens, making it easy to create independent environments even for C
39 libraries. Conda is written entirely in Python, and is BSD licensed open
40 source.
41
42 Conda is enhanced by organizations, tools, and repositories created and managed by
43 the amazing members of the conda community. Some of them can be found
44 `here <https://github.com/conda/conda/wiki/Conda-Community>`_.
45
46
47 Installation
48 ------------
49
50 Conda is a part of the `Anaconda distribution <https://store.continuum.io/cshop/anaconda/>`_. You can also download a
51 minimal installation that only includes conda and its dependencies, called
52 `Miniconda <http://conda.pydata.org/miniconda.html>`_.
53
54
55 Getting Started
56 ---------------
57
58 If you install Anaconda, you will already have hundreds of packages
59 installed. You can see what packages are installed by running
60
61 .. code-block:: bash
62
63 $ conda list
64
65 to see all the packages that are available, use
66
67 .. code-block:: bash
68
69 $ conda search
70
71 and to install a package, use
72
73 .. code-block:: bash
74
75 $ conda install <package-name>
76
77
78 The real power of conda comes from its ability to manage environments. In
79 conda, an environment can be thought of as a completely separate installation.
80 Conda installs packages into environments efficiently using `hard links
81 <http://en.wikipedia.org/wiki/Hard_links>`_ by default when it is possible, so
82 environments are space efficient, and take seconds to create.
83
84 The default environment, which ``conda`` itself is installed into is called
85 ``root``. To create another environment, use the ``conda create``
86 command. For instance, to create an environment with the IPython notebook and
87 NumPy 1.6, which is older than the version that comes with Anaconda by
88 default, you would run
89
90 .. code-block:: bash
91
92 $ conda create -n numpy16 ipython-notebook numpy=1.6
93
94 This creates an environment called ``numpy16`` with the latest version of
95 the IPython notebook, NumPy 1.6, and their dependencies.
96
97 We can now activate this environment, use
98
99 .. code-block:: bash
100
101 # On Linux and Mac OS X
102 $ source activate numpy16
103
104 # On Windows
105 > activate numpy16
106
107 This puts the bin directory of the ``numpy16`` environment in the front of the
108 ``PATH``, and sets it as the default environment for all subsequent conda commands.
109
110 To go back to the root environment, use
111
112 .. code-block:: bash
113
114 # On Linux and Mac OS X
115 $ source deactivate
116
117 # On Windows
118 > deactivate
119
120
121 Building Your Own Packages
122 --------------------------
123
124 You can easily build your own packages for conda, and upload them
125 to `anaconda.org <https://anaconda.org>`_, a free service for hosting
126 packages for conda, as well as other package managers.
127 To build a package, create a recipe.
128 See http://github.com/conda/conda-recipes for many example recipes, and
129 http://docs.continuum.io/conda/build.html for documentation on how to build
130 recipes.
131
132 To upload to anaconda.org, create an account. Then, install the
133 anaconda-client and login
134
135 .. code-block:: bash
136
137 $ conda install anaconda-client
138 $ anaconda login
139
140 Then, after you build your recipe
141
142 .. code-block:: bash
143
144 $ conda build <recipe-dir>
145
146 you will be prompted to upload to anaconda.org.
147
148 To add your anaconda.org channel, or the channel of others to conda so
149 that ``conda install`` will find and install their packages, run
150
151 .. code-block:: bash
152
153 $ conda config --add channels https://conda.anaconda.org/username
154
155 (replacing ``username`` with the user name of the person whose channel you want
156 to add).
157
158 Getting Help
159 ------------
160
161 The documentation for conda is at http://conda.pydata.org/docs/. You can
162 subscribe to the `conda mailing list
163 <https://groups.google.com/a/continuum.io/forum/#!forum/conda>`_. The source
164 code and issue tracker for conda are on `GitHub <https://github.com/conda/conda>`_.
165
166 Contributing
167 ------------
168
169 Contributions to conda are welcome. Just fork the GitHub repository and send a
170 pull request.
171
172 To develop on conda, the easiest way is to use a development build. This can be
173 accomplished as follows:
174
175 * clone the conda git repository to a computer with conda already installed
176 * navigate to the root directory of the git clone
177 * run ``$CONDA/bin/python setup.py develop`` where ``$CONDA`` is the path to your
178 miniconda installation
179
180 Note building a development file requires git to be installed.
181
182 To undo this, run ``$CONDA/bin/python setup.py develop -u``. Note that if you
183 used a python other than ``$CONDA/bin/python`` to install, you may have to manually
184 delete the conda executable. For example, on OS X, if you use a homebrew python
185 located at ``/usr/local/bin/python``, then you'll need to ``rm /usr/local/bin/conda``
186 so that ``which -a conda`` lists first your miniconda installation.
187
188 If you are worried about breaking your conda installation, you can install a
189 separate instance of `Miniconda <http://conda.pydata.org/miniconda.html>`_ and
190 work off it. This is also the only way to test conda in both Python 2 and
191 Python 3, as conda can only be installed into a root environment.
192
193 To run the tests, set up a testing environment by running
194
195 * ``$CONDA/bin/python -m pip install -r utils/requirements-test.txt``.
196 * ``$CONDA/bin/python utils/setup-testing.py develop``
197
198 and then running ``py.test`` in the conda directory. You can also run tests using the
199 Makefile by running ``make unit``, ``make smoketest`` (a single integration test), or
200 ``make integration``. The tests are also run by various CI systems when you make a
201 pull request.
202
[end of README.rst]
[start of conda/_vendor/auxlib/_vendor/five.py]
1 # -*- coding: utf-8 -*-
2 """
3 amqp.five
4 ~~~~~~~~~~~
5
6 Compatibility implementations of features
7 only available in newer Python versions.
8
9
10 """
11 from __future__ import absolute_import
12
13 import io
14 import sys
15
16 try:
17 from collections import Counter
18 except ImportError: # pragma: no cover
19 from collections import defaultdict
20
21 def Counter(): # noqa
22 return defaultdict(int)
23
24 try:
25 buffer_t = buffer
26 except NameError: # pragma: no cover
27 # Py3 does not have buffer, only use this for isa checks.
28
29 class buffer_t(object): # noqa
30 pass
31
32 bytes_t = bytes
33
34 __all__ = ['Counter', 'reload', 'UserList', 'UserDict',
35 'Queue', 'Empty', 'Full', 'LifoQueue', 'builtins',
36 'zip_longest', 'map', 'zip', 'string', 'string_t', 'bytes_t',
37 'long_t', 'text_t', 'int_types', 'module_name_t',
38 'range', 'items', 'keys', 'values', 'nextfun', 'reraise',
39 'WhateverIO', 'with_metaclass', 'open_fqdn', 'StringIO',
40 'THREAD_TIMEOUT_MAX', 'format_d', 'monotonic', 'buffer_t']
41
42
43 # ############# py3k ########################################################
44 PY3 = sys.version_info[0] == 3
45
46 try:
47 reload = reload # noqa
48 except NameError: # pragma: no cover
49 from imp import reload # noqa
50
51 try:
52 from collections import UserList # noqa
53 except ImportError: # pragma: no cover
54 from UserList import UserList # noqa
55
56 try:
57 from collections import UserDict # noqa
58 except ImportError: # pragma: no cover
59 from UserDict import UserDict # noqa
60
61 # ############# time.monotonic #############################################
62
63 if sys.version_info < (3, 3):
64
65 import platform
66 SYSTEM = platform.system()
67
68 try:
69 import ctypes
70 except ImportError: # pragma: no cover
71 ctypes = None # noqa
72
73 if SYSTEM == 'Darwin' and ctypes is not None:
74 from ctypes.util import find_library
75 libSystem = ctypes.CDLL(find_library('libSystem.dylib'))
76 CoreServices = ctypes.CDLL(find_library('CoreServices'),
77 use_errno=True)
78 mach_absolute_time = libSystem.mach_absolute_time
79 mach_absolute_time.restype = ctypes.c_uint64
80 absolute_to_nanoseconds = CoreServices.AbsoluteToNanoseconds
81 absolute_to_nanoseconds.restype = ctypes.c_uint64
82 absolute_to_nanoseconds.argtypes = [ctypes.c_uint64]
83
84 def _monotonic():
85 return absolute_to_nanoseconds(mach_absolute_time()) * 1e-9
86
87 elif SYSTEM == 'Linux' and ctypes is not None:
88 # from stackoverflow:
89 # questions/1205722/how-do-i-get-monotonic-time-durations-in-python
90 import os
91
92 CLOCK_MONOTONIC = 1 # see <linux/time.h>
93
94 class timespec(ctypes.Structure):
95 _fields_ = [
96 ('tv_sec', ctypes.c_long),
97 ('tv_nsec', ctypes.c_long),
98 ]
99
100 librt = ctypes.CDLL('librt.so.1', use_errno=True)
101 clock_gettime = librt.clock_gettime
102 clock_gettime.argtypes = [
103 ctypes.c_int, ctypes.POINTER(timespec),
104 ]
105
106 def _monotonic(): # noqa
107 t = timespec()
108 if clock_gettime(CLOCK_MONOTONIC, ctypes.pointer(t)) != 0:
109 errno_ = ctypes.get_errno()
110 raise OSError(errno_, os.strerror(errno_))
111 return t.tv_sec + t.tv_nsec * 1e-9
112 else:
113 from time import time as _monotonic
114 try:
115 from time import monotonic
116 except ImportError:
117 monotonic = _monotonic # noqa
118
119 # ############# Py3 <-> Py2 #################################################
120
121 if PY3: # pragma: no cover
122 import builtins
123
124 from itertools import zip_longest
125
126 map = map
127 zip = zip
128 string = str
129 string_t = str
130 long_t = int
131 text_t = str
132 range = range
133 int_types = (int,)
134 module_name_t = str
135
136 open_fqdn = 'builtins.open'
137
138 def items(d):
139 return d.items()
140
141 def keys(d):
142 return d.keys()
143
144 def values(d):
145 return d.values()
146
147 def nextfun(it):
148 return it.__next__
149
150 exec_ = getattr(builtins, 'exec')
151
152 def reraise(tp, value, tb=None):
153 if value.__traceback__ is not tb:
154 raise value.with_traceback(tb)
155 raise value
156
157 else:
158 import __builtin__ as builtins # noqa
159 from itertools import ( # noqa
160 imap as map,
161 izip as zip,
162 izip_longest as zip_longest,
163 )
164
165 string = unicode # noqa
166 string_t = basestring # noqa
167 text_t = unicode
168 long_t = long # noqa
169 range = xrange
170 module_name_t = str
171 int_types = (int, long)
172
173 open_fqdn = '__builtin__.open'
174
175 def items(d): # noqa
176 return d.iteritems()
177
178 def keys(d): # noqa
179 return d.iterkeys()
180
181 def values(d): # noqa
182 return d.itervalues()
183
184 def nextfun(it): # noqa
185 return it.next
186
187 def exec_(code, globs=None, locs=None): # pragma: no cover
188 """Execute code in a namespace."""
189 if globs is None:
190 frame = sys._getframe(1)
191 globs = frame.f_globals
192 if locs is None:
193 locs = frame.f_locals
194 del frame
195 elif locs is None:
196 locs = globs
197 exec("""exec code in globs, locs""")
198
199 exec_("""def reraise(tp, value, tb=None): raise tp, value, tb""")
200
201
202 def with_metaclass(Type, skip_attrs=set(('__dict__', '__weakref__'))):
203 """Class decorator to set metaclass.
204
205 Works with both Python 2 and Python 3 and it does not add
206 an extra class in the lookup order like ``six.with_metaclass`` does
207 (that is -- it copies the original class instead of using inheritance).
208
209 """
210
211 def _clone_with_metaclass(Class):
212 attrs = dict((key, value) for key, value in items(vars(Class))
213 if key not in skip_attrs)
214 return Type(Class.__name__, Class.__bases__, attrs)
215
216 return _clone_with_metaclass
217
218 # ############# threading.TIMEOUT_MAX ########################################
219 try:
220 from threading import TIMEOUT_MAX as THREAD_TIMEOUT_MAX
221 except ImportError:
222 THREAD_TIMEOUT_MAX = 1e10 # noqa
223
224 # ############# format(int, ',d') ############################################
225
226 if sys.version_info >= (2, 7): # pragma: no cover
227 def format_d(i):
228 return format(i, ',d')
229 else: # pragma: no cover
230 def format_d(i): # noqa
231 s = '%d' % i
232 groups = []
233 while s and s[-1].isdigit():
234 groups.append(s[-3:])
235 s = s[:-3]
236 return s + ','.join(reversed(groups))
237
238 StringIO = io.StringIO
239 _SIO_write = StringIO.write
240 _SIO_init = StringIO.__init__
241
242
243 class WhateverIO(StringIO):
244
245 def __init__(self, v=None, *a, **kw):
246 _SIO_init(self, v.decode() if isinstance(v, bytes) else v, *a, **kw)
247
248 def write(self, data):
249 _SIO_write(self, data.decode() if isinstance(data, bytes) else data)
[end of conda/_vendor/auxlib/_vendor/five.py]
[start of conda/activate.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from glob import glob
5 import os
6 from os.path import abspath, basename, dirname, expanduser, expandvars, isdir, join
7 import re
8 import sys
9 from tempfile import NamedTemporaryFile
10
11 try:
12 from cytoolz.itertoolz import concatv
13 except ImportError: # pragma: no cover
14 from ._vendor.toolz.itertoolz import concatv # NOQA
15
16
17 class Activator(object):
18 # Activate and deactivate have three tasks
19 # 1. Set and unset environment variables
20 # 2. Execute/source activate.d/deactivate.d scripts
21 # 3. Update the command prompt
22 #
23 # Shells should also use 'reactivate' following conda's install, update, and
24 # remove/uninstall commands.
25 #
26 # All core logic is in build_activate() or build_deactivate(), and is independent of
27 # shell type. Each returns a map containing the keys:
28 # set_vars
29 # unset_var
30 # activate_scripts
31 # deactivate_scripts
32 #
33 # The value of the CONDA_PROMPT_MODIFIER environment variable holds conda's contribution
34 # to the command prompt.
35 #
36 # To implement support for a new shell, ideally one would only need to add shell-specific
37 # information to the __init__ method of this class.
38
39 def __init__(self, shell):
40 from .base.context import context
41 self.context = context
42 self.shell = shell
43
44 if shell == 'posix':
45 self.pathsep_join = ':'.join
46 self.path_conversion = native_path_to_unix
47 self.script_extension = '.sh'
48 self.tempfile_extension = None # write instructions to stdout rather than a temp file
49
50 self.unset_var_tmpl = 'unset %s'
51 self.set_var_tmpl = 'export %s="%s"'
52 self.run_script_tmpl = '. "%s"'
53
54 elif shell == 'csh':
55 self.pathsep_join = ':'.join
56 self.path_conversion = native_path_to_unix
57 self.script_extension = '.csh'
58 self.tempfile_extension = None # write instructions to stdout rather than a temp file
59
60 self.unset_var_tmpl = 'unset %s'
61 self.set_var_tmpl = 'setenv %s "%s"'
62 self.run_script_tmpl = 'source "%s"'
63
64 elif shell == 'xonsh':
65 self.pathsep_join = ':'.join
66 self.path_conversion = native_path_to_unix
67 self.script_extension = '.xsh'
68 self.tempfile_extension = '.xsh'
69
70 self.unset_var_tmpl = 'del $%s'
71 self.set_var_tmpl = '$%s = "%s"'
72 self.run_script_tmpl = 'source "%s"'
73
74 elif shell == 'cmd.exe':
75 self.pathsep_join = ';'.join
76 self.path_conversion = path_identity
77 self.script_extension = '.bat'
78 self.tempfile_extension = '.bat'
79
80 self.unset_var_tmpl = '@SET %s='
81 self.set_var_tmpl = '@SET "%s=%s"'
82 self.run_script_tmpl = '@CALL "%s"'
83
84 elif shell == 'fish':
85 self.pathsep_join = ' '.join
86 self.path_conversion = native_path_to_unix
87 self.script_extension = '.fish'
88 self.tempfile_extension = None # write instructions to stdout rather than a temp file
89
90 self.unset_var_tmpl = 'set -e %s'
91 self.set_var_tmpl = 'set -gx %s "%s"'
92 self.run_script_tmpl = 'source "%s"'
93
94 elif shell == 'powershell':
95 self.pathsep_join = ';'.join
96 self.path_conversion = path_identity
97 self.script_extension = '.ps1'
98 self.tempfile_extension = None # write instructions to stdout rather than a temp file
99
100 self.unset_var_tmpl = 'Remove-Variable %s'
101 self.set_var_tmpl = '$env:%s = "%s"'
102 self.run_script_tmpl = '. "%s"'
103
104 else:
105 raise NotImplementedError()
106
107 def _finalize(self, commands, ext):
108 commands = concatv(commands, ('',)) # add terminating newline
109 if ext is None:
110 return '\n'.join(commands)
111 elif ext:
112 with NamedTemporaryFile(suffix=ext, delete=False) as tf:
113 tf.write(ensure_binary('\n'.join(commands)))
114 return tf.name
115 else:
116 raise NotImplementedError()
117
118 def activate(self, name_or_prefix):
119 return self._finalize(self._yield_commands(self.build_activate(name_or_prefix)),
120 self.tempfile_extension)
121
122 def deactivate(self):
123 return self._finalize(self._yield_commands(self.build_deactivate()),
124 self.tempfile_extension)
125
126 def reactivate(self):
127 return self._finalize(self._yield_commands(self.build_reactivate()),
128 self.tempfile_extension)
129
130 def _yield_commands(self, cmds_dict):
131 for key in sorted(cmds_dict.get('unset_vars', ())):
132 yield self.unset_var_tmpl % key
133
134 for key, value in sorted(iteritems(cmds_dict.get('set_vars', {}))):
135 yield self.set_var_tmpl % (key, value)
136
137 for script in cmds_dict.get('deactivate_scripts', ()):
138 yield self.run_script_tmpl % script
139
140 for script in cmds_dict.get('activate_scripts', ()):
141 yield self.run_script_tmpl % script
142
143 def build_activate(self, name_or_prefix):
144 test_path = expand(name_or_prefix)
145 if isdir(test_path):
146 prefix = test_path
147 if not isdir(join(prefix, 'conda-meta')):
148 from .exceptions import EnvironmentLocationNotFound
149 raise EnvironmentLocationNotFound(prefix)
150 elif re.search(r'\\|/', name_or_prefix):
151 prefix = name_or_prefix
152 if not isdir(join(prefix, 'conda-meta')):
153 from .exceptions import EnvironmentLocationNotFound
154 raise EnvironmentLocationNotFound(prefix)
155 else:
156 from .base.context import locate_prefix_by_name
157 prefix = locate_prefix_by_name(self.context, name_or_prefix)
158
159 # query environment
160 old_conda_shlvl = int(os.getenv('CONDA_SHLVL', 0))
161 old_conda_prefix = os.getenv('CONDA_PREFIX')
162 max_shlvl = self.context.max_shlvl
163
164 if old_conda_prefix == prefix:
165 return self.build_reactivate()
166 elif os.getenv('CONDA_PREFIX_%s' % (old_conda_shlvl-1)) == prefix:
167 # in this case, user is attempting to activate the previous environment,
168 # i.e. step back down
169 return self.build_deactivate()
170
171 activate_scripts = glob(join(
172 prefix, 'etc', 'conda', 'activate.d', '*' + self.script_extension
173 ))
174 conda_default_env = self._default_env(prefix)
175 conda_prompt_modifier = self._prompt_modifier(conda_default_env)
176
177 assert 0 <= old_conda_shlvl <= max_shlvl
178 if old_conda_shlvl == 0:
179 new_path = self.pathsep_join(self._add_prefix_to_path(prefix))
180 set_vars = {
181 'CONDA_PYTHON_EXE': sys.executable,
182 'PATH': new_path,
183 'CONDA_PREFIX': prefix,
184 'CONDA_SHLVL': old_conda_shlvl + 1,
185 'CONDA_DEFAULT_ENV': conda_default_env,
186 'CONDA_PROMPT_MODIFIER': conda_prompt_modifier,
187 }
188 deactivate_scripts = ()
189 elif old_conda_shlvl == max_shlvl:
190 new_path = self.pathsep_join(self._replace_prefix_in_path(old_conda_prefix, prefix))
191 set_vars = {
192 'PATH': new_path,
193 'CONDA_PREFIX': prefix,
194 'CONDA_DEFAULT_ENV': conda_default_env,
195 'CONDA_PROMPT_MODIFIER': conda_prompt_modifier,
196 }
197 deactivate_scripts = glob(join(
198 old_conda_prefix, 'etc', 'conda', 'deactivate.d', '*' + self.script_extension
199 ))
200 else:
201 new_path = self.pathsep_join(self._add_prefix_to_path(prefix))
202 set_vars = {
203 'PATH': new_path,
204 'CONDA_PREFIX': prefix,
205 'CONDA_PREFIX_%d' % old_conda_shlvl: old_conda_prefix,
206 'CONDA_SHLVL': old_conda_shlvl + 1,
207 'CONDA_DEFAULT_ENV': conda_default_env,
208 'CONDA_PROMPT_MODIFIER': conda_prompt_modifier,
209 }
210 deactivate_scripts = ()
211
212 return {
213 'unset_vars': (),
214 'set_vars': set_vars,
215 'deactivate_scripts': deactivate_scripts,
216 'activate_scripts': activate_scripts,
217 }
218
219 def build_deactivate(self):
220 # query environment
221 old_conda_shlvl = int(os.getenv('CONDA_SHLVL', 0))
222 old_conda_prefix = os.environ['CONDA_PREFIX']
223 deactivate_scripts = self._get_deactivate_scripts(old_conda_prefix)
224
225 new_conda_shlvl = old_conda_shlvl - 1
226 new_path = self.pathsep_join(self._remove_prefix_from_path(old_conda_prefix))
227
228 assert old_conda_shlvl > 0
229 if old_conda_shlvl == 1:
230 # TODO: warn conda floor
231 unset_vars = (
232 'CONDA_PREFIX',
233 'CONDA_DEFAULT_ENV',
234 'CONDA_PYTHON_EXE',
235 'CONDA_PROMPT_MODIFIER',
236 )
237 set_vars = {
238 'PATH': new_path,
239 'CONDA_SHLVL': new_conda_shlvl,
240 }
241 activate_scripts = ()
242 else:
243 new_prefix = os.getenv('CONDA_PREFIX_%d' % new_conda_shlvl)
244 conda_default_env = self._default_env(new_prefix)
245 conda_prompt_modifier = self._prompt_modifier(conda_default_env)
246
247 unset_vars = (
248 'CONDA_PREFIX_%d' % new_conda_shlvl,
249 )
250 set_vars = {
251 'PATH': new_path,
252 'CONDA_SHLVL': new_conda_shlvl,
253 'CONDA_PREFIX': new_prefix,
254 'CONDA_DEFAULT_ENV': conda_default_env,
255 'CONDA_PROMPT_MODIFIER': conda_prompt_modifier,
256 }
257 activate_scripts = self._get_activate_scripts(new_prefix)
258
259 return {
260 'unset_vars': unset_vars,
261 'set_vars': set_vars,
262 'deactivate_scripts': deactivate_scripts,
263 'activate_scripts': activate_scripts,
264 }
265
266 def build_reactivate(self):
267 conda_prefix = os.environ['CONDA_PREFIX']
268 return {
269 'unset_vars': (),
270 'set_vars': {},
271 'deactivate_scripts': self._get_deactivate_scripts(conda_prefix),
272 'activate_scripts': self._get_activate_scripts(conda_prefix),
273 }
274
275 def _get_starting_path_list(self):
276 path = os.environ['PATH']
277 if on_win:
278 # on Windows, the python interpreter prepends sys.prefix\Library\bin on startup WTF
279 return path.split(os.pathsep)[1:]
280 else:
281 return path.split(os.pathsep)
282
283 def _get_path_dirs(self, prefix):
284 if on_win: # pragma: unix no cover
285 yield prefix.rstrip("\\")
286 yield join(prefix, 'Library', 'mingw-w64', 'bin')
287 yield join(prefix, 'Library', 'usr', 'bin')
288 yield join(prefix, 'Library', 'bin')
289 yield join(prefix, 'Scripts')
290 else:
291 yield join(prefix, 'bin')
292
293 def _add_prefix_to_path(self, prefix, starting_path_dirs=None):
294 if starting_path_dirs is None:
295 starting_path_dirs = self._get_starting_path_list()
296 return self.path_conversion(*tuple(concatv(
297 self._get_path_dirs(prefix),
298 starting_path_dirs,
299 )))
300
301 def _remove_prefix_from_path(self, prefix, starting_path_dirs=None):
302 return self._replace_prefix_in_path(prefix, None, starting_path_dirs)
303
304 def _replace_prefix_in_path(self, old_prefix, new_prefix, starting_path_dirs=None):
305 if starting_path_dirs is None:
306 path_list = self._get_starting_path_list()
307 else:
308 path_list = list(starting_path_dirs)
309 if on_win: # pragma: unix no cover
310 # windows has a nasty habit of adding extra Library\bin directories
311 prefix_dirs = tuple(self._get_path_dirs(old_prefix))
312 try:
313 first_idx = path_list.index(prefix_dirs[0])
314 except ValueError:
315 first_idx = 0
316 else:
317 last_idx = path_list.index(prefix_dirs[-1])
318 del path_list[first_idx:last_idx+1]
319 if new_prefix is not None:
320 path_list[first_idx:first_idx] = list(self._get_path_dirs(new_prefix))
321 else:
322 try:
323 idx = path_list.index(join(old_prefix, 'bin'))
324 except ValueError:
325 idx = 0
326 else:
327 del path_list[idx]
328 if new_prefix is not None:
329 path_list.insert(idx, join(new_prefix, 'bin'))
330 return self.path_conversion(*path_list)
331
332 def _default_env(self, prefix):
333 if prefix == self.context.root_prefix:
334 return 'root'
335 return basename(prefix) if basename(dirname(prefix)) == 'envs' else prefix
336
337 def _prompt_modifier(self, conda_default_env):
338 return "(%s) " % conda_default_env if self.context.changeps1 else ""
339
340 def _get_activate_scripts(self, prefix):
341 return glob(join(
342 prefix, 'etc', 'conda', 'activate.d', '*' + self.script_extension
343 ))
344
345 def _get_deactivate_scripts(self, prefix):
346 return glob(join(
347 prefix, 'etc', 'conda', 'deactivate.d', '*' + self.script_extension
348 ))
349
350
351 def expand(path):
352 return abspath(expanduser(expandvars(path)))
353
354
355 def ensure_binary(value):
356 try:
357 return value.encode('utf-8')
358 except AttributeError: # pragma: no cover
359 # AttributeError: '<>' object has no attribute 'encode'
360 # In this case assume already binary type and do nothing
361 return value
362
363
364 def native_path_to_unix(*paths): # pragma: unix no cover
365 # on windows, uses cygpath to convert windows native paths to posix paths
366 if not on_win:
367 return path_identity(*paths)
368 from subprocess import PIPE, Popen
369 from shlex import split
370 command = 'cygpath --path -f -'
371 p = Popen(split(command), stdin=PIPE, stdout=PIPE, stderr=PIPE)
372 joined = ("%s" % os.pathsep).join(paths)
373 if hasattr(joined, 'encode'):
374 joined = joined.encode('utf-8')
375 stdout, stderr = p.communicate(input=joined)
376 rc = p.returncode
377 if rc != 0 or stderr:
378 from subprocess import CalledProcessError
379 message = "\n stdout: %s\n stderr: %s\n rc: %s\n" % (stdout, stderr, rc)
380 print(message, file=sys.stderr)
381 raise CalledProcessError(rc, command, message)
382 if hasattr(stdout, 'decode'):
383 stdout = stdout.decode('utf-8')
384 final = stdout.strip().split(':')
385 return final[0] if len(final) == 1 else tuple(final)
386
387
388 def path_identity(*paths):
389 return paths[0] if len(paths) == 1 else paths
390
391
392 on_win = bool(sys.platform == "win32")
393 PY2 = sys.version_info[0] == 2
394 if PY2: # pragma: py3 no cover
395 string_types = basestring, # NOQA
396
397 def iteritems(d, **kw):
398 return d.iteritems(**kw)
399 else: # pragma: py2 no cover
400 string_types = str,
401
402 def iteritems(d, **kw):
403 return iter(d.items(**kw))
404
405
406 def main():
407 command = sys.argv[1]
408 shell = sys.argv[2]
409 activator = Activator(shell)
410 remainder_args = sys.argv[3:] if len(sys.argv) >= 4 else ()
411 # if '-h' in remainder_args or '--help' in remainder_args:
412 # pass
413 if command == 'shell.activate':
414 if len(remainder_args) > 1:
415 from .exceptions import ArgumentError
416 raise ArgumentError("activate only accepts a single argument")
417 print(activator.activate(remainder_args and remainder_args[0] or "root"))
418 elif command == 'shell.deactivate':
419 if remainder_args:
420 from .exceptions import ArgumentError
421 raise ArgumentError("deactivate does not accept arguments")
422 print(activator.deactivate())
423 elif command == 'shell.reactivate':
424 if remainder_args:
425 from .exceptions import ArgumentError
426 raise ArgumentError("reactivate does not accept arguments")
427 print(activator.reactivate())
428 else:
429 raise NotImplementedError()
430 return 0
431
432
433 if __name__ == '__main__':
434 sys.exit(main())
435
[end of conda/activate.py]
[start of conda/cli/main.py]
1 # (c) Continuum Analytics, Inc. / http://continuum.io
2 # All Rights Reserved
3 #
4 # conda is distributed under the terms of the BSD 3-clause license.
5 # Consult LICENSE.txt or http://opensource.org/licenses/BSD-3-Clause.
6 """conda is a tool for managing environments and packages.
7
8 conda provides the following commands:
9
10 Information
11 ===========
12
13 info : display information about the current install
14 list : list packages linked into a specified environment
15 search : print information about a specified package
16 help : display a list of available conda commands and their help
17 strings
18
19 Package Management
20 ==================
21
22 create : create a new conda environment from a list of specified
23 packages
24 install : install new packages into an existing conda environment
25 update : update packages in a specified conda environment
26
27
28 Packaging
29 =========
30
31 package : create a conda package in an environment
32
33 Additional help for each command can be accessed by using:
34
35 conda <command> -h
36 """
37 from __future__ import absolute_import, division, print_function, unicode_literals
38 import sys
39
40
41 def generate_parser():
42 from argparse import SUPPRESS
43
44 from .. import __version__
45 from .conda_argparse import ArgumentParser
46
47 p = ArgumentParser(
48 description='conda is a tool for managing and deploying applications,'
49 ' environments and packages.',
50 )
51 p.add_argument(
52 '-V', '--version',
53 action='version',
54 version='conda %s' % __version__,
55 help="Show the conda version number and exit."
56 )
57 p.add_argument(
58 "--debug",
59 action="store_true",
60 help=SUPPRESS,
61 )
62 p.add_argument(
63 "--json",
64 action="store_true",
65 help=SUPPRESS,
66 )
67 sub_parsers = p.add_subparsers(
68 metavar='command',
69 dest='cmd',
70 )
71 # http://bugs.python.org/issue9253
72 # http://stackoverflow.com/a/18283730/1599393
73 sub_parsers.required = True
74
75 return p, sub_parsers
76
77
78 def _main(*args):
79 import importlib
80 from logging import CRITICAL, DEBUG, getLogger
81
82 try:
83 from cytoolz.itertoolz import concatv
84 except ImportError: # pragma: no cover
85 from .._vendor.toolz.itertoolz import concatv
86
87 from ..base.constants import SEARCH_PATH
88 from ..base.context import context
89 from ..gateways.logging import set_all_logger_level, set_verbosity
90
91 log = getLogger(__name__)
92
93 if len(args) == 1:
94 args = args + ('-h',)
95
96 p, sub_parsers = generate_parser()
97
98 main_modules = ["info", "help", "list", "search", "create", "install", "update",
99 "remove", "config", "clean", "package"]
100 modules = ["conda.cli.main_"+suffix for suffix in main_modules]
101 for module in modules:
102 imported = importlib.import_module(module)
103 imported.configure_parser(sub_parsers)
104 if "update" in module:
105 imported.configure_parser(sub_parsers, name='upgrade')
106 if "remove" in module:
107 imported.configure_parser(sub_parsers, name='uninstall')
108
109 from .find_commands import find_commands
110
111 # when using sys.argv, first argument is generally conda or __main__.py. Ignore it.
112 if (any(sname in args[0] for sname in ('conda', 'conda.exe', '__main__.py', 'conda-script.py'))
113 and (args[1] in concatv(sub_parsers.choices, find_commands())
114 or args[1].startswith('-'))):
115 log.debug("Ignoring first argument (%s), as it is not a subcommand", args[0])
116 args = args[1:]
117
118 args = p.parse_args(args)
119
120 context.__init__(SEARCH_PATH, 'conda', args)
121
122 if getattr(args, 'json', False):
123 # Silence logging info to avoid interfering with JSON output
124 for logger in ('print', 'dotupdate', 'stdoutlog', 'stderrlog'):
125 getLogger(logger).setLevel(CRITICAL + 1)
126
127 if context.debug:
128 set_all_logger_level(DEBUG)
129 elif context.verbosity:
130 set_verbosity(context.verbosity)
131 log.debug("verbosity set to %s", context.verbosity)
132
133 exit_code = args.func(args, p)
134 if isinstance(exit_code, int):
135 return exit_code
136
137
138 def _ensure_text_type(value):
139 # copying here from conda/common/compat.py to avoid the import
140 try:
141 return value.decode('utf-8')
142 except AttributeError:
143 # AttributeError: '<>' object has no attribute 'decode'
144 # In this case assume already text_type and do nothing
145 return value
146 except UnicodeDecodeError:
147 from requests.packages.chardet import detect
148 encoding = detect(value).get('encoding') or 'utf-8'
149 return value.decode(encoding)
150
151
152 def main(*args):
153 if not args:
154 args = sys.argv
155
156 args = tuple(_ensure_text_type(s) for s in args)
157
158 if len(args) > 1:
159 try:
160 argv1 = args[1].strip()
161 if argv1.startswith('shell.'):
162 from ..activate import main as activator_main
163 return activator_main()
164 elif argv1.startswith('..'):
165 import conda.cli.activate as activate
166 activate.main()
167 return
168 if argv1 in ('activate', 'deactivate'):
169 from ..exceptions import CommandNotFoundError
170 raise CommandNotFoundError(argv1)
171 except Exception as e:
172 from ..exceptions import handle_exception
173 from ..gateways import initialize_logging
174 initialize_logging()
175 return handle_exception(e)
176
177 from ..exceptions import conda_exception_handler
178 return conda_exception_handler(_main, *args)
179
180
181 if __name__ == '__main__':
182 sys.exit(main())
183
[end of conda/cli/main.py]
[start of conda/cli/main_help.py]
1 # (c) 2012-2013 Continuum Analytics, Inc. / http://continuum.io
2 # All Rights Reserved
3 #
4 # conda is distributed under the terms of the BSD 3-clause license.
5 # Consult LICENSE.txt or http://opensource.org/licenses/BSD-3-Clause.
6 from __future__ import print_function, division, absolute_import, unicode_literals
7
8 descr = "Displays a list of available conda commands and their help strings."
9
10 example = """
11 Examples:
12
13 conda help install
14 """
15
16
17 def configure_parser(sub_parsers):
18 p = sub_parsers.add_parser(
19 'help',
20 description=descr,
21 help=descr,
22 epilog=example,
23 )
24 p.add_argument(
25 'command',
26 metavar='COMMAND',
27 action="store",
28 nargs='?',
29 help="""Print help information for COMMAND (same as: conda COMMAND
30 --help).""",
31 )
32 p.set_defaults(func=execute)
33
34
35 def execute(args, parser):
36 if not args.command:
37 parser.print_help()
38 return
39
40 import sys
41 import subprocess
42
43 subprocess.call([sys.executable, sys.argv[0], args.command, '-h'])
44
[end of conda/cli/main_help.py]
[start of conda/gateways/subprocess.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from collections import namedtuple
5 from logging import getLogger
6 import os
7 from os.path import abspath
8 from shlex import split as shlex_split
9 from subprocess import CalledProcessError, PIPE, Popen
10 import sys
11
12 from .logging import TRACE
13 from .. import ACTIVE_SUBPROCESSES
14 from .._vendor.auxlib.ish import dals
15 from ..common.compat import ensure_binary, ensure_text_type, iteritems, on_win, string_types
16
17 log = getLogger(__name__)
18 Response = namedtuple('Response', ('stdout', 'stderr', 'rc'))
19
20
21 def _split_on_unix(command):
22 # I guess windows doesn't like shlex.split
23 return command if on_win else shlex_split(command)
24
25
26 def _format_output(command_str, path, rc, stdout, stderr):
27 return dals("""
28 $ %s
29 ==> cwd: %s <==
30 ==> exit code: %d <==
31 ==> stdout <==
32 %s
33 ==> stderr <==
34 %s
35 """) % (command_str, path, rc, stdout, stderr)
36
37
38 def subprocess_call(command, env=None, path=None, stdin=None, raise_on_error=True):
39 """This utility function should be preferred for all conda subprocessing.
40 It handles multiple tricky details.
41 """
42 env = {str(k): str(v) for k, v in iteritems(env if env else os.environ)}
43 path = sys.prefix if path is None else abspath(path)
44 command_str = command if isinstance(command, string_types) else ' '.join(command)
45 command_arg = _split_on_unix(command) if isinstance(command, string_types) else command
46 log.debug("executing>> %s", command_str)
47 p = Popen(command_arg, cwd=path, stdin=PIPE, stdout=PIPE, stderr=PIPE, env=env)
48 ACTIVE_SUBPROCESSES.add(p)
49 stdin = ensure_binary(stdin) if isinstance(stdin, string_types) else None
50 stdout, stderr = p.communicate(input=stdin)
51 rc = p.returncode
52 ACTIVE_SUBPROCESSES.remove(p)
53 if raise_on_error and rc != 0:
54 log.info(_format_output(command_str, path, rc, stdout, stderr))
55 raise CalledProcessError(rc, command,
56 output=_format_output(command_str, path, rc, stdout, stderr))
57 if log.isEnabledFor(TRACE):
58 log.trace(_format_output(command_str, path, rc, stdout, stderr))
59
60 return Response(ensure_text_type(stdout), ensure_text_type(stderr), int(rc))
61
[end of conda/gateways/subprocess.py]
[start of conda_env/installers/pip.py]
1 from __future__ import absolute_import
2
3 import os
4 import os.path as op
5 import subprocess
6 import tempfile
7 from conda_env.pip_util import pip_args
8 from conda.exceptions import CondaValueError
9
10
11 def _pip_install_via_requirements(prefix, specs, args, *_):
12 """
13 Installs the pip dependencies in specs using a temporary pip requirements file.
14
15 Args
16 ----
17 prefix: string
18 The path to the python and pip executables.
19
20 specs: iterable of strings
21 Each element should be a valid pip dependency.
22 See: https://pip.pypa.io/en/stable/user_guide/#requirements-files
23 https://pip.pypa.io/en/stable/reference/pip_install/#requirements-file-format
24 """
25 try:
26 pip_workdir = op.dirname(op.abspath(args.file))
27 except AttributeError:
28 pip_workdir = None
29 requirements = None
30 try:
31 # Generate the temporary requirements file
32 requirements = tempfile.NamedTemporaryFile(mode='w',
33 prefix='condaenv.',
34 suffix='.requirements.txt',
35 dir=pip_workdir,
36 delete=False)
37 requirements.write('\n'.join(specs))
38 requirements.close()
39 # pip command line...
40 pip_cmd = pip_args(prefix) + ['install', '-r', requirements.name]
41 # ...run it
42 process = subprocess.Popen(pip_cmd,
43 cwd=pip_workdir,
44 universal_newlines=True)
45 process.communicate()
46 if process.returncode != 0:
47 raise CondaValueError("pip returned an error")
48 finally:
49 # Win/Appveyor does not like it if we use context manager + delete=True.
50 # So we delete the temporary file in a finally block.
51 if requirements is not None and op.isfile(requirements.name):
52 os.remove(requirements.name)
53
54
55 # Conform to Installers API
56 install = _pip_install_via_requirements
57
[end of conda_env/installers/pip.py]
[start of conda_env/pip_util.py]
1 """
2 Functions related to core conda functionality that relates to pip
3
4 NOTE: This modules used to in conda, as conda/pip.py
5 """
6 from __future__ import absolute_import, print_function
7
8 import json
9 import os
10 from os.path import isfile, join
11 import subprocess
12 import sys
13
14
15 def pip_args(prefix):
16 """
17 return the arguments required to invoke pip (in prefix), or None if pip
18 is not installed
19 """
20 if sys.platform == 'win32':
21 pip_path = join(prefix, 'Scripts', 'pip-script.py')
22 py_path = join(prefix, 'python.exe')
23 else:
24 pip_path = join(prefix, 'bin', 'pip')
25 py_path = join(prefix, 'bin', 'python')
26 if isfile(pip_path) and isfile(py_path):
27 ret = [py_path, pip_path]
28
29 # Check the version of pip
30 # --disable-pip-version-check was introduced in pip 6.0
31 # If older than that, they should probably get the warning anyway.
32 pip_version = subprocess.check_output(ret + ['-V']).decode('utf-8').split()[1]
33 major_ver = pip_version.split('.')[0]
34 if int(major_ver) >= 6:
35 ret.append('--disable-pip-version-check')
36 return ret
37 else:
38 return None
39
40
41 class PipPackage(dict):
42 def __str__(self):
43 if 'path' in self:
44 return '%s (%s)-%s-<pip>' % (
45 self['name'],
46 self['path'],
47 self['version']
48 )
49 return '%s-%s-<pip>' % (self['name'], self['version'])
50
51
52 def installed(prefix, output=True):
53 args = pip_args(prefix)
54 if args is None:
55 return
56
57 env = os.environ.copy()
58 env[str('PIP_FORMAT')] = str('legacy')
59
60 args += ['list', '--format', 'json']
61
62 try:
63 s = subprocess.check_output(args, universal_newlines=True, env=env)
64 except Exception:
65 # Any error should just be ignored
66 if output:
67 print("# Warning: subprocess call to pip failed")
68 return
69 pkgs = json.loads(s)
70
71 # For every package in pipinst that is not already represented
72 # in installed append a fake name to installed with 'pip'
73 # as the build string
74 for kwargs in pkgs:
75 kwargs['name'] = kwargs['name'].lower()
76 if ', ' in kwargs['version']:
77 # Packages installed with setup.py develop will include a path in
78 # the version. They should be included here, even if they are
79 # installed with conda, as they are preferred over the conda
80 # version. We still include the conda version, though, because it
81 # is still installed.
82
83 version, path = kwargs['version'].split(', ')
84 # We do this because the code below uses rsplit('-', 2)
85 version = version.replace('-', ' ')
86 kwargs['version'] = version
87 kwargs['path'] = path
88 yield PipPackage(**kwargs)
89
90
91 def add_pip_installed(prefix, installed_pkgs, json=None, output=True):
92 # Defer to json for backwards compatibility
93 if isinstance(json, bool):
94 output = not json
95
96 # TODO Refactor so installed is a real list of objects/dicts
97 # instead of strings allowing for direct comparison
98 # split :: to get rid of channel info
99 conda_names = {d.quad[0] for d in installed_pkgs}
100 for pip_pkg in installed(prefix, output=output):
101 if pip_pkg['name'] in conda_names and 'path' not in pip_pkg:
102 continue
103 installed_pkgs.add(str(pip_pkg))
104
[end of conda_env/pip_util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| conda/conda | 98c6d80f3299edf775b495f90651d558248d2cf8 | conda should exec to non-conda subcommands, not subprocess
| 2017-05-18T13:17:36Z | <patch>
diff --git a/conda/cli/conda_argparse.py b/conda/cli/conda_argparse.py
--- a/conda/cli/conda_argparse.py
+++ b/conda/cli/conda_argparse.py
@@ -45,7 +45,6 @@ def _get_action_from_name(self, name):
def error(self, message):
import re
- import subprocess
from .find_commands import find_executable
exc = sys.exc_info()[1]
@@ -57,7 +56,7 @@ def error(self, message):
else:
argument = None
if argument and argument.dest == "cmd":
- m = re.compile(r"invalid choice: '([\w\-]+)'").match(exc.message)
+ m = re.compile(r"invalid choice: u?'([\w\-]+)'").match(exc.message)
if m:
cmd = m.group(1)
executable = find_executable('conda-' + cmd)
@@ -67,13 +66,7 @@ def error(self, message):
args = [find_executable('conda-' + cmd)]
args.extend(sys.argv[2:])
- p = subprocess.Popen(args)
- try:
- p.communicate()
- except KeyboardInterrupt:
- p.wait()
- finally:
- sys.exit(p.returncode)
+ os.execv(args[0], args)
super(ArgumentParser, self).error(message)
</patch> | [] | [] | ||||
pandas-dev__pandas-9743 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[] (__getitem__) boolean indexing assignment bug with nans
See repro below:
``` python
import pandas as pd
import numpy as np
temp = pd.Series(np.random.randn(10))
temp[3:6] = np.nan
temp[8] = np.nan
nan_index = np.isnan(temp)
# this works
temp1 = temp.copy()
temp1[nan_index] = [99, 99, 99, 99]
temp1[nan_index]
3 99
4 99
5 99
8 99
dtype: float64
# this doesn't - values look like they're being assigned in a different order?
temp2 = temp.copy()
temp2[nan_index] = [99, 99, 99, np.nan]
3 NaN
4 99
5 99
8 99
dtype: float64
# ... but it works properly when using .loc
temp2 = temp.copy()
temp2.loc[nan_index] = [99, 99, 99, np.nan]
3 99
4 99
5 99
8 NaN
dtype: float64
```
output of show_versions():
```
INSTALLED VERSIONS
------------------
commit: None
python: 2.7.9.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.16.0
nose: 1.3.4
Cython: 0.21.2
numpy: 1.9.2
scipy: 0.14.0
statsmodels: 0.5.0
IPython: 3.0.0
sphinx: 1.2.3
patsy: 0.2.1
dateutil: 2.4.1
pytz: 2015.2
bottleneck: 0.8.0
tables: 3.1.1
numexpr: 2.3.1
matplotlib: 1.4.0
openpyxl: 2.0.2
xlrd: 0.9.3
xlwt: 0.7.5
xlsxwriter: 0.6.6
lxml: 3.4.2
bs4: 4.3.2
html5lib: 0.999
httplib2: 0.8
apiclient: None
sqlalchemy: 0.9.8
pymysql: None
psycopg2: None
```
</issue>
<code>
[start of README.md]
1 # pandas: powerful Python data analysis toolkit
2
3 
4
5 ## What is it
6
7 **pandas** is a Python package providing fast, flexible, and expressive data
8 structures designed to make working with "relational" or "labeled" data both
9 easy and intuitive. It aims to be the fundamental high-level building block for
10 doing practical, **real world** data analysis in Python. Additionally, it has
11 the broader goal of becoming **the most powerful and flexible open source data
12 analysis / manipulation tool available in any language**. It is already well on
13 its way toward this goal.
14
15 ## Main Features
16 Here are just a few of the things that pandas does well:
17
18 - Easy handling of [**missing data**][missing-data] (represented as
19 `NaN`) in floating point as well as non-floating point data
20 - Size mutability: columns can be [**inserted and
21 deleted**][insertion-deletion] from DataFrame and higher dimensional
22 objects
23 - Automatic and explicit [**data alignment**][alignment]: objects can
24 be explicitly aligned to a set of labels, or the user can simply
25 ignore the labels and let `Series`, `DataFrame`, etc. automatically
26 align the data for you in computations
27 - Powerful, flexible [**group by**][groupby] functionality to perform
28 split-apply-combine operations on data sets, for both aggregating
29 and transforming data
30 - Make it [**easy to convert**][conversion] ragged,
31 differently-indexed data in other Python and NumPy data structures
32 into DataFrame objects
33 - Intelligent label-based [**slicing**][slicing], [**fancy
34 indexing**][fancy-indexing], and [**subsetting**][subsetting] of
35 large data sets
36 - Intuitive [**merging**][merging] and [**joining**][joining] data
37 sets
38 - Flexible [**reshaping**][reshape] and [**pivoting**][pivot-table] of
39 data sets
40 - [**Hierarchical**][mi] labeling of axes (possible to have multiple
41 labels per tick)
42 - Robust IO tools for loading data from [**flat files**][flat-files]
43 (CSV and delimited), [**Excel files**][excel], [**databases**][db],
44 and saving/loading data from the ultrafast [**HDF5 format**][hdfstore]
45 - [**Time series**][timeseries]-specific functionality: date range
46 generation and frequency conversion, moving window statistics,
47 moving window linear regressions, date shifting and lagging, etc.
48
49
50 [missing-data]: http://pandas.pydata.org/pandas-docs/stable/missing_data.html#working-with-missing-data
51 [insertion-deletion]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
52 [alignment]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html?highlight=alignment#intro-to-data-structures
53 [groupby]: http://pandas.pydata.org/pandas-docs/stable/groupby.html#group-by-split-apply-combine
54 [conversion]: http://pandas.pydata.org/pandas-docs/stable/dsintro.html#dataframe
55 [slicing]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#slicing-ranges
56 [fancy-indexing]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#advanced-indexing-with-ix
57 [subsetting]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#boolean-indexing
58 [merging]: http://pandas.pydata.org/pandas-docs/stable/merging.html#database-style-dataframe-joining-merging
59 [joining]: http://pandas.pydata.org/pandas-docs/stable/merging.html#joining-on-index
60 [reshape]: http://pandas.pydata.org/pandas-docs/stable/reshaping.html#reshaping-and-pivot-tables
61 [pivot-table]: http://pandas.pydata.org/pandas-docs/stable/reshaping.html#pivot-tables-and-cross-tabulations
62 [mi]: http://pandas.pydata.org/pandas-docs/stable/indexing.html#hierarchical-indexing-multiindex
63 [flat-files]: http://pandas.pydata.org/pandas-docs/stable/io.html#csv-text-files
64 [excel]: http://pandas.pydata.org/pandas-docs/stable/io.html#excel-files
65 [db]: http://pandas.pydata.org/pandas-docs/stable/io.html#sql-queries
66 [hdfstore]: http://pandas.pydata.org/pandas-docs/stable/io.html#hdf5-pytables
67 [timeseries]: http://pandas.pydata.org/pandas-docs/stable/timeseries.html#time-series-date-functionality
68
69 ## Where to get it
70 The source code is currently hosted on GitHub at:
71 http://github.com/pydata/pandas
72
73 Binary installers for the latest released version are available at the Python
74 package index
75
76 http://pypi.python.org/pypi/pandas/
77
78 And via `easy_install`:
79
80 ```sh
81 easy_install pandas
82 ```
83
84 or `pip`:
85
86 ```sh
87 pip install pandas
88 ```
89
90 or `conda`:
91
92 ```sh
93 conda install pandas
94 ```
95
96 ## Dependencies
97 - [NumPy](http://www.numpy.org): 1.7.0 or higher
98 - [python-dateutil](http://labix.org/python-dateutil): 1.5 or higher
99 - [pytz](http://pytz.sourceforge.net)
100 - Needed for time zone support with ``pandas.date_range``
101
102 ### Highly Recommended Dependencies
103 - [numexpr](https://github.com/pydata/numexpr)
104 - Needed to accelerate some expression evaluation operations
105 - Required by PyTables
106 - [bottleneck](http://berkeleyanalytics.com/bottleneck)
107 - Needed to accelerate certain numerical operations
108
109 ### Optional dependencies
110 - [Cython](http://www.cython.org): Only necessary to build development version. Version 0.17.1 or higher.
111 - [SciPy](http://www.scipy.org): miscellaneous statistical functions
112 - [PyTables](http://www.pytables.org): necessary for HDF5-based storage
113 - [SQLAlchemy](http://www.sqlalchemy.org): for SQL database support. Version 0.8.1 or higher recommended.
114 - [matplotlib](http://matplotlib.sourceforge.net/): for plotting
115 - [statsmodels](http://statsmodels.sourceforge.net/)
116 - Needed for parts of `pandas.stats`
117 - For Excel I/O:
118 - [xlrd/xlwt](http://www.python-excel.org/)
119 - Excel reading (xlrd) and writing (xlwt)
120 - [openpyxl](http://packages.python.org/openpyxl/)
121 - openpyxl version 1.6.1 or higher, but lower than 2.0.0, for
122 writing .xlsx files
123 - xlrd >= 0.9.0
124 - [XlsxWriter](https://pypi.python.org/pypi/XlsxWriter)
125 - Alternative Excel writer.
126 - [Google bq Command Line Tool](https://developers.google.com/bigquery/bq-command-line-tool/)
127 - Needed for `pandas.io.gbq`
128 - [boto](https://pypi.python.org/pypi/boto): necessary for Amazon S3 access.
129 - One of the following combinations of libraries is needed to use the
130 top-level [`pandas.read_html`][read-html-docs] function:
131 - [BeautifulSoup4][BeautifulSoup4] and [html5lib][html5lib] (Any
132 recent version of [html5lib][html5lib] is okay.)
133 - [BeautifulSoup4][BeautifulSoup4] and [lxml][lxml]
134 - [BeautifulSoup4][BeautifulSoup4] and [html5lib][html5lib] and [lxml][lxml]
135 - Only [lxml][lxml], although see [HTML reading gotchas][html-gotchas]
136 for reasons as to why you should probably **not** take this approach.
137
138 #### Notes about HTML parsing libraries
139 - If you install [BeautifulSoup4][BeautifulSoup4] you must install
140 either [lxml][lxml] or [html5lib][html5lib] or both.
141 `pandas.read_html` will **not** work with *only* `BeautifulSoup4`
142 installed.
143 - You are strongly encouraged to read [HTML reading
144 gotchas][html-gotchas]. It explains issues surrounding the
145 installation and usage of the above three libraries.
146 - You may need to install an older version of
147 [BeautifulSoup4][BeautifulSoup4]:
148 - Versions 4.2.1, 4.1.3 and 4.0.2 have been confirmed for 64 and
149 32-bit Ubuntu/Debian
150 - Additionally, if you're using [Anaconda][Anaconda] you should
151 definitely read [the gotchas about HTML parsing][html-gotchas]
152 libraries
153 - If you're on a system with `apt-get` you can do
154
155 ```sh
156 sudo apt-get build-dep python-lxml
157 ```
158
159 to get the necessary dependencies for installation of [lxml][lxml].
160 This will prevent further headaches down the line.
161
162 [html5lib]: https://github.com/html5lib/html5lib-python "html5lib"
163 [BeautifulSoup4]: http://www.crummy.com/software/BeautifulSoup "BeautifulSoup4"
164 [lxml]: http://lxml.de
165 [Anaconda]: https://store.continuum.io/cshop/anaconda
166 [NumPy]: http://numpy.scipy.org/
167 [html-gotchas]: http://pandas.pydata.org/pandas-docs/stable/gotchas.html#html-table-parsing
168 [read-html-docs]: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.io.html.read_html.html#pandas.io.html.read_html
169
170 ## Installation from sources
171 To install pandas from source you need Cython in addition to the normal
172 dependencies above. Cython can be installed from pypi:
173
174 ```sh
175 pip install cython
176 ```
177
178 In the `pandas` directory (same one where you found this file after
179 cloning the git repo), execute:
180
181 ```sh
182 python setup.py install
183 ```
184
185 or for installing in [development mode](http://www.pip-installer.org/en/latest/usage.html):
186
187 ```sh
188 python setup.py develop
189 ```
190
191 Alternatively, you can use `pip` if you want all the dependencies pulled
192 in automatically (the `-e` option is for installing it in [development
193 mode](http://www.pip-installer.org/en/latest/usage.html)):
194
195 ```sh
196 pip install -e .
197 ```
198
199 On Windows, you will need to install MinGW and execute:
200
201 ```sh
202 python setup.py build --compiler=mingw32
203 python setup.py install
204 ```
205
206 See http://pandas.pydata.org/ for more information.
207
208 ## License
209 BSD
210
211 ## Documentation
212 The official documentation is hosted on PyData.org: http://pandas.pydata.org/
213
214 The Sphinx documentation should provide a good starting point for learning how
215 to use the library. Expect the docs to continue to expand as time goes on.
216
217 ## Background
218 Work on ``pandas`` started at AQR (a quantitative hedge fund) in 2008 and
219 has been under active development since then.
220
221 ## Discussion and Development
222 Since pandas development is related to a number of other scientific
223 Python projects, questions are welcome on the scipy-user mailing
224 list. Specialized discussions or design issues should take place on
225 the PyData mailing list / Google group:
226
227 https://groups.google.com/forum/#!forum/pydata
228
[end of README.md]
[start of pandas/tseries/tools.py]
1 from datetime import datetime, timedelta
2 import re
3 import sys
4
5 import numpy as np
6
7 import pandas.lib as lib
8 import pandas.tslib as tslib
9 import pandas.core.common as com
10 from pandas.compat import StringIO, callable
11 import pandas.compat as compat
12
13 try:
14 import dateutil
15 from dateutil.parser import parse, DEFAULTPARSER
16 from dateutil.relativedelta import relativedelta
17
18 # raise exception if dateutil 2.0 install on 2.x platform
19 if (sys.version_info[0] == 2 and
20 dateutil.__version__ == '2.0'): # pragma: no cover
21 raise Exception('dateutil 2.0 incompatible with Python 2.x, you must '
22 'install version 1.5 or 2.1+!')
23 except ImportError: # pragma: no cover
24 print('Please install python-dateutil via easy_install or some method!')
25 raise # otherwise a 2nd import won't show the message
26
27 _DATEUTIL_LEXER_SPLIT = None
28 try:
29 # Since these are private methods from dateutil, it is safely imported
30 # here so in case this interface changes, pandas will just fallback
31 # to not using the functionality
32 from dateutil.parser import _timelex
33
34 if hasattr(_timelex, 'split'):
35 def _lexer_split_from_str(dt_str):
36 # The StringIO(str(_)) is for dateutil 2.2 compatibility
37 return _timelex.split(StringIO(str(dt_str)))
38
39 _DATEUTIL_LEXER_SPLIT = _lexer_split_from_str
40 except (ImportError, AttributeError):
41 pass
42
43 def _infer_tzinfo(start, end):
44 def _infer(a, b):
45 tz = a.tzinfo
46 if b and b.tzinfo:
47 if not (tslib.get_timezone(tz) == tslib.get_timezone(b.tzinfo)):
48 raise AssertionError('Inputs must both have the same timezone,'
49 ' {0} != {1}'.format(tz, b.tzinfo))
50 return tz
51 tz = None
52 if start is not None:
53 tz = _infer(start, end)
54 elif end is not None:
55 tz = _infer(end, start)
56 return tz
57
58
59 def _guess_datetime_format(dt_str, dayfirst=False,
60 dt_str_parse=compat.parse_date,
61 dt_str_split=_DATEUTIL_LEXER_SPLIT):
62 """
63 Guess the datetime format of a given datetime string.
64
65 Parameters
66 ----------
67 dt_str : string, datetime string to guess the format of
68 dayfirst : boolean, default False
69 If True parses dates with the day first, eg 20/01/2005
70 Warning: dayfirst=True is not strict, but will prefer to parse
71 with day first (this is a known bug).
72 dt_str_parse : function, defaults to `compate.parse_date` (dateutil)
73 This function should take in a datetime string and return
74 a `datetime.datetime` guess that the datetime string represents
75 dt_str_split : function, defaults to `_DATEUTIL_LEXER_SPLIT` (dateutil)
76 This function should take in a datetime string and return
77 a list of strings, the guess of the various specific parts
78 e.g. '2011/12/30' -> ['2011', '/', '12', '/', '30']
79
80 Returns
81 -------
82 ret : datetime formatt string (for `strftime` or `strptime`)
83 """
84 if dt_str_parse is None or dt_str_split is None:
85 return None
86
87 if not isinstance(dt_str, compat.string_types):
88 return None
89
90 day_attribute_and_format = (('day',), '%d')
91
92 datetime_attrs_to_format = [
93 (('year', 'month', 'day'), '%Y%m%d'),
94 (('year',), '%Y'),
95 (('month',), '%B'),
96 (('month',), '%b'),
97 (('month',), '%m'),
98 day_attribute_and_format,
99 (('hour',), '%H'),
100 (('minute',), '%M'),
101 (('second',), '%S'),
102 (('microsecond',), '%f'),
103 (('second', 'microsecond'), '%S.%f'),
104 ]
105
106 if dayfirst:
107 datetime_attrs_to_format.remove(day_attribute_and_format)
108 datetime_attrs_to_format.insert(0, day_attribute_and_format)
109
110 try:
111 parsed_datetime = dt_str_parse(dt_str, dayfirst=dayfirst)
112 except:
113 # In case the datetime can't be parsed, its format cannot be guessed
114 return None
115
116 if parsed_datetime is None:
117 return None
118
119 try:
120 tokens = dt_str_split(dt_str)
121 except:
122 # In case the datetime string can't be split, its format cannot
123 # be guessed
124 return None
125
126 format_guess = [None] * len(tokens)
127 found_attrs = set()
128
129 for attrs, attr_format in datetime_attrs_to_format:
130 # If a given attribute has been placed in the format string, skip
131 # over other formats for that same underlying attribute (IE, month
132 # can be represented in multiple different ways)
133 if set(attrs) & found_attrs:
134 continue
135
136 if all(getattr(parsed_datetime, attr) is not None for attr in attrs):
137 for i, token_format in enumerate(format_guess):
138 if (token_format is None and
139 tokens[i] == parsed_datetime.strftime(attr_format)):
140 format_guess[i] = attr_format
141 found_attrs.update(attrs)
142 break
143
144 # Only consider it a valid guess if we have a year, month and day
145 if len(set(['year', 'month', 'day']) & found_attrs) != 3:
146 return None
147
148 output_format = []
149 for i, guess in enumerate(format_guess):
150 if guess is not None:
151 # Either fill in the format placeholder (like %Y)
152 output_format.append(guess)
153 else:
154 # Or just the token separate (IE, the dashes in "01-01-2013")
155 try:
156 # If the token is numeric, then we likely didn't parse it
157 # properly, so our guess is wrong
158 float(tokens[i])
159 return None
160 except ValueError:
161 pass
162
163 output_format.append(tokens[i])
164
165 guessed_format = ''.join(output_format)
166
167 if parsed_datetime.strftime(guessed_format) == dt_str:
168 return guessed_format
169
170 def _guess_datetime_format_for_array(arr, **kwargs):
171 # Try to guess the format based on the first non-NaN element
172 non_nan_elements = com.notnull(arr).nonzero()[0]
173 if len(non_nan_elements):
174 return _guess_datetime_format(arr[non_nan_elements[0]], **kwargs)
175
176 def to_datetime(arg, errors='ignore', dayfirst=False, utc=None, box=True,
177 format=None, exact=True, coerce=False, unit='ns',
178 infer_datetime_format=False):
179 """
180 Convert argument to datetime.
181
182 Parameters
183 ----------
184 arg : string, datetime, array of strings (with possible NAs)
185 errors : {'ignore', 'raise'}, default 'ignore'
186 Errors are ignored by default (values left untouched)
187 dayfirst : boolean, default False
188 If True parses dates with the day first, eg 20/01/2005
189 Warning: dayfirst=True is not strict, but will prefer to parse
190 with day first (this is a known bug).
191 utc : boolean, default None
192 Return UTC DatetimeIndex if True (converting any tz-aware
193 datetime.datetime objects as well)
194 box : boolean, default True
195 If True returns a DatetimeIndex, if False returns ndarray of values
196 format : string, default None
197 strftime to parse time, eg "%d/%m/%Y", note that "%f" will parse
198 all the way up to nanoseconds
199 exact : boolean, True by default
200 If True, require an exact format match.
201 If False, allow the format to match anywhere in the target string.
202 coerce : force errors to NaT (False by default)
203 Timestamps outside the interval between Timestamp.min and Timestamp.max
204 (approximately 1677-09-22 to 2262-04-11) will be also forced to NaT.
205 unit : unit of the arg (D,s,ms,us,ns) denote the unit in epoch
206 (e.g. a unix timestamp), which is an integer/float number
207 infer_datetime_format : boolean, default False
208 If no `format` is given, try to infer the format based on the first
209 datetime string. Provides a large speed-up in many cases.
210
211 Returns
212 -------
213 ret : datetime if parsing succeeded. Return type depends on input:
214 - list-like: DatetimeIndex
215 - Series: Series of datetime64 dtype
216 - scalar: Timestamp
217 In case when it is not possible to return designated types (e.g. when
218 any element of input is before Timestamp.min or after Timestamp.max)
219 return will have datetime.datetime type (or correspoding array/Series).
220
221 Examples
222 --------
223 Take separate series and convert to datetime
224
225 >>> import pandas as pd
226 >>> i = pd.date_range('20000101',periods=100)
227 >>> df = pd.DataFrame(dict(year = i.year, month = i.month, day = i.day))
228 >>> pd.to_datetime(df.year*10000 + df.month*100 + df.day, format='%Y%m%d')
229 0 2000-01-01
230 1 2000-01-02
231 ...
232 98 2000-04-08
233 99 2000-04-09
234 Length: 100, dtype: datetime64[ns]
235
236 Or from strings
237
238 >>> df = df.astype(str)
239 >>> pd.to_datetime(df.day + df.month + df.year, format="%d%m%Y")
240 0 2000-01-01
241 1 2000-01-02
242 ...
243 98 2000-04-08
244 99 2000-04-09
245 Length: 100, dtype: datetime64[ns]
246
247 Date that does not meet timestamp limitations:
248
249 >>> pd.to_datetime('13000101', format='%Y%m%d')
250 datetime.datetime(1300, 1, 1, 0, 0)
251 >>> pd.to_datetime('13000101', format='%Y%m%d', coerce=True)
252 NaT
253 """
254 from pandas import Timestamp
255 from pandas.core.series import Series
256 from pandas.tseries.index import DatetimeIndex
257
258 def _convert_listlike(arg, box, format):
259
260 if isinstance(arg, (list,tuple)):
261 arg = np.array(arg, dtype='O')
262
263 if com.is_datetime64_ns_dtype(arg):
264 if box and not isinstance(arg, DatetimeIndex):
265 try:
266 return DatetimeIndex(arg, tz='utc' if utc else None)
267 except ValueError:
268 pass
269
270 return arg
271
272 arg = com._ensure_object(arg)
273
274 if infer_datetime_format and format is None:
275 format = _guess_datetime_format_for_array(arg, dayfirst=dayfirst)
276
277 if format is not None:
278 # There is a special fast-path for iso8601 formatted
279 # datetime strings, so in those cases don't use the inferred
280 # format because this path makes process slower in this
281 # special case
282 format_is_iso8601 = (
283 '%Y-%m-%dT%H:%M:%S.%f'.startswith(format) or
284 '%Y-%m-%d %H:%M:%S.%f'.startswith(format)
285 )
286 if format_is_iso8601:
287 format = None
288
289 try:
290 result = None
291
292 if format is not None:
293 # shortcut formatting here
294 if format == '%Y%m%d':
295 try:
296 result = _attempt_YYYYMMDD(arg, coerce=coerce)
297 except:
298 raise ValueError("cannot convert the input to '%Y%m%d' date format")
299
300 # fallback
301 if result is None:
302 try:
303 result = tslib.array_strptime(
304 arg, format, exact=exact, coerce=coerce
305 )
306 except (tslib.OutOfBoundsDatetime):
307 if errors == 'raise':
308 raise
309 result = arg
310 except ValueError:
311 # Only raise this error if the user provided the
312 # datetime format, and not when it was inferred
313 if not infer_datetime_format:
314 raise
315
316 if result is None and (format is None or infer_datetime_format):
317 result = tslib.array_to_datetime(arg, raise_=errors == 'raise',
318 utc=utc, dayfirst=dayfirst,
319 coerce=coerce, unit=unit)
320
321 if com.is_datetime64_dtype(result) and box:
322 result = DatetimeIndex(result, tz='utc' if utc else None)
323 return result
324
325 except ValueError as e:
326 try:
327 values, tz = tslib.datetime_to_datetime64(arg)
328 return DatetimeIndex._simple_new(values, None, tz=tz)
329 except (ValueError, TypeError):
330 raise e
331
332 if arg is None:
333 return arg
334 elif isinstance(arg, Timestamp):
335 return arg
336 elif isinstance(arg, Series):
337 values = _convert_listlike(arg.values, False, format)
338 return Series(values, index=arg.index, name=arg.name)
339 elif com.is_list_like(arg):
340 return _convert_listlike(arg, box, format)
341
342 return _convert_listlike(np.array([ arg ]), box, format)[0]
343
344 class DateParseError(ValueError):
345 pass
346
347 def _attempt_YYYYMMDD(arg, coerce):
348 """ try to parse the YYYYMMDD/%Y%m%d format, try to deal with NaT-like,
349 arg is a passed in as an object dtype, but could really be ints/strings with nan-like/or floats (e.g. with nan) """
350
351 def calc(carg):
352 # calculate the actual result
353 carg = carg.astype(object)
354 return tslib.array_to_datetime(lib.try_parse_year_month_day(carg/10000,carg/100 % 100, carg % 100), coerce=coerce)
355
356 def calc_with_mask(carg,mask):
357 result = np.empty(carg.shape, dtype='M8[ns]')
358 iresult = result.view('i8')
359 iresult[~mask] = tslib.iNaT
360 result[mask] = calc(carg[mask].astype(np.float64).astype(np.int64)).astype('M8[ns]')
361 return result
362
363 # try intlike / strings that are ints
364 try:
365 return calc(arg.astype(np.int64))
366 except:
367 pass
368
369 # a float with actual np.nan
370 try:
371 carg = arg.astype(np.float64)
372 return calc_with_mask(carg,com.notnull(carg))
373 except:
374 pass
375
376 # string with NaN-like
377 try:
378 mask = ~lib.ismember(arg, tslib._nat_strings)
379 return calc_with_mask(arg,mask)
380 except:
381 pass
382
383 return None
384
385 # patterns for quarters like '4Q2005', '05Q1'
386 qpat1full = re.compile(r'(\d)Q-?(\d\d\d\d)')
387 qpat2full = re.compile(r'(\d\d\d\d)-?Q(\d)')
388 qpat1 = re.compile(r'(\d)Q-?(\d\d)')
389 qpat2 = re.compile(r'(\d\d)-?Q(\d)')
390 ypat = re.compile(r'(\d\d\d\d)$')
391 has_time = re.compile('(.+)([\s]|T)+(.+)')
392
393
394 def parse_time_string(arg, freq=None, dayfirst=None, yearfirst=None):
395 """
396 Try hard to parse datetime string, leveraging dateutil plus some extra
397 goodies like quarter recognition.
398
399 Parameters
400 ----------
401 arg : compat.string_types
402 freq : str or DateOffset, default None
403 Helps with interpreting time string if supplied
404 dayfirst : bool, default None
405 If None uses default from print_config
406 yearfirst : bool, default None
407 If None uses default from print_config
408
409 Returns
410 -------
411 datetime, datetime/dateutil.parser._result, str
412 """
413 from pandas.core.config import get_option
414 from pandas.tseries.offsets import DateOffset
415 from pandas.tseries.frequencies import (_get_rule_month, _month_numbers,
416 _get_freq_str)
417
418 if not isinstance(arg, compat.string_types):
419 return arg
420
421 arg = arg.upper()
422
423 default = datetime(1, 1, 1).replace(hour=0, minute=0,
424 second=0, microsecond=0)
425
426 # special handling for possibilities eg, 2Q2005, 2Q05, 2005Q1, 05Q1
427 if len(arg) in [4, 5, 6, 7]:
428 m = ypat.match(arg)
429 if m:
430 ret = default.replace(year=int(m.group(1)))
431 return ret, ret, 'year'
432
433 add_century = False
434 if len(arg) > 5:
435 qpats = [(qpat1full, 1), (qpat2full, 0)]
436 else:
437 add_century = True
438 qpats = [(qpat1, 1), (qpat2, 0)]
439
440 for pat, yfirst in qpats:
441 qparse = pat.match(arg)
442 if qparse is not None:
443 if yfirst:
444 yi, qi = 1, 2
445 else:
446 yi, qi = 2, 1
447 q = int(qparse.group(yi))
448 y_str = qparse.group(qi)
449 y = int(y_str)
450 if add_century:
451 y += 2000
452
453 if freq is not None:
454 # hack attack, #1228
455 mnum = _month_numbers[_get_rule_month(freq)] + 1
456 month = (mnum + (q - 1) * 3) % 12 + 1
457 if month > mnum:
458 y -= 1
459 else:
460 month = (q - 1) * 3 + 1
461
462 ret = default.replace(year=y, month=month)
463 return ret, ret, 'quarter'
464
465 is_mo_str = freq is not None and freq == 'M'
466 is_mo_off = getattr(freq, 'rule_code', None) == 'M'
467 is_monthly = is_mo_str or is_mo_off
468 if len(arg) == 6 and is_monthly:
469 try:
470 ret = _try_parse_monthly(arg)
471 if ret is not None:
472 return ret, ret, 'month'
473 except Exception:
474 pass
475
476 # montly f7u12
477 mresult = _attempt_monthly(arg)
478 if mresult:
479 return mresult
480
481 if dayfirst is None:
482 dayfirst = get_option("display.date_dayfirst")
483 if yearfirst is None:
484 yearfirst = get_option("display.date_yearfirst")
485
486 try:
487 parsed, reso = dateutil_parse(arg, default, dayfirst=dayfirst,
488 yearfirst=yearfirst)
489 except Exception as e:
490 # TODO: allow raise of errors within instead
491 raise DateParseError(e)
492
493 if parsed is None:
494 raise DateParseError("Could not parse %s" % arg)
495
496 return parsed, parsed, reso # datetime, resolution
497
498
499 def dateutil_parse(timestr, default,
500 ignoretz=False, tzinfos=None,
501 **kwargs):
502 """ lifted from dateutil to get resolution"""
503 from dateutil import tz
504 import time
505 fobj = StringIO(str(timestr))
506
507 res = DEFAULTPARSER._parse(fobj, **kwargs)
508
509 # dateutil 2.2 compat
510 if isinstance(res, tuple):
511 res, _ = res
512
513 if res is None:
514 raise ValueError("unknown string format")
515
516 repl = {}
517 reso = None
518 for attr in ["year", "month", "day", "hour",
519 "minute", "second", "microsecond"]:
520 value = getattr(res, attr)
521 if value is not None:
522 repl[attr] = value
523 reso = attr
524
525 if reso is None:
526 raise ValueError("Cannot parse date.")
527
528 if reso == 'microsecond':
529 if repl['microsecond'] == 0:
530 reso = 'second'
531 elif repl['microsecond'] % 1000 == 0:
532 reso = 'millisecond'
533
534 ret = default.replace(**repl)
535 if res.weekday is not None and not res.day:
536 ret = ret + relativedelta.relativedelta(weekday=res.weekday)
537 if not ignoretz:
538 if callable(tzinfos) or tzinfos and res.tzname in tzinfos:
539 if callable(tzinfos):
540 tzdata = tzinfos(res.tzname, res.tzoffset)
541 else:
542 tzdata = tzinfos.get(res.tzname)
543 if isinstance(tzdata, datetime.tzinfo):
544 tzinfo = tzdata
545 elif isinstance(tzdata, compat.string_types):
546 tzinfo = tz.tzstr(tzdata)
547 elif isinstance(tzdata, int):
548 tzinfo = tz.tzoffset(res.tzname, tzdata)
549 else:
550 raise ValueError("offset must be tzinfo subclass, "
551 "tz string, or int offset")
552 ret = ret.replace(tzinfo=tzinfo)
553 elif res.tzname and res.tzname in time.tzname:
554 ret = ret.replace(tzinfo=tz.tzlocal())
555 elif res.tzoffset == 0:
556 ret = ret.replace(tzinfo=tz.tzutc())
557 elif res.tzoffset:
558 ret = ret.replace(tzinfo=tz.tzoffset(res.tzname, res.tzoffset))
559 return ret, reso
560
561
562 def _attempt_monthly(val):
563 pats = ['%Y-%m', '%m-%Y', '%b %Y', '%b-%Y']
564 for pat in pats:
565 try:
566 ret = datetime.strptime(val, pat)
567 return ret, ret, 'month'
568 except Exception:
569 pass
570
571
572 def _try_parse_monthly(arg):
573 base = 2000
574 add_base = False
575 default = datetime(1, 1, 1).replace(hour=0, minute=0, second=0,
576 microsecond=0)
577
578 if len(arg) == 4:
579 add_base = True
580 y = int(arg[:2])
581 m = int(arg[2:4])
582 elif len(arg) >= 6: # 201201
583 y = int(arg[:4])
584 m = int(arg[4:6])
585 if add_base:
586 y += base
587 ret = default.replace(year=y, month=m)
588 return ret
589
590
591 normalize_date = tslib.normalize_date
592
593
594 def format(dt):
595 """Returns date in YYYYMMDD format."""
596 return dt.strftime('%Y%m%d')
597
598 OLE_TIME_ZERO = datetime(1899, 12, 30, 0, 0, 0)
599
600
601 def ole2datetime(oledt):
602 """function for converting excel date to normal date format"""
603 val = float(oledt)
604
605 # Excel has a bug where it thinks the date 2/29/1900 exists
606 # we just reject any date before 3/1/1900.
607 if val < 61:
608 raise ValueError("Value is outside of acceptable range: %s " % val)
609
610 return OLE_TIME_ZERO + timedelta(days=val)
611
[end of pandas/tseries/tools.py]
[start of pandas/util/print_versions.py]
1 import os
2 import platform
3 import sys
4 import struct
5 import subprocess
6 import codecs
7
8
9 def get_sys_info():
10 "Returns system information as a dict"
11
12 blob = []
13
14 # get full commit hash
15 commit = None
16 if os.path.isdir(".git") and os.path.isdir("pandas"):
17 try:
18 pipe = subprocess.Popen('git log --format="%H" -n 1'.split(" "),
19 stdout=subprocess.PIPE, stderr=subprocess.PIPE)
20 so, serr = pipe.communicate()
21 except:
22 pass
23 else:
24 if pipe.returncode == 0:
25 commit = so
26 try:
27 commit = so.decode('utf-8')
28 except ValueError:
29 pass
30 commit = commit.strip().strip('"')
31
32 blob.append(('commit', commit))
33
34 try:
35 sysname, nodename, release, version, machine, processor = platform.uname(
36 )
37 blob.extend([
38 ("python", "%d.%d.%d.%s.%s" % sys.version_info[:]),
39 ("python-bits", struct.calcsize("P") * 8),
40 ("OS", "%s" % (sysname)),
41 ("OS-release", "%s" % (release)),
42 # ("Version", "%s" % (version)),
43 ("machine", "%s" % (machine)),
44 ("processor", "%s" % (processor)),
45 ("byteorder", "%s" % sys.byteorder),
46 ("LC_ALL", "%s" % os.environ.get('LC_ALL', "None")),
47 ("LANG", "%s" % os.environ.get('LANG', "None")),
48
49 ])
50 except:
51 pass
52
53 return blob
54
55
56 def show_versions(as_json=False):
57 import imp
58 sys_info = get_sys_info()
59
60 deps = [
61 # (MODULE_NAME, f(mod) -> mod version)
62 ("pandas", lambda mod: mod.__version__),
63 ("nose", lambda mod: mod.__version__),
64 ("Cython", lambda mod: mod.__version__),
65 ("numpy", lambda mod: mod.version.version),
66 ("scipy", lambda mod: mod.version.version),
67 ("statsmodels", lambda mod: mod.__version__),
68 ("IPython", lambda mod: mod.__version__),
69 ("sphinx", lambda mod: mod.__version__),
70 ("patsy", lambda mod: mod.__version__),
71 ("dateutil", lambda mod: mod.__version__),
72 ("pytz", lambda mod: mod.VERSION),
73 ("bottleneck", lambda mod: mod.__version__),
74 ("tables", lambda mod: mod.__version__),
75 ("numexpr", lambda mod: mod.__version__),
76 ("matplotlib", lambda mod: mod.__version__),
77 ("openpyxl", lambda mod: mod.__version__),
78 ("xlrd", lambda mod: mod.__VERSION__),
79 ("xlwt", lambda mod: mod.__VERSION__),
80 ("xlsxwriter", lambda mod: mod.__version__),
81 ("lxml", lambda mod: mod.etree.__version__),
82 ("bs4", lambda mod: mod.__version__),
83 ("html5lib", lambda mod: mod.__version__),
84 ("httplib2", lambda mod: mod.__version__),
85 ("apiclient", lambda mod: mod.__version__),
86 ("sqlalchemy", lambda mod: mod.__version__),
87 ("pymysql", lambda mod: mod.__version__),
88 ("psycopg2", lambda mod: mod.__version__),
89 ]
90
91 deps_blob = list()
92 for (modname, ver_f) in deps:
93 try:
94 try:
95 mod = imp.load_module(modname, *imp.find_module(modname))
96 except (ImportError):
97 import importlib
98 mod = importlib.import_module(modname)
99 ver = ver_f(mod)
100 deps_blob.append((modname, ver))
101 except:
102 deps_blob.append((modname, None))
103
104 if (as_json):
105 # 2.6-safe
106 try:
107 import json
108 except:
109 import simplejson as json
110
111 j = dict(system=dict(sys_info), dependencies=dict(deps_blob))
112
113 if as_json == True:
114 print(j)
115 else:
116 with codecs.open(as_json, "wb", encoding='utf8') as f:
117 json.dump(j, f, indent=2)
118
119 else:
120
121 print("\nINSTALLED VERSIONS")
122 print("------------------")
123
124 for k, stat in sys_info:
125 print("%s: %s" % (k, stat))
126
127 print("")
128 for k, stat in deps_blob:
129 print("%s: %s" % (k, stat))
130
131
132 def main():
133 # optparse is 2.6-safe
134 from optparse import OptionParser
135 parser = OptionParser()
136 parser.add_option("-j", "--json", metavar="FILE", nargs=1,
137 help="Save output as JSON into file, pass in '-' to output to stdout")
138
139 (options, args) = parser.parse_args()
140
141 if options.json == "-":
142 options.json = True
143
144 show_versions(as_json=options.json)
145
146 return 0
147
148 if __name__ == "__main__":
149 sys.exit(main())
150
[end of pandas/util/print_versions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| pandas-dev/pandas | 8d2818e32d0bbb50e183ccb5724c391e4f604670 | [] (__getitem__) boolean indexing assignment bug with nans
See repro below:
``` python
import pandas as pd
import numpy as np
temp = pd.Series(np.random.randn(10))
temp[3:6] = np.nan
temp[8] = np.nan
nan_index = np.isnan(temp)
# this works
temp1 = temp.copy()
temp1[nan_index] = [99, 99, 99, 99]
temp1[nan_index]
3 99
4 99
5 99
8 99
dtype: float64
# this doesn't - values look like they're being assigned in a different order?
temp2 = temp.copy()
temp2[nan_index] = [99, 99, 99, np.nan]
3 NaN
4 99
5 99
8 99
dtype: float64
# ... but it works properly when using .loc
temp2 = temp.copy()
temp2.loc[nan_index] = [99, 99, 99, np.nan]
3 99
4 99
5 99
8 NaN
dtype: float64
```
output of show_versions():
```
INSTALLED VERSIONS
------------------
commit: None
python: 2.7.9.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.16.0
nose: 1.3.4
Cython: 0.21.2
numpy: 1.9.2
scipy: 0.14.0
statsmodels: 0.5.0
IPython: 3.0.0
sphinx: 1.2.3
patsy: 0.2.1
dateutil: 2.4.1
pytz: 2015.2
bottleneck: 0.8.0
tables: 3.1.1
numexpr: 2.3.1
matplotlib: 1.4.0
openpyxl: 2.0.2
xlrd: 0.9.3
xlwt: 0.7.5
xlsxwriter: 0.6.6
lxml: 3.4.2
bs4: 4.3.2
html5lib: 0.999
httplib2: 0.8
apiclient: None
sqlalchemy: 0.9.8
pymysql: None
psycopg2: None
```
| 2015-03-28T14:08:51Z | <patch>
diff --git a/doc/source/whatsnew/v0.16.1.txt b/doc/source/whatsnew/v0.16.1.txt
--- a/doc/source/whatsnew/v0.16.1.txt
+++ b/doc/source/whatsnew/v0.16.1.txt
@@ -64,3 +64,4 @@ Bug Fixes
- Bug in ``Series.quantile`` on empty Series of type ``Datetime`` or ``Timedelta`` (:issue:`9675`)
+- Bug in ``where`` causing incorrect results when upcasting was required (:issue:`9731`)
diff --git a/pandas/core/common.py b/pandas/core/common.py
--- a/pandas/core/common.py
+++ b/pandas/core/common.py
@@ -1081,15 +1081,6 @@ def _infer_dtype_from_scalar(val):
return dtype, val
-def _maybe_cast_scalar(dtype, value):
- """ if we a scalar value and are casting to a dtype that needs nan -> NaT
- conversion
- """
- if np.isscalar(value) and dtype in _DATELIKE_DTYPES and isnull(value):
- return tslib.iNaT
- return value
-
-
def _maybe_promote(dtype, fill_value=np.nan):
# if we passed an array here, determine the fill value by dtype
@@ -1154,16 +1145,39 @@ def _maybe_promote(dtype, fill_value=np.nan):
return dtype, fill_value
-def _maybe_upcast_putmask(result, mask, other, dtype=None, change=None):
- """ a safe version of put mask that (potentially upcasts the result
- return the result
- if change is not None, then MUTATE the change (and change the dtype)
- return a changed flag
+def _maybe_upcast_putmask(result, mask, other):
"""
+ A safe version of putmask that potentially upcasts the result
- if mask.any():
+ Parameters
+ ----------
+ result : ndarray
+ The destination array. This will be mutated in-place if no upcasting is
+ necessary.
+ mask : boolean ndarray
+ other : ndarray or scalar
+ The source array or value
- other = _maybe_cast_scalar(result.dtype, other)
+ Returns
+ -------
+ result : ndarray
+ changed : boolean
+ Set to true if the result array was upcasted
+ """
+
+ if mask.any():
+ # Two conversions for date-like dtypes that can't be done automatically
+ # in np.place:
+ # NaN -> NaT
+ # integer or integer array -> date-like array
+ if result.dtype in _DATELIKE_DTYPES:
+ if lib.isscalar(other):
+ if isnull(other):
+ other = tslib.iNaT
+ elif is_integer(other):
+ other = np.array(other, dtype=result.dtype)
+ elif is_integer_dtype(other):
+ other = np.array(other, dtype=result.dtype)
def changeit():
@@ -1173,39 +1187,26 @@ def changeit():
om = other[mask]
om_at = om.astype(result.dtype)
if (om == om_at).all():
- new_other = result.values.copy()
- new_other[mask] = om_at
- result[:] = new_other
+ new_result = result.values.copy()
+ new_result[mask] = om_at
+ result[:] = new_result
return result, False
except:
pass
# we are forced to change the dtype of the result as the input
# isn't compatible
- r, fill_value = _maybe_upcast(
- result, fill_value=other, dtype=dtype, copy=True)
- np.putmask(r, mask, other)
-
- # we need to actually change the dtype here
- if change is not None:
-
- # if we are trying to do something unsafe
- # like put a bigger dtype in a smaller one, use the smaller one
- # pragma: no cover
- if change.dtype.itemsize < r.dtype.itemsize:
- raise AssertionError(
- "cannot change dtype of input to smaller size")
- change.dtype = r.dtype
- change[:] = r
+ r, _ = _maybe_upcast(result, fill_value=other, copy=True)
+ np.place(r, mask, other)
return r, True
- # we want to decide whether putmask will work
+ # we want to decide whether place will work
# if we have nans in the False portion of our mask then we need to
- # upcast (possibily) otherwise we DON't want to upcast (e.g. if we are
- # have values, say integers in the success portion then its ok to not
+ # upcast (possibly), otherwise we DON't want to upcast (e.g. if we
+ # have values, say integers, in the success portion then it's ok to not
# upcast)
- new_dtype, fill_value = _maybe_promote(result.dtype, other)
+ new_dtype, _ = _maybe_promote(result.dtype, other)
if new_dtype != result.dtype:
# we have a scalar or len 0 ndarray
@@ -1222,7 +1223,7 @@ def changeit():
return changeit()
try:
- np.putmask(result, mask, other)
+ np.place(result, mask, other)
except:
return changeit()
</patch> | [] | [] | ||||
conan-io__conan-5547 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
build_requirements is ignored
I have A package, which build_requires B package. And C package requires A, build_requires B. When I execute "conan install" for C, conan will skip B. If I remove requires A, conan will not skip B. What I want is conan will install A and B. Any help you can provide would be great.
Thanks
To help us debug your issue please explain:
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
</issue>
<code>
[start of README.rst]
1 |Logo|
2
3 Conan
4 =====
5
6 Decentralized, open-source (MIT), C/C++ package manager.
7
8 - Homepage: https://conan.io/
9 - Github: https://github.com/conan-io/conan
10 - Docs: https://docs.conan.io/en/latest/
11 - Slack: https://cpplang.now.sh/ (#conan channel)
12 - Twitter: https://twitter.com/conan_io
13
14
15 Conan is a package manager for C and C++ developers:
16
17 - It is fully decentralized. Users can host their packages in their servers, privately. Integrates with Artifactory and Bintray.
18 - Portable. Works across all platforms, including Linux, OSX, Windows (with native and first class support, WSL, MinGW),
19 Solaris, FreeBSD, embedded and cross compiling, docker, WSL
20 - Manage binaries. It is able to create, upload and download binaries for any configuration and platform,
21 even cross-compiling, saving lots of time in development and continuous integration. The binary compatibility
22 can be configured and customized. Manage all your artifacts in exactly the same way in all platforms.
23 - Integrates with any build system, including any propietary and custom one. Provides tested support for major build systems
24 (CMake, MSBuild, Makefiles, Meson, etc).
25 - Extensible: Its python based recipes, together with extensions points allows for a great power and flexibility.
26 - Large and active community, specially in Github (https://github.com/conan-io/conan) and Slack (https://cpplang.now.sh/ #conan channel).
27 This community also create and maintains packages in Conan-center and Bincrafters repositories in Bintray.
28 - Stable. Used in production by many companies, since 1.0 there is a committment not to break package recipes and documented behavior.
29
30
31
32 +------------------------+-------------------------+-------------------------+-------------------------+
33 | **master** | **develop** | **Coverage** | **Code Climate** |
34 +========================+=========================+=========================+=========================+
35 | |Build Status Master| | |Build Status Develop| | |Develop coverage| | |Develop climate| |
36 +------------------------+-------------------------+-------------------------+-------------------------+
37
38
39 Setup
40 =====
41
42 Please read https://docs.conan.io/en/latest/installation.html
43
44 From binaries
45 -------------
46
47 We have installers for `most platforms here <http://conan.io>`__ but you
48 can run **conan** from sources if you want.
49
50 From pip
51 --------
52
53 Conan is compatible with Python 2 and Python 3.
54
55 - Install pip following `pip docs`_.
56 - Install conan:
57
58 .. code-block:: bash
59
60 $ pip install conan
61
62 You can also use `test.pypi.org <https://test.pypi.org/project/conan/#history>`_ repository to install development (non-stable) Conan versions:
63
64
65 .. code-block:: bash
66
67 $ pip install --index-url https://test.pypi.org/simple/ conan
68
69
70 From Homebrew (OSx)
71 -------------------
72
73 - Install Homebrew following `brew homepage`_.
74
75 .. code-block:: bash
76
77 $ brew update
78 $ brew install conan
79
80 From source
81 -----------
82
83 You can run **conan** client and server in Windows, MacOS, and Linux.
84
85 - **Install pip following** `pip docs`_.
86
87 - **Clone conan repository:**
88
89 .. code-block:: bash
90
91 $ git clone https://github.com/conan-io/conan.git
92
93 - **Install in editable mode**
94
95 .. code-block:: bash
96
97 $ cd conan && sudo pip install -e .
98
99 If you are in Windows, using ``sudo`` is not required.
100
101 - **You are ready, try to run conan:**
102
103 .. code-block::
104
105 $ conan --help
106
107 Consumer commands
108 install Installs the requirements specified in a conanfile (.py or .txt).
109 config Manages configuration. Edits the conan.conf or installs config files.
110 get Gets a file or list a directory of a given reference or package.
111 info Gets information about the dependency graph of a recipe.
112 search Searches package recipes and binaries in the local cache or in a remote.
113 Creator commands
114 new Creates a new package recipe template with a 'conanfile.py'.
115 create Builds a binary package for recipe (conanfile.py) located in current dir.
116 upload Uploads a recipe and binary packages to a remote.
117 export Copies the recipe (conanfile.py & associated files) to your local cache.
118 export-pkg Exports a recipe & creates a package with given files calling 'package'.
119 test Test a package, consuming it with a conanfile recipe with a test() method.
120 Package development commands
121 source Calls your local conanfile.py 'source()' method.
122 build Calls your local conanfile.py 'build()' method.
123 package Calls your local conanfile.py 'package()' method.
124 Misc commands
125 profile Lists profiles in the '.conan/profiles' folder, or shows profile details.
126 remote Manages the remote list and the package recipes associated to a remote.
127 user Authenticates against a remote with user/pass, caching the auth token.
128 imports Calls your local conanfile.py or conanfile.txt 'imports' method.
129 copy Copies conan recipes and packages to another user/channel.
130 remove Removes packages or binaries matching pattern from local cache or remote.
131 alias Creates and exports an 'alias recipe'.
132 download Downloads recipe and binaries to the local cache, without using settings.
133
134 Conan commands. Type "conan <command> -h" for help
135
136 Contributing to the project
137 ===========================
138
139 Feedback and contribution is always welcome in this project.
140 Please read our `contributing guide <https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md>`_.
141
142 Running the tests
143 =================
144
145 Using tox
146 ---------
147
148 .. code-block:: bash
149
150 $ tox
151
152 It will install the needed requirements and launch `nose` skipping some heavy and slow test.
153 If you want to run the full test suite:
154
155 .. code-block:: bash
156
157 $ tox -e full
158
159 Without tox
160 -----------
161
162 **Install python requirements**
163
164 .. code-block:: bash
165
166 $ pip install -r conans/requirements.txt
167 $ pip install -r conans/requirements_server.txt
168 $ pip install -r conans/requirements_dev.txt
169
170
171 Only in OSX:
172
173 .. code-block:: bash
174
175 $ pip install -r conans/requirements_osx.txt # You can omit this one if not running OSX
176
177
178 If you are not Windows and you are not using a python virtual environment, you will need to run these
179 commands using `sudo`.
180
181 Before you can run the tests, you need to set a few environment variables first.
182
183 .. code-block:: bash
184
185 $ export PYTHONPATH=$PYTHONPATH:$(pwd)
186
187 On Windows it would be (while being in the conan root directory):
188
189 .. code-block:: bash
190
191 $ set PYTHONPATH=.
192
193 Ensure that your ``cmake`` has version 2.8 or later. You can see the
194 version with the following command:
195
196 .. code-block:: bash
197
198 $ cmake --version
199
200 The appropriate values of ``CONAN_COMPILER`` and ``CONAN_COMPILER_VERSION`` depend on your
201 operating system and your requirements.
202
203 These should work for the GCC from ``build-essential`` on Ubuntu 14.04:
204
205 .. code-block:: bash
206
207 $ export CONAN_COMPILER=gcc
208 $ export CONAN_COMPILER_VERSION=4.8
209
210 These should work for OS X:
211
212 .. code-block:: bash
213
214 $ export CONAN_COMPILER=clang
215 $ export CONAN_COMPILER_VERSION=3.5
216
217 Finally, there are some tests that use conan to package Go-lang
218 libraries, so you might **need to install go-lang** in your computer and
219 add it to the path.
220
221 You can run the actual tests like this:
222
223 .. code-block:: bash
224
225 $ nosetests .
226
227
228 There are a couple of test attributes defined, as ``slow``, or ``golang`` that you can use
229 to filter the tests, and do not execute them:
230
231 .. code-block:: bash
232
233 $ nosetests . -a !golang
234
235 A few minutes later it should print ``OK``:
236
237 .. code-block:: bash
238
239 ............................................................................................
240 ----------------------------------------------------------------------
241 Ran 146 tests in 50.993s
242
243 OK
244
245 To run specific tests, you can specify the test name too, something like:
246
247 .. code-block:: bash
248
249 $ nosetests conans.test.command.config_install_test:ConfigInstallTest.install_file_test --nocapture
250
251 The ``--nocapture`` argument can be useful to see some output that otherwise is captured by nosetests.
252
253 License
254 -------
255
256 `MIT LICENSE <./LICENSE.md>`__
257
258 .. |Build Status Master| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/master
259 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/master
260
261 .. |Build Status Develop| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/develop
262 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/develop
263
264 .. |Master coverage| image:: https://codecov.io/gh/conan-io/conan/branch/master/graph/badge.svg
265 :target: https://codecov.io/gh/conan-io/conan/branch/master
266
267 .. |Develop coverage| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graph/badge.svg
268 :target: https://codecov.io/gh/conan-io/conan/branch/develop
269
270 .. |Coverage graph| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graphs/tree.svg
271 :height: 50px
272 :width: 50 px
273 :alt: Conan develop coverage
274
275 .. |Develop climate| image:: https://api.codeclimate.com/v1/badges/081b53e570d5220b34e4/maintainability.svg
276 :target: https://codeclimate.com/github/conan-io/conan/maintainability
277
278 .. |Logo| image:: https://conan.io/img/jfrog_conan_logo.png
279
280
281 .. _`pip docs`: https://pip.pypa.io/en/stable/installing/
282
283 .. _`brew homepage`: http://brew.sh/
284
[end of README.rst]
[start of conans/client/generators/ycm.py]
1 import json
2
3 from conans.model import Generator
4
5
6 class YouCompleteMeGenerator(Generator):
7 template = '''
8 # This file is NOT licensed under the GPLv3, which is the license for the rest
9 # of YouCompleteMe.
10 #
11 # Here's the license text for this file:
12 #
13 # This is free and unencumbered software released into the public domain.
14 #
15 # Anyone is free to copy, modify, publish, use, compile, sell, or
16 # distribute this software, either in source code form or as a compiled
17 # binary, for any purpose, commercial or non-commercial, and by any
18 # means.
19 #
20 # In jurisdictions that recognize copyright laws, the author or authors
21 # of this software dedicate any and all copyright interest in the
22 # software to the public domain. We make this dedication for the benefit
23 # of the public at large and to the detriment of our heirs and
24 # successors. We intend this dedication to be an overt act of
25 # relinquishment in perpetuity of all present and future rights to this
26 # software under copyright law.
27 #
28 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
29 # EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
30 # MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
31 # IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
32 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
33 # ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
34 # OTHER DEALINGS IN THE SOFTWARE.
35 #
36 # For more information, please refer to <http://unlicense.org/>
37
38 import os
39 import json
40 import ycm_core
41 import logging
42
43
44 _logger = logging.getLogger(__name__)
45
46
47 def DirectoryOfThisScript():
48 return os.path.dirname( os.path.abspath( __file__ ) )
49
50
51 # These are the compilation flags that will be used in case there's no
52 # compilation database set (by default, one is not set).
53 # CHANGE THIS LIST OF FLAGS. YES, THIS IS THE DROID YOU HAVE BEEN LOOKING FOR.
54 flags = [
55 '-x', 'c++'
56 ]
57
58 conan_flags = json.loads(open("conan_ycm_flags.json", "r").read())
59
60 flags.extend(conan_flags["flags"])
61 flags.extend(conan_flags["defines"])
62 flags.extend(conan_flags["includes"])
63
64
65 # Set this to the absolute path to the folder (NOT the file!) containing the
66 # compile_commands.json file to use that instead of 'flags'. See here for
67 # more details: http://clang.llvm.org/docs/JSONCompilationDatabase.html
68 #
69 # You can get CMake to generate this file for you by adding:
70 # set( CMAKE_EXPORT_COMPILE_COMMANDS 1 )
71 # to your CMakeLists.txt file.
72 #
73 # Most projects will NOT need to set this to anything; you can just change the
74 # 'flags' list of compilation flags. Notice that YCM itself uses that approach.
75 compilation_database_folder = os.path.join(DirectoryOfThisScript(), 'Debug')
76
77 if os.path.exists( compilation_database_folder ):
78 database = ycm_core.CompilationDatabase( compilation_database_folder )
79 if not database.DatabaseSuccessfullyLoaded():
80 _logger.warn("Failed to load database")
81 database = None
82 else:
83 database = None
84
85 SOURCE_EXTENSIONS = [ '.cpp', '.cxx', '.cc', '.c', '.m', '.mm' ]
86
87 def GetAbsolutePath(include_path, working_directory):
88 if os.path.isabs(include_path):
89 return include_path
90 return os.path.join(working_directory, include_path)
91
92
93 def MakeRelativePathsInFlagsAbsolute( flags, working_directory ):
94 if not working_directory:
95 return list( flags )
96 new_flags = []
97 make_next_absolute = False
98 path_flags = [ '-isystem', '-I', '-iquote', '--sysroot=' ]
99 for flag in flags:
100 new_flag = flag
101
102 if make_next_absolute:
103 make_next_absolute = False
104 new_flag = GetAbsolutePath(flag, working_directory)
105
106 for path_flag in path_flags:
107 if flag == path_flag:
108 make_next_absolute = True
109 break
110
111 if flag.startswith( path_flag ):
112 path = flag[ len( path_flag ): ]
113 new_flag = flag[:len(path_flag)] + GetAbsolutePath(path, working_directory)
114 break
115
116 if new_flag:
117 new_flags.append( new_flag )
118 return new_flags
119
120
121 def IsHeaderFile( filename ):
122 extension = os.path.splitext( filename )[ 1 ]
123 return extension.lower() in [ '.h', '.hxx', '.hpp', '.hh' ]
124
125
126 def GetCompilationInfoForFile( filename ):
127 # The compilation_commands.json file generated by CMake does not have entries
128 # for header files. So we do our best by asking the db for flags for a
129 # corresponding source file, if any. If one exists, the flags for that file
130 # should be good enough.
131 if IsHeaderFile( filename ):
132 basename = os.path.splitext( filename )[ 0 ]
133 for extension in SOURCE_EXTENSIONS:
134 replacement_file = basename + extension
135 if os.path.exists( replacement_file ):
136 compilation_info = database.GetCompilationInfoForFile( replacement_file )
137 if compilation_info.compiler_flags_:
138 return compilation_info
139 return None
140 return database.GetCompilationInfoForFile( filename )
141
142
143 def FlagsForFile( filename, **kwargs ):
144 relative_to = None
145 compiler_flags = None
146
147 if database:
148 # Bear in mind that compilation_info.compiler_flags_ does NOT return a
149 # python list, but a "list-like" StringVec object
150 compilation_info = GetCompilationInfoForFile( filename )
151 if compilation_info is None:
152 relative_to = DirectoryOfThisScript()
153 compiler_flags = flags
154 else:
155 relative_to = compilation_info.compiler_working_dir_
156 compiler_flags = compilation_info.compiler_flags_
157
158 else:
159 relative_to = DirectoryOfThisScript()
160 compiler_flags = flags
161
162 final_flags = MakeRelativePathsInFlagsAbsolute( compiler_flags, relative_to )
163 for flag in final_flags:
164 if flag.startswith("-W"):
165 final_flags.remove(flag)
166 _logger.info("Final flags for %s are %s" % (filename, ' '.join(final_flags)))
167
168 return {{
169 'flags': final_flags + ["-I/usr/include", "-I/usr/include/c++/{cxx_version}"],
170 'do_cache': True
171 }}
172 '''
173
174 @property
175 def filename(self):
176 pass
177
178 @property
179 def content(self):
180 def prefixed(prefix, values):
181 return [prefix + x for x in values]
182
183 conan_flags = {
184 "includes": prefixed("-isystem", self.deps_build_info.include_paths),
185 "defines": prefixed("-D", self.deps_build_info.defines),
186 "flags": self.deps_build_info.cxxflags
187 }
188
189 cxx_version = ''
190 try:
191 cxx_version = str(self.settings.compiler.version).split('.')[0]
192 except Exception:
193 pass
194
195 ycm_data = self.template.format(cxx_version=cxx_version)
196 return {"conan_ycm_extra_conf.py": ycm_data,
197 "conan_ycm_flags.json": json.dumps(conan_flags, indent=2)}
198
[end of conans/client/generators/ycm.py]
[start of conans/client/graph/graph_manager.py]
1 import fnmatch
2 import os
3 from collections import OrderedDict
4
5 from conans.client.generators.text import TXTGenerator
6 from conans.client.graph.build_mode import BuildMode
7 from conans.client.graph.graph import BINARY_BUILD, Node,\
8 RECIPE_CONSUMER, RECIPE_VIRTUAL, BINARY_EDITABLE
9 from conans.client.graph.graph_binaries import GraphBinariesAnalyzer
10 from conans.client.graph.graph_builder import DepsGraphBuilder
11 from conans.errors import ConanException, conanfile_exception_formatter
12 from conans.model.conan_file import get_env_context_manager
13 from conans.model.graph_info import GraphInfo
14 from conans.model.graph_lock import GraphLock, GraphLockFile
15 from conans.model.ref import ConanFileReference
16 from conans.paths import BUILD_INFO
17 from conans.util.files import load
18
19
20 class _RecipeBuildRequires(OrderedDict):
21 def __init__(self, conanfile):
22 super(_RecipeBuildRequires, self).__init__()
23 build_requires = getattr(conanfile, "build_requires", [])
24 if not isinstance(build_requires, (list, tuple)):
25 build_requires = [build_requires]
26 for build_require in build_requires:
27 self.add(build_require)
28
29 def add(self, build_require):
30 if not isinstance(build_require, ConanFileReference):
31 build_require = ConanFileReference.loads(build_require)
32 self[build_require.name] = build_require
33
34 def __call__(self, build_require):
35 self.add(build_require)
36
37 def update(self, build_requires):
38 for build_require in build_requires:
39 self.add(build_require)
40
41 def __str__(self):
42 return ", ".join(str(r) for r in self.values())
43
44
45 class GraphManager(object):
46 def __init__(self, output, cache, remote_manager, loader, proxy, resolver):
47 self._proxy = proxy
48 self._output = output
49 self._resolver = resolver
50 self._cache = cache
51 self._remote_manager = remote_manager
52 self._loader = loader
53
54 def load_consumer_conanfile(self, conanfile_path, info_folder,
55 deps_info_required=False, test=None):
56 """loads a conanfile for local flow: source, imports, package, build
57 """
58 try:
59 graph_info = GraphInfo.load(info_folder)
60 graph_lock_file = GraphLockFile.load(info_folder)
61 graph_lock = graph_lock_file.graph_lock
62 self._output.info("Using lockfile: '{}/conan.lock'".format(info_folder))
63 profile = graph_lock_file.profile
64 self._output.info("Using cached profile from lockfile")
65 except IOError: # Only if file is missing
66 graph_lock = None
67 # This is very dirty, should be removed for Conan 2.0 (source() method only)
68 profile = self._cache.default_profile
69 profile.process_settings(self._cache)
70 name, version, user, channel = None, None, None, None
71 else:
72 name, version, user, channel, _ = graph_info.root
73 profile.process_settings(self._cache, preprocess=False)
74 # This is the hack of recovering the options from the graph_info
75 profile.options.update(graph_info.options)
76 processed_profile = profile
77 if conanfile_path.endswith(".py"):
78 lock_python_requires = None
79 if graph_lock and not test: # Only lock python requires if it is not test_package
80 node_id = graph_lock.get_node(graph_info.root)
81 lock_python_requires = graph_lock.python_requires(node_id)
82 conanfile = self._loader.load_consumer(conanfile_path,
83 processed_profile=processed_profile, test=test,
84 name=name, version=version,
85 user=user, channel=channel,
86 lock_python_requires=lock_python_requires)
87 with get_env_context_manager(conanfile, without_python=True):
88 with conanfile_exception_formatter(str(conanfile), "config_options"):
89 conanfile.config_options()
90 with conanfile_exception_formatter(str(conanfile), "configure"):
91 conanfile.configure()
92
93 conanfile.settings.validate() # All has to be ok!
94 conanfile.options.validate()
95 else:
96 conanfile = self._loader.load_conanfile_txt(conanfile_path, processed_profile)
97
98 load_deps_info(info_folder, conanfile, required=deps_info_required)
99
100 return conanfile
101
102 def load_graph(self, reference, create_reference, graph_info, build_mode, check_updates, update,
103 remotes, recorder, apply_build_requires=True):
104
105 def _inject_require(conanfile, ref):
106 """ test_package functionality requires injecting the tested package as requirement
107 before running the install
108 """
109 require = conanfile.requires.get(ref.name)
110 if require:
111 require.ref = require.range_ref = ref
112 else:
113 conanfile.requires.add_ref(ref)
114 conanfile._conan_user = ref.user
115 conanfile._conan_channel = ref.channel
116
117 # Computing the full dependency graph
118 profile = graph_info.profile
119 processed_profile = profile
120 processed_profile.dev_reference = create_reference
121 ref = None
122 graph_lock = graph_info.graph_lock
123 if isinstance(reference, list): # Install workspace with multiple root nodes
124 conanfile = self._loader.load_virtual(reference, processed_profile,
125 scope_options=False)
126 root_node = Node(ref, conanfile, recipe=RECIPE_VIRTUAL)
127 elif isinstance(reference, ConanFileReference):
128 if not self._cache.config.revisions_enabled and reference.revision is not None:
129 raise ConanException("Revisions not enabled in the client, specify a "
130 "reference without revision")
131 # create without test_package and install <ref>
132 conanfile = self._loader.load_virtual([reference], processed_profile)
133 root_node = Node(ref, conanfile, recipe=RECIPE_VIRTUAL)
134 if graph_lock: # Find the Node ID in the lock of current root
135 graph_lock.find_consumer_node(root_node, reference)
136 else:
137 path = reference
138 if path.endswith(".py"):
139 test = str(create_reference) if create_reference else None
140 lock_python_requires = None
141 # do not try apply lock_python_requires for test_package/conanfile.py consumer
142 if graph_lock and not create_reference:
143 if graph_info.root.name is None:
144 # If the graph_info information is not there, better get what we can from
145 # the conanfile
146 conanfile = self._loader.load_class(path)
147 graph_info.root = ConanFileReference(graph_info.root.name or conanfile.name,
148 graph_info.root.version or conanfile.version,
149 graph_info.root.user,
150 graph_info.root.channel, validate=False)
151 node_id = graph_lock.get_node(graph_info.root)
152 lock_python_requires = graph_lock.python_requires(node_id)
153
154 conanfile = self._loader.load_consumer(path, processed_profile, test=test,
155 name=graph_info.root.name,
156 version=graph_info.root.version,
157 user=graph_info.root.user,
158 channel=graph_info.root.channel,
159 lock_python_requires=lock_python_requires)
160 if create_reference: # create with test_package
161 _inject_require(conanfile, create_reference)
162
163 ref = ConanFileReference(conanfile.name, conanfile.version,
164 conanfile._conan_user, conanfile._conan_channel,
165 validate=False)
166 else:
167 conanfile = self._loader.load_conanfile_txt(path, processed_profile,
168 ref=graph_info.root)
169
170 root_node = Node(ref, conanfile, recipe=RECIPE_CONSUMER)
171
172 if graph_lock: # Find the Node ID in the lock of current root
173 graph_lock.find_consumer_node(root_node, create_reference)
174
175 build_mode = BuildMode(build_mode, self._output)
176 deps_graph = self._load_graph(root_node, check_updates, update,
177 build_mode=build_mode, remotes=remotes,
178 profile_build_requires=profile.build_requires,
179 recorder=recorder,
180 processed_profile=processed_profile,
181 apply_build_requires=apply_build_requires,
182 graph_lock=graph_lock)
183
184 # THIS IS NECESSARY to store dependencies options in profile, for consumer
185 # FIXME: This is a hack. Might dissapear if graph for local commands is always recomputed
186 graph_info.options = root_node.conanfile.options.values
187 if ref:
188 graph_info.root = ref
189 if graph_info.graph_lock is None:
190 graph_info.graph_lock = GraphLock(deps_graph)
191 else:
192 graph_info.graph_lock.update_check_graph(deps_graph, self._output)
193
194 version_ranges_output = self._resolver.output
195 if version_ranges_output:
196 self._output.success("Version ranges solved")
197 for msg in version_ranges_output:
198 self._output.info(" %s" % msg)
199 self._output.writeln("")
200
201 build_mode.report_matches()
202 return deps_graph, conanfile
203
204 @staticmethod
205 def _get_recipe_build_requires(conanfile):
206 conanfile.build_requires = _RecipeBuildRequires(conanfile)
207 if hasattr(conanfile, "build_requirements"):
208 with get_env_context_manager(conanfile):
209 with conanfile_exception_formatter(str(conanfile), "build_requirements"):
210 conanfile.build_requirements()
211
212 return conanfile.build_requires
213
214 def _recurse_build_requires(self, graph, builder, binaries_analyzer, check_updates, update,
215 build_mode, remotes, profile_build_requires, recorder,
216 processed_profile, graph_lock, apply_build_requires=True):
217
218 binaries_analyzer.evaluate_graph(graph, build_mode, update, remotes)
219 if not apply_build_requires:
220 return
221
222 for node in graph.ordered_iterate():
223 # Virtual conanfiles doesn't have output, but conanfile.py and conanfile.txt do
224 # FIXME: To be improved and build a explicit model for this
225 if node.recipe == RECIPE_VIRTUAL:
226 continue
227 if (node.binary not in (BINARY_BUILD, BINARY_EDITABLE)
228 and node.recipe != RECIPE_CONSUMER):
229 continue
230 package_build_requires = self._get_recipe_build_requires(node.conanfile)
231 str_ref = str(node.ref)
232 new_profile_build_requires = []
233 profile_build_requires = profile_build_requires or {}
234 for pattern, build_requires in profile_build_requires.items():
235 if ((node.recipe == RECIPE_CONSUMER and pattern == "&") or
236 (node.recipe != RECIPE_CONSUMER and pattern == "&!") or
237 fnmatch.fnmatch(str_ref, pattern)):
238 for build_require in build_requires:
239 if build_require.name in package_build_requires: # Override defined
240 # this is a way to have only one package Name for all versions
241 # (no conflicts)
242 # but the dict key is not used at all
243 package_build_requires[build_require.name] = build_require
244 elif build_require.name != node.name: # Profile one
245 new_profile_build_requires.append(build_require)
246
247 if package_build_requires:
248 subgraph = builder.extend_build_requires(graph, node,
249 package_build_requires.values(),
250 check_updates, update, remotes,
251 processed_profile, graph_lock)
252 self._recurse_build_requires(subgraph, builder, binaries_analyzer, check_updates,
253 update, build_mode,
254 remotes, profile_build_requires, recorder,
255 processed_profile, graph_lock)
256 graph.nodes.update(subgraph.nodes)
257
258 if new_profile_build_requires:
259 subgraph = builder.extend_build_requires(graph, node, new_profile_build_requires,
260 check_updates, update, remotes,
261 processed_profile, graph_lock)
262 self._recurse_build_requires(subgraph, builder, binaries_analyzer, check_updates,
263 update, build_mode,
264 remotes, {}, recorder,
265 processed_profile, graph_lock)
266 graph.nodes.update(subgraph.nodes)
267
268 def _load_graph(self, root_node, check_updates, update, build_mode, remotes,
269 profile_build_requires, recorder, processed_profile, apply_build_requires,
270 graph_lock):
271
272 assert isinstance(build_mode, BuildMode)
273 builder = DepsGraphBuilder(self._proxy, self._output, self._loader, self._resolver,
274 recorder)
275 graph = builder.load_graph(root_node, check_updates, update, remotes, processed_profile,
276 graph_lock)
277 binaries_analyzer = GraphBinariesAnalyzer(self._cache, self._output,
278 self._remote_manager)
279
280 self._recurse_build_requires(graph, builder, binaries_analyzer, check_updates, update,
281 build_mode, remotes,
282 profile_build_requires, recorder, processed_profile,
283 graph_lock,
284 apply_build_requires=apply_build_requires)
285
286 # Sort of closures, for linking order
287 inverse_levels = {n: i for i, level in enumerate(graph.inverse_levels()) for n in level}
288 for node in graph.nodes:
289 closure = node.public_closure
290 closure.pop(node.name)
291 node_order = list(closure.values())
292 # List sort is stable, will keep the original order of closure, but prioritize levels
293 node_order.sort(key=lambda n: inverse_levels[n])
294 node.public_closure = node_order
295
296 return graph
297
298
299 def load_deps_info(current_path, conanfile, required):
300
301 def get_forbidden_access_object(field_name):
302 class InfoObjectNotDefined(object):
303 def __getitem__(self, item):
304 raise ConanException("self.%s not defined. If you need it for a "
305 "local command run 'conan install'" % field_name)
306 __getattr__ = __getitem__
307
308 return InfoObjectNotDefined()
309
310 if not current_path:
311 return
312 info_file_path = os.path.join(current_path, BUILD_INFO)
313 try:
314 deps_cpp_info, deps_user_info, deps_env_info = TXTGenerator.loads(load(info_file_path))
315 conanfile.deps_cpp_info = deps_cpp_info
316 conanfile.deps_user_info = deps_user_info
317 conanfile.deps_env_info = deps_env_info
318 except IOError:
319 if required:
320 raise ConanException("%s file not found in %s\nIt is required for this command\n"
321 "You can generate it using 'conan install'"
322 % (BUILD_INFO, current_path))
323 conanfile.deps_cpp_info = get_forbidden_access_object("deps_cpp_info")
324 conanfile.deps_user_info = get_forbidden_access_object("deps_user_info")
325 except ConanException:
326 raise ConanException("Parse error in '%s' file in %s" % (BUILD_INFO, current_path))
327
[end of conans/client/graph/graph_manager.py]
[start of conans/model/conan_file.py]
1 import os
2 from contextlib import contextmanager
3
4 from conans.client import tools
5 from conans.client.output import Color, ScopedOutput
6 from conans.client.tools.env import environment_append, no_op, pythonpath
7 from conans.client.tools.oss import OSInfo
8 from conans.errors import ConanException, ConanInvalidConfiguration
9 from conans.model.build_info import DepsCppInfo
10 from conans.model.env_info import DepsEnvInfo
11 from conans.model.options import Options, OptionsValues, PackageOptions
12 from conans.model.requires import Requirements
13 from conans.model.user_info import DepsUserInfo
14 from conans.paths import RUN_LOG_NAME
15
16
17 def create_options(conanfile):
18 try:
19 package_options = PackageOptions(getattr(conanfile, "options", None))
20 options = Options(package_options)
21
22 default_options = getattr(conanfile, "default_options", None)
23 if default_options:
24 if isinstance(default_options, (list, tuple, dict)):
25 default_values = OptionsValues(default_options)
26 elif isinstance(default_options, str):
27 default_values = OptionsValues.loads(default_options)
28 else:
29 raise ConanException("Please define your default_options as list, "
30 "multiline string or dictionary")
31 options.values = default_values
32 return options
33 except Exception as e:
34 raise ConanException("Error while initializing options. %s" % str(e))
35
36
37 def create_requirements(conanfile):
38 try:
39 # Actual requirements of this package
40 if not hasattr(conanfile, "requires"):
41 return Requirements()
42 else:
43 if not conanfile.requires:
44 return Requirements()
45 if isinstance(conanfile.requires, (tuple, list)):
46 return Requirements(*conanfile.requires)
47 else:
48 return Requirements(conanfile.requires, )
49 except Exception as e:
50 raise ConanException("Error while initializing requirements. %s" % str(e))
51
52
53 def create_settings(conanfile, settings):
54 try:
55 defined_settings = getattr(conanfile, "settings", None)
56 if isinstance(defined_settings, str):
57 defined_settings = [defined_settings]
58 current = defined_settings or {}
59 settings.constraint(current)
60 return settings
61 except Exception as e:
62 raise ConanInvalidConfiguration("Error while initializing settings. %s" % str(e))
63
64
65 @contextmanager
66 def _env_and_python(conanfile):
67 with environment_append(conanfile.env):
68 with pythonpath(conanfile):
69 yield
70
71
72 def get_env_context_manager(conanfile, without_python=False):
73 if not conanfile.apply_env:
74 return no_op()
75 if without_python:
76 return environment_append(conanfile.env)
77 return _env_and_python(conanfile)
78
79
80 class ConanFile(object):
81 """ The base class for all package recipes
82 """
83
84 name = None
85 version = None # Any str, can be "1.1" or whatever
86 url = None # The URL where this File is located, as github, to collaborate in package
87 # The license of the PACKAGE, just a shortcut, does not replace or
88 # change the actual license of the source code
89 license = None
90 author = None # Main maintainer/responsible for the package, any format
91 description = None
92 topics = None
93 homepage = None
94 build_policy = None
95 short_paths = False
96 apply_env = True # Apply environment variables from requires deps_env_info and profiles
97 exports = None
98 exports_sources = None
99 generators = ["txt"]
100 revision_mode = "hash"
101
102 # Vars to control the build steps (build(), package())
103 should_configure = True
104 should_build = True
105 should_install = True
106 should_test = True
107 in_local_cache = True
108 develop = False
109
110 # Defaulting the reference fields
111 default_channel = None
112 default_user = None
113
114 # Settings and Options
115 settings = None
116 options = None
117 default_options = None
118
119 def __init__(self, output, runner, display_name="", user=None, channel=None):
120 # an output stream (writeln, info, warn error)
121 self.output = ScopedOutput(display_name, output)
122 self.display_name = display_name
123 # something that can run commands, as os.sytem
124 self._conan_runner = runner
125 self._conan_user = user
126 self._conan_channel = channel
127
128 def initialize(self, settings, env):
129 if isinstance(self.generators, str):
130 self.generators = [self.generators]
131 # User defined options
132 self.options = create_options(self)
133 self.requires = create_requirements(self)
134 self.settings = create_settings(self, settings)
135
136 try:
137 if self.settings.os_build and self.settings.os:
138 self.output.writeln("*"*60, front=Color.BRIGHT_RED)
139 self.output.writeln(" This package defines both 'os' and 'os_build' ",
140 front=Color.BRIGHT_RED)
141 self.output.writeln(" Please use 'os' for libraries and 'os_build'",
142 front=Color.BRIGHT_RED)
143 self.output.writeln(" only for build-requires used for cross-building",
144 front=Color.BRIGHT_RED)
145 self.output.writeln("*"*60, front=Color.BRIGHT_RED)
146 except ConanException:
147 pass
148
149 if 'cppstd' in self.settings.fields:
150 self.output.warn("Setting 'cppstd' is deprecated in favor of 'compiler.cppstd',"
151 " please update your recipe.")
152
153 # needed variables to pack the project
154 self.cpp_info = None # Will be initialized at processing time
155 self.deps_cpp_info = DepsCppInfo()
156
157 # environment variables declared in the package_info
158 self.env_info = None # Will be initialized at processing time
159 self.deps_env_info = DepsEnvInfo()
160
161 # user declared variables
162 self.user_info = None
163 # Keys are the package names, and the values a dict with the vars
164 self.deps_user_info = DepsUserInfo()
165
166 # user specified env variables
167 self._conan_env_values = env.copy() # user specified -e
168
169 @property
170 def env(self):
171 """Apply the self.deps_env_info into a copy of self._conan_env_values (will prioritize the
172 self._conan_env_values, user specified from profiles or -e first, then inherited)"""
173 # Cannot be lazy cached, because it's called in configure node, and we still don't have
174 # the deps_env_info objects available
175 tmp_env_values = self._conan_env_values.copy()
176 tmp_env_values.update(self.deps_env_info)
177
178 ret, multiple = tmp_env_values.env_dicts(self.name)
179 ret.update(multiple)
180 return ret
181
182 @property
183 def channel(self):
184 if not self._conan_channel:
185 self._conan_channel = os.getenv("CONAN_CHANNEL") or self.default_channel
186 if not self._conan_channel:
187 raise ConanException("CONAN_CHANNEL environment variable not defined, "
188 "but self.channel is used in conanfile")
189 return self._conan_channel
190
191 @property
192 def user(self):
193 if not self._conan_user:
194 self._conan_user = os.getenv("CONAN_USERNAME") or self.default_user
195 if not self._conan_user:
196 raise ConanException("CONAN_USERNAME environment variable not defined, "
197 "but self.user is used in conanfile")
198 return self._conan_user
199
200 def collect_libs(self, folder=None):
201 self.output.warn("'self.collect_libs' is deprecated, "
202 "use 'tools.collect_libs(self)' instead")
203 return tools.collect_libs(self, folder=folder)
204
205 @property
206 def build_policy_missing(self):
207 return self.build_policy == "missing"
208
209 @property
210 def build_policy_always(self):
211 return self.build_policy == "always"
212
213 def source(self):
214 pass
215
216 def system_requirements(self):
217 """ this method can be overwritten to implement logic for system package
218 managers, as apt-get
219
220 You can define self.global_system_requirements = True, if you want the installation
221 to be for all packages (not depending on settings/options/requirements)
222 """
223
224 def config_options(self):
225 """ modify options, probably conditioned to some settings. This call is executed
226 before config_settings. E.g.
227 if self.settings.os == "Windows":
228 del self.options.shared # shared/static not supported in win
229 """
230
231 def configure(self):
232 """ modify settings, probably conditioned to some options. This call is executed
233 after config_options. E.g.
234 if self.options.header_only:
235 self.settings.clear()
236 This is also the place for conditional requirements
237 """
238
239 def build(self):
240 """ build your project calling the desired build tools as done in the command line.
241 E.g. self.run("cmake --build .") Or use the provided build helpers. E.g. cmake.build()
242 """
243 self.output.warn("This conanfile has no build step")
244
245 def package(self):
246 """ package the needed files from source and build folders.
247 E.g. self.copy("*.h", src="src/includes", dst="includes")
248 """
249 self.output.warn("This conanfile has no package step")
250
251 def package_info(self):
252 """ define cpp_build_info, flags, etc
253 """
254
255 def run(self, command, output=True, cwd=None, win_bash=False, subsystem=None, msys_mingw=True,
256 ignore_errors=False, run_environment=False, with_login=True):
257 def _run():
258 if not win_bash:
259 return self._conan_runner(command, output, os.path.abspath(RUN_LOG_NAME), cwd)
260 # FIXME: run in windows bash is not using output
261 return tools.run_in_windows_bash(self, bashcmd=command, cwd=cwd, subsystem=subsystem,
262 msys_mingw=msys_mingw, with_login=with_login)
263 if run_environment:
264 with tools.run_environment(self):
265 if OSInfo().is_macos:
266 command = 'DYLD_LIBRARY_PATH="%s" %s' % (os.environ.get('DYLD_LIBRARY_PATH', ''),
267 command)
268 retcode = _run()
269 else:
270 retcode = _run()
271
272 if not ignore_errors and retcode != 0:
273 raise ConanException("Error %d while executing %s" % (retcode, command))
274
275 return retcode
276
277 def package_id(self):
278 """ modify the binary info, typically to narrow values
279 e.g.: self.info.settings.compiler = "Any" => All compilers will generate same ID
280 """
281
282 def test(self):
283 """ test the generated executable.
284 E.g. self.run("./example")
285 """
286 raise ConanException("You need to create a method 'test' in your test/conanfile.py")
287
288 def __repr__(self):
289 return self.display_name
290
[end of conans/model/conan_file.py]
[start of setup.py]
1 """A setuptools based setup module.
2 See:
3 https://packaging.python.org/en/latest/distributing.html
4 https://github.com/pypa/sampleproject
5 """
6
7 import os
8 import platform
9 import re
10 # To use a consistent encoding
11 from codecs import open
12 from os import path
13
14 # Always prefer setuptools over distutils
15 from setuptools import find_packages, setup
16
17 here = path.abspath(path.dirname(__file__))
18
19
20 def get_requires(filename):
21 requirements = []
22 with open(filename, "rt") as req_file:
23 for line in req_file.read().splitlines():
24 if not line.strip().startswith("#"):
25 requirements.append(line)
26 return requirements
27
28
29 project_requirements = get_requires("conans/requirements.txt")
30 if platform.system() == "Darwin":
31 project_requirements.extend(get_requires("conans/requirements_osx.txt"))
32 project_requirements.extend(get_requires("conans/requirements_server.txt"))
33 dev_requirements = get_requires("conans/requirements_dev.txt")
34 # The tests utils are used by conan-package-tools
35 exclude_test_packages = ["conans.test.{}*".format(d)
36 for d in os.listdir(os.path.join(here, "conans/test"))
37 if os.path.isdir(os.path.join(here, "conans/test", d)) and d != "utils"]
38
39
40 def load_version():
41 '''Loads a file content'''
42 filename = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(__file__)),
43 "conans", "__init__.py"))
44 with open(filename, "rt") as version_file:
45 conan_init = version_file.read()
46 version = re.search("__version__ = '([0-9a-z.-]+)'", conan_init).group(1)
47 return version
48
49
50 def generate_long_description_file():
51 this_directory = path.abspath(path.dirname(__file__))
52 with open(path.join(this_directory, 'README.rst'), encoding='utf-8') as f:
53 long_description = f.read()
54 return long_description
55
56
57 setup(
58 name='conan',
59 # Versions should comply with PEP440. For a discussion on single-sourcing
60 # the version across setup.py and the project code, see
61 # https://packaging.python.org/en/latest/single_source_version.html
62 version=load_version(), # + ".rc1",
63
64 description='Conan C/C++ package manager',
65 long_description=generate_long_description_file(),
66 long_description_content_type='text/x-rst',
67
68 # The project's main homepage.
69 url='https://conan.io',
70
71 # Author details
72 author='JFrog LTD',
73 author_email='[email protected]',
74
75 # Choose your license
76 license='MIT',
77
78 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
79 classifiers=[
80 'Development Status :: 5 - Production/Stable',
81 'Intended Audience :: Developers',
82 'Topic :: Software Development :: Build Tools',
83 'License :: OSI Approved :: MIT License',
84 'Programming Language :: Python :: 2',
85 'Programming Language :: Python :: 2.7',
86 'Programming Language :: Python :: 3',
87 'Programming Language :: Python :: 3.6'
88 ],
89
90 # What does your project relate to?
91 keywords=['C/C++', 'package', 'libraries', 'developer', 'manager',
92 'dependency', 'tool', 'c', 'c++', 'cpp'],
93
94 # You can just specify the packages manually here if your project is
95 # simple. Or you can use find_packages().
96 packages=find_packages(exclude=exclude_test_packages),
97
98 # Alternatively, if you want to distribute just a my_module.py, uncomment
99 # this:
100 # py_modules=["my_module"],
101
102 # List run-time dependencies here. These will be installed by pip when
103 # your project is installed. For an analysis of "install_requires" vs pip's
104 # requirements files see:
105 # https://packaging.python.org/en/latest/requirements.html
106 install_requires=project_requirements,
107
108 # List additional groups of dependencies here (e.g. development
109 # dependencies). You can install these using the following syntax,
110 # for example:
111 # $ pip install -e .[dev,test]
112 extras_require={
113 'dev': dev_requirements,
114 'test': dev_requirements,
115 },
116
117 # If there are data files included in your packages that need to be
118 # installed, specify them here. If using Python 2.6 or less, then these
119 # have to be included in MANIFEST.in as well.
120 package_data={
121 'conans': ['*.txt'],
122 },
123
124 # Although 'package_data' is the preferred approach, in some case you may
125 # need to place data files outside of your packages. See:
126 # http://docs.python.org/3.4/distutils/setupscript.html#installing-additional-files # noqa
127 # In this case, 'data_file' will be installed into '<sys.prefix>/my_data'
128 # data_files=[('my_data', ['data/data_file'])],
129
130 # To provide executable scripts, use entry points in preference to the
131 # "scripts" keyword. Entry points provide cross-platform support and allow
132 # pip to create the appropriate form of executable for the target platform.
133 entry_points={
134 'console_scripts': [
135 'conan=conans.conan:run',
136 'conan_server=conans.conan_server:run',
137 'conan_build_info=conans.build_info.command:run'
138 ],
139 },
140 )
141
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| conan-io/conan | 56a5b42691907598535ff9e61ac8eac0fb251305 | build_requirements is ignored
I have A package, which build_requires B package. And C package requires A, build_requires B. When I execute "conan install" for C, conan will skip B. If I remove requires A, conan will not skip B. What I want is conan will install A and B. Any help you can provide would be great.
Thanks
To help us debug your issue please explain:
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [x] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
| Hi @xyz1001
I am trying to reproduce your case, but so far no success. Please check the following test, that is passing:
```python
class BuildRequiresTest(unittest.TestCase):
def test_consumer(self):
# https://github.com/conan-io/conan/issues/5425
t = TestClient()
t.save({"conanfile.py": str(TestConanFile("ToolB", "0.1"))})
t.run("create . ToolB/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibA", "0.1",
build_requires=["ToolB/0.1@user/testing"]))})
t.run("create . LibA/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibC", "0.1",
requires=["LibA/0.1@user/testing"],
build_requires=["ToolB/0.1@user/testing"]))})
t.run("install .")
self.assertIn("ToolB/0.1@user/testing from local cache", t.out)
```
As you can see, the build require to ToolB is not being skipped. Could you please double check it? Maybe a more complete and reproducible case would help. Thanks!
I am sorry, LibA is private_requires ToolB. I modified the test case:
```
class BuildRequiresTest(unittest.TestCase):
def test_consumer(self):
# https://github.com/conan-io/conan/issues/5425
t = TestClient()
t.save({"conanfile.py": str(TestConanFile("ToolB", "0.1"))})
t.run("create . ToolB/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibA", "0.1",
private_requires=[("ToolB/0.1@user/testing")]))})
t.run("create . LibA/0.1@user/testing")
t.save({"conanfile.py": str(TestConanFile("LibC", "0.1",
requires=[
"LibA/0.1@user/testing"],
build_requires=["ToolB/0.1@user/testing"]))})
t.run("install .")
self.assertIn("ToolB/0.1@user/testing from local cache", t.out)
```
I try the test case and it is passed. However, In my project `XXX`, it did print `ToolB/0.1@user/testing from local cache`, but the conanbuildinfo.txt has not any info about the `ToolB`. Here is the `conan install` output:
```
conanfile.py (XXX/None@None/None): Installing package
Requirements
catch2/2.4.2@bincrafters/stable from 'conan-local' - Cache
fmt/5.2.1@bincrafters/stable from 'conan-local' - Cache
xxx_logger/1.2.13@screenshare/stable from 'conan-local' - Cache
spdlog/1.2.1@bincrafters/stable from 'conan-local' - Cache
Packages
catch2/2.4.2@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Skip
fmt/5.2.1@bincrafters/stable:038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec - Cache
xxx_logger/1.2.13@screenshare/stable:aa971e8736e335273eb99282f27319bdaa20df9d - Cache
spdlog/1.2.1@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Cache
Build requirements
catch2/2.4.2@bincrafters/stable from 'conan-local' - Cache
Build requirements packages
catch2/2.4.2@bincrafters/stable:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Skip
fmt/5.2.1@bincrafters/stable: Already installed!
spdlog/1.2.1@bincrafters/stable: Already installed!
xxx_logger/1.2.13@screenshare/stable: Already installed!
```
catch2 -> ToolB
xxx_logger -> LibA
XXX -> LibC
here is the conanbuildinfo.txt.
```
[includedirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/include
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/include
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/include
[libdirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/lib
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/lib
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/lib
[bindirs]
[resdirs]
[builddirs]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/
[libs]
xxx_logger
pthread
fmtd
[defines]
SPDLOG_FMT_EXTERNAL
[cppflags]
[cxxflags]
[cflags]
[sharedlinkflags]
[exelinkflags]
[sysroot]
[includedirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/include
[libdirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/lib
[bindirs_xxx_logger]
[resdirs_xxx_logger]
[builddirs_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d/
[libs_xxx_logger]
xxx_logger
pthread
[defines_xxx_logger]
[cppflags_xxx_logger]
[cxxflags_xxx_logger]
[cflags_xxx_logger]
[sharedlinkflags_xxx_logger]
[exelinkflags_xxx_logger]
[sysroot_xxx_logger]
[rootpath_xxx_logger]
/home/xyz1001/.conan/data/xxx_logger/1.2.13/screenshare/stable/package/aa971e8736e335273eb99282f27319bdaa20df9d
[includedirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/include
[libdirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/lib
[bindirs_spdlog]
[resdirs_spdlog]
[builddirs_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9/
[libs_spdlog]
pthread
[defines_spdlog]
SPDLOG_FMT_EXTERNAL
[cppflags_spdlog]
[cxxflags_spdlog]
[cflags_spdlog]
[sharedlinkflags_spdlog]
[exelinkflags_spdlog]
[sysroot_spdlog]
[rootpath_spdlog]
/home/xyz1001/.conan/data/spdlog/1.2.1/bincrafters/stable/package/5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9
[includedirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/include
[libdirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/lib
[bindirs_fmt]
[resdirs_fmt]
[builddirs_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec/
[libs_fmt]
fmtd
[defines_fmt]
[cppflags_fmt]
[cxxflags_fmt]
[cflags_fmt]
[sharedlinkflags_fmt]
[exelinkflags_fmt]
[sysroot_fmt]
[rootpath_fmt]
/home/xyz1001/.conan/data/fmt/5.2.1/bincrafters/stable/package/038f8796e196b3dba76fcc5fd4ef5d3d9c6866ec
[USER_xxx_logger]
[USER_spdlog]
[USER_fmt]
[ENV_xxx_logger]
[ENV_spdlog]
[ENV_fmt]
```
Confirmed this is an unfortunate bug, coming from a mixture of build-requirements and private requirements. It seems not trivial, it would take some time to fix.
In the meanwhile, I would strongly suggest to reconsider the usage of ``private`` requirements. We are discouraging its use (as you can see they are barely documented), should be only for some extreme cases, like needing to wrap 2 different versions of the same library. What would be the case of ``private`` requirement of ``catch`` library?
| 2019-07-29T07:06:58Z | <patch>
diff --git a/conans/client/graph/graph_binaries.py b/conans/client/graph/graph_binaries.py
--- a/conans/client/graph/graph_binaries.py
+++ b/conans/client/graph/graph_binaries.py
@@ -39,7 +39,6 @@ def _evaluate_node(self, node, build_mode, update, evaluated_nodes, remotes):
return
ref, conanfile = node.ref, node.conanfile
- pref = node.pref
# If it has lock
locked = node.graph_lock_node
if locked and locked.pref.id == node.package_id:
@@ -53,7 +52,13 @@ def _evaluate_node(self, node, build_mode, update, evaluated_nodes, remotes):
if previous_nodes:
previous_nodes.append(node)
previous_node = previous_nodes[0]
- node.binary = previous_node.binary
+ # The previous node might have been skipped, but current one not necessarily
+ # keep the original node.binary value (before being skipped), and if it will be
+ # defined as SKIP again by self._handle_private(node) if it is really private
+ if previous_node.binary == BINARY_SKIP:
+ node.binary = previous_node.binary_non_skip
+ else:
+ node.binary = previous_node.binary
node.binary_remote = previous_node.binary_remote
node.prev = previous_node.prev
return
@@ -229,6 +234,8 @@ def _handle_private(self, node):
# Current closure contains own node to be skipped
for n in neigh.public_closure.values():
if n.private:
+ # store the binary origin before being overwritten by SKIP
+ n.binary_non_skip = n.binary
n.binary = BINARY_SKIP
self._handle_private(n)
</patch> | [] | [] | |||
PrefectHQ__prefect-2646 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement Depth-First Execution with Mapping
Currently each "level" of a mapped pipeline is executed before proceeding to the next level. This is undesirable especially for pipelines where it's important that each "branch" of the pipeline finish as quickly as possible.
To implement DFE, we'll need to rearrange two things:
- how mapped work gets submitted (it should start being submitted from the Flow Runner not the Task Runner)
- in order to submit work to Dask and let Dask handle the DFE scheduling, we'll want to refactor how we walk the DAG and wait to determine the width of a pipeline before we submit it (because mapping is fully dynamic we can only ascertain this width at runtime)
We'll need to be vigilant about:
- performance
- retries
- result handling
</issue>
<code>
[start of README.md]
1 <p align="center" style="margin-bottom:40px;">
2 <img src="https://uploads-ssl.webflow.com/5ba446b0e783e26d5a2f2382/5c942c9ca934ec5c88588297_primary-color-vertical.svg" height=350 style="max-height: 350px;">
3 </p>
4
5 <p align="center">
6 <a href=https://circleci.com/gh/PrefectHQ/prefect/tree/master>
7 <img src="https://circleci.com/gh/PrefectHQ/prefect/tree/master.svg?style=shield&circle-token=28689a55edc3c373486aaa5f11a1af3e5fc53344">
8 </a>
9
10 <a href="https://codecov.io/gh/PrefectHQ/prefect">
11 <img src="https://codecov.io/gh/PrefectHQ/prefect/branch/master/graph/badge.svg" />
12 </a>
13
14 <a href=https://github.com/ambv/black>
15 <img src="https://img.shields.io/badge/code%20style-black-000000.svg">
16 </a>
17
18 <a href="https://pypi.org/project/prefect/">
19 <img src="https://img.shields.io/pypi/dm/prefect.svg?color=%2327B1FF&label=installs&logoColor=%234D606E">
20 </a>
21
22 <a href="https://hub.docker.com/r/prefecthq/prefect">
23 <img src="https://img.shields.io/docker/pulls/prefecthq/prefect.svg?color=%2327B1FF&logoColor=%234D606E">
24 </a>
25
26 <a href="https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE">
27 <img src="https://prefect-slackin.herokuapp.com/badge.svg">
28 </a>
29
30 </p>
31
32 ## Hello, world! 👋
33
34 We've rebuilt data engineering for the data science era.
35
36 Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. Users organize `Tasks` into `Flows`, and Prefect takes care of the rest.
37
38 Read the [docs](https://docs.prefect.io); get the [code](#installation); ask us [anything](https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE)!
39
40 ### Welcome to Workflows
41
42 Prefect's Pythonic API should feel familiar for newcomers. Mark functions as tasks and call them on each other to build up a flow.
43
44 ```python
45 from prefect import task, Flow, Parameter
46
47
48 @task(log_stdout=True)
49 def say_hello(name):
50 print("Hello, {}!".format(name))
51
52
53 with Flow("My First Flow") as flow:
54 name = Parameter('name')
55 say_hello(name)
56
57
58 flow.run(name='world') # "Hello, world!"
59 flow.run(name='Marvin') # "Hello, Marvin!"
60 ```
61
62 For more detail, please see the [Core docs](https://docs.prefect.io/core/)
63
64 ### UI and Server
65
66 <p align="center" style="margin-bottom:40px;">
67 <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/orchestration/ui/dashboard-overview.png" height=440 style="max-height: 440px;">
68 </p>
69
70 In addition to the [Prefect Cloud](https://www.prefect.io/cloud) platform, Prefect includes an open-source server and UI for orchestrating and managing flows. The local server stores flow metadata in a Postgres database and exposes a GraphQL API.
71
72 Before running the server for the first time, run `prefect backend server` to configure Prefect for local orchestration. Please note the server requires [Docker](https://www.docker.com/) and [Docker Compose](https://docs.docker.com/compose/install/) to be running.
73
74 To start the server, UI, and all required infrastructure, run:
75
76 ```
77 prefect server start
78 ```
79
80 Once all components are running, you can view the UI by visiting [http://localhost:8080](http://localhost:8080).
81
82 Please note that executing flows from the server requires at least one Prefect Agent to be running: `prefect agent start`.
83
84 Finally, to register any flow with the server, call `flow.register()`. For more detail, please see the [orchestration docs](https://docs.prefect.io/orchestration/).
85
86 ## "...Prefect?"
87
88 From the Latin _praefectus_, meaning "one who is in charge", a prefect is an official who oversees a domain and makes sure that the rules are followed. Similarly, Prefect is responsible for making sure that workflows execute properly.
89
90 It also happens to be the name of a roving researcher for that wholly remarkable book, _The Hitchhiker's Guide to the Galaxy_.
91
92 ## Integrations
93
94 Thanks to Prefect's growing task library and deep ecosystem integrations, building data applications is easier than ever.
95
96 Something missing? Open a [feature request](https://github.com/PrefectHQ/prefect/issues/new/choose) or [contribute a PR](https://docs.prefect.io/core/development/overview.html)! Prefect was designed to make adding new functionality extremely easy, whether you build on top of the open-source package or maintain an internal task library for your team.
97
98 ### Task Library
99
100 | | | | | |
101 | :---: | :---: | :---: | :---: | :---: |
102 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/airtable.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Airtable</p>](https://docs.prefect.io/core/task_library/airtable.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/aws.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>AWS</p>](https://docs.prefect.io/core/task_library/aws.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure</p>](https://docs.prefect.io/core/task_library/azure.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure_ml.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure ML</p>](https://docs.prefect.io/core/task_library/azureml.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dbt.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>DBT</p>](https://docs.prefect.io/core/task_library/dbt.html) |
103 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/docker.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Docker</p>](https://docs.prefect.io/core/task_library/docker.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dropbox.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Dropbox</p>](https://docs.prefect.io/core/task_library/dropbox.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/email.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Email</p>](https://docs.prefect.io/core/task_library/email.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/google_cloud.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Google Cloud</p>](https://docs.prefect.io/core/task_library/gcp.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/github.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>GitHub</p>](https://docs.prefect.io/core/task_library/github.html) |
104 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/jira.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Jira</p>](https://docs.prefect.io/core/task_library/jira.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/kubernetes.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Kubernetes</p>](https://docs.prefect.io/core/task_library/kubernetes.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/postgres.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>PostgreSQL</p>](https://docs.prefect.io/core/task_library/postgres.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/python.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Python</p>](https://docs.prefect.io/core/task_library/function.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/pushbullet.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Pushbullet</p>](https://docs.prefect.io/core/task_library/pushbullet.html) |
105 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/redis.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Redis</p>](https://docs.prefect.io/core/task_library/redis.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/rss.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>RSS</p>](https://docs.prefect.io/core/task_library/rss.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/shell.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Shell</p>](https://docs.prefect.io/core/task_library/shell.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/slack.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Slack</p>](https://docs.prefect.io/core/task_library/slack.html)| <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/snowflake.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Snowflake</p>](https://docs.prefect.io/core/task_library/snowflake.html) |
106 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/spacy.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>SpaCy</p>](https://docs.prefect.io/core/task_library/spacy.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/sqlite.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>SQLite</p>](https://docs.prefect.io/core/task_library/sqlite.html) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/twitter.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Twitter</p>](https://docs.prefect.io/core/task_library/twitter.html) |
107
108 ### Deployment & Execution
109
110 | | | | | |
111 | :---: | :---: | :---: | :---: | :---: |
112 | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/azure.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Azure</p>](https://azure.microsoft.com/en-us/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/aws.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>AWS</p>](https://aws.amazon.com/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/dask.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Dask</p>](https://dask.org/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/docker.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Docker</p>](https://www.docker.com/) | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/google_cloud.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Google Cloud</p>](https://cloud.google.com/)
113 <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/kubernetes.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Kubernetes</p>](https://kubernetes.io/) | | | | <img src="https://raw.githubusercontent.com/PrefectHQ/prefect/master/docs/.vuepress/public/logos/shell.png" height=128 width=128 style="max-height: 128px; max-width: 128px;"> [<p>Universal Deploy</p>](https://medium.com/the-prefect-blog/introducing-prefect-universal-deploy-7992283e5911)
114
115 ## Resources
116
117 Prefect provides a variety of resources to help guide you to a successful outcome.
118
119 We are committed to ensuring a positive environment, and all interactions are governed by our [Code of Conduct](https://docs.prefect.io/core/code_of_conduct.html).
120
121 ### Documentation
122
123 Prefect's documentation -- including concepts, tutorials, and a full API reference -- is always available at [docs.prefect.io](https://docs.prefect.io).
124
125 Instructions for contributing to documentation can be found in the [development guide](https://docs.prefect.io/core/development/documentation.html).
126
127 ### Slack Community
128
129 Join our [Slack](https://join.slack.com/t/prefect-community/shared_invite/enQtODQ3MTA2MjI4OTgyLTliYjEyYzljNTc2OThlMDE4YmViYzk3NDU4Y2EzMWZiODM0NmU3NjM0NjIyNWY0MGIxOGQzODMxNDMxYWYyOTE) to chat about Prefect, ask questions, and share tips.
130
131 ### Blog
132
133 Visit the [Prefect Blog](https://medium.com/the-prefect-blog) for updates and insights from the Prefect team.
134
135 ### Support
136
137 Prefect offers a variety of community and premium [support options](https://www.prefect.io/support) for users of both Prefect Core and Prefect Cloud.
138
139 ### Contributing
140
141 Read about Prefect's [community](https://docs.prefect.io/core/community.html) or dive in to the [development guides](https://docs.prefect.io/core/development/overview.html) for information about contributions, documentation, code style, and testing.
142
143 ## Installation
144
145 ### Requirements
146
147 Prefect requires Python 3.6+. If you're new to Python, we recommend installing the [Anaconda distribution](https://www.anaconda.com/distribution/).
148
149 ### Latest Release
150
151 To install Prefect, run:
152
153 ```bash
154 pip install prefect
155 ```
156
157 or, if you prefer to use `conda`:
158
159 ```bash
160 conda install -c conda-forge prefect
161 ```
162
163 or `pipenv`:
164
165 ```bash
166 pipenv install --pre prefect
167 ```
168
169 ### Bleeding Edge
170
171 For development or just to try out the latest features, you may want to install Prefect directly from source.
172
173 Please note that the master branch of Prefect is not guaranteed to be compatible with Prefect Cloud or the local server.
174
175 ```bash
176 git clone https://github.com/PrefectHQ/prefect.git
177 pip install ./prefect
178 ```
179
180 ## License
181
182 Prefect is variously licensed under the [Apache Software License Version 2.0](https://www.apache.org/licenses/LICENSE-2.0) or the [Prefect Community License](https://www.prefect.io/legal/prefect-community-license).
183
184 All code except the `/server` directory is Apache 2.0-licensed unless otherwise noted. The `/server` directory is licensed under the Prefect Community License.
185
[end of README.md]
[start of src/prefect/engine/flow_runner.py]
1 from typing import (
2 Any,
3 Callable,
4 Dict,
5 Iterable,
6 NamedTuple,
7 Optional,
8 Set,
9 Union,
10 )
11
12 import pendulum
13
14 import prefect
15 from prefect.core import Edge, Flow, Task
16 from prefect.engine.result import Result
17 from prefect.engine.results import ConstantResult
18 from prefect.engine.runner import ENDRUN, Runner, call_state_handlers
19 from prefect.engine.state import (
20 Cancelled,
21 Failed,
22 Mapped,
23 Pending,
24 Retrying,
25 Running,
26 Scheduled,
27 State,
28 Success,
29 )
30 from prefect.utilities.collections import flatten_seq
31 from prefect.utilities.executors import run_with_heartbeat
32
33 FlowRunnerInitializeResult = NamedTuple(
34 "FlowRunnerInitializeResult",
35 [
36 ("state", State),
37 ("task_states", Dict[Task, State]),
38 ("context", Dict[str, Any]),
39 ("task_contexts", Dict[Task, Dict[str, Any]]),
40 ],
41 )
42
43
44 class FlowRunner(Runner):
45 """
46 FlowRunners handle the execution of Flows and determine the State of a Flow
47 before, during and after the Flow is run.
48
49 In particular, through the FlowRunner you can specify which tasks should be
50 the first tasks to run, which tasks should be returned after the Flow is finished,
51 and what states each task should be initialized with.
52
53 Args:
54 - flow (Flow): the `Flow` to be run
55 - task_runner_cls (TaskRunner, optional): The class used for running
56 individual Tasks. Defaults to [TaskRunner](task_runner.html)
57 - state_handlers (Iterable[Callable], optional): A list of state change handlers
58 that will be called whenever the flow changes state, providing an
59 opportunity to inspect or modify the new state. The handler
60 will be passed the flow runner instance, the old (prior) state, and the new
61 (current) state, with the following signature:
62 `state_handler(fr: FlowRunner, old_state: State, new_state: State) -> Optional[State]`
63 If multiple functions are passed, then the `new_state` argument will be the
64 result of the previous handler.
65
66 Note: new FlowRunners are initialized within the call to `Flow.run()` and in general,
67 this is the endpoint through which FlowRunners will be interacted with most frequently.
68
69 Example:
70 ```python
71 @task
72 def say_hello():
73 print('hello')
74
75 with Flow("My Flow") as f:
76 say_hello()
77
78 fr = FlowRunner(flow=f)
79 flow_state = fr.run()
80 ```
81 """
82
83 def __init__(
84 self,
85 flow: Flow,
86 task_runner_cls: type = None,
87 state_handlers: Iterable[Callable] = None,
88 ):
89 self.context = prefect.context.to_dict()
90 self.flow = flow
91 if task_runner_cls is None:
92 task_runner_cls = prefect.engine.get_default_task_runner_class()
93 self.task_runner_cls = task_runner_cls
94 super().__init__(state_handlers=state_handlers)
95
96 def __repr__(self) -> str:
97 return "<{}: {}>".format(type(self).__name__, self.flow.name)
98
99 def call_runner_target_handlers(self, old_state: State, new_state: State) -> State:
100 """
101 A special state handler that the FlowRunner uses to call its flow's state handlers.
102 This method is called as part of the base Runner's `handle_state_change()` method.
103
104 Args:
105 - old_state (State): the old (previous) state
106 - new_state (State): the new (current) state
107
108 Returns:
109 - State: the new state
110 """
111 self.logger.debug(
112 "Flow '{name}': Handling state change from {old} to {new}".format(
113 name=self.flow.name,
114 old=type(old_state).__name__,
115 new=type(new_state).__name__,
116 )
117 )
118 for handler in self.flow.state_handlers:
119 new_state = handler(self.flow, old_state, new_state) or new_state
120
121 return new_state
122
123 def initialize_run( # type: ignore
124 self,
125 state: Optional[State],
126 task_states: Dict[Task, State],
127 context: Dict[str, Any],
128 task_contexts: Dict[Task, Dict[str, Any]],
129 parameters: Dict[str, Any],
130 ) -> FlowRunnerInitializeResult:
131 """
132 Initializes the Task run by initializing state and context appropriately.
133
134 If the provided state is a Submitted state, the state it wraps is extracted.
135
136 Args:
137 - state (Optional[State]): the initial state of the run
138 - task_states (Dict[Task, State]): a dictionary of any initial task states
139 - context (Dict[str, Any], optional): prefect.Context to use for execution
140 to use for each Task run
141 - task_contexts (Dict[Task, Dict[str, Any]], optional): contexts that will be provided to each task
142 - parameters(dict): the parameter values for the run
143
144 Returns:
145 - NamedTuple: a tuple of initialized objects:
146 `(state, task_states, context, task_contexts)`
147 """
148
149 # overwrite context parameters one-by-one
150 if parameters:
151 context_params = context.setdefault("parameters", {})
152 for param, value in parameters.items():
153 context_params[param] = value
154
155 context.update(flow_name=self.flow.name)
156 context.setdefault("scheduled_start_time", pendulum.now("utc"))
157
158 # add various formatted dates to context
159 now = pendulum.now("utc")
160 dates = {
161 "date": now,
162 "today": now.strftime("%Y-%m-%d"),
163 "yesterday": now.add(days=-1).strftime("%Y-%m-%d"),
164 "tomorrow": now.add(days=1).strftime("%Y-%m-%d"),
165 "today_nodash": now.strftime("%Y%m%d"),
166 "yesterday_nodash": now.add(days=-1).strftime("%Y%m%d"),
167 "tomorrow_nodash": now.add(days=1).strftime("%Y%m%d"),
168 }
169 for key, val in dates.items():
170 context.setdefault(key, val)
171
172 for task in self.flow.tasks:
173 task_contexts.setdefault(task, {}).update(
174 task_name=task.name, task_slug=task.slug
175 )
176 state, context = super().initialize_run(state=state, context=context)
177 return FlowRunnerInitializeResult(
178 state=state,
179 task_states=task_states,
180 context=context,
181 task_contexts=task_contexts,
182 )
183
184 def run(
185 self,
186 state: State = None,
187 task_states: Dict[Task, State] = None,
188 return_tasks: Iterable[Task] = None,
189 parameters: Dict[str, Any] = None,
190 task_runner_state_handlers: Iterable[Callable] = None,
191 executor: "prefect.engine.executors.Executor" = None,
192 context: Dict[str, Any] = None,
193 task_contexts: Dict[Task, Dict[str, Any]] = None,
194 ) -> State:
195 """
196 The main endpoint for FlowRunners. Calling this method will perform all
197 computations contained within the Flow and return the final state of the Flow.
198
199 Args:
200 - state (State, optional): starting state for the Flow. Defaults to
201 `Pending`
202 - task_states (dict, optional): dictionary of task states to begin
203 computation with, with keys being Tasks and values their corresponding state
204 - return_tasks ([Task], optional): list of Tasks to include in the
205 final returned Flow state. Defaults to `None`
206 - parameters (dict, optional): dictionary of any needed Parameter
207 values, with keys being strings representing Parameter names and values being
208 their corresponding values
209 - task_runner_state_handlers (Iterable[Callable], optional): A list of state change
210 handlers that will be provided to the task_runner, and called whenever a task changes
211 state.
212 - executor (Executor, optional): executor to use when performing
213 computation; defaults to the executor specified in your prefect configuration
214 - context (Dict[str, Any], optional): prefect.Context to use for execution
215 to use for each Task run
216 - task_contexts (Dict[Task, Dict[str, Any]], optional): contexts that will be provided to each task
217
218 Returns:
219 - State: `State` representing the final post-run state of the `Flow`.
220
221 """
222
223 self.logger.info("Beginning Flow run for '{}'".format(self.flow.name))
224
225 # make copies to avoid modifying user inputs
226 task_states = dict(task_states or {})
227 context = dict(context or {})
228 task_contexts = dict(task_contexts or {})
229 parameters = dict(parameters or {})
230 if executor is None:
231 executor = prefect.engine.get_default_executor_class()()
232
233 try:
234 state, task_states, context, task_contexts = self.initialize_run(
235 state=state,
236 task_states=task_states,
237 context=context,
238 task_contexts=task_contexts,
239 parameters=parameters,
240 )
241
242 with prefect.context(context):
243 state = self.check_flow_is_pending_or_running(state)
244 state = self.check_flow_reached_start_time(state)
245 state = self.set_flow_to_running(state)
246 state = self.get_flow_run_state(
247 state,
248 task_states=task_states,
249 task_contexts=task_contexts,
250 return_tasks=return_tasks,
251 task_runner_state_handlers=task_runner_state_handlers,
252 executor=executor,
253 )
254
255 except ENDRUN as exc:
256 state = exc.state
257
258 except KeyboardInterrupt:
259 self.logger.debug("Interrupt signal raised, cancelling Flow run.")
260 state = Cancelled(message="Interrupt signal raised, cancelling flow run.")
261
262 # All other exceptions are trapped and turned into Failed states
263 except Exception as exc:
264 self.logger.exception(
265 "Unexpected error while running flow: {}".format(repr(exc))
266 )
267 if prefect.context.get("raise_on_exception"):
268 raise exc
269 new_state = Failed(
270 message="Unexpected error while running flow: {}".format(repr(exc)),
271 result=exc,
272 )
273 state = self.handle_state_change(state or Pending(), new_state)
274
275 return state
276
277 @call_state_handlers
278 def check_flow_reached_start_time(self, state: State) -> State:
279 """
280 Checks if the Flow is in a Scheduled state and, if it is, ensures that the scheduled
281 time has been reached.
282
283 Args:
284 - state (State): the current state of this Flow
285
286 Returns:
287 - State: the state of the flow after performing the check
288
289 Raises:
290 - ENDRUN: if the flow is Scheduled with a future scheduled time
291 """
292 if isinstance(state, Scheduled):
293 if state.start_time and state.start_time > pendulum.now("utc"):
294 self.logger.debug(
295 "Flow '{name}': start_time has not been reached; ending run.".format(
296 name=self.flow.name
297 )
298 )
299 raise ENDRUN(state)
300 return state
301
302 @call_state_handlers
303 def check_flow_is_pending_or_running(self, state: State) -> State:
304 """
305 Checks if the flow is in either a Pending state or Running state. Either are valid
306 starting points (because we allow simultaneous runs of the same flow run).
307
308 Args:
309 - state (State): the current state of this flow
310
311 Returns:
312 - State: the state of the flow after running the check
313
314 Raises:
315 - ENDRUN: if the flow is not pending or running
316 """
317
318 # the flow run is already finished
319 if state.is_finished() is True:
320 self.logger.info("Flow run has already finished.")
321 raise ENDRUN(state)
322
323 # the flow run must be either pending or running (possibly redundant with above)
324 elif not (state.is_pending() or state.is_running()):
325 self.logger.info("Flow is not ready to run.")
326 raise ENDRUN(state)
327
328 return state
329
330 @call_state_handlers
331 def set_flow_to_running(self, state: State) -> State:
332 """
333 Puts Pending flows in a Running state; leaves Running flows Running.
334
335 Args:
336 - state (State): the current state of this flow
337
338 Returns:
339 - State: the state of the flow after running the check
340
341 Raises:
342 - ENDRUN: if the flow is not pending or running
343 """
344 if state.is_pending():
345 self.logger.info("Starting flow run.")
346 return Running(message="Running flow.")
347 elif state.is_running():
348 return state
349 else:
350 raise ENDRUN(state)
351
352 @run_with_heartbeat
353 @call_state_handlers
354 def get_flow_run_state(
355 self,
356 state: State,
357 task_states: Dict[Task, State],
358 task_contexts: Dict[Task, Dict[str, Any]],
359 return_tasks: Set[Task],
360 task_runner_state_handlers: Iterable[Callable],
361 executor: "prefect.engine.executors.base.Executor",
362 ) -> State:
363 """
364 Runs the flow.
365
366 Args:
367 - state (State): starting state for the Flow. Defaults to
368 `Pending`
369 - task_states (dict): dictionary of task states to begin
370 computation with, with keys being Tasks and values their corresponding state
371 - task_contexts (Dict[Task, Dict[str, Any]]): contexts that will be provided to each task
372 - return_tasks ([Task], optional): list of Tasks to include in the
373 final returned Flow state. Defaults to `None`
374 - task_runner_state_handlers (Iterable[Callable]): A list of state change
375 handlers that will be provided to the task_runner, and called whenever a task changes
376 state.
377 - executor (Executor): executor to use when performing
378 computation; defaults to the executor provided in your prefect configuration
379
380 Returns:
381 - State: `State` representing the final post-run state of the `Flow`.
382
383 """
384
385 if not state.is_running():
386 self.logger.info("Flow is not in a Running state.")
387 raise ENDRUN(state)
388
389 if return_tasks is None:
390 return_tasks = set()
391 if set(return_tasks).difference(self.flow.tasks):
392 raise ValueError("Some tasks in return_tasks were not found in the flow.")
393
394 # -- process each task in order
395
396 with executor.start():
397
398 for task in self.flow.sorted_tasks():
399
400 task_state = task_states.get(task)
401 if task_state is None and isinstance(
402 task, prefect.tasks.core.constants.Constant
403 ):
404 task_states[task] = task_state = Success(result=task.value)
405
406 # if the state is finished, don't run the task, just use the provided state
407 if (
408 isinstance(task_state, State)
409 and task_state.is_finished()
410 and not task_state.is_cached()
411 and not task_state.is_mapped()
412 ):
413 continue
414
415 upstream_states = {} # type: Dict[Edge, Union[State, Iterable]]
416
417 # -- process each edge to the task
418 for edge in self.flow.edges_to(task):
419 upstream_states[edge] = task_states.get(
420 edge.upstream_task, Pending(message="Task state not available.")
421 )
422
423 # augment edges with upstream constants
424 for key, val in self.flow.constants[task].items():
425 edge = Edge(
426 upstream_task=prefect.tasks.core.constants.Constant(val),
427 downstream_task=task,
428 key=key,
429 )
430 upstream_states[edge] = Success(
431 "Auto-generated constant value",
432 result=ConstantResult(value=val),
433 )
434
435 # -- run the task
436
437 with prefect.context(task_full_name=task.name, task_tags=task.tags):
438 task_states[task] = executor.submit(
439 self.run_task,
440 task=task,
441 state=task_state,
442 upstream_states=upstream_states,
443 context=dict(prefect.context, **task_contexts.get(task, {})),
444 task_runner_state_handlers=task_runner_state_handlers,
445 executor=executor,
446 )
447
448 # ---------------------------------------------
449 # Collect results
450 # ---------------------------------------------
451
452 # terminal tasks determine if the flow is finished
453 terminal_tasks = self.flow.terminal_tasks()
454
455 # reference tasks determine flow state
456 reference_tasks = self.flow.reference_tasks()
457
458 # wait until all terminal tasks are finished
459 final_tasks = terminal_tasks.union(reference_tasks).union(return_tasks)
460 final_states = executor.wait(
461 {
462 t: task_states.get(t, Pending("Task not evaluated by FlowRunner."))
463 for t in final_tasks
464 }
465 )
466
467 # also wait for any children of Mapped tasks to finish, and add them
468 # to the dictionary to determine flow state
469 all_final_states = final_states.copy()
470 for t, s in list(final_states.items()):
471 if s.is_mapped():
472 s.map_states = executor.wait(s.map_states)
473 s.result = [ms.result for ms in s.map_states]
474 all_final_states[t] = s.map_states
475
476 assert isinstance(final_states, dict)
477
478 key_states = set(flatten_seq([all_final_states[t] for t in reference_tasks]))
479 terminal_states = set(
480 flatten_seq([all_final_states[t] for t in terminal_tasks])
481 )
482 return_states = {t: final_states[t] for t in return_tasks}
483
484 state = self.determine_final_state(
485 state=state,
486 key_states=key_states,
487 return_states=return_states,
488 terminal_states=terminal_states,
489 )
490
491 return state
492
493 def determine_final_state(
494 self,
495 state: State,
496 key_states: Set[State],
497 return_states: Dict[Task, State],
498 terminal_states: Set[State],
499 ) -> State:
500 """
501 Implements the logic for determining the final state of the flow run.
502
503 Args:
504 - state (State): the current state of the Flow
505 - key_states (Set[State]): the states which will determine the success / failure of the flow run
506 - return_states (Dict[Task, State]): states to return as results
507 - terminal_states (Set[State]): the states of the terminal tasks for this flow
508
509 Returns:
510 - State: the final state of the flow run
511 """
512 # check that the flow is finished
513 if not all(s.is_finished() for s in terminal_states):
514 self.logger.info("Flow run RUNNING: terminal tasks are incomplete.")
515 state.result = return_states
516
517 # check if any key task failed
518 elif any(s.is_failed() for s in key_states):
519 self.logger.info("Flow run FAILED: some reference tasks failed.")
520 state = Failed(message="Some reference tasks failed.", result=return_states)
521
522 # check if all reference tasks succeeded
523 elif all(s.is_successful() for s in key_states):
524 self.logger.info("Flow run SUCCESS: all reference tasks succeeded")
525 state = Success(
526 message="All reference tasks succeeded.", result=return_states
527 )
528
529 # check for any unanticipated state that is finished but neither success nor failed
530 else:
531 self.logger.info("Flow run SUCCESS: no reference tasks failed")
532 state = Success(message="No reference tasks failed.", result=return_states)
533
534 return state
535
536 def run_task(
537 self,
538 task: Task,
539 state: State,
540 upstream_states: Dict[Edge, State],
541 context: Dict[str, Any],
542 task_runner_state_handlers: Iterable[Callable],
543 executor: "prefect.engine.executors.Executor",
544 ) -> State:
545 """
546
547 Runs a specific task. This method is intended to be called by submitting it to
548 an executor.
549
550 Args:
551 - task (Task): the task to run
552 - state (State): starting state for the Flow. Defaults to
553 `Pending`
554 - upstream_states (Dict[Edge, State]): dictionary of upstream states
555 - context (Dict[str, Any]): a context dictionary for the task run
556 - task_runner_state_handlers (Iterable[Callable]): A list of state change
557 handlers that will be provided to the task_runner, and called whenever a task changes
558 state.
559 - executor (Executor): executor to use when performing
560 computation; defaults to the executor provided in your prefect configuration
561
562 Returns:
563 - State: `State` representing the final post-run state of the `Flow`.
564
565 """
566 with prefect.context(self.context):
567 default_result = task.result or self.flow.result
568 task_runner = self.task_runner_cls(
569 task=task,
570 state_handlers=task_runner_state_handlers,
571 result=default_result or Result(),
572 default_result=self.flow.result,
573 )
574
575 # if this task reduces over a mapped state, make sure its children have finished
576 for edge, upstream_state in upstream_states.items():
577
578 # if the upstream state is Mapped, wait until its results are all available
579 if not edge.mapped and upstream_state.is_mapped():
580 assert isinstance(upstream_state, Mapped) # mypy assert
581 upstream_state.map_states = executor.wait(upstream_state.map_states)
582 upstream_state.result = [
583 s.result for s in upstream_state.map_states
584 ]
585
586 return task_runner.run(
587 state=state,
588 upstream_states=upstream_states,
589 context=context,
590 executor=executor,
591 )
592
[end of src/prefect/engine/flow_runner.py]
[start of src/prefect/environments/execution/dask/cloud_provider.py]
1 from typing import Any, Callable, Dict, List, Type
2 from urllib.parse import urlparse
3
4 import prefect
5 from distributed.deploy.cluster import Cluster
6 from distributed.security import Security
7 from prefect import Client
8 from prefect.environments.execution.dask.remote import RemoteDaskEnvironment
9
10
11 class DaskCloudProviderEnvironment(RemoteDaskEnvironment):
12 """
13 DaskCloudProviderEnvironment creates Dask clusters using the Dask Cloud Provider
14 project. For each flow run, a new Dask cluster will be dynamically created and the
15 flow will run using a `RemoteDaskEnvironment` with the Dask scheduler address
16 from the newly created Dask cluster. You can specify the number of Dask workers
17 manually (for example, passing the kwarg `n_workers`) or enable adaptive mode by
18 passing `adaptive_min_workers` and, optionally, `adaptive_max_workers`. This
19 environment aims to provide a very easy path to Dask scalability for users of
20 cloud platforms, like AWS.
21
22 **NOTE:** AWS Fargate Task (not Prefect Task) startup time can be slow, depending
23 on docker image size. Total startup time for a Dask scheduler and workers can
24 be several minutes. This environment is a much better fit for production
25 deployments of scheduled Flows where there's little sensitivity to startup
26 time. `DaskCloudProviderEnvironment` is a particularly good fit for automated
27 deployment of Flows in a CI/CD pipeline where the infrastructure for each Flow
28 should be as independent as possible, e.g. each Flow could have its own docker
29 image, dynamically create the Dask cluster to run on, etc. However, for
30 development and interactive testing, creating a Dask cluster manually with Dask
31 Cloud Provider and then using `RemoteDaskEnvironment` or just `DaskExecutor`
32 with your flows will result in a much better development experience.
33
34 (Dask Cloud Provider currently only supports AWS using either Fargate or ECS.
35 Support for AzureML is coming soon.)
36
37 *IMPORTANT* By default, Dask Cloud Provider may create a Dask cluster in some
38 environments (e.g. Fargate) that is accessible via a public IP, without any
39 authentication, and configured to NOT encrypt network traffic. Please be
40 conscious of security issues if you test this environment. (Also see pull
41 requests [85](https://github.com/dask/dask-cloudprovider/pull/85) and
42 [91](https://github.com/dask/dask-cloudprovider/pull/91) in the Dask Cloud
43 Provider project.)
44
45 Args:
46 - provider_class (class): Class of a provider from the Dask Cloud Provider
47 projects. Current supported options are `ECSCluster` and `FargateCluster`.
48 - adaptive_min_workers (int, optional): Minimum number of workers for adaptive
49 mode. If this value is None, then adaptive mode will not be used and you
50 should pass `n_workers` or the appropriate kwarg for the provider class you
51 are using.
52 - adaptive_max_workers (int, optional): Maximum number of workers for adaptive
53 mode.
54 - security (Type[Security], optional): a Dask Security object from `distributed.security.Security`.
55 Use this to connect to a Dask cluster that is enabled with TLS encryption.
56 For more on using TLS with Dask see https://distributed.dask.org/en/latest/tls.html
57 - executor_kwargs (dict, optional): a dictionary of kwargs to be passed to
58 the executor; defaults to an empty dictionary
59 - labels (List[str], optional): a list of labels, which are arbitrary string identifiers used by Prefect
60 Agents when polling for work
61 - on_execute (Callable[[Dict[str, Any], Dict[str, Any]], None], optional): a function callback which will
62 be called before the flow begins to run. The callback function can examine the Flow run
63 parameters and modify kwargs to be passed to the Dask Cloud Provider class's constructor prior
64 to launching the Dask cluster for the Flow run. This allows for dynamically sizing the cluster based
65 on the Flow run parameters, e.g. settings n_workers. The callback function's signature should be:
66 `def on_execute(parameters: Dict[str, Any], provider_kwargs: Dict[str, Any]) -> None:`
67 The callback function may modify provider_kwargs (e.g. `provider_kwargs["n_workers"] = 3`) and any
68 relevant changes will be used when creating the Dask cluster via a Dask Cloud Provider class.
69 - on_start (Callable, optional): a function callback which will be called before the flow begins to run
70 - on_exit (Callable, optional): a function callback which will be called after the flow finishes its run
71 - **kwargs (dict, optional): additional keyword arguments to pass to boto3 for
72 `register_task_definition` and `run_task`
73 """
74
75 def __init__( # type: ignore
76 self,
77 provider_class: Type[Cluster],
78 adaptive_min_workers: int = None,
79 adaptive_max_workers: int = None,
80 security: Security = None,
81 executor_kwargs: Dict[str, Any] = None,
82 labels: List[str] = None,
83 on_execute: Callable[[Dict[str, Any], Dict[str, Any]], None] = None,
84 on_start: Callable = None,
85 on_exit: Callable = None,
86 **kwargs
87 ) -> None:
88 self._provider_class = provider_class
89 self._adaptive_min_workers = adaptive_min_workers
90 self._adaptive_max_workers = adaptive_max_workers
91 self._on_execute = on_execute
92 self._provider_kwargs = kwargs
93 if "skip_cleanup" not in self._provider_kwargs:
94 # Prefer this default (if not provided) to avoid deregistering task definitions
95 # See this issue in Dask Cloud Provider: https://github.com/dask/dask-cloudprovider/issues/94
96 self._provider_kwargs["skip_cleanup"] = True
97 self._security = security
98 if self._security:
99 # We'll use the security config object both for our Dask Client connection *and*
100 # for the particular Dask Cloud Provider (e.g. Fargate) to use with *its* Dask
101 # Client when it connects to the scheduler after cluster creation. So we
102 # put it in _provider_kwargs so it gets passed to the Dask Cloud Provider's constructor
103 self._provider_kwargs["security"] = self._security
104 self.cluster = None
105 super().__init__(
106 address="", # The scheduler address will be set after cluster creation
107 executor_kwargs=executor_kwargs,
108 labels=labels,
109 on_start=on_start,
110 on_exit=on_exit,
111 security=self._security,
112 )
113
114 @property
115 def dependencies(self) -> list:
116 return ["dask_cloudprovider"]
117
118 def _create_dask_cluster(self) -> None:
119 self.logger.info("Creating Dask cluster using {}".format(self._provider_class))
120 self.cluster = self._provider_class(**self._provider_kwargs)
121 if self.cluster and self.cluster.scheduler and self.cluster.scheduler.address:
122 self.logger.info(
123 "Dask cluster created. Sheduler address: {} Dashboard: http://{}:8787 "
124 "(unless port was changed from default of 8787)".format(
125 self.cluster.scheduler.address,
126 urlparse(self.cluster.scheduler.address).hostname,
127 ) # TODO submit PR to Dask Cloud Provider allowing discovery of dashboard port
128 )
129
130 self.executor_kwargs["address"] = self.cluster.scheduler.address # type: ignore
131 else:
132 if self.cluster:
133 self.cluster.close()
134 raise Exception(
135 "Unable to determine the Dask scheduler address after cluster creation. "
136 "Tearting down cluster and terminating setup."
137 )
138 if self._adaptive_min_workers:
139 self.logger.info(
140 "Enabling adaptive mode with min_workers={} max_workers={}".format(
141 self._adaptive_min_workers, self._adaptive_max_workers
142 )
143 )
144 self.cluster.adapt( # type: ignore
145 minimum=self._adaptive_min_workers, maximum=self._adaptive_max_workers
146 )
147
148 def execute( # type: ignore
149 self, storage: "Storage", flow_location: str, **kwargs: Any # type: ignore
150 ) -> None:
151 flow_run_info = None
152 flow_run_id = prefect.context.get("flow_run_id")
153 if self._on_execute:
154 # If an on_execute Callable has been provided, retrieve the flow run parameters
155 # and then allow the Callable a chance to update _provider_kwargs. This allows
156 # better sizing of the cluster resources based on parameters for this Flow run.
157 try:
158 client = Client()
159 flow_run_info = client.get_flow_run_info(flow_run_id)
160 parameters = flow_run_info.parameters or {} # type: ignore
161 self._on_execute(parameters, self._provider_kwargs)
162 except Exception as exc:
163 self.logger.info(
164 "Failed to retrieve flow run info with error: {}".format(repr(exc))
165 )
166 if "image" not in self._provider_kwargs or not self._provider_kwargs.get(
167 "image"
168 ):
169 # If image is not specified, use the Flow's image so that dependencies are
170 # identical on all containers: Flow runner, Dask scheduler, and Dask workers
171 flow_id = prefect.context.get("flow_id")
172 try:
173 client = Client()
174 if not flow_id: # We've observed cases where flow_id is None
175 if not flow_run_info:
176 flow_run_info = client.get_flow_run_info(flow_run_id)
177 flow_id = flow_run_info.flow_id
178 flow_info = client.graphql(
179 """query {
180 flow(where: {id: {_eq: "%s"}}) {
181 storage
182 }
183 }"""
184 % flow_id
185 )
186 storage_info = flow_info["data"]["flow"][0]["storage"]
187 image = "{}/{}:{}".format(
188 storage_info["registry_url"],
189 storage_info["image_name"],
190 storage_info["image_tag"],
191 )
192 self.logger.info(
193 "Using Flow's Docker image for Dask scheduler & workers: {}".format(
194 image
195 )
196 )
197 self._provider_kwargs["image"] = image
198 except Exception as exc:
199 self.logger.info(
200 "Failed to retrieve flow info with error: {}".format(repr(exc))
201 )
202
203 self._create_dask_cluster()
204
205 self.logger.info(
206 "Executing on dynamically created Dask Cluster with scheduler address: {}".format(
207 self.executor_kwargs["address"]
208 )
209 )
210 super().execute(storage, flow_location, **kwargs)
211
[end of src/prefect/environments/execution/dask/cloud_provider.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| PrefectHQ/prefect | 35aa1de018a983cf972c9c30a77159ac7f2de18d | Implement Depth-First Execution with Mapping
Currently each "level" of a mapped pipeline is executed before proceeding to the next level. This is undesirable especially for pipelines where it's important that each "branch" of the pipeline finish as quickly as possible.
To implement DFE, we'll need to rearrange two things:
- how mapped work gets submitted (it should start being submitted from the Flow Runner not the Task Runner)
- in order to submit work to Dask and let Dask handle the DFE scheduling, we'll want to refactor how we walk the DAG and wait to determine the width of a pipeline before we submit it (because mapping is fully dynamic we can only ascertain this width at runtime)
We'll need to be vigilant about:
- performance
- retries
- result handling
| 2020-05-24T02:51:51Z | <patch>
diff --git a/src/prefect/engine/cloud/task_runner.py b/src/prefect/engine/cloud/task_runner.py
--- a/src/prefect/engine/cloud/task_runner.py
+++ b/src/prefect/engine/cloud/task_runner.py
@@ -339,7 +339,7 @@ def run(
state: State = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
+ is_mapped_parent: bool = False,
) -> State:
"""
The main endpoint for TaskRunners. Calling this method will conditionally execute
@@ -354,8 +354,8 @@ def run(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
Returns:
- `State` object representing the final post-run state of the Task
@@ -365,7 +365,7 @@ def run(
state=state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
while (end_state.is_retrying() or end_state.is_queued()) and (
end_state.start_time <= pendulum.now("utc").add(minutes=10) # type: ignore
@@ -388,6 +388,6 @@ def run(
state=end_state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
return end_state
diff --git a/src/prefect/engine/executors/__init__.py b/src/prefect/engine/executors/__init__.py
--- a/src/prefect/engine/executors/__init__.py
+++ b/src/prefect/engine/executors/__init__.py
@@ -8,9 +8,6 @@
has completed running
- `wait(object)`: resolves any objects returned by `executor.submit` to
their values; this function _will_ block until execution of `object` is complete
-- `map(fn, *args, upstream_states, **kwargs)`: submit function to be mapped
- over based on the edge information contained in `upstream_states`. Any "mapped" Edge
- will be converted into multiple function submissions, one for each value of the upstream mapped tasks.
Currently, the available executor options are:
diff --git a/src/prefect/engine/executors/base.py b/src/prefect/engine/executors/base.py
--- a/src/prefect/engine/executors/base.py
+++ b/src/prefect/engine/executors/base.py
@@ -1,8 +1,6 @@
import uuid
from contextlib import contextmanager
-from typing import Any, Callable, Iterator, List
-
-from prefect.utilities.executors import timeout_handler
+from typing import Any, Callable, Iterator
class Executor:
@@ -10,8 +8,6 @@ class Executor:
Base Executor class that all other executors inherit from.
"""
- timeout_handler = staticmethod(timeout_handler)
-
def __init__(self) -> None:
self.executor_id = type(self).__name__ + ": " + str(uuid.uuid4())
@@ -28,20 +24,6 @@ def start(self) -> Iterator[None]:
"""
yield
- def map(self, fn: Callable, *args: Any) -> List[Any]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[Any]: the result of computating the function over the arguments
-
- """
- raise NotImplementedError()
-
def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
"""
Submit a function to the executor for execution. Returns a future-like object.
diff --git a/src/prefect/engine/executors/dask.py b/src/prefect/engine/executors/dask.py
--- a/src/prefect/engine/executors/dask.py
+++ b/src/prefect/engine/executors/dask.py
@@ -2,7 +2,7 @@
import uuid
import warnings
from contextlib import contextmanager
-from typing import TYPE_CHECKING, Any, Callable, Iterator, List, Union
+from typing import Any, Callable, Iterator, TYPE_CHECKING, Union
from prefect import context
from prefect.engine.executors.base import Executor
@@ -63,8 +63,6 @@ class name (e.g. `"distributed.LocalCluster"`), or the class itself.
your Prefect configuration.
- **kwargs: DEPRECATED
- Example:
-
Using a temporary local dask cluster:
```python
@@ -269,41 +267,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "Future":
fire_and_forget(future)
return future
- def map(self, fn: Callable, *args: Any, **kwargs: Any) -> List["Future"]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
- - **kwargs (Any): additional keyword arguments that will be passed to the Dask Client
-
- Returns:
- - List[Future]: a list of Future-like objects that represent each computation of
- fn(*a), where a = zip(*args)[i]
-
- """
- if not args:
- return []
-
- # import dask functions here to decrease our import times
- from distributed import fire_and_forget, worker_client
-
- dask_kwargs = self._prep_dask_kwargs()
- kwargs.update(dask_kwargs)
-
- if self.is_started and hasattr(self, "client"):
- futures = self.client.map(fn, *args, **kwargs)
- elif self.is_started:
- with worker_client(separate_thread=True) as client:
- futures = client.map(fn, *args, **kwargs)
- return client.gather(futures)
- else:
- raise ValueError("This executor has not been started.")
-
- fire_and_forget(futures)
- return futures
-
def wait(self, futures: Any) -> Any:
"""
Resolves the Future objects to their values. Blocks until the computation is complete.
@@ -331,8 +294,6 @@ class LocalDaskExecutor(Executor):
An executor that runs all functions locally using `dask` and a configurable dask scheduler. Note that
this executor is known to occasionally run tasks twice when using multi-level mapping.
- Prefect's mapping feature will not work in conjunction with setting `scheduler="processes"`.
-
Args:
- scheduler (str): The local dask scheduler to use; common options are "synchronous", "threads" and "processes". Defaults to "threads".
- **kwargs (Any): Additional keyword arguments to pass to dask config
@@ -373,28 +334,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> "dask.delayed":
return dask.delayed(fn)(*args, **kwargs)
- def map(self, fn: Callable, *args: Any) -> List["dask.delayed"]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[dask.delayed]: the result of computating the function over the arguments
-
- """
- if self.scheduler == "processes":
- raise RuntimeError(
- "LocalDaskExecutor cannot map if scheduler='processes'. Please set to either 'synchronous' or 'threads'."
- )
-
- results = []
- for args_i in zip(*args):
- results.append(self.submit(fn, *args_i))
- return results
-
def wait(self, futures: Any) -> Any:
"""
Resolves a `dask.delayed` object to its values. Blocks until the computation is complete.
diff --git a/src/prefect/engine/executors/local.py b/src/prefect/engine/executors/local.py
--- a/src/prefect/engine/executors/local.py
+++ b/src/prefect/engine/executors/local.py
@@ -1,4 +1,4 @@
-from typing import Any, Callable, List
+from typing import Any, Callable
from prefect.engine.executors.base import Executor
@@ -23,23 +23,6 @@ def submit(self, fn: Callable, *args: Any, **kwargs: Any) -> Any:
"""
return fn(*args, **kwargs)
- def map(self, fn: Callable, *args: Any) -> List[Any]:
- """
- Submit a function to be mapped over its iterable arguments.
-
- Args:
- - fn (Callable): function that is being submitted for execution
- - *args (Any): arguments that the function will be mapped over
-
- Returns:
- - List[Any]: the result of computating the function over the arguments
-
- """
- results = []
- for args_i in zip(*args):
- results.append(fn(*args_i))
- return results
-
def wait(self, futures: Any) -> Any:
"""
Returns the results of the provided futures.
diff --git a/src/prefect/engine/flow_runner.py b/src/prefect/engine/flow_runner.py
--- a/src/prefect/engine/flow_runner.py
+++ b/src/prefect/engine/flow_runner.py
@@ -10,7 +10,6 @@
)
import pendulum
-
import prefect
from prefect.core import Edge, Flow, Task
from prefect.engine.result import Result
@@ -28,7 +27,10 @@
Success,
)
from prefect.utilities.collections import flatten_seq
-from prefect.utilities.executors import run_with_heartbeat
+from prefect.utilities.executors import (
+ run_with_heartbeat,
+ prepare_upstream_states_for_mapping,
+)
FlowRunnerInitializeResult = NamedTuple(
"FlowRunnerInitializeResult",
@@ -381,6 +383,11 @@ def get_flow_run_state(
- State: `State` representing the final post-run state of the `Flow`.
"""
+ # this dictionary is used for tracking the states of "children" mapped tasks;
+ # when running on Dask, we want to avoid serializing futures, so instead
+ # of storing child task states in the `map_states` attribute we instead store
+ # in this dictionary and only after they are resolved do we attach them to the Mapped state
+ mapped_children = dict() # type: Dict[Task, list]
if not state.is_running():
self.logger.info("Flow is not in a Running state.")
@@ -396,14 +403,19 @@ def get_flow_run_state(
with executor.start():
for task in self.flow.sorted_tasks():
-
task_state = task_states.get(task)
+
+ # if a task is a constant task, we already know its return value
+ # no need to use up resources by running it through a task runner
if task_state is None and isinstance(
task, prefect.tasks.core.constants.Constant
):
task_states[task] = task_state = Success(result=task.value)
# if the state is finished, don't run the task, just use the provided state
+ # if the state is cached / mapped, we still want to run the task runner pipeline steps
+ # to either ensure the cache is still valid / or to recreate the mapped pipeline for
+ # possible retries
if (
isinstance(task_state, State)
and task_state.is_finished()
@@ -412,7 +424,12 @@ def get_flow_run_state(
):
continue
- upstream_states = {} # type: Dict[Edge, Union[State, Iterable]]
+ upstream_states = {} # type: Dict[Edge, State]
+
+ # this dictionary is used exclusively for "reduce" tasks
+ # in particular we store the states / futures corresponding to
+ # the upstream children, and if running on Dask, let Dask resolve them at the appropriate time
+ upstream_mapped_states = {} # type: Dict[Edge, list]
# -- process each edge to the task
for edge in self.flow.edges_to(task):
@@ -420,6 +437,13 @@ def get_flow_run_state(
edge.upstream_task, Pending(message="Task state not available.")
)
+ # this checks whether the task is a "reduce" task for a mapped pipeline
+ # and if so, collects the appropriate upstream children
+ if not edge.mapped and isinstance(upstream_states[edge], Mapped):
+ upstream_mapped_states[edge] = mapped_children.get(
+ edge.upstream_task, []
+ )
+
# augment edges with upstream constants
for key, val in self.flow.constants[task].items():
edge = Edge(
@@ -432,9 +456,80 @@ def get_flow_run_state(
result=ConstantResult(value=val),
)
- # -- run the task
+ # handle mapped tasks
+ if any([edge.mapped for edge in upstream_states.keys()]):
- with prefect.context(task_full_name=task.name, task_tags=task.tags):
+ ## wait on upstream states to determine the width of the pipeline
+ ## this is the key to depth-first execution
+ upstream_states.update(
+ executor.wait(
+ {e: state for e, state in upstream_states.items()}
+ )
+ )
+
+ ## we submit the task to the task runner to determine if
+ ## we can proceed with mapping - if the new task state is not a Mapped
+ ## state then we don't proceed
+ task_states[task] = executor.wait(
+ executor.submit(
+ self.run_task,
+ task=task,
+ state=task_state, # original state
+ upstream_states=upstream_states,
+ context=dict(
+ prefect.context, **task_contexts.get(task, {})
+ ),
+ task_runner_state_handlers=task_runner_state_handlers,
+ upstream_mapped_states=upstream_mapped_states,
+ is_mapped_parent=True,
+ )
+ )
+
+ ## either way, we should now have enough resolved states to restructure
+ ## the upstream states into a list of upstream state dictionaries to iterate over
+ list_of_upstream_states = prepare_upstream_states_for_mapping(
+ task_states[task], upstream_states, mapped_children
+ )
+
+ submitted_states = []
+
+ for idx, states in enumerate(list_of_upstream_states):
+ ## if we are on a future rerun of a partially complete flow run,
+ ## there might be mapped children in a retrying state; this check
+ ## looks into the current task state's map_states for such info
+ if (
+ isinstance(task_state, Mapped)
+ and len(task_state.map_states) >= idx + 1
+ ):
+ current_state = task_state.map_states[
+ idx
+ ] # type: Optional[State]
+ elif isinstance(task_state, Mapped):
+ current_state = None
+ else:
+ current_state = task_state
+
+ ## this is where each child is submitted for actual work
+ submitted_states.append(
+ executor.submit(
+ self.run_task,
+ task=task,
+ state=current_state,
+ upstream_states=states,
+ context=dict(
+ prefect.context,
+ **task_contexts.get(task, {}),
+ map_index=idx,
+ ),
+ task_runner_state_handlers=task_runner_state_handlers,
+ upstream_mapped_states=upstream_mapped_states,
+ )
+ )
+ if isinstance(task_states.get(task), Mapped):
+ mapped_children[task] = submitted_states # type: ignore
+
+ # -- run the task
+ else:
task_states[task] = executor.submit(
self.run_task,
task=task,
@@ -442,7 +537,7 @@ def get_flow_run_state(
upstream_states=upstream_states,
context=dict(prefect.context, **task_contexts.get(task, {})),
task_runner_state_handlers=task_runner_state_handlers,
- executor=executor,
+ upstream_mapped_states=upstream_mapped_states,
)
# ---------------------------------------------
@@ -469,7 +564,9 @@ def get_flow_run_state(
all_final_states = final_states.copy()
for t, s in list(final_states.items()):
if s.is_mapped():
- s.map_states = executor.wait(s.map_states)
+ # ensure we wait for any mapped children to complete
+ if t in mapped_children:
+ s.map_states = executor.wait(mapped_children[t])
s.result = [ms.result for ms in s.map_states]
all_final_states[t] = s.map_states
@@ -540,7 +637,8 @@ def run_task(
upstream_states: Dict[Edge, State],
context: Dict[str, Any],
task_runner_state_handlers: Iterable[Callable],
- executor: "prefect.engine.executors.Executor",
+ is_mapped_parent: bool = False,
+ upstream_mapped_states: Dict[Edge, list] = None,
) -> State:
"""
@@ -556,13 +654,17 @@ def run_task(
- task_runner_state_handlers (Iterable[Callable]): A list of state change
handlers that will be provided to the task_runner, and called whenever a task changes
state.
- - executor (Executor): executor to use when performing
- computation; defaults to the executor provided in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
+ - upstream_mapped_states (Dict[Edge, list]): dictionary of upstream states corresponding to
+ mapped children dependencies
Returns:
- State: `State` representing the final post-run state of the `Flow`.
"""
+ upstream_mapped_states = upstream_mapped_states or {}
+
with prefect.context(self.context):
default_result = task.result or self.flow.result
task_runner = self.task_runner_cls(
@@ -578,7 +680,9 @@ def run_task(
# if the upstream state is Mapped, wait until its results are all available
if not edge.mapped and upstream_state.is_mapped():
assert isinstance(upstream_state, Mapped) # mypy assert
- upstream_state.map_states = executor.wait(upstream_state.map_states)
+ upstream_state.map_states = upstream_mapped_states.get(
+ edge, upstream_state.map_states
+ )
upstream_state.result = [
s.result for s in upstream_state.map_states
]
@@ -587,5 +691,5 @@ def run_task(
state=state,
upstream_states=upstream_states,
context=context,
- executor=executor,
+ is_mapped_parent=is_mapped_parent,
)
diff --git a/src/prefect/engine/task_runner.py b/src/prefect/engine/task_runner.py
--- a/src/prefect/engine/task_runner.py
+++ b/src/prefect/engine/task_runner.py
@@ -1,6 +1,4 @@
-import copy
from contextlib import redirect_stdout
-import itertools
import json
from typing import (
Any,
@@ -196,7 +194,7 @@ def run(
state: State = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
+ is_mapped_parent: bool = False,
) -> State:
"""
The main endpoint for TaskRunners. Calling this method will conditionally execute
@@ -210,8 +208,8 @@ def run(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
+ - is_mapped_parent (bool): a boolean indicating whether this task run is the run of a parent
+ mapped task
Returns:
- `State` object representing the final post-run state of the Task
@@ -224,15 +222,6 @@ def run(
index=("" if map_index is None else "[{}]".format(map_index)),
)
- if executor is None:
- executor = prefect.engine.get_default_executor_class()()
-
- # if mapped is true, this task run is going to generate a Mapped state. It won't
- # actually run, but rather spawn children tasks to map over its inputs. We
- # detect this case by checking for:
- # - upstream edges that are `mapped`
- # - no `map_index` (which indicates that this is the child task, not the parent)
- mapped = any([e.mapped for e in upstream_states]) and map_index is None
task_inputs = {} # type: Dict[str, Any]
try:
@@ -270,29 +259,16 @@ def run(
state=state, upstream_states=upstream_states
)
- # if the task is mapped, process the mapped children and exit
- if mapped:
- state = self.run_mapped_task(
- state=state,
- upstream_states=upstream_states,
- context=context,
- executor=executor,
- )
-
- state = self.wait_for_mapped_task(state=state, executor=executor)
-
- self.logger.debug(
- "Task '{name}': task has been mapped; ending run.".format(
- name=context["task_full_name"]
- )
- )
- raise ENDRUN(state)
-
# retrieve task inputs from upstream and also explicitly passed inputs
task_inputs = self.get_task_inputs(
state=state, upstream_states=upstream_states
)
+ if is_mapped_parent:
+ state = self.check_task_ready_to_map(
+ state, upstream_states=upstream_states
+ )
+
if self.task.target:
# check to see if there is a Result at the task's target
state = self.check_target(state, inputs=task_inputs)
@@ -309,9 +285,7 @@ def run(
state = self.set_task_to_running(state, inputs=task_inputs)
# run the task
- state = self.get_task_run_state(
- state, inputs=task_inputs, timeout_handler=executor.timeout_handler
- )
+ state = self.get_task_run_state(state, inputs=task_inputs)
# cache the output, if appropriate
state = self.cache_result(state, inputs=task_inputs)
@@ -324,7 +298,6 @@ def run(
inputs=task_inputs,
upstream_states=upstream_states,
context=context,
- executor=executor,
)
# for pending signals, including retries and pauses we need to make sure the
@@ -438,6 +411,45 @@ def check_upstream_skipped(
)
return state
+ @call_state_handlers
+ def check_task_ready_to_map(
+ self, state: State, upstream_states: Dict[Edge, State]
+ ) -> State:
+ """
+ Checks if the parent task is ready to proceed with mapping.
+
+ Args:
+ - state (State): the current state of this task
+ - upstream_states (Dict[Edge, Union[State, List[State]]]): the upstream states
+
+ Raises:
+ - ENDRUN: either way, we dont continue past this point
+ """
+ if state.is_mapped():
+ raise ENDRUN(state)
+
+ ## we can't map if there are no success states with iterables upstream
+ if upstream_states and not any(
+ [
+ edge.mapped and state.is_successful()
+ for edge, state in upstream_states.items()
+ ]
+ ):
+ new_state = Failed("No upstream states can be mapped over.") # type: State
+ raise ENDRUN(new_state)
+ elif not all(
+ [
+ hasattr(state.result, "__getitem__")
+ for edge, state in upstream_states.items()
+ if state.is_successful() and not state.is_mapped() and edge.mapped
+ ]
+ ):
+ new_state = Failed("No upstream states can be mapped over.")
+ raise ENDRUN(new_state)
+ else:
+ new_state = Mapped("Ready to proceed with mapping.")
+ raise ENDRUN(new_state)
+
@call_state_handlers
def check_task_trigger(
self, state: State, upstream_states: Dict[Edge, State]
@@ -718,153 +730,6 @@ def check_task_is_cached(self, state: State, inputs: Dict[str, Result]) -> State
)
return state or Pending("Cache was invalid; ready to run.")
- def run_mapped_task(
- self,
- state: State,
- upstream_states: Dict[Edge, State],
- context: Dict[str, Any],
- executor: "prefect.engine.executors.Executor",
- ) -> State:
- """
- If the task is being mapped, submits children tasks for execution. Returns a `Mapped` state.
-
- Args:
- - state (State): the current task state
- - upstream_states (Dict[Edge, State]): the upstream states
- - context (dict, optional): prefect Context to use for execution
- - executor (Executor): executor to use when performing computation
-
- Returns:
- - State: the state of the task after running the check
-
- Raises:
- - ENDRUN: if the current state is not `Running`
- """
-
- map_upstream_states = []
-
- # we don't know how long the iterables are, but we want to iterate until we reach
- # the end of the shortest one
- counter = itertools.count()
-
- # infinite loop, if upstream_states has any entries
- while True and upstream_states:
- i = next(counter)
- states = {}
-
- try:
-
- for edge, upstream_state in upstream_states.items():
-
- # if the edge is not mapped over, then we take its state
- if not edge.mapped:
- states[edge] = upstream_state
-
- # if the edge is mapped and the upstream state is Mapped, then we are mapping
- # over a mapped task. In this case, we take the appropriately-indexed upstream
- # state from the upstream tasks's `Mapped.map_states` array.
- # Note that these "states" might actually be futures at this time; we aren't
- # blocking until they finish.
- elif edge.mapped and upstream_state.is_mapped():
- states[edge] = upstream_state.map_states[i] # type: ignore
-
- # Otherwise, we are mapping over the result of a "vanilla" task. In this
- # case, we create a copy of the upstream state but set the result to the
- # appropriately-indexed item from the upstream task's `State.result`
- # array.
- else:
- states[edge] = copy.copy(upstream_state)
-
- # if the current state is already Mapped, then we might be executing
- # a re-run of the mapping pipeline. In that case, the upstream states
- # might not have `result` attributes (as any required results could be
- # in the `cached_inputs` attribute of one of the child states).
- # Therefore, we only try to get a result if EITHER this task's
- # state is not already mapped OR the upstream result is not None.
- if not state.is_mapped() or upstream_state._result != NoResult:
- if not hasattr(upstream_state.result, "__getitem__"):
- raise TypeError(
- "Cannot map over unsubscriptable object of type {t}: {preview}...".format(
- t=type(upstream_state.result),
- preview=repr(upstream_state.result)[:10],
- )
- )
- upstream_result = upstream_state._result.from_value( # type: ignore
- upstream_state.result[i]
- )
- states[edge].result = upstream_result
- elif state.is_mapped():
- if i >= len(state.map_states): # type: ignore
- raise IndexError()
-
- # only add this iteration if we made it through all iterables
- map_upstream_states.append(states)
-
- # index error means we reached the end of the shortest iterable
- except IndexError:
- break
-
- def run_fn(
- state: State, map_index: int, upstream_states: Dict[Edge, State]
- ) -> State:
- map_context = context.copy()
- map_context.update(map_index=map_index)
- with prefect.context(self.context):
- return self.run(
- upstream_states=upstream_states,
- # if we set the state here, then it will not be processed by `initialize_run()`
- state=state,
- context=map_context,
- executor=executor,
- )
-
- # generate initial states, if available
- if isinstance(state, Mapped):
- initial_states = list(state.map_states) # type: List[Optional[State]]
- else:
- initial_states = []
- initial_states.extend([None] * (len(map_upstream_states) - len(initial_states)))
-
- current_state = Mapped(
- message="Preparing to submit {} mapped tasks.".format(len(initial_states)),
- map_states=initial_states, # type: ignore
- )
- state = self.handle_state_change(old_state=state, new_state=current_state)
- if state is not current_state:
- return state
-
- # map over the initial states, a counter representing the map_index, and also the mapped upstream states
- map_states = executor.map(
- run_fn, initial_states, range(len(map_upstream_states)), map_upstream_states
- )
-
- self.logger.debug(
- "{} mapped tasks submitted for execution.".format(len(map_states))
- )
- new_state = Mapped(
- message="Mapped tasks submitted for execution.", map_states=map_states
- )
- return self.handle_state_change(old_state=state, new_state=new_state)
-
- @call_state_handlers
- def wait_for_mapped_task(
- self, state: State, executor: "prefect.engine.executors.Executor"
- ) -> State:
- """
- Blocks until a mapped state's children have finished running.
-
- Args:
- - state (State): the current `Mapped` state
- - executor (Executor): the run's executor
-
- Returns:
- - State: the new state
- """
- if state.is_mapped():
- assert isinstance(state, Mapped) # mypy assert
- state.map_states = executor.wait(state.map_states)
- return state
-
@call_state_handlers
def set_task_to_running(self, state: State, inputs: Dict[str, Result]) -> State:
"""
@@ -895,12 +760,7 @@ def set_task_to_running(self, state: State, inputs: Dict[str, Result]) -> State:
@run_with_heartbeat
@call_state_handlers
- def get_task_run_state(
- self,
- state: State,
- inputs: Dict[str, Result],
- timeout_handler: Optional[Callable] = None,
- ) -> State:
+ def get_task_run_state(self, state: State, inputs: Dict[str, Result],) -> State:
"""
Runs the task and traps any signals or errors it raises.
Also checkpoints the result of a successful task, if `task.checkpoint` is `True`.
@@ -909,9 +769,6 @@ def get_task_run_state(
- state (State): the current state of this task
- inputs (Dict[str, Result], optional): a dictionary of inputs whose keys correspond
to the task's `run()` arguments.
- - timeout_handler (Callable, optional): function for timing out
- task execution, with call signature `handler(fn, *args, **kwargs)`. Defaults to
- `prefect.utilities.executors.timeout_handler`
Returns:
- State: the state of the task after running the check
@@ -937,9 +794,7 @@ def get_task_run_state(
name=prefect.context.get("task_full_name", self.task.name)
)
)
- timeout_handler = (
- timeout_handler or prefect.utilities.executors.timeout_handler
- )
+ timeout_handler = prefect.utilities.executors.timeout_handler
raw_inputs = {k: r.value for k, r in inputs.items()}
if getattr(self.task, "log_stdout", False):
@@ -1096,7 +951,6 @@ def check_task_is_looping(
inputs: Dict[str, Result] = None,
upstream_states: Dict[Edge, State] = None,
context: Dict[str, Any] = None,
- executor: "prefect.engine.executors.Executor" = None,
) -> State:
"""
Checks to see if the task is in a `Looped` state and if so, rerun the pipeline with an incremeneted `loop_count`.
@@ -1110,8 +964,6 @@ def check_task_is_looping(
representing the states of any tasks upstream of this one. The keys of the
dictionary should correspond to the edges leading to the task.
- context (dict, optional): prefect Context to use for execution
- - executor (Executor, optional): executor to use when performing
- computation; defaults to the executor specified in your prefect configuration
Returns:
- `State` object representing the final post-run state of the Task
@@ -1134,7 +986,6 @@ def check_task_is_looping(
new_state,
upstream_states=upstream_states,
context=context,
- executor=executor,
)
return state
diff --git a/src/prefect/utilities/executors.py b/src/prefect/utilities/executors.py
--- a/src/prefect/utilities/executors.py
+++ b/src/prefect/utilities/executors.py
@@ -1,3 +1,5 @@
+import copy
+import itertools
import multiprocessing
import os
import signal
@@ -8,13 +10,15 @@
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import TimeoutError as FutureTimeout
from functools import wraps
-from typing import TYPE_CHECKING, Any, Callable, List, Union
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Union
import prefect
if TYPE_CHECKING:
import prefect.engine.runner
import prefect.engine.state
+ from prefect.core.edge import Edge # pylint: disable=W0611
+ from prefect.core.task import Task # pylint: disable=W0611
from prefect.engine.state import State # pylint: disable=W0611
StateList = Union["State", List["State"]]
@@ -271,3 +275,99 @@ def wrapper(*args: Any, **kwargs: Any) -> Any:
setattr(wrapper, "__wrapped_func__", func)
return wrapper
+
+
+def prepare_upstream_states_for_mapping(
+ state: "State",
+ upstream_states: Dict["Edge", "State"],
+ mapped_children: Dict["Task", list],
+) -> list:
+ """
+ If the task is being mapped, submits children tasks for execution. Returns a `Mapped` state.
+
+ Args:
+ - state (State): the parent task's current state
+ - upstream_states (Dict[Edge, State]): the upstream states to this task
+ - mapped_children (Dict[Task, List[State]]): any mapped children upstream of this task
+
+ Returns:
+ - List: a restructured list of upstream states correponding to each new mapped child task
+ """
+
+ ## if the current state is failed / skipped or otherwise
+ ## in a state that signifies we should not continue with mapping,
+ ## we return an empty list
+ if state.is_pending() or state.is_failed() or state.is_skipped():
+ return []
+
+ map_upstream_states = []
+
+ # we don't know how long the iterables are, but we want to iterate until we reach
+ # the end of the shortest one
+ counter = itertools.count()
+
+ # infinite loop, if upstream_states has any entries
+ while True and upstream_states:
+ i = next(counter)
+ states = {}
+
+ try:
+
+ for edge, upstream_state in upstream_states.items():
+
+ # ensure we are working with populated result objects
+ if edge.key in state.cached_inputs:
+ upstream_state._result = state.cached_inputs[edge.key]
+
+ # if the edge is not mapped over, then we take its state
+ if not edge.mapped:
+ states[edge] = upstream_state
+
+ # if the edge is mapped and the upstream state is Mapped, then we are mapping
+ # over a mapped task. In this case, we take the appropriately-indexed upstream
+ # state from the upstream tasks's `Mapped.map_states` array.
+ # Note that these "states" might actually be futures at this time; we aren't
+ # blocking until they finish.
+ elif edge.mapped and upstream_state.is_mapped():
+ states[edge] = mapped_children[edge.upstream_task][i] # type: ignore
+
+ # Otherwise, we are mapping over the result of a "vanilla" task. In this
+ # case, we create a copy of the upstream state but set the result to the
+ # appropriately-indexed item from the upstream task's `State.result`
+ # array.
+ else:
+ states[edge] = copy.copy(upstream_state)
+
+ # if the current state is already Mapped, then we might be executing
+ # a re-run of the mapping pipeline. In that case, the upstream states
+ # might not have `result` attributes (as any required results could be
+ # in the `cached_inputs` attribute of one of the child states).
+ # Therefore, we only try to get a result if EITHER this task's
+ # state is not already mapped OR the upstream result is not None.
+ if (
+ not state.is_mapped()
+ or upstream_state._result != prefect.engine.result.NoResult
+ ):
+ if not hasattr(upstream_state.result, "__getitem__"):
+ raise TypeError(
+ "Cannot map over unsubscriptable object of type {t}: {preview}...".format(
+ t=type(upstream_state.result),
+ preview=repr(upstream_state.result)[:10],
+ )
+ )
+ upstream_result = upstream_state._result.from_value( # type: ignore
+ upstream_state.result[i]
+ )
+ states[edge].result = upstream_result
+ elif state.is_mapped():
+ if i >= len(state.map_states): # type: ignore
+ raise IndexError()
+
+ # only add this iteration if we made it through all iterables
+ map_upstream_states.append(states)
+
+ # index error means we reached the end of the shortest iterable
+ except IndexError:
+ break
+
+ return map_upstream_states
</patch> | [] | [] | ||||
googleapis__google-cloud-python-3156 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Language: support mention type in Entity.mentions.
[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.
Furthermore, this change should add mention_type information to the mention documentation.
</issue>
<code>
[start of README.rst]
1 Google Cloud Python Client
2 ==========================
3
4 Python idiomatic client for `Google Cloud Platform`_ services.
5
6 .. _Google Cloud Platform: https://cloud.google.com/
7
8 |pypi| |circleci| |build| |appveyor| |coverage| |versions|
9
10 - `Homepage`_
11 - `API Documentation`_
12 - `Read The Docs Documentation`_
13
14 .. _Homepage: https://googlecloudplatform.github.io/google-cloud-python/
15 .. _API Documentation: https://googlecloudplatform.github.io/google-cloud-python/stable/
16 .. _Read The Docs Documentation: https://google-cloud-python.readthedocs.io/en/latest/
17
18 This client library has **beta** support for the following Google
19 Cloud Platform services:
20
21 - `Google BigQuery`_ (`BigQuery README`_)
22 - `Google Cloud Datastore`_ (`Datastore README`_)
23 - `Stackdriver Logging`_ (`Logging README`_)
24 - `Google Cloud Storage`_ (`Storage README`_)
25 - `Google Cloud Vision`_ (`Vision README`_)
26
27 **Beta** indicates that the client library for a particular service is
28 mostly stable and is being prepared for release. Issues and requests
29 against beta libraries are addressed with a higher priority.
30
31 This client library has **alpha** support for the following Google
32 Cloud Platform services:
33
34 - `Google Cloud Pub/Sub`_ (`Pub/Sub README`_)
35 - `Google Cloud Resource Manager`_ (`Resource Manager README`_)
36 - `Stackdriver Monitoring`_ (`Monitoring README`_)
37 - `Google Cloud Bigtable`_ (`Bigtable README`_)
38 - `Google Cloud DNS`_ (`DNS README`_)
39 - `Stackdriver Error Reporting`_ (`Error Reporting README`_)
40 - `Google Cloud Natural Language`_ (`Natural Language README`_)
41 - `Google Cloud Translation`_ (`Translation README`_)
42 - `Google Cloud Speech`_ (`Speech README`_)
43 - `Google Cloud Bigtable - HappyBase`_ (`HappyBase README`_)
44 - `Google Cloud Runtime Configuration`_ (`Runtime Config README`_)
45 - `Cloud Spanner`_ (`Cloud Spanner README`_)
46
47 **Alpha** indicates that the client library for a particular service is
48 still a work-in-progress and is more likely to get backwards-incompatible
49 updates. See `versioning`_ for more details.
50
51 .. _Google Cloud Datastore: https://pypi.python.org/pypi/google-cloud-datastore
52 .. _Datastore README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/datastore
53 .. _Google Cloud Storage: https://pypi.python.org/pypi/google-cloud-storage
54 .. _Storage README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/storage
55 .. _Google Cloud Pub/Sub: https://pypi.python.org/pypi/google-cloud-pubsub
56 .. _Pub/Sub README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/pubsub
57 .. _Google BigQuery: https://pypi.python.org/pypi/google-cloud-bigquery
58 .. _BigQuery README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/bigquery
59 .. _Google Cloud Resource Manager: https://pypi.python.org/pypi/google-cloud-resource-manager
60 .. _Resource Manager README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/resource_manager
61 .. _Stackdriver Logging: https://pypi.python.org/pypi/google-cloud-logging
62 .. _Logging README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/logging
63 .. _Stackdriver Monitoring: https://pypi.python.org/pypi/google-cloud-monitoring
64 .. _Monitoring README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/monitoring
65 .. _Google Cloud Bigtable: https://pypi.python.org/pypi/google-cloud-bigtable
66 .. _Bigtable README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/bigtable
67 .. _Google Cloud DNS: https://pypi.python.org/pypi/google-cloud-dns
68 .. _DNS README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/dns
69 .. _Stackdriver Error Reporting: https://pypi.python.org/pypi/google-cloud-error-reporting
70 .. _Error Reporting README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/error_reporting
71 .. _Google Cloud Natural Language: https://pypi.python.org/pypi/google-cloud-language
72 .. _Natural Language README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/language
73 .. _Google Cloud Translation: https://pypi.python.org/pypi/google-cloud-translate
74 .. _Translation README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/translate
75 .. _Google Cloud Speech: https://pypi.python.org/pypi/google-cloud-speech
76 .. _Speech README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/speech
77 .. _Google Cloud Vision: https://pypi.python.org/pypi/google-cloud-vision
78 .. _Vision README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/vision
79 .. _Google Cloud Bigtable - HappyBase: https://pypi.python.org/pypi/google-cloud-happybase/
80 .. _HappyBase README: https://github.com/GoogleCloudPlatform/google-cloud-python-happybase
81 .. _Google Cloud Runtime Configuration: https://cloud.google.com/deployment-manager/runtime-configurator/
82 .. _Runtime Config README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/runtimeconfig
83 .. _Cloud Spanner: https://cloud.google.com/spanner/
84 .. _Cloud Spanner README: https://github.com/GoogleCloudPlatform/google-cloud-python/tree/master/spanner
85 .. _versioning: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst#versioning
86
87 If you need support for other Google APIs, check out the
88 `Google APIs Python Client library`_.
89
90 .. _Google APIs Python Client library: https://github.com/google/google-api-python-client
91
92 Quick Start
93 -----------
94
95 .. code-block:: console
96
97 $ pip install --upgrade google-cloud
98
99 Example Applications
100 --------------------
101
102 - `getting-started-python`_ - A sample and `tutorial`_ that demonstrates how to build a complete web application using Cloud Datastore, Cloud Storage, and Cloud Pub/Sub and deploy it to Google App Engine or Google Compute Engine.
103 - `google-cloud-python-expenses-demo`_ - A sample expenses demo using Cloud Datastore and Cloud Storage
104
105 .. _getting-started-python: https://github.com/GoogleCloudPlatform/getting-started-python
106 .. _tutorial: https://cloud.google.com/python
107 .. _google-cloud-python-expenses-demo: https://github.com/GoogleCloudPlatform/google-cloud-python-expenses-demo
108
109 Authentication
110 --------------
111
112 With ``google-cloud-python`` we try to make authentication as painless as possible.
113 Check out the `Authentication section`_ in our documentation to learn more.
114 You may also find the `authentication document`_ shared by all the
115 ``google-cloud-*`` libraries to be helpful.
116
117 .. _Authentication section: https://google-cloud-python.readthedocs.io/en/latest/google-cloud-auth.html
118 .. _authentication document: https://github.com/GoogleCloudPlatform/gcloud-common/tree/master/authentication
119
120 Contributing
121 ------------
122
123 Contributions to this library are always welcome and highly encouraged.
124
125 See `CONTRIBUTING`_ for more information on how to get started.
126
127 .. _CONTRIBUTING: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/CONTRIBUTING.rst
128
129 Community
130 ---------
131
132 Google Cloud Platform Python developers hang out in `Slack`_ in the ``#python``
133 channel, click here to `get an invitation`_.
134
135
136 .. _Slack: https://googlecloud-community.slack.com
137 .. _get an invitation: https://gcp-slack.appspot.com/
138
139 License
140 -------
141
142 Apache 2.0 - See `LICENSE`_ for more information.
143
144 .. _LICENSE: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/LICENSE
145
146 .. |build| image:: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python.svg?branch=master
147 :target: https://travis-ci.org/GoogleCloudPlatform/google-cloud-python
148 .. |circleci| image:: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python.svg?style=shield
149 :target: https://circleci.com/gh/GoogleCloudPlatform/google-cloud-python
150 .. |appveyor| image:: https://ci.appveyor.com/api/projects/status/github/googlecloudplatform/google-cloud-python?branch=master&svg=true
151 :target: https://ci.appveyor.com/project/GoogleCloudPlatform/google-cloud-python
152 .. |coverage| image:: https://coveralls.io/repos/GoogleCloudPlatform/google-cloud-python/badge.svg?branch=master
153 :target: https://coveralls.io/r/GoogleCloudPlatform/google-cloud-python?branch=master
154 .. |pypi| image:: https://img.shields.io/pypi/v/google-cloud.svg
155 :target: https://pypi.python.org/pypi/google-cloud
156 .. |versions| image:: https://img.shields.io/pypi/pyversions/google-cloud.svg
157 :target: https://pypi.python.org/pypi/google-cloud
158
[end of README.rst]
[start of datastore/google/cloud/datastore/helpers.py]
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helper functions for dealing with Cloud Datastore's Protobuf API.
16
17 The non-private functions are part of the API.
18 """
19
20 import datetime
21 import itertools
22
23 from google.protobuf import struct_pb2
24 from google.type import latlng_pb2
25 import six
26
27 from google.cloud._helpers import _datetime_to_pb_timestamp
28 from google.cloud._helpers import _pb_timestamp_to_datetime
29 from google.cloud.proto.datastore.v1 import entity_pb2 as _entity_pb2
30 from google.cloud.datastore.entity import Entity
31 from google.cloud.datastore.key import Key
32
33
34 def _get_meaning(value_pb, is_list=False):
35 """Get the meaning from a protobuf value.
36
37 :type value_pb: :class:`.entity_pb2.Value`
38 :param value_pb: The protobuf value to be checked for an
39 associated meaning.
40
41 :type is_list: bool
42 :param is_list: Boolean indicating if the ``value_pb`` contains
43 a list value.
44
45 :rtype: int
46 :returns: The meaning for the ``value_pb`` if one is set, else
47 :data:`None`. For a list value, if there are disagreeing
48 means it just returns a list of meanings. If all the
49 list meanings agree, it just condenses them.
50 """
51 meaning = None
52 if is_list:
53 # An empty list will have no values, hence no shared meaning
54 # set among them.
55 if len(value_pb.array_value.values) == 0:
56 return None
57
58 # We check among all the meanings, some of which may be None,
59 # the rest which may be enum/int values.
60 all_meanings = [_get_meaning(sub_value_pb)
61 for sub_value_pb in value_pb.array_value.values]
62 unique_meanings = set(all_meanings)
63 if len(unique_meanings) == 1:
64 # If there is a unique meaning, we preserve it.
65 meaning = unique_meanings.pop()
66 else: # We know len(value_pb.array_value.values) > 0.
67 # If the meaning is not unique, just return all of them.
68 meaning = all_meanings
69 elif value_pb.meaning: # Simple field (int32).
70 meaning = value_pb.meaning
71
72 return meaning
73
74
75 def _new_value_pb(entity_pb, name):
76 """Add (by name) a new ``Value`` protobuf to an entity protobuf.
77
78 :type entity_pb: :class:`.entity_pb2.Entity`
79 :param entity_pb: An entity protobuf to add a new property to.
80
81 :type name: str
82 :param name: The name of the new property.
83
84 :rtype: :class:`.entity_pb2.Value`
85 :returns: The new ``Value`` protobuf that was added to the entity.
86 """
87 return entity_pb.properties.get_or_create(name)
88
89
90 def _property_tuples(entity_pb):
91 """Iterator of name, ``Value`` tuples from entity properties.
92
93 :type entity_pb: :class:`.entity_pb2.Entity`
94 :param entity_pb: An entity protobuf to add a new property to.
95
96 :rtype: :class:`generator`
97 :returns: An iterator that yields tuples of a name and ``Value``
98 corresponding to properties on the entity.
99 """
100 return six.iteritems(entity_pb.properties)
101
102
103 def entity_from_protobuf(pb):
104 """Factory method for creating an entity based on a protobuf.
105
106 The protobuf should be one returned from the Cloud Datastore
107 Protobuf API.
108
109 :type pb: :class:`.entity_pb2.Entity`
110 :param pb: The Protobuf representing the entity.
111
112 :rtype: :class:`google.cloud.datastore.entity.Entity`
113 :returns: The entity derived from the protobuf.
114 """
115 key = None
116 if pb.HasField('key'): # Message field (Key)
117 key = key_from_protobuf(pb.key)
118
119 entity_props = {}
120 entity_meanings = {}
121 exclude_from_indexes = []
122
123 for prop_name, value_pb in _property_tuples(pb):
124 value = _get_value_from_value_pb(value_pb)
125 entity_props[prop_name] = value
126
127 # Check if the property has an associated meaning.
128 is_list = isinstance(value, list)
129 meaning = _get_meaning(value_pb, is_list=is_list)
130 if meaning is not None:
131 entity_meanings[prop_name] = (meaning, value)
132
133 # Check if ``value_pb`` was excluded from index. Lists need to be
134 # special-cased and we require all ``exclude_from_indexes`` values
135 # in a list agree.
136 if is_list:
137 exclude_values = set(value_pb.exclude_from_indexes
138 for value_pb in value_pb.array_value.values)
139 if len(exclude_values) != 1:
140 raise ValueError('For an array_value, subvalues must either '
141 'all be indexed or all excluded from '
142 'indexes.')
143
144 if exclude_values.pop():
145 exclude_from_indexes.append(prop_name)
146 else:
147 if value_pb.exclude_from_indexes:
148 exclude_from_indexes.append(prop_name)
149
150 entity = Entity(key=key, exclude_from_indexes=exclude_from_indexes)
151 entity.update(entity_props)
152 entity._meanings.update(entity_meanings)
153 return entity
154
155
156 def _set_pb_meaning_from_entity(entity, name, value, value_pb,
157 is_list=False):
158 """Add meaning information (from an entity) to a protobuf.
159
160 :type entity: :class:`google.cloud.datastore.entity.Entity`
161 :param entity: The entity to be turned into a protobuf.
162
163 :type name: str
164 :param name: The name of the property.
165
166 :type value: object
167 :param value: The current value stored as property ``name``.
168
169 :type value_pb: :class:`.entity_pb2.Value`
170 :param value_pb: The protobuf value to add meaning / meanings to.
171
172 :type is_list: bool
173 :param is_list: (Optional) Boolean indicating if the ``value`` is
174 a list value.
175 """
176 if name not in entity._meanings:
177 return
178
179 meaning, orig_value = entity._meanings[name]
180 # Only add the meaning back to the protobuf if the value is
181 # unchanged from when it was originally read from the API.
182 if orig_value is not value:
183 return
184
185 # For lists, we set meaning on each sub-element.
186 if is_list:
187 if not isinstance(meaning, list):
188 meaning = itertools.repeat(meaning)
189 val_iter = six.moves.zip(value_pb.array_value.values,
190 meaning)
191 for sub_value_pb, sub_meaning in val_iter:
192 if sub_meaning is not None:
193 sub_value_pb.meaning = sub_meaning
194 else:
195 value_pb.meaning = meaning
196
197
198 def entity_to_protobuf(entity):
199 """Converts an entity into a protobuf.
200
201 :type entity: :class:`google.cloud.datastore.entity.Entity`
202 :param entity: The entity to be turned into a protobuf.
203
204 :rtype: :class:`.entity_pb2.Entity`
205 :returns: The protobuf representing the entity.
206 """
207 entity_pb = _entity_pb2.Entity()
208 if entity.key is not None:
209 key_pb = entity.key.to_protobuf()
210 entity_pb.key.CopyFrom(key_pb)
211
212 for name, value in entity.items():
213 value_is_list = isinstance(value, list)
214 if value_is_list and len(value) == 0:
215 continue
216
217 value_pb = _new_value_pb(entity_pb, name)
218 # Set the appropriate value.
219 _set_protobuf_value(value_pb, value)
220
221 # Add index information to protobuf.
222 if name in entity.exclude_from_indexes:
223 if not value_is_list:
224 value_pb.exclude_from_indexes = True
225
226 for sub_value in value_pb.array_value.values:
227 sub_value.exclude_from_indexes = True
228
229 # Add meaning information to protobuf.
230 _set_pb_meaning_from_entity(entity, name, value, value_pb,
231 is_list=value_is_list)
232
233 return entity_pb
234
235
236 def key_from_protobuf(pb):
237 """Factory method for creating a key based on a protobuf.
238
239 The protobuf should be one returned from the Cloud Datastore
240 Protobuf API.
241
242 :type pb: :class:`.entity_pb2.Key`
243 :param pb: The Protobuf representing the key.
244
245 :rtype: :class:`google.cloud.datastore.key.Key`
246 :returns: a new `Key` instance
247 """
248 path_args = []
249 for element in pb.path:
250 path_args.append(element.kind)
251 if element.id: # Simple field (int64)
252 path_args.append(element.id)
253 # This is safe: we expect proto objects returned will only have
254 # one of `name` or `id` set.
255 if element.name: # Simple field (string)
256 path_args.append(element.name)
257
258 project = None
259 if pb.partition_id.project_id: # Simple field (string)
260 project = pb.partition_id.project_id
261 namespace = None
262 if pb.partition_id.namespace_id: # Simple field (string)
263 namespace = pb.partition_id.namespace_id
264
265 return Key(*path_args, namespace=namespace, project=project)
266
267
268 def _pb_attr_value(val):
269 """Given a value, return the protobuf attribute name and proper value.
270
271 The Protobuf API uses different attribute names based on value types
272 rather than inferring the type. This function simply determines the
273 proper attribute name based on the type of the value provided and
274 returns the attribute name as well as a properly formatted value.
275
276 Certain value types need to be coerced into a different type (such
277 as a `datetime.datetime` into an integer timestamp, or a
278 `google.cloud.datastore.key.Key` into a Protobuf representation. This
279 function handles that for you.
280
281 .. note::
282 Values which are "text" ('unicode' in Python2, 'str' in Python3) map
283 to 'string_value' in the datastore; values which are "bytes"
284 ('str' in Python2, 'bytes' in Python3) map to 'blob_value'.
285
286 For example:
287
288 >>> _pb_attr_value(1234)
289 ('integer_value', 1234)
290 >>> _pb_attr_value('my_string')
291 ('string_value', 'my_string')
292
293 :type val: `datetime.datetime`, :class:`google.cloud.datastore.key.Key`,
294 bool, float, integer, string
295 :param val: The value to be scrutinized.
296
297 :rtype: tuple
298 :returns: A tuple of the attribute name and proper value type.
299 """
300
301 if isinstance(val, datetime.datetime):
302 name = 'timestamp'
303 value = _datetime_to_pb_timestamp(val)
304 elif isinstance(val, Key):
305 name, value = 'key', val.to_protobuf()
306 elif isinstance(val, bool):
307 name, value = 'boolean', val
308 elif isinstance(val, float):
309 name, value = 'double', val
310 elif isinstance(val, six.integer_types):
311 name, value = 'integer', val
312 elif isinstance(val, six.text_type):
313 name, value = 'string', val
314 elif isinstance(val, (bytes, str)):
315 name, value = 'blob', val
316 elif isinstance(val, Entity):
317 name, value = 'entity', val
318 elif isinstance(val, list):
319 name, value = 'array', val
320 elif isinstance(val, GeoPoint):
321 name, value = 'geo_point', val.to_protobuf()
322 elif val is None:
323 name, value = 'null', struct_pb2.NULL_VALUE
324 else:
325 raise ValueError("Unknown protobuf attr type %s" % type(val))
326
327 return name + '_value', value
328
329
330 def _get_value_from_value_pb(value_pb):
331 """Given a protobuf for a Value, get the correct value.
332
333 The Cloud Datastore Protobuf API returns a Property Protobuf which
334 has one value set and the rest blank. This function retrieves the
335 the one value provided.
336
337 Some work is done to coerce the return value into a more useful type
338 (particularly in the case of a timestamp value, or a key value).
339
340 :type value_pb: :class:`.entity_pb2.Value`
341 :param value_pb: The Value Protobuf.
342
343 :rtype: object
344 :returns: The value provided by the Protobuf.
345 :raises: :class:`ValueError <exceptions.ValueError>` if no value type
346 has been set.
347 """
348 value_type = value_pb.WhichOneof('value_type')
349
350 if value_type == 'timestamp_value':
351 result = _pb_timestamp_to_datetime(value_pb.timestamp_value)
352
353 elif value_type == 'key_value':
354 result = key_from_protobuf(value_pb.key_value)
355
356 elif value_type == 'boolean_value':
357 result = value_pb.boolean_value
358
359 elif value_type == 'double_value':
360 result = value_pb.double_value
361
362 elif value_type == 'integer_value':
363 result = value_pb.integer_value
364
365 elif value_type == 'string_value':
366 result = value_pb.string_value
367
368 elif value_type == 'blob_value':
369 result = value_pb.blob_value
370
371 elif value_type == 'entity_value':
372 result = entity_from_protobuf(value_pb.entity_value)
373
374 elif value_type == 'array_value':
375 result = [_get_value_from_value_pb(value)
376 for value in value_pb.array_value.values]
377
378 elif value_type == 'geo_point_value':
379 result = GeoPoint(value_pb.geo_point_value.latitude,
380 value_pb.geo_point_value.longitude)
381
382 elif value_type == 'null_value':
383 result = None
384
385 else:
386 raise ValueError('Value protobuf did not have any value set')
387
388 return result
389
390
391 def _set_protobuf_value(value_pb, val):
392 """Assign 'val' to the correct subfield of 'value_pb'.
393
394 The Protobuf API uses different attribute names based on value types
395 rather than inferring the type.
396
397 Some value types (entities, keys, lists) cannot be directly
398 assigned; this function handles them correctly.
399
400 :type value_pb: :class:`.entity_pb2.Value`
401 :param value_pb: The value protobuf to which the value is being assigned.
402
403 :type val: :class:`datetime.datetime`, boolean, float, integer, string,
404 :class:`google.cloud.datastore.key.Key`,
405 :class:`google.cloud.datastore.entity.Entity`
406 :param val: The value to be assigned.
407 """
408 attr, val = _pb_attr_value(val)
409 if attr == 'key_value':
410 value_pb.key_value.CopyFrom(val)
411 elif attr == 'timestamp_value':
412 value_pb.timestamp_value.CopyFrom(val)
413 elif attr == 'entity_value':
414 entity_pb = entity_to_protobuf(val)
415 value_pb.entity_value.CopyFrom(entity_pb)
416 elif attr == 'array_value':
417 l_pb = value_pb.array_value.values
418 for item in val:
419 i_pb = l_pb.add()
420 _set_protobuf_value(i_pb, item)
421 elif attr == 'geo_point_value':
422 value_pb.geo_point_value.CopyFrom(val)
423 else: # scalar, just assign
424 setattr(value_pb, attr, val)
425
426
427 class GeoPoint(object):
428 """Simple container for a geo point value.
429
430 :type latitude: float
431 :param latitude: Latitude of a point.
432
433 :type longitude: float
434 :param longitude: Longitude of a point.
435 """
436
437 def __init__(self, latitude, longitude):
438 self.latitude = latitude
439 self.longitude = longitude
440
441 def to_protobuf(self):
442 """Convert the current object to protobuf.
443
444 :rtype: :class:`google.type.latlng_pb2.LatLng`.
445 :returns: The current point as a protobuf.
446 """
447 return latlng_pb2.LatLng(latitude=self.latitude,
448 longitude=self.longitude)
449
450 def __eq__(self, other):
451 """Compare two geo points for equality.
452
453 :rtype: bool
454 :returns: True if the points compare equal, else False.
455 """
456 if not isinstance(other, GeoPoint):
457 return False
458
459 return (self.latitude == other.latitude and
460 self.longitude == other.longitude)
461
462 def __ne__(self, other):
463 """Compare two geo points for inequality.
464
465 :rtype: bool
466 :returns: False if the points compare equal, else True.
467 """
468 return not self.__eq__(other)
469
[end of datastore/google/cloud/datastore/helpers.py]
[start of docs/conf.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # google-cloud documentation build configuration file, created by
16 # sphinx-quickstart on Tue Jan 21 22:24:47 2014.
17 #
18 # This file is execfile()d with the current directory set to its containing dir.
19 #
20 # Note that not all possible configuration values are present in this
21 # autogenerated file.
22 #
23 # All configuration values have a default; values that are commented out
24 # serve to show the default.
25
26 from email import message_from_string
27 import os
28 from pkg_resources import get_distribution
29 import sys
30 import urllib
31
32 import sphinx_rtd_theme
33
34
35 ON_READ_THE_DOCS = os.environ.get('READTHEDOCS', None) == 'True'
36
37 # If extensions (or modules to document with autodoc) are in another directory,
38 # add these directories to sys.path here. If the directory is relative to the
39 # documentation root, use os.path.abspath to make it absolute, like shown here.
40 sys.path.insert(0, os.path.abspath('..'))
41
42 # -- General configuration -----------------------------------------------------
43
44 # If your documentation needs a minimal Sphinx version, state it here.
45 #needs_sphinx = '1.0'
46
47 # Add any Sphinx extension module names here, as strings. They can be extensions
48 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
49 extensions = [
50 'sphinx.ext.autodoc',
51 'sphinx.ext.autosummary',
52 'sphinx.ext.doctest',
53 'sphinx.ext.intersphinx',
54 'sphinx.ext.todo',
55 'sphinx.ext.viewcode',
56 ]
57
58 # Add any paths that contain templates here, relative to this directory.
59 templates_path = []
60
61 # The suffix of source filenames.
62 source_suffix = '.rst'
63
64 # The encoding of source files.
65 #source_encoding = 'utf-8-sig'
66
67 # The master toctree document.
68 master_doc = 'index'
69
70 # General information about the project.
71 project = u'google-cloud'
72 copyright = u'2014, Google'
73
74 # The version info for the project you're documenting, acts as replacement for
75 # |version| and |release|, also used in various other places throughout the
76 # built documents.
77 #
78 # The short X.Y version.
79 distro = get_distribution('google-cloud')
80 release = os.getenv('SPHINX_RELEASE', distro.version)
81
82 # The language for content autogenerated by Sphinx. Refer to documentation
83 # for a list of supported languages.
84 #language = None
85
86 # There are two options for replacing |today|: either, you set today to some
87 # non-false value, then it is used:
88 #today = ''
89 # Else, today_fmt is used as the format for a strftime call.
90 #today_fmt = '%B %d, %Y'
91
92 # List of patterns, relative to source directory, that match files and
93 # directories to ignore when looking for source files.
94 exclude_patterns = ['_build']
95
96 # The reST default role (used for this markup: `text`) to use for all documents.
97 #default_role = None
98
99 # If true, '()' will be appended to :func: etc. cross-reference text.
100 #add_function_parentheses = True
101
102 # If true, the current module name will be prepended to all description
103 # unit titles (such as .. function::).
104 #add_module_names = True
105
106 # If true, sectionauthor and moduleauthor directives will be shown in the
107 # output. They are ignored by default.
108 #show_authors = False
109
110 # The name of the Pygments (syntax highlighting) style to use.
111 pygments_style = 'sphinx'
112
113 # A list of ignored prefixes for module index sorting.
114 #modindex_common_prefix = []
115
116
117 # -- Options for HTML output ---------------------------------------------------
118
119 # The theme to use for HTML and HTML Help pages. See the documentation for
120 # a list of builtin themes.
121
122 if not ON_READ_THE_DOCS:
123 html_theme = 'sphinx_rtd_theme'
124 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
125
126 # Theme options are theme-specific and customize the look and feel of a theme
127 # further. For a list of options available for each theme, see the
128 # documentation.
129 #html_theme_options = {}
130
131 # Add any paths that contain custom themes here, relative to this directory.
132 #html_theme_path = []
133
134 # The name for this set of Sphinx documents. If None, it defaults to
135 # "<project> v<release> documentation".
136 #html_title = None
137
138 # A shorter title for the navigation bar. Default is the same as html_title.
139 #html_short_title = None
140
141 # The name of an image file (relative to this directory) to place at the top
142 # of the sidebar.
143 #html_logo = None
144
145 # The name of an image file (within the static path) to use as favicon of the
146 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
147 # pixels large.
148 html_favicon = '_static/images/favicon.ico'
149
150 # Add any paths that contain custom static files (such as style sheets) here,
151 # relative to this directory. They are copied after the builtin static files,
152 # so a file named "default.css" will overwrite the builtin "default.css".
153 html_static_path = ['_static']
154
155 html_add_permalinks = '#'
156
157 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
158 # using the given strftime format.
159 #html_last_updated_fmt = '%b %d, %Y'
160
161 # If true, SmartyPants will be used to convert quotes and dashes to
162 # typographically correct entities.
163 #html_use_smartypants = True
164
165 # Custom sidebar templates, maps document names to template names.
166 #html_sidebars = {}
167
168 # Additional templates that should be rendered to pages, maps page names to
169 # template names.
170 #html_additional_pages = {}
171
172 # If false, no module index is generated.
173 #html_domain_indices = True
174
175 # If false, no index is generated.
176 #html_use_index = True
177
178 # If true, the index is split into individual pages for each letter.
179 #html_split_index = False
180
181 # If true, links to the reST sources are added to the pages.
182 #html_show_sourcelink = True
183
184 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
185 #html_show_sphinx = True
186
187 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
188 #html_show_copyright = True
189
190 # If true, an OpenSearch description file will be output, and all pages will
191 # contain a <link> tag referring to it. The value of this option must be the
192 # base URL from which the finished HTML is served.
193 #html_use_opensearch = ''
194
195 # This is the file name suffix for HTML files (e.g. ".xhtml").
196 #html_file_suffix = None
197
198 # Output file base name for HTML help builder.
199 htmlhelp_basename = 'google-cloud-doc'
200
201 html_context = {}
202
203
204 # -- Options for LaTeX output --------------------------------------------------
205
206 latex_elements = {
207 # The paper size ('letterpaper' or 'a4paper').
208 #'papersize': 'letterpaper',
209
210 # The font size ('10pt', '11pt' or '12pt').
211 #'pointsize': '10pt',
212
213 # Additional stuff for the LaTeX preamble.
214 #'preamble': '',
215 }
216
217 metadata = distro.get_metadata(distro.PKG_INFO)
218 author = message_from_string(metadata).get('Author')
219 # Grouping the document tree into LaTeX files. List of tuples
220 # (source start file, target name, title, author, documentclass [howto/manual]).
221 latex_documents = [
222 ('index', 'google-cloud.tex', u'google-cloud Documentation',
223 author, 'manual'),
224 ]
225
226 # The name of an image file (relative to this directory) to place at the top of
227 # the title page.
228 #latex_logo = None
229
230 # For "manual" documents, if this is true, then toplevel headings are parts,
231 # not chapters.
232 #latex_use_parts = False
233
234 # If true, show page references after internal links.
235 #latex_show_pagerefs = False
236
237 # If true, show URL addresses after external links.
238 #latex_show_urls = False
239
240 # Documents to append as an appendix to all manuals.
241 #latex_appendices = []
242
243 # If false, no module index is generated.
244 #latex_domain_indices = True
245
246
247 # -- Options for manual page output --------------------------------------------
248
249 # One entry per manual page. List of tuples
250 # (source start file, name, description, authors, manual section).
251 man_pages = [
252 ('index', 'google-cloud', u'google-cloud Documentation',
253 [author], 1)
254 ]
255
256 # If true, show URL addresses after external links.
257 #man_show_urls = False
258
259
260 # -- Options for Texinfo output ------------------------------------------------
261
262 # Grouping the document tree into Texinfo files. List of tuples
263 # (source start file, target name, title, author,
264 # dir menu entry, description, category)
265 texinfo_documents = [
266 ('index', 'google-cloud', u'google-cloud Documentation',
267 author, 'google-cloud', 'Python API for Google Cloud.',
268 'Miscellaneous'),
269 ]
270
271 # Documents to append as an appendix to all manuals.
272 #texinfo_appendices = []
273
274 # If false, no module index is generated.
275 #texinfo_domain_indices = True
276
277 # How to display URL addresses: 'footnote', 'no', or 'inline'.
278 #texinfo_show_urls = 'footnote'
279
280 # This pulls class descriptions from the class docstring,
281 # and parameter definitions from the __init__ docstring.
282 autoclass_content = 'both'
283
284 # Configuration for intersphinx:
285 # Refer to the Python standard library and the oauth2client and
286 # httplib2 libraries.
287 intersphinx_mapping = {
288 'httplib2': ('http://httplib2.readthedocs.io/en/latest/', None),
289 'oauth2client': ('http://oauth2client.readthedocs.io/en/latest', None),
290 'pandas': ('http://pandas.pydata.org/pandas-docs/stable/', None),
291 'python': ('https://docs.python.org/2', None),
292 'google-auth': ('https://google-auth.readthedocs.io/en/stable', None),
293 }
294
[end of docs/conf.py]
[start of language/google/cloud/language/document.py]
1 # Copyright 2016-2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Definition for Google Cloud Natural Language API documents.
16
17 A document is used to hold text to be analyzed and annotated.
18 """
19
20 import collections
21 import sys
22
23 from google.cloud.language import api_responses
24 from google.cloud.language.entity import Entity
25 from google.cloud.language.sentiment import Sentiment
26 from google.cloud.language.sentence import Sentence
27 from google.cloud.language.syntax import Token
28
29
30 Annotations = collections.namedtuple(
31 'Annotations',
32 ['sentences', 'tokens', 'sentiment', 'entities', 'language'])
33 """Annotations for a document.
34
35 :type sentences: list
36 :param sentences: List of :class:`.Sentence` in a document.
37
38 :type tokens: list
39 :param tokens: List of :class:`.Token` from a document.
40
41 :type sentiment: :class:`Sentiment`
42 :param sentiment: The sentiment of a document.
43
44 :type entities: list
45 :param entities: List of :class:`~.language.entity.Entity`
46 found in a document.
47
48 :type language: str
49 :param language: The language used for the annotation.
50 """
51
52
53 class Encoding(object):
54 """The encoding type used to calculate offsets.
55
56 Represents the text encoding that the caller uses to process the output.
57 The API provides the beginning offsets for various outputs, such as tokens
58 and mentions.
59 """
60
61 NONE = 'NONE'
62 """Unspecified encoding type."""
63
64 UTF8 = 'UTF8'
65 """UTF-8 encoding type."""
66
67 UTF16 = 'UTF16'
68 """UTF-16 encoding type."""
69
70 UTF32 = 'UTF32'
71 """UTF-32 encoding type."""
72
73 @classmethod
74 def get_default(cls):
75 """Return the appropriate default encoding on this system.
76
77 :rtype: str
78 :returns: The correct default encoding on this system.
79 """
80 if sys.maxunicode == 65535:
81 return cls.UTF16
82 return cls.UTF32
83
84
85 class Document(object):
86 """Document to send to Google Cloud Natural Language API.
87
88 Represents either plain text or HTML, and the content is either
89 stored on the document or referred to in a Google Cloud Storage
90 object.
91
92 :type client: :class:`~google.cloud.language.client.Client`
93 :param client: A client which holds credentials and other
94 configuration.
95
96 :type content: str
97 :param content: (Optional) The document text content (either plain
98 text or HTML).
99
100 :type gcs_url: str
101 :param gcs_url: (Optional) The URL of the Google Cloud Storage object
102 holding the content. Of the form
103 ``gs://{bucket}/{blob-name}``.
104
105 :type doc_type: str
106 :param doc_type: (Optional) The type of text in the document.
107 Defaults to plain text. Can be one of
108 :attr:`~.Document.PLAIN_TEXT` or
109 or :attr:`~.Document.HTML`.
110
111 :type language: str
112 :param language: (Optional) The language of the document text.
113 Defaults to None (auto-detect).
114
115 :type encoding: str
116 :param encoding: (Optional) The encoding of the document text.
117 Defaults to UTF-8. Can be one of
118 :attr:`~.Encoding.UTF8`, :attr:`~.Encoding.UTF16`
119 or :attr:`~.Encoding.UTF32`.
120
121 :raises: :class:`~exceptions.ValueError` both ``content`` and ``gcs_url``
122 are specified or if neither are specified.
123 """
124
125 TYPE_UNSPECIFIED = 'TYPE_UNSPECIFIED'
126 """Unspecified document type."""
127
128 PLAIN_TEXT = 'PLAIN_TEXT'
129 """Plain text document type."""
130
131 HTML = 'HTML'
132 """HTML document type."""
133
134 def __init__(self, client, content=None, gcs_url=None, doc_type=PLAIN_TEXT,
135 language=None, encoding=Encoding.get_default()):
136 if content is not None and gcs_url is not None:
137 raise ValueError('A Document cannot contain both local text and '
138 'a link to text in a Google Cloud Storage object')
139 if content is None and gcs_url is None:
140 raise ValueError('A Document must contain either local text or a '
141 'link to text in a Google Cloud Storage object')
142 self.client = client
143 self.content = content
144 self.gcs_url = gcs_url
145 self.doc_type = doc_type
146 self.language = language
147 self.encoding = encoding
148
149 def _to_dict(self):
150 """Helper to convert the current document into a dictionary.
151
152 To be used when constructing requests.
153
154 :rtype: dict
155 :returns: The Document value as a JSON dictionary.
156 """
157 info = {
158 'type': self.doc_type,
159 }
160 if self.language is not None:
161 info['language'] = self.language
162 if self.content is not None:
163 info['content'] = self.content
164 elif self.gcs_url is not None:
165 info['gcsContentUri'] = self.gcs_url
166 return info
167
168 def analyze_entities(self):
169 """Analyze the entities in the current document.
170
171 Finds named entities (currently finds proper names as of August 2016)
172 in the text, entity types, salience, mentions for each entity, and
173 other properties.
174
175 .. _analyzeEntities: https://cloud.google.com/natural-language/\
176 reference/rest/v1/documents/analyzeEntities
177
178 See `analyzeEntities`_.
179
180 :rtype: :class:`~.language.entity.EntityResponse`
181 :returns: A representation of the entity response.
182 """
183 data = {
184 'document': self._to_dict(),
185 'encodingType': self.encoding,
186 }
187 api_response = self.client._connection.api_request(
188 method='POST', path='analyzeEntities', data=data)
189 return api_responses.EntityResponse.from_api_repr(api_response)
190
191 def analyze_sentiment(self):
192 """Analyze the sentiment in the current document.
193
194 .. _analyzeSentiment: https://cloud.google.com/natural-language/\
195 reference/rest/v1/documents/analyzeSentiment
196
197 See `analyzeSentiment`_.
198
199 :rtype: :class:`.SentimentResponse`
200 :returns: A representation of the sentiment response.
201 """
202 data = {'document': self._to_dict()}
203 api_response = self.client._connection.api_request(
204 method='POST', path='analyzeSentiment', data=data)
205 return api_responses.SentimentResponse.from_api_repr(api_response)
206
207 def analyze_syntax(self):
208 """Analyze the syntax in the current document.
209
210 .. _analyzeSyntax: https://cloud.google.com/natural-language/\
211 reference/rest/v1/documents/analyzeSyntax
212
213 See `analyzeSyntax`_.
214
215 :rtype: list
216 :returns: A list of :class:`~.language.syntax.Token` returned from
217 the API.
218 """
219 data = {
220 'document': self._to_dict(),
221 'encodingType': self.encoding,
222 }
223 api_response = self.client._connection.api_request(
224 method='POST', path='analyzeSyntax', data=data)
225 return api_responses.SyntaxResponse.from_api_repr(api_response)
226
227 def annotate_text(self, include_syntax=True, include_entities=True,
228 include_sentiment=True):
229 """Advanced natural language API: document syntax and other features.
230
231 Includes the full functionality of :meth:`analyze_entities` and
232 :meth:`analyze_sentiment`, enabled by the flags
233 ``include_entities`` and ``include_sentiment`` respectively.
234
235 In addition ``include_syntax`` adds a new feature that analyzes
236 the document for semantic and syntacticinformation.
237
238 .. note::
239
240 This API is intended for users who are familiar with machine
241 learning and need in-depth text features to build upon.
242
243 .. _annotateText: https://cloud.google.com/natural-language/\
244 reference/rest/v1/documents/annotateText
245
246 See `annotateText`_.
247
248 :type include_syntax: bool
249 :param include_syntax: (Optional) Flag to enable syntax analysis
250 of the current document.
251
252 :type include_entities: bool
253 :param include_entities: (Optional) Flag to enable entity extraction
254 from the current document.
255
256 :type include_sentiment: bool
257 :param include_sentiment: (Optional) Flag to enable sentiment
258 analysis of the current document.
259
260 :rtype: :class:`Annotations`
261 :returns: A tuple of each of the four values returned from the API:
262 sentences, tokens, sentiment and entities.
263 """
264 features = {}
265 if include_syntax:
266 features['extractSyntax'] = True
267 if include_entities:
268 features['extractEntities'] = True
269 if include_sentiment:
270 features['extractDocumentSentiment'] = True
271
272 data = {
273 'document': self._to_dict(),
274 'features': features,
275 'encodingType': self.encoding,
276 }
277 api_response = self.client._connection.api_request(
278 method='POST', path='annotateText', data=data)
279
280 sentences = [Sentence.from_api_repr(sentence)
281 for sentence in api_response['sentences']]
282 tokens = [Token.from_api_repr(token)
283 for token in api_response['tokens']]
284 sentiment_info = api_response.get('documentSentiment')
285 if sentiment_info is None:
286 sentiment = None
287 else:
288 sentiment = Sentiment.from_api_repr(sentiment_info)
289 entities = [Entity.from_api_repr(entity)
290 for entity in api_response['entities']]
291 annotations = Annotations(
292 entities=entities,
293 language=api_response.get('language'),
294 sentences=sentences,
295 sentiment=sentiment,
296 tokens=tokens,
297 )
298 return annotations
299
[end of language/google/cloud/language/document.py]
[start of language/google/cloud/language/entity.py]
1 # Copyright 2016-2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Definition for Google Cloud Natural Language API entities.
16
17 An entity is used to describe a proper name extracted from text.
18 """
19
20
21 class EntityType(object):
22 """List of possible entity types."""
23
24 UNKNOWN = 'UNKNOWN'
25 """Unknown entity type."""
26
27 PERSON = 'PERSON'
28 """Person entity type."""
29
30 LOCATION = 'LOCATION'
31 """Location entity type."""
32
33 ORGANIZATION = 'ORGANIZATION'
34 """Organization entity type."""
35
36 EVENT = 'EVENT'
37 """Event entity type."""
38
39 WORK_OF_ART = 'WORK_OF_ART'
40 """Work of art entity type."""
41
42 CONSUMER_GOOD = 'CONSUMER_GOOD'
43 """Consumer good entity type."""
44
45 OTHER = 'OTHER'
46 """Other entity type (i.e. known but not classified)."""
47
48
49 class Entity(object):
50 """A Google Cloud Natural Language API entity.
51
52 Represents a phrase in text that is a known entity, such as a person,
53 an organization, or location. The API associates information, such as
54 salience and mentions, with entities.
55
56 .. _Entity message: https://cloud.google.com/natural-language/\
57 reference/rest/v1/Entity
58 .. _EntityType enum: https://cloud.google.com/natural-language/\
59 reference/rest/v1/Entity#Type
60
61 See `Entity message`_.
62
63 :type name: str
64 :param name: The name / phrase identified as the entity.
65
66 :type entity_type: str
67 :param entity_type: The type of the entity. See `EntityType enum`_.
68
69 :type metadata: dict
70 :param metadata: The metadata associated with the entity.
71 Wikipedia URLs and Knowledge Graph MIDs are
72 provided, if available. The associated keys are
73 "wikipedia_url" and "mid", respectively.
74
75 :type salience: float
76 :param salience: The prominence of the entity / phrase within the text
77 containing it.
78
79 :type mentions: list
80 :param mentions: List of strings that mention the entity.
81 """
82
83 def __init__(self, name, entity_type, metadata, salience, mentions):
84 self.name = name
85 self.entity_type = entity_type
86 self.metadata = metadata
87 self.salience = salience
88 self.mentions = mentions
89
90 @classmethod
91 def from_api_repr(cls, payload):
92 """Convert an Entity from the JSON API into an :class:`Entity`.
93
94 :param payload: dict
95 :type payload: The value from the backend.
96
97 :rtype: :class:`Entity`
98 :returns: The entity parsed from the API representation.
99 """
100 name = payload['name']
101 entity_type = payload['type']
102 metadata = payload['metadata']
103 salience = payload['salience']
104 mentions = [value['text']['content']
105 for value in payload['mentions']]
106 return cls(name, entity_type, metadata, salience, mentions)
107
[end of language/google/cloud/language/entity.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| googleapis/google-cloud-python | ebb77fb029efc65273890cb17c4aa62f99d54607 | Language: support mention type in Entity.mentions.
[Currently](https://github.com/GoogleCloudPlatform/google-cloud-python/blob/master/language/google/cloud/language/entity.py#L79) the mentions property of an entity is only a list of strings whereas it should be a list of objects containing the mention text and mention type.
Furthermore, this change should add mention_type information to the mention documentation.
| Adding the release blocking tag; this is a beta blocker. | 2017-03-16T16:21:51Z | <patch>
diff --git a/language/google/cloud/language/entity.py b/language/google/cloud/language/entity.py
--- a/language/google/cloud/language/entity.py
+++ b/language/google/cloud/language/entity.py
@@ -46,6 +46,80 @@ class EntityType(object):
"""Other entity type (i.e. known but not classified)."""
+class MentionType(object):
+ """List of possible mention types."""
+
+ TYPE_UNKNOWN = 'TYPE_UNKNOWN'
+ """Unknown mention type"""
+
+ PROPER = 'PROPER'
+ """Proper name"""
+
+ COMMON = 'COMMON'
+ """Common noun (or noun compound)"""
+
+
+class Mention(object):
+ """A Google Cloud Natural Language API mention.
+
+ Represents a mention for an entity in the text. Currently, proper noun
+ mentions are supported.
+ """
+ def __init__(self, text, mention_type):
+ self.text = text
+ self.mention_type = mention_type
+
+ def __str__(self):
+ return str(self.text)
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a Mention from the JSON API into an :class:`Mention`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`Mention`
+ :returns: The mention parsed from the API representation.
+ """
+ text = TextSpan.from_api_repr(payload['text'])
+ mention_type = payload['type']
+ return cls(text, mention_type)
+
+
+class TextSpan(object):
+ """A span of text from Google Cloud Natural Language API.
+
+ Represents a word or phrase of text, as well as its offset
+ from the original document.
+ """
+ def __init__(self, content, begin_offset):
+ self.content = content
+ self.begin_offset = begin_offset
+
+ def __str__(self):
+ """Return the string representation of this TextSpan.
+
+ :rtype: str
+ :returns: The text content
+ """
+ return self.content
+
+ @classmethod
+ def from_api_repr(cls, payload):
+ """Convert a TextSpan from the JSON API into an :class:`TextSpan`.
+
+ :param payload: dict
+ :type payload: The value from the backend.
+
+ :rtype: :class:`TextSpan`
+ :returns: The text span parsed from the API representation.
+ """
+ content = payload['content']
+ begin_offset = payload['beginOffset']
+ return cls(content=content, begin_offset=begin_offset)
+
+
class Entity(object):
"""A Google Cloud Natural Language API entity.
@@ -101,6 +175,5 @@ def from_api_repr(cls, payload):
entity_type = payload['type']
metadata = payload['metadata']
salience = payload['salience']
- mentions = [value['text']['content']
- for value in payload['mentions']]
+ mentions = [Mention.from_api_repr(val) for val in payload['mentions']]
return cls(name, entity_type, metadata, salience, mentions)
</patch> | [] | [] | |||
conan-io__conan-4003 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GNU Make generator
https://github.com/solvingj/conan-make_generator/blob/master/conanfile.py by @solvingj is almost it.
I agree it could be built-in.
Can use conditional:
```
ifneq ($(USE_CONAN),)
INC_PATHS += $(CONAN_INC_PATHS)
LD_PATHS += $(CONAN_LIB_PATHS)
LD_LIBS += $(CONAN_LIBS)
CXXFLAGS += $(CONAN_CPP_FLAGS)
CFLAGS += $(CONAN_CFLAGS)
DEFINES += $(CONAN_DEFINES)
LDFLAGS_SHARED += $(CONAN_SHAREDLINKFLAGS)
LDFLAGS_EXE += $(CONAN_EXELINKFLAGS)
C_SRCS += $(CONAN_C_SRCS)
CXX_SRCS += $(CONAN_CXX_SRCS)
endif
```
</issue>
<code>
[start of README.rst]
1 Conan
2 =====
3
4 A distributed, open-source, C/C++ package manager.
5
6 +------------------------+-------------------------+
7 | **master** | **develop** |
8 +========================+=========================+
9 | |Build Status Master| | |Build Status Develop| |
10 +------------------------+-------------------------+
11
12
13 +------------------------+---------------------------+---------------------------------------------+
14 | **Coverage master** | **Coverage develop** | **Coverage graph** |
15 +========================+===========================+=============================================+
16 | |Master coverage| | |Develop coverage| | |Coverage graph| |
17 +------------------------+---------------------------+---------------------------------------------+
18
19
20 Setup
21 ======
22
23 From binaries
24 -------------
25
26 We have installers for `most platforms here <http://conan.io>`__ but you
27 can run **conan** from sources if you want.
28
29 From pip
30 --------
31
32 Conan is compatible with Python 2 and Python 3.
33
34 - Install pip following `pip docs`_.
35 - Install conan:
36
37 .. code-block:: bash
38
39 $ pip install conan
40
41 From Homebrew (OSx)
42 -------------------
43
44 - Install Homebrew following `brew homepage`_.
45
46 .. code-block:: bash
47
48 $ brew update
49 $ brew install conan
50
51 From source
52 -----------
53
54 You can run **conan** client and server in Windows, MacOS, and Linux.
55
56 - **Install pip following** `pip docs`_.
57
58 - **Clone conan repository:**
59
60 .. code-block:: bash
61
62 $ git clone https://github.com/conan-io/conan.git
63
64 - **Install in editable mode**
65
66 .. code-block:: bash
67
68 $ cd conan && sudo pip install -e .
69
70 If you are in Windows, using ``sudo`` is not required.
71
72 - **You are ready, try to run conan:**
73
74 .. code-block::
75
76 $ conan --help
77
78 Consumer commands
79 install Installs the requirements specified in a conanfile (.py or .txt).
80 config Manages configuration. Edits the conan.conf or installs config files.
81 get Gets a file or list a directory of a given reference or package.
82 info Gets information about the dependency graph of a recipe.
83 search Searches package recipes and binaries in the local cache or in a remote.
84 Creator commands
85 new Creates a new package recipe template with a 'conanfile.py'.
86 create Builds a binary package for recipe (conanfile.py) located in current dir.
87 upload Uploads a recipe and binary packages to a remote.
88 export Copies the recipe (conanfile.py & associated files) to your local cache.
89 export-pkg Exports a recipe & creates a package with given files calling 'package'.
90 test Test a package, consuming it with a conanfile recipe with a test() method.
91 Package development commands
92 source Calls your local conanfile.py 'source()' method.
93 build Calls your local conanfile.py 'build()' method.
94 package Calls your local conanfile.py 'package()' method.
95 Misc commands
96 profile Lists profiles in the '.conan/profiles' folder, or shows profile details.
97 remote Manages the remote list and the package recipes associated to a remote.
98 user Authenticates against a remote with user/pass, caching the auth token.
99 imports Calls your local conanfile.py or conanfile.txt 'imports' method.
100 copy Copies conan recipes and packages to another user/channel.
101 remove Removes packages or binaries matching pattern from local cache or remote.
102 alias Creates and exports an 'alias recipe'.
103 download Downloads recipe and binaries to the local cache, without using settings.
104
105 Conan commands. Type "conan <command> -h" for help
106
107 Running the tests
108 =================
109
110 **Install python requirements**
111
112 .. code-block:: bash
113
114 $ pip install -r conans/requirements.txt
115 $ pip install -r conans/requirements_server.txt
116 $ pip install -r conans/requirements_dev.txt
117
118
119 Only in OSX:
120
121
122 .. code-block:: bash
123
124 $ pip install -r conans/requirements_osx.txt # You can omit this one if not running OSX
125
126
127 If you are not Windows and you are not using a python virtual environment, you will need to run these
128 commands using `sudo`.
129
130 Before you can run the tests, you need to set a few environment variables first.
131
132 .. code-block:: bash
133
134 $ export PYTHONPATH=$PYTHONPATH:$(pwd)
135
136 On Windows it would be (while being in the conan root directory):
137
138 .. code-block:: bash
139
140 $ set PYTHONPATH=.
141
142 Ensure that your ``cmake`` has version 2.8 or later. You can see the
143 version with the following command:
144
145 .. code-block:: bash
146
147 $ cmake --version
148
149 The appropriate values of ``CONAN_COMPILER`` and ``CONAN_COMPILER_VERSION`` depend on your
150 operating system and your requirements.
151
152 These should work for the GCC from ``build-essential`` on Ubuntu 14.04:
153
154 .. code-block:: bash
155
156 $ export CONAN_COMPILER=gcc
157 $ export CONAN_COMPILER_VERSION=4.8
158
159 These should work for OS X:
160
161 .. code-block:: bash
162
163 $ export CONAN_COMPILER=clang
164 $ export CONAN_COMPILER_VERSION=3.5
165
166 Finally, there are some tests that use conan to package Go-lang
167 libraries, so you might **need to install go-lang** in your computer and
168 add it to the path.
169
170 You can run the actual tests like this:
171
172 .. code-block:: bash
173
174 $ nosetests .
175
176
177 There are a couple of test attributes defined, as ``slow``, or ``golang`` that you can use
178 to filter the tests, and do not execute them:
179
180 .. code-block:: bash
181
182 $ nosetests . -a !golang
183
184 A few minutes later it should print ``OK``:
185
186 .. code-block:: bash
187
188 ............................................................................................
189 ----------------------------------------------------------------------
190 Ran 146 tests in 50.993s
191
192 OK
193
194 To run specific tests, you can specify the test name too, something like:
195
196 .. code-block:: bash
197
198 $ nosetests conans.test.command.config_install_test:ConfigInstallTest.install_file_test --nocapture
199
200 The ``--nocapture`` argument can be useful to see some output that otherwise is captured by nosetests.
201
202 License
203 -------
204
205 `MIT LICENSE <./LICENSE.md>`__
206
207 .. |Build Status Master| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/master
208 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/master
209
210 .. |Build Status Develop| image:: https://conan-ci.jfrog.info/buildStatus/icon?job=ConanTestSuite/develop
211 :target: https://conan-ci.jfrog.info/job/ConanTestSuite/job/develop
212
213 .. |Master coverage| image:: https://codecov.io/gh/conan-io/conan/branch/master/graph/badge.svg
214 :target: https://codecov.io/gh/conan-io/conan/branch/master
215
216 .. |Develop coverage| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graph/badge.svg
217 :target: https://codecov.io/gh/conan-io/conan/branch/develop
218
219 .. |Coverage graph| image:: https://codecov.io/gh/conan-io/conan/branch/develop/graphs/tree.svg
220 :height: 50px
221 :width: 50 px
222 :alt: Conan develop coverage
223
224 .. _`pip docs`: https://pip.pypa.io/en/stable/installing/
225
226 .. _`brew homepage`: http://brew.sh/
227
[end of README.rst]
[start of conans/client/generators/boostbuild.py]
1
2 """
3 Boost Build Conan Generator
4
5 This is a simple project-root.jam generator declaring all conan dependencies
6 as boost-build lib targets. This lets you link against them in your Jamfile
7 as a <library> property. Link against the "conant-deps" target.
8
9 """
10
11 from conans.model import Generator
12
13
14 def JamfileOutput(dep_cpp_info):
15 out = ''
16 for lib in dep_cpp_info.libs:
17 out += 'lib %s :\n' % lib
18 out += '\t: # requirements\n'
19 out += '\t<name>%s\n' % lib
20 out += ''.join('\t<search>%s\n' % x.replace("\\", "/") for x in dep_cpp_info.lib_paths)
21 out += '\t: # default-build\n'
22 out += '\t: # usage-requirements\n'
23 out += ''.join('\t<define>%s\n' % x for x in dep_cpp_info.defines)
24 out += ''.join('\t<include>%s\n' % x.replace("\\", "/") for x in dep_cpp_info.include_paths)
25 out += ''.join('\t<cxxflags>%s\n' % x for x in dep_cpp_info.cppflags)
26 out += ''.join('\t<cflags>%s\n' % x for x in dep_cpp_info.cflags)
27 out += ''.join('\t<ldflags>%s\n' % x for x in dep_cpp_info.sharedlinkflags)
28 out += '\t;\n\n'
29 return out
30
31
32 class BoostBuildGenerator(Generator):
33 @property
34 def filename(self):
35 return "project-root.jam"
36
37 @property
38 def content(self):
39 out = ''
40
41 for dep_name, dep_cpp_info in self.deps_build_info.dependencies:
42 out += JamfileOutput(dep_cpp_info)
43
44 out += 'alias conan-deps :\n'
45 for dep_name, dep_cpp_info in self.deps_build_info.dependencies:
46 for lib in dep_cpp_info.libs:
47 out += '\t%s\n' % lib
48 out += ';\n'
49
50 return out
51
52
[end of conans/client/generators/boostbuild.py]
[start of conans/client/generators/cmake_common.py]
1 _cmake_single_dep_vars = """set(CONAN_{dep}_ROOT{build_type} {deps.rootpath})
2 set(CONAN_INCLUDE_DIRS_{dep}{build_type} {deps.include_paths})
3 set(CONAN_LIB_DIRS_{dep}{build_type} {deps.lib_paths})
4 set(CONAN_BIN_DIRS_{dep}{build_type} {deps.bin_paths})
5 set(CONAN_RES_DIRS_{dep}{build_type} {deps.res_paths})
6 set(CONAN_SRC_DIRS_{dep}{build_type} {deps.src_paths})
7 set(CONAN_BUILD_DIRS_{dep}{build_type} {deps.build_paths})
8 set(CONAN_LIBS_{dep}{build_type} {deps.libs})
9 set(CONAN_DEFINES_{dep}{build_type} {deps.defines})
10 # COMPILE_DEFINITIONS are equal to CONAN_DEFINES without -D, for targets
11 set(CONAN_COMPILE_DEFINITIONS_{dep}{build_type} {deps.compile_definitions})
12
13 set(CONAN_C_FLAGS_{dep}{build_type} "{deps.cflags}")
14 set(CONAN_CXX_FLAGS_{dep}{build_type} "{deps.cppflags}")
15 set(CONAN_SHARED_LINKER_FLAGS_{dep}{build_type} "{deps.sharedlinkflags}")
16 set(CONAN_EXE_LINKER_FLAGS_{dep}{build_type} "{deps.exelinkflags}")
17
18 # For modern cmake targets we use the list variables (separated with ;)
19 set(CONAN_C_FLAGS_{dep}{build_type}_LIST "{deps.cflags_list}")
20 set(CONAN_CXX_FLAGS_{dep}{build_type}_LIST "{deps.cppflags_list}")
21 set(CONAN_SHARED_LINKER_FLAGS_{dep}{build_type}_LIST "{deps.sharedlinkflags_list}")
22 set(CONAN_EXE_LINKER_FLAGS_{dep}{build_type}_LIST "{deps.exelinkflags_list}")
23
24 """
25
26
27 def _cmake_string_representation(value):
28 """Escapes the specified string for use in a CMake command surrounded with double quotes
29 :param value the string to escape"""
30 return '"{0}"'.format(value.replace('\\', '\\\\')
31 .replace('$', '\\$')
32 .replace('"', '\\"'))
33
34
35 def _build_type_str(build_type):
36 if build_type:
37 return "_" + str(build_type).upper()
38 return ""
39
40
41 def cmake_user_info_vars(deps_user_info):
42 lines = []
43 for dep, the_vars in deps_user_info.items():
44 for name, value in the_vars.vars.items():
45 lines.append('set(CONAN_USER_%s_%s %s)'
46 % (dep.upper(), name, _cmake_string_representation(value)))
47 return "\n".join(lines)
48
49
50 def cmake_dependency_vars(name, deps, build_type=""):
51 build_type = _build_type_str(build_type)
52 return _cmake_single_dep_vars.format(dep=name.upper(), deps=deps, build_type=build_type)
53
54
55 _cmake_package_info = """set(CONAN_PACKAGE_NAME {name})
56 set(CONAN_PACKAGE_VERSION {version})
57 """
58
59
60 def cmake_package_info(name, version):
61 return _cmake_package_info.format(name=name, version=version)
62
63
64 def cmake_settings_info(settings):
65 settings_info = ""
66 for item in settings.items():
67 key, value = item
68 name = "CONAN_SETTINGS_%s" % key.upper().replace(".", "_")
69 settings_info += "set({key} {value})\n".format(key=name,
70 value=_cmake_string_representation(value))
71 return settings_info
72
73
74 def cmake_dependencies(dependencies, build_type=""):
75 build_type = _build_type_str(build_type)
76 dependencies = " ".join(dependencies)
77 return "set(CONAN_DEPENDENCIES{build_type} {dependencies})".format(dependencies=dependencies,
78 build_type=build_type)
79
80
81 _cmake_multi_dep_vars = """{cmd_line_args}
82 set(CONAN_INCLUDE_DIRS{build_type} {deps.include_paths} ${{CONAN_INCLUDE_DIRS{build_type}}})
83 set(CONAN_LIB_DIRS{build_type} {deps.lib_paths} ${{CONAN_LIB_DIRS{build_type}}})
84 set(CONAN_BIN_DIRS{build_type} {deps.bin_paths} ${{CONAN_BIN_DIRS{build_type}}})
85 set(CONAN_RES_DIRS{build_type} {deps.res_paths} ${{CONAN_RES_DIRS{build_type}}})
86 set(CONAN_LIBS{build_type} {deps.libs} ${{CONAN_LIBS{build_type}}})
87 set(CONAN_DEFINES{build_type} {deps.defines} ${{CONAN_DEFINES{build_type}}})
88 set(CONAN_CMAKE_MODULE_PATH{build_type} {deps.build_paths} ${{CONAN_CMAKE_MODULE_PATH{build_type}}})
89
90 set(CONAN_CXX_FLAGS{build_type} "{deps.cppflags} ${{CONAN_CXX_FLAGS{build_type}}}")
91 set(CONAN_SHARED_LINKER_FLAGS{build_type} "{deps.sharedlinkflags} ${{CONAN_SHARED_LINKER_FLAGS{build_type}}}")
92 set(CONAN_EXE_LINKER_FLAGS{build_type} "{deps.exelinkflags} ${{CONAN_EXE_LINKER_FLAGS{build_type}}}")
93 set(CONAN_C_FLAGS{build_type} "{deps.cflags} ${{CONAN_C_FLAGS{build_type}}}")
94 """
95
96
97 def cmake_global_vars(deps, build_type=""):
98 if not build_type:
99 cmd_line_args = """# Storing original command line args (CMake helper) flags
100 set(CONAN_CMD_CXX_FLAGS ${CONAN_CXX_FLAGS})
101
102 set(CONAN_CMD_SHARED_LINKER_FLAGS ${CONAN_SHARED_LINKER_FLAGS})
103 set(CONAN_CMD_C_FLAGS ${CONAN_C_FLAGS})
104 # Defining accumulated conan variables for all deps
105 """
106 else:
107 cmd_line_args = ""
108 return _cmake_multi_dep_vars.format(cmd_line_args=cmd_line_args,
109 deps=deps, build_type=_build_type_str(build_type))
110
111
112 _target_template = """
113 conan_package_library_targets("${{CONAN_LIBS_{uname}}}" "${{CONAN_LIB_DIRS_{uname}}}"
114 CONAN_PACKAGE_TARGETS_{uname} "{deps}" "" {pkg_name})
115 conan_package_library_targets("${{CONAN_LIBS_{uname}_DEBUG}}" "${{CONAN_LIB_DIRS_{uname}_DEBUG}}"
116 CONAN_PACKAGE_TARGETS_{uname}_DEBUG "{deps}" "debug" {pkg_name})
117 conan_package_library_targets("${{CONAN_LIBS_{uname}_RELEASE}}" "${{CONAN_LIB_DIRS_{uname}_RELEASE}}"
118 CONAN_PACKAGE_TARGETS_{uname}_RELEASE "{deps}" "release" {pkg_name})
119
120 add_library({name} INTERFACE IMPORTED)
121
122 # Property INTERFACE_LINK_FLAGS do not work, necessary to add to INTERFACE_LINK_LIBRARIES
123 set_property(TARGET {name} PROPERTY INTERFACE_LINK_LIBRARIES ${{CONAN_PACKAGE_TARGETS_{uname}}} ${{CONAN_SHARED_LINKER_FLAGS_{uname}_LIST}} ${{CONAN_EXE_LINKER_FLAGS_{uname}_LIST}}
124 $<$<CONFIG:Release>:${{CONAN_PACKAGE_TARGETS_{uname}_RELEASE}} ${{CONAN_SHARED_LINKER_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_EXE_LINKER_FLAGS_{uname}_RELEASE_LIST}}>
125 $<$<CONFIG:RelWithDebInfo>:${{CONAN_PACKAGE_TARGETS_{uname}_RELEASE}} ${{CONAN_SHARED_LINKER_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_EXE_LINKER_FLAGS_{uname}_RELEASE_LIST}}>
126 $<$<CONFIG:MinSizeRel>:${{CONAN_PACKAGE_TARGETS_{uname}_RELEASE}} ${{CONAN_SHARED_LINKER_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_EXE_LINKER_FLAGS_{uname}_RELEASE_LIST}}>
127 $<$<CONFIG:Debug>:${{CONAN_PACKAGE_TARGETS_{uname}_DEBUG}} ${{CONAN_SHARED_LINKER_FLAGS_{uname}_DEBUG_LIST}} ${{CONAN_EXE_LINKER_FLAGS_{uname}_DEBUG_LIST}}>
128 {deps})
129 set_property(TARGET {name} PROPERTY INTERFACE_INCLUDE_DIRECTORIES ${{CONAN_INCLUDE_DIRS_{uname}}}
130 $<$<CONFIG:Release>:${{CONAN_INCLUDE_DIRS_{uname}_RELEASE}}>
131 $<$<CONFIG:RelWithDebInfo>:${{CONAN_INCLUDE_DIRS_{uname}_RELEASE}}>
132 $<$<CONFIG:MinSizeRel>:${{CONAN_INCLUDE_DIRS_{uname}_RELEASE}}>
133 $<$<CONFIG:Debug>:${{CONAN_INCLUDE_DIRS_{uname}_DEBUG}}>)
134 set_property(TARGET {name} PROPERTY INTERFACE_COMPILE_DEFINITIONS ${{CONAN_COMPILE_DEFINITIONS_{uname}}}
135 $<$<CONFIG:Release>:${{CONAN_COMPILE_DEFINITIONS_{uname}_RELEASE}}>
136 $<$<CONFIG:RelWithDebInfo>:${{CONAN_COMPILE_DEFINITIONS_{uname}_RELEASE}}>
137 $<$<CONFIG:MinSizeRel>:${{CONAN_COMPILE_DEFINITIONS_{uname}_RELEASE}}>
138 $<$<CONFIG:Debug>:${{CONAN_COMPILE_DEFINITIONS_{uname}_DEBUG}}>)
139 set_property(TARGET {name} PROPERTY INTERFACE_COMPILE_OPTIONS ${{CONAN_C_FLAGS_{uname}_LIST}} ${{CONAN_CXX_FLAGS_{uname}_LIST}}
140 $<$<CONFIG:Release>:${{CONAN_C_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_CXX_FLAGS_{uname}_RELEASE_LIST}}>
141 $<$<CONFIG:RelWithDebInfo>:${{CONAN_C_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_CXX_FLAGS_{uname}_RELEASE_LIST}}>
142 $<$<CONFIG:MinSizeRel>:${{CONAN_C_FLAGS_{uname}_RELEASE_LIST}} ${{CONAN_CXX_FLAGS_{uname}_RELEASE_LIST}}>
143 $<$<CONFIG:Debug>:${{CONAN_C_FLAGS_{uname}_DEBUG_LIST}} ${{CONAN_CXX_FLAGS_{uname}_DEBUG_LIST}}>)
144 """
145
146
147 def generate_targets_section(dependencies):
148 section = []
149 section.append("\n### Definition of macros and functions ###\n")
150 section.append('macro(conan_define_targets)\n'
151 ' if(${CMAKE_VERSION} VERSION_LESS "3.1.2")\n'
152 ' message(FATAL_ERROR "TARGETS not supported by your CMake version!")\n'
153 ' endif() # CMAKE > 3.x\n'
154 ' set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${CONAN_CMD_CXX_FLAGS}")\n'
155 ' set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${CONAN_CMD_C_FLAGS}")\n'
156 ' set(CMAKE_SHARED_LINKER_FLAGS "${CMAKE_SHARED_LINKER_FLAGS} ${CONAN_CMD_SHARED_LINKER_FLAGS}")\n')
157
158 for dep_name, dep_info in dependencies:
159 use_deps = ["CONAN_PKG::%s" % d for d in dep_info.public_deps]
160 deps = "" if not use_deps else " ".join(use_deps)
161 section.append(_target_template.format(name="CONAN_PKG::%s" % dep_name, deps=deps,
162 uname=dep_name.upper(), pkg_name=dep_name))
163
164 all_targets = " ".join(["CONAN_PKG::%s" % name for name, _ in dependencies])
165 section.append(' set(CONAN_TARGETS %s)\n' % all_targets)
166 section.append('endmacro()\n')
167 return section
168
169
170 _cmake_common_macros = """
171
172 function(conan_find_libraries_abs_path libraries package_libdir libraries_abs_path)
173 foreach(_LIBRARY_NAME ${libraries})
174 unset(CONAN_FOUND_LIBRARY CACHE)
175 find_library(CONAN_FOUND_LIBRARY NAME ${_LIBRARY_NAME} PATHS ${package_libdir}
176 NO_DEFAULT_PATH NO_CMAKE_FIND_ROOT_PATH)
177 if(CONAN_FOUND_LIBRARY)
178 message(STATUS "Library ${_LIBRARY_NAME} found ${CONAN_FOUND_LIBRARY}")
179 set(CONAN_FULLPATH_LIBS ${CONAN_FULLPATH_LIBS} ${CONAN_FOUND_LIBRARY})
180 else()
181 message(STATUS "Library ${_LIBRARY_NAME} not found in package, might be system one")
182 set(CONAN_FULLPATH_LIBS ${CONAN_FULLPATH_LIBS} ${_LIBRARY_NAME})
183 endif()
184 endforeach()
185 unset(CONAN_FOUND_LIBRARY CACHE)
186 set(${libraries_abs_path} ${CONAN_FULLPATH_LIBS} PARENT_SCOPE)
187 endfunction()
188
189 function(conan_package_library_targets libraries package_libdir libraries_abs_path deps build_type package_name)
190 foreach(_LIBRARY_NAME ${libraries})
191 unset(CONAN_FOUND_LIBRARY CACHE)
192 find_library(CONAN_FOUND_LIBRARY NAME ${_LIBRARY_NAME} PATHS ${package_libdir}
193 NO_DEFAULT_PATH NO_CMAKE_FIND_ROOT_PATH)
194 if(CONAN_FOUND_LIBRARY)
195 message(STATUS "Library ${_LIBRARY_NAME} found ${CONAN_FOUND_LIBRARY}")
196 set(_LIB_NAME CONAN_LIB::${package_name}_${_LIBRARY_NAME}${build_type})
197 add_library(${_LIB_NAME} UNKNOWN IMPORTED)
198 set_target_properties(${_LIB_NAME} PROPERTIES IMPORTED_LOCATION ${CONAN_FOUND_LIBRARY})
199 string(REPLACE " " ";" deps_list "${deps}")
200 set_property(TARGET ${_LIB_NAME} PROPERTY INTERFACE_LINK_LIBRARIES ${deps_list})
201 set(CONAN_FULLPATH_LIBS ${CONAN_FULLPATH_LIBS} ${_LIB_NAME})
202 else()
203 message(STATUS "Library ${_LIBRARY_NAME} not found in package, might be system one")
204 set(CONAN_FULLPATH_LIBS ${CONAN_FULLPATH_LIBS} ${_LIBRARY_NAME})
205 endif()
206 endforeach()
207 unset(CONAN_FOUND_LIBRARY CACHE)
208 set(${libraries_abs_path} ${CONAN_FULLPATH_LIBS} PARENT_SCOPE)
209 endfunction()
210
211 macro(conan_set_libcxx)
212 if(DEFINED CONAN_LIBCXX)
213 message(STATUS "Conan: C++ stdlib: ${CONAN_LIBCXX}")
214 if(CONAN_COMPILER STREQUAL "clang" OR CONAN_COMPILER STREQUAL "apple-clang")
215 if(CONAN_LIBCXX STREQUAL "libstdc++" OR CONAN_LIBCXX STREQUAL "libstdc++11" )
216 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -stdlib=libstdc++")
217 elseif(CONAN_LIBCXX STREQUAL "libc++")
218 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -stdlib=libc++")
219 endif()
220 endif()
221 if(CONAN_COMPILER STREQUAL "sun-cc")
222 if(CONAN_LIBCXX STREQUAL "libCstd")
223 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -library=Cstd")
224 elseif(CONAN_LIBCXX STREQUAL "libstdcxx")
225 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -library=stdcxx4")
226 elseif(CONAN_LIBCXX STREQUAL "libstlport")
227 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -library=stlport4")
228 elseif(CONAN_LIBCXX STREQUAL "libstdc++")
229 set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -library=stdcpp")
230 endif()
231 endif()
232 if(CONAN_LIBCXX STREQUAL "libstdc++11")
233 add_definitions(-D_GLIBCXX_USE_CXX11_ABI=1)
234 elseif(CONAN_LIBCXX STREQUAL "libstdc++")
235 add_definitions(-D_GLIBCXX_USE_CXX11_ABI=0)
236 endif()
237 endif()
238 endmacro()
239
240 macro(conan_set_std)
241 # Do not warn "Manually-specified variables were not used by the project"
242 set(ignorevar "${CONAN_STD_CXX_FLAG}${CONAN_CMAKE_CXX_STANDARD}${CONAN_CMAKE_CXX_EXTENSIONS}")
243 if (CMAKE_VERSION VERSION_LESS "3.1" OR
244 (CMAKE_VERSION VERSION_LESS "3.12" AND ("${CONAN_CMAKE_CXX_STANDARD}" STREQUAL "20" OR "${CONAN_CMAKE_CXX_STANDARD}" STREQUAL "gnu20")))
245 if(CONAN_STD_CXX_FLAG)
246 message(STATUS "Conan setting CXX_FLAGS flags: ${CONAN_STD_CXX_FLAG}")
247 set(CMAKE_CXX_FLAGS "${CONAN_STD_CXX_FLAG} ${CMAKE_CXX_FLAGS}")
248 endif()
249 else()
250 if(CONAN_CMAKE_CXX_STANDARD)
251 message(STATUS "Conan setting CPP STANDARD: ${CONAN_CMAKE_CXX_STANDARD} WITH EXTENSIONS ${CONAN_CMAKE_CXX_EXTENSIONS}")
252 set(CMAKE_CXX_STANDARD ${CONAN_CMAKE_CXX_STANDARD})
253 set(CMAKE_CXX_EXTENSIONS ${CONAN_CMAKE_CXX_EXTENSIONS})
254 endif()
255 endif()
256 endmacro()
257
258 macro(conan_set_rpath)
259 if(APPLE)
260 # https://cmake.org/Wiki/CMake_RPATH_handling
261 # CONAN GUIDE: All generated libraries should have the id and dependencies to other
262 # dylibs without path, just the name, EX:
263 # libMyLib1.dylib:
264 # libMyLib1.dylib (compatibility version 0.0.0, current version 0.0.0)
265 # libMyLib0.dylib (compatibility version 0.0.0, current version 0.0.0)
266 # /usr/lib/libc++.1.dylib (compatibility version 1.0.0, current version 120.0.0)
267 # /usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1197.1.1)
268 set(CMAKE_SKIP_RPATH 1) # AVOID RPATH FOR *.dylib, ALL LIBS BETWEEN THEM AND THE EXE
269 # SHOULD BE ON THE LINKER RESOLVER PATH (./ IS ONE OF THEM)
270 # Policy CMP0068
271 # We want the old behavior, in CMake >= 3.9 CMAKE_SKIP_RPATH won't affect the install_name in OSX
272 set(CMAKE_INSTALL_NAME_DIR "")
273 endif()
274 endmacro()
275
276 macro(conan_set_fpic)
277 if(DEFINED CONAN_CMAKE_POSITION_INDEPENDENT_CODE)
278 message(STATUS "Conan: Adjusting fPIC flag (${CONAN_CMAKE_POSITION_INDEPENDENT_CODE})")
279 set(CMAKE_POSITION_INDEPENDENT_CODE ${CONAN_CMAKE_POSITION_INDEPENDENT_CODE})
280 endif()
281 endmacro()
282
283 macro(conan_output_dirs_setup)
284 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR}/bin)
285 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_RELEASE ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
286 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_RELWITHDEBINFO ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
287 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_MINSIZEREL ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
288 set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_DEBUG ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
289
290 set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR}/lib)
291 set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY_RELEASE ${CMAKE_ARCHIVE_OUTPUT_DIRECTORY})
292 set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY_RELWITHDEBINFO ${CMAKE_ARCHIVE_OUTPUT_DIRECTORY})
293 set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY_MINSIZEREL ${CMAKE_ARCHIVE_OUTPUT_DIRECTORY})
294 set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY_DEBUG ${CMAKE_ARCHIVE_OUTPUT_DIRECTORY})
295
296 set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_CURRENT_BINARY_DIR}/lib)
297 set(CMAKE_LIBRARY_OUTPUT_DIRECTORY_RELEASE ${CMAKE_LIBRARY_OUTPUT_DIRECTORY})
298 set(CMAKE_LIBRARY_OUTPUT_DIRECTORY_RELWITHDEBINFO ${CMAKE_LIBRARY_OUTPUT_DIRECTORY})
299 set(CMAKE_LIBRARY_OUTPUT_DIRECTORY_MINSIZEREL ${CMAKE_LIBRARY_OUTPUT_DIRECTORY})
300 set(CMAKE_LIBRARY_OUTPUT_DIRECTORY_DEBUG ${CMAKE_LIBRARY_OUTPUT_DIRECTORY})
301 endmacro()
302
303 macro(conan_split_version VERSION_STRING MAJOR MINOR)
304 #make a list from the version string
305 string(REPLACE "." ";" VERSION_LIST "${VERSION_STRING}")
306
307 #write output values
308 list(LENGTH VERSION_LIST _version_len)
309 list(GET VERSION_LIST 0 ${MAJOR})
310 if(${_version_len} GREATER 1)
311 list(GET VERSION_LIST 1 ${MINOR})
312 endif()
313 endmacro()
314
315 macro(conan_error_compiler_version)
316 message(FATAL_ERROR "Incorrect '${CONAN_COMPILER}' version 'compiler.version=${CONAN_COMPILER_VERSION}'"
317 " is not the one detected by CMake: '${CMAKE_CXX_COMPILER_ID}=" ${VERSION_MAJOR}.${VERSION_MINOR}')
318 endmacro()
319
320 set(_CONAN_CURRENT_DIR ${CMAKE_CURRENT_LIST_DIR})
321 function(conan_get_compiler CONAN_INFO_COMPILER CONAN_INFO_COMPILER_VERSION)
322 MESSAGE(STATUS "Current conanbuildinfo.cmake directory: " ${_CONAN_CURRENT_DIR})
323 if(NOT EXISTS ${_CONAN_CURRENT_DIR}/conaninfo.txt)
324 message(STATUS "WARN: conaninfo.txt not found")
325 return()
326 endif()
327
328 file (READ "${_CONAN_CURRENT_DIR}/conaninfo.txt" CONANINFO)
329
330 string(REGEX MATCH "compiler=([-A-Za-z0-9_ ]+)" _MATCHED ${CONANINFO})
331 if(DEFINED CMAKE_MATCH_1)
332 string(STRIP "${CMAKE_MATCH_1}" _CONAN_INFO_COMPILER)
333 set(${CONAN_INFO_COMPILER} ${_CONAN_INFO_COMPILER} PARENT_SCOPE)
334 endif()
335
336 string(REGEX MATCH "compiler.version=([-A-Za-z0-9_.]+)" _MATCHED ${CONANINFO})
337 if(DEFINED CMAKE_MATCH_1)
338 string(STRIP "${CMAKE_MATCH_1}" _CONAN_INFO_COMPILER_VERSION)
339 set(${CONAN_INFO_COMPILER_VERSION} ${_CONAN_INFO_COMPILER_VERSION} PARENT_SCOPE)
340 endif()
341 endfunction()
342
343 function(check_compiler_version)
344 conan_split_version(${CMAKE_CXX_COMPILER_VERSION} VERSION_MAJOR VERSION_MINOR)
345 if(CMAKE_CXX_COMPILER_ID MATCHES MSVC)
346 # https://cmake.org/cmake/help/v3.2/variable/MSVC_VERSION.html
347 if( (CONAN_COMPILER_VERSION STREQUAL "14" AND NOT VERSION_MAJOR STREQUAL "19") OR
348 (CONAN_COMPILER_VERSION STREQUAL "12" AND NOT VERSION_MAJOR STREQUAL "18") OR
349 (CONAN_COMPILER_VERSION STREQUAL "11" AND NOT VERSION_MAJOR STREQUAL "17") OR
350 (CONAN_COMPILER_VERSION STREQUAL "10" AND NOT VERSION_MAJOR STREQUAL "16") OR
351 (CONAN_COMPILER_VERSION STREQUAL "9" AND NOT VERSION_MAJOR STREQUAL "15") OR
352 (CONAN_COMPILER_VERSION STREQUAL "8" AND NOT VERSION_MAJOR STREQUAL "14") OR
353 (CONAN_COMPILER_VERSION STREQUAL "7" AND NOT VERSION_MAJOR STREQUAL "13") OR
354 (CONAN_COMPILER_VERSION STREQUAL "6" AND NOT VERSION_MAJOR STREQUAL "12") )
355 conan_error_compiler_version()
356 endif()
357 elseif(CONAN_COMPILER STREQUAL "gcc")
358 set(_CHECK_VERSION ${VERSION_MAJOR}.${VERSION_MINOR})
359 if(NOT ${CONAN_COMPILER_VERSION} VERSION_LESS 5.0)
360 message(STATUS "Conan: Compiler GCC>=5, checking major version ${CONAN_COMPILER_VERSION}")
361 conan_split_version(${CONAN_COMPILER_VERSION} CONAN_COMPILER_MAJOR CONAN_COMPILER_MINOR)
362 if("${CONAN_COMPILER_MINOR}" STREQUAL "")
363 set(_CHECK_VERSION ${VERSION_MAJOR})
364 endif()
365 endif()
366 message(STATUS "Conan: Checking correct version: ${_CHECK_VERSION}")
367 if(NOT ${_CHECK_VERSION} VERSION_EQUAL CONAN_COMPILER_VERSION)
368 conan_error_compiler_version()
369 endif()
370 elseif(CONAN_COMPILER STREQUAL "clang")
371 set(_CHECK_VERSION ${VERSION_MAJOR}.${VERSION_MINOR})
372 if(NOT ${CONAN_COMPILER_VERSION} VERSION_LESS 8.0)
373 message(STATUS "Conan: Compiler Clang>=8, checking major version ${CONAN_COMPILER_VERSION}")
374 conan_split_version(${CONAN_COMPILER_VERSION} CONAN_COMPILER_MAJOR CONAN_COMPILER_MINOR)
375 if("${CONAN_COMPILER_MINOR}" STREQUAL "")
376 set(_CHECK_VERSION ${VERSION_MAJOR})
377 endif()
378 endif()
379 message(STATUS "Conan: Checking correct version: ${_CHECK_VERSION}")
380 if(NOT ${_CHECK_VERSION} VERSION_EQUAL CONAN_COMPILER_VERSION)
381 conan_error_compiler_version()
382 endif()
383 elseif(CONAN_COMPILER STREQUAL "apple-clang" OR CONAN_COMPILER STREQUAL "sun-cc")
384 conan_split_version(${CONAN_COMPILER_VERSION} CONAN_COMPILER_MAJOR CONAN_COMPILER_MINOR)
385 if(NOT ${VERSION_MAJOR}.${VERSION_MINOR} VERSION_EQUAL ${CONAN_COMPILER_MAJOR}.${CONAN_COMPILER_MINOR})
386 conan_error_compiler_version()
387 endif()
388 else()
389 message(STATUS "WARN: Unknown compiler '${CONAN_COMPILER}', skipping the version check...")
390 endif()
391 endfunction()
392
393 function(conan_check_compiler)
394 if(NOT DEFINED CMAKE_CXX_COMPILER_ID)
395 if(DEFINED CMAKE_C_COMPILER_ID)
396 message(STATUS "This project seems to be plain C, using '${CMAKE_C_COMPILER_ID}' compiler")
397 set(CMAKE_CXX_COMPILER_ID ${CMAKE_C_COMPILER_ID})
398 set(CMAKE_CXX_COMPILER_VERSION ${CMAKE_C_COMPILER_VERSION})
399 else()
400 message(FATAL_ERROR "This project seems to be plain C, but no compiler defined")
401 endif()
402 endif()
403 if(CONAN_DISABLE_CHECK_COMPILER)
404 message(STATUS "WARN: Disabled conan compiler checks")
405 return()
406 endif()
407 if(NOT CMAKE_CXX_COMPILER_ID AND NOT CMAKE_C_COMPILER_ID)
408 # This use case happens when compiler is not identified by CMake, but the compilers are there and work
409 message(STATUS "*** WARN: CMake was not able to identify a C or C++ compiler ***")
410 message(STATUS "*** WARN: Disabling compiler checks. Please make sure your settings match your environment ***")
411 return()
412 endif()
413 if(NOT DEFINED CONAN_COMPILER)
414 conan_get_compiler(CONAN_COMPILER CONAN_COMPILER_VERSION)
415 if(NOT DEFINED CONAN_COMPILER)
416 message(STATUS "WARN: CONAN_COMPILER variable not set, please make sure yourself that "
417 "your compiler and version matches your declared settings")
418 return()
419 endif()
420 endif()
421
422 if(NOT CMAKE_HOST_SYSTEM_NAME STREQUAL ${CMAKE_SYSTEM_NAME})
423 set(CROSS_BUILDING 1)
424 endif()
425
426 # If using VS, verify toolset
427 if (CONAN_COMPILER STREQUAL "Visual Studio")
428 if (CONAN_SETTINGS_COMPILER_TOOLSET MATCHES "LLVM" OR
429 CONAN_SETTINGS_COMPILER_TOOLSET MATCHES "clang")
430 set(EXPECTED_CMAKE_CXX_COMPILER_ID "Clang")
431 elseif (CONAN_SETTINGS_COMPILER_TOOLSET MATCHES "Intel")
432 set(EXPECTED_CMAKE_CXX_COMPILER_ID "Intel")
433 else()
434 set(EXPECTED_CMAKE_CXX_COMPILER_ID "MSVC")
435 endif()
436
437 if (NOT CMAKE_CXX_COMPILER_ID MATCHES ${EXPECTED_CMAKE_CXX_COMPILER_ID})
438 message(FATAL_ERROR "Incorrect '${CONAN_COMPILER}'. Toolset specifies compiler as '${EXPECTED_CMAKE_CXX_COMPILER_ID}' "
439 "but CMake detected '${CMAKE_CXX_COMPILER_ID}'")
440 endif()
441
442 # Avoid checks when cross compiling, apple-clang crashes because its APPLE but not apple-clang
443 # Actually CMake is detecting "clang" when you are using apple-clang, only if CMP0025 is set to NEW will detect apple-clang
444 elseif((CONAN_COMPILER STREQUAL "gcc" AND NOT CMAKE_CXX_COMPILER_ID MATCHES "GNU") OR
445 (CONAN_COMPILER STREQUAL "apple-clang" AND NOT CROSS_BUILDING AND (NOT APPLE OR NOT CMAKE_CXX_COMPILER_ID MATCHES "Clang")) OR
446 (CONAN_COMPILER STREQUAL "clang" AND NOT CMAKE_CXX_COMPILER_ID MATCHES "Clang") OR
447 (CONAN_COMPILER STREQUAL "sun-cc" AND NOT CMAKE_CXX_COMPILER_ID MATCHES "SunPro") )
448 message(FATAL_ERROR "Incorrect '${CONAN_COMPILER}', is not the one detected by CMake: '${CMAKE_CXX_COMPILER_ID}'")
449 endif()
450
451
452 if(NOT DEFINED CONAN_COMPILER_VERSION)
453 message(STATUS "WARN: CONAN_COMPILER_VERSION variable not set, please make sure yourself "
454 "that your compiler version matches your declared settings")
455 return()
456 endif()
457 check_compiler_version()
458 endfunction()
459
460 macro(conan_set_flags build_type)
461 set(CMAKE_CXX_FLAGS${build_type} "${CMAKE_CXX_FLAGS${build_type}} ${CONAN_CXX_FLAGS${build_type}}")
462 set(CMAKE_C_FLAGS${build_type} "${CMAKE_C_FLAGS${build_type}} ${CONAN_C_FLAGS${build_type}}")
463 set(CMAKE_SHARED_LINKER_FLAGS${build_type} "${CMAKE_SHARED_LINKER_FLAGS${build_type}} ${CONAN_SHARED_LINKER_FLAGS${build_type}}")
464 set(CMAKE_EXE_LINKER_FLAGS${build_type} "${CMAKE_EXE_LINKER_FLAGS${build_type}} ${CONAN_EXE_LINKER_FLAGS${build_type}}")
465 endmacro()
466
467 macro(conan_global_flags)
468 if(CONAN_SYSTEM_INCLUDES)
469 include_directories(SYSTEM ${CONAN_INCLUDE_DIRS}
470 "$<$<CONFIG:Release>:${CONAN_INCLUDE_DIRS_RELEASE}>"
471 "$<$<CONFIG:RelWithDebInfo>:${CONAN_INCLUDE_DIRS_RELEASE}>"
472 "$<$<CONFIG:MinSizeRel>:${CONAN_INCLUDE_DIRS_RELEASE}>"
473 "$<$<CONFIG:Debug>:${CONAN_INCLUDE_DIRS_DEBUG}>")
474 else()
475 include_directories(${CONAN_INCLUDE_DIRS}
476 "$<$<CONFIG:Release>:${CONAN_INCLUDE_DIRS_RELEASE}>"
477 "$<$<CONFIG:RelWithDebInfo>:${CONAN_INCLUDE_DIRS_RELEASE}>"
478 "$<$<CONFIG:MinSizeRel>:${CONAN_INCLUDE_DIRS_RELEASE}>"
479 "$<$<CONFIG:Debug>:${CONAN_INCLUDE_DIRS_DEBUG}>")
480 endif()
481
482 link_directories(${CONAN_LIB_DIRS})
483
484 conan_find_libraries_abs_path("${CONAN_LIBS_DEBUG}" "${CONAN_LIB_DIRS_DEBUG}"
485 CONAN_LIBS_DEBUG)
486 conan_find_libraries_abs_path("${CONAN_LIBS_RELEASE}" "${CONAN_LIB_DIRS_RELEASE}"
487 CONAN_LIBS_RELEASE)
488
489 add_compile_options(${CONAN_DEFINES}
490 "$<$<CONFIG:Debug>:${CONAN_DEFINES_DEBUG}>"
491 "$<$<CONFIG:Release>:${CONAN_DEFINES_RELEASE}>"
492 "$<$<CONFIG:RelWithDebInfo>:${CONAN_DEFINES_RELEASE}>"
493 "$<$<CONFIG:MinSizeRel>:${CONAN_DEFINES_RELEASE}>")
494
495 conan_set_flags("")
496 conan_set_flags("_RELEASE")
497 conan_set_flags("_DEBUG")
498
499 endmacro()
500
501 macro(conan_target_link_libraries target)
502 if(CONAN_TARGETS)
503 target_link_libraries(${target} ${CONAN_TARGETS})
504 else()
505 target_link_libraries(${target} ${CONAN_LIBS})
506 foreach(_LIB ${CONAN_LIBS_RELEASE})
507 target_link_libraries(${target} optimized ${_LIB})
508 endforeach()
509 foreach(_LIB ${CONAN_LIBS_DEBUG})
510 target_link_libraries(${target} debug ${_LIB})
511 endforeach()
512 endif()
513 endmacro()
514 """
515
516 cmake_macros = """
517 macro(conan_basic_setup)
518 set(options TARGETS NO_OUTPUT_DIRS SKIP_RPATH KEEP_RPATHS SKIP_STD SKIP_FPIC)
519 cmake_parse_arguments(ARGUMENTS "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN} )
520 if(CONAN_EXPORTED)
521 message(STATUS "Conan: called by CMake conan helper")
522 endif()
523 if(CONAN_IN_LOCAL_CACHE)
524 message(STATUS "Conan: called inside local cache")
525 endif()
526 conan_check_compiler()
527 if(NOT ARGUMENTS_NO_OUTPUT_DIRS)
528 conan_output_dirs_setup()
529 endif()
530 conan_set_find_library_paths()
531 if(NOT ARGUMENTS_TARGETS)
532 message(STATUS "Conan: Using cmake global configuration")
533 conan_global_flags()
534 else()
535 message(STATUS "Conan: Using cmake targets configuration")
536 conan_define_targets()
537 endif()
538 if(ARGUMENTS_SKIP_RPATH)
539 # Change by "DEPRECATION" or "SEND_ERROR" when we are ready
540 message(WARNING "Conan: SKIP_RPATH is deprecated, it has been renamed to KEEP_RPATHS")
541 endif()
542 if(NOT ARGUMENTS_SKIP_RPATH AND NOT ARGUMENTS_KEEP_RPATHS)
543 # Parameter has renamed, but we keep the compatibility with old SKIP_RPATH
544 message(STATUS "Conan: Adjusting default RPATHs Conan policies")
545 conan_set_rpath()
546 endif()
547 if(NOT ARGUMENTS_SKIP_STD)
548 message(STATUS "Conan: Adjusting language standard")
549 conan_set_std()
550 endif()
551 if(NOT ARGUMENTS_SKIP_FPIC)
552 conan_set_fpic()
553 endif()
554 conan_set_vs_runtime()
555 conan_set_libcxx()
556 conan_set_find_paths()
557 endmacro()
558
559 macro(conan_set_find_paths)
560 # CMAKE_MODULE_PATH does not have Debug/Release config, but there are variables
561 # CONAN_CMAKE_MODULE_PATH_DEBUG to be used by the consumer
562 # CMake can find findXXX.cmake files in the root of packages
563 set(CMAKE_MODULE_PATH ${CONAN_CMAKE_MODULE_PATH} ${CMAKE_MODULE_PATH})
564
565 # Make find_package() to work
566 set(CMAKE_PREFIX_PATH ${CONAN_CMAKE_MODULE_PATH} ${CMAKE_PREFIX_PATH})
567
568 # Set the find root path (cross build)
569 set(CMAKE_FIND_ROOT_PATH ${CONAN_CMAKE_FIND_ROOT_PATH} ${CMAKE_FIND_ROOT_PATH})
570 if(CONAN_CMAKE_FIND_ROOT_PATH_MODE_PROGRAM)
571 set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM ${CONAN_CMAKE_FIND_ROOT_PATH_MODE_PROGRAM})
572 endif()
573 if(CONAN_CMAKE_FIND_ROOT_PATH_MODE_LIBRARY)
574 set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ${CONAN_CMAKE_FIND_ROOT_PATH_MODE_LIBRARY})
575 endif()
576 if(CONAN_CMAKE_FIND_ROOT_PATH_MODE_INCLUDE)
577 set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ${CONAN_CMAKE_FIND_ROOT_PATH_MODE_INCLUDE})
578 endif()
579 endmacro()
580
581 macro(conan_set_find_library_paths)
582 # CMAKE_INCLUDE_PATH, CMAKE_LIBRARY_PATH does not have Debug/Release config, but there are variables
583 # CONAN_INCLUDE_DIRS_DEBUG/RELEASE CONAN_LIB_DIRS_DEBUG/RELEASE to be used by the consumer
584 # For find_library
585 set(CMAKE_INCLUDE_PATH ${CONAN_INCLUDE_DIRS} ${CMAKE_INCLUDE_PATH})
586 set(CMAKE_LIBRARY_PATH ${CONAN_LIB_DIRS} ${CMAKE_LIBRARY_PATH})
587 endmacro()
588
589 macro(conan_set_vs_runtime)
590 if(CONAN_LINK_RUNTIME)
591 foreach(flag CMAKE_C_FLAGS_RELEASE CMAKE_CXX_FLAGS_RELEASE
592 CMAKE_C_FLAGS_RELWITHDEBINFO CMAKE_CXX_FLAGS_RELWITHDEBINFO
593 CMAKE_C_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_MINSIZEREL)
594 if(DEFINED ${flag})
595 string(REPLACE "/MD" ${CONAN_LINK_RUNTIME} ${flag} "${${flag}}")
596 endif()
597 endforeach()
598 foreach(flag CMAKE_C_FLAGS_DEBUG CMAKE_CXX_FLAGS_DEBUG)
599 if(DEFINED ${flag})
600 string(REPLACE "/MDd" ${CONAN_LINK_RUNTIME} ${flag} "${${flag}}")
601 endif()
602 endforeach()
603 endif()
604 endmacro()
605
606 macro(conan_flags_setup)
607 # Macro maintained for backwards compatibility
608 conan_set_find_library_paths()
609 conan_global_flags()
610 conan_set_rpath()
611 conan_set_vs_runtime()
612 conan_set_libcxx()
613 endmacro()
614
615 """ + _cmake_common_macros
616
617
618 cmake_macros_multi = """
619 if(EXISTS ${CMAKE_CURRENT_LIST_DIR}/conanbuildinfo_release.cmake)
620 include(${CMAKE_CURRENT_LIST_DIR}/conanbuildinfo_release.cmake)
621 else()
622 message(FATAL_ERROR "No conanbuildinfo_release.cmake, please install the Release conf first")
623 endif()
624 if(EXISTS ${CMAKE_CURRENT_LIST_DIR}/conanbuildinfo_debug.cmake)
625 include(${CMAKE_CURRENT_LIST_DIR}/conanbuildinfo_debug.cmake)
626 else()
627 message(FATAL_ERROR "No conanbuildinfo_debug.cmake, please install the Debug conf first")
628 endif()
629
630 macro(conan_basic_setup)
631 set(options TARGETS)
632 cmake_parse_arguments(ARGUMENTS "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN} )
633 if(CONAN_EXPORTED)
634 message(STATUS "Conan: called by CMake conan helper")
635 endif()
636 if(CONAN_IN_LOCAL_CACHE)
637 message(STATUS "Conan: called inside local cache")
638 endif()
639 conan_check_compiler()
640 # conan_output_dirs_setup()
641 if(NOT ARGUMENTS_TARGETS)
642 message(STATUS "Conan: Using cmake global configuration")
643 conan_global_flags()
644 else()
645 message(STATUS "Conan: Using cmake targets configuration")
646 conan_define_targets()
647 endif()
648 conan_set_rpath()
649 conan_set_vs_runtime()
650 conan_set_libcxx()
651 conan_set_find_paths()
652 conan_set_fpic()
653 endmacro()
654
655 macro(conan_set_vs_runtime)
656 # This conan_set_vs_runtime is MORE opinionated than the regular one. It will
657 # Leave the defaults MD (MDd) or replace them with MT (MTd) but taking into account the
658 # debug, forcing MXd for debug builds. It will generate MSVCRT warnings if the dependencies
659 # are installed with "conan install" and the wrong build time.
660 if(CONAN_LINK_RUNTIME MATCHES "MT")
661 foreach(flag CMAKE_C_FLAGS_RELEASE CMAKE_CXX_FLAGS_RELEASE
662 CMAKE_C_FLAGS_RELWITHDEBINFO CMAKE_CXX_FLAGS_RELWITHDEBINFO
663 CMAKE_C_FLAGS_MINSIZEREL CMAKE_CXX_FLAGS_MINSIZEREL)
664 if(DEFINED ${flag})
665 string(REPLACE "/MD" "/MT" ${flag} "${${flag}}")
666 endif()
667 endforeach()
668 foreach(flag CMAKE_C_FLAGS_DEBUG CMAKE_CXX_FLAGS_DEBUG)
669 if(DEFINED ${flag})
670 string(REPLACE "/MDd" "/MTd" ${flag} "${${flag}}")
671 endif()
672 endforeach()
673 endif()
674 endmacro()
675
676 macro(conan_set_find_paths)
677 if(CMAKE_BUILD_TYPE)
678 if(${CMAKE_BUILD_TYPE} MATCHES "Debug")
679 set(CMAKE_PREFIX_PATH ${CONAN_CMAKE_MODULE_PATH_DEBUG} ${CMAKE_PREFIX_PATH})
680 set(CMAKE_MODULE_PATH ${CONAN_CMAKE_MODULE_PATH_DEBUG} ${CMAKE_MODULE_PATH})
681 else()
682 set(CMAKE_PREFIX_PATH ${CONAN_CMAKE_MODULE_PATH_RELEASE} ${CMAKE_PREFIX_PATH})
683 set(CMAKE_MODULE_PATH ${CONAN_CMAKE_MODULE_PATH_RELEASE} ${CMAKE_MODULE_PATH})
684 endif()
685 endif()
686 endmacro()
687 """ + _cmake_common_macros
688
[end of conans/client/generators/cmake_common.py]
[start of conans/client/generators/premake.py]
1 from conans.model import Generator
2 from conans.paths import BUILD_INFO_PREMAKE
3
4
5 class PremakeDeps(object):
6 def __init__(self, deps_cpp_info):
7 self.include_paths = ",\n".join('"%s"' % p.replace("\\", "/")
8 for p in deps_cpp_info.include_paths)
9 self.lib_paths = ",\n".join('"%s"' % p.replace("\\", "/")
10 for p in deps_cpp_info.lib_paths)
11 self.bin_paths = ",\n".join('"%s"' % p.replace("\\", "/")
12 for p in deps_cpp_info.bin_paths)
13 self.libs = ", ".join('"%s"' % p for p in deps_cpp_info.libs)
14 self.defines = ", ".join('"%s"' % p for p in deps_cpp_info.defines)
15 self.cppflags = ", ".join('"%s"' % p for p in deps_cpp_info.cppflags)
16 self.cflags = ", ".join('"%s"' % p for p in deps_cpp_info.cflags)
17 self.sharedlinkflags = ", ".join('"%s"' % p for p in deps_cpp_info.sharedlinkflags)
18 self.exelinkflags = ", ".join('"%s"' % p for p in deps_cpp_info.exelinkflags)
19
20 self.rootpath = "%s" % deps_cpp_info.rootpath.replace("\\", "/")
21
22
23 class PremakeGenerator(Generator):
24 @property
25 def filename(self):
26 return BUILD_INFO_PREMAKE
27
28 @property
29 def content(self):
30 deps = PremakeDeps(self.deps_build_info)
31
32 template = ('conan_includedirs{dep} = {{{deps.include_paths}}}\n'
33 'conan_libdirs{dep} = {{{deps.lib_paths}}}\n'
34 'conan_bindirs{dep} = {{{deps.bin_paths}}}\n'
35 'conan_libs{dep} = {{{deps.libs}}}\n'
36 'conan_cppdefines{dep} = {{{deps.defines}}}\n'
37 'conan_cppflags{dep} = {{{deps.cppflags}}}\n'
38 'conan_cflags{dep} = {{{deps.cflags}}}\n'
39 'conan_sharedlinkflags{dep} = {{{deps.sharedlinkflags}}}\n'
40 'conan_exelinkflags{dep} = {{{deps.exelinkflags}}}\n')
41
42 sections = ["#!lua"]
43 all_flags = template.format(dep="", deps=deps)
44 sections.append(all_flags)
45 template_deps = template + 'conan_rootpath{dep} = "{deps.rootpath}"\n'
46
47 for dep_name, dep_cpp_info in self.deps_build_info.dependencies:
48 deps = PremakeDeps(dep_cpp_info)
49 dep_name = dep_name.replace("-", "_")
50 dep_flags = template_deps.format(dep="_" + dep_name, deps=deps)
51 sections.append(dep_flags)
52
53 return "\n".join(sections)
54
[end of conans/client/generators/premake.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| conan-io/conan | 4486c5d6ca77e979ac0a991b964a86cdf26e95d2 | GNU Make generator
https://github.com/solvingj/conan-make_generator/blob/master/conanfile.py by @solvingj is almost it.
I agree it could be built-in.
Can use conditional:
```
ifneq ($(USE_CONAN),)
INC_PATHS += $(CONAN_INC_PATHS)
LD_PATHS += $(CONAN_LIB_PATHS)
LD_LIBS += $(CONAN_LIBS)
CXXFLAGS += $(CONAN_CPP_FLAGS)
CFLAGS += $(CONAN_CFLAGS)
DEFINES += $(CONAN_DEFINES)
LDFLAGS_SHARED += $(CONAN_SHAREDLINKFLAGS)
LDFLAGS_EXE += $(CONAN_EXELINKFLAGS)
C_SRCS += $(CONAN_C_SRCS)
CXX_SRCS += $(CONAN_CXX_SRCS)
endif
```
| Labeled as high because the invest should be minimal. | 2018-11-26T17:02:07Z | <patch>
diff --git a/conans/client/generators/__init__.py b/conans/client/generators/__init__.py
--- a/conans/client/generators/__init__.py
+++ b/conans/client/generators/__init__.py
@@ -28,6 +28,7 @@
from conans.util.env_reader import get_env
from .b2 import B2Generator
from .premake import PremakeGenerator
+from .make import MakeGenerator
class _GeneratorManager(object):
@@ -74,6 +75,7 @@ def __getitem__(self, key):
registered_generators.add("json", JsonGenerator)
registered_generators.add("b2", B2Generator)
registered_generators.add("premake", PremakeGenerator)
+registered_generators.add("make", MakeGenerator)
def write_generators(conanfile, path, output):
diff --git a/conans/client/generators/make.py b/conans/client/generators/make.py
new file mode 100644
--- /dev/null
+++ b/conans/client/generators/make.py
@@ -0,0 +1,109 @@
+from conans.model import Generator
+from conans.paths import BUILD_INFO_MAKE
+
+
+class MakeGenerator(Generator):
+
+ def __init__(self, conanfile):
+ Generator.__init__(self, conanfile)
+ self.makefile_newline = "\n"
+ self.makefile_line_continuation = " \\\n"
+ self.assignment_if_absent = " ?= "
+ self.assignment_append = " += "
+
+ @property
+ def filename(self):
+ return BUILD_INFO_MAKE
+
+ @property
+ def content(self):
+
+ content = [
+ "#-------------------------------------------------------------------#",
+ "# Makefile variables from Conan Dependencies #",
+ "#-------------------------------------------------------------------#",
+ "",
+ ]
+
+ for line_as_list in self.create_deps_content():
+ content.append("".join(line_as_list))
+
+ content.append("#-------------------------------------------------------------------#")
+ content.append(self.makefile_newline)
+ return self.makefile_newline.join(content)
+
+ def create_deps_content(self):
+ deps_content = self.create_content_from_deps()
+ deps_content.extend(self.create_combined_content())
+ return deps_content
+
+ def create_content_from_deps(self):
+ content = []
+ for pkg_name, cpp_info in self.deps_build_info.dependencies:
+ content.extend(self.create_content_from_dep(pkg_name, cpp_info))
+ return content
+
+ def create_content_from_dep(self, pkg_name, cpp_info):
+
+ vars_info = [("ROOT", self.assignment_if_absent, [cpp_info.rootpath]),
+ ("SYSROOT", self.assignment_if_absent, [cpp_info.sysroot]),
+ ("INCLUDE_PATHS", self.assignment_append, cpp_info.include_paths),
+ ("LIB_PATHS", self.assignment_append, cpp_info.lib_paths),
+ ("BIN_PATHS", self.assignment_append, cpp_info.bin_paths),
+ ("BUILD_PATHS", self.assignment_append, cpp_info.build_paths),
+ ("RES_PATHS", self.assignment_append, cpp_info.res_paths),
+ ("LIBS", self.assignment_append, cpp_info.libs),
+ ("DEFINES", self.assignment_append, cpp_info.defines),
+ ("CFLAGS", self.assignment_append, cpp_info.cflags),
+ ("CPPFLAGS", self.assignment_append, cpp_info.cppflags),
+ ("SHAREDLINKFLAGS", self.assignment_append, cpp_info.sharedlinkflags),
+ ("EXELINKFLAGS", self.assignment_append, cpp_info.exelinkflags)]
+
+ return [self.create_makefile_var_pkg(var_name, pkg_name, operator, info)
+ for var_name, operator, info in vars_info]
+
+ def create_combined_content(self):
+ content = []
+ for var_name in self.all_dep_vars():
+ content.append(self.create_makefile_var_global(var_name, self.assignment_append,
+ self.create_combined_var_list(var_name)))
+ return content
+
+ def create_combined_var_list(self, var_name):
+ make_vars = []
+ for pkg_name, _ in self.deps_build_info.dependencies:
+ pkg_var = self.create_makefile_var_name_pkg(var_name, pkg_name)
+ make_vars.append("$({pkg_var})".format(pkg_var=pkg_var))
+ return make_vars
+
+ def create_makefile_var_global(self, var_name, operator, values):
+ make_var = [self.create_makefile_var_name_global(var_name)]
+ make_var.extend(self.create_makefile_var_common(operator, values))
+ return make_var
+
+ def create_makefile_var_pkg(self, var_name, pkg_name, operator, values):
+ make_var = [self.create_makefile_var_name_pkg(var_name, pkg_name)]
+ make_var.extend(self.create_makefile_var_common(operator, values))
+ return make_var
+
+ def create_makefile_var_common(self, operator, values):
+ return [operator, self.makefile_line_continuation, self.create_makefile_var_value(values),
+ self.makefile_newline]
+
+ @staticmethod
+ def create_makefile_var_name_global(var_name):
+ return "CONAN_{var}".format(var=var_name).upper()
+
+ @staticmethod
+ def create_makefile_var_name_pkg(var_name, pkg_name):
+ return "CONAN_{var}_{lib}".format(var=var_name, lib=pkg_name).upper()
+
+ def create_makefile_var_value(self, values):
+ formatted_values = [value.replace("\\", "/") for value in values]
+ return self.makefile_line_continuation.join(formatted_values)
+
+ @staticmethod
+ def all_dep_vars():
+ return ["rootpath", "sysroot", "include_paths", "lib_paths", "bin_paths", "build_paths",
+ "res_paths", "libs", "defines", "cflags", "cppflags", "sharedlinkflags",
+ "exelinkflags"]
diff --git a/conans/client/generators/premake.py b/conans/client/generators/premake.py
--- a/conans/client/generators/premake.py
+++ b/conans/client/generators/premake.py
@@ -3,6 +3,7 @@
class PremakeDeps(object):
+
def __init__(self, deps_cpp_info):
self.include_paths = ",\n".join('"%s"' % p.replace("\\", "/")
for p in deps_cpp_info.include_paths)
diff --git a/conans/paths.py b/conans/paths.py
--- a/conans/paths.py
+++ b/conans/paths.py
@@ -35,6 +35,7 @@ def path_shortener(x, _):
BUILD_INFO_VISUAL_STUDIO = 'conanbuildinfo.props'
BUILD_INFO_XCODE = 'conanbuildinfo.xcconfig'
BUILD_INFO_PREMAKE = 'conanbuildinfo.lua'
+BUILD_INFO_MAKE = 'conanbuildinfo.mak'
CONANINFO = "conaninfo.txt"
CONANENV = "conanenv.txt"
SYSTEM_REQS = "system_reqs.txt"
</patch> | [] | [] | |||
pypa__pip-7289 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip 19.3 doesn't send client certificate
**Ubuntu 18.04 virtual environment**
* pip version: 19.3
* Python version: 3.6.8
* OS: Ubuntu 18.04.3 LTS
We have a private Pypi server hosted with [pypicloud](https://pypicloud.readthedocs.io/en/latest/index.html). We use client certificates to authenticate users for downloading/uploading packages.
**Description**
pip 19.3 doesn't seem to send our client certificates so authentication fails and packages cannot be installed:
`WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<our package name>/
`
I captured some of the SSL traffic from pip install in Wireshark and the client certificate option is there in the SSL handshake, but the certificates length is 0 with pip 19.3:
In 19.2.1, the length is non-zero and Wireshark shows the client certificate I expect.
**Expected behavior**
We should not get an SSL error if our client certificates and CA certificates are not expired. I have checked our server logs there don't appear to be any errors there with our certificates.
If I downgrade to pip 19.2.1 or 19.2.3 in my virtual environment, then the SSL error goes away.
I also checked with the `openssl s_client` that a handshake succeeded with the same client certificate:
```
openssl s_client -connect <my server> -cert <cert> -key <key> -state
CONNECTED(00000005)
SSL_connect:before SSL initialization
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS read server hello
depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
verify return:1
depth=0 CN = <my server>
verify return:1
SSL_connect:SSLv3/TLS read server certificate
SSL_connect:SSLv3/TLS read server key exchange
SSL_connect:SSLv3/TLS read server certificate request
SSL_connect:SSLv3/TLS read server done
SSL_connect:SSLv3/TLS write client certificate
...
SSL handshake has read 4268 bytes and written 1546 bytes
Verification: OK
---
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-GCM-SHA384
Session-ID:
```
**How to Reproduce**
1. Setup pip.conf or command-line arguments to use client certificate
2. pip install <package>
3. sslv3 alert handshake failure occurs
**Output**
```
pip install <my package>
Looking in indexes: https://pypi.org/simple/, https://<my server>/simple/
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
```
</issue>
<code>
[start of README.rst]
1 pip - The Python Package Installer
2 ==================================
3
4 .. image:: https://img.shields.io/pypi/v/pip.svg
5 :target: https://pypi.org/project/pip/
6
7 .. image:: https://readthedocs.org/projects/pip/badge/?version=latest
8 :target: https://pip.pypa.io/en/latest
9
10 pip is the `package installer`_ for Python. You can use pip to install packages from the `Python Package Index`_ and other indexes.
11
12 Please take a look at our documentation for how to install and use pip:
13
14 * `Installation`_
15 * `Usage`_
16
17 Updates are released regularly, with a new version every 3 months. More details can be found in our documentation:
18
19 * `Release notes`_
20 * `Release process`_
21
22 If you find bugs, need help, or want to talk to the developers please use our mailing lists or chat rooms:
23
24 * `Issue tracking`_
25 * `Discourse channel`_
26 * `User IRC`_
27
28 If you want to get involved head over to GitHub to get the source code, look at our development documentation and feel free to jump on the developer mailing lists and chat rooms:
29
30 * `GitHub page`_
31 * `Dev documentation`_
32 * `Dev mailing list`_
33 * `Dev IRC`_
34
35 Code of Conduct
36 ---------------
37
38 Everyone interacting in the pip project's codebases, issue trackers, chat
39 rooms, and mailing lists is expected to follow the `PyPA Code of Conduct`_.
40
41 .. _package installer: https://packaging.python.org/en/latest/current/
42 .. _Python Package Index: https://pypi.org
43 .. _Installation: https://pip.pypa.io/en/stable/installing.html
44 .. _Usage: https://pip.pypa.io/en/stable/
45 .. _Release notes: https://pip.pypa.io/en/stable/news.html
46 .. _Release process: https://pip.pypa.io/en/latest/development/release-process/
47 .. _GitHub page: https://github.com/pypa/pip
48 .. _Dev documentation: https://pip.pypa.io/en/latest/development
49 .. _Issue tracking: https://github.com/pypa/pip/issues
50 .. _Discourse channel: https://discuss.python.org/c/packaging
51 .. _Dev mailing list: https://groups.google.com/forum/#!forum/pypa-dev
52 .. _User IRC: https://webchat.freenode.net/?channels=%23pypa
53 .. _Dev IRC: https://webchat.freenode.net/?channels=%23pypa-dev
54 .. _PyPA Code of Conduct: https://www.pypa.io/en/latest/code-of-conduct/
55
[end of README.rst]
[start of src/pip/_vendor/requests/adapters.py]
1 # -*- coding: utf-8 -*-
2
3 """
4 requests.adapters
5 ~~~~~~~~~~~~~~~~~
6
7 This module contains the transport adapters that Requests uses to define
8 and maintain connections.
9 """
10
11 import os.path
12 import socket
13
14 from pip._vendor.urllib3.poolmanager import PoolManager, proxy_from_url
15 from pip._vendor.urllib3.response import HTTPResponse
16 from pip._vendor.urllib3.util import parse_url
17 from pip._vendor.urllib3.util import Timeout as TimeoutSauce
18 from pip._vendor.urllib3.util.retry import Retry
19 from pip._vendor.urllib3.exceptions import ClosedPoolError
20 from pip._vendor.urllib3.exceptions import ConnectTimeoutError
21 from pip._vendor.urllib3.exceptions import HTTPError as _HTTPError
22 from pip._vendor.urllib3.exceptions import MaxRetryError
23 from pip._vendor.urllib3.exceptions import NewConnectionError
24 from pip._vendor.urllib3.exceptions import ProxyError as _ProxyError
25 from pip._vendor.urllib3.exceptions import ProtocolError
26 from pip._vendor.urllib3.exceptions import ReadTimeoutError
27 from pip._vendor.urllib3.exceptions import SSLError as _SSLError
28 from pip._vendor.urllib3.exceptions import ResponseError
29 from pip._vendor.urllib3.exceptions import LocationValueError
30
31 from .models import Response
32 from .compat import urlparse, basestring
33 from .utils import (DEFAULT_CA_BUNDLE_PATH, extract_zipped_paths,
34 get_encoding_from_headers, prepend_scheme_if_needed,
35 get_auth_from_url, urldefragauth, select_proxy)
36 from .structures import CaseInsensitiveDict
37 from .cookies import extract_cookies_to_jar
38 from .exceptions import (ConnectionError, ConnectTimeout, ReadTimeout, SSLError,
39 ProxyError, RetryError, InvalidSchema, InvalidProxyURL,
40 InvalidURL)
41 from .auth import _basic_auth_str
42
43 try:
44 from pip._vendor.urllib3.contrib.socks import SOCKSProxyManager
45 except ImportError:
46 def SOCKSProxyManager(*args, **kwargs):
47 raise InvalidSchema("Missing dependencies for SOCKS support.")
48
49 DEFAULT_POOLBLOCK = False
50 DEFAULT_POOLSIZE = 10
51 DEFAULT_RETRIES = 0
52 DEFAULT_POOL_TIMEOUT = None
53
54
55 class BaseAdapter(object):
56 """The Base Transport Adapter"""
57
58 def __init__(self):
59 super(BaseAdapter, self).__init__()
60
61 def send(self, request, stream=False, timeout=None, verify=True,
62 cert=None, proxies=None):
63 """Sends PreparedRequest object. Returns Response object.
64
65 :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
66 :param stream: (optional) Whether to stream the request content.
67 :param timeout: (optional) How long to wait for the server to send
68 data before giving up, as a float, or a :ref:`(connect timeout,
69 read timeout) <timeouts>` tuple.
70 :type timeout: float or tuple
71 :param verify: (optional) Either a boolean, in which case it controls whether we verify
72 the server's TLS certificate, or a string, in which case it must be a path
73 to a CA bundle to use
74 :param cert: (optional) Any user-provided SSL certificate to be trusted.
75 :param proxies: (optional) The proxies dictionary to apply to the request.
76 """
77 raise NotImplementedError
78
79 def close(self):
80 """Cleans up adapter specific items."""
81 raise NotImplementedError
82
83
84 class HTTPAdapter(BaseAdapter):
85 """The built-in HTTP Adapter for urllib3.
86
87 Provides a general-case interface for Requests sessions to contact HTTP and
88 HTTPS urls by implementing the Transport Adapter interface. This class will
89 usually be created by the :class:`Session <Session>` class under the
90 covers.
91
92 :param pool_connections: The number of urllib3 connection pools to cache.
93 :param pool_maxsize: The maximum number of connections to save in the pool.
94 :param max_retries: The maximum number of retries each connection
95 should attempt. Note, this applies only to failed DNS lookups, socket
96 connections and connection timeouts, never to requests where data has
97 made it to the server. By default, Requests does not retry failed
98 connections. If you need granular control over the conditions under
99 which we retry a request, import urllib3's ``Retry`` class and pass
100 that instead.
101 :param pool_block: Whether the connection pool should block for connections.
102
103 Usage::
104
105 >>> import requests
106 >>> s = requests.Session()
107 >>> a = requests.adapters.HTTPAdapter(max_retries=3)
108 >>> s.mount('http://', a)
109 """
110 __attrs__ = ['max_retries', 'config', '_pool_connections', '_pool_maxsize',
111 '_pool_block']
112
113 def __init__(self, pool_connections=DEFAULT_POOLSIZE,
114 pool_maxsize=DEFAULT_POOLSIZE, max_retries=DEFAULT_RETRIES,
115 pool_block=DEFAULT_POOLBLOCK):
116 if max_retries == DEFAULT_RETRIES:
117 self.max_retries = Retry(0, read=False)
118 else:
119 self.max_retries = Retry.from_int(max_retries)
120 self.config = {}
121 self.proxy_manager = {}
122
123 super(HTTPAdapter, self).__init__()
124
125 self._pool_connections = pool_connections
126 self._pool_maxsize = pool_maxsize
127 self._pool_block = pool_block
128
129 self.init_poolmanager(pool_connections, pool_maxsize, block=pool_block)
130
131 def __getstate__(self):
132 return {attr: getattr(self, attr, None) for attr in self.__attrs__}
133
134 def __setstate__(self, state):
135 # Can't handle by adding 'proxy_manager' to self.__attrs__ because
136 # self.poolmanager uses a lambda function, which isn't pickleable.
137 self.proxy_manager = {}
138 self.config = {}
139
140 for attr, value in state.items():
141 setattr(self, attr, value)
142
143 self.init_poolmanager(self._pool_connections, self._pool_maxsize,
144 block=self._pool_block)
145
146 def init_poolmanager(self, connections, maxsize, block=DEFAULT_POOLBLOCK, **pool_kwargs):
147 """Initializes a urllib3 PoolManager.
148
149 This method should not be called from user code, and is only
150 exposed for use when subclassing the
151 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
152
153 :param connections: The number of urllib3 connection pools to cache.
154 :param maxsize: The maximum number of connections to save in the pool.
155 :param block: Block when no free connections are available.
156 :param pool_kwargs: Extra keyword arguments used to initialize the Pool Manager.
157 """
158 # save these values for pickling
159 self._pool_connections = connections
160 self._pool_maxsize = maxsize
161 self._pool_block = block
162
163 self.poolmanager = PoolManager(num_pools=connections, maxsize=maxsize,
164 block=block, strict=True, **pool_kwargs)
165
166 def proxy_manager_for(self, proxy, **proxy_kwargs):
167 """Return urllib3 ProxyManager for the given proxy.
168
169 This method should not be called from user code, and is only
170 exposed for use when subclassing the
171 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
172
173 :param proxy: The proxy to return a urllib3 ProxyManager for.
174 :param proxy_kwargs: Extra keyword arguments used to configure the Proxy Manager.
175 :returns: ProxyManager
176 :rtype: urllib3.ProxyManager
177 """
178 if proxy in self.proxy_manager:
179 manager = self.proxy_manager[proxy]
180 elif proxy.lower().startswith('socks'):
181 username, password = get_auth_from_url(proxy)
182 manager = self.proxy_manager[proxy] = SOCKSProxyManager(
183 proxy,
184 username=username,
185 password=password,
186 num_pools=self._pool_connections,
187 maxsize=self._pool_maxsize,
188 block=self._pool_block,
189 **proxy_kwargs
190 )
191 else:
192 proxy_headers = self.proxy_headers(proxy)
193 manager = self.proxy_manager[proxy] = proxy_from_url(
194 proxy,
195 proxy_headers=proxy_headers,
196 num_pools=self._pool_connections,
197 maxsize=self._pool_maxsize,
198 block=self._pool_block,
199 **proxy_kwargs)
200
201 return manager
202
203 def cert_verify(self, conn, url, verify, cert):
204 """Verify a SSL certificate. This method should not be called from user
205 code, and is only exposed for use when subclassing the
206 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
207
208 :param conn: The urllib3 connection object associated with the cert.
209 :param url: The requested URL.
210 :param verify: Either a boolean, in which case it controls whether we verify
211 the server's TLS certificate, or a string, in which case it must be a path
212 to a CA bundle to use
213 :param cert: The SSL certificate to verify.
214 """
215 if url.lower().startswith('https') and verify:
216
217 cert_loc = None
218
219 # Allow self-specified cert location.
220 if verify is not True:
221 cert_loc = verify
222
223 if not cert_loc:
224 cert_loc = extract_zipped_paths(DEFAULT_CA_BUNDLE_PATH)
225
226 if not cert_loc or not os.path.exists(cert_loc):
227 raise IOError("Could not find a suitable TLS CA certificate bundle, "
228 "invalid path: {}".format(cert_loc))
229
230 conn.cert_reqs = 'CERT_REQUIRED'
231
232 if not os.path.isdir(cert_loc):
233 conn.ca_certs = cert_loc
234 else:
235 conn.ca_cert_dir = cert_loc
236 else:
237 conn.cert_reqs = 'CERT_NONE'
238 conn.ca_certs = None
239 conn.ca_cert_dir = None
240
241 if cert:
242 if not isinstance(cert, basestring):
243 conn.cert_file = cert[0]
244 conn.key_file = cert[1]
245 else:
246 conn.cert_file = cert
247 conn.key_file = None
248 if conn.cert_file and not os.path.exists(conn.cert_file):
249 raise IOError("Could not find the TLS certificate file, "
250 "invalid path: {}".format(conn.cert_file))
251 if conn.key_file and not os.path.exists(conn.key_file):
252 raise IOError("Could not find the TLS key file, "
253 "invalid path: {}".format(conn.key_file))
254
255 def build_response(self, req, resp):
256 """Builds a :class:`Response <requests.Response>` object from a urllib3
257 response. This should not be called from user code, and is only exposed
258 for use when subclassing the
259 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`
260
261 :param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
262 :param resp: The urllib3 response object.
263 :rtype: requests.Response
264 """
265 response = Response()
266
267 # Fallback to None if there's no status_code, for whatever reason.
268 response.status_code = getattr(resp, 'status', None)
269
270 # Make headers case-insensitive.
271 response.headers = CaseInsensitiveDict(getattr(resp, 'headers', {}))
272
273 # Set encoding.
274 response.encoding = get_encoding_from_headers(response.headers)
275 response.raw = resp
276 response.reason = response.raw.reason
277
278 if isinstance(req.url, bytes):
279 response.url = req.url.decode('utf-8')
280 else:
281 response.url = req.url
282
283 # Add new cookies from the server.
284 extract_cookies_to_jar(response.cookies, req, resp)
285
286 # Give the Response some context.
287 response.request = req
288 response.connection = self
289
290 return response
291
292 def get_connection(self, url, proxies=None):
293 """Returns a urllib3 connection for the given URL. This should not be
294 called from user code, and is only exposed for use when subclassing the
295 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
296
297 :param url: The URL to connect to.
298 :param proxies: (optional) A Requests-style dictionary of proxies used on this request.
299 :rtype: urllib3.ConnectionPool
300 """
301 proxy = select_proxy(url, proxies)
302
303 if proxy:
304 proxy = prepend_scheme_if_needed(proxy, 'http')
305 proxy_url = parse_url(proxy)
306 if not proxy_url.host:
307 raise InvalidProxyURL("Please check proxy URL. It is malformed"
308 " and could be missing the host.")
309 proxy_manager = self.proxy_manager_for(proxy)
310 conn = proxy_manager.connection_from_url(url)
311 else:
312 # Only scheme should be lower case
313 parsed = urlparse(url)
314 url = parsed.geturl()
315 conn = self.poolmanager.connection_from_url(url)
316
317 return conn
318
319 def close(self):
320 """Disposes of any internal state.
321
322 Currently, this closes the PoolManager and any active ProxyManager,
323 which closes any pooled connections.
324 """
325 self.poolmanager.clear()
326 for proxy in self.proxy_manager.values():
327 proxy.clear()
328
329 def request_url(self, request, proxies):
330 """Obtain the url to use when making the final request.
331
332 If the message is being sent through a HTTP proxy, the full URL has to
333 be used. Otherwise, we should only use the path portion of the URL.
334
335 This should not be called from user code, and is only exposed for use
336 when subclassing the
337 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
338
339 :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
340 :param proxies: A dictionary of schemes or schemes and hosts to proxy URLs.
341 :rtype: str
342 """
343 proxy = select_proxy(request.url, proxies)
344 scheme = urlparse(request.url).scheme
345
346 is_proxied_http_request = (proxy and scheme != 'https')
347 using_socks_proxy = False
348 if proxy:
349 proxy_scheme = urlparse(proxy).scheme.lower()
350 using_socks_proxy = proxy_scheme.startswith('socks')
351
352 url = request.path_url
353 if is_proxied_http_request and not using_socks_proxy:
354 url = urldefragauth(request.url)
355
356 return url
357
358 def add_headers(self, request, **kwargs):
359 """Add any headers needed by the connection. As of v2.0 this does
360 nothing by default, but is left for overriding by users that subclass
361 the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
362
363 This should not be called from user code, and is only exposed for use
364 when subclassing the
365 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
366
367 :param request: The :class:`PreparedRequest <PreparedRequest>` to add headers to.
368 :param kwargs: The keyword arguments from the call to send().
369 """
370 pass
371
372 def proxy_headers(self, proxy):
373 """Returns a dictionary of the headers to add to any request sent
374 through a proxy. This works with urllib3 magic to ensure that they are
375 correctly sent to the proxy, rather than in a tunnelled request if
376 CONNECT is being used.
377
378 This should not be called from user code, and is only exposed for use
379 when subclassing the
380 :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
381
382 :param proxy: The url of the proxy being used for this request.
383 :rtype: dict
384 """
385 headers = {}
386 username, password = get_auth_from_url(proxy)
387
388 if username:
389 headers['Proxy-Authorization'] = _basic_auth_str(username,
390 password)
391
392 return headers
393
394 def send(self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None):
395 """Sends PreparedRequest object. Returns Response object.
396
397 :param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
398 :param stream: (optional) Whether to stream the request content.
399 :param timeout: (optional) How long to wait for the server to send
400 data before giving up, as a float, or a :ref:`(connect timeout,
401 read timeout) <timeouts>` tuple.
402 :type timeout: float or tuple or urllib3 Timeout object
403 :param verify: (optional) Either a boolean, in which case it controls whether
404 we verify the server's TLS certificate, or a string, in which case it
405 must be a path to a CA bundle to use
406 :param cert: (optional) Any user-provided SSL certificate to be trusted.
407 :param proxies: (optional) The proxies dictionary to apply to the request.
408 :rtype: requests.Response
409 """
410
411 try:
412 conn = self.get_connection(request.url, proxies)
413 except LocationValueError as e:
414 raise InvalidURL(e, request=request)
415
416 self.cert_verify(conn, request.url, verify, cert)
417 url = self.request_url(request, proxies)
418 self.add_headers(request, stream=stream, timeout=timeout, verify=verify, cert=cert, proxies=proxies)
419
420 chunked = not (request.body is None or 'Content-Length' in request.headers)
421
422 if isinstance(timeout, tuple):
423 try:
424 connect, read = timeout
425 timeout = TimeoutSauce(connect=connect, read=read)
426 except ValueError as e:
427 # this may raise a string formatting error.
428 err = ("Invalid timeout {}. Pass a (connect, read) "
429 "timeout tuple, or a single float to set "
430 "both timeouts to the same value".format(timeout))
431 raise ValueError(err)
432 elif isinstance(timeout, TimeoutSauce):
433 pass
434 else:
435 timeout = TimeoutSauce(connect=timeout, read=timeout)
436
437 try:
438 if not chunked:
439 resp = conn.urlopen(
440 method=request.method,
441 url=url,
442 body=request.body,
443 headers=request.headers,
444 redirect=False,
445 assert_same_host=False,
446 preload_content=False,
447 decode_content=False,
448 retries=self.max_retries,
449 timeout=timeout
450 )
451
452 # Send the request.
453 else:
454 if hasattr(conn, 'proxy_pool'):
455 conn = conn.proxy_pool
456
457 low_conn = conn._get_conn(timeout=DEFAULT_POOL_TIMEOUT)
458
459 try:
460 low_conn.putrequest(request.method,
461 url,
462 skip_accept_encoding=True)
463
464 for header, value in request.headers.items():
465 low_conn.putheader(header, value)
466
467 low_conn.endheaders()
468
469 for i in request.body:
470 low_conn.send(hex(len(i))[2:].encode('utf-8'))
471 low_conn.send(b'\r\n')
472 low_conn.send(i)
473 low_conn.send(b'\r\n')
474 low_conn.send(b'0\r\n\r\n')
475
476 # Receive the response from the server
477 try:
478 # For Python 2.7, use buffering of HTTP responses
479 r = low_conn.getresponse(buffering=True)
480 except TypeError:
481 # For compatibility with Python 3.3+
482 r = low_conn.getresponse()
483
484 resp = HTTPResponse.from_httplib(
485 r,
486 pool=conn,
487 connection=low_conn,
488 preload_content=False,
489 decode_content=False
490 )
491 except:
492 # If we hit any problems here, clean up the connection.
493 # Then, reraise so that we can handle the actual exception.
494 low_conn.close()
495 raise
496
497 except (ProtocolError, socket.error) as err:
498 raise ConnectionError(err, request=request)
499
500 except MaxRetryError as e:
501 if isinstance(e.reason, ConnectTimeoutError):
502 # TODO: Remove this in 3.0.0: see #2811
503 if not isinstance(e.reason, NewConnectionError):
504 raise ConnectTimeout(e, request=request)
505
506 if isinstance(e.reason, ResponseError):
507 raise RetryError(e, request=request)
508
509 if isinstance(e.reason, _ProxyError):
510 raise ProxyError(e, request=request)
511
512 if isinstance(e.reason, _SSLError):
513 # This branch is for urllib3 v1.22 and later.
514 raise SSLError(e, request=request)
515
516 raise ConnectionError(e, request=request)
517
518 except ClosedPoolError as e:
519 raise ConnectionError(e, request=request)
520
521 except _ProxyError as e:
522 raise ProxyError(e)
523
524 except (_SSLError, _HTTPError) as e:
525 if isinstance(e, _SSLError):
526 # This branch is for urllib3 versions earlier than v1.22
527 raise SSLError(e, request=request)
528 elif isinstance(e, ReadTimeoutError):
529 raise ReadTimeout(e, request=request)
530 else:
531 raise
532
533 return self.build_response(request, resp)
534
[end of src/pip/_vendor/requests/adapters.py]
[start of src/pip/_vendor/urllib3/exceptions.py]
1 from __future__ import absolute_import
2 from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
3
4 # Base Exceptions
5
6
7 class HTTPError(Exception):
8 "Base exception used by this module."
9 pass
10
11
12 class HTTPWarning(Warning):
13 "Base warning used by this module."
14 pass
15
16
17 class PoolError(HTTPError):
18 "Base exception for errors caused within a pool."
19
20 def __init__(self, pool, message):
21 self.pool = pool
22 HTTPError.__init__(self, "%s: %s" % (pool, message))
23
24 def __reduce__(self):
25 # For pickling purposes.
26 return self.__class__, (None, None)
27
28
29 class RequestError(PoolError):
30 "Base exception for PoolErrors that have associated URLs."
31
32 def __init__(self, pool, url, message):
33 self.url = url
34 PoolError.__init__(self, pool, message)
35
36 def __reduce__(self):
37 # For pickling purposes.
38 return self.__class__, (None, self.url, None)
39
40
41 class SSLError(HTTPError):
42 "Raised when SSL certificate fails in an HTTPS connection."
43 pass
44
45
46 class ProxyError(HTTPError):
47 "Raised when the connection to a proxy fails."
48 pass
49
50
51 class DecodeError(HTTPError):
52 "Raised when automatic decoding based on Content-Type fails."
53 pass
54
55
56 class ProtocolError(HTTPError):
57 "Raised when something unexpected happens mid-request/response."
58 pass
59
60
61 #: Renamed to ProtocolError but aliased for backwards compatibility.
62 ConnectionError = ProtocolError
63
64
65 # Leaf Exceptions
66
67
68 class MaxRetryError(RequestError):
69 """Raised when the maximum number of retries is exceeded.
70
71 :param pool: The connection pool
72 :type pool: :class:`~urllib3.connectionpool.HTTPConnectionPool`
73 :param string url: The requested Url
74 :param exceptions.Exception reason: The underlying error
75
76 """
77
78 def __init__(self, pool, url, reason=None):
79 self.reason = reason
80
81 message = "Max retries exceeded with url: %s (Caused by %r)" % (url, reason)
82
83 RequestError.__init__(self, pool, url, message)
84
85
86 class HostChangedError(RequestError):
87 "Raised when an existing pool gets a request for a foreign host."
88
89 def __init__(self, pool, url, retries=3):
90 message = "Tried to open a foreign host with url: %s" % url
91 RequestError.__init__(self, pool, url, message)
92 self.retries = retries
93
94
95 class TimeoutStateError(HTTPError):
96 """ Raised when passing an invalid state to a timeout """
97
98 pass
99
100
101 class TimeoutError(HTTPError):
102 """ Raised when a socket timeout error occurs.
103
104 Catching this error will catch both :exc:`ReadTimeoutErrors
105 <ReadTimeoutError>` and :exc:`ConnectTimeoutErrors <ConnectTimeoutError>`.
106 """
107
108 pass
109
110
111 class ReadTimeoutError(TimeoutError, RequestError):
112 "Raised when a socket timeout occurs while receiving data from a server"
113 pass
114
115
116 # This timeout error does not have a URL attached and needs to inherit from the
117 # base HTTPError
118 class ConnectTimeoutError(TimeoutError):
119 "Raised when a socket timeout occurs while connecting to a server"
120 pass
121
122
123 class NewConnectionError(ConnectTimeoutError, PoolError):
124 "Raised when we fail to establish a new connection. Usually ECONNREFUSED."
125 pass
126
127
128 class EmptyPoolError(PoolError):
129 "Raised when a pool runs out of connections and no more are allowed."
130 pass
131
132
133 class ClosedPoolError(PoolError):
134 "Raised when a request enters a pool after the pool has been closed."
135 pass
136
137
138 class LocationValueError(ValueError, HTTPError):
139 "Raised when there is something wrong with a given URL input."
140 pass
141
142
143 class LocationParseError(LocationValueError):
144 "Raised when get_host or similar fails to parse the URL input."
145
146 def __init__(self, location):
147 message = "Failed to parse: %s" % location
148 HTTPError.__init__(self, message)
149
150 self.location = location
151
152
153 class ResponseError(HTTPError):
154 "Used as a container for an error reason supplied in a MaxRetryError."
155 GENERIC_ERROR = "too many error responses"
156 SPECIFIC_ERROR = "too many {status_code} error responses"
157
158
159 class SecurityWarning(HTTPWarning):
160 "Warned when performing security reducing actions"
161 pass
162
163
164 class SubjectAltNameWarning(SecurityWarning):
165 "Warned when connecting to a host with a certificate missing a SAN."
166 pass
167
168
169 class InsecureRequestWarning(SecurityWarning):
170 "Warned when making an unverified HTTPS request."
171 pass
172
173
174 class SystemTimeWarning(SecurityWarning):
175 "Warned when system time is suspected to be wrong"
176 pass
177
178
179 class InsecurePlatformWarning(SecurityWarning):
180 "Warned when certain SSL configuration is not available on a platform."
181 pass
182
183
184 class SNIMissingWarning(HTTPWarning):
185 "Warned when making a HTTPS request without SNI available."
186 pass
187
188
189 class DependencyWarning(HTTPWarning):
190 """
191 Warned when an attempt is made to import a module with missing optional
192 dependencies.
193 """
194
195 pass
196
197
198 class ResponseNotChunked(ProtocolError, ValueError):
199 "Response needs to be chunked in order to read it as chunks."
200 pass
201
202
203 class BodyNotHttplibCompatible(HTTPError):
204 """
205 Body should be httplib.HTTPResponse like (have an fp attribute which
206 returns raw chunks) for read_chunked().
207 """
208
209 pass
210
211
212 class IncompleteRead(HTTPError, httplib_IncompleteRead):
213 """
214 Response length doesn't match expected Content-Length
215
216 Subclass of http_client.IncompleteRead to allow int value
217 for `partial` to avoid creating large objects on streamed
218 reads.
219 """
220
221 def __init__(self, partial, expected):
222 super(IncompleteRead, self).__init__(partial, expected)
223
224 def __repr__(self):
225 return "IncompleteRead(%i bytes read, " "%i more expected)" % (
226 self.partial,
227 self.expected,
228 )
229
230
231 class InvalidHeader(HTTPError):
232 "The header provided was somehow invalid."
233 pass
234
235
236 class ProxySchemeUnknown(AssertionError, ValueError):
237 "ProxyManager does not support the supplied scheme"
238 # TODO(t-8ch): Stop inheriting from AssertionError in v2.0.
239
240 def __init__(self, scheme):
241 message = "Not supported proxy scheme %s" % scheme
242 super(ProxySchemeUnknown, self).__init__(message)
243
244
245 class HeaderParsingError(HTTPError):
246 "Raised by assert_header_parsing, but we convert it to a log.warning statement."
247
248 def __init__(self, defects, unparsed_data):
249 message = "%s, unparsed data: %r" % (defects or "Unknown", unparsed_data)
250 super(HeaderParsingError, self).__init__(message)
251
252
253 class UnrewindableBodyError(HTTPError):
254 "urllib3 encountered an error when trying to rewind a body"
255 pass
256
[end of src/pip/_vendor/urllib3/exceptions.py]
[start of src/pip/_vendor/urllib3/util/ssl_.py]
1 from __future__ import absolute_import
2 import errno
3 import warnings
4 import hmac
5 import sys
6
7 from binascii import hexlify, unhexlify
8 from hashlib import md5, sha1, sha256
9
10 from .url import IPV4_RE, BRACELESS_IPV6_ADDRZ_RE
11 from ..exceptions import SSLError, InsecurePlatformWarning, SNIMissingWarning
12 from ..packages import six
13
14
15 SSLContext = None
16 HAS_SNI = False
17 IS_PYOPENSSL = False
18 IS_SECURETRANSPORT = False
19
20 # Maps the length of a digest to a possible hash function producing this digest
21 HASHFUNC_MAP = {32: md5, 40: sha1, 64: sha256}
22
23
24 def _const_compare_digest_backport(a, b):
25 """
26 Compare two digests of equal length in constant time.
27
28 The digests must be of type str/bytes.
29 Returns True if the digests match, and False otherwise.
30 """
31 result = abs(len(a) - len(b))
32 for l, r in zip(bytearray(a), bytearray(b)):
33 result |= l ^ r
34 return result == 0
35
36
37 _const_compare_digest = getattr(hmac, "compare_digest", _const_compare_digest_backport)
38
39 try: # Test for SSL features
40 import ssl
41 from ssl import wrap_socket, CERT_REQUIRED
42 from ssl import HAS_SNI # Has SNI?
43 except ImportError:
44 pass
45
46 try: # Platform-specific: Python 3.6
47 from ssl import PROTOCOL_TLS
48
49 PROTOCOL_SSLv23 = PROTOCOL_TLS
50 except ImportError:
51 try:
52 from ssl import PROTOCOL_SSLv23 as PROTOCOL_TLS
53
54 PROTOCOL_SSLv23 = PROTOCOL_TLS
55 except ImportError:
56 PROTOCOL_SSLv23 = PROTOCOL_TLS = 2
57
58
59 try:
60 from ssl import OP_NO_SSLv2, OP_NO_SSLv3, OP_NO_COMPRESSION
61 except ImportError:
62 OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000
63 OP_NO_COMPRESSION = 0x20000
64
65
66 # A secure default.
67 # Sources for more information on TLS ciphers:
68 #
69 # - https://wiki.mozilla.org/Security/Server_Side_TLS
70 # - https://www.ssllabs.com/projects/best-practices/index.html
71 # - https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
72 #
73 # The general intent is:
74 # - prefer cipher suites that offer perfect forward secrecy (DHE/ECDHE),
75 # - prefer ECDHE over DHE for better performance,
76 # - prefer any AES-GCM and ChaCha20 over any AES-CBC for better performance and
77 # security,
78 # - prefer AES-GCM over ChaCha20 because hardware-accelerated AES is common,
79 # - disable NULL authentication, MD5 MACs, DSS, and other
80 # insecure ciphers for security reasons.
81 # - NOTE: TLS 1.3 cipher suites are managed through a different interface
82 # not exposed by CPython (yet!) and are enabled by default if they're available.
83 DEFAULT_CIPHERS = ":".join(
84 [
85 "ECDHE+AESGCM",
86 "ECDHE+CHACHA20",
87 "DHE+AESGCM",
88 "DHE+CHACHA20",
89 "ECDH+AESGCM",
90 "DH+AESGCM",
91 "ECDH+AES",
92 "DH+AES",
93 "RSA+AESGCM",
94 "RSA+AES",
95 "!aNULL",
96 "!eNULL",
97 "!MD5",
98 "!DSS",
99 ]
100 )
101
102 try:
103 from ssl import SSLContext # Modern SSL?
104 except ImportError:
105
106 class SSLContext(object): # Platform-specific: Python 2
107 def __init__(self, protocol_version):
108 self.protocol = protocol_version
109 # Use default values from a real SSLContext
110 self.check_hostname = False
111 self.verify_mode = ssl.CERT_NONE
112 self.ca_certs = None
113 self.options = 0
114 self.certfile = None
115 self.keyfile = None
116 self.ciphers = None
117
118 def load_cert_chain(self, certfile, keyfile):
119 self.certfile = certfile
120 self.keyfile = keyfile
121
122 def load_verify_locations(self, cafile=None, capath=None):
123 self.ca_certs = cafile
124
125 if capath is not None:
126 raise SSLError("CA directories not supported in older Pythons")
127
128 def set_ciphers(self, cipher_suite):
129 self.ciphers = cipher_suite
130
131 def wrap_socket(self, socket, server_hostname=None, server_side=False):
132 warnings.warn(
133 "A true SSLContext object is not available. This prevents "
134 "urllib3 from configuring SSL appropriately and may cause "
135 "certain SSL connections to fail. You can upgrade to a newer "
136 "version of Python to solve this. For more information, see "
137 "https://urllib3.readthedocs.io/en/latest/advanced-usage.html"
138 "#ssl-warnings",
139 InsecurePlatformWarning,
140 )
141 kwargs = {
142 "keyfile": self.keyfile,
143 "certfile": self.certfile,
144 "ca_certs": self.ca_certs,
145 "cert_reqs": self.verify_mode,
146 "ssl_version": self.protocol,
147 "server_side": server_side,
148 }
149 return wrap_socket(socket, ciphers=self.ciphers, **kwargs)
150
151
152 def assert_fingerprint(cert, fingerprint):
153 """
154 Checks if given fingerprint matches the supplied certificate.
155
156 :param cert:
157 Certificate as bytes object.
158 :param fingerprint:
159 Fingerprint as string of hexdigits, can be interspersed by colons.
160 """
161
162 fingerprint = fingerprint.replace(":", "").lower()
163 digest_length = len(fingerprint)
164 hashfunc = HASHFUNC_MAP.get(digest_length)
165 if not hashfunc:
166 raise SSLError("Fingerprint of invalid length: {0}".format(fingerprint))
167
168 # We need encode() here for py32; works on py2 and p33.
169 fingerprint_bytes = unhexlify(fingerprint.encode())
170
171 cert_digest = hashfunc(cert).digest()
172
173 if not _const_compare_digest(cert_digest, fingerprint_bytes):
174 raise SSLError(
175 'Fingerprints did not match. Expected "{0}", got "{1}".'.format(
176 fingerprint, hexlify(cert_digest)
177 )
178 )
179
180
181 def resolve_cert_reqs(candidate):
182 """
183 Resolves the argument to a numeric constant, which can be passed to
184 the wrap_socket function/method from the ssl module.
185 Defaults to :data:`ssl.CERT_NONE`.
186 If given a string it is assumed to be the name of the constant in the
187 :mod:`ssl` module or its abbreviation.
188 (So you can specify `REQUIRED` instead of `CERT_REQUIRED`.
189 If it's neither `None` nor a string we assume it is already the numeric
190 constant which can directly be passed to wrap_socket.
191 """
192 if candidate is None:
193 return CERT_REQUIRED
194
195 if isinstance(candidate, str):
196 res = getattr(ssl, candidate, None)
197 if res is None:
198 res = getattr(ssl, "CERT_" + candidate)
199 return res
200
201 return candidate
202
203
204 def resolve_ssl_version(candidate):
205 """
206 like resolve_cert_reqs
207 """
208 if candidate is None:
209 return PROTOCOL_TLS
210
211 if isinstance(candidate, str):
212 res = getattr(ssl, candidate, None)
213 if res is None:
214 res = getattr(ssl, "PROTOCOL_" + candidate)
215 return res
216
217 return candidate
218
219
220 def create_urllib3_context(
221 ssl_version=None, cert_reqs=None, options=None, ciphers=None
222 ):
223 """All arguments have the same meaning as ``ssl_wrap_socket``.
224
225 By default, this function does a lot of the same work that
226 ``ssl.create_default_context`` does on Python 3.4+. It:
227
228 - Disables SSLv2, SSLv3, and compression
229 - Sets a restricted set of server ciphers
230
231 If you wish to enable SSLv3, you can do::
232
233 from pip._vendor.urllib3.util import ssl_
234 context = ssl_.create_urllib3_context()
235 context.options &= ~ssl_.OP_NO_SSLv3
236
237 You can do the same to enable compression (substituting ``COMPRESSION``
238 for ``SSLv3`` in the last line above).
239
240 :param ssl_version:
241 The desired protocol version to use. This will default to
242 PROTOCOL_SSLv23 which will negotiate the highest protocol that both
243 the server and your installation of OpenSSL support.
244 :param cert_reqs:
245 Whether to require the certificate verification. This defaults to
246 ``ssl.CERT_REQUIRED``.
247 :param options:
248 Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,
249 ``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``.
250 :param ciphers:
251 Which cipher suites to allow the server to select.
252 :returns:
253 Constructed SSLContext object with specified options
254 :rtype: SSLContext
255 """
256 context = SSLContext(ssl_version or PROTOCOL_TLS)
257
258 context.set_ciphers(ciphers or DEFAULT_CIPHERS)
259
260 # Setting the default here, as we may have no ssl module on import
261 cert_reqs = ssl.CERT_REQUIRED if cert_reqs is None else cert_reqs
262
263 if options is None:
264 options = 0
265 # SSLv2 is easily broken and is considered harmful and dangerous
266 options |= OP_NO_SSLv2
267 # SSLv3 has several problems and is now dangerous
268 options |= OP_NO_SSLv3
269 # Disable compression to prevent CRIME attacks for OpenSSL 1.0+
270 # (issue #309)
271 options |= OP_NO_COMPRESSION
272
273 context.options |= options
274
275 # Enable post-handshake authentication for TLS 1.3, see GH #1634. PHA is
276 # necessary for conditional client cert authentication with TLS 1.3.
277 # The attribute is None for OpenSSL <= 1.1.0 or does not exist in older
278 # versions of Python. We only enable on Python 3.7.4+ or if certificate
279 # verification is enabled to work around Python issue #37428
280 # See: https://bugs.python.org/issue37428
281 if (cert_reqs == ssl.CERT_REQUIRED or sys.version_info >= (3, 7, 4)) and getattr(
282 context, "post_handshake_auth", None
283 ) is not None:
284 context.post_handshake_auth = True
285
286 context.verify_mode = cert_reqs
287 if (
288 getattr(context, "check_hostname", None) is not None
289 ): # Platform-specific: Python 3.2
290 # We do our own verification, including fingerprints and alternative
291 # hostnames. So disable it here
292 context.check_hostname = False
293 return context
294
295
296 def ssl_wrap_socket(
297 sock,
298 keyfile=None,
299 certfile=None,
300 cert_reqs=None,
301 ca_certs=None,
302 server_hostname=None,
303 ssl_version=None,
304 ciphers=None,
305 ssl_context=None,
306 ca_cert_dir=None,
307 key_password=None,
308 ):
309 """
310 All arguments except for server_hostname, ssl_context, and ca_cert_dir have
311 the same meaning as they do when using :func:`ssl.wrap_socket`.
312
313 :param server_hostname:
314 When SNI is supported, the expected hostname of the certificate
315 :param ssl_context:
316 A pre-made :class:`SSLContext` object. If none is provided, one will
317 be created using :func:`create_urllib3_context`.
318 :param ciphers:
319 A string of ciphers we wish the client to support.
320 :param ca_cert_dir:
321 A directory containing CA certificates in multiple separate files, as
322 supported by OpenSSL's -CApath flag or the capath argument to
323 SSLContext.load_verify_locations().
324 :param key_password:
325 Optional password if the keyfile is encrypted.
326 """
327 context = ssl_context
328 if context is None:
329 # Note: This branch of code and all the variables in it are no longer
330 # used by urllib3 itself. We should consider deprecating and removing
331 # this code.
332 context = create_urllib3_context(ssl_version, cert_reqs, ciphers=ciphers)
333
334 if ca_certs or ca_cert_dir:
335 try:
336 context.load_verify_locations(ca_certs, ca_cert_dir)
337 except IOError as e: # Platform-specific: Python 2.7
338 raise SSLError(e)
339 # Py33 raises FileNotFoundError which subclasses OSError
340 # These are not equivalent unless we check the errno attribute
341 except OSError as e: # Platform-specific: Python 3.3 and beyond
342 if e.errno == errno.ENOENT:
343 raise SSLError(e)
344 raise
345
346 elif ssl_context is None and hasattr(context, "load_default_certs"):
347 # try to load OS default certs; works well on Windows (require Python3.4+)
348 context.load_default_certs()
349
350 # Attempt to detect if we get the goofy behavior of the
351 # keyfile being encrypted and OpenSSL asking for the
352 # passphrase via the terminal and instead error out.
353 if keyfile and key_password is None and _is_key_file_encrypted(keyfile):
354 raise SSLError("Client private key is encrypted, password is required")
355
356 if certfile:
357 if key_password is None:
358 context.load_cert_chain(certfile, keyfile)
359 else:
360 context.load_cert_chain(certfile, keyfile, key_password)
361
362 # If we detect server_hostname is an IP address then the SNI
363 # extension should not be used according to RFC3546 Section 3.1
364 # We shouldn't warn the user if SNI isn't available but we would
365 # not be using SNI anyways due to IP address for server_hostname.
366 if (
367 server_hostname is not None and not is_ipaddress(server_hostname)
368 ) or IS_SECURETRANSPORT:
369 if HAS_SNI and server_hostname is not None:
370 return context.wrap_socket(sock, server_hostname=server_hostname)
371
372 warnings.warn(
373 "An HTTPS request has been made, but the SNI (Server Name "
374 "Indication) extension to TLS is not available on this platform. "
375 "This may cause the server to present an incorrect TLS "
376 "certificate, which can cause validation failures. You can upgrade to "
377 "a newer version of Python to solve this. For more information, see "
378 "https://urllib3.readthedocs.io/en/latest/advanced-usage.html"
379 "#ssl-warnings",
380 SNIMissingWarning,
381 )
382
383 return context.wrap_socket(sock)
384
385
386 def is_ipaddress(hostname):
387 """Detects whether the hostname given is an IPv4 or IPv6 address.
388 Also detects IPv6 addresses with Zone IDs.
389
390 :param str hostname: Hostname to examine.
391 :return: True if the hostname is an IP address, False otherwise.
392 """
393 if not six.PY2 and isinstance(hostname, bytes):
394 # IDN A-label bytes are ASCII compatible.
395 hostname = hostname.decode("ascii")
396 return bool(IPV4_RE.match(hostname) or BRACELESS_IPV6_ADDRZ_RE.match(hostname))
397
398
399 def _is_key_file_encrypted(key_file):
400 """Detects if a key file is encrypted or not."""
401 with open(key_file, "r") as f:
402 for line in f:
403 # Look for Proc-Type: 4,ENCRYPTED
404 if "ENCRYPTED" in line:
405 return True
406
407 return False
408
[end of src/pip/_vendor/urllib3/util/ssl_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| pypa/pip | 44c8caccd4a39d6230666bca637157dfc78b95ea | pip 19.3 doesn't send client certificate
**Ubuntu 18.04 virtual environment**
* pip version: 19.3
* Python version: 3.6.8
* OS: Ubuntu 18.04.3 LTS
We have a private Pypi server hosted with [pypicloud](https://pypicloud.readthedocs.io/en/latest/index.html). We use client certificates to authenticate users for downloading/uploading packages.
**Description**
pip 19.3 doesn't seem to send our client certificates so authentication fails and packages cannot be installed:
`WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<our package name>/
`
I captured some of the SSL traffic from pip install in Wireshark and the client certificate option is there in the SSL handshake, but the certificates length is 0 with pip 19.3:

In 19.2.1, the length is non-zero and Wireshark shows the client certificate I expect.
**Expected behavior**
We should not get an SSL error if our client certificates and CA certificates are not expired. I have checked our server logs there don't appear to be any errors there with our certificates.
If I downgrade to pip 19.2.1 or 19.2.3 in my virtual environment, then the SSL error goes away.
I also checked with the `openssl s_client` that a handshake succeeded with the same client certificate:
```
openssl s_client -connect <my server> -cert <cert> -key <key> -state
CONNECTED(00000005)
SSL_connect:before SSL initialization
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS write client hello
SSL_connect:SSLv3/TLS read server hello
depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3
verify return:1
depth=0 CN = <my server>
verify return:1
SSL_connect:SSLv3/TLS read server certificate
SSL_connect:SSLv3/TLS read server key exchange
SSL_connect:SSLv3/TLS read server certificate request
SSL_connect:SSLv3/TLS read server done
SSL_connect:SSLv3/TLS write client certificate
...
SSL handshake has read 4268 bytes and written 1546 bytes
Verification: OK
---
New, TLSv1.2, Cipher is ECDHE-RSA-AES256-GCM-SHA384
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES256-GCM-SHA384
Session-ID:
```
**How to Reproduce**
1. Setup pip.conf or command-line arguments to use client certificate
2. pip install <package>
3. sslv3 alert handshake failure occurs
**Output**
```
pip install <my package>
Looking in indexes: https://pypi.org/simple/, https://<my server>/simple/
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:852)'),)': /simple/<my package>/
```
| I cannot reproduce this (Ubuntu 18.04.2, Python 3.6.7) with
<details>
<summary><strong>repro.sh</strong></summary>
```
#!/bin/sh
trap "exit" INT TERM
trap "kill 0" EXIT
set -e
cd "$(mktemp -d)"
openssl req -new -x509 -nodes \
-out cert.pem -keyout cert.pem \
-addext 'subjectAltName = IP:127.0.0.1' \
-subj '/CN=127.0.0.1'
cat <<EOF > server.py
import socket
import ssl
import sys
from pathlib import Path
cert = sys.argv[1]
context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
context.load_cert_chain(cert, cert)
context.load_verify_locations(cafile=cert)
context.verify_mode = ssl.CERT_REQUIRED
with socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) as sock:
sock.bind(('127.0.0.1', 0))
sock.listen(1)
_, port = sock.getsockname()
Path('port.txt').write_text(str(port), encoding='utf-8')
with context.wrap_socket(sock, server_side=True) as ssock:
while True:
conn, addr = ssock.accept()
cert = conn.getpeercert()
print(cert)
conn.write(b'HTTP/1.1 400 Bad Request\r\n\r\n')
conn.close()
EOF
PYTHON="${PYTHON:-python}"
"$PYTHON" -V
"$PYTHON" -m venv venv
venv/bin/python server.py cert.pem &
sleep 1
venv/bin/python -m pip install --upgrade pip==19.2.3
echo "- Old pip ------------------------------"
venv/bin/python -m pip -V
venv/bin/python -m pip install \
--ignore-installed \
--disable-pip-version-check \
--index-url https://127.0.0.1:$(cat port.txt) \
--cert cert.pem \
--client-cert cert.pem \
pip || true
venv/bin/python -m pip install --upgrade pip
echo "- New pip ------------------------------"
venv/bin/python -m pip -V
pip install \
--ignore-installed \
--disable-pip-version-check \
--index-url https://127.0.0.1:$(cat port.txt) \
--cert cert.pem \
--client-cert cert.pem \
pip
```
</details>
My output is
<details>
<summary><strong>Output</strong></summary>
```
$ PYTHON=~/.pyenv/versions/3.6.7/bin/python ./repro.sh
Generating a RSA private key
................................................................+++++
.......+++++
writing new private key to 'cert.pem'
-----
Python 3.6.7
Collecting pip==19.2.3
Using cached https://files.pythonhosted.org/packages/30/db/9e38760b32e3e7f40cce46dd5fb107b8c73840df38f0046d8e6514e675a1/pip-19.2.3-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Successfully installed pip-19.2.3
You are using pip version 19.2.3, however version 19.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
- Old pip ------------------------------
pip 19.2.3 from /tmp/user/1000/tmp.ZqHiG62cpt/venv/lib/python3.6/site-packages/pip (python 3.6)
Looking in indexes: https://127.0.0.1:55649
Collecting pip
{'subject': ((('commonName', '127.0.0.1'),),), 'issuer': ((('commonName', '127.0.0.1'),),), 'version': 3, 'serialNumber': '5D7B2701E9D3E0E8A9E6CA66AEC3849D3BE826CD', 'notBefore': 'Oct 15 01:55:59 2019 GMT', 'notAfter': 'Nov 14 01:55:59 2019 GMT', 'subjectAltName': (('IP Address', '127.0.0.1'),)}
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
Collecting pip
Using cached https://files.pythonhosted.org/packages/4a/08/6ca123073af4ebc4c5488a5bc8a010ac57aa39ce4d3c8a931ad504de4185/pip-19.3-py2.py3-none-any.whl
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-19.3
- New pip ------------------------------
pip 19.3 from /tmp/user/1000/tmp.ZqHiG62cpt/venv/lib/python3.6/site-packages/pip (python 3.6)
Looking in indexes: https://127.0.0.1:55649
Collecting pip
{'subject': ((('commonName', '127.0.0.1'),),), 'issuer': ((('commonName', '127.0.0.1'),),), 'version': 3, 'serialNumber': '5D7B2701E9D3E0E8A9E6CA66AEC3849D3BE826CD', 'notBefore': 'Oct 15 01:55:59 2019 GMT', 'notAfter': 'Nov 14 01:55:59 2019 GMT', 'subjectAltName': (('IP Address', '127.0.0.1'),)}
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
```
</details>
Notice in the second instance (with pip 19.3) that the server is still tracing the peer (pip) certificate.
How are you configuring the client cert for pip? Command line, configuration file, or environment variable?
Can you try shaping `repro.sh` from above into something self-contained that demonstrates your issue?
We're using ~/.pip/pip.conf to specify the client certificates. I modified your `repo.sh` and was not able to reproduce the problem using our client + server certificates and a fake SSL server (instead of the python one, I wanted to disable TLS 1.3 so I could see the certificates being sent in Wireshark):
`openssl s_server -accept 8999 -www -cert server.pem -key server.key -CAfile ca-cert.pem -no_tls1_3 -Verify 1`
It's a bit hard to produce something self-contained since we've got a Letsencrypt certificate tied to our own domain and a private PKI infrastructure for the client certificates.
It's looking like it might be an issue when the client certificate bundle is specified in pip.conf, specifying on the command-line seemed to work fine in 19.3. I'll try and come up with a new repro script that simulates this.
You may also run in a container so as not to clobber any existing configuration.
Ok, I think I have a container + script that reproduces the issue. It sets up its own CA and server/client certificates so it should be self-contained. I ran tshark in the Docker container and verified that when pip 19.3 talks to a dummy openssl server acting as pypi.org on the loopback interface, it doesn't send the client cert.
It has something to do with the `trusted-host` parameter in /root/.pip/pip.conf. With that commented out, there's no error. In the output below, some of the output from the openssl s_server process is mixed in with the script output (showing no client certificate sent).
<details>
<summary>Dockerfile</summary>
```
FROM python:3.8.0-slim-buster
COPY repro.sh /root
COPY pip.conf /root/.pip/pip.conf
WORKDIR /root
```
</details>
<details>
<summary>pip.conf</summary>
```
[global]
index-url = https://127.0.0.1:8999
trusted-host = 127.0.0.1
client-cert = /root/pip.client.bundle.pem
```
</details>
<details>
<summary>repro.sh</summary>
```bash
#!/bin/sh
trap "exit" INT TERM
trap "kill 0" EXIT
set -e
# CA + server cert
openssl genrsa -des3 -out ca.key -passout pass:notsecure 2048
openssl req -x509 -new -nodes -key ca.key -sha256 -days 1825 -addext "keyUsage = cRLSign, digitalSignature, keyCertSign" -out ca.pem -subj "/CN=Fake Root CA" -passin pass:notsecure
openssl genrsa -out pip.local.key 2048
openssl req -new -key pip.local.key -out pip.local.csr -subj "/CN=127.0.0.1"
cat << EOF > pip.local.ext
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
IP.1 = 127.0.0.1
EOF
openssl x509 -req -in pip.local.csr -CA ca.pem -CAkey ca.key -CAcreateserial \
-out pip.local.pem -days 1825 -sha256 -extfile pip.local.ext -passin pass:notsecure
cat << EOF > pip.client.ext
keyUsage = digitalSignature
extendedKeyUsage = clientAuth
EOF
# client cert
openssl genrsa -out pip.client.key 2048
openssl req -new -key pip.client.key -out pip.client.csr -subj "/CN=pip install"
openssl x509 -req -in pip.client.csr -CA ca.pem -CAkey ca.key -CAcreateserial \
-out pip.client.pem -days 1825 -sha256 -extfile pip.client.ext -passin pass:notsecure
# create key + cert bundle for pip install
cat pip.client.key pip.client.pem > pip.client.bundle.pem
PYTHON="${PYTHON:-python3}"
"$PYTHON" -V
"$PYTHON" -m venv venv
openssl s_server -accept 8999 -www -cert pip.local.pem -key pip.local.key -CAfile ca.pem -no_tls1_3 -Verify 1 &
sleep 1
venv/bin/python -m pip install --index-url https://pypi.org/simple/ --upgrade pip==19.2.3
echo "- Old pip ------------------------------"
venv/bin/python -m pip -V
venv/bin/python -m pip install \
--ignore-installed \
--disable-pip-version-check \
--cert /root/ca.pem \
pip || true
echo "Upgrading pip --------------------------"
venv/bin/python -m pip install --index-url https://pypi.org/simple/ --upgrade pip
echo "- New pip ------------------------------"
venv/bin/python -m pip -V
pip install \
--ignore-installed \
--disable-pip-version-check \
--cert ca.pem \
pip
```
</details>
<details>
<summary>Usage</summary>
```bash
docker build -t pip-debug -f Dockerfile .
docker run -it pip-debug bash
root@6d0a40c1179c:~# ./repro.sh
```
</details>
<details>
<summary>Output</summary>
```
root@0e1127dd4124:~# ./repro.sh
Generating RSA private key, 2048 bit long modulus (2 primes)
.......................+++++
..........+++++
e is 65537 (0x010001)
Generating RSA private key, 2048 bit long modulus (2 primes)
...................................+++++
......................................................................................................................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = 127.0.0.1
Getting CA Private Key
Generating RSA private key, 2048 bit long modulus (2 primes)
........................................+++++
.......................+++++
e is 65537 (0x010001)
Signature ok
subject=CN = pip install
Getting CA Private Key
Python 3.8.0
verify depth is 1, must return a certificate
Using default temp DH parameters
ACCEPT
Looking in indexes: https://pypi.org/simple/
Requirement already up-to-date: pip==19.2.3 in ./venv/lib/python3.8/site-packages (19.2.3)
WARNING: You are using pip version 19.2.3, however version 19.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
- Old pip ------------------------------
pip 19.2.3 from /root/venv/lib/python3.8/site-packages/pip (python 3.8)
Looking in indexes: https://127.0.0.1:8999
Collecting pip
depth=1 CN = Fake Root CA
verify return:1
depth=0 CN = pip install
verify return:1
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
Upgrading pip --------------------------
Looking in indexes: https://pypi.org/simple/
Collecting pip
Downloading https://files.pythonhosted.org/packages/4a/08/6ca123073af4ebc4c5488a5bc8a010ac57aa39ce4d3c8a931ad504de4185/pip-19.3-py2.py3-none-any.whl (1.4MB)
|████████████████████████████████| 1.4MB 3.7MB/s
Installing collected packages: pip
Found existing installation: pip 19.2.3
Uninstalling pip-19.2.3:
Successfully uninstalled pip-19.2.3
Successfully installed pip-19.3
- New pip ------------------------------
pip 19.3 from /root/venv/lib/python3.8/site-packages/pip (python 3.8)
Looking in indexes: https://127.0.0.1:8999
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))': /pip/
140716939547776:error:1417C0C7:SSL routines:tls_process_client_certificate:peer did not return a certificate:../ssl/statem/statem_srvr.c:3672:
Could not fetch URL https://127.0.0.1:8999/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='127.0.0.1', port=8999): Max retries exceeded with url: /pip/ (Caused by SSLError(SSLError(1, '[SSL: SSLV3_ALERT_HANDSHAKE_FAILURE] sslv3 alert handshake failure (_ssl.c:1108)'))) - skipping
ERROR: Could not find a version that satisfies the requirement pip (from versions: none)
ERROR: No matching distribution found for pip
```
</details>
Nice, thanks.
I bisected and it looks like the issue was introduced in 3f9136f. Previously the "trusted host" parameter with https URLs was only being applied for index URLs that did not have a port specified. As of 19.3 we assume that an unspecified port means the port is a wildcard. That change in conjunction with your configuration may have uncovered a bug in our `InsecureHTTPAdapter` [here](https://github.com/pypa/pip/blob/8c50c8a9bc8579886fa787a631dc15d4b503a8ac/src/pip/_internal/network/session.py#L214-L216) - we aren't doing anything with the `cert` parameter.
If I'm not missing something, I think we should be doing something like
```python
super(InsecureHTTPAdapter, self).cert_verify(conn=conn, url=url, verify=False, cert=cert)
```
to get the correct behavior (from [here](https://github.com/psf/requests/blob/67a7b2e8336951d527e223429672354989384197/requests/adapters.py#L241-L253)).
In your particular case is it possible to drop the trusted-host parameter since it wasn't being applied in previous versions?
Yeah, we can drop `trusted-host` for now. Most people have just reverted to pip 19.2.3
Thanks @surry for a well designed reproducer and @chrahunt for figuring out a potential root cause! :) | 2019-11-03T18:18:36Z | <patch>
diff --git a/src/pip/_internal/network/session.py b/src/pip/_internal/network/session.py
--- a/src/pip/_internal/network/session.py
+++ b/src/pip/_internal/network/session.py
@@ -212,8 +212,9 @@ def close(self):
class InsecureHTTPAdapter(HTTPAdapter):
def cert_verify(self, conn, url, verify, cert):
- conn.cert_reqs = 'CERT_NONE'
- conn.ca_certs = None
+ super(InsecureHTTPAdapter, self).cert_verify(
+ conn=conn, url=url, verify=False, cert=cert
+ )
class PipSession(requests.Session):
</patch> | [] | [] | |||
Lightning-AI__lightning-941 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support stepping options for lr scheduler
Currently schedulers get called every epoch. Sometimes though, we want them to be called every step.
Proposal 1:
Allow configure_optimizers to return this:
```python
return Adam, {'scheduler': LRScheduler, 'interval': 'batch|epoch'}
```
@ethanwharris @Borda thoughts? any simpler more general way of doing this? i think this dict can eventually have more options if we need to.
@srush
</issue>
<code>
[start of README.md]
1 <div align="center">
2
3 
4
5 # PyTorch Lightning
6
7 **The lightweight PyTorch wrapper for ML researchers. Scale your models. Write less boilerplate.**
8
9
10 [](https://badge.fury.io/py/pytorch-lightning)
11 [](https://pepy.tech/project/pytorch-lightning)
12 [](https://github.com/PytorchLightning/pytorch-lightning/tree/master/tests#running-coverage)
13 [](https://www.codefactor.io/repository/github/pytorchlightning/pytorch-lightning)
14
15 [](https://pytorch-lightning.readthedocs.io/en/latest/)
16 [](https://join.slack.com/t/pytorch-lightning/shared_invite/enQtODU5ODIyNTUzODQwLTFkMDg5Mzc1MDBmNjEzMDgxOTVmYTdhYjA1MDdmODUyOTg2OGQ1ZWZkYTQzODhhNzdhZDA3YmNhMDhlMDY4YzQ)
17 [](https://github.com/PytorchLightning/pytorch-lightning/blob/master/LICENSE)
18 [](https://shields.io/)
19
20 <!--
21 removed until codecov badge isn't empy. likely a config error showing nothing on master.
22 [](https://codecov.io/gh/Borda/pytorch-lightning)
23 -->
24 </div>
25
26 ---
27 ## Continuous Integration
28 <center>
29
30 | System / PyTorch Version | 1.1 | 1.2 | 1.3 | 1.4 |
31 | :---: | :---: | :---: | :---: | :---: |
32 | Linux py3.6 | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) | [](https://circleci.com/gh/PyTorchLightning/pytorch-lightning) |
33 | Linux py3.7 |  | <center>—</center> | <center>—</center> |  |
34 | OSX py3.6 |  | <center>—</center> | <center>—</center> |  |
35 | OSX py3.7 |  | <center>—</center> | <center>—</center> |  |
36 | Windows py3.6 |  | <center>—</center> | <center>—</center> |  |
37 | Windows py3.7 |  | <center>—</center> | <center>—</center> |  |
38
39 </center>
40
41 Simple installation from PyPI
42 ```bash
43 pip install pytorch-lightning
44 ```
45
46 ## Docs
47 - [master](https://pytorch-lightning.readthedocs.io/en/latest)
48 - [0.6.0](https://pytorch-lightning.readthedocs.io/en/0.6.0/)
49 - [0.5.3.2](https://pytorch-lightning.readthedocs.io/en/0.5.3.2/)
50
51 ## Demo
52 [Copy and run this COLAB!](https://colab.research.google.com/drive/1F_RNcHzTfFuQf-LeKvSlud6x7jXYkG31#scrollTo=HOk9c4_35FKg)
53
54 ## What is it?
55 Lightning is a way to organize your PyTorch code to decouple the science code from the engineering. It's more of a style-guide than a framework.
56
57 By refactoring your code, we can automate most of the non-research code. Lightning guarantees tested, correct, modern best practices for the automated parts.
58
59 Here's an example of how to organize PyTorch code into the LightningModule.
60
61 
62
63 - If you are a researcher, Lightning is infinitely flexible, you can modify everything down to the way .backward is called or distributed is set up.
64 - If you are a scientist or production team, lightning is very simple to use with best practice defaults.
65
66 ## What does lightning control for me?
67
68 Everything in Blue!
69 This is how lightning separates the science (red) from the engineering (blue).
70
71 
72
73 ## How much effort is it to convert?
74 You're probably tired of switching frameworks at this point. But it is a very quick process to refactor into the Lightning format (ie: hours). [Check out this tutorial](https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09).
75
76 ## What are the differences with PyTorch?
77 If you're wondering what you gain out of refactoring your PyTorch code, [read this comparison!](https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09)
78
79 ## Starting a new project?
80 [Use our seed-project aimed at reproducibility!](https://github.com/PytorchLightning/pytorch-lightning-conference-seed)
81
82 ## Why do I want to use lightning?
83 Every research project starts the same, a model, a training loop, validation loop, etc. As your research advances, you're likely to need distributed training, 16-bit precision, checkpointing, gradient accumulation, etc.
84
85 Lightning sets up all the boilerplate state-of-the-art training for you so you can focus on the research.
86
87 ---
88
89 ## README Table of Contents
90 - [How do I use it](https://github.com/PytorchLightning/pytorch-lightning#how-do-i-do-use-it)
91 - [What lightning automates](https://github.com/PytorchLightning/pytorch-lightning#what-does-lightning-control-for-me)
92 - [Tensorboard integration](https://github.com/PytorchLightning/pytorch-lightning#tensorboard)
93 - [Lightning features](https://github.com/PytorchLightning/pytorch-lightning#lightning-automates-all-of-the-following-each-is-also-configurable)
94 - [Examples](https://github.com/PytorchLightning/pytorch-lightning#examples)
95 - [Tutorials](https://github.com/PytorchLightning/pytorch-lightning#tutorials)
96 - [Asking for help](https://github.com/PytorchLightning/pytorch-lightning#asking-for-help)
97 - [Contributing](https://github.com/PytorchLightning/pytorch-lightning/blob/master/.github/CONTRIBUTING.md)
98 - [Bleeding edge install](https://github.com/PytorchLightning/pytorch-lightning#bleeding-edge)
99 - [Lightning Design Principles](https://github.com/PytorchLightning/pytorch-lightning#lightning-design-principles)
100 - [Lightning team](https://github.com/PytorchLightning/pytorch-lightning#lightning-team)
101 - [FAQ](https://github.com/PytorchLightning/pytorch-lightning#faq)
102
103 ---
104
105 ## How do I do use it?
106 Think about Lightning as refactoring your research code instead of using a new framework. The research code goes into a [LightningModule](https://pytorch-lightning.rtfd.io/en/latest/lightning-module.html) which you fit using a Trainer.
107
108 The LightningModule defines a *system* such as seq-2-seq, GAN, etc... It can ALSO define a simple classifier such as the example below.
109
110 To use lightning do 2 things:
111 1. [Define a LightningModule](https://pytorch-lightning.rtfd.io/en/latest/lightning-module.html)
112 **WARNING:** This syntax is for version 0.5.0+ where abbreviations were removed.
113 ```python
114 import os
115
116 import torch
117 from torch.nn import functional as F
118 from torch.utils.data import DataLoader
119 from torchvision.datasets import MNIST
120 from torchvision import transforms
121
122 import pytorch_lightning as pl
123
124 class CoolSystem(pl.LightningModule):
125
126 def __init__(self):
127 super(CoolSystem, self).__init__()
128 # not the best model...
129 self.l1 = torch.nn.Linear(28 * 28, 10)
130
131 def forward(self, x):
132 return torch.relu(self.l1(x.view(x.size(0), -1)))
133
134 def training_step(self, batch, batch_idx):
135 # REQUIRED
136 x, y = batch
137 y_hat = self.forward(x)
138 loss = F.cross_entropy(y_hat, y)
139 tensorboard_logs = {'train_loss': loss}
140 return {'loss': loss, 'log': tensorboard_logs}
141
142 def validation_step(self, batch, batch_idx):
143 # OPTIONAL
144 x, y = batch
145 y_hat = self.forward(x)
146 return {'val_loss': F.cross_entropy(y_hat, y)}
147
148 def validation_end(self, outputs):
149 # OPTIONAL
150 avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
151 tensorboard_logs = {'val_loss': avg_loss}
152 return {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
153
154 def test_step(self, batch, batch_idx):
155 # OPTIONAL
156 x, y = batch
157 y_hat = self.forward(x)
158 return {'test_loss': F.cross_entropy(y_hat, y)}
159
160 def test_end(self, outputs):
161 # OPTIONAL
162 avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
163 tensorboard_logs = {'test_loss': avg_loss}
164 return {'avg_test_loss': avg_loss, 'log': tensorboard_logs}
165
166 def configure_optimizers(self):
167 # REQUIRED
168 # can return multiple optimizers and learning_rate schedulers
169 # (LBFGS it is automatically supported, no need for closure function)
170 return torch.optim.Adam(self.parameters(), lr=0.02)
171
172 @pl.data_loader
173 def train_dataloader(self):
174 # REQUIRED
175 return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
176
177 @pl.data_loader
178 def val_dataloader(self):
179 # OPTIONAL
180 return DataLoader(MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()), batch_size=32)
181
182 @pl.data_loader
183 def test_dataloader(self):
184 # OPTIONAL
185 return DataLoader(MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor()), batch_size=32)
186 ```
187 2. Fit with a [trainer](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.html)
188 ```python
189 from pytorch_lightning import Trainer
190
191 model = CoolSystem()
192
193 # most basic trainer, uses good defaults
194 trainer = Trainer()
195 trainer.fit(model)
196 ```
197
198 Trainer sets up a tensorboard logger, early stopping and checkpointing by default (you can modify all of them or
199 use something other than tensorboard).
200
201 Here are more advanced examples
202 ```python
203 # train on cpu using only 10% of the data (for demo purposes)
204 trainer = Trainer(max_epochs=1, train_percent_check=0.1)
205
206 # train on 4 gpus (lightning chooses GPUs for you)
207 # trainer = Trainer(max_epochs=1, gpus=4, distributed_backend='ddp')
208
209 # train on 4 gpus (you choose GPUs)
210 # trainer = Trainer(max_epochs=1, gpus=[0, 1, 3, 7], distributed_backend='ddp')
211
212 # train on 32 gpus across 4 nodes (make sure to submit appropriate SLURM job)
213 # trainer = Trainer(max_epochs=1, gpus=8, num_gpu_nodes=4, distributed_backend='ddp')
214
215 # train (1 epoch only here for demo)
216 trainer.fit(model)
217
218 # view tensorboard logs
219 logging.info(f'View tensorboard logs by running\ntensorboard --logdir {os.getcwd()}')
220 logging.info('and going to http://localhost:6006 on your browser')
221 ```
222
223 When you're all done you can even run the test set separately.
224 ```python
225 trainer.test()
226 ```
227
228 **Could be as complex as seq-2-seq + attention**
229
230 ```python
231 # define what happens for training here
232 def training_step(self, batch, batch_idx):
233 x, y = batch
234
235 # define your own forward and loss calculation
236 hidden_states = self.encoder(x)
237
238 # even as complex as a seq-2-seq + attn model
239 # (this is just a toy, non-working example to illustrate)
240 start_token = '<SOS>'
241 last_hidden = torch.zeros(...)
242 loss = 0
243 for step in range(max_seq_len):
244 attn_context = self.attention_nn(hidden_states, start_token)
245 pred = self.decoder(start_token, attn_context, last_hidden)
246 last_hidden = pred
247 pred = self.predict_nn(pred)
248 loss += self.loss(last_hidden, y[step])
249
250 #toy example as well
251 loss = loss / max_seq_len
252 return {'loss': loss}
253 ```
254
255 **Or as basic as CNN image classification**
256
257 ```python
258 # define what happens for validation here
259 def validation_step(self, batch, batch_idx):
260 x, y = batch
261
262 # or as basic as a CNN classification
263 out = self.forward(x)
264 loss = my_loss(out, y)
265 return {'loss': loss}
266 ```
267
268 **And you also decide how to collate the output of all validation steps**
269
270 ```python
271 def validation_end(self, outputs):
272 """
273 Called at the end of validation to aggregate outputs
274 :param outputs: list of individual outputs of each validation step
275 :return:
276 """
277 val_loss_mean = 0
278 val_acc_mean = 0
279 for output in outputs:
280 val_loss_mean += output['val_loss']
281 val_acc_mean += output['val_acc']
282
283 val_loss_mean /= len(outputs)
284 val_acc_mean /= len(outputs)
285 logs = {'val_loss': val_loss_mean.item(), 'val_acc': val_acc_mean.item()}
286 result = {'log': logs}
287 return result
288 ```
289
290 ## Tensorboard
291 Lightning is fully integrated with tensorboard, MLFlow and supports any logging module.
292
293 
294
295 Lightning also adds a text column with all the hyperparameters for this experiment.
296
297 
298
299 ## Lightning automates all of the following ([each is also configurable](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.html)):
300
301
302 - [Running grid search on a cluster](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.distrib_data_parallel.html)
303 - [Fast dev run](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.utilities.debugging.html)
304 - [Logging](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.loggers.html)
305 - [Implement Your Own Distributed (DDP) training](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.lightning.html#pytorch_lightning.core.lightning.LightningModule.configure_ddp)
306 - [Multi-GPU & Multi-node](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.distrib_parts.html)
307 - [Training loop](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.training_loop.html)
308 - [Hooks](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.hooks.html)
309 - [Configure optimizers](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.core.lightning.html#pytorch_lightning.core.lightning.LightningModule.configure_optimizers)
310 - [Validations](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.evaluation_loop.html)
311 - [Model saving & Restoring training session](https://pytorch-lightning.rtfd.io/en/latest/pytorch_lightning.trainer.training_io.html)
312
313
314 ## Examples
315 - [GAN](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/domain_templates/gan.py)
316 - [MNIST](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/basic_examples)
317 - [Other projects using Lightning](https://github.com/PytorchLightning/pytorch-lightning/network/dependents?package_id=UGFja2FnZS0zNzE3NDU4OTM%3D)
318 - [Multi-node](https://github.com/PytorchLightning/pytorch-lightning/tree/master/pl_examples/multi_node_examples)
319
320 ## Tutorials
321 - [Basic Lightning use](https://towardsdatascience.com/supercharge-your-ai-research-with-pytorch-lightning-337948a99eec)
322 - [9 key speed features in Pytorch-Lightning](https://towardsdatascience.com/9-tips-for-training-lightning-fast-neural-networks-in-pytorch-8e63a502f565)
323 - [SLURM, multi-node training with Lightning](https://towardsdatascience.com/trivial-multi-node-training-with-pytorch-lightning-ff75dfb809bd)
324
325 ---
326
327 ## Asking for help
328 Welcome to the Lightning community!
329
330 If you have any questions, feel free to:
331 1. [read the docs](https://pytorch-lightning.rtfd.io/en/latest/).
332 2. [Search through the issues](https://github.com/PytorchLightning/pytorch-lightning/issues?utf8=%E2%9C%93&q=my++question).
333 3. [Ask on stackoverflow](https://stackoverflow.com/questions/ask?guided=false) with the tag pytorch-lightning.
334
335 If no one replies to you quickly enough, feel free to post the stackoverflow link to our Gitter chat!
336
337 To chat with the rest of us visit our [gitter channel](https://gitter.im/PyTorch-Lightning/community)!
338
339 ---
340 ## FAQ
341 **How do I use Lightning for rapid research?**
342 [Here's a walk-through](https://pytorch-lightning.rtfd.io/en/latest/)
343
344 **Why was Lightning created?**
345 Lightning has 3 goals in mind:
346 1. Maximal flexibility while abstracting out the common boilerplate across research projects.
347 2. Reproducibility. If all projects use the LightningModule template, it will be much much easier to understand what's going on and where to look! It will also mean every implementation follows a standard format.
348 3. Democratizing PyTorch power user features. Distributed training? 16-bit? know you need them but don't want to take the time to implement? All good... these come built into Lightning.
349
350 **How does Lightning compare with Ignite and fast.ai?**
351 [Here's a thorough comparison](https://medium.com/@_willfalcon/pytorch-lightning-vs-pytorch-ignite-vs-fast-ai-61dc7480ad8a).
352
353 **Is this another library I have to learn?**
354 Nope! We use pure Pytorch everywhere and don't add unecessary abstractions!
355
356 **Are there plans to support Python 2?**
357 Nope.
358
359 **Are there plans to support virtualenv?**
360 Nope. Please use anaconda or miniconda.
361
362 **Which PyTorch versions do you support?**
363 - **PyTorch 1.1.0**
364 ```bash
365 # install pytorch 1.1.0 using the official instructions
366
367 # install test-tube 0.6.7.6 which supports 1.1.0
368 pip install test-tube==0.6.7.6
369
370 # install latest Lightning version without upgrading deps
371 pip install -U --no-deps pytorch-lightning
372 ```
373 - **PyTorch 1.2.0, 1.3.0,**
374 Install via pip as normal
375
376 ## Custom installation
377
378 ### Bleeding edge
379
380 If you can't wait for the next release, install the most up to date code with:
381 * using GIT (locally clone whole repo with full history)
382 ```bash
383 pip install git+https://github.com/PytorchLightning/pytorch-lightning.git@master --upgrade
384 ```
385 * using instant zip (last state of the repo without git history)
386 ```bash
387 pip install https://github.com/PytorchLightning/pytorch-lightning/archive/master.zip --upgrade
388 ```
389
390 ### Any release installation
391
392 You can also install any past release `0.X.Y` from this repository:
393 ```bash
394 pip install https://github.com/PytorchLightning/pytorch-lightning/archive/0.X.Y.zip --upgrade
395 ```
396
397 ### Lightning team
398
399 #### Leads
400 - William Falcon [(williamFalcon)](https://github.com/williamFalcon) (Lightning founder)
401 - Jirka Borovec [(Borda)](https://github.com/Borda) (-_-)
402 - Ethan Harris [(ethanwharris)](https://github.com/ethanwharris) (Torchbearer founder)
403 - Matthew Painter [(MattPainter01)](https://github.com/MattPainter01) (Torchbearer founder)
404
405 #### Core Maintainers
406
407 - Nick Eggert [(neggert)](https://github.com/neggert)
408 - Jeremy Jordan [(jeremyjordan)](https://github.com/jeremyjordan)
409 - Jeff Ling [(jeffling)](https://github.com/jeffling)
410 - Tullie Murrell [(tullie)](https://github.com/tullie)
411
412 ## Bibtex
413 If you want to cite the framework feel free to use this (but only if you loved it 😊):
414 ```
415 @misc{Falcon2019,
416 author = {Falcon, W.A. et al.},
417 title = {PyTorch Lightning},
418 year = {2019},
419 publisher = {GitHub},
420 journal = {GitHub repository},
421 howpublished = {\url{https://github.com/PytorchLightning/pytorch-lightning}}
422 }
423 ```
424
[end of README.md]
[start of pytorch_lightning/trainer/distrib_parts.py]
1 """
2 Lightning makes multi-gpu training and 16 bit training trivial.
3
4 .. note:: None of the flags below require changing anything about your lightningModel definition.
5
6 Choosing a backend
7 ==================
8
9 Lightning supports two backends. DataParallel and DistributedDataParallel.
10 Both can be used for single-node multi-GPU training.
11 For multi-node training you must use DistributedDataParallel.
12
13 DataParallel (dp)
14 -----------------
15
16 Splits a batch across multiple GPUs on the same node. Cannot be used for multi-node training.
17
18 DistributedDataParallel (ddp)
19 -----------------------------
20
21 Trains a copy of the model on each GPU and only syncs gradients. If used with DistributedSampler, each GPU trains
22 on a subset of the full dataset.
23
24 DistributedDataParallel-2 (ddp2)
25 --------------------------------
26
27 Works like DDP, except each node trains a single copy of the model using ALL GPUs on that node.
28 Very useful when dealing with negative samples, etc...
29
30 You can toggle between each mode by setting this flag.
31
32 .. code-block:: python
33
34 # DEFAULT (when using single GPU or no GPUs)
35 trainer = Trainer(distributed_backend=None)
36
37 # Change to DataParallel (gpus > 1)
38 trainer = Trainer(distributed_backend='dp')
39
40 # change to distributed data parallel (gpus > 1)
41 trainer = Trainer(distributed_backend='ddp')
42
43 # change to distributed data parallel (gpus > 1)
44 trainer = Trainer(distributed_backend='ddp2')
45
46 If you request multiple nodes, the back-end will auto-switch to ddp.
47 We recommend you use DistributedDataparallel even for single-node multi-GPU training.
48 It is MUCH faster than DP but *may* have configuration issues depending on your cluster.
49
50 For a deeper understanding of what lightning is doing, feel free to read this
51 `guide <https://medium.com/@_willfalcon/9-tips-for-training-lightning-fast-neural-networks-in-pytorch-8e63a502f565>`_.
52
53 Distributed and 16-bit precision
54 --------------------------------
55
56 Due to an issue with apex and DistributedDataParallel (PyTorch and NVIDIA issue), Lightning does
57 not allow 16-bit and DP training. We tried to get this to work, but it's an issue on their end.
58
59 Below are the possible configurations we support.
60
61 +-------+---------+----+-----+---------+------------------------------------------------------------+
62 | 1 GPU | 1+ GPUs | DP | DDP | 16-bit | command |
63 +=======+=========+====+=====+=========+============================================================+
64 | Y | | | | | `Trainer(gpus=1)` |
65 +-------+---------+----+-----+---------+------------------------------------------------------------+
66 | Y | | | | Y | `Trainer(gpus=1, use_amp=True)` |
67 +-------+---------+----+-----+---------+------------------------------------------------------------+
68 | | Y | Y | | | `Trainer(gpus=k, distributed_backend='dp')` |
69 +-------+---------+----+-----+---------+------------------------------------------------------------+
70 | | Y | | Y | | `Trainer(gpus=k, distributed_backend='ddp')` |
71 +-------+---------+----+-----+---------+------------------------------------------------------------+
72 | | Y | | Y | Y | `Trainer(gpus=k, distributed_backend='ddp', use_amp=True)` |
73 +-------+---------+----+-----+---------+------------------------------------------------------------+
74
75 You also have the option of specifying which GPUs to use by passing a list:
76
77 .. code-block:: python
78
79 # DEFAULT (int) specifies how many GPUs to use.
80 Trainer(gpus=k)
81
82 # Above is equivalent to
83 Trainer(gpus=list(range(k)))
84
85 # You specify which GPUs (don't use if running on cluster)
86 Trainer(gpus=[0, 1])
87
88 # can also be a string
89 Trainer(gpus='0, 1')
90
91 # can also be -1 or '-1', this uses all available GPUs
92 # this is equivalent to list(range(torch.cuda.available_devices()))
93 Trainer(gpus=-1)
94
95
96 CUDA flags
97 ----------
98
99 CUDA flags make certain GPUs visible to your script.
100 Lightning sets these for you automatically, there's NO NEED to do this yourself.
101
102 .. code-block:: python
103
104 # lightning will set according to what you give the trainer
105 os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
106 os.environ["CUDA_VISIBLE_DEVICES"] = "0"
107
108
109 However, when using a cluster, Lightning will NOT set these flags (and you should not either).
110 SLURM will set these for you.
111
112 16-bit mixed precision
113 ----------------------
114
115 16 bit precision can cut your memory footprint by half. If using volta architecture GPUs
116 it can give a dramatic training speed-up as well.
117 First, install apex (if install fails, look `here <https://github.com/NVIDIA/apex>`_::
118
119 $ git clone https://github.com/NVIDIA/apex
120 $ cd apex
121
122 # ------------------------
123 # OPTIONAL: on your cluster you might need to load cuda 10 or 9
124 # depending on how you installed PyTorch
125
126 # see available modules
127 module avail
128
129 # load correct cuda before install
130 module load cuda-10.0
131 # ------------------------
132
133 # make sure you've loaded a cuda version > 4.0 and < 7.0
134 module load gcc-6.1.0
135
136 $ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
137
138
139 then set this use_amp to True.::
140
141 # DEFAULT
142 trainer = Trainer(amp_level='O2', use_amp=False)
143
144
145 Single-gpu
146 ----------
147
148 Make sure you're on a GPU machine.::
149
150 # DEFAULT
151 trainer = Trainer(gpus=1)
152
153 Multi-gpu
154 ---------
155
156 Make sure you're on a GPU machine. You can set as many GPUs as you want.
157 In this setting, the model will run on all 8 GPUs at once using DataParallel under the hood.
158
159 .. code-block:: python
160
161 # to use DataParallel
162 trainer = Trainer(gpus=8, distributed_backend='dp')
163
164 # RECOMMENDED use DistributedDataParallel
165 trainer = Trainer(gpus=8, distributed_backend='ddp')
166
167 Custom device selection
168 -----------------------
169
170 The number of GPUs can also be selected with a list of indices or a string containing
171 a comma separated list of GPU ids.
172 The table below lists examples of possible input formats and how they are interpreted by Lightning.
173 Note in particular the difference between `gpus=0`, `gpus=[0]` and `gpus="0"`.
174
175 +---------------+-----------+---------------------+---------------------------------+
176 | `gpus` | Type | Parsed | Meaning |
177 +===============+===========+=====================+=================================+
178 | None | NoneType | None | CPU |
179 +---------------+-----------+---------------------+---------------------------------+
180 | 0 | int | None | CPU |
181 +---------------+-----------+---------------------+---------------------------------+
182 | 3 | int | [0, 1, 2] | first 3 GPUs |
183 +---------------+-----------+---------------------+---------------------------------+
184 | -1 | int | [0, 1, 2, ...] | all available GPUs |
185 +---------------+-----------+---------------------+---------------------------------+
186 | [0] | list | [0] | GPU 0 |
187 +---------------+-----------+---------------------+---------------------------------+
188 | [1, 3] | list | [1, 3] | GPUs 1 and 3 |
189 +---------------+-----------+---------------------+---------------------------------+
190 | "0" | str | [0] | GPU 0 |
191 +---------------+-----------+---------------------+---------------------------------+
192 | "3" | str | [3] | GPU 3 |
193 +---------------+-----------+---------------------+---------------------------------+
194 | "1, 3" | str | [1, 3] | GPUs 1 and 3 |
195 +---------------+-----------+---------------------+---------------------------------+
196 | "-1" | str | [0, 1, 2, ...] | all available GPUs |
197 +---------------+-----------+---------------------+---------------------------------+
198
199
200 Multi-node
201 ----------
202
203 Multi-node training is easily done by specifying these flags.
204
205 .. code-block:: python
206
207 # train on 12*8 GPUs
208 trainer = Trainer(gpus=8, num_nodes=12, distributed_backend='ddp')
209
210
211 You must configure your job submission script correctly for the trainer to work.
212 Here is an example script for the above trainer configuration.
213
214 .. code-block:: bash
215
216 #!/bin/bash -l
217
218 # SLURM SUBMIT SCRIPT
219 #SBATCH --nodes=12
220 #SBATCH --gres=gpu:8
221 #SBATCH --ntasks-per-node=8
222 #SBATCH --mem=0
223 #SBATCH --time=0-02:00:00
224
225 # activate conda env
226 conda activate my_env
227
228 # -------------------------
229 # OPTIONAL
230 # -------------------------
231 # debugging flags (optional)
232 # export NCCL_DEBUG=INFO
233 # export PYTHONFAULTHANDLER=1
234
235 # PyTorch comes with prebuilt NCCL support... but if you have issues with it
236 # you might need to load the latest version from your modules
237 # module load NCCL/2.4.7-1-cuda.10.0
238
239 # on your cluster you might need these:
240 # set the network interface
241 # export NCCL_SOCKET_IFNAME=^docker0,lo
242 # -------------------------
243
244 # random port between 12k and 20k
245 export MASTER_PORT=$((12000 + RANDOM % 20000))
246
247 # run script from above
248 python my_main_file.py
249
250 .. note:: When running in DDP mode, any errors in your code will show up as an NCCL issue.
251 Set the `NCCL_DEBUG=INFO` flag to see the ACTUAL error.
252
253 Finally, make sure to add a distributed sampler to your dataset. The distributed sampler copies a
254 portion of your dataset onto each GPU. (World_size = gpus_per_node * nb_nodes).
255
256 .. code-block:: python
257
258 # ie: this:
259 dataset = myDataset()
260 dataloader = Dataloader(dataset)
261
262 # becomes:
263 dataset = myDataset()
264 dist_sampler = torch.utils.data.distributed.DistributedSampler(dataset)
265 dataloader = Dataloader(dataset, sampler=dist_sampler)
266
267
268 Auto-slurm-job-submission
269 -------------------------
270
271 Instead of manually building SLURM scripts, you can use the
272 `SlurmCluster object <https://williamfalcon.github.io/test-tube/hpc/SlurmCluster>`_
273 to do this for you. The SlurmCluster can also run a grid search if you pass
274 in a `HyperOptArgumentParser
275 <https://williamfalcon.github.io/test-tube/hyperparameter_optimization/HyperOptArgumentParser>`_.
276
277 Here is an example where you run a grid search of 9 combinations of hyperparams.
278 The full examples are
279 `here <https://git.io/Jv87p>`_.
280
281 .. code-block:: python
282
283 # grid search 3 values of learning rate and 3 values of number of layers for your net
284 # this generates 9 experiments (lr=1e-3, layers=16), (lr=1e-3, layers=32),
285 # (lr=1e-3, layers=64), ... (lr=1e-1, layers=64)
286 parser = HyperOptArgumentParser(strategy='grid_search', add_help=False)
287 parser.opt_list('--learning_rate', default=0.001, type=float,
288 options=[1e-3, 1e-2, 1e-1], tunable=True)
289 parser.opt_list('--layers', default=1, type=float, options=[16, 32, 64], tunable=True)
290 hyperparams = parser.parse_args()
291
292 # Slurm cluster submits 9 jobs, each with a set of hyperparams
293 cluster = SlurmCluster(
294 hyperparam_optimizer=hyperparams,
295 log_path='/some/path/to/save',
296 )
297
298 # OPTIONAL FLAGS WHICH MAY BE CLUSTER DEPENDENT
299 # which interface your nodes use for communication
300 cluster.add_command('export NCCL_SOCKET_IFNAME=^docker0,lo')
301
302 # see output of the NCCL connection process
303 # NCCL is how the nodes talk to each other
304 cluster.add_command('export NCCL_DEBUG=INFO')
305
306 # setting a master port here is a good idea.
307 cluster.add_command('export MASTER_PORT=%r' % PORT)
308
309 # ************** DON'T FORGET THIS ***************
310 # MUST load the latest NCCL version
311 cluster.load_modules(['NCCL/2.4.7-1-cuda.10.0'])
312
313 # configure cluster
314 cluster.per_experiment_nb_nodes = 12
315 cluster.per_experiment_nb_gpus = 8
316
317 cluster.add_slurm_cmd(cmd='ntasks-per-node', value=8, comment='1 task per gpu')
318
319 # submit a script with 9 combinations of hyper params
320 # (lr=1e-3, layers=16), (lr=1e-3, layers=32), (lr=1e-3, layers=64), ... (lr=1e-1, layers=64)
321 cluster.optimize_parallel_cluster_gpu(
322 main,
323 nb_trials=9, # how many permutations of the grid search to run
324 job_name='name_for_squeue'
325 )
326
327
328 The other option is that you generate scripts on your own via a bash command or use another library...
329
330 Self-balancing architecture
331 ---------------------------
332
333 Here lightning distributes parts of your module across available GPUs to optimize for speed and memory.
334
335 """
336
337 from abc import ABC, abstractmethod
338 import logging as log
339 import os
340 import signal
341
342 import torch
343
344 from pytorch_lightning.overrides.data_parallel import (
345 LightningDistributedDataParallel,
346 LightningDataParallel,
347 )
348 from pytorch_lightning.utilities.debugging import MisconfigurationException
349
350 try:
351 from apex import amp
352 except ImportError:
353 APEX_AVAILABLE = False
354 else:
355 APEX_AVAILABLE = True
356
357 try:
358 import torch_xla.core.xla_model as xm
359 except ImportError:
360 XLA_AVAILABLE = False
361 else:
362 XLA_AVAILABLE = True
363
364
365 class TrainerDPMixin(ABC):
366
367 # this is just a summary on variables used in this abstract class,
368 # the proper values/initialisation should be done in child class
369 on_gpu: bool
370 use_dp: bool
371 use_ddp2: bool
372 use_ddp: bool
373 use_amp: bool
374 testing: bool
375 single_gpu: bool
376 root_gpu: ...
377 amp_level: str
378 precision: ...
379 current_tpu_idx: ...
380 proc_rank: int
381 tpu_local_core_rank: int
382 tpu_global_core_rank: int
383 use_tpu: bool
384 data_parallel_device_ids: ...
385
386 @abstractmethod
387 def run_pretrain_routine(self, *args):
388 """Warning: this is just empty shell for code implemented in other class."""
389
390 @abstractmethod
391 def init_optimizers(self, *args):
392 """Warning: this is just empty shell for code implemented in other class."""
393
394 def copy_trainer_model_properties(self, model):
395 if isinstance(model, LightningDataParallel):
396 ref_model = model.module
397 elif isinstance(model, LightningDistributedDataParallel):
398 ref_model = model.module
399 else:
400 ref_model = model
401
402 for m in [model, ref_model]:
403 m.trainer = self
404 m.on_gpu = self.on_gpu
405 m.use_dp = self.use_dp
406 m.use_ddp2 = self.use_ddp2
407 m.use_ddp = self.use_ddp
408 m.use_amp = self.use_amp
409 m.testing = self.testing
410 m.single_gpu = self.single_gpu
411 m.use_tpu = self.use_tpu
412 m.tpu_local_core_rank = self.tpu_local_core_rank
413 m.tpu_global_core_rank = self.tpu_global_core_rank
414
415 def transfer_batch_to_tpu(self, batch):
416 return self.__transfer_data_to_device(batch, device='tpu')
417
418 def transfer_batch_to_gpu(self, batch, gpu_id):
419 return self.__transfer_data_to_device(batch, device='gpu', gpu_id=gpu_id)
420
421 def __transfer_data_to_device(self, batch, device, gpu_id=None):
422 if device == 'tpu' and XLA_AVAILABLE:
423 # base case: object can be directly moved using `to`
424 if callable(getattr(batch, 'to', None)):
425 return batch.to(xm.xla_device())
426
427 if device == 'gpu':
428 # base case: object can be directly moved using `cuda` or `to`
429 if callable(getattr(batch, 'cuda', None)):
430 return batch.cuda(gpu_id)
431
432 if callable(getattr(batch, 'to', None)):
433 return batch.to(torch.device('cuda', gpu_id))
434
435 # when list
436 if isinstance(batch, list):
437 for i, x in enumerate(batch):
438 batch[i] = self.__transfer_data_to_device(x, device, gpu_id)
439 return batch
440
441 # when tuple
442 if isinstance(batch, tuple):
443 batch = list(batch)
444 for i, x in enumerate(batch):
445 batch[i] = self.__transfer_data_to_device(x, device, gpu_id)
446 return tuple(batch)
447
448 # when dict
449 if isinstance(batch, dict):
450 for k, v in batch.items():
451 batch[k] = self.__transfer_data_to_device(v, device, gpu_id)
452
453 return batch
454
455 # nothing matches, return the value as is without transform
456 return batch
457
458 def single_gpu_train(self, model):
459 model.cuda(self.root_gpu)
460
461 # CHOOSE OPTIMIZER
462 # allow for lr schedulers as well
463 self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
464
465 if self.use_amp:
466 # An example
467 model, optimizers = model.configure_apex(amp, model, self.optimizers, self.amp_level)
468 self.optimizers = optimizers
469
470 self.run_pretrain_routine(model)
471
472 def tpu_train(self, tpu_core_idx, model):
473 # put model on tpu
474 model.to(xm.xla_device())
475
476 # get the appropriate tpu ranks
477 self.tpu_local_core_rank = xm.get_local_ordinal()
478 self.tpu_global_core_rank = xm.get_ordinal()
479
480 # avoid duplicating progress bar
481 self.show_progress_bar = self.show_progress_bar and self.tpu_global_core_rank == 0
482
483 # track current tpu
484 self.current_tpu_idx = tpu_core_idx
485 self.proc_rank = self.tpu_local_core_rank
486
487 # CHOOSE OPTIMIZER
488 # allow for lr schedulers as well
489 self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
490
491 # init 16 bit for TPU
492 if self.precision == 16:
493 os.environ['XLA_USE_BF16'] = str(1)
494
495 m = f'INIT TPU local core: {self.tpu_local_core_rank}, ' \
496 f'global rank: {self.tpu_global_core_rank}'
497 log.info(m)
498
499 # continue training routine
500 self.run_pretrain_routine(model)
501
502 self.save_spawn_weights(model)
503
504 def dp_train(self, model):
505
506 # CHOOSE OPTIMIZER
507 # allow for lr schedulers as well
508 self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
509
510 model.cuda(self.root_gpu)
511
512 # check for this bug (amp + dp + !01 doesn't work)
513 # https://github.com/NVIDIA/apex/issues/227
514 if self.use_dp and self.use_amp:
515 if self.amp_level == 'O2':
516 m = f"""
517 Amp level {self.amp_level} with DataParallel is not supported.
518 See this note from NVIDIA for more info: https://github.com/NVIDIA/apex/issues/227.
519 We recommend you switch to ddp if you want to use amp
520 """
521 raise MisconfigurationException(m)
522 else:
523 model, optimizers = model.configure_apex(amp, model, self.optimizers, self.amp_level)
524
525 # create list of device ids
526 device_ids = self.data_parallel_device_ids
527 if isinstance(device_ids, int):
528 device_ids = list(range(device_ids))
529
530 model = LightningDataParallel(model, device_ids=device_ids)
531
532 self.run_pretrain_routine(model)
533
534
535 def normalize_parse_gpu_string_input(s):
536 if isinstance(s, str):
537 if s == '-1':
538 return -1
539 else:
540 return [int(x.strip()) for x in s.split(',')]
541 else:
542 return s
543
544
545 def get_all_available_gpus():
546 """
547 :return: a list of all available gpus
548 """
549 return list(range(torch.cuda.device_count()))
550
551
552 def check_gpus_data_type(gpus):
553 """
554 :param gpus: gpus parameter as passed to the Trainer
555 Function checks that it is one of: None, Int, String or List
556 Throws otherwise
557 :return: return unmodified gpus variable
558 """
559
560 if gpus is not None and type(gpus) not in (int, str, list):
561 raise MisconfigurationException("GPUs must be int, string or list of ints or None.")
562
563
564 def normalize_parse_gpu_input_to_list(gpus):
565 assert gpus is not None
566 if isinstance(gpus, list):
567 return gpus
568
569 # must be an int
570 if not gpus: # gpus==0
571 return None
572 if gpus == -1:
573 return get_all_available_gpus()
574
575 return list(range(gpus))
576
577
578 def sanitize_gpu_ids(gpus):
579 """
580 :param gpus: list of ints corresponding to GPU indices
581 Checks that each of the GPUs in the list is actually available.
582 Throws if any of the GPUs is not available.
583 :return: unmodified gpus variable
584 """
585 all_available_gpus = get_all_available_gpus()
586 for gpu in gpus:
587 if gpu not in all_available_gpus:
588 message = f"""
589 You requested GPUs: {gpus}
590 But your machine only has: {all_available_gpus}
591 """
592 raise MisconfigurationException(message)
593 return gpus
594
595
596 def parse_gpu_ids(gpus):
597 """
598 :param gpus: Int, string or list
599 An int -1 or string '-1' indicate that all available GPUs should be used.
600 A list of ints or a string containing list of comma separated integers
601 indicates specific GPUs to use
602 An int 0 means that no GPUs should be used
603 Any int N > 0 indicates that GPUs [0..N) should be used.
604 :return: List of gpus to be used
605
606 If no GPUs are available but the value of gpus variable indicates request for GPUs
607 then a misconfiguration exception is raised.
608 """
609
610 # Check that gpus param is None, Int, String or List
611 check_gpus_data_type(gpus)
612
613 # Handle the case when no gpus are requested
614 if gpus is None or isinstance(gpus, int) and gpus == 0:
615 return None
616
617 # We know user requested GPUs therefore if some of the
618 # requested GPUs are not available an exception is thrown.
619
620 gpus = normalize_parse_gpu_string_input(gpus)
621 gpus = normalize_parse_gpu_input_to_list(gpus)
622 gpus = sanitize_gpu_ids(gpus)
623
624 if not gpus:
625 raise MisconfigurationException("GPUs requested but none are available.")
626 return gpus
627
628
629 def determine_root_gpu_device(gpus):
630 """
631 :param gpus: non empty list of ints representing which gpus to use
632 :return: designated root GPU device
633 """
634 if gpus is None:
635 return None
636
637 assert isinstance(gpus, list), "gpus should be a list"
638 assert len(gpus) > 0, "gpus should be a non empty list"
639
640 # set root gpu
641 root_gpu = gpus[0]
642
643 return root_gpu
644
[end of pytorch_lightning/trainer/distrib_parts.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| Lightning-AI/lightning | bcb45d906d5f378a30461d513728cad34fc647ce | Support stepping options for lr scheduler
Currently schedulers get called every epoch. Sometimes though, we want them to be called every step.
Proposal 1:
Allow configure_optimizers to return this:
```python
return Adam, {'scheduler': LRScheduler, 'interval': 'batch|epoch'}
```
@ethanwharris @Borda thoughts? any simpler more general way of doing this? i think this dict can eventually have more options if we need to.
@srush
| 2020-02-25T15:48:00Z | <patch>
diff --git a/pytorch_lightning/core/lightning.py b/pytorch_lightning/core/lightning.py
--- a/pytorch_lightning/core/lightning.py
+++ b/pytorch_lightning/core/lightning.py
@@ -758,6 +758,15 @@ def configure_optimizers(self):
discriminator_sched = CosineAnnealing(discriminator_opt, T_max=10)
return [generator_opt, disriminator_opt], [discriminator_sched]
+ # example with step-based learning_rate schedulers
+ def configure_optimizers(self):
+ gen_opt = Adam(self.model_gen.parameters(), lr=0.01)
+ dis_opt = Adam(self.model_disc.parameters(), lr=0.02)
+ gen_sched = {'scheduler': ExponentialLR(gen_opt, 0.99),
+ 'interval': 'step'} # called after each training step
+ dis_sched = CosineAnnealing(discriminator_opt, T_max=10) # called after each epoch
+ return [gen_opt, dis_opt], [gen_sched, dis_sched]
+
.. note:: Lightning calls .backward() and .step() on each optimizer and learning rate scheduler as needed.
.. note:: If you use 16-bit precision (use_amp=True), Lightning will automatically
@@ -773,6 +782,8 @@ def configure_optimizers(self):
.. note:: If you need to control how often those optimizers step or override the default .step() schedule,
override the `optimizer_step` hook.
+ .. note:: If you only want to call a learning rate schduler every `x` step or epoch,
+ you can input this as 'frequency' key: dict(scheduler=lr_schudler, interval='step' or 'epoch', frequency=x)
"""
return Adam(self.parameters(), lr=1e-3)
diff --git a/pytorch_lightning/trainer/trainer.py b/pytorch_lightning/trainer/trainer.py
--- a/pytorch_lightning/trainer/trainer.py
+++ b/pytorch_lightning/trainer/trainer.py
@@ -6,6 +6,7 @@
from argparse import ArgumentParser
import torch
+from torch import optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.utils.data import DataLoader
@@ -743,8 +744,6 @@ def on_train_end(self):
# creates a default one if none passed in
self.configure_early_stopping(early_stop_callback)
- self.reduce_lr_on_plateau_scheduler = None
-
# configure checkpoint callback
self.checkpoint_callback = checkpoint_callback
self.weights_save_path = weights_save_path
@@ -1079,26 +1078,56 @@ def init_optimizers(
optimizers: Union[Optimizer, Tuple[List, List], List[Optimizer], Tuple[Optimizer]]
) -> Tuple[List, List]:
- # single optimizer
+ # single output, single optimizer
if isinstance(optimizers, Optimizer):
return [optimizers], []
- # two lists
- if len(optimizers) == 2 and isinstance(optimizers[0], list):
+ # two lists, optimizer + lr schedulers
+ elif len(optimizers) == 2 and isinstance(optimizers[0], list):
optimizers, lr_schedulers = optimizers
- lr_schedulers, self.reduce_lr_on_plateau_scheduler = self.configure_schedulers(lr_schedulers)
+ lr_schedulers = self.configure_schedulers(lr_schedulers)
return optimizers, lr_schedulers
- # single list or tuple
- if isinstance(optimizers, (list, tuple)):
+ # single list or tuple, multiple optimizer
+ elif isinstance(optimizers, (list, tuple)):
return optimizers, []
+ # unknown configuration
+ else:
+ raise ValueError('Unknown configuration for model optimizers. Output'
+ 'from model.configure_optimizers() should either be:'
+ '* single output, single torch.optim.Optimizer'
+ '* single output, list of torch.optim.Optimizer'
+ '* two outputs, first being a list of torch.optim.Optimizer',
+ 'second being a list of torch.optim.lr_scheduler')
+
def configure_schedulers(self, schedulers: list):
- for i, scheduler in enumerate(schedulers):
- if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
- reduce_lr_on_plateau_scheduler = schedulers.pop(i)
- return schedulers, reduce_lr_on_plateau_scheduler
- return schedulers, None
+ # Convert each scheduler into dict sturcture with relevant information
+ lr_schedulers = []
+ default_config = {'interval': 'epoch', # default every epoch
+ 'frequency': 1, # default every epoch/batch
+ 'reduce_on_plateau': False, # most often not ReduceLROnPlateau scheduler
+ 'monitor': 'val_loss'} # default value to monitor for ReduceLROnPlateau
+ for scheduler in schedulers:
+ if isinstance(scheduler, dict):
+ if 'scheduler' not in scheduler:
+ raise ValueError(f'Lr scheduler should have key `scheduler`',
+ ' with item being a lr scheduler')
+ scheduler['reduce_on_plateau'] = \
+ isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau)
+
+ lr_schedulers.append({**default_config, **scheduler})
+
+ elif isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau):
+ lr_schedulers.append({**default_config, 'scheduler': scheduler,
+ 'reduce_on_plateau': True})
+
+ elif isinstance(scheduler, optim.lr_scheduler._LRScheduler):
+ lr_schedulers.append({**default_config, 'scheduler': scheduler})
+ else:
+ raise ValueError(f'Input {scheduler} to lr schedulers '
+ 'is a invalid input.')
+ return lr_schedulers
def run_pretrain_routine(self, model: LightningModule):
"""Sanity check a few things before starting actual training.
diff --git a/pytorch_lightning/trainer/training_io.py b/pytorch_lightning/trainer/training_io.py
--- a/pytorch_lightning/trainer/training_io.py
+++ b/pytorch_lightning/trainer/training_io.py
@@ -1,3 +1,94 @@
+"""
+Lightning can automate saving and loading checkpoints
+=====================================================
+
+Checkpointing is enabled by default to the current working directory.
+To change the checkpoint path pass in::
+
+ Trainer(default_save_path='/your/path/to/save/checkpoints')
+
+
+To modify the behavior of checkpointing pass in your own callback.
+
+.. code-block:: python
+
+ from pytorch_lightning.callbacks import ModelCheckpoint
+
+ # DEFAULTS used by the Trainer
+ checkpoint_callback = ModelCheckpoint(
+ filepath=os.getcwd(),
+ save_best_only=True,
+ verbose=True,
+ monitor='val_loss',
+ mode='min',
+ prefix=''
+ )
+
+ trainer = Trainer(checkpoint_callback=checkpoint_callback)
+
+
+Restoring training session
+--------------------------
+
+You might want to not only load a model but also continue training it. Use this method to
+restore the trainer state as well. This will continue from the epoch and global step you last left off.
+However, the dataloaders will start from the first batch again (if you shuffled it shouldn't matter).
+
+Lightning will restore the session if you pass a logger with the same version and there's a saved checkpoint.
+
+.. code-block:: python
+
+ from pytorch_lightning import Trainer
+ from pytorch_lightning.loggers import TestTubeLogger
+
+ logger = TestTubeLogger(
+ save_dir='./savepath',
+ version=1 # An existing version with a saved checkpoint
+ )
+ trainer = Trainer(
+ logger=logger,
+ default_save_path='./savepath'
+ )
+
+ # this fit call loads model weights and trainer state
+ # the trainer continues seamlessly from where you left off
+ # without having to do anything else.
+ trainer.fit(model)
+
+
+The trainer restores:
+
+- global_step
+- current_epoch
+- All optimizers
+- All lr_schedulers
+- Model weights
+
+You can even change the logic of your model as long as the weights and "architecture" of
+the system isn't different. If you add a layer, for instance, it might not work.
+
+At a rough level, here's what happens inside Trainer :py:mod:`pytorch_lightning.base_module.model_saving.py`:
+
+.. code-block:: python
+
+ self.global_step = checkpoint['global_step']
+ self.current_epoch = checkpoint['epoch']
+
+ # restore the optimizers
+ optimizer_states = checkpoint['optimizer_states']
+ for optimizer, opt_state in zip(self.optimizers, optimizer_states):
+ optimizer.load_state_dict(opt_state)
+
+ # restore the lr schedulers
+ lr_schedulers = checkpoint['lr_schedulers']
+ for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
+ scheduler['scheduler'].load_state_dict(lrs_state)
+
+ # uses the model you passed into trainer
+ model.load_state_dict(checkpoint['state_dict'])
+
+"""
+
import logging as log
import os
import re
@@ -228,8 +319,8 @@ def dump_checkpoint(self):
# save lr schedulers
lr_schedulers = []
- for i, scheduler in enumerate(self.lr_schedulers):
- lr_schedulers.append(scheduler.state_dict())
+ for scheduler in self.lr_schedulers:
+ lr_schedulers.append(scheduler['scheduler'].state_dict())
checkpoint['lr_schedulers'] = lr_schedulers
@@ -320,7 +411,7 @@ def restore_training_state(self, checkpoint):
# restore the lr schedulers
lr_schedulers = checkpoint['lr_schedulers']
for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
- scheduler.load_state_dict(lrs_state)
+ scheduler['scheduler'].load_state_dict(lrs_state)
# ----------------------------------
# PRIVATE OPS
diff --git a/pytorch_lightning/trainer/training_loop.py b/pytorch_lightning/trainer/training_loop.py
--- a/pytorch_lightning/trainer/training_loop.py
+++ b/pytorch_lightning/trainer/training_loop.py
@@ -361,17 +361,7 @@ def train(self):
self.run_training_epoch()
# update LR schedulers
- if self.lr_schedulers is not None:
- for lr_scheduler in self.lr_schedulers:
- lr_scheduler.step()
- if self.reduce_lr_on_plateau_scheduler is not None:
- val_loss = self.callback_metrics.get('val_loss')
- if val_loss is None:
- avail_metrics = ','.join(list(self.callback_metrics.keys()))
- m = f'ReduceLROnPlateau conditioned on metric val_loss ' \
- f'which is not available. Available metrics are: {avail_metrics}'
- raise MisconfigurationException(m)
- self.reduce_lr_on_plateau_scheduler.step(val_loss)
+ self.update_learning_rates(interval='epoch')
if self.max_steps and self.max_steps == self.global_step:
self.run_training_teardown()
@@ -444,6 +434,9 @@ def run_training_epoch(self):
# when returning -1 from train_step, we end epoch early
early_stop_epoch = batch_result == -1
+ # update lr
+ self.update_learning_rates(interval='step')
+
# ---------------
# RUN VAL STEP
# ---------------
@@ -716,6 +709,34 @@ def training_forward(self, batch, batch_idx, opt_idx, hiddens):
return output
+ def update_learning_rates(self, interval):
+ ''' Update learning rates
+ Args:
+ interval (str): either 'epoch' or 'step'.
+ '''
+ if not self.lr_schedulers:
+ return
+
+ for lr_scheduler in self.lr_schedulers:
+ current_idx = self.batch_idx if interval == 'step' else self.current_epoch
+ current_idx += 1 # account for both batch and epoch starts from 0
+ # Take step if call to update_learning_rates matches the interval key and
+ # the current step modulo the schedulers frequency is zero
+ if lr_scheduler['interval'] == interval and current_idx % lr_scheduler['frequency'] == 0:
+ # If instance of ReduceLROnPlateau, we need to pass validation loss
+ if lr_scheduler['reduce_on_plateau']:
+ monitor_key = lr_scheduler['monitor']
+ monitor_val = self.callback_metrics.get(monitor_key)
+ if monitor_val is None:
+ avail_metrics = ','.join(list(self.callback_metrics.keys()))
+ m = f'ReduceLROnPlateau conditioned on metric {monitor_key} ' \
+ f'which is not available. Available metrics are: {avail_metrics}. ' \
+ 'Condition can be set using `monitor` key in lr scheduler dict'
+ raise MisconfigurationException(m)
+ lr_scheduler['scheduler'].step(monitor_val)
+ else:
+ lr_scheduler['scheduler'].step()
+
def call_checkpoint_callback(self):
if self.checkpoint_callback is not None:
self.checkpoint_callback.on_validation_end(self, self.get_model())
</patch> | [] | [] | ||||
PrefectHQ__prefect-1386 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`auth login` CLI check needs token required query
## Description
`prefect auth login` runs a graphql query to verify the token provided is valid. The current query is `query { hello }` and this query does not require authentication. This query needs to be updated to one which requires authentication (which is every other query, let's just find the smallest one)
## Expected Behavior
If the token is invalid it should elevate an error to the user
## Reproduction
Query the API with `query { hello }` without a token and it will still work.
## Environment
N/A
</issue>
<code>
[start of README.md]
1 <p align="center" style="margin-bottom:40px;">
2 <img src="https://uploads-ssl.webflow.com/5ba446b0e783e26d5a2f2382/5c942c9ca934ec5c88588297_primary-color-vertical.svg" height=350 style="max-height: 350px;">
3 </p>
4
5 <p align="center">
6 <a href=https://circleci.com/gh/PrefectHQ/prefect/tree/master>
7 <img src="https://circleci.com/gh/PrefectHQ/prefect/tree/master.svg?style=shield&circle-token=28689a55edc3c373486aaa5f11a1af3e5fc53344">
8 </a>
9
10 <a href="https://codecov.io/gh/PrefectHQ/prefect">
11 <img src="https://codecov.io/gh/PrefectHQ/prefect/branch/master/graph/badge.svg" />
12 </a>
13
14 <a href=https://github.com/ambv/black>
15 <img src="https://img.shields.io/badge/code%20style-black-000000.svg">
16 </a>
17
18 <a href="https://pypi.org/project/prefect/">
19 <img src="https://img.shields.io/pypi/dm/prefect.svg?color=%2327B1FF&label=installs&logoColor=%234D606E">
20 </a>
21
22 <a href="https://hub.docker.com/r/prefecthq/prefect">
23 <img src="https://img.shields.io/docker/pulls/prefecthq/prefect.svg?color=%2327B1FF&logoColor=%234D606E">
24 </a>
25
26 <a href="https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU">
27 <img src="https://img.shields.io/static/v1.svg?label=chat&message=on%20slack&color=27b1ff&style=flat">
28 </a>
29
30 </p>
31
32 ## Hello, world! 👋
33
34 We've rebuilt data engineering for the data science era.
35
36 Prefect is a new workflow management system, designed for modern infrastructure and powered by the open-source Prefect Core workflow engine. Users organize `Tasks` into `Flows`, and Prefect takes care of the rest.
37
38 Read the [docs](https://docs.prefect.io); get the [code](#installation); ask us [anything](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU)!
39
40 ```python
41 from prefect import task, Flow
42
43
44 @task
45 def say_hello():
46 print("Hello, world!")
47
48
49 with Flow("My First Flow") as flow:
50 say_hello()
51
52
53 flow.run() # "Hello, world!"
54 ```
55
56 ## Docs
57
58 Prefect's documentation -- including concepts, tutorials, and a full API reference -- is always available at [docs.prefect.io](https://docs.prefect.io).
59
60 ## Contributing
61
62 Read about Prefect's [community](https://docs.prefect.io/guide/welcome/community.html) or dive in to the [development guides](https://docs.prefect.io/guide/development/overview.html) for information about contributions, documentation, code style, and testing.
63
64 Join our [Slack](https://join.slack.com/t/prefect-public/shared_invite/enQtNzE5OTU3OTQwNzc1LTQ5M2FkZmQzZjI0ODg1ZTBmOTc0ZjVjYWFjMWExZDAyYzBmYjVmMTE1NTQ1Y2IxZTllOTc4MmI3NzYxMDlhYWU) to chat about Prefect, ask questions, and share tips.
65
66 Prefect is committed to ensuring a positive environment. All interactions are governed by our [Code of Conduct](https://docs.prefect.io/guide/welcome/code_of_conduct.html).
67
68 ## "...Prefect?"
69
70 From the Latin _praefectus_, meaning "one who is in charge", a prefect is an official who oversees a domain and makes sure that the rules are followed. Similarly, Prefect is responsible for making sure that workflows execute properly.
71
72 It also happens to be the name of a roving researcher for that wholly remarkable book, _The Hitchhiker's Guide to the Galaxy_.
73
74 ## Installation
75
76 ### Requirements
77
78 Prefect requires Python 3.5.2+.
79
80 ### Install latest release
81
82 Using `pip`:
83
84 ```bash
85 pip install prefect
86 ```
87
88 or `conda`:
89
90 ```bash
91 conda install -c conda-forge prefect
92 ```
93
94 or `pipenv`:
95 ```
96 pipenv install --pre prefect
97 ```
98
99 ### Install bleeding edge
100
101 ```bash
102 git clone https://github.com/PrefectHQ/prefect.git
103 pip install ./prefect
104 ```
105
106 ## License
107
108 Prefect is licensed under the Apache Software License version 2.0.
109
[end of README.md]
[start of src/prefect/agent/agent.py]
1 import logging
2 from typing import Union
3
4 import pendulum
5 import time
6
7 from prefect import config
8 from prefect.client import Client
9 from prefect.serialization import state
10 from prefect.engine.state import Submitted
11 from prefect.utilities.graphql import with_args
12
13
14 ascii_name = r"""
15 ____ __ _ _ _
16 | _ \ _ __ ___ / _| ___ ___| |_ / \ __ _ ___ _ __ | |_
17 | |_) | '__/ _ \ |_ / _ \/ __| __| / _ \ / _` |/ _ \ '_ \| __|
18 | __/| | | __/ _| __/ (__| |_ / ___ \ (_| | __/ | | | |_
19 |_| |_| \___|_| \___|\___|\__| /_/ \_\__, |\___|_| |_|\__|
20 |___/
21 """
22
23
24 class Agent:
25 """
26 Base class for Agents.
27
28 This Agent class is a standard point for executing Flows in Prefect Cloud. It is meant
29 to have subclasses which inherit functionality from this class. The only piece that
30 the subclasses should implement is the `deploy_flows` function, which specifies how to run a Flow on the given platform. It is built in this
31 way to keep Prefect Cloud logic standard but allows for platform specific
32 customizability.
33
34 In order for this to operate `PREFECT__CLOUD__AGENT__AUTH_TOKEN` must be set as an
35 environment variable or in your user configuration file.
36 """
37
38 def __init__(self) -> None:
39 self.loop_interval = config.cloud.agent.get("loop_interval")
40
41 self.client = Client(token=config.cloud.agent.get("auth_token"))
42
43 logger = logging.getLogger("agent")
44 logger.setLevel(logging.DEBUG)
45 ch = logging.StreamHandler()
46 ch.setLevel(logging.DEBUG)
47 formatter = logging.Formatter(
48 "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
49 )
50 ch.setFormatter(formatter)
51 logger.addHandler(ch)
52
53 self.logger = logger
54
55 def start(self) -> None:
56 """
57 The main entrypoint to the agent. This function loops and constantly polls for
58 new flow runs to deploy
59 """
60 tenant_id = self.agent_connect()
61 while True:
62 self.agent_process(tenant_id)
63 time.sleep(self.loop_interval)
64
65 def agent_connect(self) -> str:
66 """
67 Verify agent connection to Prefect Cloud by finding and returning a tenant id
68
69 Returns:
70 - str: The current tenant id
71 """
72 print(ascii_name)
73 self.logger.info("Starting {}".format(type(self).__name__))
74 self.logger.info(
75 "Agent documentation can be found at https://docs.prefect.io/cloud/agent"
76 )
77 tenant_id = self.query_tenant_id()
78
79 if not tenant_id:
80 raise ConnectionError(
81 "Tenant ID not found. Verify that you are using the proper API token."
82 )
83
84 self.logger.info("Agent successfully connected to Prefect Cloud")
85 self.logger.info("Waiting for flow runs...")
86
87 return tenant_id
88
89 def agent_process(self, tenant_id: str) -> None:
90 """
91 Full process for finding flow runs, updating states, and deploying.
92
93 Args:
94 - tenant_id (str): The tenant id to use in the query
95 """
96 try:
97 flow_runs = self.query_flow_runs(tenant_id=tenant_id)
98
99 if flow_runs:
100 self.logger.info(
101 "Found {} flow run(s) to submit for execution.".format(
102 len(flow_runs)
103 )
104 )
105
106 self.update_states(flow_runs)
107 self.deploy_flows(flow_runs)
108 self.logger.info(
109 "Submitted {} flow run(s) for execution.".format(len(flow_runs))
110 )
111 except Exception as exc:
112 self.logger.error(exc)
113
114 def query_tenant_id(self) -> Union[str, None]:
115 """
116 Query Prefect Cloud for the tenant id that corresponds to the agent's auth token
117
118 Returns:
119 - Union[str, None]: The current tenant id if found, None otherwise
120 """
121 query = {"query": {"tenant": {"id"}}}
122 result = self.client.graphql(query)
123
124 if result.data.tenant: # type: ignore
125 return result.data.tenant[0].id # type: ignore
126
127 return None
128
129 def query_flow_runs(self, tenant_id: str) -> list:
130 """
131 Query Prefect Cloud for flow runs which need to be deployed and executed
132
133 Args:
134 - tenant_id (str): The tenant id to use in the query
135
136 Returns:
137 - list: A list of GraphQLResult flow run objects
138 """
139
140 # Get scheduled flow runs from queue
141 mutation = {
142 "mutation($input: getRunsInQueueInput!)": {
143 "getRunsInQueue(input: $input)": {"flow_run_ids"}
144 }
145 }
146
147 result = self.client.graphql(
148 mutation, variables={"input": {"tenantId": tenant_id}}
149 )
150 flow_run_ids = result.data.getRunsInQueue.flow_run_ids # type: ignore
151 now = pendulum.now("UTC")
152
153 # Query metadata fow flow runs found in queue
154 query = {
155 "query": {
156 with_args(
157 "flow_run",
158 {
159 # match flow runs in the flow_run_ids list
160 "where": {
161 "id": {"_in": flow_run_ids},
162 "_or": [
163 # who are EITHER scheduled...
164 {"state": {"_eq": "Scheduled"}},
165 # OR running with task runs scheduled to start more than 3 seconds ago
166 {
167 "state": {"_eq": "Running"},
168 "task_runs": {
169 "state_start_time": {
170 "_lte": str(now.subtract(seconds=3))
171 }
172 },
173 },
174 ],
175 }
176 },
177 ): {
178 "id": True,
179 "version": True,
180 "tenant_id": True,
181 "state": True,
182 "serialized_state": True,
183 "parameters": True,
184 "flow": {"id", "name", "environment", "storage"},
185 with_args(
186 "task_runs",
187 {
188 "where": {
189 "state_start_time": {
190 "_lte": str(now.subtract(seconds=3))
191 }
192 }
193 },
194 ): {"id", "version", "task_id", "serialized_state"},
195 }
196 }
197 }
198
199 result = self.client.graphql(query)
200 return result.data.flow_run # type: ignore
201
202 def update_states(self, flow_runs: list) -> None:
203 """
204 After a flow run is grabbed this function sets the state to Submitted so it
205 won't be picked up by any other processes
206
207 Args:
208 - flow_runs (list): A list of GraphQLResult flow run objects
209 """
210 for flow_run in flow_runs:
211
212 # Set flow run state to `Submitted` if it is currently `Scheduled`
213 if state.StateSchema().load(flow_run.serialized_state).is_scheduled():
214 self.client.set_flow_run_state(
215 flow_run_id=flow_run.id,
216 version=flow_run.version,
217 state=Submitted(
218 message="Submitted for execution",
219 state=state.StateSchema().load(flow_run.serialized_state),
220 ),
221 )
222
223 # Set task run states to `Submitted` if they are currently `Scheduled`
224 for task_run in flow_run.task_runs:
225 if state.StateSchema().load(task_run.serialized_state).is_scheduled():
226 self.client.set_task_run_state(
227 task_run_id=task_run.id,
228 version=task_run.version,
229 state=Submitted(
230 message="Submitted for execution",
231 state=state.StateSchema().load(task_run.serialized_state),
232 ),
233 )
234
235 def deploy_flows(self, flow_runs: list) -> None:
236 """
237 Meant to be overridden by a platform specific deployment option
238
239 Args:
240 - flow_runs (list): A list of GraphQLResult flow run objects
241 """
242 pass
243
244
245 if __name__ == "__main__":
246 Agent().start()
247
[end of src/prefect/agent/agent.py]
[start of src/prefect/cli/__init__.py]
1 #!/usr/bin/env python
2
3
4 import click
5
6 import prefect
7
8 from .agent import agent as _agent
9 from .auth import auth as _auth
10 from .describe import describe as _describe
11 from .execute import execute as _execute
12 from .get import get as _get
13 from .run import run as _run
14
15
16 CONTEXT_SETTINGS = dict(help_option_names=["-h", "--help"])
17
18
19 @click.group(context_settings=CONTEXT_SETTINGS)
20 def cli():
21 """
22 The Prefect CLI for creating, managing, and inspecting your flows.
23
24 \b
25 Note: a Prefect Cloud API token is required for all Cloud related commands. If a token
26 is not set then run `prefect auth login` to set it.
27
28 \b
29 Query Commands:
30 get List high-level object information
31 describe Retrieve detailed object descriptions
32
33 \b
34 Execution Commands:
35 execute Execute a flow's environment
36 run Run a flow
37 agent Manage agents
38
39 \b
40 Setup Commands:
41 auth Handle Prefect Cloud authorization
42
43 \b
44 Miscellaneous Commands:
45 version Get your current Prefect version
46 config Output your Prefect config
47 """
48 pass
49
50
51 cli.add_command(_agent)
52 cli.add_command(_auth)
53 cli.add_command(_describe)
54 cli.add_command(_execute)
55 cli.add_command(_get)
56 cli.add_command(_run)
57
58
59 # Miscellaneous Commands
60
61
62 @cli.command(hidden=True)
63 def version():
64 """
65 Get your current Prefect version
66 """
67 click.echo(prefect.__version__)
68
69
70 @cli.command(hidden=True)
71 def config():
72 """
73 Output your Prefect config
74 """
75 click.echo(prefect.config.to_dict())
76
[end of src/prefect/cli/__init__.py]
[start of src/prefect/cli/auth.py]
1 import click
2
3 from prefect import Client, config
4 from prefect.utilities.exceptions import AuthorizationError, ClientError
5
6
7 @click.group(hidden=True)
8 def auth():
9 """
10 Handle Prefect Cloud authorization.
11
12 \b
13 Usage:
14 $ prefect auth [COMMAND]
15
16 \b
17 Arguments:
18 login Login to Prefect Cloud
19
20 \b
21 Examples:
22 $ prefect auth login --token MY_TOKEN
23 """
24 pass
25
26
27 @auth.command(hidden=True)
28 @click.option(
29 "--token", "-t", required=True, help="A Prefect Cloud API token.", hidden=True
30 )
31 def login(token):
32 """
33 Login to Prefect Cloud with an api token to use for Cloud communication.
34
35 \b
36 Options:
37 --token, -t TEXT A Prefect Cloud api token [required]
38 """
39
40 if config.cloud.auth_token:
41 click.confirm(
42 "Prefect Cloud API token already set in config. Do you want to override?",
43 default=True,
44 )
45
46 client = Client()
47 client.login(api_token=token)
48
49 # Verify login obtained a valid api token
50 try:
51 client.graphql(query={"query": "hello"})
52 except AuthorizationError:
53 click.secho(
54 "Error attempting to use Prefect API token {}".format(token), fg="red"
55 )
56 return
57 except ClientError:
58 click.secho("Error attempting to communicate with Prefect Cloud", fg="red")
59 return
60
61 click.secho("Login successful", fg="green")
62
[end of src/prefect/cli/auth.py]
[start of src/prefect/cli/execute.py]
1 import click
2
3 import prefect
4 from prefect.client import Client
5 from prefect.utilities.graphql import with_args
6
7
8 @click.group(hidden=True)
9 def execute():
10 """
11 Execute flow environments.
12
13 \b
14 Usage:
15 $ prefect execute [OBJECT]
16
17 \b
18 Arguments:
19 cloud-flow Execute a cloud flow's environment (during deployment)
20
21 \b
22 Examples:
23 $ prefect execute cloud-flow
24
25 \b
26 $ prefect execute local-flow ~/.prefect/flows/my_flow.prefect
27 """
28 pass
29
30
31 @execute.command(hidden=True)
32 def cloud_flow():
33 """
34 Execute a flow's environment in the context of Prefect Cloud.
35
36 Note: this is a command that runs during Cloud execution of flows and is not meant
37 for local use.
38 """
39 flow_run_id = prefect.context.get("flow_run_id")
40 if not flow_run_id:
41 click.echo("Not currently executing a flow within a Cloud context.")
42 raise Exception("Not currently executing a flow within a Cloud context.")
43
44 query = {
45 "query": {
46 with_args("flow_run", {"where": {"id": {"_eq": flow_run_id}}}): {
47 "flow": {"name": True, "storage": True, "environment": True},
48 "version": True,
49 }
50 }
51 }
52
53 client = Client()
54 result = client.graphql(query)
55 flow_run = result.data.flow_run
56
57 if not flow_run:
58 click.echo("Flow run {} not found".format(flow_run_id))
59 raise ValueError("Flow run {} not found".format(flow_run_id))
60
61 try:
62 flow_data = flow_run[0].flow
63 storage_schema = prefect.serialization.storage.StorageSchema()
64 storage = storage_schema.load(flow_data.storage)
65
66 environment_schema = prefect.serialization.environment.EnvironmentSchema()
67 environment = environment_schema.load(flow_data.environment)
68
69 environment.setup(storage=storage)
70 environment.execute(
71 storage=storage, flow_location=storage.flows[flow_data.name]
72 )
73 except Exception as exc:
74 msg = "Failed to load and execute Flow's environment: {}".format(repr(exc))
75 state = prefect.engine.state.Failed(message=msg)
76 version = result.data.flow_run[0].version
77 client.set_flow_run_state(flow_run_id=flow_run_id, version=version, state=state)
78 click.echo(str(exc))
79 raise exc
80
[end of src/prefect/cli/execute.py]
[start of src/prefect/client/client.py]
1 import base64
2 import datetime
3 import json
4 import logging
5 import os
6 from typing import TYPE_CHECKING, Any, Dict, List, NamedTuple, Optional, Union
7
8 import pendulum
9 import requests
10 from requests.adapters import HTTPAdapter
11 from requests.packages.urllib3.util.retry import Retry
12
13 import prefect
14 from prefect.utilities.exceptions import AuthorizationError, ClientError
15 from prefect.utilities.graphql import (
16 EnumValue,
17 GraphQLResult,
18 as_nested_dict,
19 compress,
20 parse_graphql,
21 with_args,
22 )
23
24 if TYPE_CHECKING:
25 from prefect.core import Flow
26 JSONLike = Union[bool, dict, list, str, int, float, None]
27
28 # type definitions for GraphQL results
29
30 TaskRunInfoResult = NamedTuple(
31 "TaskRunInfoResult",
32 [
33 ("id", str),
34 ("task_id", str),
35 ("task_slug", str),
36 ("version", int),
37 ("state", "prefect.engine.state.State"),
38 ],
39 )
40
41 FlowRunInfoResult = NamedTuple(
42 "FlowRunInfoResult",
43 [
44 ("parameters", Dict[str, Any]),
45 ("context", Dict[str, Any]),
46 ("version", int),
47 ("scheduled_start_time", datetime.datetime),
48 ("state", "prefect.engine.state.State"),
49 ("task_runs", List[TaskRunInfoResult]),
50 ],
51 )
52
53
54 class Client:
55 """
56 Client for communication with Prefect Cloud
57
58 If the arguments aren't specified the client initialization first checks the prefect
59 configuration and if the server is not set there it checks the current context. The
60 token will only be present in the current context.
61
62 Args:
63 - graphql_server (str, optional): the URL to send all GraphQL requests
64 to; if not provided, will be pulled from `cloud.graphql` config var
65 - token (str, optional): a Prefect Cloud auth token for communication; if not
66 provided, will be pulled from `cloud.auth_token` config var
67 """
68
69 def __init__(self, graphql_server: str = None, token: str = None):
70
71 if not graphql_server:
72 graphql_server = prefect.config.cloud.get("graphql")
73 self.graphql_server = graphql_server
74
75 token = token or prefect.config.cloud.get("auth_token", None)
76
77 self.token_is_local = False
78 if token is None:
79 if os.path.exists(self.local_token_path):
80 with open(self.local_token_path, "r") as f:
81 token = f.read() or None
82 self.token_is_local = True
83
84 self.token = token
85
86 @property
87 def local_token_path(self) -> str:
88 """
89 Returns the local token path corresponding to the provided graphql_server
90 """
91 graphql_server = (self.graphql_server or "").replace("/", "_")
92 return os.path.expanduser("~/.prefect/tokens/{}".format(graphql_server))
93
94 # -------------------------------------------------------------------------
95 # Utilities
96
97 def get(
98 self,
99 path: str,
100 server: str = None,
101 headers: dict = None,
102 params: Dict[str, JSONLike] = None,
103 ) -> dict:
104 """
105 Convenience function for calling the Prefect API with token auth and GET request
106
107 Args:
108 - path (str): the path of the API url. For example, to GET
109 http://prefect-server/v1/auth/login, path would be 'auth/login'.
110 - server (str, optional): the server to send the GET request to;
111 defaults to `self.graphql_server`
112 - headers (dict, optional): Headers to pass with the request
113 - params (dict): GET parameters
114
115 Returns:
116 - dict: Dictionary representation of the request made
117 """
118 response = self._request(
119 method="GET", path=path, params=params, server=server, headers=headers
120 )
121 if response.text:
122 return response.json()
123 else:
124 return {}
125
126 def post(
127 self,
128 path: str,
129 server: str = None,
130 headers: dict = None,
131 params: Dict[str, JSONLike] = None,
132 ) -> dict:
133 """
134 Convenience function for calling the Prefect API with token auth and POST request
135
136 Args:
137 - path (str): the path of the API url. For example, to POST
138 http://prefect-server/v1/auth/login, path would be 'auth/login'.
139 - server (str, optional): the server to send the POST request to;
140 defaults to `self.graphql_server`
141 - headers(dict): headers to pass with the request
142 - params (dict): POST parameters
143
144 Returns:
145 - dict: Dictionary representation of the request made
146 """
147 response = self._request(
148 method="POST", path=path, params=params, server=server, headers=headers
149 )
150 if response.text:
151 return response.json()
152 else:
153 return {}
154
155 def graphql(
156 self,
157 query: Any,
158 raise_on_error: bool = True,
159 headers: Dict[str, str] = None,
160 variables: Dict[str, JSONLike] = None,
161 ) -> GraphQLResult:
162 """
163 Convenience function for running queries against the Prefect GraphQL API
164
165 Args:
166 - query (Any): A representation of a graphql query to be executed. It will be
167 parsed by prefect.utilities.graphql.parse_graphql().
168 - raise_on_error (bool): if True, a `ClientError` will be raised if the GraphQL
169 returns any `errors`.
170 - headers (dict): any additional headers that should be passed as part of the
171 request
172 - variables (dict): Variables to be filled into a query with the key being
173 equivalent to the variables that are accepted by the query
174
175 Returns:
176 - dict: Data returned from the GraphQL query
177
178 Raises:
179 - ClientError if there are errors raised by the GraphQL mutation
180 """
181 result = self.post(
182 path="",
183 server=self.graphql_server,
184 headers=headers,
185 params=dict(query=parse_graphql(query), variables=json.dumps(variables)),
186 )
187
188 if raise_on_error and "errors" in result:
189 raise ClientError(result["errors"])
190 else:
191 return as_nested_dict(result, GraphQLResult) # type: ignore
192
193 def _request(
194 self,
195 method: str,
196 path: str,
197 params: Dict[str, JSONLike] = None,
198 server: str = None,
199 headers: dict = None,
200 ) -> "requests.models.Response":
201 """
202 Runs any specified request (GET, POST, DELETE) against the server
203
204 Args:
205 - method (str): The type of request to be made (GET, POST, DELETE)
206 - path (str): Path of the API URL
207 - params (dict, optional): Parameters used for the request
208 - server (str, optional): The server to make requests against, base API
209 server is used if not specified
210 - headers (dict, optional): Headers to pass with the request
211
212 Returns:
213 - requests.models.Response: The response returned from the request
214
215 Raises:
216 - ClientError: if the client token is not in the context (due to not being logged in)
217 - ValueError: if a method is specified outside of the accepted GET, POST, DELETE
218 - requests.HTTPError: if a status code is returned that is not `200` or `401`
219 """
220 if server is None:
221 server = self.graphql_server
222 assert isinstance(server, str) # mypy assert
223
224 if self.token is None:
225 raise AuthorizationError("No token found; call Client.login() to set one.")
226
227 url = os.path.join(server, path.lstrip("/")).rstrip("/")
228
229 params = params or {}
230
231 headers = headers or {}
232 headers.update({"Authorization": "Bearer {}".format(self.token)})
233 session = requests.Session()
234 retries = Retry(
235 total=6,
236 backoff_factor=1,
237 status_forcelist=[500, 502, 503, 504],
238 method_whitelist=["DELETE", "GET", "POST"],
239 )
240 session.mount("https://", HTTPAdapter(max_retries=retries))
241 if method == "GET":
242 response = session.get(url, headers=headers, params=params)
243 elif method == "POST":
244 response = session.post(url, headers=headers, json=params)
245 elif method == "DELETE":
246 response = session.delete(url, headers=headers)
247 else:
248 raise ValueError("Invalid method: {}".format(method))
249
250 # Check if request returned a successful status
251 response.raise_for_status()
252
253 return response
254
255 # -------------------------------------------------------------------------
256 # Auth
257 # -------------------------------------------------------------------------
258
259 def login(self, api_token: str) -> None:
260 """
261 Logs in to Prefect Cloud with an API token. The token is written to local storage
262 so it persists across Prefect sessions.
263
264 Args:
265 - api_token (str): a Prefect Cloud API token
266
267 Raises:
268 - AuthorizationError if unable to login to the server (request does not return `200`)
269 """
270 if not os.path.exists(os.path.dirname(self.local_token_path)):
271 os.makedirs(os.path.dirname(self.local_token_path))
272 with open(self.local_token_path, "w+") as f:
273 f.write(api_token)
274 self.token = api_token
275 self.token_is_local = True
276
277 def logout(self) -> None:
278 """
279 Deletes the token from this client, and removes it from local storage.
280 """
281 self.token = None
282 if self.token_is_local:
283 if os.path.exists(self.local_token_path):
284 os.remove(self.local_token_path)
285 self.token_is_local = False
286
287 def deploy(
288 self,
289 flow: "Flow",
290 project_name: str,
291 build: bool = True,
292 set_schedule_active: bool = True,
293 compressed: bool = True,
294 ) -> str:
295 """
296 Push a new flow to Prefect Cloud
297
298 Args:
299 - flow (Flow): a flow to deploy
300 - project_name (str): the project that should contain this flow.
301 - build (bool, optional): if `True`, the flow's environment is built
302 prior to serialization; defaults to `True`
303 - set_schedule_active (bool, optional): if `False`, will set the
304 schedule to inactive in the database to prevent auto-scheduling runs (if the Flow has a schedule).
305 Defaults to `True`. This can be changed later.
306 - compressed (bool, optional): if `True`, the serialized flow will be; defaults to `True`
307 compressed
308
309 Returns:
310 - str: the ID of the newly-deployed flow
311
312 Raises:
313 - ClientError: if the deploy failed
314 """
315 required_parameters = {p for p in flow.parameters() if p.required}
316 if flow.schedule is not None and required_parameters:
317 raise ClientError(
318 "Flows with required parameters can not be scheduled automatically."
319 )
320 if compressed:
321 create_mutation = {
322 "mutation($input: createFlowFromCompressedStringInput!)": {
323 "createFlowFromCompressedString(input: $input)": {"id"}
324 }
325 }
326 else:
327 create_mutation = {
328 "mutation($input: createFlowInput!)": {
329 "createFlow(input: $input)": {"id"}
330 }
331 }
332
333 query_project = {
334 "query": {
335 with_args("project", {"where": {"name": {"_eq": project_name}}}): {
336 "id": True
337 }
338 }
339 }
340
341 project = self.graphql(query_project).data.project # type: ignore
342
343 if not project:
344 raise ValueError(
345 "Project {} not found. Run `client.create_project({})` to create it.".format(
346 project_name, project_name
347 )
348 )
349
350 serialized_flow = flow.serialize(build=build) # type: Any
351 if compressed:
352 serialized_flow = compress(serialized_flow)
353 res = self.graphql(
354 create_mutation,
355 variables=dict(
356 input=dict(
357 projectId=project[0].id,
358 serializedFlow=serialized_flow,
359 setScheduleActive=set_schedule_active,
360 )
361 ),
362 ) # type: Any
363
364 flow_id = (
365 res.data.createFlowFromCompressedString.id
366 if compressed
367 else res.data.createFlow.id
368 )
369 return flow_id
370
371 def create_project(self, project_name: str) -> str:
372 """
373 Create a new Project
374
375 Args:
376 - project_name (str): the project that should contain this flow.
377
378 Returns:
379 - str: the ID of the newly-created project
380
381 Raises:
382 - ClientError: if the project creation failed
383 """
384 project_mutation = {
385 "mutation($input: createProjectInput!)": {
386 "createProject(input: $input)": {"id"}
387 }
388 }
389
390 res = self.graphql(
391 project_mutation, variables=dict(input=dict(name=project_name))
392 ) # type: Any
393
394 return res.data.createProject.id
395
396 def create_flow_run(
397 self,
398 flow_id: str,
399 context: dict = None,
400 parameters: dict = None,
401 scheduled_start_time: datetime.datetime = None,
402 idempotency_key: str = None,
403 ) -> str:
404 """
405 Create a new flow run for the given flow id. If `start_time` is not provided, the flow run will be scheduled to start immediately.
406
407 Args:
408 - flow_id (str): the id of the Flow you wish to schedule
409 - context (dict, optional): the run context
410 - parameters (dict, optional): a dictionary of parameter values to pass to the flow run
411 - scheduled_start_time (datetime, optional): the time to schedule the execution for; if not provided, defaults to now
412 - idempotency_key (str, optional): an idempotency key; if provided, this run will be cached for 24
413 hours. Any subsequent attempts to create a run with the same idempotency key
414 will return the ID of the originally created run (no new run will be created after the first).
415 An error will be raised if parameters or context are provided and don't match the original.
416 Each subsequent request will reset the TTL for 24 hours.
417
418 Returns:
419 - str: the ID of the newly-created flow run
420
421 Raises:
422 - ClientError: if the GraphQL query is bad for any reason
423 """
424 create_mutation = {
425 "mutation($input: createFlowRunInput!)": {
426 "createFlowRun(input: $input)": {"flow_run": "id"}
427 }
428 }
429 inputs = dict(flowId=flow_id)
430 if parameters is not None:
431 inputs.update(parameters=parameters) # type: ignore
432 if context is not None:
433 inputs.update(context=context) # type: ignore
434 if idempotency_key is not None:
435 inputs.update(idempotencyKey=idempotency_key) # type: ignore
436 if scheduled_start_time is not None:
437 inputs.update(
438 scheduledStartTime=scheduled_start_time.isoformat()
439 ) # type: ignore
440 res = self.graphql(create_mutation, variables=dict(input=inputs))
441 return res.data.createFlowRun.flow_run.id # type: ignore
442
443 def get_flow_run_info(self, flow_run_id: str) -> FlowRunInfoResult:
444 """
445 Retrieves version and current state information for the given flow run.
446
447 Args:
448 - flow_run_id (str): the id of the flow run to get information for
449
450 Returns:
451 - GraphQLResult: a `DotDict` representing information about the flow run
452
453 Raises:
454 - ClientError: if the GraphQL mutation is bad for any reason
455 """
456 query = {
457 "query": {
458 with_args("flow_run_by_pk", {"id": flow_run_id}): {
459 "parameters": True,
460 "context": True,
461 "version": True,
462 "scheduled_start_time": True,
463 "serialized_state": True,
464 # load all task runs except dynamic task runs
465 with_args("task_runs", {"where": {"map_index": {"_eq": -1}}}): {
466 "id": True,
467 "task": {"id": True, "slug": True},
468 "version": True,
469 "serialized_state": True,
470 },
471 }
472 }
473 }
474 result = self.graphql(query).data.flow_run_by_pk # type: ignore
475 if result is None:
476 raise ClientError('Flow run ID not found: "{}"'.format(flow_run_id))
477
478 # convert scheduled_start_time from string to datetime
479 result.scheduled_start_time = pendulum.parse(result.scheduled_start_time)
480
481 # create "state" attribute from serialized_state
482 result.state = prefect.engine.state.State.deserialize(
483 result.pop("serialized_state")
484 )
485
486 # reformat task_runs
487 task_runs = []
488 for tr in result.task_runs:
489 tr.state = prefect.engine.state.State.deserialize(
490 tr.pop("serialized_state")
491 )
492 task_info = tr.pop("task")
493 tr.task_id = task_info["id"]
494 tr.task_slug = task_info["slug"]
495 task_runs.append(TaskRunInfoResult(**tr))
496
497 result.task_runs = task_runs
498 result.context = (
499 result.context.to_dict() if result.context is not None else None
500 )
501 result.parameters = (
502 result.parameters.to_dict() if result.parameters is not None else None
503 )
504 return FlowRunInfoResult(**result)
505
506 def update_flow_run_heartbeat(self, flow_run_id: str) -> None:
507 """
508 Convenience method for heartbeating a flow run.
509
510 Does NOT raise an error if the update fails.
511
512 Args:
513 - flow_run_id (str): the flow run ID to heartbeat
514
515 """
516 mutation = {
517 "mutation": {
518 with_args(
519 "updateFlowRunHeartbeat", {"input": {"flowRunId": flow_run_id}}
520 ): {"success"}
521 }
522 }
523 self.graphql(mutation, raise_on_error=False)
524
525 def update_task_run_heartbeat(self, task_run_id: str) -> None:
526 """
527 Convenience method for heartbeating a task run.
528
529 Does NOT raise an error if the update fails.
530
531 Args:
532 - task_run_id (str): the task run ID to heartbeat
533
534 """
535 mutation = {
536 "mutation": {
537 with_args(
538 "updateTaskRunHeartbeat", {"input": {"taskRunId": task_run_id}}
539 ): {"success"}
540 }
541 }
542 self.graphql(mutation, raise_on_error=False)
543
544 def set_flow_run_state(
545 self, flow_run_id: str, version: int, state: "prefect.engine.state.State"
546 ) -> None:
547 """
548 Sets new state for a flow run in the database.
549
550 Args:
551 - flow_run_id (str): the id of the flow run to set state for
552 - version (int): the current version of the flow run state
553 - state (State): the new state for this flow run
554
555 Raises:
556 - ClientError: if the GraphQL mutation is bad for any reason
557 """
558 mutation = {
559 "mutation($state: JSON!)": {
560 with_args(
561 "setFlowRunState",
562 {
563 "input": {
564 "flowRunId": flow_run_id,
565 "version": version,
566 "state": EnumValue("$state"),
567 }
568 },
569 ): {"id"}
570 }
571 }
572
573 serialized_state = state.serialize()
574
575 self.graphql(mutation, variables=dict(state=serialized_state)) # type: Any
576
577 def get_latest_cached_states(
578 self, task_id: str, cache_key: Optional[str], created_after: datetime.datetime
579 ) -> List["prefect.engine.state.State"]:
580 """
581 Pulls all Cached states for the given task that were created after the provided date.
582
583 Args:
584 - task_id (str): the task id for this task run
585 - cache_key (Optional[str]): the cache key for this Task's cache; if `None`, the task id alone will be used
586 - created_after (datetime.datetime): the earliest date the state should have been created at
587
588 Returns:
589 - List[State]: a list of Cached states created after the given date
590 """
591 where_clause = {
592 "where": {
593 "state": {"_eq": "Cached"},
594 "_or": [
595 {"cache_key": {"_eq": cache_key}},
596 {"task_id": {"_eq": task_id}},
597 ],
598 "state_timestamp": {"_gte": created_after.isoformat()},
599 },
600 "order_by": {"state_timestamp": EnumValue("desc")},
601 }
602 query = {"query": {with_args("task_run", where_clause): "serialized_state"}}
603 result = self.graphql(query) # type: Any
604 deserializer = prefect.engine.state.State.deserialize
605 valid_states = [
606 deserializer(res.serialized_state) for res in result.data.task_run
607 ]
608 return valid_states
609
610 def get_task_run_info(
611 self, flow_run_id: str, task_id: str, map_index: Optional[int] = None
612 ) -> TaskRunInfoResult:
613 """
614 Retrieves version and current state information for the given task run.
615
616 Args:
617 - flow_run_id (str): the id of the flow run that this task run lives in
618 - task_id (str): the task id for this task run
619 - map_index (int, optional): the mapping index for this task run; if
620 `None`, it is assumed this task is _not_ mapped
621
622 Returns:
623 - NamedTuple: a tuple containing `id, task_id, version, state`
624
625 Raises:
626 - ClientError: if the GraphQL mutation is bad for any reason
627 """
628
629 mutation = {
630 "mutation": {
631 with_args(
632 "getOrCreateTaskRun",
633 {
634 "input": {
635 "flowRunId": flow_run_id,
636 "taskId": task_id,
637 "mapIndex": -1 if map_index is None else map_index,
638 }
639 },
640 ): {
641 "task_run": {
642 "id": True,
643 "version": True,
644 "serialized_state": True,
645 "task": {"slug": True},
646 }
647 }
648 }
649 }
650 result = self.graphql(mutation) # type: Any
651 task_run = result.data.getOrCreateTaskRun.task_run
652
653 state = prefect.engine.state.State.deserialize(task_run.serialized_state)
654 return TaskRunInfoResult(
655 id=task_run.id,
656 task_id=task_id,
657 task_slug=task_run.task.slug,
658 version=task_run.version,
659 state=state,
660 )
661
662 def set_task_run_state(
663 self,
664 task_run_id: str,
665 version: int,
666 state: "prefect.engine.state.State",
667 cache_for: datetime.timedelta = None,
668 ) -> None:
669 """
670 Sets new state for a task run.
671
672 Args:
673 - task_run_id (str): the id of the task run to set state for
674 - version (int): the current version of the task run state
675 - state (State): the new state for this task run
676 - cache_for (timedelta, optional): how long to store the result of this task for, using the
677 serializer set in config; if not provided, no caching occurs
678
679 Raises:
680 - ClientError: if the GraphQL mutation is bad for any reason
681 """
682 mutation = {
683 "mutation($state: JSON!)": {
684 with_args(
685 "setTaskRunState",
686 {
687 "input": {
688 "taskRunId": task_run_id,
689 "version": version,
690 "state": EnumValue("$state"),
691 }
692 },
693 ): {"id"}
694 }
695 }
696
697 serialized_state = state.serialize()
698
699 self.graphql(mutation, variables=dict(state=serialized_state)) # type: Any
700
701 def set_secret(self, name: str, value: Any) -> None:
702 """
703 Set a secret with the given name and value.
704
705 Args:
706 - name (str): the name of the secret; used for retrieving the secret
707 during task runs
708 - value (Any): the value of the secret
709
710 Raises:
711 - ClientError: if the GraphQL mutation is bad for any reason
712 - ValueError: if the secret-setting was unsuccessful
713 """
714 mutation = {
715 "mutation($input: setSecretInput!)": {
716 "setSecret(input: $input)": {"success"}
717 }
718 }
719
720 result = self.graphql(
721 mutation, variables=dict(input=dict(name=name, value=value))
722 ) # type: Any
723
724 if not result.data.setSecret.success:
725 raise ValueError("Setting secret failed.")
726
727 def write_run_log(
728 self,
729 flow_run_id: str,
730 task_run_id: str = None,
731 timestamp: datetime.datetime = None,
732 name: str = None,
733 message: str = None,
734 level: str = None,
735 info: Any = None,
736 ) -> None:
737 """
738 Writes a log to Cloud
739
740 Args:
741 - flow_run_id (str): the flow run id
742 - task_run_id (str, optional): the task run id
743 - timestamp (datetime, optional): the timestamp; defaults to now
744 - name (str, optional): the name of the logger
745 - message (str, optional): the log message
746 - level (str, optional): the log level as a string. Defaults to INFO, should be one of
747 DEBUG, INFO, WARNING, ERROR, or CRITICAL.
748 - info (Any, optional): a JSON payload of additional information
749
750 Raises:
751 - ValueError: if writing the log fails
752 """
753 mutation = {
754 "mutation($input: writeRunLogInput!)": {
755 "writeRunLog(input: $input)": {"success"}
756 }
757 }
758
759 if timestamp is None:
760 timestamp = pendulum.now("UTC")
761 timestamp_str = pendulum.instance(timestamp).isoformat()
762 result = self.graphql(
763 mutation,
764 variables=dict(
765 input=dict(
766 flowRunId=flow_run_id,
767 taskRunId=task_run_id,
768 timestamp=timestamp_str,
769 name=name,
770 message=message,
771 level=level,
772 info=info,
773 )
774 ),
775 ) # type: Any
776
777 if not result.data.writeRunLog.success:
778 raise ValueError("Writing log failed.")
779
[end of src/prefect/client/client.py]
[start of src/prefect/tasks/snowflake/snowflake.py]
1 import snowflake.connector as sf
2
3 from prefect import Task
4 from prefect.utilities.tasks import defaults_from_attrs
5
6
7 class SnowflakeQuery(Task):
8 """
9 Task for executing a query against a snowflake database.
10
11 Args:
12 - account (str): snowflake account name, see snowflake connector
13 package documentation for details
14 - user (str): user name used to authenticate
15 - password (str): password used to authenticate
16 - database (str, optional): name of the default database to use
17 - schema (int, optional): name of the default schema to use
18 - role (str, optional): name of the default role to use
19 - warehouse (str, optional): name of the default warehouse to use
20 - query (str, optional): query to execute against database
21 - data (tuple, optional): values to use in query, must be specified using placeholder is query string
22 - autocommit (bool, optional): set to True to autocommit, defaults to None, which
23 takes snowflake AUTOCOMMIT parameter
24 - **kwargs (dict, optional): additional keyword arguments to pass to the
25 Task constructor
26 """
27
28 def __init__(
29 self,
30 account: str,
31 user: str,
32 password: str,
33 database: str = None,
34 schema: str = None,
35 role: str = None,
36 warehouse: str = None,
37 query: str = None,
38 data: tuple = None,
39 autocommit: bool = None,
40 **kwargs
41 ):
42 self.account = account
43 self.user = user
44 self.password = password
45 self.database = database
46 self.schema = schema
47 self.role = role
48 self.warehouse = warehouse
49 self.query = query
50 self.data = data
51 self.autocommit = autocommit
52 super().__init__(**kwargs)
53
54 @defaults_from_attrs("query", "data", "autocommit")
55 def run(self, query: str = None, data: tuple = None, autocommit: bool = None):
56 """
57 Task run method. Executes a query against snowflake database.
58
59 Args:
60 - query (str, optional): query to execute against database
61 - data (tuple, optional): values to use in query, must be specified using
62 placeholder is query string
63 - autocommit (bool, optional): set to True to autocommit, defaults to None
64 which takes the snowflake AUTOCOMMIT parameter
65
66 Returns:
67 - None
68
69 Raises:
70 - ValueError: if query parameter is None or a blank string
71 - DatabaseError: if exception occurs when executing the query
72 """
73 if not query:
74 raise ValueError("A query string must be provided")
75
76 # build the connection parameter dictionary
77 # we will remove `None` values next
78 connect_params = {
79 "account": self.account,
80 "user": self.user,
81 "password": self.password,
82 "database": self.database,
83 "schema": self.schema,
84 "role": self.role,
85 "warehouse": self.warehouse,
86 "autocommit": self.autocommit,
87 }
88 # filter out unset values
89 connect_params = {
90 param: value
91 for (param, value) in connect_params.items()
92 if value is not None
93 }
94
95 ## connect to database, open cursor
96 conn = sf.connect(**connect_params)
97 ## try to execute query
98 ## context manager automatically rolls back failed transactions
99 try:
100 with conn:
101 with conn.cursor() as cursor:
102 executed = cursor.execute(query=query, params=data)
103
104 conn.close()
105 return executed
106
107 ## pass through error, and ensure connection is closed
108 except Exception as error:
109 conn.close()
110 raise error
111
[end of src/prefect/tasks/snowflake/snowflake.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| PrefectHQ/prefect | e92d10977339e7cf230471804bf471db2f6ace7d | `auth login` CLI check needs token required query
## Description
`prefect auth login` runs a graphql query to verify the token provided is valid. The current query is `query { hello }` and this query does not require authentication. This query needs to be updated to one which requires authentication (which is every other query, let's just find the smallest one)
## Expected Behavior
If the token is invalid it should elevate an error to the user
## Reproduction
Query the API with `query { hello }` without a token and it will still work.
## Environment
N/A
| 2019-08-21T17:00:45Z | <patch>
diff --git a/src/prefect/cli/auth.py b/src/prefect/cli/auth.py
--- a/src/prefect/cli/auth.py
+++ b/src/prefect/cli/auth.py
@@ -37,10 +37,11 @@ def login(token):
--token, -t TEXT A Prefect Cloud api token [required]
"""
- if config.cloud.auth_token:
+ if config.cloud.get("auth_token"):
click.confirm(
"Prefect Cloud API token already set in config. Do you want to override?",
default=True,
+ abort=True,
)
client = Client()
@@ -48,7 +49,7 @@ def login(token):
# Verify login obtained a valid api token
try:
- client.graphql(query={"query": "hello"})
+ client.graphql(query={"query": {"tenant": "id"}})
except AuthorizationError:
click.secho(
"Error attempting to use Prefect API token {}".format(token), fg="red"
</patch> | [] | [] | ||||
pandas-dev__pandas-34877 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: s3 reads from public buckets not working
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of pandas.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandas.
---
#### Code Sample
```python
# Your code here
import pandas as pd
df = pd.read_csv("s3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv")
```
<details>
<summary> Error stack trace </summary>
<pre>
Traceback (most recent call last):
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 33, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
botocore.exceptions.NoCredentialsError: Unable to locate credentials
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f
return _read(filepath_or_buffer, kwds)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 431, in _read
filepath_or_buffer, encoding, compression
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/common.py", line 212, in get_filepath_or_buffer
filepath_or_buffer, encoding=encoding, compression=compression, mode=mode
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 52, in get_filepath_or_buffer
file, _fs = get_file_and_filesystem(filepath_or_buffer, mode=mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 42, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
</pre>
</details>
#### Problem description
Reading directly from s3 public buckets (without manually configuring the `anon` parameter via s3fs) is broken with pandas 1.0.4 (worked with 1.0.3).
Looks like reading from public buckets requires `anon=True` while creating the filesystem. This 22cf0f5dfcfbddd5506fdaf260e485bff1b88ef1 seems to have introduced the issue, where `anon=False` is passed when the `noCredentialsError` is encountered.
#### Output of ``pd.show_versions()``
<details>
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Linux
OS-release : 4.15.0-55-generic
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.0.4
numpy : 1.18.1
pytz : 2020.1
dateutil : 2.8.1
pip : 20.0.2
setuptools : 47.1.1.post20200604
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : 0.15.1
pytables : None
pytest : None
pyxlsb : None
s3fs : 0.4.2
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
xlsxwriter : None
numba : None
</details>
</issue>
<code>
[start of README.md]
1 <div align="center">
2 <img src="https://dev.pandas.io/static/img/pandas.svg"><br>
3 </div>
4
5 -----------------
6
7 # pandas: powerful Python data analysis toolkit
8 [](https://pypi.org/project/pandas/)
9 [](https://anaconda.org/anaconda/pandas/)
10 [](https://doi.org/10.5281/zenodo.3509134)
11 [](https://pypi.org/project/pandas/)
12 [](https://github.com/pandas-dev/pandas/blob/master/LICENSE)
13 [](https://travis-ci.org/pandas-dev/pandas)
14 [](https://dev.azure.com/pandas-dev/pandas/_build/latest?definitionId=1&branch=master)
15 [](https://codecov.io/gh/pandas-dev/pandas)
16 [](https://pandas.pydata.org)
17 [](https://gitter.im/pydata/pandas)
18 [](https://numfocus.org)
19 [](https://github.com/psf/black)
20
21 ## What is it?
22
23 **pandas** is a Python package that provides fast, flexible, and expressive data
24 structures designed to make working with "relational" or "labeled" data both
25 easy and intuitive. It aims to be the fundamental high-level building block for
26 doing practical, **real world** data analysis in Python. Additionally, it has
27 the broader goal of becoming **the most powerful and flexible open source data
28 analysis / manipulation tool available in any language**. It is already well on
29 its way towards this goal.
30
31 ## Main Features
32 Here are just a few of the things that pandas does well:
33
34 - Easy handling of [**missing data**][missing-data] (represented as
35 `NaN`) in floating point as well as non-floating point data
36 - Size mutability: columns can be [**inserted and
37 deleted**][insertion-deletion] from DataFrame and higher dimensional
38 objects
39 - Automatic and explicit [**data alignment**][alignment]: objects can
40 be explicitly aligned to a set of labels, or the user can simply
41 ignore the labels and let `Series`, `DataFrame`, etc. automatically
42 align the data for you in computations
43 - Powerful, flexible [**group by**][groupby] functionality to perform
44 split-apply-combine operations on data sets, for both aggregating
45 and transforming data
46 - Make it [**easy to convert**][conversion] ragged,
47 differently-indexed data in other Python and NumPy data structures
48 into DataFrame objects
49 - Intelligent label-based [**slicing**][slicing], [**fancy
50 indexing**][fancy-indexing], and [**subsetting**][subsetting] of
51 large data sets
52 - Intuitive [**merging**][merging] and [**joining**][joining] data
53 sets
54 - Flexible [**reshaping**][reshape] and [**pivoting**][pivot-table] of
55 data sets
56 - [**Hierarchical**][mi] labeling of axes (possible to have multiple
57 labels per tick)
58 - Robust IO tools for loading data from [**flat files**][flat-files]
59 (CSV and delimited), [**Excel files**][excel], [**databases**][db],
60 and saving/loading data from the ultrafast [**HDF5 format**][hdfstore]
61 - [**Time series**][timeseries]-specific functionality: date range
62 generation and frequency conversion, moving window statistics,
63 date shifting and lagging.
64
65
66 [missing-data]: https://pandas.pydata.org/pandas-docs/stable/missing_data.html#working-with-missing-data
67 [insertion-deletion]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html#column-selection-addition-deletion
68 [alignment]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html?highlight=alignment#intro-to-data-structures
69 [groupby]: https://pandas.pydata.org/pandas-docs/stable/groupby.html#group-by-split-apply-combine
70 [conversion]: https://pandas.pydata.org/pandas-docs/stable/dsintro.html#dataframe
71 [slicing]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#slicing-ranges
72 [fancy-indexing]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#advanced-indexing-with-ix
73 [subsetting]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#boolean-indexing
74 [merging]: https://pandas.pydata.org/pandas-docs/stable/merging.html#database-style-dataframe-joining-merging
75 [joining]: https://pandas.pydata.org/pandas-docs/stable/merging.html#joining-on-index
76 [reshape]: https://pandas.pydata.org/pandas-docs/stable/reshaping.html#reshaping-and-pivot-tables
77 [pivot-table]: https://pandas.pydata.org/pandas-docs/stable/reshaping.html#pivot-tables-and-cross-tabulations
78 [mi]: https://pandas.pydata.org/pandas-docs/stable/indexing.html#hierarchical-indexing-multiindex
79 [flat-files]: https://pandas.pydata.org/pandas-docs/stable/io.html#csv-text-files
80 [excel]: https://pandas.pydata.org/pandas-docs/stable/io.html#excel-files
81 [db]: https://pandas.pydata.org/pandas-docs/stable/io.html#sql-queries
82 [hdfstore]: https://pandas.pydata.org/pandas-docs/stable/io.html#hdf5-pytables
83 [timeseries]: https://pandas.pydata.org/pandas-docs/stable/timeseries.html#time-series-date-functionality
84
85 ## Where to get it
86 The source code is currently hosted on GitHub at:
87 https://github.com/pandas-dev/pandas
88
89 Binary installers for the latest released version are available at the [Python
90 package index](https://pypi.org/project/pandas) and on conda.
91
92 ```sh
93 # conda
94 conda install pandas
95 ```
96
97 ```sh
98 # or PyPI
99 pip install pandas
100 ```
101
102 ## Dependencies
103 - [NumPy](https://www.numpy.org)
104 - [python-dateutil](https://labix.org/python-dateutil)
105 - [pytz](https://pythonhosted.org/pytz)
106
107 See the [full installation instructions](https://pandas.pydata.org/pandas-docs/stable/install.html#dependencies) for minimum supported versions of required, recommended and optional dependencies.
108
109 ## Installation from sources
110 To install pandas from source you need Cython in addition to the normal
111 dependencies above. Cython can be installed from pypi:
112
113 ```sh
114 pip install cython
115 ```
116
117 In the `pandas` directory (same one where you found this file after
118 cloning the git repo), execute:
119
120 ```sh
121 python setup.py install
122 ```
123
124 or for installing in [development mode](https://pip.pypa.io/en/latest/reference/pip_install.html#editable-installs):
125
126
127 ```sh
128 python -m pip install -e . --no-build-isolation --no-use-pep517
129 ```
130
131 If you have `make`, you can also use `make develop` to run the same command.
132
133 or alternatively
134
135 ```sh
136 python setup.py develop
137 ```
138
139 See the full instructions for [installing from source](https://pandas.pydata.org/pandas-docs/stable/install.html#installing-from-source).
140
141 ## License
142 [BSD 3](LICENSE)
143
144 ## Documentation
145 The official documentation is hosted on PyData.org: https://pandas.pydata.org/pandas-docs/stable
146
147 ## Background
148 Work on ``pandas`` started at AQR (a quantitative hedge fund) in 2008 and
149 has been under active development since then.
150
151 ## Getting Help
152
153 For usage questions, the best place to go to is [StackOverflow](https://stackoverflow.com/questions/tagged/pandas).
154 Further, general questions and discussions can also take place on the [pydata mailing list](https://groups.google.com/forum/?fromgroups#!forum/pydata).
155
156 ## Discussion and Development
157 Most development discussions take place on github in this repo. Further, the [pandas-dev mailing list](https://mail.python.org/mailman/listinfo/pandas-dev) can also be used for specialized discussions or design issues, and a [Gitter channel](https://gitter.im/pydata/pandas) is available for quick development related questions.
158
159 ## Contributing to pandas [](https://www.codetriage.com/pandas-dev/pandas)
160
161 All contributions, bug reports, bug fixes, documentation improvements, enhancements, and ideas are welcome.
162
163 A detailed overview on how to contribute can be found in the **[contributing guide](https://pandas.pydata.org/docs/dev/development/contributing.html)**. There is also an [overview](.github/CONTRIBUTING.md) on GitHub.
164
165 If you are simply looking to start working with the pandas codebase, navigate to the [GitHub "issues" tab](https://github.com/pandas-dev/pandas/issues) and start looking through interesting issues. There are a number of issues listed under [Docs](https://github.com/pandas-dev/pandas/issues?labels=Docs&sort=updated&state=open) and [good first issue](https://github.com/pandas-dev/pandas/issues?labels=good+first+issue&sort=updated&state=open) where you could start out.
166
167 You can also triage issues which may include reproducing bug reports, or asking for vital information such as version numbers or reproduction instructions. If you would like to start triaging issues, one easy way to get started is to [subscribe to pandas on CodeTriage](https://www.codetriage.com/pandas-dev/pandas).
168
169 Or maybe through using pandas you have an idea of your own or are looking for something in the documentation and thinking ‘this can be improved’...you can do something about it!
170
171 Feel free to ask questions on the [mailing list](https://groups.google.com/forum/?fromgroups#!forum/pydata) or on [Gitter](https://gitter.im/pydata/pandas).
172
173 As contributors and maintainers to this project, you are expected to abide by pandas' code of conduct. More information can be found at: [Contributor Code of Conduct](https://github.com/pandas-dev/pandas/blob/master/.github/CODE_OF_CONDUCT.md)
174
[end of README.md]
[start of pandas/compat/_optional.py]
1 import distutils.version
2 import importlib
3 import types
4 import warnings
5
6 # Update install.rst when updating versions!
7
8 VERSIONS = {
9 "bs4": "4.6.0",
10 "bottleneck": "1.2.1",
11 "fsspec": "0.7.4",
12 "fastparquet": "0.3.2",
13 "gcsfs": "0.6.0",
14 "lxml.etree": "3.8.0",
15 "matplotlib": "2.2.2",
16 "numexpr": "2.6.2",
17 "odfpy": "1.3.0",
18 "openpyxl": "2.5.7",
19 "pandas_gbq": "0.12.0",
20 "pyarrow": "0.13.0",
21 "pytables": "3.4.3",
22 "pytest": "5.0.1",
23 "pyxlsb": "1.0.6",
24 "s3fs": "0.4.0",
25 "scipy": "1.2.0",
26 "sqlalchemy": "1.1.4",
27 "tables": "3.4.3",
28 "tabulate": "0.8.3",
29 "xarray": "0.8.2",
30 "xlrd": "1.1.0",
31 "xlwt": "1.2.0",
32 "xlsxwriter": "0.9.8",
33 "numba": "0.46.0",
34 }
35
36
37 def _get_version(module: types.ModuleType) -> str:
38 version = getattr(module, "__version__", None)
39 if version is None:
40 # xlrd uses a capitalized attribute name
41 version = getattr(module, "__VERSION__", None)
42
43 if version is None:
44 raise ImportError(f"Can't determine version for {module.__name__}")
45 return version
46
47
48 def import_optional_dependency(
49 name: str, extra: str = "", raise_on_missing: bool = True, on_version: str = "raise"
50 ):
51 """
52 Import an optional dependency.
53
54 By default, if a dependency is missing an ImportError with a nice
55 message will be raised. If a dependency is present, but too old,
56 we raise.
57
58 Parameters
59 ----------
60 name : str
61 The module name. This should be top-level only, so that the
62 version may be checked.
63 extra : str
64 Additional text to include in the ImportError message.
65 raise_on_missing : bool, default True
66 Whether to raise if the optional dependency is not found.
67 When False and the module is not present, None is returned.
68 on_version : str {'raise', 'warn'}
69 What to do when a dependency's version is too old.
70
71 * raise : Raise an ImportError
72 * warn : Warn that the version is too old. Returns None
73 * ignore: Return the module, even if the version is too old.
74 It's expected that users validate the version locally when
75 using ``on_version="ignore"`` (see. ``io/html.py``)
76
77 Returns
78 -------
79 maybe_module : Optional[ModuleType]
80 The imported module, when found and the version is correct.
81 None is returned when the package is not found and `raise_on_missing`
82 is False, or when the package's version is too old and `on_version`
83 is ``'warn'``.
84 """
85 msg = (
86 f"Missing optional dependency '{name}'. {extra} "
87 f"Use pip or conda to install {name}."
88 )
89 try:
90 module = importlib.import_module(name)
91 except ImportError:
92 if raise_on_missing:
93 raise ImportError(msg) from None
94 else:
95 return None
96
97 minimum_version = VERSIONS.get(name)
98 if minimum_version:
99 version = _get_version(module)
100 if distutils.version.LooseVersion(version) < minimum_version:
101 assert on_version in {"warn", "raise", "ignore"}
102 msg = (
103 f"Pandas requires version '{minimum_version}' or newer of '{name}' "
104 f"(version '{version}' currently installed)."
105 )
106 if on_version == "warn":
107 warnings.warn(msg, UserWarning)
108 return None
109 elif on_version == "raise":
110 raise ImportError(msg)
111
112 return module
113
[end of pandas/compat/_optional.py]
[start of pandas/io/common.py]
1 """Common IO api utilities"""
2
3 import bz2
4 from collections import abc
5 import gzip
6 from io import BufferedIOBase, BytesIO, RawIOBase
7 import mmap
8 import os
9 import pathlib
10 from typing import (
11 IO,
12 TYPE_CHECKING,
13 Any,
14 AnyStr,
15 Dict,
16 List,
17 Mapping,
18 Optional,
19 Tuple,
20 Type,
21 Union,
22 )
23 from urllib.parse import (
24 urljoin,
25 urlparse as parse_url,
26 uses_netloc,
27 uses_params,
28 uses_relative,
29 )
30 import zipfile
31
32 from pandas._typing import FilePathOrBuffer
33 from pandas.compat import _get_lzma_file, _import_lzma
34 from pandas.compat._optional import import_optional_dependency
35
36 from pandas.core.dtypes.common import is_file_like
37
38 lzma = _import_lzma()
39
40
41 _VALID_URLS = set(uses_relative + uses_netloc + uses_params)
42 _VALID_URLS.discard("")
43
44
45 if TYPE_CHECKING:
46 from io import IOBase # noqa: F401
47
48
49 def is_url(url) -> bool:
50 """
51 Check to see if a URL has a valid protocol.
52
53 Parameters
54 ----------
55 url : str or unicode
56
57 Returns
58 -------
59 isurl : bool
60 If `url` has a valid protocol return True otherwise False.
61 """
62 if not isinstance(url, str):
63 return False
64 return parse_url(url).scheme in _VALID_URLS
65
66
67 def _expand_user(
68 filepath_or_buffer: FilePathOrBuffer[AnyStr],
69 ) -> FilePathOrBuffer[AnyStr]:
70 """
71 Return the argument with an initial component of ~ or ~user
72 replaced by that user's home directory.
73
74 Parameters
75 ----------
76 filepath_or_buffer : object to be converted if possible
77
78 Returns
79 -------
80 expanded_filepath_or_buffer : an expanded filepath or the
81 input if not expandable
82 """
83 if isinstance(filepath_or_buffer, str):
84 return os.path.expanduser(filepath_or_buffer)
85 return filepath_or_buffer
86
87
88 def validate_header_arg(header) -> None:
89 if isinstance(header, bool):
90 raise TypeError(
91 "Passing a bool to header is invalid. Use header=None for no header or "
92 "header=int or list-like of ints to specify "
93 "the row(s) making up the column names"
94 )
95
96
97 def stringify_path(
98 filepath_or_buffer: FilePathOrBuffer[AnyStr],
99 ) -> FilePathOrBuffer[AnyStr]:
100 """
101 Attempt to convert a path-like object to a string.
102
103 Parameters
104 ----------
105 filepath_or_buffer : object to be converted
106
107 Returns
108 -------
109 str_filepath_or_buffer : maybe a string version of the object
110
111 Notes
112 -----
113 Objects supporting the fspath protocol (python 3.6+) are coerced
114 according to its __fspath__ method.
115
116 For backwards compatibility with older pythons, pathlib.Path and
117 py.path objects are specially coerced.
118
119 Any other object is passed through unchanged, which includes bytes,
120 strings, buffers, or anything else that's not even path-like.
121 """
122 if hasattr(filepath_or_buffer, "__fspath__"):
123 # https://github.com/python/mypy/issues/1424
124 return filepath_or_buffer.__fspath__() # type: ignore
125 elif isinstance(filepath_or_buffer, pathlib.Path):
126 return str(filepath_or_buffer)
127 return _expand_user(filepath_or_buffer)
128
129
130 def urlopen(*args, **kwargs):
131 """
132 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
133 the stdlib.
134 """
135 import urllib.request
136
137 return urllib.request.urlopen(*args, **kwargs)
138
139
140 def is_fsspec_url(url: FilePathOrBuffer) -> bool:
141 """
142 Returns true if the given URL looks like
143 something fsspec can handle
144 """
145 return (
146 isinstance(url, str)
147 and "://" in url
148 and not url.startswith(("http://", "https://"))
149 )
150
151
152 def get_filepath_or_buffer(
153 filepath_or_buffer: FilePathOrBuffer,
154 encoding: Optional[str] = None,
155 compression: Optional[str] = None,
156 mode: Optional[str] = None,
157 storage_options: Optional[Dict[str, Any]] = None,
158 ):
159 """
160 If the filepath_or_buffer is a url, translate and return the buffer.
161 Otherwise passthrough.
162
163 Parameters
164 ----------
165 filepath_or_buffer : a url, filepath (str, py.path.local or pathlib.Path),
166 or buffer
167 compression : {{'gzip', 'bz2', 'zip', 'xz', None}}, optional
168 encoding : the encoding to use to decode bytes, default is 'utf-8'
169 mode : str, optional
170 storage_options: dict, optional
171 passed on to fsspec, if using it; this is not yet accessed by the public API
172
173 Returns
174 -------
175 Tuple[FilePathOrBuffer, str, str, bool]
176 Tuple containing the filepath or buffer, the encoding, the compression
177 and should_close.
178 """
179 filepath_or_buffer = stringify_path(filepath_or_buffer)
180
181 if isinstance(filepath_or_buffer, str) and is_url(filepath_or_buffer):
182 # TODO: fsspec can also handle HTTP via requests, but leaving this unchanged
183 req = urlopen(filepath_or_buffer)
184 content_encoding = req.headers.get("Content-Encoding", None)
185 if content_encoding == "gzip":
186 # Override compression based on Content-Encoding header
187 compression = "gzip"
188 reader = BytesIO(req.read())
189 req.close()
190 return reader, encoding, compression, True
191
192 if is_fsspec_url(filepath_or_buffer):
193 assert isinstance(
194 filepath_or_buffer, str
195 ) # just to appease mypy for this branch
196 # two special-case s3-like protocols; these have special meaning in Hadoop,
197 # but are equivalent to just "s3" from fsspec's point of view
198 # cc #11071
199 if filepath_or_buffer.startswith("s3a://"):
200 filepath_or_buffer = filepath_or_buffer.replace("s3a://", "s3://")
201 if filepath_or_buffer.startswith("s3n://"):
202 filepath_or_buffer = filepath_or_buffer.replace("s3n://", "s3://")
203 fsspec = import_optional_dependency("fsspec")
204
205 file_obj = fsspec.open(
206 filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
207 ).open()
208 return file_obj, encoding, compression, True
209
210 if isinstance(filepath_or_buffer, (str, bytes, mmap.mmap)):
211 return _expand_user(filepath_or_buffer), None, compression, False
212
213 if not is_file_like(filepath_or_buffer):
214 msg = f"Invalid file path or buffer object type: {type(filepath_or_buffer)}"
215 raise ValueError(msg)
216
217 return filepath_or_buffer, None, compression, False
218
219
220 def file_path_to_url(path: str) -> str:
221 """
222 converts an absolute native path to a FILE URL.
223
224 Parameters
225 ----------
226 path : a path in native format
227
228 Returns
229 -------
230 a valid FILE URL
231 """
232 # lazify expensive import (~30ms)
233 from urllib.request import pathname2url
234
235 return urljoin("file:", pathname2url(path))
236
237
238 _compression_to_extension = {"gzip": ".gz", "bz2": ".bz2", "zip": ".zip", "xz": ".xz"}
239
240
241 def get_compression_method(
242 compression: Optional[Union[str, Mapping[str, str]]]
243 ) -> Tuple[Optional[str], Dict[str, str]]:
244 """
245 Simplifies a compression argument to a compression method string and
246 a mapping containing additional arguments.
247
248 Parameters
249 ----------
250 compression : str or mapping
251 If string, specifies the compression method. If mapping, value at key
252 'method' specifies compression method.
253
254 Returns
255 -------
256 tuple of ({compression method}, Optional[str]
257 {compression arguments}, Dict[str, str])
258
259 Raises
260 ------
261 ValueError on mapping missing 'method' key
262 """
263 if isinstance(compression, Mapping):
264 compression_args = dict(compression)
265 try:
266 compression = compression_args.pop("method")
267 except KeyError as err:
268 raise ValueError("If mapping, compression must have key 'method'") from err
269 else:
270 compression_args = {}
271 return compression, compression_args
272
273
274 def infer_compression(
275 filepath_or_buffer: FilePathOrBuffer, compression: Optional[str]
276 ) -> Optional[str]:
277 """
278 Get the compression method for filepath_or_buffer. If compression='infer',
279 the inferred compression method is returned. Otherwise, the input
280 compression method is returned unchanged, unless it's invalid, in which
281 case an error is raised.
282
283 Parameters
284 ----------
285 filepath_or_buffer : str or file handle
286 File path or object.
287 compression : {'infer', 'gzip', 'bz2', 'zip', 'xz', None}
288 If 'infer' and `filepath_or_buffer` is path-like, then detect
289 compression from the following extensions: '.gz', '.bz2', '.zip',
290 or '.xz' (otherwise no compression).
291
292 Returns
293 -------
294 string or None
295
296 Raises
297 ------
298 ValueError on invalid compression specified.
299 """
300 # No compression has been explicitly specified
301 if compression is None:
302 return None
303
304 # Infer compression
305 if compression == "infer":
306 # Convert all path types (e.g. pathlib.Path) to strings
307 filepath_or_buffer = stringify_path(filepath_or_buffer)
308 if not isinstance(filepath_or_buffer, str):
309 # Cannot infer compression of a buffer, assume no compression
310 return None
311
312 # Infer compression from the filename/URL extension
313 for compression, extension in _compression_to_extension.items():
314 if filepath_or_buffer.endswith(extension):
315 return compression
316 return None
317
318 # Compression has been specified. Check that it's valid
319 if compression in _compression_to_extension:
320 return compression
321
322 msg = f"Unrecognized compression type: {compression}"
323 valid = ["infer", None] + sorted(_compression_to_extension)
324 msg += f"\nValid compression types are {valid}"
325 raise ValueError(msg)
326
327
328 def get_handle(
329 path_or_buf,
330 mode: str,
331 encoding=None,
332 compression: Optional[Union[str, Mapping[str, Any]]] = None,
333 memory_map: bool = False,
334 is_text: bool = True,
335 errors=None,
336 ):
337 """
338 Get file handle for given path/buffer and mode.
339
340 Parameters
341 ----------
342 path_or_buf : str or file handle
343 File path or object.
344 mode : str
345 Mode to open path_or_buf with.
346 encoding : str or None
347 Encoding to use.
348 compression : str or dict, default None
349 If string, specifies compression mode. If dict, value at key 'method'
350 specifies compression mode. Compression mode must be one of {'infer',
351 'gzip', 'bz2', 'zip', 'xz', None}. If compression mode is 'infer'
352 and `filepath_or_buffer` is path-like, then detect compression from
353 the following extensions: '.gz', '.bz2', '.zip', or '.xz' (otherwise
354 no compression). If dict and compression mode is one of
355 {'zip', 'gzip', 'bz2'}, or inferred as one of the above,
356 other entries passed as additional compression options.
357
358 .. versionchanged:: 1.0.0
359
360 May now be a dict with key 'method' as compression mode
361 and other keys as compression options if compression
362 mode is 'zip'.
363
364 .. versionchanged:: 1.1.0
365
366 Passing compression options as keys in dict is now
367 supported for compression modes 'gzip' and 'bz2' as well as 'zip'.
368
369 memory_map : boolean, default False
370 See parsers._parser_params for more information.
371 is_text : boolean, default True
372 whether file/buffer is in text format (csv, json, etc.), or in binary
373 mode (pickle, etc.).
374 errors : str, default 'strict'
375 Specifies how encoding and decoding errors are to be handled.
376 See the errors argument for :func:`open` for a full list
377 of options.
378
379 .. versionadded:: 1.1.0
380
381 Returns
382 -------
383 f : file-like
384 A file-like object.
385 handles : list of file-like objects
386 A list of file-like object that were opened in this function.
387 """
388 need_text_wrapping: Tuple[Type["IOBase"], ...]
389 try:
390 from s3fs import S3File
391
392 need_text_wrapping = (BufferedIOBase, RawIOBase, S3File)
393 except ImportError:
394 need_text_wrapping = (BufferedIOBase, RawIOBase)
395
396 handles: List[IO] = list()
397 f = path_or_buf
398
399 # Convert pathlib.Path/py.path.local or string
400 path_or_buf = stringify_path(path_or_buf)
401 is_path = isinstance(path_or_buf, str)
402
403 compression, compression_args = get_compression_method(compression)
404 if is_path:
405 compression = infer_compression(path_or_buf, compression)
406
407 if compression:
408
409 # GH33398 the type ignores here seem related to mypy issue #5382;
410 # it may be possible to remove them once that is resolved.
411
412 # GZ Compression
413 if compression == "gzip":
414 if is_path:
415 f = gzip.open(
416 path_or_buf, mode, **compression_args # type: ignore
417 )
418 else:
419 f = gzip.GzipFile(
420 fileobj=path_or_buf, **compression_args # type: ignore
421 )
422
423 # BZ Compression
424 elif compression == "bz2":
425 if is_path:
426 f = bz2.BZ2File(
427 path_or_buf, mode, **compression_args # type: ignore
428 )
429 else:
430 f = bz2.BZ2File(path_or_buf, **compression_args) # type: ignore
431
432 # ZIP Compression
433 elif compression == "zip":
434 zf = _BytesZipFile(path_or_buf, mode, **compression_args)
435 # Ensure the container is closed as well.
436 handles.append(zf)
437 if zf.mode == "w":
438 f = zf
439 elif zf.mode == "r":
440 zip_names = zf.namelist()
441 if len(zip_names) == 1:
442 f = zf.open(zip_names.pop())
443 elif len(zip_names) == 0:
444 raise ValueError(f"Zero files found in ZIP file {path_or_buf}")
445 else:
446 raise ValueError(
447 "Multiple files found in ZIP file. "
448 f"Only one file per ZIP: {zip_names}"
449 )
450
451 # XZ Compression
452 elif compression == "xz":
453 f = _get_lzma_file(lzma)(path_or_buf, mode)
454
455 # Unrecognized Compression
456 else:
457 msg = f"Unrecognized compression type: {compression}"
458 raise ValueError(msg)
459
460 handles.append(f)
461
462 elif is_path:
463 if encoding:
464 # Encoding
465 f = open(path_or_buf, mode, encoding=encoding, errors=errors, newline="")
466 elif is_text:
467 # No explicit encoding
468 f = open(path_or_buf, mode, errors="replace", newline="")
469 else:
470 # Binary mode
471 f = open(path_or_buf, mode)
472 handles.append(f)
473
474 # Convert BytesIO or file objects passed with an encoding
475 if is_text and (compression or isinstance(f, need_text_wrapping)):
476 from io import TextIOWrapper
477
478 g = TextIOWrapper(f, encoding=encoding, errors=errors, newline="")
479 if not isinstance(f, (BufferedIOBase, RawIOBase)):
480 handles.append(g)
481 f = g
482
483 if memory_map and hasattr(f, "fileno"):
484 try:
485 wrapped = _MMapWrapper(f)
486 f.close()
487 f = wrapped
488 except Exception:
489 # we catch any errors that may have occurred
490 # because that is consistent with the lower-level
491 # functionality of the C engine (pd.read_csv), so
492 # leave the file handler as is then
493 pass
494
495 return f, handles
496
497
498 class _BytesZipFile(zipfile.ZipFile, BytesIO): # type: ignore
499 """
500 Wrapper for standard library class ZipFile and allow the returned file-like
501 handle to accept byte strings via `write` method.
502
503 BytesIO provides attributes of file-like object and ZipFile.writestr writes
504 bytes strings into a member of the archive.
505 """
506
507 # GH 17778
508 def __init__(
509 self,
510 file: FilePathOrBuffer,
511 mode: str,
512 archive_name: Optional[str] = None,
513 **kwargs,
514 ):
515 if mode in ["wb", "rb"]:
516 mode = mode.replace("b", "")
517 self.archive_name = archive_name
518 super().__init__(file, mode, zipfile.ZIP_DEFLATED, **kwargs)
519
520 def write(self, data):
521 archive_name = self.filename
522 if self.archive_name is not None:
523 archive_name = self.archive_name
524 super().writestr(archive_name, data)
525
526 @property
527 def closed(self):
528 return self.fp is None
529
530
531 class _MMapWrapper(abc.Iterator):
532 """
533 Wrapper for the Python's mmap class so that it can be properly read in
534 by Python's csv.reader class.
535
536 Parameters
537 ----------
538 f : file object
539 File object to be mapped onto memory. Must support the 'fileno'
540 method or have an equivalent attribute
541
542 """
543
544 def __init__(self, f: IO):
545 self.mmap = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
546
547 def __getattr__(self, name: str):
548 return getattr(self.mmap, name)
549
550 def __iter__(self) -> "_MMapWrapper":
551 return self
552
553 def __next__(self) -> str:
554 newbytes = self.mmap.readline()
555
556 # readline returns bytes, not str, but Python's CSV reader
557 # expects str, so convert the output to str before continuing
558 newline = newbytes.decode("utf-8")
559
560 # mmap doesn't raise if reading past the allocated
561 # data but instead returns an empty string, so raise
562 # if that is returned
563 if newline == "":
564 raise StopIteration
565 return newline
566
[end of pandas/io/common.py]
[start of scripts/generate_pip_deps_from_conda.py]
1 #!/usr/bin/env python3
2 """
3 Convert the conda environment.yml to the pip requirements-dev.txt,
4 or check that they have the same packages (for the CI)
5
6 Usage:
7
8 Generate `requirements-dev.txt`
9 $ ./conda_to_pip
10
11 Compare and fail (exit status != 0) if `requirements-dev.txt` has not been
12 generated with this script:
13 $ ./conda_to_pip --compare
14 """
15 import argparse
16 import os
17 import re
18 import sys
19
20 import yaml
21
22 EXCLUDE = {"python"}
23 RENAME = {"pytables": "tables", "pyqt": "pyqt5", "dask-core": "dask"}
24
25
26 def conda_package_to_pip(package):
27 """
28 Convert a conda package to its pip equivalent.
29
30 In most cases they are the same, those are the exceptions:
31 - Packages that should be excluded (in `EXCLUDE`)
32 - Packages that should be renamed (in `RENAME`)
33 - A package requiring a specific version, in conda is defined with a single
34 equal (e.g. ``pandas=1.0``) and in pip with two (e.g. ``pandas==1.0``)
35 """
36 package = re.sub("(?<=[^<>])=", "==", package).strip()
37
38 for compare in ("<=", ">=", "=="):
39 if compare not in package:
40 continue
41
42 pkg, version = package.split(compare)
43 if pkg in EXCLUDE:
44 return
45
46 if pkg in RENAME:
47 return "".join((RENAME[pkg], compare, version))
48
49 break
50
51 if package in RENAME:
52 return RENAME[package]
53
54 return package
55
56
57 def main(conda_fname, pip_fname, compare=False):
58 """
59 Generate the pip dependencies file from the conda file, or compare that
60 they are synchronized (``compare=True``).
61
62 Parameters
63 ----------
64 conda_fname : str
65 Path to the conda file with dependencies (e.g. `environment.yml`).
66 pip_fname : str
67 Path to the pip file with dependencies (e.g. `requirements-dev.txt`).
68 compare : bool, default False
69 Whether to generate the pip file (``False``) or to compare if the
70 pip file has been generated with this script and the last version
71 of the conda file (``True``).
72
73 Returns
74 -------
75 bool
76 True if the comparison fails, False otherwise
77 """
78 with open(conda_fname) as conda_fd:
79 deps = yaml.safe_load(conda_fd)["dependencies"]
80
81 pip_deps = []
82 for dep in deps:
83 if isinstance(dep, str):
84 conda_dep = conda_package_to_pip(dep)
85 if conda_dep:
86 pip_deps.append(conda_dep)
87 elif isinstance(dep, dict) and len(dep) == 1 and "pip" in dep:
88 pip_deps += dep["pip"]
89 else:
90 raise ValueError(f"Unexpected dependency {dep}")
91
92 fname = os.path.split(conda_fname)[1]
93 header = (
94 f"# This file is auto-generated from {fname}, do not modify.\n"
95 "# See that file for comments about the need/usage of each dependency.\n\n"
96 )
97 pip_content = header + "\n".join(pip_deps)
98
99 if compare:
100 with open(pip_fname) as pip_fd:
101 return pip_content != pip_fd.read()
102 else:
103 with open(pip_fname, "w") as pip_fd:
104 pip_fd.write(pip_content)
105 return False
106
107
108 if __name__ == "__main__":
109 argparser = argparse.ArgumentParser(
110 description="convert (or compare) conda file to pip"
111 )
112 argparser.add_argument(
113 "--compare",
114 action="store_true",
115 help="compare whether the two files are equivalent",
116 )
117 argparser.add_argument(
118 "--azure", action="store_true", help="show the output in azure-pipelines format"
119 )
120 args = argparser.parse_args()
121
122 repo_path = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
123 res = main(
124 os.path.join(repo_path, "environment.yml"),
125 os.path.join(repo_path, "requirements-dev.txt"),
126 compare=args.compare,
127 )
128 if res:
129 msg = (
130 f"`requirements-dev.txt` has to be generated with `{sys.argv[0]}` after "
131 "`environment.yml` is modified.\n"
132 )
133 if args.azure:
134 msg = (
135 f"##vso[task.logissue type=error;sourcepath=requirements-dev.txt]{msg}"
136 )
137 sys.stderr.write(msg)
138 sys.exit(res)
139
[end of scripts/generate_pip_deps_from_conda.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| pandas-dev/pandas | b0468aa45f3912d6f8823d1cd418af34ffdcd2b1 | BUG: s3 reads from public buckets not working
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of pandas.
- [ ] (optional) I have confirmed this bug exists on the master branch of pandas.
---
#### Code Sample
```python
# Your code here
import pandas as pd
df = pd.read_csv("s3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv")
```
<details>
<summary> Error stack trace </summary>
<pre>
Traceback (most recent call last):
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 33, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
botocore.exceptions.NoCredentialsError: Unable to locate credentials
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f
return _read(filepath_or_buffer, kwds)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/parsers.py", line 431, in _read
filepath_or_buffer, encoding, compression
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/common.py", line 212, in get_filepath_or_buffer
filepath_or_buffer, encoding=encoding, compression=compression, mode=mode
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 52, in get_filepath_or_buffer
file, _fs = get_file_and_filesystem(filepath_or_buffer, mode=mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/pandas/io/s3.py", line 42, in get_file_and_filesystem
file = fs.open(_strip_schema(filepath_or_buffer), mode)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 775, in open
**kwargs
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 378, in _open
autocommit=autocommit, requester_pays=requester_pays)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 1097, in __init__
cache_type=cache_type)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/fsspec/spec.py", line 1065, in __init__
self.details = fs.info(path)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 530, in info
Key=key, **version_id_kw(version_id), **self.req_kw)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/s3fs/core.py", line 200, in _call_s3
return method(**additional_kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 316, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 622, in _make_api_call
operation_model, request_dict, request_context)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/client.py", line 641, in _make_request
return self._endpoint.make_request(operation_model, request_dict)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 102, in make_request
return self._send_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 132, in _send_request
request = self.create_request(request_dict, operation_model)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/endpoint.py", line 116, in create_request
operation_name=operation_model.name)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 356, in emit
return self._emitter.emit(aliased_event_name, **kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 228, in emit
return self._emit(event_name, kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/hooks.py", line 211, in _emit
response = handler(**kwargs)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 90, in handler
return self.sign(operation_name, request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/signers.py", line 160, in sign
auth.add_auth(request)
File "/home/conda/envs/pandas-test/lib/python3.7/site-packages/botocore/auth.py", line 357, in add_auth
raise NoCredentialsError
</pre>
</details>
#### Problem description
Reading directly from s3 public buckets (without manually configuring the `anon` parameter via s3fs) is broken with pandas 1.0.4 (worked with 1.0.3).
Looks like reading from public buckets requires `anon=True` while creating the filesystem. This 22cf0f5dfcfbddd5506fdaf260e485bff1b88ef1 seems to have introduced the issue, where `anon=False` is passed when the `noCredentialsError` is encountered.
#### Output of ``pd.show_versions()``
<details>
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Linux
OS-release : 4.15.0-55-generic
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.0.4
numpy : 1.18.1
pytz : 2020.1
dateutil : 2.8.1
pip : 20.0.2
setuptools : 47.1.1.post20200604
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
pyarrow : 0.15.1
pytables : None
pytest : None
pyxlsb : None
s3fs : 0.4.2
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
xlsxwriter : None
numba : None
</details>
| @ayushdg thanks for the report!
cc @simonjayhawkins @alimcmaster1 for 1.0.5, it might be safer to revert https://github.com/pandas-dev/pandas/pull/33632, and then target the fixes (like https://github.com/pandas-dev/pandas/pull/34500) to master
Agree @jorisvandenbossche - do you want me to open a PR to revert #33632 on 1.0.x branch? Apologies for this change it didn’t go as planned. I’ll check why our test cases didn’t catch the above!
> do you want me to open a PR to revert #33632 on 1.0.x branch?
Yes, that sounds good
> Apologies for this change it didn’t go as planned.
No, no, nobody of us had foreseen the breakages ;)
Can't seem to reproduce this using moto... Potentially related: https://github.com/dask/s3fs/blob/master/s3fs/tests/test_s3fs.py#L1089
(I can repo locally using the s3 URL above - if I remove AWS Creds from my environment)
The fix for this to target 1.1 is to set ‘anon=True’ in S3FileSystem https://github.com/pandas-dev/pandas/pull/33632/files#diff-a37b395bed03f0404dec864a4529c97dR41
I’ll wait as we are moving to fsspec which gets rid of this logic https://github.com/pandas-dev/pandas/pull/34266 - but we should definitely trying using moto to test this.
Can anyone summarize the status here?
1.0.3: worked
1.0.4: broken
master: broken?
master+https://github.com/pandas-dev/pandas/pull/34266: broken?
Do we have a plan in place to restore this? IIUC the old way was to
1. try with the default (which I think looks up keys based on env vars)
2. If we get an error, retry with `anon=True`
Yep, it broke in 1.0.4, and will be fixed in 1.0.5 by reverting the patch that broke it.
That means that master is still broken, and thus we first need to write a test for it, and check whether #34266 actually fixes it already, or otherwise still fix it differently.
The old way was indeed to try with `anon=True` if it first failed. I suppose we can "simply" restore that logic? (in case it's not automatically fixed with fsspec)
Thanks
> in case it's not automatically fixed with fsspec
It's not. So we'll need to do that explicitly. Long-term we might want to get away from this logic by asking users to do `read_csv(..., storage_options={"requester_pays": False})`. But for 1.1 we'll want to restore the old implicit retry behavior if possible. | 2020-06-19T23:07:29Z | <patch>
diff --git a/pandas/io/common.py b/pandas/io/common.py
--- a/pandas/io/common.py
+++ b/pandas/io/common.py
@@ -202,9 +202,37 @@ def get_filepath_or_buffer(
filepath_or_buffer = filepath_or_buffer.replace("s3n://", "s3://")
fsspec = import_optional_dependency("fsspec")
- file_obj = fsspec.open(
- filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
- ).open()
+ # If botocore is installed we fallback to reading with anon=True
+ # to allow reads from public buckets
+ err_types_to_retry_with_anon: List[Any] = []
+ try:
+ import_optional_dependency("botocore")
+ from botocore.exceptions import ClientError, NoCredentialsError
+
+ err_types_to_retry_with_anon = [
+ ClientError,
+ NoCredentialsError,
+ PermissionError,
+ ]
+ except ImportError:
+ pass
+
+ try:
+ file_obj = fsspec.open(
+ filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
+ ).open()
+ # GH 34626 Reads from Public Buckets without Credentials needs anon=True
+ except tuple(err_types_to_retry_with_anon):
+ if storage_options is None:
+ storage_options = {"anon": True}
+ else:
+ # don't mutate user input.
+ storage_options = dict(storage_options)
+ storage_options["anon"] = True
+ file_obj = fsspec.open(
+ filepath_or_buffer, mode=mode or "rb", **(storage_options or {})
+ ).open()
+
return file_obj, encoding, compression, True
if isinstance(filepath_or_buffer, (str, bytes, mmap.mmap)):
</patch> | [] | [] | |||
Qiskit__qiskit-9386 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DAGCircuitError: 'bit mapping invalid
### Informations
- **Qiskit: 0.39.2**:
- **Python: 3.10.9**:
- **Mac**:
### What is the current behavior?
I'm implementing quantum half adder on Jupyter Notebook.
When I try running my circuit on the simulator "qasm_simulator", Jupyter said
DAGCircuitError: 'bit mapping invalid: expected 4, got 8'
here is the code I've written. The error occurs on the last line of the third code.
```
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute, Aer
#SUM
X = QuantumRegister(1, "in |X⟩")
Y = QuantumRegister(1, "in |Y⟩")
sum_out = QuantumRegister(1, "out SUM |0⟩")
SUM = QuantumCircuit(X, Y, sum_out, name='SUM')
SUM.cx(1, 2)
SUM.cx(0, 2)
fig = SUM.draw('mpl', True)
SUM = SUM.to_instruction()
fig
```
```
#half_adder
cout = QuantumRegister(1, 'out Carry |0⟩')
c = ClassicalRegister(4)
hadder = QuantumCircuit(X,Y,sum_out,cout,c)
hadder.ccx(X,Y,cout)
hadder.append(SUM,[0,1,2])
show = hadder.draw("mpl",True)
hadder = hadder.to_instruction()
show
```
```
#testing half_adder
qu = QuantumRegister(4)
cl = ClassicalRegister(4)
circ = QuantumCircuit(qu,cl)
circ.x(qu[0])
circ.x(qu[1])
circ.append(hadder,[0,1,2,3])
for i in range(0,4):
circ.measure(qu[i],cl[i])
circ.draw("mpl",True)
print(execute(circ,Aer.get_backend('qasm_simulator'), shots = 1).result().get_counts())
```
### What is the expected behavior?
I don't totally understand the error. I hope to troubleshoot to see the result.
### Suggested solutions
</issue>
<code>
[start of README.md]
1 # Qiskit Terra
2 [](https://opensource.org/licenses/Apache-2.0)<!--- long-description-skip-begin -->[](https://github.com/Qiskit/qiskit-terra/releases)[](https://pypi.org/project/qiskit-terra/)[](https://coveralls.io/github/Qiskit/qiskit-terra?branch=main)[](https://rust-lang.github.io/rfcs/2495-min-rust-version.html)<!--- long-description-skip-end -->
3
4 **Qiskit** is an open-source framework for working with noisy quantum computers at the level of pulses, circuits, and algorithms.
5
6 This library is the core component of Qiskit, **Terra**, which contains the building blocks for creating
7 and working with quantum circuits, programs, and algorithms. It also contains a compiler that supports
8 different quantum computers and a common interface for running programs on different quantum computer architectures.
9
10 For more details on how to use Qiskit you can refer to the documentation located here:
11
12 https://qiskit.org/documentation/
13
14
15 ## Installation
16
17 We encourage installing Qiskit via ``pip``. The following command installs the core Qiskit components, including Terra.
18
19 ```bash
20 pip install qiskit
21 ```
22
23 Pip will handle all dependencies automatically and you will always install the latest (and well-tested) version.
24
25 To install from source, follow the instructions in the [documentation](https://qiskit.org/documentation/contributing_to_qiskit.html#install-install-from-source-label).
26
27 ## Creating Your First Quantum Program in Qiskit Terra
28
29 Now that Qiskit is installed, it's time to begin working with Qiskit. To do this
30 we create a `QuantumCircuit` object to define a basic quantum program.
31
32 ```python
33 from qiskit import QuantumCircuit
34 qc = QuantumCircuit(2, 2)
35 qc.h(0)
36 qc.cx(0, 1)
37 qc.measure([0,1], [0,1])
38 ```
39
40 This simple example makes an entangled state, also called a [Bell state](https://qiskit.org/textbook/ch-gates/multiple-qubits-entangled-states.html#3.2-Entangled-States-).
41
42 Once you've made your first quantum circuit, you can then simulate it.
43 To do this, first we need to compile your circuit for the target backend we're going to run
44 on. In this case we are leveraging the built-in `BasicAer` simulator. However, this
45 simulator is primarily for testing and is limited in performance and functionality (as the name
46 implies). You should consider more sophisticated simulators, such as [`qiskit-aer`](https://github.com/Qiskit/qiskit-aer/),
47 for any real simulation work.
48
49 ```python
50 from qiskit import transpile
51 from qiskit.providers.basicaer import QasmSimulatorPy
52 backend_sim = QasmSimulatorPy()
53 transpiled_qc = transpile(qc, backend_sim)
54 ```
55
56 After compiling the circuit we can then run this on the ``backend`` object with:
57
58 ```python
59 result = backend_sim.run(transpiled_qc).result()
60 print(result.get_counts(qc))
61 ```
62
63 The output from this execution will look similar to this:
64
65 ```python
66 {'00': 513, '11': 511}
67 ```
68
69 For further examples of using Qiskit you can look at the example scripts in **examples/python**. You can start with
70 [using_qiskit_terra_level_0.py](examples/python/using_qiskit_terra_level_0.py) and working up in the levels. Also
71 you can refer to the tutorials in the documentation here:
72
73 https://qiskit.org/documentation/tutorials.html
74
75
76 ### Executing your code on a real quantum chip
77
78 You can also use Qiskit to execute your code on a **real quantum processor**.
79 Qiskit provides an abstraction layer that lets users run quantum circuits on hardware from any
80 vendor that provides an interface to their systems through Qiskit. Using these ``providers`` you can run any Qiskit code against
81 real quantum computers. Some examples of published provider packages for running on real hardware are:
82
83 * https://github.com/Qiskit/qiskit-ibmq-provider
84 * https://github.com/Qiskit-Partners/qiskit-ionq
85 * https://github.com/Qiskit-Partners/qiskit-aqt-provider
86 * https://github.com/qiskit-community/qiskit-braket-provider
87 * https://github.com/qiskit-community/qiskit-quantinuum-provider
88 * https://github.com/rigetti/qiskit-rigetti
89
90 <!-- This is not an exhasutive list, and if you maintain a provider package please feel free to open a PR to add new providers -->
91
92 You can refer to the documentation of these packages for further instructions
93 on how to get access and use these systems.
94
95 ## Contribution Guidelines
96
97 If you'd like to contribute to Qiskit Terra, please take a look at our
98 [contribution guidelines](CONTRIBUTING.md). This project adheres to Qiskit's [code of conduct](CODE_OF_CONDUCT.md). By participating, you are expected to uphold this code.
99
100 We use [GitHub issues](https://github.com/Qiskit/qiskit-terra/issues) for tracking requests and bugs. Please
101 [join the Qiskit Slack community](https://qisk.it/join-slack)
102 and use our [Qiskit Slack channel](https://qiskit.slack.com) for discussion and simple questions.
103 For questions that are more suited for a forum we use the `qiskit` tag in the [Stack Exchange](https://quantumcomputing.stackexchange.com/questions/tagged/qiskit).
104
105 ## Next Steps
106
107 Now you're set up and ready to check out some of the other examples from our
108 [Qiskit Tutorials](https://github.com/Qiskit/qiskit-tutorials) repository.
109
110 ## Authors and Citation
111
112 Qiskit Terra is the work of [many people](https://github.com/Qiskit/qiskit-terra/graphs/contributors) who contribute
113 to the project at different levels. If you use Qiskit, please cite as per the included [BibTeX file](https://github.com/Qiskit/qiskit/blob/master/Qiskit.bib).
114
115 ## Changelog and Release Notes
116
117 The changelog for a particular release is dynamically generated and gets
118 written to the release page on Github for each release. For example, you can
119 find the page for the `0.9.0` release here:
120
121 https://github.com/Qiskit/qiskit-terra/releases/tag/0.9.0
122
123 The changelog for the current release can be found in the releases tab:
124 [](https://github.com/Qiskit/qiskit-terra/releases)
125 The changelog provides a quick overview of notable changes for a given
126 release.
127
128 Additionally, as part of each release detailed release notes are written to
129 document in detail what has changed as part of a release. This includes any
130 documentation on potential breaking changes on upgrade and new features.
131 For example, you can find the release notes for the `0.9.0` release in the
132 Qiskit documentation here:
133
134 https://qiskit.org/documentation/release_notes.html#terra-0-9
135
136 ## License
137
138 [Apache License 2.0](LICENSE.txt)
139
[end of README.md]
[start of examples/python/rippleadd.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """
14 Ripple adder example based on Cuccaro et al., quant-ph/0410184.
15
16 """
17
18 from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit
19 from qiskit import BasicAer
20 from qiskit import execute
21
22 ###############################################################
23 # Set the backend name and coupling map.
24 ###############################################################
25 backend = BasicAer.get_backend("qasm_simulator")
26 coupling_map = [
27 [0, 1],
28 [0, 8],
29 [1, 2],
30 [1, 9],
31 [2, 3],
32 [2, 10],
33 [3, 4],
34 [3, 11],
35 [4, 5],
36 [4, 12],
37 [5, 6],
38 [5, 13],
39 [6, 7],
40 [6, 14],
41 [7, 15],
42 [8, 9],
43 [9, 10],
44 [10, 11],
45 [11, 12],
46 [12, 13],
47 [13, 14],
48 [14, 15],
49 ]
50
51 ###############################################################
52 # Make a quantum program for the n-bit ripple adder.
53 ###############################################################
54 n = 2
55
56 a = QuantumRegister(n, "a")
57 b = QuantumRegister(n, "b")
58 cin = QuantumRegister(1, "cin")
59 cout = QuantumRegister(1, "cout")
60 ans = ClassicalRegister(n + 1, "ans")
61 qc = QuantumCircuit(a, b, cin, cout, ans, name="rippleadd")
62
63
64 def majority(p, a, b, c):
65 """Majority gate."""
66 p.cx(c, b)
67 p.cx(c, a)
68 p.ccx(a, b, c)
69
70
71 def unmajority(p, a, b, c):
72 """Unmajority gate."""
73 p.ccx(a, b, c)
74 p.cx(c, a)
75 p.cx(a, b)
76
77
78 # Build a temporary subcircuit that adds a to b,
79 # storing the result in b
80 adder_subcircuit = QuantumCircuit(cin, a, b, cout)
81 majority(adder_subcircuit, cin[0], b[0], a[0])
82 for j in range(n - 1):
83 majority(adder_subcircuit, a[j], b[j + 1], a[j + 1])
84 adder_subcircuit.cx(a[n - 1], cout[0])
85 for j in reversed(range(n - 1)):
86 unmajority(adder_subcircuit, a[j], b[j + 1], a[j + 1])
87 unmajority(adder_subcircuit, cin[0], b[0], a[0])
88
89 # Set the inputs to the adder
90 qc.x(a[0]) # Set input a = 0...0001
91 qc.x(b) # Set input b = 1...1111
92 # Apply the adder
93 qc &= adder_subcircuit
94 # Measure the output register in the computational basis
95 for j in range(n):
96 qc.measure(b[j], ans[j])
97 qc.measure(cout[0], ans[n])
98
99 ###############################################################
100 # execute the program.
101 ###############################################################
102
103 # First version: not mapped
104 job = execute(qc, backend=backend, coupling_map=None, shots=1024)
105 result = job.result()
106 print(result.get_counts(qc))
107
108 # Second version: mapped to 2x8 array coupling graph
109 job = execute(qc, backend=backend, coupling_map=coupling_map, shots=1024)
110 result = job.result()
111 print(result.get_counts(qc))
112
113 # Both versions should give the same distribution
114
[end of examples/python/rippleadd.py]
[start of qiskit/circuit/__init__.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """
14 ========================================
15 Quantum Circuits (:mod:`qiskit.circuit`)
16 ========================================
17
18 .. currentmodule:: qiskit.circuit
19
20 Overview
21 ========
22
23 The fundamental element of quantum computing is the **quantum circuit**.
24 A quantum circuit is a computational routine consisting of coherent quantum
25 operations on quantum data, such as qubits. It is an ordered sequence of quantum
26 gates, measurements and resets, which may be conditioned on real-time classical
27 computation. A set of quantum gates is said to be universal if any unitary
28 transformation of the quantum data can be efficiently approximated arbitrarily well
29 as as sequence of gates in the set. Any quantum program can be represented by a
30 sequence of quantum circuits and classical near-time computation.
31
32 In Qiskit, this core element is represented by the :class:`QuantumCircuit` class.
33 Below is an example of a quantum circuit that makes a three-qubit GHZ state
34 defined as:
35
36 .. math::
37
38 |\\psi\\rangle = \\left(|000\\rangle+|111\\rangle\\right)/\\sqrt{2}
39
40
41 .. plot::
42 :include-source:
43
44 from qiskit import QuantumCircuit
45 # Create a circuit with a register of three qubits
46 circ = QuantumCircuit(3)
47 # H gate on qubit 0, putting this qubit in a superposition of |0> + |1>.
48 circ.h(0)
49 # A CX (CNOT) gate on control qubit 0 and target qubit 1 generating a Bell state.
50 circ.cx(0, 1)
51 # CX (CNOT) gate on control qubit 0 and target qubit 2 resulting in a GHZ state.
52 circ.cx(0, 2)
53 # Draw the circuit
54 circ.draw('mpl')
55
56
57 Supplementary Information
58 =========================
59
60 .. dropdown:: Quantum Circuit with conditionals
61 :animate: fade-in-slide-down
62
63 When building a quantum circuit, there can be interest in applying a certain gate only
64 if a classical register has a specific value. This can be done with the
65 :meth:`InstructionSet.c_if` method.
66
67 In the following example, we start with a single-qubit circuit formed by only a Hadamard gate
68 (:class:`~.HGate`), in which we expect to get :math:`|0\\rangle` and :math:`|1\\rangle`
69 with equal probability.
70
71 .. plot::
72 :include-source:
73
74 from qiskit import BasicAer, transpile, QuantumRegister, ClassicalRegister, QuantumCircuit
75
76 qr = QuantumRegister(1)
77 cr = ClassicalRegister(1)
78 qc = QuantumCircuit(qr, cr)
79 qc.h(0)
80 qc.measure(0, 0)
81 qc.draw('mpl')
82
83 .. code-block::
84
85 backend = BasicAer.get_backend('qasm_simulator')
86 tqc = transpile(qc, backend)
87 counts = backend.run(tqc).result().get_counts()
88
89 print(counts)
90
91 .. parsed-literal::
92
93 {'0': 524, '1': 500}
94
95 Now, we add an :class:`~.XGate` only if the value of the :class:`~.ClassicalRegister` is 0.
96 That way, if the state is :math:`|0\\rangle`, it will be changed to :math:`|1\\rangle` and
97 if the state is :math:`|1\\rangle`, it will not be changed at all, so the final state will
98 always be :math:`|1\\rangle`.
99
100 .. plot::
101 :include-source:
102
103 from qiskit import BasicAer, transpile, QuantumRegister, ClassicalRegister, QuantumCircuit
104
105 qr = QuantumRegister(1)
106 cr = ClassicalRegister(1)
107 qc = QuantumCircuit(qr, cr)
108 qc.h(0)
109 qc.measure(0, 0)
110
111 qc.x(0).c_if(cr, 0)
112 qc.measure(0, 0)
113
114 qc.draw('mpl')
115
116 .. code-block::
117
118 backend = BasicAer.get_backend('qasm_simulator')
119 tqc = transpile(qc, backend)
120 counts = backend.run(tqc).result().get_counts()
121
122 print(counts)
123
124 .. parsed-literal::
125
126 {'1': 1024}
127
128 .. dropdown:: Quantum Circuit Properties
129 :animate: fade-in-slide-down
130
131 When constructing quantum circuits, there are several properties that help quantify
132 the "size" of the circuits, and their ability to be run on a noisy quantum device.
133 Some of these, like number of qubits, are straightforward to understand, while others
134 like depth and number of tensor components require a bit more explanation. Here we will
135 explain all of these properties, and, in preparation for understanding how circuits change
136 when run on actual devices, highlight the conditions under which they change.
137
138 Consider the following circuit:
139
140 .. plot::
141 :include-source:
142
143 from qiskit import QuantumCircuit
144 qc = QuantumCircuit(12)
145 for idx in range(5):
146 qc.h(idx)
147 qc.cx(idx, idx+5)
148
149 qc.cx(1, 7)
150 qc.x(8)
151 qc.cx(1, 9)
152 qc.x(7)
153 qc.cx(1, 11)
154 qc.swap(6, 11)
155 qc.swap(6, 9)
156 qc.swap(6, 10)
157 qc.x(6)
158 qc.draw('mpl')
159
160 From the plot, it is easy to see that this circuit has 12 qubits, and a collection of
161 Hadamard, CNOT, X, and SWAP gates. But how to quantify this programmatically? Because we
162 can do single-qubit gates on all the qubits simultaneously, the number of qubits in this
163 circuit is equal to the **width** of the circuit:
164
165 .. code-block::
166
167 qc.width()
168
169 .. parsed-literal::
170
171 12
172
173 We can also just get the number of qubits directly:
174
175 .. code-block::
176
177 qc.num_qubits
178
179 .. parsed-literal::
180
181 12
182
183 .. important::
184
185 For a quantum circuit composed from just qubits, the circuit width is equal
186 to the number of qubits. This is the definition used in quantum computing. However,
187 for more complicated circuits with classical registers, and classically controlled gates,
188 this equivalence breaks down. As such, from now on we will not refer to the number of
189 qubits in a quantum circuit as the width.
190
191
192 It is also straightforward to get the number and type of the gates in a circuit using
193 :meth:`QuantumCircuit.count_ops`:
194
195 .. code-block::
196
197 qc.count_ops()
198
199 .. parsed-literal::
200
201 OrderedDict([('cx', 8), ('h', 5), ('x', 3), ('swap', 3)])
202
203 We can also get just the raw count of operations by computing the circuits
204 :meth:`QuantumCircuit.size`:
205
206 .. code-block::
207
208 qc.size()
209
210 .. parsed-literal::
211
212 19
213
214 A particularly important circuit property is known as the circuit **depth**. The depth
215 of a quantum circuit is a measure of how many "layers" of quantum gates, executed in
216 parallel, it takes to complete the computation defined by the circuit. Because quantum
217 gates take time to implement, the depth of a circuit roughly corresponds to the amount of
218 time it takes the quantum computer to execute the circuit. Thus, the depth of a circuit
219 is one important quantity used to measure if a quantum circuit can be run on a device.
220
221 The depth of a quantum circuit has a mathematical definition as the longest path in a
222 directed acyclic graph (DAG). However, such a definition is a bit hard to grasp, even for
223 experts. Fortunately, the depth of a circuit can be easily understood by anyone familiar
224 with playing `Tetris <https://en.wikipedia.org/wiki/Tetris>`_. Lets see how to compute this
225 graphically:
226
227 .. image:: /source_images/depth.gif
228
229
230 .. raw:: html
231
232 <br><br>
233
234
235 We can verify our graphical result using :meth:`QuantumCircuit.depth`:
236
237 .. code-block::
238
239 qc.depth()
240
241 .. parsed-literal::
242
243 9
244
245 .. raw:: html
246
247 <br>
248
249 Quantum Circuit API
250 ===================
251
252 Quantum Circuit Construction
253 ----------------------------
254
255 .. autosummary::
256 :toctree: ../stubs/
257
258 QuantumCircuit
259 QuantumRegister
260 Qubit
261 ClassicalRegister
262 Clbit
263 AncillaRegister
264 AncillaQubit
265 CircuitInstruction
266 Register
267 Bit
268
269 Gates and Instructions
270 ----------------------
271
272 .. autosummary::
273 :toctree: ../stubs/
274
275 Gate
276 ControlledGate
277 Delay
278 Instruction
279 InstructionSet
280 Operation
281 EquivalenceLibrary
282
283 Control Flow Operations
284 -----------------------
285
286 .. autosummary::
287 :toctree: ../stubs/
288
289 ControlFlowOp
290 IfElseOp
291 WhileLoopOp
292 ForLoopOp
293 BreakLoopOp
294 ContinueLoopOp
295
296 Parametric Quantum Circuits
297 ---------------------------
298
299 .. autosummary::
300 :toctree: ../stubs/
301
302 Parameter
303 ParameterVector
304 ParameterExpression
305
306 Random Circuits
307 ---------------
308
309 .. autosummary::
310 :toctree: ../stubs/
311
312 random.random_circuit
313 """
314 from .quantumcircuit import QuantumCircuit
315 from .classicalregister import ClassicalRegister, Clbit
316 from .quantumregister import QuantumRegister, Qubit, AncillaRegister, AncillaQubit
317 from .gate import Gate
318
319 # pylint: disable=cyclic-import
320 from .controlledgate import ControlledGate
321 from .instruction import Instruction
322 from .instructionset import InstructionSet
323 from .operation import Operation
324 from .barrier import Barrier
325 from .delay import Delay
326 from .measure import Measure
327 from .reset import Reset
328 from .parameter import Parameter
329 from .parametervector import ParameterVector
330 from .parameterexpression import ParameterExpression
331 from .quantumcircuitdata import CircuitInstruction
332 from .equivalence import EquivalenceLibrary
333 from .bit import Bit
334 from .register import Register
335 from . import library
336 from .commutation_checker import CommutationChecker
337
338 from .controlflow import (
339 ControlFlowOp,
340 WhileLoopOp,
341 ForLoopOp,
342 IfElseOp,
343 BreakLoopOp,
344 ContinueLoopOp,
345 )
346
347
348 _DEPRECATED_NAMES = {
349 "Int1": "qiskit.circuit.classicalfunction.types",
350 "Int2": "qiskit.circuit.classicalfunction.types",
351 "classical_function": "qiskit.circuit.classicalfunction",
352 "BooleanExpression": "qiskit.circuit.classicalfunction",
353 }
354
355
356 def __getattr__(name):
357 if name in _DEPRECATED_NAMES:
358 import importlib
359 import warnings
360
361 module_name = _DEPRECATED_NAMES[name]
362 warnings.warn(
363 f"Accessing '{name}' from '{__name__}' is deprecated since Qiskit Terra 0.22 "
364 f"and will be removed in 0.23. Import from '{module_name}' instead. "
365 "This will require installing 'tweedledum' as an optional dependency from Terra 0.23.",
366 DeprecationWarning,
367 stacklevel=2,
368 )
369 return getattr(importlib.import_module(module_name), name)
370 raise AttributeError(f"module '{__name__}' has no attribute '{name}'")
371
[end of qiskit/circuit/__init__.py]
[start of qiskit/transpiler/passes/routing/stochastic_swap.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017, 2018.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """Map a DAGCircuit onto a `coupling_map` adding swap gates."""
14
15 import itertools
16 import logging
17 from math import inf
18 import numpy as np
19
20 from qiskit.converters import dag_to_circuit, circuit_to_dag
21 from qiskit.circuit.quantumregister import QuantumRegister
22 from qiskit.transpiler.basepasses import TransformationPass
23 from qiskit.transpiler.exceptions import TranspilerError
24 from qiskit.dagcircuit import DAGCircuit
25 from qiskit.circuit.library.standard_gates import SwapGate
26 from qiskit.transpiler.layout import Layout
27 from qiskit.circuit import IfElseOp, WhileLoopOp, ForLoopOp, ControlFlowOp, Instruction
28 from qiskit._accelerate import stochastic_swap as stochastic_swap_rs
29 from qiskit._accelerate import nlayout
30
31 from .utils import get_swap_map_dag
32
33 logger = logging.getLogger(__name__)
34
35
36 class StochasticSwap(TransformationPass):
37 """Map a DAGCircuit onto a `coupling_map` adding swap gates.
38
39 Uses a randomized algorithm.
40
41 Notes:
42 1. Measurements may occur and be followed by swaps that result in repeated
43 measurement of the same qubit. Near-term experiments cannot implement
44 these circuits, so some care is required when using this mapper
45 with experimental backend targets.
46
47 2. We do not use the fact that the input state is zero to simplify
48 the circuit.
49 """
50
51 def __init__(self, coupling_map, trials=20, seed=None, fake_run=False, initial_layout=None):
52 """StochasticSwap initializer.
53
54 The coupling map is a connected graph
55
56 If these are not satisfied, the behavior is undefined.
57
58 Args:
59 coupling_map (CouplingMap): Directed graph representing a coupling
60 map.
61 trials (int): maximum number of iterations to attempt
62 seed (int): seed for random number generator
63 fake_run (bool): if true, it only pretend to do routing, i.e., no
64 swap is effectively added.
65 initial_layout (Layout): starting layout at beginning of pass.
66 """
67 super().__init__()
68 self.coupling_map = coupling_map
69 self.trials = trials
70 self.seed = seed
71 self.rng = None
72 self.fake_run = fake_run
73 self.qregs = None
74 self.initial_layout = initial_layout
75 self._qubit_to_int = None
76 self._int_to_qubit = None
77
78 def run(self, dag):
79 """Run the StochasticSwap pass on `dag`.
80
81 Args:
82 dag (DAGCircuit): DAG to map.
83
84 Returns:
85 DAGCircuit: A mapped DAG.
86
87 Raises:
88 TranspilerError: if the coupling map or the layout are not
89 compatible with the DAG, or if the coupling_map=None
90 """
91
92 if self.coupling_map is None:
93 raise TranspilerError("StochasticSwap cannot run with coupling_map=None")
94
95 if len(dag.qregs) != 1 or dag.qregs.get("q", None) is None:
96 raise TranspilerError("StochasticSwap runs on physical circuits only")
97
98 if len(dag.qubits) > len(self.coupling_map.physical_qubits):
99 raise TranspilerError("The layout does not match the amount of qubits in the DAG")
100
101 self.rng = np.random.default_rng(self.seed)
102
103 canonical_register = dag.qregs["q"]
104 if self.initial_layout is None:
105 self.initial_layout = Layout.generate_trivial_layout(canonical_register)
106 # Qubit indices are used to assign an integer to each virtual qubit during the routing: it's
107 # a mapping of {virtual: virtual}, for converting between Python and Rust forms.
108 self._qubit_to_int = {bit: idx for idx, bit in enumerate(dag.qubits)}
109 self._int_to_qubit = tuple(dag.qubits)
110
111 self.qregs = dag.qregs
112 logger.debug("StochasticSwap rng seeded with seed=%s", self.seed)
113 self.coupling_map.compute_distance_matrix()
114 new_dag = self._mapper(dag, self.coupling_map, trials=self.trials)
115 return new_dag
116
117 def _layer_permutation(self, layer_partition, layout, qubit_subset, coupling, trials):
118 """Find a swap circuit that implements a permutation for this layer.
119
120 The goal is to swap qubits such that qubits in the same two-qubit gates
121 are adjacent.
122
123 Based on S. Bravyi's algorithm.
124
125 Args:
126 layer_partition (list): The layer_partition is a list of (qu)bit
127 lists and each qubit is a tuple (qreg, index).
128 layout (Layout): The layout is a Layout object mapping virtual
129 qubits in the input circuit to physical qubits in the coupling
130 graph. It reflects the current positions of the data.
131 qubit_subset (list): The qubit_subset is the set of qubits in
132 the coupling graph that we have chosen to map into, as tuples
133 (Register, index).
134 coupling (CouplingMap): Directed graph representing a coupling map.
135 This coupling map should be one that was provided to the
136 stochastic mapper.
137 trials (int): Number of attempts the randomized algorithm makes.
138
139 Returns:
140 Tuple: success_flag, best_circuit, best_depth, best_layout
141
142 If success_flag is True, then best_circuit contains a DAGCircuit with
143 the swap circuit, best_depth contains the depth of the swap circuit,
144 and best_layout contains the new positions of the data qubits after the
145 swap circuit has been applied.
146
147 Raises:
148 TranspilerError: if anything went wrong.
149 """
150 logger.debug("layer_permutation: layer_partition = %s", layer_partition)
151 logger.debug("layer_permutation: layout = %s", layout.get_virtual_bits())
152 logger.debug("layer_permutation: qubit_subset = %s", qubit_subset)
153 logger.debug("layer_permutation: trials = %s", trials)
154
155 # The input dag is on a flat canonical register
156 canonical_register = QuantumRegister(len(layout), "q")
157
158 gates = [] # list of lists of tuples [[(register, index), ...], ...]
159 for gate_args in layer_partition:
160 if len(gate_args) > 2:
161 raise TranspilerError("Layer contains > 2-qubit gates")
162 if len(gate_args) == 2:
163 gates.append(tuple(gate_args))
164 logger.debug("layer_permutation: gates = %s", gates)
165
166 # Can we already apply the gates? If so, there is no work to do.
167 # Accessing via private attributes to avoid overhead from __getitem__
168 # and to optimize performance of the distance matrix access
169 dist = sum(coupling._dist_matrix[layout._v2p[g[0]], layout._v2p[g[1]]] for g in gates)
170 logger.debug("layer_permutation: distance = %s", dist)
171 if dist == len(gates):
172 logger.debug("layer_permutation: nothing to do")
173 circ = DAGCircuit()
174 circ.add_qreg(canonical_register)
175 return True, circ, 0, layout
176
177 # Begin loop over trials of randomized algorithm
178 num_qubits = len(layout)
179 best_depth = inf # initialize best depth
180 best_edges = None # best edges found
181 best_circuit = None # initialize best swap circuit
182 best_layout = None # initialize best final layout
183
184 cdist2 = coupling._dist_matrix**2
185 int_qubit_subset = np.fromiter(
186 (self._qubit_to_int[bit] for bit in qubit_subset),
187 dtype=np.uintp,
188 count=len(qubit_subset),
189 )
190
191 int_gates = np.fromiter(
192 (self._qubit_to_int[bit] for gate in gates for bit in gate),
193 dtype=np.uintp,
194 count=2 * len(gates),
195 )
196
197 layout_mapping = {self._qubit_to_int[k]: v for k, v in layout.get_virtual_bits().items()}
198 int_layout = nlayout.NLayout(layout_mapping, num_qubits, coupling.size())
199
200 trial_circuit = DAGCircuit() # SWAP circuit for slice of swaps in this trial
201 trial_circuit.add_qubits(layout.get_virtual_bits())
202
203 edges = np.asarray(coupling.get_edges(), dtype=np.uintp).ravel()
204 cdist = coupling._dist_matrix
205 best_edges, best_layout, best_depth = stochastic_swap_rs.swap_trials(
206 trials,
207 num_qubits,
208 int_layout,
209 int_qubit_subset,
210 int_gates,
211 cdist,
212 cdist2,
213 edges,
214 seed=self.seed,
215 )
216 # If we have no best circuit for this layer, all of the trials have failed
217 if best_layout is None:
218 logger.debug("layer_permutation: failed!")
219 return False, None, None, None
220
221 edges = best_edges.edges()
222 for idx in range(len(edges) // 2):
223 swap_src = self._int_to_qubit[edges[2 * idx]]
224 swap_tgt = self._int_to_qubit[edges[2 * idx + 1]]
225 trial_circuit.apply_operation_back(SwapGate(), [swap_src, swap_tgt], [])
226 best_circuit = trial_circuit
227
228 # Otherwise, we return our result for this layer
229 logger.debug("layer_permutation: success!")
230 layout_mapping = best_layout.layout_mapping()
231
232 best_lay = Layout({best_circuit.qubits[k]: v for (k, v) in layout_mapping})
233 return True, best_circuit, best_depth, best_lay
234
235 def _layer_update(self, dag, layer, best_layout, best_depth, best_circuit):
236 """Add swaps followed by the now mapped layer from the original circuit.
237
238 Args:
239 dag (DAGCircuit): The DAGCircuit object that the _mapper method is building
240 layer (DAGCircuit): A DAGCircuit layer from the original circuit
241 best_layout (Layout): layout returned from _layer_permutation
242 best_depth (int): depth returned from _layer_permutation
243 best_circuit (DAGCircuit): swap circuit returned from _layer_permutation
244 """
245 logger.debug("layer_update: layout = %s", best_layout)
246 logger.debug("layer_update: self.initial_layout = %s", self.initial_layout)
247
248 # Output any swaps
249 if best_depth > 0:
250 logger.debug("layer_update: there are swaps in this layer, depth %d", best_depth)
251 dag.compose(best_circuit, qubits={bit: bit for bit in best_circuit.qubits})
252 else:
253 logger.debug("layer_update: there are no swaps in this layer")
254 # Output this layer
255 dag.compose(layer["graph"], qubits=best_layout.reorder_bits(dag.qubits))
256
257 def _mapper(self, circuit_graph, coupling_graph, trials=20):
258 """Map a DAGCircuit onto a CouplingMap using swap gates.
259
260 Args:
261 circuit_graph (DAGCircuit): input DAG circuit
262 coupling_graph (CouplingMap): coupling graph to map onto
263 trials (int): number of trials.
264
265 Returns:
266 DAGCircuit: object containing a circuit equivalent to
267 circuit_graph that respects couplings in coupling_graph
268
269 Raises:
270 TranspilerError: if there was any error during the mapping
271 or with the parameters.
272 """
273 # Schedule the input circuit by calling layers()
274 layerlist = list(circuit_graph.layers())
275 logger.debug("schedule:")
276 for i, v in enumerate(layerlist):
277 logger.debug(" %d: %s", i, v["partition"])
278
279 qubit_subset = self.initial_layout.get_virtual_bits().keys()
280
281 # Find swap circuit to precede each layer of input circuit
282 layout = self.initial_layout.copy()
283
284 # Construct an empty DAGCircuit with the same set of
285 # qregs and cregs as the input circuit
286 dagcircuit_output = None
287 if not self.fake_run:
288 dagcircuit_output = circuit_graph.copy_empty_like()
289
290 logger.debug("layout = %s", layout)
291
292 # Iterate over layers
293 for i, layer in enumerate(layerlist):
294 # First try and compute a route for the entire layer in one go.
295 if not layer["graph"].op_nodes(op=ControlFlowOp):
296 success_flag, best_circuit, best_depth, best_layout = self._layer_permutation(
297 layer["partition"], layout, qubit_subset, coupling_graph, trials
298 )
299
300 logger.debug("mapper: layer %d", i)
301 logger.debug("mapper: success_flag=%s,best_depth=%s", success_flag, str(best_depth))
302 if success_flag:
303 layout = best_layout
304
305 # Update the DAG
306 if not self.fake_run:
307 self._layer_update(
308 dagcircuit_output, layerlist[i], best_layout, best_depth, best_circuit
309 )
310 continue
311
312 # If we're here, we need to go through every gate in the layer serially.
313 logger.debug("mapper: failed, layer %d, retrying sequentially", i)
314 # Go through each gate in the layer
315 for j, serial_layer in enumerate(layer["graph"].serial_layers()):
316 layer_dag = serial_layer["graph"]
317 # layer_dag has only one operation
318 op_node = layer_dag.op_nodes()[0]
319 if isinstance(op_node.op, ControlFlowOp):
320 layout = self._controlflow_layer_update(
321 dagcircuit_output, layer_dag, layout, circuit_graph
322 )
323 else:
324 (success_flag, best_circuit, best_depth, best_layout) = self._layer_permutation(
325 serial_layer["partition"], layout, qubit_subset, coupling_graph, trials
326 )
327 logger.debug("mapper: layer %d, sublayer %d", i, j)
328 logger.debug(
329 "mapper: success_flag=%s,best_depth=%s,", success_flag, str(best_depth)
330 )
331
332 # Give up if we fail again
333 if not success_flag:
334 raise TranspilerError(
335 "swap mapper failed: " + "layer %d, sublayer %d" % (i, j)
336 )
337
338 # Update the record of qubit positions
339 # for each inner iteration
340 layout = best_layout
341 # Update the DAG
342 if not self.fake_run:
343 self._layer_update(
344 dagcircuit_output,
345 serial_layer,
346 best_layout,
347 best_depth,
348 best_circuit,
349 )
350
351 # This is the final edgemap. We might use it to correctly replace
352 # any measurements that needed to be removed earlier.
353 logger.debug("mapper: self.initial_layout = %s", self.initial_layout)
354 logger.debug("mapper: layout = %s", layout)
355
356 self.property_set["final_layout"] = layout
357 if self.fake_run:
358 return circuit_graph
359 return dagcircuit_output
360
361 def _controlflow_layer_update(self, dagcircuit_output, layer_dag, current_layout, root_dag):
362 """
363 Updates the new dagcircuit with a routed control flow operation.
364
365 Args:
366 dagcircuit_output (DAGCircuit): dagcircuit that is being built with routed operations.
367 layer_dag (DAGCircuit): layer to route containing a single controlflow operation.
368 current_layout (Layout): current layout coming into this layer.
369 root_dag (DAGCircuit): root dag of pass
370
371 Returns:
372 Layout: updated layout after this layer has been routed.
373
374 Raises:
375 TranspilerError: if layer_dag does not contain a recognized ControlFlowOp.
376
377 """
378 node = layer_dag.op_nodes()[0]
379 if not isinstance(node.op, (IfElseOp, ForLoopOp, WhileLoopOp)):
380 raise TranspilerError(f"unsupported control flow operation: {node}")
381 # For each block, expand it up be the full width of the containing DAG so we can be certain
382 # that it is routable, then route it within that. When we recombine later, we'll reduce all
383 # these blocks down to remove any qubits that are idle.
384 block_dags = []
385 block_layouts = []
386 for block in node.op.blocks:
387 inner_pass = self._recursive_pass(current_layout)
388 block_dags.append(inner_pass.run(_dag_from_block(block, node, root_dag)))
389 block_layouts.append(inner_pass.property_set["final_layout"].copy())
390
391 # Determine what layout we need to go towards. For some blocks (such as `for`), we must
392 # guarantee that the final layout is the same as the initial or the loop won't work. For an
393 # `if` with an `else`, we don't need that as long as the two branches are the same. We have
394 # to be careful with `if` _without_ an else, though - the `if` needs to restore the layout
395 # in case it isn't taken; we can't have two different virtual layouts.
396 if not (isinstance(node.op, IfElseOp) and len(node.op.blocks) == 2):
397 final_layout = current_layout
398 else:
399 # We heuristically just choose to use the layout of whatever the deepest block is, to
400 # avoid extending the total depth by too much.
401 final_layout = max(
402 zip(block_layouts, block_dags), key=lambda x: x[1].depth(recurse=True)
403 )[0]
404 if self.fake_run:
405 return final_layout
406
407 # Add swaps to the end of each block to make sure they all have the same layout at the end.
408 # Adding these swaps can cause fewer wires to be idle than we expect (if we have to swap
409 # across unused qubits), so we track that at this point too.
410 idle_qubits = set(root_dag.qubits)
411 for layout, updated_dag_block in zip(block_layouts, block_dags):
412 swap_dag, swap_qubits = get_swap_map_dag(
413 root_dag, self.coupling_map, layout, final_layout, seed=self._new_seed()
414 )
415 if swap_dag.size(recurse=False):
416 updated_dag_block.compose(swap_dag, qubits=swap_qubits)
417 idle_qubits &= set(updated_dag_block.idle_wires())
418
419 # Now for each block, expand it to be full width over all active wires (all blocks of a
420 # control-flow operation need to have equal input wires), and convert it to circuit form.
421 block_circuits = []
422 for updated_dag_block in block_dags:
423 updated_dag_block.remove_qubits(*idle_qubits)
424 block_circuits.append(dag_to_circuit(updated_dag_block))
425
426 new_op = node.op.replace_blocks(block_circuits)
427 new_qargs = block_circuits[0].qubits
428 dagcircuit_output.apply_operation_back(new_op, new_qargs, node.cargs)
429 return final_layout
430
431 def _new_seed(self):
432 """Get a seed for a new RNG instance."""
433 return self.rng.integers(0x7FFF_FFFF_FFFF_FFFF)
434
435 def _recursive_pass(self, initial_layout):
436 """Get a new instance of this class to handle a recursive call for a control-flow block.
437
438 Each pass starts with its own new seed, determined deterministically from our own."""
439 return self.__class__(
440 self.coupling_map,
441 # This doesn't cause an exponential explosion of the trials because we only generate a
442 # recursive pass instance for control-flow operations, while the trial multiplicity is
443 # only for non-control-flow layers.
444 trials=self.trials,
445 seed=self._new_seed(),
446 fake_run=self.fake_run,
447 initial_layout=initial_layout,
448 )
449
450
451 def _dag_from_block(block, node, root_dag):
452 """Get a :class:`DAGCircuit` that represents the :class:`.QuantumCircuit` ``block`` embedded
453 within the ``root_dag`` for full-width routing purposes. This means that all the qubits are in
454 the output DAG, but only the necessary clbits and classical registers are."""
455 out = DAGCircuit()
456 # The pass already ensured that `root_dag` has only a single quantum register with everything.
457 for qreg in root_dag.qregs.values():
458 out.add_qreg(qreg)
459 # For clbits, we need to take more care. Nested control-flow might need registers to exist for
460 # conditions on inner blocks. `DAGCircuit.substitute_node_with_dag` handles this register
461 # mapping when required, so we use that with a dummy block.
462 out.add_clbits(node.cargs)
463 dummy = out.apply_operation_back(
464 Instruction("dummy", len(node.qargs), len(node.cargs), []), node.qargs, node.cargs
465 )
466 wire_map = dict(itertools.chain(zip(block.qubits, node.qargs), zip(block.clbits, node.cargs)))
467 out.substitute_node_with_dag(dummy, circuit_to_dag(block), wires=wire_map)
468 return out
469
[end of qiskit/transpiler/passes/routing/stochastic_swap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| Qiskit/qiskit | 3ab57152c1d7e0eb572eb298f6fa922299492586 | DAGCircuitError: 'bit mapping invalid
### Informations
- **Qiskit: 0.39.2**:
- **Python: 3.10.9**:
- **Mac**:
### What is the current behavior?
I'm implementing quantum half adder on Jupyter Notebook.
When I try running my circuit on the simulator "qasm_simulator", Jupyter said
DAGCircuitError: 'bit mapping invalid: expected 4, got 8'
here is the code I've written. The error occurs on the last line of the third code.
```
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute, Aer
#SUM
X = QuantumRegister(1, "in |X⟩")
Y = QuantumRegister(1, "in |Y⟩")
sum_out = QuantumRegister(1, "out SUM |0⟩")
SUM = QuantumCircuit(X, Y, sum_out, name='SUM')
SUM.cx(1, 2)
SUM.cx(0, 2)
fig = SUM.draw('mpl', True)
SUM = SUM.to_instruction()
fig
```
```
#half_adder
cout = QuantumRegister(1, 'out Carry |0⟩')
c = ClassicalRegister(4)
hadder = QuantumCircuit(X,Y,sum_out,cout,c)
hadder.ccx(X,Y,cout)
hadder.append(SUM,[0,1,2])
show = hadder.draw("mpl",True)
hadder = hadder.to_instruction()
show
```
```
#testing half_adder
qu = QuantumRegister(4)
cl = ClassicalRegister(4)
circ = QuantumCircuit(qu,cl)
circ.x(qu[0])
circ.x(qu[1])
circ.append(hadder,[0,1,2,3])
for i in range(0,4):
circ.measure(qu[i],cl[i])
circ.draw("mpl",True)
print(execute(circ,Aer.get_backend('qasm_simulator'), shots = 1).result().get_counts())
```
### What is the expected behavior?
I don't totally understand the error. I hope to troubleshoot to see the result.
### Suggested solutions
| Your immediate problem is that the line
```python
circ.append(hadder, [0, 1, 2, 3])
```
doesn't include any classical arguments to apply `hadder` to, but it expects 4 (though they're not used). Perhaps you either meant not to have the `ClassicalRegister` `c` in `hadder`, or you meant to write the above line as
```python
circ.append(hadder, [0, 1, 2, 3], [0, 1, 2, 3])
```
On our side, the `append` call I pulled out should have raised an error. I'm not certain why it didn't, but it definitely looks like a bug that it didn't. | 2023-01-18T12:43:42Z | <patch>
diff --git a/qiskit/circuit/instruction.py b/qiskit/circuit/instruction.py
--- a/qiskit/circuit/instruction.py
+++ b/qiskit/circuit/instruction.py
@@ -481,6 +481,11 @@ def broadcast_arguments(self, qargs, cargs):
f"The amount of qubit arguments {len(qargs)} does not match"
f" the instruction expectation ({self.num_qubits})."
)
+ if len(cargs) != self.num_clbits:
+ raise CircuitError(
+ f"The amount of clbit arguments {len(cargs)} does not match"
+ f" the instruction expectation ({self.num_clbits})."
+ )
# [[q[0], q[1]], [c[0], c[1]]] -> [q[0], c[0]], [q[1], c[1]]
flat_qargs = [qarg for sublist in qargs for qarg in sublist]
</patch> | [] | [] | |||
docker__compose-3056 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pyinstaller has issues with signals
There's a bunch of history in #1040 and #2055.
We've tried multiple implementations of signal handlers, but each has their own set of issues, but **ONLY** when run from the frozen binary created by pyinstaller.
It looks like there is a very old issue in pyinstaller around this: https://github.com/pyinstaller/pyinstaller/issues/208
These problems can manifest in three ways:
- a `thread.error` when a signal interrupts a thread lock
- the signal handlers being completely ignored and raising a `KeynoardInterupt` instead
- the signal handlers being registered but the try/except to handle the except is skipped (this could be caused by the signal firing multiple times for a single `ctrl-c`, but I can't really verify that's what is happening)
</issue>
<code>
[start of README.md]
1 Docker Compose
2 ==============
3 
4
5 Compose is a tool for defining and running multi-container Docker applications.
6 With Compose, you use a Compose file to configure your application's services.
7 Then, using a single command, you create and start all the services
8 from your configuration. To learn more about all the features of Compose
9 see [the list of features](https://github.com/docker/compose/blob/release/docs/overview.md#features).
10
11 Compose is great for development, testing, and staging environments, as well as
12 CI workflows. You can learn more about each case in
13 [Common Use Cases](https://github.com/docker/compose/blob/release/docs/overview.md#common-use-cases).
14
15 Using Compose is basically a three-step process.
16
17 1. Define your app's environment with a `Dockerfile` so it can be
18 reproduced anywhere.
19 2. Define the services that make up your app in `docker-compose.yml` so
20 they can be run together in an isolated environment:
21 3. Lastly, run `docker-compose up` and Compose will start and run your entire app.
22
23 A `docker-compose.yml` looks like this:
24
25 web:
26 build: .
27 ports:
28 - "5000:5000"
29 volumes:
30 - .:/code
31 links:
32 - redis
33 redis:
34 image: redis
35
36 For more information about the Compose file, see the
37 [Compose file reference](https://github.com/docker/compose/blob/release/docs/compose-file.md)
38
39 Compose has commands for managing the whole lifecycle of your application:
40
41 * Start, stop and rebuild services
42 * View the status of running services
43 * Stream the log output of running services
44 * Run a one-off command on a service
45
46 Installation and documentation
47 ------------------------------
48
49 - Full documentation is available on [Docker's website](https://docs.docker.com/compose/).
50 - If you have any questions, you can talk in real-time with other developers in the #docker-compose IRC channel on Freenode. [Click here to join using IRCCloud.](https://www.irccloud.com/invite?hostname=irc.freenode.net&channel=%23docker-compose)
51 - Code repository for Compose is on [Github](https://github.com/docker/compose)
52 - If you find any problems please fill out an [issue](https://github.com/docker/compose/issues/new)
53
54 Contributing
55 ------------
56
57 [](http://jenkins.dockerproject.org/job/Compose%20Master/)
58
59 Want to help build Compose? Check out our [contributing documentation](https://github.com/docker/compose/blob/master/CONTRIBUTING.md).
60
61 Releasing
62 ---------
63
64 Releases are built by maintainers, following an outline of the [release process](https://github.com/docker/compose/blob/master/project/RELEASE-PROCESS.md).
65
[end of README.md]
[start of compose/cli/docker_client.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import logging
5 import os
6
7 from docker import Client
8 from docker.errors import TLSParameterError
9 from docker.utils import kwargs_from_env
10
11 from ..const import HTTP_TIMEOUT
12 from .errors import UserError
13
14 log = logging.getLogger(__name__)
15
16
17 def docker_client(version=None):
18 """
19 Returns a docker-py client configured using environment variables
20 according to the same logic as the official Docker client.
21 """
22 if 'DOCKER_CLIENT_TIMEOUT' in os.environ:
23 log.warn("The DOCKER_CLIENT_TIMEOUT environment variable is deprecated. "
24 "Please use COMPOSE_HTTP_TIMEOUT instead.")
25
26 try:
27 kwargs = kwargs_from_env(assert_hostname=False)
28 except TLSParameterError:
29 raise UserError(
30 "TLS configuration is invalid - make sure your DOCKER_TLS_VERIFY "
31 "and DOCKER_CERT_PATH are set correctly.\n"
32 "You might need to run `eval \"$(docker-machine env default)\"`")
33
34 if version:
35 kwargs['version'] = version
36
37 kwargs['timeout'] = HTTP_TIMEOUT
38
39 return Client(**kwargs)
40
[end of compose/cli/docker_client.py]
[start of compose/cli/main.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import contextlib
6 import json
7 import logging
8 import re
9 import sys
10 from inspect import getdoc
11 from operator import attrgetter
12
13 from docker.errors import APIError
14 from requests.exceptions import ReadTimeout
15
16 from . import signals
17 from .. import __version__
18 from ..config import config
19 from ..config import ConfigurationError
20 from ..config import parse_environment
21 from ..config.serialize import serialize_config
22 from ..const import API_VERSION_TO_ENGINE_VERSION
23 from ..const import DEFAULT_TIMEOUT
24 from ..const import HTTP_TIMEOUT
25 from ..const import IS_WINDOWS_PLATFORM
26 from ..progress_stream import StreamOutputError
27 from ..project import NoSuchService
28 from ..service import BuildError
29 from ..service import ConvergenceStrategy
30 from ..service import ImageType
31 from ..service import NeedsBuildError
32 from .command import friendly_error_message
33 from .command import get_config_path_from_options
34 from .command import project_from_options
35 from .docopt_command import DocoptCommand
36 from .docopt_command import NoSuchCommand
37 from .errors import UserError
38 from .formatter import ConsoleWarningFormatter
39 from .formatter import Formatter
40 from .log_printer import LogPrinter
41 from .utils import get_version_info
42 from .utils import yesno
43
44
45 if not IS_WINDOWS_PLATFORM:
46 from dockerpty.pty import PseudoTerminal, RunOperation, ExecOperation
47
48 log = logging.getLogger(__name__)
49 console_handler = logging.StreamHandler(sys.stderr)
50
51
52 def main():
53 setup_logging()
54 try:
55 command = TopLevelCommand()
56 command.sys_dispatch()
57 except KeyboardInterrupt:
58 log.error("Aborting.")
59 sys.exit(1)
60 except (UserError, NoSuchService, ConfigurationError) as e:
61 log.error(e.msg)
62 sys.exit(1)
63 except NoSuchCommand as e:
64 commands = "\n".join(parse_doc_section("commands:", getdoc(e.supercommand)))
65 log.error("No such command: %s\n\n%s", e.command, commands)
66 sys.exit(1)
67 except APIError as e:
68 log_api_error(e)
69 sys.exit(1)
70 except BuildError as e:
71 log.error("Service '%s' failed to build: %s" % (e.service.name, e.reason))
72 sys.exit(1)
73 except StreamOutputError as e:
74 log.error(e)
75 sys.exit(1)
76 except NeedsBuildError as e:
77 log.error("Service '%s' needs to be built, but --no-build was passed." % e.service.name)
78 sys.exit(1)
79 except ReadTimeout as e:
80 log.error(
81 "An HTTP request took too long to complete. Retry with --verbose to "
82 "obtain debug information.\n"
83 "If you encounter this issue regularly because of slow network "
84 "conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher "
85 "value (current value: %s)." % HTTP_TIMEOUT
86 )
87 sys.exit(1)
88
89
90 def log_api_error(e):
91 if 'client is newer than server' in e.explanation:
92 # we need JSON formatted errors. In the meantime...
93 # TODO: fix this by refactoring project dispatch
94 # http://github.com/docker/compose/pull/2832#commitcomment-15923800
95 client_version = e.explanation.split('client API version: ')[1].split(',')[0]
96 log.error(
97 "The engine version is lesser than the minimum required by "
98 "compose. Your current project requires a Docker Engine of "
99 "version {version} or superior.".format(
100 version=API_VERSION_TO_ENGINE_VERSION[client_version]
101 ))
102 else:
103 log.error(e.explanation)
104
105
106 def setup_logging():
107 root_logger = logging.getLogger()
108 root_logger.addHandler(console_handler)
109 root_logger.setLevel(logging.DEBUG)
110
111 # Disable requests logging
112 logging.getLogger("requests").propagate = False
113
114
115 def setup_console_handler(handler, verbose):
116 if handler.stream.isatty():
117 format_class = ConsoleWarningFormatter
118 else:
119 format_class = logging.Formatter
120
121 if verbose:
122 handler.setFormatter(format_class('%(name)s.%(funcName)s: %(message)s'))
123 handler.setLevel(logging.DEBUG)
124 else:
125 handler.setFormatter(format_class())
126 handler.setLevel(logging.INFO)
127
128
129 # stolen from docopt master
130 def parse_doc_section(name, source):
131 pattern = re.compile('^([^\n]*' + name + '[^\n]*\n?(?:[ \t].*?(?:\n|$))*)',
132 re.IGNORECASE | re.MULTILINE)
133 return [s.strip() for s in pattern.findall(source)]
134
135
136 class TopLevelCommand(DocoptCommand):
137 """Define and run multi-container applications with Docker.
138
139 Usage:
140 docker-compose [-f=<arg>...] [options] [COMMAND] [ARGS...]
141 docker-compose -h|--help
142
143 Options:
144 -f, --file FILE Specify an alternate compose file (default: docker-compose.yml)
145 -p, --project-name NAME Specify an alternate project name (default: directory name)
146 --verbose Show more output
147 -v, --version Print version and exit
148
149 Commands:
150 build Build or rebuild services
151 config Validate and view the compose file
152 create Create services
153 down Stop and remove containers, networks, images, and volumes
154 events Receive real time events from containers
155 exec Execute a command in a running container
156 help Get help on a command
157 kill Kill containers
158 logs View output from containers
159 pause Pause services
160 port Print the public port for a port binding
161 ps List containers
162 pull Pulls service images
163 restart Restart services
164 rm Remove stopped containers
165 run Run a one-off command
166 scale Set number of containers for a service
167 start Start services
168 stop Stop services
169 unpause Unpause services
170 up Create and start containers
171 version Show the Docker-Compose version information
172 """
173 base_dir = '.'
174
175 def docopt_options(self):
176 options = super(TopLevelCommand, self).docopt_options()
177 options['version'] = get_version_info('compose')
178 return options
179
180 def perform_command(self, options, handler, command_options):
181 setup_console_handler(console_handler, options.get('--verbose'))
182
183 if options['COMMAND'] in ('help', 'version'):
184 # Skip looking up the compose file.
185 handler(None, command_options)
186 return
187
188 if options['COMMAND'] == 'config':
189 handler(options, command_options)
190 return
191
192 project = project_from_options(self.base_dir, options)
193 with friendly_error_message():
194 handler(project, command_options)
195
196 def build(self, project, options):
197 """
198 Build or rebuild services.
199
200 Services are built once and then tagged as `project_service`,
201 e.g. `composetest_db`. If you change a service's `Dockerfile` or the
202 contents of its build directory, you can run `docker-compose build` to rebuild it.
203
204 Usage: build [options] [SERVICE...]
205
206 Options:
207 --force-rm Always remove intermediate containers.
208 --no-cache Do not use cache when building the image.
209 --pull Always attempt to pull a newer version of the image.
210 """
211 project.build(
212 service_names=options['SERVICE'],
213 no_cache=bool(options.get('--no-cache', False)),
214 pull=bool(options.get('--pull', False)),
215 force_rm=bool(options.get('--force-rm', False)))
216
217 def config(self, config_options, options):
218 """
219 Validate and view the compose file.
220
221 Usage: config [options]
222
223 Options:
224 -q, --quiet Only validate the configuration, don't print
225 anything.
226 --services Print the service names, one per line.
227
228 """
229 config_path = get_config_path_from_options(config_options)
230 compose_config = config.load(config.find(self.base_dir, config_path))
231
232 if options['--quiet']:
233 return
234
235 if options['--services']:
236 print('\n'.join(service['name'] for service in compose_config.services))
237 return
238
239 print(serialize_config(compose_config))
240
241 def create(self, project, options):
242 """
243 Creates containers for a service.
244
245 Usage: create [options] [SERVICE...]
246
247 Options:
248 --force-recreate Recreate containers even if their configuration and
249 image haven't changed. Incompatible with --no-recreate.
250 --no-recreate If containers already exist, don't recreate them.
251 Incompatible with --force-recreate.
252 --no-build Don't build an image, even if it's missing
253 """
254 service_names = options['SERVICE']
255
256 project.create(
257 service_names=service_names,
258 strategy=convergence_strategy_from_opts(options),
259 do_build=not options['--no-build']
260 )
261
262 def down(self, project, options):
263 """
264 Stop containers and remove containers, networks, volumes, and images
265 created by `up`. Only containers and networks are removed by default.
266
267 Usage: down [options]
268
269 Options:
270 --rmi type Remove images, type may be one of: 'all' to remove
271 all images, or 'local' to remove only images that
272 don't have an custom name set by the `image` field
273 -v, --volumes Remove data volumes
274 """
275 image_type = image_type_from_opt('--rmi', options['--rmi'])
276 project.down(image_type, options['--volumes'])
277
278 def events(self, project, options):
279 """
280 Receive real time events from containers.
281
282 Usage: events [options] [SERVICE...]
283
284 Options:
285 --json Output events as a stream of json objects
286 """
287 def format_event(event):
288 attributes = ["%s=%s" % item for item in event['attributes'].items()]
289 return ("{time} {type} {action} {id} ({attrs})").format(
290 attrs=", ".join(sorted(attributes)),
291 **event)
292
293 def json_format_event(event):
294 event['time'] = event['time'].isoformat()
295 return json.dumps(event)
296
297 for event in project.events():
298 formatter = json_format_event if options['--json'] else format_event
299 print(formatter(event))
300 sys.stdout.flush()
301
302 def exec_command(self, project, options):
303 """
304 Execute a command in a running container
305
306 Usage: exec [options] SERVICE COMMAND [ARGS...]
307
308 Options:
309 -d Detached mode: Run command in the background.
310 --privileged Give extended privileges to the process.
311 --user USER Run the command as this user.
312 -T Disable pseudo-tty allocation. By default `docker-compose exec`
313 allocates a TTY.
314 --index=index index of the container if there are multiple
315 instances of a service [default: 1]
316 """
317 index = int(options.get('--index'))
318 service = project.get_service(options['SERVICE'])
319 try:
320 container = service.get_container(number=index)
321 except ValueError as e:
322 raise UserError(str(e))
323 command = [options['COMMAND']] + options['ARGS']
324 tty = not options["-T"]
325
326 create_exec_options = {
327 "privileged": options["--privileged"],
328 "user": options["--user"],
329 "tty": tty,
330 "stdin": tty,
331 }
332
333 exec_id = container.create_exec(command, **create_exec_options)
334
335 if options['-d']:
336 container.start_exec(exec_id, tty=tty)
337 return
338
339 signals.set_signal_handler_to_shutdown()
340 try:
341 operation = ExecOperation(
342 project.client,
343 exec_id,
344 interactive=tty,
345 )
346 pty = PseudoTerminal(project.client, operation)
347 pty.start()
348 except signals.ShutdownException:
349 log.info("received shutdown exception: closing")
350 exit_code = project.client.exec_inspect(exec_id).get("ExitCode")
351 sys.exit(exit_code)
352
353 def help(self, project, options):
354 """
355 Get help on a command.
356
357 Usage: help COMMAND
358 """
359 handler = self.get_handler(options['COMMAND'])
360 raise SystemExit(getdoc(handler))
361
362 def kill(self, project, options):
363 """
364 Force stop service containers.
365
366 Usage: kill [options] [SERVICE...]
367
368 Options:
369 -s SIGNAL SIGNAL to send to the container.
370 Default signal is SIGKILL.
371 """
372 signal = options.get('-s', 'SIGKILL')
373
374 project.kill(service_names=options['SERVICE'], signal=signal)
375
376 def logs(self, project, options):
377 """
378 View output from containers.
379
380 Usage: logs [options] [SERVICE...]
381
382 Options:
383 --no-color Produce monochrome output.
384 """
385 containers = project.containers(service_names=options['SERVICE'], stopped=True)
386
387 monochrome = options['--no-color']
388 print("Attaching to", list_containers(containers))
389 LogPrinter(containers, monochrome=monochrome).run()
390
391 def pause(self, project, options):
392 """
393 Pause services.
394
395 Usage: pause [SERVICE...]
396 """
397 containers = project.pause(service_names=options['SERVICE'])
398 exit_if(not containers, 'No containers to pause', 1)
399
400 def port(self, project, options):
401 """
402 Print the public port for a port binding.
403
404 Usage: port [options] SERVICE PRIVATE_PORT
405
406 Options:
407 --protocol=proto tcp or udp [default: tcp]
408 --index=index index of the container if there are multiple
409 instances of a service [default: 1]
410 """
411 index = int(options.get('--index'))
412 service = project.get_service(options['SERVICE'])
413 try:
414 container = service.get_container(number=index)
415 except ValueError as e:
416 raise UserError(str(e))
417 print(container.get_local_port(
418 options['PRIVATE_PORT'],
419 protocol=options.get('--protocol') or 'tcp') or '')
420
421 def ps(self, project, options):
422 """
423 List containers.
424
425 Usage: ps [options] [SERVICE...]
426
427 Options:
428 -q Only display IDs
429 """
430 containers = sorted(
431 project.containers(service_names=options['SERVICE'], stopped=True) +
432 project.containers(service_names=options['SERVICE'], one_off=True),
433 key=attrgetter('name'))
434
435 if options['-q']:
436 for container in containers:
437 print(container.id)
438 else:
439 headers = [
440 'Name',
441 'Command',
442 'State',
443 'Ports',
444 ]
445 rows = []
446 for container in containers:
447 command = container.human_readable_command
448 if len(command) > 30:
449 command = '%s ...' % command[:26]
450 rows.append([
451 container.name,
452 command,
453 container.human_readable_state,
454 container.human_readable_ports,
455 ])
456 print(Formatter().table(headers, rows))
457
458 def pull(self, project, options):
459 """
460 Pulls images for services.
461
462 Usage: pull [options] [SERVICE...]
463
464 Options:
465 --ignore-pull-failures Pull what it can and ignores images with pull failures.
466 """
467 project.pull(
468 service_names=options['SERVICE'],
469 ignore_pull_failures=options.get('--ignore-pull-failures')
470 )
471
472 def rm(self, project, options):
473 """
474 Remove stopped service containers.
475
476 By default, volumes attached to containers will not be removed. You can see all
477 volumes with `docker volume ls`.
478
479 Any data which is not in a volume will be lost.
480
481 Usage: rm [options] [SERVICE...]
482
483 Options:
484 -f, --force Don't ask to confirm removal
485 -v Remove volumes associated with containers
486 """
487 all_containers = project.containers(service_names=options['SERVICE'], stopped=True)
488 stopped_containers = [c for c in all_containers if not c.is_running]
489
490 if len(stopped_containers) > 0:
491 print("Going to remove", list_containers(stopped_containers))
492 if options.get('--force') \
493 or yesno("Are you sure? [yN] ", default=False):
494 project.remove_stopped(
495 service_names=options['SERVICE'],
496 v=options.get('-v', False)
497 )
498 else:
499 print("No stopped containers")
500
501 def run(self, project, options):
502 """
503 Run a one-off command on a service.
504
505 For example:
506
507 $ docker-compose run web python manage.py shell
508
509 By default, linked services will be started, unless they are already
510 running. If you do not want to start linked services, use
511 `docker-compose run --no-deps SERVICE COMMAND [ARGS...]`.
512
513 Usage: run [options] [-p PORT...] [-e KEY=VAL...] SERVICE [COMMAND] [ARGS...]
514
515 Options:
516 -d Detached mode: Run container in the background, print
517 new container name.
518 --name NAME Assign a name to the container
519 --entrypoint CMD Override the entrypoint of the image.
520 -e KEY=VAL Set an environment variable (can be used multiple times)
521 -u, --user="" Run as specified username or uid
522 --no-deps Don't start linked services.
523 --rm Remove container after run. Ignored in detached mode.
524 -p, --publish=[] Publish a container's port(s) to the host
525 --service-ports Run command with the service's ports enabled and mapped
526 to the host.
527 -T Disable pseudo-tty allocation. By default `docker-compose run`
528 allocates a TTY.
529 """
530 service = project.get_service(options['SERVICE'])
531 detach = options['-d']
532
533 if IS_WINDOWS_PLATFORM and not detach:
534 raise UserError(
535 "Interactive mode is not yet supported on Windows.\n"
536 "Please pass the -d flag when using `docker-compose run`."
537 )
538
539 if options['COMMAND']:
540 command = [options['COMMAND']] + options['ARGS']
541 else:
542 command = service.options.get('command')
543
544 container_options = {
545 'command': command,
546 'tty': not (detach or options['-T'] or not sys.stdin.isatty()),
547 'stdin_open': not detach,
548 'detach': detach,
549 }
550
551 if options['-e']:
552 container_options['environment'] = parse_environment(options['-e'])
553
554 if options['--entrypoint']:
555 container_options['entrypoint'] = options.get('--entrypoint')
556
557 if options['--rm']:
558 container_options['restart'] = None
559
560 if options['--user']:
561 container_options['user'] = options.get('--user')
562
563 if not options['--service-ports']:
564 container_options['ports'] = []
565
566 if options['--publish']:
567 container_options['ports'] = options.get('--publish')
568
569 if options['--publish'] and options['--service-ports']:
570 raise UserError(
571 'Service port mapping and manual port mapping '
572 'can not be used togather'
573 )
574
575 if options['--name']:
576 container_options['name'] = options['--name']
577
578 run_one_off_container(container_options, project, service, options)
579
580 def scale(self, project, options):
581 """
582 Set number of containers to run for a service.
583
584 Numbers are specified in the form `service=num` as arguments.
585 For example:
586
587 $ docker-compose scale web=2 worker=3
588
589 Usage: scale [options] [SERVICE=NUM...]
590
591 Options:
592 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
593 (default: 10)
594 """
595 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
596
597 for s in options['SERVICE=NUM']:
598 if '=' not in s:
599 raise UserError('Arguments to scale should be in the form service=num')
600 service_name, num = s.split('=', 1)
601 try:
602 num = int(num)
603 except ValueError:
604 raise UserError('Number of containers for service "%s" is not a '
605 'number' % service_name)
606 project.get_service(service_name).scale(num, timeout=timeout)
607
608 def start(self, project, options):
609 """
610 Start existing containers.
611
612 Usage: start [SERVICE...]
613 """
614 containers = project.start(service_names=options['SERVICE'])
615 exit_if(not containers, 'No containers to start', 1)
616
617 def stop(self, project, options):
618 """
619 Stop running containers without removing them.
620
621 They can be started again with `docker-compose start`.
622
623 Usage: stop [options] [SERVICE...]
624
625 Options:
626 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
627 (default: 10)
628 """
629 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
630 project.stop(service_names=options['SERVICE'], timeout=timeout)
631
632 def restart(self, project, options):
633 """
634 Restart running containers.
635
636 Usage: restart [options] [SERVICE...]
637
638 Options:
639 -t, --timeout TIMEOUT Specify a shutdown timeout in seconds.
640 (default: 10)
641 """
642 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
643 containers = project.restart(service_names=options['SERVICE'], timeout=timeout)
644 exit_if(not containers, 'No containers to restart', 1)
645
646 def unpause(self, project, options):
647 """
648 Unpause services.
649
650 Usage: unpause [SERVICE...]
651 """
652 containers = project.unpause(service_names=options['SERVICE'])
653 exit_if(not containers, 'No containers to unpause', 1)
654
655 def up(self, project, options):
656 """
657 Builds, (re)creates, starts, and attaches to containers for a service.
658
659 Unless they are already running, this command also starts any linked services.
660
661 The `docker-compose up` command aggregates the output of each container. When
662 the command exits, all containers are stopped. Running `docker-compose up -d`
663 starts the containers in the background and leaves them running.
664
665 If there are existing containers for a service, and the service's configuration
666 or image was changed after the container's creation, `docker-compose up` picks
667 up the changes by stopping and recreating the containers (preserving mounted
668 volumes). To prevent Compose from picking up changes, use the `--no-recreate`
669 flag.
670
671 If you want to force Compose to stop and recreate all containers, use the
672 `--force-recreate` flag.
673
674 Usage: up [options] [SERVICE...]
675
676 Options:
677 -d Detached mode: Run containers in the background,
678 print new container names.
679 Incompatible with --abort-on-container-exit.
680 --no-color Produce monochrome output.
681 --no-deps Don't start linked services.
682 --force-recreate Recreate containers even if their configuration
683 and image haven't changed.
684 Incompatible with --no-recreate.
685 --no-recreate If containers already exist, don't recreate them.
686 Incompatible with --force-recreate.
687 --no-build Don't build an image, even if it's missing
688 --abort-on-container-exit Stops all containers if any container was stopped.
689 Incompatible with -d.
690 -t, --timeout TIMEOUT Use this timeout in seconds for container shutdown
691 when attached or when containers are already
692 running. (default: 10)
693 """
694 monochrome = options['--no-color']
695 start_deps = not options['--no-deps']
696 cascade_stop = options['--abort-on-container-exit']
697 service_names = options['SERVICE']
698 timeout = int(options.get('--timeout') or DEFAULT_TIMEOUT)
699 detached = options.get('-d')
700
701 if detached and cascade_stop:
702 raise UserError("--abort-on-container-exit and -d cannot be combined.")
703
704 with up_shutdown_context(project, service_names, timeout, detached):
705 to_attach = project.up(
706 service_names=service_names,
707 start_deps=start_deps,
708 strategy=convergence_strategy_from_opts(options),
709 do_build=not options['--no-build'],
710 timeout=timeout,
711 detached=detached)
712
713 if detached:
714 return
715 log_printer = build_log_printer(to_attach, service_names, monochrome, cascade_stop)
716 print("Attaching to", list_containers(log_printer.containers))
717 log_printer.run()
718
719 if cascade_stop:
720 print("Aborting on container exit...")
721 project.stop(service_names=service_names, timeout=timeout)
722
723 def version(self, project, options):
724 """
725 Show version informations
726
727 Usage: version [--short]
728
729 Options:
730 --short Shows only Compose's version number.
731 """
732 if options['--short']:
733 print(__version__)
734 else:
735 print(get_version_info('full'))
736
737
738 def convergence_strategy_from_opts(options):
739 no_recreate = options['--no-recreate']
740 force_recreate = options['--force-recreate']
741 if force_recreate and no_recreate:
742 raise UserError("--force-recreate and --no-recreate cannot be combined.")
743
744 if force_recreate:
745 return ConvergenceStrategy.always
746
747 if no_recreate:
748 return ConvergenceStrategy.never
749
750 return ConvergenceStrategy.changed
751
752
753 def image_type_from_opt(flag, value):
754 if not value:
755 return ImageType.none
756 try:
757 return ImageType[value]
758 except KeyError:
759 raise UserError("%s flag must be one of: all, local" % flag)
760
761
762 def run_one_off_container(container_options, project, service, options):
763 if not options['--no-deps']:
764 deps = service.get_dependency_names()
765 if deps:
766 project.up(
767 service_names=deps,
768 start_deps=True,
769 strategy=ConvergenceStrategy.never)
770
771 project.initialize()
772
773 container = service.create_container(
774 quiet=True,
775 one_off=True,
776 **container_options)
777
778 if options['-d']:
779 service.start_container(container)
780 print(container.name)
781 return
782
783 def remove_container(force=False):
784 if options['--rm']:
785 project.client.remove_container(container.id, force=True)
786
787 signals.set_signal_handler_to_shutdown()
788 try:
789 try:
790 operation = RunOperation(
791 project.client,
792 container.id,
793 interactive=not options['-T'],
794 logs=False,
795 )
796 pty = PseudoTerminal(project.client, operation)
797 sockets = pty.sockets()
798 service.start_container(container)
799 pty.start(sockets)
800 exit_code = container.wait()
801 except signals.ShutdownException:
802 project.client.stop(container.id)
803 exit_code = 1
804 except signals.ShutdownException:
805 project.client.kill(container.id)
806 remove_container(force=True)
807 sys.exit(2)
808
809 remove_container()
810 sys.exit(exit_code)
811
812
813 def build_log_printer(containers, service_names, monochrome, cascade_stop):
814 if service_names:
815 containers = [
816 container
817 for container in containers if container.service in service_names
818 ]
819 return LogPrinter(containers, monochrome=monochrome, cascade_stop=cascade_stop)
820
821
822 @contextlib.contextmanager
823 def up_shutdown_context(project, service_names, timeout, detached):
824 if detached:
825 yield
826 return
827
828 signals.set_signal_handler_to_shutdown()
829 try:
830 try:
831 yield
832 except signals.ShutdownException:
833 print("Gracefully stopping... (press Ctrl+C again to force)")
834 project.stop(service_names=service_names, timeout=timeout)
835 except signals.ShutdownException:
836 project.kill(service_names=service_names)
837 sys.exit(2)
838
839
840 def list_containers(containers):
841 return ", ".join(c.name for c in containers)
842
843
844 def exit_if(condition, message, exit_code):
845 if condition:
846 log.error(message)
847 raise SystemExit(exit_code)
848
[end of compose/cli/main.py]
[start of compose/cli/multiplexer.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 from threading import Thread
5
6 from six.moves import _thread as thread
7
8 try:
9 from Queue import Queue, Empty
10 except ImportError:
11 from queue import Queue, Empty # Python 3.x
12
13
14 STOP = object()
15
16
17 class Multiplexer(object):
18 """
19 Create a single iterator from several iterators by running all of them in
20 parallel and yielding results as they come in.
21 """
22
23 def __init__(self, iterators, cascade_stop=False):
24 self.iterators = iterators
25 self.cascade_stop = cascade_stop
26 self._num_running = len(iterators)
27 self.queue = Queue()
28
29 def loop(self):
30 self._init_readers()
31
32 while self._num_running > 0:
33 try:
34 item, exception = self.queue.get(timeout=0.1)
35
36 if exception:
37 raise exception
38
39 if item is STOP:
40 if self.cascade_stop is True:
41 break
42 else:
43 self._num_running -= 1
44 else:
45 yield item
46 except Empty:
47 pass
48 # See https://github.com/docker/compose/issues/189
49 except thread.error:
50 raise KeyboardInterrupt()
51
52 def _init_readers(self):
53 for iterator in self.iterators:
54 t = Thread(target=_enqueue_output, args=(iterator, self.queue))
55 t.daemon = True
56 t.start()
57
58
59 def _enqueue_output(iterator, queue):
60 try:
61 for item in iterator:
62 queue.put((item, None))
63 queue.put((STOP, None))
64 except Exception as e:
65 queue.put((None, e))
66
[end of compose/cli/multiplexer.py]
[start of compose/cli/signals.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import signal
5
6
7 class ShutdownException(Exception):
8 pass
9
10
11 def shutdown(signal, frame):
12 raise ShutdownException()
13
14
15 def set_signal_handler(handler):
16 signal.signal(signal.SIGINT, handler)
17 signal.signal(signal.SIGTERM, handler)
18
19
20 def set_signal_handler_to_shutdown():
21 set_signal_handler(shutdown)
22
[end of compose/cli/signals.py]
[start of compose/config/validation.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import json
5 import logging
6 import os
7 import re
8 import sys
9
10 import six
11 from docker.utils.ports import split_port
12 from jsonschema import Draft4Validator
13 from jsonschema import FormatChecker
14 from jsonschema import RefResolver
15 from jsonschema import ValidationError
16
17 from ..const import COMPOSEFILE_V1 as V1
18 from .errors import ConfigurationError
19 from .errors import VERSION_EXPLANATION
20 from .sort_services import get_service_name_from_network_mode
21
22
23 log = logging.getLogger(__name__)
24
25
26 DOCKER_CONFIG_HINTS = {
27 'cpu_share': 'cpu_shares',
28 'add_host': 'extra_hosts',
29 'hosts': 'extra_hosts',
30 'extra_host': 'extra_hosts',
31 'device': 'devices',
32 'link': 'links',
33 'memory_swap': 'memswap_limit',
34 'port': 'ports',
35 'privilege': 'privileged',
36 'priviliged': 'privileged',
37 'privilige': 'privileged',
38 'volume': 'volumes',
39 'workdir': 'working_dir',
40 }
41
42
43 VALID_NAME_CHARS = '[a-zA-Z0-9\._\-]'
44 VALID_EXPOSE_FORMAT = r'^\d+(\-\d+)?(\/[a-zA-Z]+)?$'
45
46
47 @FormatChecker.cls_checks(format="ports", raises=ValidationError)
48 def format_ports(instance):
49 try:
50 split_port(instance)
51 except ValueError as e:
52 raise ValidationError(six.text_type(e))
53 return True
54
55
56 @FormatChecker.cls_checks(format="expose", raises=ValidationError)
57 def format_expose(instance):
58 if isinstance(instance, six.string_types):
59 if not re.match(VALID_EXPOSE_FORMAT, instance):
60 raise ValidationError(
61 "should be of the format 'PORT[/PROTOCOL]'")
62
63 return True
64
65
66 @FormatChecker.cls_checks(format="bool-value-in-mapping")
67 def format_boolean_in_environment(instance):
68 """Check if there is a boolean in the mapping sections and display a warning.
69 Always return True here so the validation won't raise an error.
70 """
71 if isinstance(instance, bool):
72 log.warn(
73 "There is a boolean value in the 'environment', 'labels', or "
74 "'extra_hosts' field of a service.\n"
75 "These sections only support string values.\n"
76 "Please add quotes to any boolean values to make them strings "
77 "(eg, 'True', 'false', 'yes', 'N', 'on', 'Off').\n"
78 "This warning will become an error in a future release. \r\n"
79 )
80 return True
81
82
83 def match_named_volumes(service_dict, project_volumes):
84 service_volumes = service_dict.get('volumes', [])
85 for volume_spec in service_volumes:
86 if volume_spec.is_named_volume and volume_spec.external not in project_volumes:
87 raise ConfigurationError(
88 'Named volume "{0}" is used in service "{1}" but no'
89 ' declaration was found in the volumes section.'.format(
90 volume_spec.repr(), service_dict.get('name')
91 )
92 )
93
94
95 def python_type_to_yaml_type(type_):
96 type_name = type(type_).__name__
97 return {
98 'dict': 'mapping',
99 'list': 'array',
100 'int': 'number',
101 'float': 'number',
102 'bool': 'boolean',
103 'unicode': 'string',
104 'str': 'string',
105 'bytes': 'string',
106 }.get(type_name, type_name)
107
108
109 def validate_config_section(filename, config, section):
110 """Validate the structure of a configuration section. This must be done
111 before interpolation so it's separate from schema validation.
112 """
113 if not isinstance(config, dict):
114 raise ConfigurationError(
115 "In file '{filename}', {section} must be a mapping, not "
116 "{type}.".format(
117 filename=filename,
118 section=section,
119 type=anglicize_json_type(python_type_to_yaml_type(config))))
120
121 for key, value in config.items():
122 if not isinstance(key, six.string_types):
123 raise ConfigurationError(
124 "In file '{filename}', the {section} name {name} must be a "
125 "quoted string, i.e. '{name}'.".format(
126 filename=filename,
127 section=section,
128 name=key))
129
130 if not isinstance(value, (dict, type(None))):
131 raise ConfigurationError(
132 "In file '{filename}', {section} '{name}' must be a mapping not "
133 "{type}.".format(
134 filename=filename,
135 section=section,
136 name=key,
137 type=anglicize_json_type(python_type_to_yaml_type(value))))
138
139
140 def validate_top_level_object(config_file):
141 if not isinstance(config_file.config, dict):
142 raise ConfigurationError(
143 "Top level object in '{}' needs to be an object not '{}'.".format(
144 config_file.filename,
145 type(config_file.config)))
146
147
148 def validate_ulimits(service_config):
149 ulimit_config = service_config.config.get('ulimits', {})
150 for limit_name, soft_hard_values in six.iteritems(ulimit_config):
151 if isinstance(soft_hard_values, dict):
152 if not soft_hard_values['soft'] <= soft_hard_values['hard']:
153 raise ConfigurationError(
154 "Service '{s.name}' has invalid ulimit '{ulimit}'. "
155 "'soft' value can not be greater than 'hard' value ".format(
156 s=service_config,
157 ulimit=ulimit_config))
158
159
160 def validate_extends_file_path(service_name, extends_options, filename):
161 """
162 The service to be extended must either be defined in the config key 'file',
163 or within 'filename'.
164 """
165 error_prefix = "Invalid 'extends' configuration for %s:" % service_name
166
167 if 'file' not in extends_options and filename is None:
168 raise ConfigurationError(
169 "%s you need to specify a 'file', e.g. 'file: something.yml'" % error_prefix
170 )
171
172
173 def validate_network_mode(service_config, service_names):
174 network_mode = service_config.config.get('network_mode')
175 if not network_mode:
176 return
177
178 if 'networks' in service_config.config:
179 raise ConfigurationError("'network_mode' and 'networks' cannot be combined")
180
181 dependency = get_service_name_from_network_mode(network_mode)
182 if not dependency:
183 return
184
185 if dependency not in service_names:
186 raise ConfigurationError(
187 "Service '{s.name}' uses the network stack of service '{dep}' which "
188 "is undefined.".format(s=service_config, dep=dependency))
189
190
191 def validate_depends_on(service_config, service_names):
192 for dependency in service_config.config.get('depends_on', []):
193 if dependency not in service_names:
194 raise ConfigurationError(
195 "Service '{s.name}' depends on service '{dep}' which is "
196 "undefined.".format(s=service_config, dep=dependency))
197
198
199 def get_unsupported_config_msg(path, error_key):
200 msg = "Unsupported config option for {}: '{}'".format(path_string(path), error_key)
201 if error_key in DOCKER_CONFIG_HINTS:
202 msg += " (did you mean '{}'?)".format(DOCKER_CONFIG_HINTS[error_key])
203 return msg
204
205
206 def anglicize_json_type(json_type):
207 if json_type.startswith(('a', 'e', 'i', 'o', 'u')):
208 return 'an ' + json_type
209 return 'a ' + json_type
210
211
212 def is_service_dict_schema(schema_id):
213 return schema_id in ('config_schema_v1.json', '#/properties/services')
214
215
216 def handle_error_for_schema_with_id(error, path):
217 schema_id = error.schema['id']
218
219 if is_service_dict_schema(schema_id) and error.validator == 'additionalProperties':
220 return "Invalid service name '{}' - only {} characters are allowed".format(
221 # The service_name is the key to the json object
222 list(error.instance)[0],
223 VALID_NAME_CHARS)
224
225 if error.validator == 'additionalProperties':
226 if schema_id == '#/definitions/service':
227 invalid_config_key = parse_key_from_error_msg(error)
228 return get_unsupported_config_msg(path, invalid_config_key)
229
230 if not error.path:
231 return '{}\n{}'.format(error.message, VERSION_EXPLANATION)
232
233
234 def handle_generic_error(error, path):
235 msg_format = None
236 error_msg = error.message
237
238 if error.validator == 'oneOf':
239 msg_format = "{path} {msg}"
240 config_key, error_msg = _parse_oneof_validator(error)
241 if config_key:
242 path.append(config_key)
243
244 elif error.validator == 'type':
245 msg_format = "{path} contains an invalid type, it should be {msg}"
246 error_msg = _parse_valid_types_from_validator(error.validator_value)
247
248 elif error.validator == 'required':
249 error_msg = ", ".join(error.validator_value)
250 msg_format = "{path} is invalid, {msg} is required."
251
252 elif error.validator == 'dependencies':
253 config_key = list(error.validator_value.keys())[0]
254 required_keys = ",".join(error.validator_value[config_key])
255
256 msg_format = "{path} is invalid: {msg}"
257 path.append(config_key)
258 error_msg = "when defining '{}' you must set '{}' as well".format(
259 config_key,
260 required_keys)
261
262 elif error.cause:
263 error_msg = six.text_type(error.cause)
264 msg_format = "{path} is invalid: {msg}"
265
266 elif error.path:
267 msg_format = "{path} value {msg}"
268
269 if msg_format:
270 return msg_format.format(path=path_string(path), msg=error_msg)
271
272 return error.message
273
274
275 def parse_key_from_error_msg(error):
276 return error.message.split("'")[1]
277
278
279 def path_string(path):
280 return ".".join(c for c in path if isinstance(c, six.string_types))
281
282
283 def _parse_valid_types_from_validator(validator):
284 """A validator value can be either an array of valid types or a string of
285 a valid type. Parse the valid types and prefix with the correct article.
286 """
287 if not isinstance(validator, list):
288 return anglicize_json_type(validator)
289
290 if len(validator) == 1:
291 return anglicize_json_type(validator[0])
292
293 return "{}, or {}".format(
294 ", ".join([anglicize_json_type(validator[0])] + validator[1:-1]),
295 anglicize_json_type(validator[-1]))
296
297
298 def _parse_oneof_validator(error):
299 """oneOf has multiple schemas, so we need to reason about which schema, sub
300 schema or constraint the validation is failing on.
301 Inspecting the context value of a ValidationError gives us information about
302 which sub schema failed and which kind of error it is.
303 """
304 types = []
305 for context in error.context:
306
307 if context.validator == 'oneOf':
308 _, error_msg = _parse_oneof_validator(context)
309 return path_string(context.path), error_msg
310
311 if context.validator == 'required':
312 return (None, context.message)
313
314 if context.validator == 'additionalProperties':
315 invalid_config_key = parse_key_from_error_msg(context)
316 return (None, "contains unsupported option: '{}'".format(invalid_config_key))
317
318 if context.path:
319 return (
320 path_string(context.path),
321 "contains {}, which is an invalid type, it should be {}".format(
322 json.dumps(context.instance),
323 _parse_valid_types_from_validator(context.validator_value)),
324 )
325
326 if context.validator == 'uniqueItems':
327 return (
328 None,
329 "contains non unique items, please remove duplicates from {}".format(
330 context.instance),
331 )
332
333 if context.validator == 'type':
334 types.append(context.validator_value)
335
336 valid_types = _parse_valid_types_from_validator(types)
337 return (None, "contains an invalid type, it should be {}".format(valid_types))
338
339
340 def process_service_constraint_errors(error, service_name, version):
341 if version == V1:
342 if 'image' in error.instance and 'build' in error.instance:
343 return (
344 "Service {} has both an image and build path specified. "
345 "A service can either be built to image or use an existing "
346 "image, not both.".format(service_name))
347
348 if 'image' in error.instance and 'dockerfile' in error.instance:
349 return (
350 "Service {} has both an image and alternate Dockerfile. "
351 "A service can either be built to image or use an existing "
352 "image, not both.".format(service_name))
353
354 if 'image' not in error.instance and 'build' not in error.instance:
355 return (
356 "Service {} has neither an image nor a build context specified. "
357 "At least one must be provided.".format(service_name))
358
359
360 def process_config_schema_errors(error):
361 path = list(error.path)
362
363 if 'id' in error.schema:
364 error_msg = handle_error_for_schema_with_id(error, path)
365 if error_msg:
366 return error_msg
367
368 return handle_generic_error(error, path)
369
370
371 def validate_against_config_schema(config_file):
372 schema = load_jsonschema(config_file.version)
373 format_checker = FormatChecker(["ports", "expose", "bool-value-in-mapping"])
374 validator = Draft4Validator(
375 schema,
376 resolver=RefResolver(get_resolver_path(), schema),
377 format_checker=format_checker)
378 handle_errors(
379 validator.iter_errors(config_file.config),
380 process_config_schema_errors,
381 config_file.filename)
382
383
384 def validate_service_constraints(config, service_name, version):
385 def handler(errors):
386 return process_service_constraint_errors(errors, service_name, version)
387
388 schema = load_jsonschema(version)
389 validator = Draft4Validator(schema['definitions']['constraints']['service'])
390 handle_errors(validator.iter_errors(config), handler, None)
391
392
393 def get_schema_path():
394 return os.path.dirname(os.path.abspath(__file__))
395
396
397 def load_jsonschema(version):
398 filename = os.path.join(
399 get_schema_path(),
400 "config_schema_v{0}.json".format(version))
401
402 with open(filename, "r") as fh:
403 return json.load(fh)
404
405
406 def get_resolver_path():
407 schema_path = get_schema_path()
408 if sys.platform == "win32":
409 scheme = "///"
410 # TODO: why is this necessary?
411 schema_path = schema_path.replace('\\', '/')
412 else:
413 scheme = "//"
414 return "file:{}{}/".format(scheme, schema_path)
415
416
417 def handle_errors(errors, format_error_func, filename):
418 """jsonschema returns an error tree full of information to explain what has
419 gone wrong. Process each error and pull out relevant information and re-write
420 helpful error messages that are relevant.
421 """
422 errors = list(sorted(errors, key=str))
423 if not errors:
424 return
425
426 error_msg = '\n'.join(format_error_func(error) for error in errors)
427 raise ConfigurationError(
428 "Validation failed{file_msg}, reason(s):\n{error_msg}".format(
429 file_msg=" in file '{}'".format(filename) if filename else "",
430 error_msg=error_msg))
431
[end of compose/config/validation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| docker/compose | 768460483089f2f712f32eb859c95d1ba30fdc0e | Pyinstaller has issues with signals
There's a bunch of history in #1040 and #2055.
We've tried multiple implementations of signal handlers, but each has their own set of issues, but **ONLY** when run from the frozen binary created by pyinstaller.
It looks like there is a very old issue in pyinstaller around this: https://github.com/pyinstaller/pyinstaller/issues/208
These problems can manifest in three ways:
- a `thread.error` when a signal interrupts a thread lock
- the signal handlers being completely ignored and raising a `KeynoardInterupt` instead
- the signal handlers being registered but the try/except to handle the except is skipped (this could be caused by the signal firing multiple times for a single `ctrl-c`, but I can't really verify that's what is happening)
| https://github.com/pyinstaller/pyinstaller/pull/1822 seems to fix it!
We could run my patched version to build the binaries if they don't want to accept the patch upstream. I'll prepare a PR so it can be tested on OSX.
It looks like the windows branch uses a completely different function, so there should be no impact on windows.
Having just upgraded to 1.6.1, I'm now hitting this most of the time. It's an irregular behaviour: sometimes CTRL-C stops the container, some times it aborts. Quite an annoying bug, leaving containers running in the background when I wasn't aware of it!
| 2016-03-01T21:46:06Z | <patch>
diff --git a/compose/cli/main.py b/compose/cli/main.py
--- a/compose/cli/main.py
+++ b/compose/cli/main.py
@@ -54,7 +54,7 @@ def main():
try:
command = TopLevelCommand()
command.sys_dispatch()
- except KeyboardInterrupt:
+ except (KeyboardInterrupt, signals.ShutdownException):
log.error("Aborting.")
sys.exit(1)
except (UserError, NoSuchService, ConfigurationError) as e:
diff --git a/compose/cli/multiplexer.py b/compose/cli/multiplexer.py
--- a/compose/cli/multiplexer.py
+++ b/compose/cli/multiplexer.py
@@ -10,6 +10,7 @@
except ImportError:
from queue import Queue, Empty # Python 3.x
+from compose.cli.signals import ShutdownException
STOP = object()
@@ -47,7 +48,7 @@ def loop(self):
pass
# See https://github.com/docker/compose/issues/189
except thread.error:
- raise KeyboardInterrupt()
+ raise ShutdownException()
def _init_readers(self):
for iterator in self.iterators:
diff --git a/compose/parallel.py b/compose/parallel.py
--- a/compose/parallel.py
+++ b/compose/parallel.py
@@ -6,9 +6,11 @@
from threading import Thread
from docker.errors import APIError
+from six.moves import _thread as thread
from six.moves.queue import Empty
from six.moves.queue import Queue
+from compose.cli.signals import ShutdownException
from compose.utils import get_output_stream
@@ -26,19 +28,7 @@ def parallel_execute(objects, func, index_func, msg):
objects = list(objects)
stream = get_output_stream(sys.stderr)
writer = ParallelStreamWriter(stream, msg)
-
- for obj in objects:
- writer.initialize(index_func(obj))
-
- q = Queue()
-
- # TODO: limit the number of threads #1828
- for obj in objects:
- t = Thread(
- target=perform_operation,
- args=(func, obj, q.put, index_func(obj)))
- t.daemon = True
- t.start()
+ q = setup_queue(writer, objects, func, index_func)
done = 0
errors = {}
@@ -48,6 +38,9 @@ def parallel_execute(objects, func, index_func, msg):
msg_index, result = q.get(timeout=1)
except Empty:
continue
+ # See https://github.com/docker/compose/issues/189
+ except thread.error:
+ raise ShutdownException()
if isinstance(result, APIError):
errors[msg_index] = "error", result.explanation
@@ -68,6 +61,23 @@ def parallel_execute(objects, func, index_func, msg):
raise error
+def setup_queue(writer, objects, func, index_func):
+ for obj in objects:
+ writer.initialize(index_func(obj))
+
+ q = Queue()
+
+ # TODO: limit the number of threads #1828
+ for obj in objects:
+ t = Thread(
+ target=perform_operation,
+ args=(func, obj, q.put, index_func(obj)))
+ t.daemon = True
+ t.start()
+
+ return q
+
+
class ParallelStreamWriter(object):
"""Write out messages for operations happening in parallel.
</patch> | [] | [] | |||
googleapis__google-cloud-python-10162 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BigQuery: raise a `TypeError` if a dictionary is passed to `insert_rows_json`
**Is your feature request related to a problem? Please describe.**
If I want to only insert a single row at a time into a table, it's easy to accidentally try something like:
```python
json_row = {"col1": "hello", "col2": "world"}
errors = client.insert_rows_json(
table,
json_row
)
```
This results in a `400 BadRequest` error from the API, because it expects a list of rows, not a single row.
**Describe the solution you'd like**
It's difficult to debug this situation from the API response, so it'd be better if we raised a client-side error for passing in the wrong type for `json_rows`.
**Describe alternatives you've considered**
Leave as-is and request a better server-side message. This may be difficult to do, as the error happens at a level above BigQuery, which translates JSON to Protobuf for internal use.
**Additional context**
This issue was encountered by a customer engineer, and it took me a bit of debugging to figure out the actual issue. I expect other customers will encounter this problem as well.
</issue>
<code>
[start of README.rst]
1 Google Cloud Python Client
2 ==========================
3
4 Python idiomatic clients for `Google Cloud Platform`_ services.
5
6 .. _Google Cloud Platform: https://cloud.google.com/
7
8 **Heads up**! These libraries are supported on App Engine standard's `Python 3 runtime`_ but are *not* supported on App Engine's `Python 2 runtime`_.
9
10 .. _Python 3 runtime: https://cloud.google.com/appengine/docs/standard/python3
11 .. _Python 2 runtime: https://cloud.google.com/appengine/docs/standard/python
12
13 General Availability
14 --------------------
15
16 **GA** (general availability) indicates that the client library for a
17 particular service is stable, and that the code surface will not change in
18 backwards-incompatible ways unless either absolutely necessary (e.g. because
19 of critical security issues) or with an extensive deprecation period.
20 Issues and requests against GA libraries are addressed with the highest
21 priority.
22
23 .. note::
24
25 Sub-components of GA libraries explicitly marked as beta in the
26 import path (e.g. ``google.cloud.language_v1beta2``) should be considered
27 to be beta.
28
29 The following client libraries have **GA** support:
30
31 - `Google BigQuery`_ (`BigQuery README`_, `BigQuery Documentation`_)
32 - `Google Cloud Bigtable`_ (`Bigtable README`_, `Bigtable Documentation`_)
33 - `Google Cloud Datastore`_ (`Datastore README`_, `Datastore Documentation`_)
34 - `Google Cloud KMS`_ (`KMS README`_, `KMS Documentation`_)
35 - `Google Cloud Natural Language`_ (`Natural Language README`_, `Natural Language Documentation`_)
36 - `Google Cloud Pub/Sub`_ (`Pub/Sub README`_, `Pub/Sub Documentation`_)
37 - `Google Cloud Scheduler`_ (`Scheduler README`_, `Scheduler Documentation`_)
38 - `Google Cloud Spanner`_ (`Spanner README`_, `Spanner Documentation`_)
39 - `Google Cloud Speech to Text`_ (`Speech to Text README`_, `Speech to Text Documentation`_)
40 - `Google Cloud Storage`_ (`Storage README`_, `Storage Documentation`_)
41 - `Google Cloud Tasks`_ (`Tasks README`_, `Tasks Documentation`_)
42 - `Google Cloud Translation`_ (`Translation README`_, `Translation Documentation`_)
43 - `Stackdriver Logging`_ (`Logging README`_, `Logging Documentation`_)
44
45 .. _Google BigQuery: https://pypi.org/project/google-cloud-bigquery/
46 .. _BigQuery README: https://github.com/googleapis/google-cloud-python/tree/master/bigquery
47 .. _BigQuery Documentation: https://googleapis.dev/python/bigquery/latest
48
49 .. _Google Cloud Bigtable: https://pypi.org/project/google-cloud-bigtable/
50 .. _Bigtable README: https://github.com/googleapis/google-cloud-python/tree/master/bigtable
51 .. _Bigtable Documentation: https://googleapis.dev/python/bigtable/latest
52
53 .. _Google Cloud Datastore: https://pypi.org/project/google-cloud-datastore/
54 .. _Datastore README: https://github.com/googleapis/google-cloud-python/tree/master/datastore
55 .. _Datastore Documentation: https://googleapis.dev/python/datastore/latest
56
57 .. _Google Cloud KMS: https://pypi.org/project/google-cloud-kms/
58 .. _KMS README: https://github.com/googleapis/google-cloud-python/tree/master/kms
59 .. _KMS Documentation: https://googleapis.dev/python/cloudkms/latest
60
61 .. _Google Cloud Natural Language: https://pypi.org/project/google-cloud-language/
62 .. _Natural Language README: https://github.com/googleapis/google-cloud-python/tree/master/language
63 .. _Natural Language Documentation: https://googleapis.dev/python/language/latest
64
65 .. _Google Cloud Pub/Sub: https://pypi.org/project/google-cloud-pubsub/
66 .. _Pub/Sub README: https://github.com/googleapis/google-cloud-python/tree/master/pubsub
67 .. _Pub/Sub Documentation: https://googleapis.dev/python/pubsub/latest
68
69 .. _Google Cloud Spanner: https://pypi.org/project/google-cloud-spanner
70 .. _Spanner README: https://github.com/googleapis/google-cloud-python/tree/master/spanner
71 .. _Spanner Documentation: https://googleapis.dev/python/spanner/latest
72
73 .. _Google Cloud Speech to Text: https://pypi.org/project/google-cloud-speech/
74 .. _Speech to Text README: https://github.com/googleapis/google-cloud-python/tree/master/speech
75 .. _Speech to Text Documentation: https://googleapis.dev/python/speech/latest
76
77 .. _Google Cloud Storage: https://pypi.org/project/google-cloud-storage/
78 .. _Storage README: https://github.com/googleapis/google-cloud-python/tree/master/storage
79 .. _Storage Documentation: https://googleapis.dev/python/storage/latest
80
81 .. _Google Cloud Tasks: https://pypi.org/project/google-cloud-tasks/
82 .. _Tasks README: https://github.com/googleapis/google-cloud-python/tree/master/tasks
83 .. _Tasks Documentation: https://googleapis.dev/python/cloudtasks/latest
84
85 .. _Google Cloud Translation: https://pypi.org/project/google-cloud-translate/
86 .. _Translation README: https://github.com/googleapis/google-cloud-python/tree/master/translate
87 .. _Translation Documentation: https://googleapis.dev/python/translation/latest
88
89 .. _Google Cloud Scheduler: https://pypi.org/project/google-cloud-scheduler/
90 .. _Scheduler README: https://github.com/googleapis/google-cloud-python/tree/master/scheduler
91 .. _Scheduler Documentation: https://googleapis.dev/python/cloudscheduler/latest
92
93 .. _Stackdriver Logging: https://pypi.org/project/google-cloud-logging/
94 .. _Logging README: https://github.com/googleapis/google-cloud-python/tree/master/logging
95 .. _Logging Documentation: https://googleapis.dev/python/logging/latest
96
97 Beta Support
98 ------------
99
100 **Beta** indicates that the client library for a particular service is
101 mostly stable and is being prepared for release. Issues and requests
102 against beta libraries are addressed with a higher priority.
103
104 The following client libraries have **beta** support:
105
106 - `Google Cloud Billing Budgets`_ (`Billing Budgets README`_, `Billing Budgets Documentation`_)
107 - `Google Cloud Data Catalog`_ (`Data Catalog README`_, `Data Catalog Documentation`_)
108 - `Google Cloud Firestore`_ (`Firestore README`_, `Firestore Documentation`_)
109 - `Google Cloud Video Intelligence`_ (`Video Intelligence README`_, `Video Intelligence Documentation`_)
110 - `Google Cloud Vision`_ (`Vision README`_, `Vision Documentation`_)
111
112 .. _Google Cloud Billing Budgets: https://pypi.org/project/google-cloud-billing-budgets/
113 .. _Billing Budgets README: https://github.com/googleapis/google-cloud-python/tree/master/billingbudgets
114 .. _Billing Budgets Documentation: https://googleapis.dev/python/billingbudgets/latest
115
116 .. _Google Cloud Data Catalog: https://pypi.org/project/google-cloud-datacatalog/
117 .. _Data Catalog README: https://github.com/googleapis/google-cloud-python/tree/master/datacatalog
118 .. _Data Catalog Documentation: https://googleapis.dev/python/datacatalog/latest
119
120 .. _Google Cloud Firestore: https://pypi.org/project/google-cloud-firestore/
121 .. _Firestore README: https://github.com/googleapis/google-cloud-python/tree/master/firestore
122 .. _Firestore Documentation: https://googleapis.dev/python/firestore/latest
123
124 .. _Google Cloud Video Intelligence: https://pypi.org/project/google-cloud-videointelligence
125 .. _Video Intelligence README: https://github.com/googleapis/google-cloud-python/tree/master/videointelligence
126 .. _Video Intelligence Documentation: https://googleapis.dev/python/videointelligence/latest
127
128 .. _Google Cloud Vision: https://pypi.org/project/google-cloud-vision/
129 .. _Vision README: https://github.com/googleapis/google-cloud-python/tree/master/vision
130 .. _Vision Documentation: https://googleapis.dev/python/vision/latest
131
132
133 Alpha Support
134 -------------
135
136 **Alpha** indicates that the client library for a particular service is
137 still a work-in-progress and is more likely to get backwards-incompatible
138 updates. See `versioning`_ for more details.
139
140 The following client libraries have **alpha** support:
141
142 - `Google Cloud Asset`_ (`Asset README`_, `Asset Documentation`_)
143 - `Google Cloud AutoML`_ (`AutoML README`_, `AutoML Documentation`_)
144 - `Google BigQuery Data Transfer`_ (`BigQuery Data Transfer README`_, `BigQuery Documentation`_)
145 - `Google Cloud Bigtable - HappyBase`_ (`HappyBase README`_, `HappyBase Documentation`_)
146 - `Google Cloud Build`_ (`Cloud Build README`_, `Cloud Build Documentation`_)
147 - `Google Cloud Container`_ (`Container README`_, `Container Documentation`_)
148 - `Google Cloud Container Analysis`_ (`Container Analysis README`_, `Container Analysis Documentation`_)
149 - `Google Cloud Dataproc`_ (`Dataproc README`_, `Dataproc Documentation`_)
150 - `Google Cloud DLP`_ (`DLP README`_, `DLP Documentation`_)
151 - `Google Cloud DNS`_ (`DNS README`_, `DNS Documentation`_)
152 - `Google Cloud IoT`_ (`IoT README`_, `IoT Documentation`_)
153 - `Google Cloud Memorystore for Redis`_ (`Redis README`_, `Redis Documentation`_)
154 - `Google Cloud Recommender`_ (`Recommender README`_, `Recommender Documentation`_)
155 - `Google Cloud Resource Manager`_ (`Resource Manager README`_, `Resource Manager Documentation`_)
156 - `Google Cloud Runtime Configuration`_ (`Runtime Config README`_, `Runtime Config Documentation`_)
157 - `Google Cloud Security Scanner`_ (`Security Scanner README`_ , `Security Scanner Documentation`_)
158 - `Google Cloud Trace`_ (`Trace README`_, `Trace Documentation`_)
159 - `Google Cloud Text-to-Speech`_ (`Text-to-Speech README`_, `Text-to-Speech Documentation`_)
160 - `Grafeas`_ (`Grafeas README`_, `Grafeas Documentation`_)
161 - `Stackdriver Error Reporting`_ (`Error Reporting README`_, `Error Reporting Documentation`_)
162 - `Stackdriver Monitoring`_ (`Monitoring README`_, `Monitoring Documentation`_)
163
164 .. _Google Cloud Asset: https://pypi.org/project/google-cloud-asset/
165 .. _Asset README: https://github.com/googleapis/google-cloud-python/blob/master/asset
166 .. _Asset Documentation: https://googleapis.dev/python/cloudasset/latest
167
168 .. _Google Cloud AutoML: https://pypi.org/project/google-cloud-automl/
169 .. _AutoML README: https://github.com/googleapis/google-cloud-python/blob/master/automl
170 .. _AutoML Documentation: https://googleapis.dev/python/automl/latest
171
172 .. _Google BigQuery Data Transfer: https://pypi.org/project/google-cloud-bigquery-datatransfer/
173 .. _BigQuery Data Transfer README: https://github.com/googleapis/google-cloud-python/tree/master/bigquery_datatransfer
174 .. _BigQuery Documentation: https://googleapis.dev/python/bigquery/latest
175
176 .. _Google Cloud Bigtable - HappyBase: https://pypi.org/project/google-cloud-happybase/
177 .. _HappyBase README: https://github.com/googleapis/google-cloud-python-happybase
178 .. _HappyBase Documentation: https://google-cloud-python-happybase.readthedocs.io/en/latest/
179
180 .. _Google Cloud Build: https://pypi.org/project/google-cloud-build/
181 .. _Cloud Build README: https://github.com/googleapis/google-cloud-python/cloudbuild
182 .. _Cloud Build Documentation: https://googleapis.dev/python/cloudbuild/latest
183
184 .. _Google Cloud Container: https://pypi.org/project/google-cloud-container/
185 .. _Container README: https://github.com/googleapis/google-cloud-python/tree/master/container
186 .. _Container Documentation: https://googleapis.dev/python/container/latest
187
188 .. _Google Cloud Container Analysis: https://pypi.org/project/google-cloud-containeranalysis/
189 .. _Container Analysis README: https://github.com/googleapis/google-cloud-python/tree/master/containeranalysis
190 .. _Container Analysis Documentation: https://googleapis.dev/python/containeranalysis/latest
191
192 .. _Google Cloud Dataproc: https://pypi.org/project/google-cloud-dataproc/
193 .. _Dataproc README: https://github.com/googleapis/google-cloud-python/tree/master/dataproc
194 .. _Dataproc Documentation: https://googleapis.dev/python/dataproc/latest
195
196 .. _Google Cloud DLP: https://pypi.org/project/google-cloud-dlp/
197 .. _DLP README: https://github.com/googleapis/google-cloud-python/tree/master/dlp
198 .. _DLP Documentation: https://googleapis.dev/python/dlp/latest
199
200 .. _Google Cloud DNS: https://pypi.org/project/google-cloud-dns/
201 .. _DNS README: https://github.com/googleapis/google-cloud-python/tree/master/dns
202 .. _DNS Documentation: https://googleapis.dev/python/dns/latest
203
204 .. _Google Cloud IoT: https://pypi.org/project/google-cloud-iot/
205 .. _IoT README: https://github.com/googleapis/google-cloud-python/tree/master/iot
206 .. _IoT Documentation: https://googleapis.dev/python/cloudiot/latest
207
208 .. _Google Cloud Memorystore for Redis: https://pypi.org/project/google-cloud-redis/
209 .. _Redis README: https://github.com/googleapis/google-cloud-python/tree/master/redis
210 .. _Redis Documentation: https://googleapis.dev/python/redis/latest
211
212 .. _Google Cloud Recommender: https://pypi.org/project/google-cloud-recommender/
213 .. _Recommender README: https://github.com/googleapis/google-cloud-python/tree/master/recommender
214 .. _Recommender Documentation: https://googleapis.dev/python/recommender/latest
215
216 .. _Google Cloud Resource Manager: https://pypi.org/project/google-cloud-resource-manager/
217 .. _Resource Manager README: https://github.com/googleapis/google-cloud-python/tree/master/resource_manager
218 .. _Resource Manager Documentation: https://googleapis.dev/python/cloudresourcemanager/latest
219
220 .. _Google Cloud Runtime Configuration: https://pypi.org/project/google-cloud-runtimeconfig/
221 .. _Runtime Config README: https://github.com/googleapis/google-cloud-python/tree/master/runtimeconfig
222 .. _Runtime Config Documentation: https://googleapis.dev/python/runtimeconfig/latest
223
224 .. _Google Cloud Security Scanner: https://pypi.org/project/google-cloud-websecurityscanner/
225 .. _Security Scanner README: https://github.com/googleapis/google-cloud-python/blob/master/websecurityscanner
226 .. _Security Scanner Documentation: https://googleapis.dev/python/websecurityscanner/latest
227
228 .. _Google Cloud Text-to-Speech: https://pypi.org/project/google-cloud-texttospeech/
229 .. _Text-to-Speech README: https://github.com/googleapis/google-cloud-python/tree/master/texttospeech
230 .. _Text-to-Speech Documentation: https://googleapis.dev/python/texttospeech/latest
231
232 .. _Google Cloud Trace: https://pypi.org/project/google-cloud-trace/
233 .. _Trace README: https://github.com/googleapis/google-cloud-python/tree/master/trace
234 .. _Trace Documentation: https://googleapis.dev/python/cloudtrace/latest
235
236 .. _Grafeas: https://pypi.org/project/grafeas/
237 .. _Grafeas README: https://github.com/googleapis/google-cloud-python/tree/master/grafeas
238 .. _Grafeas Documentation: https://googleapis.dev/python/grafeas/latest
239
240 .. _Stackdriver Error Reporting: https://pypi.org/project/google-cloud-error-reporting/
241 .. _Error Reporting README: https://github.com/googleapis/google-cloud-python/tree/master/error_reporting
242 .. _Error Reporting Documentation: https://googleapis.dev/python/clouderrorreporting/latest
243
244 .. _Stackdriver Monitoring: https://pypi.org/project/google-cloud-monitoring/
245 .. _Monitoring README: https://github.com/googleapis/google-cloud-python/tree/master/monitoring
246 .. _Monitoring Documentation: https://googleapis.dev/python/monitoring/latest
247
248 .. _versioning: https://github.com/googleapis/google-cloud-python/blob/master/CONTRIBUTING.rst#versioning
249
250 If you need support for other Google APIs, check out the
251 `Google APIs Python Client library`_.
252
253 .. _Google APIs Python Client library: https://github.com/google/google-api-python-client
254
255
256 Example Applications
257 --------------------
258
259 - `getting-started-python`_ - A sample and `tutorial`_ that demonstrates how to build a complete web application using Cloud Datastore, Cloud Storage, and Cloud Pub/Sub and deploy it to Google App Engine or Google Compute Engine.
260 - `google-cloud-python-expenses-demo`_ - A sample expenses demo using Cloud Datastore and Cloud Storage
261
262 .. _getting-started-python: https://github.com/GoogleCloudPlatform/getting-started-python
263 .. _tutorial: https://cloud.google.com/python
264 .. _google-cloud-python-expenses-demo: https://github.com/GoogleCloudPlatform/google-cloud-python-expenses-demo
265
266
267 Authentication
268 --------------
269
270 With ``google-cloud-python`` we try to make authentication as painless as possible.
271 Check out the `Authentication section`_ in our documentation to learn more.
272 You may also find the `authentication document`_ shared by all the
273 ``google-cloud-*`` libraries to be helpful.
274
275 .. _Authentication section: https://googleapis.dev/python/google-api-core/latest/auth.html
276 .. _authentication document: https://github.com/googleapis/google-cloud-common/tree/master/authentication
277
278 Contributing
279 ------------
280
281 Contributions to this library are always welcome and highly encouraged.
282
283 See the `CONTRIBUTING doc`_ for more information on how to get started.
284
285 .. _CONTRIBUTING doc: https://github.com/googleapis/google-cloud-python/blob/master/CONTRIBUTING.rst
286
287
288 Community
289 ---------
290
291 Google Cloud Platform Python developers hang out in `Slack`_ in the ``#python``
292 channel, click here to `get an invitation`_.
293
294 .. _Slack: https://googlecloud-community.slack.com
295 .. _get an invitation: https://gcp-slack.appspot.com/
296
297
298 License
299 -------
300
301 Apache 2.0 - See `the LICENSE`_ for more information.
302
303 .. _the LICENSE: https://github.com/googleapis/google-cloud-python/blob/master/LICENSE
304
[end of README.rst]
[start of bigquery_storage/google/cloud/bigquery_storage_v1beta1/gapic/big_query_storage_client.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2019 Google LLC
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # https://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """Accesses the google.cloud.bigquery.storage.v1beta1 BigQueryStorage API."""
18
19 import pkg_resources
20 import warnings
21
22 from google.oauth2 import service_account
23 import google.api_core.client_options
24 import google.api_core.gapic_v1.client_info
25 import google.api_core.gapic_v1.config
26 import google.api_core.gapic_v1.method
27 import google.api_core.path_template
28 import google.api_core.gapic_v1.routing_header
29 import google.api_core.grpc_helpers
30 import grpc
31
32 from google.cloud.bigquery_storage_v1beta1.gapic import big_query_storage_client_config
33 from google.cloud.bigquery_storage_v1beta1.gapic import enums
34 from google.cloud.bigquery_storage_v1beta1.gapic.transports import (
35 big_query_storage_grpc_transport,
36 )
37 from google.cloud.bigquery_storage_v1beta1.proto import read_options_pb2
38 from google.cloud.bigquery_storage_v1beta1.proto import storage_pb2
39 from google.cloud.bigquery_storage_v1beta1.proto import storage_pb2_grpc
40 from google.cloud.bigquery_storage_v1beta1.proto import table_reference_pb2
41 from google.protobuf import empty_pb2
42
43
44 _GAPIC_LIBRARY_VERSION = pkg_resources.get_distribution(
45 "google-cloud-bigquery-storage"
46 ).version
47
48
49 class BigQueryStorageClient(object):
50 """
51 BigQuery storage API.
52
53 The BigQuery storage API can be used to read data stored in BigQuery.
54 """
55
56 SERVICE_ADDRESS = "bigquerystorage.googleapis.com:443"
57 """The default address of the service."""
58
59 # The name of the interface for this client. This is the key used to
60 # find the method configuration in the client_config dictionary.
61 _INTERFACE_NAME = "google.cloud.bigquery.storage.v1beta1.BigQueryStorage"
62
63 @classmethod
64 def from_service_account_file(cls, filename, *args, **kwargs):
65 """Creates an instance of this client using the provided credentials
66 file.
67
68 Args:
69 filename (str): The path to the service account private key json
70 file.
71 args: Additional arguments to pass to the constructor.
72 kwargs: Additional arguments to pass to the constructor.
73
74 Returns:
75 BigQueryStorageClient: The constructed client.
76 """
77 credentials = service_account.Credentials.from_service_account_file(filename)
78 kwargs["credentials"] = credentials
79 return cls(*args, **kwargs)
80
81 from_service_account_json = from_service_account_file
82
83 def __init__(
84 self,
85 transport=None,
86 channel=None,
87 credentials=None,
88 client_config=None,
89 client_info=None,
90 client_options=None,
91 ):
92 """Constructor.
93
94 Args:
95 transport (Union[~.BigQueryStorageGrpcTransport,
96 Callable[[~.Credentials, type], ~.BigQueryStorageGrpcTransport]): A transport
97 instance, responsible for actually making the API calls.
98 The default transport uses the gRPC protocol.
99 This argument may also be a callable which returns a
100 transport instance. Callables will be sent the credentials
101 as the first argument and the default transport class as
102 the second argument.
103 channel (grpc.Channel): DEPRECATED. A ``Channel`` instance
104 through which to make calls. This argument is mutually exclusive
105 with ``credentials``; providing both will raise an exception.
106 credentials (google.auth.credentials.Credentials): The
107 authorization credentials to attach to requests. These
108 credentials identify this application to the service. If none
109 are specified, the client will attempt to ascertain the
110 credentials from the environment.
111 This argument is mutually exclusive with providing a
112 transport instance to ``transport``; doing so will raise
113 an exception.
114 client_config (dict): DEPRECATED. A dictionary of call options for
115 each method. If not specified, the default configuration is used.
116 client_info (google.api_core.gapic_v1.client_info.ClientInfo):
117 The client info used to send a user-agent string along with
118 API requests. If ``None``, then default info will be used.
119 Generally, you only need to set this if you're developing
120 your own client library.
121 client_options (Union[dict, google.api_core.client_options.ClientOptions]):
122 Client options used to set user options on the client. API Endpoint
123 should be set through client_options.
124 """
125 # Raise deprecation warnings for things we want to go away.
126 if client_config is not None:
127 warnings.warn(
128 "The `client_config` argument is deprecated.",
129 PendingDeprecationWarning,
130 stacklevel=2,
131 )
132 else:
133 client_config = big_query_storage_client_config.config
134
135 if channel:
136 warnings.warn(
137 "The `channel` argument is deprecated; use " "`transport` instead.",
138 PendingDeprecationWarning,
139 stacklevel=2,
140 )
141
142 api_endpoint = self.SERVICE_ADDRESS
143 if client_options:
144 if type(client_options) == dict:
145 client_options = google.api_core.client_options.from_dict(
146 client_options
147 )
148 if client_options.api_endpoint:
149 api_endpoint = client_options.api_endpoint
150
151 # Instantiate the transport.
152 # The transport is responsible for handling serialization and
153 # deserialization and actually sending data to the service.
154 if transport: # pragma: no cover
155 if callable(transport):
156 self.transport = transport(
157 credentials=credentials,
158 default_class=big_query_storage_grpc_transport.BigQueryStorageGrpcTransport,
159 address=api_endpoint,
160 )
161 else:
162 if credentials:
163 raise ValueError(
164 "Received both a transport instance and "
165 "credentials; these are mutually exclusive."
166 )
167 self.transport = transport
168 else:
169 self.transport = big_query_storage_grpc_transport.BigQueryStorageGrpcTransport(
170 address=api_endpoint, channel=channel, credentials=credentials
171 )
172
173 if client_info is None:
174 client_info = google.api_core.gapic_v1.client_info.ClientInfo(
175 gapic_version=_GAPIC_LIBRARY_VERSION
176 )
177 else:
178 client_info.gapic_version = _GAPIC_LIBRARY_VERSION
179 self._client_info = client_info
180
181 # Parse out the default settings for retry and timeout for each RPC
182 # from the client configuration.
183 # (Ordinarily, these are the defaults specified in the `*_config.py`
184 # file next to this one.)
185 self._method_configs = google.api_core.gapic_v1.config.parse_method_configs(
186 client_config["interfaces"][self._INTERFACE_NAME]
187 )
188
189 # Save a dictionary of cached API call functions.
190 # These are the actual callables which invoke the proper
191 # transport methods, wrapped with `wrap_method` to add retry,
192 # timeout, and the like.
193 self._inner_api_calls = {}
194
195 # Service calls
196 def create_read_session(
197 self,
198 table_reference,
199 parent,
200 table_modifiers=None,
201 requested_streams=None,
202 read_options=None,
203 format_=None,
204 sharding_strategy=None,
205 retry=google.api_core.gapic_v1.method.DEFAULT,
206 timeout=google.api_core.gapic_v1.method.DEFAULT,
207 metadata=None,
208 ):
209 """
210 Creates a new read session. A read session divides the contents of a
211 BigQuery table into one or more streams, which can then be used to read
212 data from the table. The read session also specifies properties of the
213 data to be read, such as a list of columns or a push-down filter describing
214 the rows to be returned.
215
216 A particular row can be read by at most one stream. When the caller has
217 reached the end of each stream in the session, then all the data in the
218 table has been read.
219
220 Read sessions automatically expire 24 hours after they are created and do
221 not require manual clean-up by the caller.
222
223 Example:
224 >>> from google.cloud import bigquery_storage_v1beta1
225 >>>
226 >>> client = bigquery_storage_v1beta1.BigQueryStorageClient()
227 >>>
228 >>> # TODO: Initialize `table_reference`:
229 >>> table_reference = {}
230 >>>
231 >>> # TODO: Initialize `parent`:
232 >>> parent = ''
233 >>>
234 >>> response = client.create_read_session(table_reference, parent)
235
236 Args:
237 table_reference (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.TableReference]): Required. Reference to the table to read.
238
239 If a dict is provided, it must be of the same form as the protobuf
240 message :class:`~google.cloud.bigquery_storage_v1beta1.types.TableReference`
241 parent (str): Required. String of the form ``projects/{project_id}`` indicating the
242 project this ReadSession is associated with. This is the project that
243 will be billed for usage.
244 table_modifiers (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.TableModifiers]): Any modifiers to the Table (e.g. snapshot timestamp).
245
246 If a dict is provided, it must be of the same form as the protobuf
247 message :class:`~google.cloud.bigquery_storage_v1beta1.types.TableModifiers`
248 requested_streams (int): Initial number of streams. If unset or 0, we will
249 provide a value of streams so as to produce reasonable throughput. Must be
250 non-negative. The number of streams may be lower than the requested number,
251 depending on the amount parallelism that is reasonable for the table and
252 the maximum amount of parallelism allowed by the system.
253
254 Streams must be read starting from offset 0.
255 read_options (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.TableReadOptions]): Read options for this session (e.g. column selection, filters).
256
257 If a dict is provided, it must be of the same form as the protobuf
258 message :class:`~google.cloud.bigquery_storage_v1beta1.types.TableReadOptions`
259 format_ (~google.cloud.bigquery_storage_v1beta1.types.DataFormat): Data output format. Currently default to Avro.
260 sharding_strategy (~google.cloud.bigquery_storage_v1beta1.types.ShardingStrategy): The strategy to use for distributing data among multiple streams. Currently
261 defaults to liquid sharding.
262 retry (Optional[google.api_core.retry.Retry]): A retry object used
263 to retry requests. If ``None`` is specified, requests will
264 be retried using a default configuration.
265 timeout (Optional[float]): The amount of time, in seconds, to wait
266 for the request to complete. Note that if ``retry`` is
267 specified, the timeout applies to each individual attempt.
268 metadata (Optional[Sequence[Tuple[str, str]]]): Additional metadata
269 that is provided to the method.
270
271 Returns:
272 A :class:`~google.cloud.bigquery_storage_v1beta1.types.ReadSession` instance.
273
274 Raises:
275 google.api_core.exceptions.GoogleAPICallError: If the request
276 failed for any reason.
277 google.api_core.exceptions.RetryError: If the request failed due
278 to a retryable error and retry attempts failed.
279 ValueError: If the parameters are invalid.
280 """
281 # Wrap the transport method to add retry and timeout logic.
282 if "create_read_session" not in self._inner_api_calls:
283 self._inner_api_calls[
284 "create_read_session"
285 ] = google.api_core.gapic_v1.method.wrap_method(
286 self.transport.create_read_session,
287 default_retry=self._method_configs["CreateReadSession"].retry,
288 default_timeout=self._method_configs["CreateReadSession"].timeout,
289 client_info=self._client_info,
290 )
291
292 request = storage_pb2.CreateReadSessionRequest(
293 table_reference=table_reference,
294 parent=parent,
295 table_modifiers=table_modifiers,
296 requested_streams=requested_streams,
297 read_options=read_options,
298 format=format_,
299 sharding_strategy=sharding_strategy,
300 )
301 if metadata is None:
302 metadata = []
303 metadata = list(metadata)
304 try:
305 routing_header = [
306 ("table_reference.project_id", table_reference.project_id),
307 ("table_reference.dataset_id", table_reference.dataset_id),
308 ]
309 except AttributeError:
310 pass
311 else:
312 routing_metadata = google.api_core.gapic_v1.routing_header.to_grpc_metadata(
313 routing_header
314 )
315 metadata.append(routing_metadata) # pragma: no cover
316
317 return self._inner_api_calls["create_read_session"](
318 request, retry=retry, timeout=timeout, metadata=metadata
319 )
320
321 def read_rows(
322 self,
323 read_position,
324 retry=google.api_core.gapic_v1.method.DEFAULT,
325 timeout=google.api_core.gapic_v1.method.DEFAULT,
326 metadata=None,
327 ):
328 """
329 Reads rows from the table in the format prescribed by the read session.
330 Each response contains one or more table rows, up to a maximum of 10 MiB
331 per response; read requests which attempt to read individual rows larger
332 than this will fail.
333
334 Each request also returns a set of stream statistics reflecting the
335 estimated total number of rows in the read stream. This number is computed
336 based on the total table size and the number of active streams in the read
337 session, and may change as other streams continue to read data.
338
339 Example:
340 >>> from google.cloud import bigquery_storage_v1beta1
341 >>>
342 >>> client = bigquery_storage_v1beta1.BigQueryStorageClient()
343 >>>
344 >>> # TODO: Initialize `read_position`:
345 >>> read_position = {}
346 >>>
347 >>> for element in client.read_rows(read_position):
348 ... # process element
349 ... pass
350
351 Args:
352 read_position (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.StreamPosition]): Required. Identifier of the position in the stream to start reading from.
353 The offset requested must be less than the last row read from ReadRows.
354 Requesting a larger offset is undefined.
355
356 If a dict is provided, it must be of the same form as the protobuf
357 message :class:`~google.cloud.bigquery_storage_v1beta1.types.StreamPosition`
358 retry (Optional[google.api_core.retry.Retry]): A retry object used
359 to retry requests. If ``None`` is specified, requests will
360 be retried using a default configuration.
361 timeout (Optional[float]): The amount of time, in seconds, to wait
362 for the request to complete. Note that if ``retry`` is
363 specified, the timeout applies to each individual attempt.
364 metadata (Optional[Sequence[Tuple[str, str]]]): Additional metadata
365 that is provided to the method.
366
367 Returns:
368 Iterable[~google.cloud.bigquery_storage_v1beta1.types.ReadRowsResponse].
369
370 Raises:
371 google.api_core.exceptions.GoogleAPICallError: If the request
372 failed for any reason.
373 google.api_core.exceptions.RetryError: If the request failed due
374 to a retryable error and retry attempts failed.
375 ValueError: If the parameters are invalid.
376 """
377 # Wrap the transport method to add retry and timeout logic.
378 if "read_rows" not in self._inner_api_calls:
379 self._inner_api_calls[
380 "read_rows"
381 ] = google.api_core.gapic_v1.method.wrap_method(
382 self.transport.read_rows,
383 default_retry=self._method_configs["ReadRows"].retry,
384 default_timeout=self._method_configs["ReadRows"].timeout,
385 client_info=self._client_info,
386 )
387
388 request = storage_pb2.ReadRowsRequest(read_position=read_position)
389 if metadata is None:
390 metadata = []
391 metadata = list(metadata)
392 try:
393 routing_header = [("read_position.stream.name", read_position.stream.name)]
394 except AttributeError:
395 pass
396 else:
397 routing_metadata = google.api_core.gapic_v1.routing_header.to_grpc_metadata(
398 routing_header
399 )
400 metadata.append(routing_metadata) # pragma: no cover
401
402 return self._inner_api_calls["read_rows"](
403 request, retry=retry, timeout=timeout, metadata=metadata
404 )
405
406 def batch_create_read_session_streams(
407 self,
408 session,
409 requested_streams,
410 retry=google.api_core.gapic_v1.method.DEFAULT,
411 timeout=google.api_core.gapic_v1.method.DEFAULT,
412 metadata=None,
413 ):
414 """
415 Creates additional streams for a ReadSession. This API can be used to
416 dynamically adjust the parallelism of a batch processing task upwards by
417 adding additional workers.
418
419 Example:
420 >>> from google.cloud import bigquery_storage_v1beta1
421 >>>
422 >>> client = bigquery_storage_v1beta1.BigQueryStorageClient()
423 >>>
424 >>> # TODO: Initialize `session`:
425 >>> session = {}
426 >>>
427 >>> # TODO: Initialize `requested_streams`:
428 >>> requested_streams = 0
429 >>>
430 >>> response = client.batch_create_read_session_streams(session, requested_streams)
431
432 Args:
433 session (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.ReadSession]): Required. Must be a non-expired session obtained from a call to
434 CreateReadSession. Only the name field needs to be set.
435
436 If a dict is provided, it must be of the same form as the protobuf
437 message :class:`~google.cloud.bigquery_storage_v1beta1.types.ReadSession`
438 requested_streams (int): Required. Number of new streams requested. Must be positive.
439 Number of added streams may be less than this, see CreateReadSessionRequest
440 for more information.
441 retry (Optional[google.api_core.retry.Retry]): A retry object used
442 to retry requests. If ``None`` is specified, requests will
443 be retried using a default configuration.
444 timeout (Optional[float]): The amount of time, in seconds, to wait
445 for the request to complete. Note that if ``retry`` is
446 specified, the timeout applies to each individual attempt.
447 metadata (Optional[Sequence[Tuple[str, str]]]): Additional metadata
448 that is provided to the method.
449
450 Returns:
451 A :class:`~google.cloud.bigquery_storage_v1beta1.types.BatchCreateReadSessionStreamsResponse` instance.
452
453 Raises:
454 google.api_core.exceptions.GoogleAPICallError: If the request
455 failed for any reason.
456 google.api_core.exceptions.RetryError: If the request failed due
457 to a retryable error and retry attempts failed.
458 ValueError: If the parameters are invalid.
459 """
460 # Wrap the transport method to add retry and timeout logic.
461 if "batch_create_read_session_streams" not in self._inner_api_calls:
462 self._inner_api_calls[
463 "batch_create_read_session_streams"
464 ] = google.api_core.gapic_v1.method.wrap_method(
465 self.transport.batch_create_read_session_streams,
466 default_retry=self._method_configs[
467 "BatchCreateReadSessionStreams"
468 ].retry,
469 default_timeout=self._method_configs[
470 "BatchCreateReadSessionStreams"
471 ].timeout,
472 client_info=self._client_info,
473 )
474
475 request = storage_pb2.BatchCreateReadSessionStreamsRequest(
476 session=session, requested_streams=requested_streams
477 )
478 if metadata is None:
479 metadata = []
480 metadata = list(metadata)
481 try:
482 routing_header = [("session.name", session.name)]
483 except AttributeError:
484 pass
485 else:
486 routing_metadata = google.api_core.gapic_v1.routing_header.to_grpc_metadata(
487 routing_header
488 )
489 metadata.append(routing_metadata) # pragma: no cover
490
491 return self._inner_api_calls["batch_create_read_session_streams"](
492 request, retry=retry, timeout=timeout, metadata=metadata
493 )
494
495 def finalize_stream(
496 self,
497 stream,
498 retry=google.api_core.gapic_v1.method.DEFAULT,
499 timeout=google.api_core.gapic_v1.method.DEFAULT,
500 metadata=None,
501 ):
502 """
503 Triggers the graceful termination of a single stream in a ReadSession. This
504 API can be used to dynamically adjust the parallelism of a batch processing
505 task downwards without losing data.
506
507 This API does not delete the stream -- it remains visible in the
508 ReadSession, and any data processed by the stream is not released to other
509 streams. However, no additional data will be assigned to the stream once
510 this call completes. Callers must continue reading data on the stream until
511 the end of the stream is reached so that data which has already been
512 assigned to the stream will be processed.
513
514 This method will return an error if there are no other live streams
515 in the Session, or if SplitReadStream() has been called on the given
516 Stream.
517
518 Example:
519 >>> from google.cloud import bigquery_storage_v1beta1
520 >>>
521 >>> client = bigquery_storage_v1beta1.BigQueryStorageClient()
522 >>>
523 >>> # TODO: Initialize `stream`:
524 >>> stream = {}
525 >>>
526 >>> client.finalize_stream(stream)
527
528 Args:
529 stream (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.Stream]): Stream to finalize.
530
531 If a dict is provided, it must be of the same form as the protobuf
532 message :class:`~google.cloud.bigquery_storage_v1beta1.types.Stream`
533 retry (Optional[google.api_core.retry.Retry]): A retry object used
534 to retry requests. If ``None`` is specified, requests will
535 be retried using a default configuration.
536 timeout (Optional[float]): The amount of time, in seconds, to wait
537 for the request to complete. Note that if ``retry`` is
538 specified, the timeout applies to each individual attempt.
539 metadata (Optional[Sequence[Tuple[str, str]]]): Additional metadata
540 that is provided to the method.
541
542 Raises:
543 google.api_core.exceptions.GoogleAPICallError: If the request
544 failed for any reason.
545 google.api_core.exceptions.RetryError: If the request failed due
546 to a retryable error and retry attempts failed.
547 ValueError: If the parameters are invalid.
548 """
549 # Wrap the transport method to add retry and timeout logic.
550 if "finalize_stream" not in self._inner_api_calls:
551 self._inner_api_calls[
552 "finalize_stream"
553 ] = google.api_core.gapic_v1.method.wrap_method(
554 self.transport.finalize_stream,
555 default_retry=self._method_configs["FinalizeStream"].retry,
556 default_timeout=self._method_configs["FinalizeStream"].timeout,
557 client_info=self._client_info,
558 )
559
560 request = storage_pb2.FinalizeStreamRequest(stream=stream)
561 if metadata is None:
562 metadata = []
563 metadata = list(metadata)
564 try:
565 routing_header = [("stream.name", stream.name)]
566 except AttributeError:
567 pass
568 else:
569 routing_metadata = google.api_core.gapic_v1.routing_header.to_grpc_metadata(
570 routing_header
571 )
572 metadata.append(routing_metadata) # pragma: no cover
573
574 self._inner_api_calls["finalize_stream"](
575 request, retry=retry, timeout=timeout, metadata=metadata
576 )
577
578 def split_read_stream(
579 self,
580 original_stream,
581 fraction=None,
582 retry=google.api_core.gapic_v1.method.DEFAULT,
583 timeout=google.api_core.gapic_v1.method.DEFAULT,
584 metadata=None,
585 ):
586 """
587 Splits a given read stream into two Streams. These streams are referred
588 to as the primary and the residual of the split. The original stream can
589 still be read from in the same manner as before. Both of the returned
590 streams can also be read from, and the total rows return by both child
591 streams will be the same as the rows read from the original stream.
592
593 Moreover, the two child streams will be allocated back to back in the
594 original Stream. Concretely, it is guaranteed that for streams Original,
595 Primary, and Residual, that Original[0-j] = Primary[0-j] and
596 Original[j-n] = Residual[0-m] once the streams have been read to
597 completion.
598
599 This method is guaranteed to be idempotent.
600
601 Example:
602 >>> from google.cloud import bigquery_storage_v1beta1
603 >>>
604 >>> client = bigquery_storage_v1beta1.BigQueryStorageClient()
605 >>>
606 >>> # TODO: Initialize `original_stream`:
607 >>> original_stream = {}
608 >>>
609 >>> response = client.split_read_stream(original_stream)
610
611 Args:
612 original_stream (Union[dict, ~google.cloud.bigquery_storage_v1beta1.types.Stream]): Stream to split.
613
614 If a dict is provided, it must be of the same form as the protobuf
615 message :class:`~google.cloud.bigquery_storage_v1beta1.types.Stream`
616 fraction (float): A value in the range (0.0, 1.0) that specifies the fractional point at
617 which the original stream should be split. The actual split point is
618 evaluated on pre-filtered rows, so if a filter is provided, then there is
619 no guarantee that the division of the rows between the new child streams
620 will be proportional to this fractional value. Additionally, because the
621 server-side unit for assigning data is collections of rows, this fraction
622 will always map to to a data storage boundary on the server side.
623 retry (Optional[google.api_core.retry.Retry]): A retry object used
624 to retry requests. If ``None`` is specified, requests will
625 be retried using a default configuration.
626 timeout (Optional[float]): The amount of time, in seconds, to wait
627 for the request to complete. Note that if ``retry`` is
628 specified, the timeout applies to each individual attempt.
629 metadata (Optional[Sequence[Tuple[str, str]]]): Additional metadata
630 that is provided to the method.
631
632 Returns:
633 A :class:`~google.cloud.bigquery_storage_v1beta1.types.SplitReadStreamResponse` instance.
634
635 Raises:
636 google.api_core.exceptions.GoogleAPICallError: If the request
637 failed for any reason.
638 google.api_core.exceptions.RetryError: If the request failed due
639 to a retryable error and retry attempts failed.
640 ValueError: If the parameters are invalid.
641 """
642 # Wrap the transport method to add retry and timeout logic.
643 if "split_read_stream" not in self._inner_api_calls:
644 self._inner_api_calls[
645 "split_read_stream"
646 ] = google.api_core.gapic_v1.method.wrap_method(
647 self.transport.split_read_stream,
648 default_retry=self._method_configs["SplitReadStream"].retry,
649 default_timeout=self._method_configs["SplitReadStream"].timeout,
650 client_info=self._client_info,
651 )
652
653 request = storage_pb2.SplitReadStreamRequest(
654 original_stream=original_stream, fraction=fraction
655 )
656 if metadata is None:
657 metadata = []
658 metadata = list(metadata)
659 try:
660 routing_header = [("original_stream.name", original_stream.name)]
661 except AttributeError:
662 pass
663 else:
664 routing_metadata = google.api_core.gapic_v1.routing_header.to_grpc_metadata(
665 routing_header
666 )
667 metadata.append(routing_metadata) # pragma: no cover
668
669 return self._inner_api_calls["split_read_stream"](
670 request, retry=retry, timeout=timeout, metadata=metadata
671 )
672
[end of bigquery_storage/google/cloud/bigquery_storage_v1beta1/gapic/big_query_storage_client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| googleapis/google-cloud-python | b492bdcc2d288022b5c81e90aea993432eec078a | BigQuery: raise a `TypeError` if a dictionary is passed to `insert_rows_json`
**Is your feature request related to a problem? Please describe.**
If I want to only insert a single row at a time into a table, it's easy to accidentally try something like:
```python
json_row = {"col1": "hello", "col2": "world"}
errors = client.insert_rows_json(
table,
json_row
)
```
This results in a `400 BadRequest` error from the API, because it expects a list of rows, not a single row.
**Describe the solution you'd like**
It's difficult to debug this situation from the API response, so it'd be better if we raised a client-side error for passing in the wrong type for `json_rows`.
**Describe alternatives you've considered**
Leave as-is and request a better server-side message. This may be difficult to do, as the error happens at a level above BigQuery, which translates JSON to Protobuf for internal use.
**Additional context**
This issue was encountered by a customer engineer, and it took me a bit of debugging to figure out the actual issue. I expect other customers will encounter this problem as well.
| 2020-01-16T13:04:56Z | <patch>
diff --git a/bigquery/google/cloud/bigquery/client.py b/bigquery/google/cloud/bigquery/client.py
--- a/bigquery/google/cloud/bigquery/client.py
+++ b/bigquery/google/cloud/bigquery/client.py
@@ -2506,6 +2506,8 @@ def insert_rows_json(
identifies the row, and the "errors" key contains a list of
the mappings describing one or more problems with the row.
"""
+ if not isinstance(json_rows, collections_abc.Sequence):
+ raise TypeError("json_rows argument should be a sequence of dicts")
# Convert table to just a reference because unlike insert_rows,
# insert_rows_json doesn't need the table schema. It's not doing any
# type conversions.
</patch> | [] | [] | ||||
numpy__numpy-14074 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NumPy 1.17 RC fails to compile with Intel C Compile 2016
<!-- Please describe the issue in detail here, and fill in the fields below -->
Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports("avx512f")` fails with compilation error:
```
icc: numpy/core/src/umath/cpuid.c
numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports'
compilation aborted for numpy/core/src/umath/cpuid.c (code 1)
```
Recent Intel C compiler (2019) proceeds just fine.
There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments.
</issue>
<code>
[start of README.md]
1 # <img alt="NumPy" src="https://cdn.rawgit.com/numpy/numpy/master/branding/icons/numpylogo.svg" height="60">
2
3 [](
4 https://travis-ci.org/numpy/numpy)
5 [](
6 https://ci.appveyor.com/project/charris/numpy)
7 [](
8 https://dev.azure.com/numpy/numpy/_build/latest?definitionId=5)
9 [](
10 https://codecov.io/gh/numpy/numpy)
11
12 NumPy is the fundamental package needed for scientific computing with Python.
13
14 - **Website:** https://www.numpy.org
15 - **Documentation:** http://docs.scipy.org/
16 - **Mailing list:** https://mail.python.org/mailman/listinfo/numpy-discussion
17 - **Source code:** https://github.com/numpy/numpy
18 - **Contributing:** https://www.numpy.org/devdocs/dev/index.html
19 - **Bug reports:** https://github.com/numpy/numpy/issues
20 - **Report a security vulnerability:** https://tidelift.com/docs/security
21
22 It provides:
23
24 - a powerful N-dimensional array object
25 - sophisticated (broadcasting) functions
26 - tools for integrating C/C++ and Fortran code
27 - useful linear algebra, Fourier transform, and random number capabilities
28
29 Testing:
30
31 - NumPy versions ≥ 1.15 require `pytest`
32 - NumPy versions < 1.15 require `nose`
33
34 Tests can then be run after installation with:
35
36 python -c 'import numpy; numpy.test()'
37
38
39 Call for Contributions
40 ----------------------
41
42 NumPy appreciates help from a wide range of different backgrounds.
43 Work such as high level documentation or website improvements are valuable
44 and we would like to grow our team with people filling these roles.
45 Small improvements or fixes are always appreciated and issues labeled as easy
46 may be a good starting point.
47 If you are considering larger contributions outside the traditional coding work,
48 please contact us through the mailing list.
49
50
51 [](https://numfocus.org)
52
[end of README.md]
[start of numpy/core/setup.py]
1 from __future__ import division, print_function
2
3 import os
4 import sys
5 import pickle
6 import copy
7 import warnings
8 import platform
9 import textwrap
10 from os.path import join
11
12 from numpy.distutils import log
13 from distutils.dep_util import newer
14 from distutils.sysconfig import get_config_var
15 from numpy._build_utils.apple_accelerate import (
16 uses_accelerate_framework, get_sgemv_fix
17 )
18 from numpy.compat import npy_load_module
19 from setup_common import *
20
21 # Set to True to enable relaxed strides checking. This (mostly) means
22 # that `strides[dim]` is ignored if `shape[dim] == 1` when setting flags.
23 NPY_RELAXED_STRIDES_CHECKING = (os.environ.get('NPY_RELAXED_STRIDES_CHECKING', "1") != "0")
24
25 # Put NPY_RELAXED_STRIDES_DEBUG=1 in the environment if you want numpy to use a
26 # bogus value for affected strides in order to help smoke out bad stride usage
27 # when relaxed stride checking is enabled.
28 NPY_RELAXED_STRIDES_DEBUG = (os.environ.get('NPY_RELAXED_STRIDES_DEBUG', "0") != "0")
29 NPY_RELAXED_STRIDES_DEBUG = NPY_RELAXED_STRIDES_DEBUG and NPY_RELAXED_STRIDES_CHECKING
30
31 # XXX: ugly, we use a class to avoid calling twice some expensive functions in
32 # config.h/numpyconfig.h. I don't see a better way because distutils force
33 # config.h generation inside an Extension class, and as such sharing
34 # configuration information between extensions is not easy.
35 # Using a pickled-based memoize does not work because config_cmd is an instance
36 # method, which cPickle does not like.
37 #
38 # Use pickle in all cases, as cPickle is gone in python3 and the difference
39 # in time is only in build. -- Charles Harris, 2013-03-30
40
41 class CallOnceOnly(object):
42 def __init__(self):
43 self._check_types = None
44 self._check_ieee_macros = None
45 self._check_complex = None
46
47 def check_types(self, *a, **kw):
48 if self._check_types is None:
49 out = check_types(*a, **kw)
50 self._check_types = pickle.dumps(out)
51 else:
52 out = copy.deepcopy(pickle.loads(self._check_types))
53 return out
54
55 def check_ieee_macros(self, *a, **kw):
56 if self._check_ieee_macros is None:
57 out = check_ieee_macros(*a, **kw)
58 self._check_ieee_macros = pickle.dumps(out)
59 else:
60 out = copy.deepcopy(pickle.loads(self._check_ieee_macros))
61 return out
62
63 def check_complex(self, *a, **kw):
64 if self._check_complex is None:
65 out = check_complex(*a, **kw)
66 self._check_complex = pickle.dumps(out)
67 else:
68 out = copy.deepcopy(pickle.loads(self._check_complex))
69 return out
70
71 def pythonlib_dir():
72 """return path where libpython* is."""
73 if sys.platform == 'win32':
74 return os.path.join(sys.prefix, "libs")
75 else:
76 return get_config_var('LIBDIR')
77
78 def is_npy_no_signal():
79 """Return True if the NPY_NO_SIGNAL symbol must be defined in configuration
80 header."""
81 return sys.platform == 'win32'
82
83 def is_npy_no_smp():
84 """Return True if the NPY_NO_SMP symbol must be defined in public
85 header (when SMP support cannot be reliably enabled)."""
86 # Perhaps a fancier check is in order here.
87 # so that threads are only enabled if there
88 # are actually multiple CPUS? -- but
89 # threaded code can be nice even on a single
90 # CPU so that long-calculating code doesn't
91 # block.
92 return 'NPY_NOSMP' in os.environ
93
94 def win32_checks(deflist):
95 from numpy.distutils.misc_util import get_build_architecture
96 a = get_build_architecture()
97
98 # Distutils hack on AMD64 on windows
99 print('BUILD_ARCHITECTURE: %r, os.name=%r, sys.platform=%r' %
100 (a, os.name, sys.platform))
101 if a == 'AMD64':
102 deflist.append('DISTUTILS_USE_SDK')
103
104 # On win32, force long double format string to be 'g', not
105 # 'Lg', since the MS runtime does not support long double whose
106 # size is > sizeof(double)
107 if a == "Intel" or a == "AMD64":
108 deflist.append('FORCE_NO_LONG_DOUBLE_FORMATTING')
109
110 def check_math_capabilities(config, moredefs, mathlibs):
111 def check_func(func_name):
112 return config.check_func(func_name, libraries=mathlibs,
113 decl=True, call=True)
114
115 def check_funcs_once(funcs_name):
116 decl = dict([(f, True) for f in funcs_name])
117 st = config.check_funcs_once(funcs_name, libraries=mathlibs,
118 decl=decl, call=decl)
119 if st:
120 moredefs.extend([(fname2def(f), 1) for f in funcs_name])
121 return st
122
123 def check_funcs(funcs_name):
124 # Use check_funcs_once first, and if it does not work, test func per
125 # func. Return success only if all the functions are available
126 if not check_funcs_once(funcs_name):
127 # Global check failed, check func per func
128 for f in funcs_name:
129 if check_func(f):
130 moredefs.append((fname2def(f), 1))
131 return 0
132 else:
133 return 1
134
135 #use_msvc = config.check_decl("_MSC_VER")
136
137 if not check_funcs_once(MANDATORY_FUNCS):
138 raise SystemError("One of the required function to build numpy is not"
139 " available (the list is %s)." % str(MANDATORY_FUNCS))
140
141 # Standard functions which may not be available and for which we have a
142 # replacement implementation. Note that some of these are C99 functions.
143
144 # XXX: hack to circumvent cpp pollution from python: python put its
145 # config.h in the public namespace, so we have a clash for the common
146 # functions we test. We remove every function tested by python's
147 # autoconf, hoping their own test are correct
148 for f in OPTIONAL_STDFUNCS_MAYBE:
149 if config.check_decl(fname2def(f),
150 headers=["Python.h", "math.h"]):
151 OPTIONAL_STDFUNCS.remove(f)
152
153 check_funcs(OPTIONAL_STDFUNCS)
154
155 for h in OPTIONAL_HEADERS:
156 if config.check_func("", decl=False, call=False, headers=[h]):
157 h = h.replace(".", "_").replace(os.path.sep, "_")
158 moredefs.append((fname2def(h), 1))
159
160 for tup in OPTIONAL_INTRINSICS:
161 headers = None
162 if len(tup) == 2:
163 f, args, m = tup[0], tup[1], fname2def(tup[0])
164 elif len(tup) == 3:
165 f, args, headers, m = tup[0], tup[1], [tup[2]], fname2def(tup[0])
166 else:
167 f, args, headers, m = tup[0], tup[1], [tup[2]], fname2def(tup[3])
168 if config.check_func(f, decl=False, call=True, call_args=args,
169 headers=headers):
170 moredefs.append((m, 1))
171
172 for dec, fn in OPTIONAL_FUNCTION_ATTRIBUTES:
173 if config.check_gcc_function_attribute(dec, fn):
174 moredefs.append((fname2def(fn), 1))
175
176 for dec, fn, code, header in OPTIONAL_FUNCTION_ATTRIBUTES_WITH_INTRINSICS:
177 if config.check_gcc_function_attribute_with_intrinsics(dec, fn, code,
178 header):
179 moredefs.append((fname2def(fn), 1))
180
181 for fn in OPTIONAL_VARIABLE_ATTRIBUTES:
182 if config.check_gcc_variable_attribute(fn):
183 m = fn.replace("(", "_").replace(")", "_")
184 moredefs.append((fname2def(m), 1))
185
186 # C99 functions: float and long double versions
187 check_funcs(C99_FUNCS_SINGLE)
188 check_funcs(C99_FUNCS_EXTENDED)
189
190 def check_complex(config, mathlibs):
191 priv = []
192 pub = []
193
194 try:
195 if os.uname()[0] == "Interix":
196 warnings.warn("Disabling broken complex support. See #1365", stacklevel=2)
197 return priv, pub
198 except Exception:
199 # os.uname not available on all platforms. blanket except ugly but safe
200 pass
201
202 # Check for complex support
203 st = config.check_header('complex.h')
204 if st:
205 priv.append(('HAVE_COMPLEX_H', 1))
206 pub.append(('NPY_USE_C99_COMPLEX', 1))
207
208 for t in C99_COMPLEX_TYPES:
209 st = config.check_type(t, headers=["complex.h"])
210 if st:
211 pub.append(('NPY_HAVE_%s' % type2def(t), 1))
212
213 def check_prec(prec):
214 flist = [f + prec for f in C99_COMPLEX_FUNCS]
215 decl = dict([(f, True) for f in flist])
216 if not config.check_funcs_once(flist, call=decl, decl=decl,
217 libraries=mathlibs):
218 for f in flist:
219 if config.check_func(f, call=True, decl=True,
220 libraries=mathlibs):
221 priv.append((fname2def(f), 1))
222 else:
223 priv.extend([(fname2def(f), 1) for f in flist])
224
225 check_prec('')
226 check_prec('f')
227 check_prec('l')
228
229 return priv, pub
230
231 def check_ieee_macros(config):
232 priv = []
233 pub = []
234
235 macros = []
236
237 def _add_decl(f):
238 priv.append(fname2def("decl_%s" % f))
239 pub.append('NPY_%s' % fname2def("decl_%s" % f))
240
241 # XXX: hack to circumvent cpp pollution from python: python put its
242 # config.h in the public namespace, so we have a clash for the common
243 # functions we test. We remove every function tested by python's
244 # autoconf, hoping their own test are correct
245 _macros = ["isnan", "isinf", "signbit", "isfinite"]
246 for f in _macros:
247 py_symbol = fname2def("decl_%s" % f)
248 already_declared = config.check_decl(py_symbol,
249 headers=["Python.h", "math.h"])
250 if already_declared:
251 if config.check_macro_true(py_symbol,
252 headers=["Python.h", "math.h"]):
253 pub.append('NPY_%s' % fname2def("decl_%s" % f))
254 else:
255 macros.append(f)
256 # Normally, isnan and isinf are macro (C99), but some platforms only have
257 # func, or both func and macro version. Check for macro only, and define
258 # replacement ones if not found.
259 # Note: including Python.h is necessary because it modifies some math.h
260 # definitions
261 for f in macros:
262 st = config.check_decl(f, headers=["Python.h", "math.h"])
263 if st:
264 _add_decl(f)
265
266 return priv, pub
267
268 def check_types(config_cmd, ext, build_dir):
269 private_defines = []
270 public_defines = []
271
272 # Expected size (in number of bytes) for each type. This is an
273 # optimization: those are only hints, and an exhaustive search for the size
274 # is done if the hints are wrong.
275 expected = {'short': [2], 'int': [4], 'long': [8, 4],
276 'float': [4], 'double': [8], 'long double': [16, 12, 8],
277 'Py_intptr_t': [8, 4], 'PY_LONG_LONG': [8], 'long long': [8],
278 'off_t': [8, 4]}
279
280 # Check we have the python header (-dev* packages on Linux)
281 result = config_cmd.check_header('Python.h')
282 if not result:
283 python = 'python'
284 if '__pypy__' in sys.builtin_module_names:
285 python = 'pypy'
286 raise SystemError(
287 "Cannot compile 'Python.h'. Perhaps you need to "
288 "install {0}-dev|{0}-devel.".format(python))
289 res = config_cmd.check_header("endian.h")
290 if res:
291 private_defines.append(('HAVE_ENDIAN_H', 1))
292 public_defines.append(('NPY_HAVE_ENDIAN_H', 1))
293 res = config_cmd.check_header("sys/endian.h")
294 if res:
295 private_defines.append(('HAVE_SYS_ENDIAN_H', 1))
296 public_defines.append(('NPY_HAVE_SYS_ENDIAN_H', 1))
297
298 # Check basic types sizes
299 for type in ('short', 'int', 'long'):
300 res = config_cmd.check_decl("SIZEOF_%s" % sym2def(type), headers=["Python.h"])
301 if res:
302 public_defines.append(('NPY_SIZEOF_%s' % sym2def(type), "SIZEOF_%s" % sym2def(type)))
303 else:
304 res = config_cmd.check_type_size(type, expected=expected[type])
305 if res >= 0:
306 public_defines.append(('NPY_SIZEOF_%s' % sym2def(type), '%d' % res))
307 else:
308 raise SystemError("Checking sizeof (%s) failed !" % type)
309
310 for type in ('float', 'double', 'long double'):
311 already_declared = config_cmd.check_decl("SIZEOF_%s" % sym2def(type),
312 headers=["Python.h"])
313 res = config_cmd.check_type_size(type, expected=expected[type])
314 if res >= 0:
315 public_defines.append(('NPY_SIZEOF_%s' % sym2def(type), '%d' % res))
316 if not already_declared and not type == 'long double':
317 private_defines.append(('SIZEOF_%s' % sym2def(type), '%d' % res))
318 else:
319 raise SystemError("Checking sizeof (%s) failed !" % type)
320
321 # Compute size of corresponding complex type: used to check that our
322 # definition is binary compatible with C99 complex type (check done at
323 # build time in npy_common.h)
324 complex_def = "struct {%s __x; %s __y;}" % (type, type)
325 res = config_cmd.check_type_size(complex_def,
326 expected=[2 * x for x in expected[type]])
327 if res >= 0:
328 public_defines.append(('NPY_SIZEOF_COMPLEX_%s' % sym2def(type), '%d' % res))
329 else:
330 raise SystemError("Checking sizeof (%s) failed !" % complex_def)
331
332 for type in ('Py_intptr_t', 'off_t'):
333 res = config_cmd.check_type_size(type, headers=["Python.h"],
334 library_dirs=[pythonlib_dir()],
335 expected=expected[type])
336
337 if res >= 0:
338 private_defines.append(('SIZEOF_%s' % sym2def(type), '%d' % res))
339 public_defines.append(('NPY_SIZEOF_%s' % sym2def(type), '%d' % res))
340 else:
341 raise SystemError("Checking sizeof (%s) failed !" % type)
342
343 # We check declaration AND type because that's how distutils does it.
344 if config_cmd.check_decl('PY_LONG_LONG', headers=['Python.h']):
345 res = config_cmd.check_type_size('PY_LONG_LONG', headers=['Python.h'],
346 library_dirs=[pythonlib_dir()],
347 expected=expected['PY_LONG_LONG'])
348 if res >= 0:
349 private_defines.append(('SIZEOF_%s' % sym2def('PY_LONG_LONG'), '%d' % res))
350 public_defines.append(('NPY_SIZEOF_%s' % sym2def('PY_LONG_LONG'), '%d' % res))
351 else:
352 raise SystemError("Checking sizeof (%s) failed !" % 'PY_LONG_LONG')
353
354 res = config_cmd.check_type_size('long long',
355 expected=expected['long long'])
356 if res >= 0:
357 #private_defines.append(('SIZEOF_%s' % sym2def('long long'), '%d' % res))
358 public_defines.append(('NPY_SIZEOF_%s' % sym2def('long long'), '%d' % res))
359 else:
360 raise SystemError("Checking sizeof (%s) failed !" % 'long long')
361
362 if not config_cmd.check_decl('CHAR_BIT', headers=['Python.h']):
363 raise RuntimeError(
364 "Config wo CHAR_BIT is not supported"
365 ", please contact the maintainers")
366
367 return private_defines, public_defines
368
369 def check_mathlib(config_cmd):
370 # Testing the C math library
371 mathlibs = []
372 mathlibs_choices = [[], ['m'], ['cpml']]
373 mathlib = os.environ.get('MATHLIB')
374 if mathlib:
375 mathlibs_choices.insert(0, mathlib.split(','))
376 for libs in mathlibs_choices:
377 if config_cmd.check_func("exp", libraries=libs, decl=True, call=True):
378 mathlibs = libs
379 break
380 else:
381 raise EnvironmentError("math library missing; rerun "
382 "setup.py after setting the "
383 "MATHLIB env variable")
384 return mathlibs
385
386 def visibility_define(config):
387 """Return the define value to use for NPY_VISIBILITY_HIDDEN (may be empty
388 string)."""
389 hide = '__attribute__((visibility("hidden")))'
390 if config.check_gcc_function_attribute(hide, 'hideme'):
391 return hide
392 else:
393 return ''
394
395 def configuration(parent_package='',top_path=None):
396 from numpy.distutils.misc_util import Configuration, dot_join
397 from numpy.distutils.system_info import get_info
398
399 config = Configuration('core', parent_package, top_path)
400 local_dir = config.local_path
401 codegen_dir = join(local_dir, 'code_generators')
402
403 if is_released(config):
404 warnings.simplefilter('error', MismatchCAPIWarning)
405
406 # Check whether we have a mismatch between the set C API VERSION and the
407 # actual C API VERSION
408 check_api_version(C_API_VERSION, codegen_dir)
409
410 generate_umath_py = join(codegen_dir, 'generate_umath.py')
411 n = dot_join(config.name, 'generate_umath')
412 generate_umath = npy_load_module('_'.join(n.split('.')),
413 generate_umath_py, ('.py', 'U', 1))
414
415 header_dir = 'include/numpy' # this is relative to config.path_in_package
416
417 cocache = CallOnceOnly()
418
419 def generate_config_h(ext, build_dir):
420 target = join(build_dir, header_dir, 'config.h')
421 d = os.path.dirname(target)
422 if not os.path.exists(d):
423 os.makedirs(d)
424
425 if newer(__file__, target):
426 config_cmd = config.get_config_cmd()
427 log.info('Generating %s', target)
428
429 # Check sizeof
430 moredefs, ignored = cocache.check_types(config_cmd, ext, build_dir)
431
432 # Check math library and C99 math funcs availability
433 mathlibs = check_mathlib(config_cmd)
434 moredefs.append(('MATHLIB', ','.join(mathlibs)))
435
436 check_math_capabilities(config_cmd, moredefs, mathlibs)
437 moredefs.extend(cocache.check_ieee_macros(config_cmd)[0])
438 moredefs.extend(cocache.check_complex(config_cmd, mathlibs)[0])
439
440 # Signal check
441 if is_npy_no_signal():
442 moredefs.append('__NPY_PRIVATE_NO_SIGNAL')
443
444 # Windows checks
445 if sys.platform == 'win32' or os.name == 'nt':
446 win32_checks(moredefs)
447
448 # C99 restrict keyword
449 moredefs.append(('NPY_RESTRICT', config_cmd.check_restrict()))
450
451 # Inline check
452 inline = config_cmd.check_inline()
453
454 # Use relaxed stride checking
455 if NPY_RELAXED_STRIDES_CHECKING:
456 moredefs.append(('NPY_RELAXED_STRIDES_CHECKING', 1))
457
458 # Use bogus stride debug aid when relaxed strides are enabled
459 if NPY_RELAXED_STRIDES_DEBUG:
460 moredefs.append(('NPY_RELAXED_STRIDES_DEBUG', 1))
461
462 # Get long double representation
463 rep = check_long_double_representation(config_cmd)
464 moredefs.append(('HAVE_LDOUBLE_%s' % rep, 1))
465
466 # Py3K check
467 if sys.version_info[0] == 3:
468 moredefs.append(('NPY_PY3K', 1))
469
470 # Generate the config.h file from moredefs
471 with open(target, 'w') as target_f:
472 for d in moredefs:
473 if isinstance(d, str):
474 target_f.write('#define %s\n' % (d))
475 else:
476 target_f.write('#define %s %s\n' % (d[0], d[1]))
477
478 # define inline to our keyword, or nothing
479 target_f.write('#ifndef __cplusplus\n')
480 if inline == 'inline':
481 target_f.write('/* #undef inline */\n')
482 else:
483 target_f.write('#define inline %s\n' % inline)
484 target_f.write('#endif\n')
485
486 # add the guard to make sure config.h is never included directly,
487 # but always through npy_config.h
488 target_f.write(textwrap.dedent("""
489 #ifndef _NPY_NPY_CONFIG_H_
490 #error config.h should never be included directly, include npy_config.h instead
491 #endif
492 """))
493
494 print('File:', target)
495 with open(target) as target_f:
496 print(target_f.read())
497 print('EOF')
498 else:
499 mathlibs = []
500 with open(target) as target_f:
501 for line in target_f:
502 s = '#define MATHLIB'
503 if line.startswith(s):
504 value = line[len(s):].strip()
505 if value:
506 mathlibs.extend(value.split(','))
507
508 # Ugly: this can be called within a library and not an extension,
509 # in which case there is no libraries attributes (and none is
510 # needed).
511 if hasattr(ext, 'libraries'):
512 ext.libraries.extend(mathlibs)
513
514 incl_dir = os.path.dirname(target)
515 if incl_dir not in config.numpy_include_dirs:
516 config.numpy_include_dirs.append(incl_dir)
517
518 return target
519
520 def generate_numpyconfig_h(ext, build_dir):
521 """Depends on config.h: generate_config_h has to be called before !"""
522 # put common include directory in build_dir on search path
523 # allows using code generation in headers headers
524 config.add_include_dirs(join(build_dir, "src", "common"))
525 config.add_include_dirs(join(build_dir, "src", "npymath"))
526
527 target = join(build_dir, header_dir, '_numpyconfig.h')
528 d = os.path.dirname(target)
529 if not os.path.exists(d):
530 os.makedirs(d)
531 if newer(__file__, target):
532 config_cmd = config.get_config_cmd()
533 log.info('Generating %s', target)
534
535 # Check sizeof
536 ignored, moredefs = cocache.check_types(config_cmd, ext, build_dir)
537
538 if is_npy_no_signal():
539 moredefs.append(('NPY_NO_SIGNAL', 1))
540
541 if is_npy_no_smp():
542 moredefs.append(('NPY_NO_SMP', 1))
543 else:
544 moredefs.append(('NPY_NO_SMP', 0))
545
546 mathlibs = check_mathlib(config_cmd)
547 moredefs.extend(cocache.check_ieee_macros(config_cmd)[1])
548 moredefs.extend(cocache.check_complex(config_cmd, mathlibs)[1])
549
550 if NPY_RELAXED_STRIDES_CHECKING:
551 moredefs.append(('NPY_RELAXED_STRIDES_CHECKING', 1))
552
553 if NPY_RELAXED_STRIDES_DEBUG:
554 moredefs.append(('NPY_RELAXED_STRIDES_DEBUG', 1))
555
556 # Check whether we can use inttypes (C99) formats
557 if config_cmd.check_decl('PRIdPTR', headers=['inttypes.h']):
558 moredefs.append(('NPY_USE_C99_FORMATS', 1))
559
560 # visibility check
561 hidden_visibility = visibility_define(config_cmd)
562 moredefs.append(('NPY_VISIBILITY_HIDDEN', hidden_visibility))
563
564 # Add the C API/ABI versions
565 moredefs.append(('NPY_ABI_VERSION', '0x%.8X' % C_ABI_VERSION))
566 moredefs.append(('NPY_API_VERSION', '0x%.8X' % C_API_VERSION))
567
568 # Add moredefs to header
569 with open(target, 'w') as target_f:
570 for d in moredefs:
571 if isinstance(d, str):
572 target_f.write('#define %s\n' % (d))
573 else:
574 target_f.write('#define %s %s\n' % (d[0], d[1]))
575
576 # Define __STDC_FORMAT_MACROS
577 target_f.write(textwrap.dedent("""
578 #ifndef __STDC_FORMAT_MACROS
579 #define __STDC_FORMAT_MACROS 1
580 #endif
581 """))
582
583 # Dump the numpyconfig.h header to stdout
584 print('File: %s' % target)
585 with open(target) as target_f:
586 print(target_f.read())
587 print('EOF')
588 config.add_data_files((header_dir, target))
589 return target
590
591 def generate_api_func(module_name):
592 def generate_api(ext, build_dir):
593 script = join(codegen_dir, module_name + '.py')
594 sys.path.insert(0, codegen_dir)
595 try:
596 m = __import__(module_name)
597 log.info('executing %s', script)
598 h_file, c_file, doc_file = m.generate_api(os.path.join(build_dir, header_dir))
599 finally:
600 del sys.path[0]
601 config.add_data_files((header_dir, h_file),
602 (header_dir, doc_file))
603 return (h_file,)
604 return generate_api
605
606 generate_numpy_api = generate_api_func('generate_numpy_api')
607 generate_ufunc_api = generate_api_func('generate_ufunc_api')
608
609 config.add_include_dirs(join(local_dir, "src", "common"))
610 config.add_include_dirs(join(local_dir, "src"))
611 config.add_include_dirs(join(local_dir))
612
613 config.add_data_dir('include/numpy')
614 config.add_include_dirs(join('src', 'npymath'))
615 config.add_include_dirs(join('src', 'multiarray'))
616 config.add_include_dirs(join('src', 'umath'))
617 config.add_include_dirs(join('src', 'npysort'))
618
619 config.add_define_macros([("NPY_INTERNAL_BUILD", "1")]) # this macro indicates that Numpy build is in process
620 config.add_define_macros([("HAVE_NPY_CONFIG_H", "1")])
621 if sys.platform[:3] == "aix":
622 config.add_define_macros([("_LARGE_FILES", None)])
623 else:
624 config.add_define_macros([("_FILE_OFFSET_BITS", "64")])
625 config.add_define_macros([('_LARGEFILE_SOURCE', '1')])
626 config.add_define_macros([('_LARGEFILE64_SOURCE', '1')])
627
628 config.numpy_include_dirs.extend(config.paths('include'))
629
630 deps = [join('src', 'npymath', '_signbit.c'),
631 join('include', 'numpy', '*object.h'),
632 join(codegen_dir, 'genapi.py'),
633 ]
634
635 #######################################################################
636 # dummy module #
637 #######################################################################
638
639 # npymath needs the config.h and numpyconfig.h files to be generated, but
640 # build_clib cannot handle generate_config_h and generate_numpyconfig_h
641 # (don't ask). Because clib are generated before extensions, we have to
642 # explicitly add an extension which has generate_config_h and
643 # generate_numpyconfig_h as sources *before* adding npymath.
644
645 config.add_extension('_dummy',
646 sources=[join('src', 'dummymodule.c'),
647 generate_config_h,
648 generate_numpyconfig_h,
649 generate_numpy_api]
650 )
651
652 #######################################################################
653 # npymath library #
654 #######################################################################
655
656 subst_dict = dict([("sep", os.path.sep), ("pkgname", "numpy.core")])
657
658 def get_mathlib_info(*args):
659 # Another ugly hack: the mathlib info is known once build_src is run,
660 # but we cannot use add_installed_pkg_config here either, so we only
661 # update the substitution dictionary during npymath build
662 config_cmd = config.get_config_cmd()
663
664 # Check that the toolchain works, to fail early if it doesn't
665 # (avoid late errors with MATHLIB which are confusing if the
666 # compiler does not work).
667 st = config_cmd.try_link('int main(void) { return 0;}')
668 if not st:
669 raise RuntimeError("Broken toolchain: cannot link a simple C program")
670 mlibs = check_mathlib(config_cmd)
671
672 posix_mlib = ' '.join(['-l%s' % l for l in mlibs])
673 msvc_mlib = ' '.join(['%s.lib' % l for l in mlibs])
674 subst_dict["posix_mathlib"] = posix_mlib
675 subst_dict["msvc_mathlib"] = msvc_mlib
676
677 npymath_sources = [join('src', 'npymath', 'npy_math_internal.h.src'),
678 join('src', 'npymath', 'npy_math.c'),
679 join('src', 'npymath', 'ieee754.c.src'),
680 join('src', 'npymath', 'npy_math_complex.c.src'),
681 join('src', 'npymath', 'halffloat.c')
682 ]
683
684 # Must be true for CRT compilers but not MinGW/cygwin. See gh-9977.
685 # Intel and Clang also don't seem happy with /GL
686 is_msvc = (platform.platform().startswith('Windows') and
687 platform.python_compiler().startswith('MS'))
688 config.add_installed_library('npymath',
689 sources=npymath_sources + [get_mathlib_info],
690 install_dir='lib',
691 build_info={
692 'include_dirs' : [], # empty list required for creating npy_math_internal.h
693 'extra_compiler_args' : (['/GL-'] if is_msvc else []),
694 })
695 config.add_npy_pkg_config("npymath.ini.in", "lib/npy-pkg-config",
696 subst_dict)
697 config.add_npy_pkg_config("mlib.ini.in", "lib/npy-pkg-config",
698 subst_dict)
699
700 #######################################################################
701 # npysort library #
702 #######################################################################
703
704 # This library is created for the build but it is not installed
705 npysort_sources = [join('src', 'common', 'npy_sort.h.src'),
706 join('src', 'npysort', 'quicksort.c.src'),
707 join('src', 'npysort', 'mergesort.c.src'),
708 join('src', 'npysort', 'timsort.c.src'),
709 join('src', 'npysort', 'heapsort.c.src'),
710 join('src', 'npysort', 'radixsort.c.src'),
711 join('src', 'common', 'npy_partition.h.src'),
712 join('src', 'npysort', 'selection.c.src'),
713 join('src', 'common', 'npy_binsearch.h.src'),
714 join('src', 'npysort', 'binsearch.c.src'),
715 ]
716 config.add_library('npysort',
717 sources=npysort_sources,
718 include_dirs=[])
719
720 #######################################################################
721 # multiarray_tests module #
722 #######################################################################
723
724 config.add_extension('_multiarray_tests',
725 sources=[join('src', 'multiarray', '_multiarray_tests.c.src'),
726 join('src', 'common', 'mem_overlap.c')],
727 depends=[join('src', 'common', 'mem_overlap.h'),
728 join('src', 'common', 'npy_extint128.h')],
729 libraries=['npymath'])
730
731 #######################################################################
732 # _multiarray_umath module - common part #
733 #######################################################################
734
735 common_deps = [
736 join('src', 'common', 'array_assign.h'),
737 join('src', 'common', 'binop_override.h'),
738 join('src', 'common', 'cblasfuncs.h'),
739 join('src', 'common', 'lowlevel_strided_loops.h'),
740 join('src', 'common', 'mem_overlap.h'),
741 join('src', 'common', 'npy_cblas.h'),
742 join('src', 'common', 'npy_config.h'),
743 join('src', 'common', 'npy_ctypes.h'),
744 join('src', 'common', 'npy_extint128.h'),
745 join('src', 'common', 'npy_import.h'),
746 join('src', 'common', 'npy_longdouble.h'),
747 join('src', 'common', 'templ_common.h.src'),
748 join('src', 'common', 'ucsnarrow.h'),
749 join('src', 'common', 'ufunc_override.h'),
750 join('src', 'common', 'umathmodule.h'),
751 join('src', 'common', 'numpyos.h'),
752 ]
753
754 common_src = [
755 join('src', 'common', 'array_assign.c'),
756 join('src', 'common', 'mem_overlap.c'),
757 join('src', 'common', 'npy_longdouble.c'),
758 join('src', 'common', 'templ_common.h.src'),
759 join('src', 'common', 'ucsnarrow.c'),
760 join('src', 'common', 'ufunc_override.c'),
761 join('src', 'common', 'numpyos.c'),
762 ]
763
764 blas_info = get_info('blas_opt', 0)
765 if blas_info and ('HAVE_CBLAS', None) in blas_info.get('define_macros', []):
766 extra_info = blas_info
767 # These files are also in MANIFEST.in so that they are always in
768 # the source distribution independently of HAVE_CBLAS.
769 common_src.extend([join('src', 'common', 'cblasfuncs.c'),
770 join('src', 'common', 'python_xerbla.c'),
771 ])
772 if uses_accelerate_framework(blas_info):
773 common_src.extend(get_sgemv_fix())
774 else:
775 extra_info = {}
776
777 #######################################################################
778 # _multiarray_umath module - multiarray part #
779 #######################################################################
780
781 multiarray_deps = [
782 join('src', 'multiarray', 'arrayobject.h'),
783 join('src', 'multiarray', 'arraytypes.h'),
784 join('src', 'multiarray', 'arrayfunction_override.h'),
785 join('src', 'multiarray', 'buffer.h'),
786 join('src', 'multiarray', 'calculation.h'),
787 join('src', 'multiarray', 'common.h'),
788 join('src', 'multiarray', 'convert_datatype.h'),
789 join('src', 'multiarray', 'convert.h'),
790 join('src', 'multiarray', 'conversion_utils.h'),
791 join('src', 'multiarray', 'ctors.h'),
792 join('src', 'multiarray', 'descriptor.h'),
793 join('src', 'multiarray', 'dragon4.h'),
794 join('src', 'multiarray', 'getset.h'),
795 join('src', 'multiarray', 'hashdescr.h'),
796 join('src', 'multiarray', 'iterators.h'),
797 join('src', 'multiarray', 'mapping.h'),
798 join('src', 'multiarray', 'methods.h'),
799 join('src', 'multiarray', 'multiarraymodule.h'),
800 join('src', 'multiarray', 'nditer_impl.h'),
801 join('src', 'multiarray', 'number.h'),
802 join('src', 'multiarray', 'refcount.h'),
803 join('src', 'multiarray', 'scalartypes.h'),
804 join('src', 'multiarray', 'sequence.h'),
805 join('src', 'multiarray', 'shape.h'),
806 join('src', 'multiarray', 'strfuncs.h'),
807 join('src', 'multiarray', 'typeinfo.h'),
808 join('src', 'multiarray', 'usertypes.h'),
809 join('src', 'multiarray', 'vdot.h'),
810 join('include', 'numpy', 'arrayobject.h'),
811 join('include', 'numpy', '_neighborhood_iterator_imp.h'),
812 join('include', 'numpy', 'npy_endian.h'),
813 join('include', 'numpy', 'arrayscalars.h'),
814 join('include', 'numpy', 'noprefix.h'),
815 join('include', 'numpy', 'npy_interrupt.h'),
816 join('include', 'numpy', 'npy_3kcompat.h'),
817 join('include', 'numpy', 'npy_math.h'),
818 join('include', 'numpy', 'halffloat.h'),
819 join('include', 'numpy', 'npy_common.h'),
820 join('include', 'numpy', 'npy_os.h'),
821 join('include', 'numpy', 'utils.h'),
822 join('include', 'numpy', 'ndarrayobject.h'),
823 join('include', 'numpy', 'npy_cpu.h'),
824 join('include', 'numpy', 'numpyconfig.h'),
825 join('include', 'numpy', 'ndarraytypes.h'),
826 join('include', 'numpy', 'npy_1_7_deprecated_api.h'),
827 # add library sources as distuils does not consider libraries
828 # dependencies
829 ] + npysort_sources + npymath_sources
830
831 multiarray_src = [
832 join('src', 'multiarray', 'alloc.c'),
833 join('src', 'multiarray', 'arrayobject.c'),
834 join('src', 'multiarray', 'arraytypes.c.src'),
835 join('src', 'multiarray', 'array_assign_scalar.c'),
836 join('src', 'multiarray', 'array_assign_array.c'),
837 join('src', 'multiarray', 'arrayfunction_override.c'),
838 join('src', 'multiarray', 'buffer.c'),
839 join('src', 'multiarray', 'calculation.c'),
840 join('src', 'multiarray', 'compiled_base.c'),
841 join('src', 'multiarray', 'common.c'),
842 join('src', 'multiarray', 'convert.c'),
843 join('src', 'multiarray', 'convert_datatype.c'),
844 join('src', 'multiarray', 'conversion_utils.c'),
845 join('src', 'multiarray', 'ctors.c'),
846 join('src', 'multiarray', 'datetime.c'),
847 join('src', 'multiarray', 'datetime_strings.c'),
848 join('src', 'multiarray', 'datetime_busday.c'),
849 join('src', 'multiarray', 'datetime_busdaycal.c'),
850 join('src', 'multiarray', 'descriptor.c'),
851 join('src', 'multiarray', 'dragon4.c'),
852 join('src', 'multiarray', 'dtype_transfer.c'),
853 join('src', 'multiarray', 'einsum.c.src'),
854 join('src', 'multiarray', 'flagsobject.c'),
855 join('src', 'multiarray', 'getset.c'),
856 join('src', 'multiarray', 'hashdescr.c'),
857 join('src', 'multiarray', 'item_selection.c'),
858 join('src', 'multiarray', 'iterators.c'),
859 join('src', 'multiarray', 'lowlevel_strided_loops.c.src'),
860 join('src', 'multiarray', 'mapping.c'),
861 join('src', 'multiarray', 'methods.c'),
862 join('src', 'multiarray', 'multiarraymodule.c'),
863 join('src', 'multiarray', 'nditer_templ.c.src'),
864 join('src', 'multiarray', 'nditer_api.c'),
865 join('src', 'multiarray', 'nditer_constr.c'),
866 join('src', 'multiarray', 'nditer_pywrap.c'),
867 join('src', 'multiarray', 'number.c'),
868 join('src', 'multiarray', 'refcount.c'),
869 join('src', 'multiarray', 'sequence.c'),
870 join('src', 'multiarray', 'shape.c'),
871 join('src', 'multiarray', 'scalarapi.c'),
872 join('src', 'multiarray', 'scalartypes.c.src'),
873 join('src', 'multiarray', 'strfuncs.c'),
874 join('src', 'multiarray', 'temp_elide.c'),
875 join('src', 'multiarray', 'typeinfo.c'),
876 join('src', 'multiarray', 'usertypes.c'),
877 join('src', 'multiarray', 'vdot.c'),
878 ]
879
880 #######################################################################
881 # _multiarray_umath module - umath part #
882 #######################################################################
883
884 def generate_umath_c(ext, build_dir):
885 target = join(build_dir, header_dir, '__umath_generated.c')
886 dir = os.path.dirname(target)
887 if not os.path.exists(dir):
888 os.makedirs(dir)
889 script = generate_umath_py
890 if newer(script, target):
891 with open(target, 'w') as f:
892 f.write(generate_umath.make_code(generate_umath.defdict,
893 generate_umath.__file__))
894 return []
895
896 umath_src = [
897 join('src', 'umath', 'umathmodule.c'),
898 join('src', 'umath', 'reduction.c'),
899 join('src', 'umath', 'funcs.inc.src'),
900 join('src', 'umath', 'simd.inc.src'),
901 join('src', 'umath', 'loops.h.src'),
902 join('src', 'umath', 'loops.c.src'),
903 join('src', 'umath', 'matmul.h.src'),
904 join('src', 'umath', 'matmul.c.src'),
905 join('src', 'umath', 'clip.h.src'),
906 join('src', 'umath', 'clip.c.src'),
907 join('src', 'umath', 'ufunc_object.c'),
908 join('src', 'umath', 'extobj.c'),
909 join('src', 'umath', 'cpuid.c'),
910 join('src', 'umath', 'scalarmath.c.src'),
911 join('src', 'umath', 'ufunc_type_resolution.c'),
912 join('src', 'umath', 'override.c'),
913 ]
914
915 umath_deps = [
916 generate_umath_py,
917 join('include', 'numpy', 'npy_math.h'),
918 join('include', 'numpy', 'halffloat.h'),
919 join('src', 'multiarray', 'common.h'),
920 join('src', 'multiarray', 'number.h'),
921 join('src', 'common', 'templ_common.h.src'),
922 join('src', 'umath', 'simd.inc.src'),
923 join('src', 'umath', 'override.h'),
924 join(codegen_dir, 'generate_ufunc_api.py'),
925 ]
926
927 config.add_extension('_multiarray_umath',
928 sources=multiarray_src + umath_src +
929 npymath_sources + common_src +
930 [generate_config_h,
931 generate_numpyconfig_h,
932 generate_numpy_api,
933 join(codegen_dir, 'generate_numpy_api.py'),
934 join('*.py'),
935 generate_umath_c,
936 generate_ufunc_api,
937 ],
938 depends=deps + multiarray_deps + umath_deps +
939 common_deps,
940 libraries=['npymath', 'npysort'],
941 extra_info=extra_info)
942
943 #######################################################################
944 # umath_tests module #
945 #######################################################################
946
947 config.add_extension('_umath_tests',
948 sources=[join('src', 'umath', '_umath_tests.c.src')])
949
950 #######################################################################
951 # custom rational dtype module #
952 #######################################################################
953
954 config.add_extension('_rational_tests',
955 sources=[join('src', 'umath', '_rational_tests.c.src')])
956
957 #######################################################################
958 # struct_ufunc_test module #
959 #######################################################################
960
961 config.add_extension('_struct_ufunc_tests',
962 sources=[join('src', 'umath', '_struct_ufunc_tests.c.src')])
963
964
965 #######################################################################
966 # operand_flag_tests module #
967 #######################################################################
968
969 config.add_extension('_operand_flag_tests',
970 sources=[join('src', 'umath', '_operand_flag_tests.c.src')])
971
972 config.add_data_dir('tests')
973 config.add_data_dir('tests/data')
974
975 config.make_svn_version_py()
976
977 return config
978
979 if __name__ == '__main__':
980 from numpy.distutils.core import setup
981 setup(configuration=configuration)
982
[end of numpy/core/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
| numpy/numpy | ab87388a76c0afca4eb1159ab0ed232d502a8378 | NumPy 1.17 RC fails to compile with Intel C Compile 2016
<!-- Please describe the issue in detail here, and fill in the fields below -->
Compiling NumPy 1.17.0rc2 sources with Intel C Compiler 2016, which does not yet implement `__builtin_cpu_supports("avx512f")` fails with compilation error:
```
icc: numpy/core/src/umath/cpuid.c
numpy/core/src/umath/cpuid.c(63): catastrophic error: invalid use of '__builtin_cpu_supports'
compilation aborted for numpy/core/src/umath/cpuid.c (code 1)
```
Recent Intel C compiler (2019) proceeds just fine.
There is config test to probe compiler for support of `__builtin_cpu_supports`, but the the test does not discriminate between supported arguments.
| @mattip This is the issue with 1.17 sources and older compiler that I mentioned at the sprint.
To reproduce I did:
1. `conda create -n b_np117 -c defaults --override-channels python setuptools cython pip pytest mkl-devel`
2. `git clone http://github.com/numpy/numpy.git --branch maintenance/1.17.x numpy_src`
3. `conda activate b_np117`
4. Edit `site.cfg`. So that
```
(b_np117) [16:15:03 vmlin numpy_src_tmp]$ cat site.cfg
[mkl]
library_dirs = /tmp/miniconda/envs/b_np117/lib
include_dirs = /tmp/miniconda/envs/b_np117/include
lapack_libs = mkl_rt
mkl_libs = mkl_rt
```
5. Check compiler version:
```
(b_np117) [17:02:25 vmlin numpy_src_tmp]$ icc --version
icc (ICC) 16.0.3 20160415
Copyright (C) 1985-2016 Intel Corporation. All rights reserved.
```
6. Execute `CFLAGS="-DNDEBUG -I$PREFIX/include $CFLAGS" python setup.py config_cc --compiler=intelem config_fc --fcompiler=intelem build --force build_ext --inplace`
It seems we need someone with that compiler to test and fix this.
I definitely volunteer for testing and fixing it, but I would appreciate some guidance as what to try tweaking and where.
Pinging @r-devulap, maybe you can have a look/know something? It seems he wrote (or modified it and is also at Intel – albeit a very different part).
@oleksandr-pavlyk could you try this fix from my branch https://github.com/r-devulap/numpy/tree/avx512-cpuid and let me know if that fixes your problem. If it does, I can submit a PR.
never mind, created a PR with a simpler fix. | 2019-07-21T14:28:45Z | <patch>
diff --git a/numpy/core/setup_common.py b/numpy/core/setup_common.py
--- a/numpy/core/setup_common.py
+++ b/numpy/core/setup_common.py
@@ -138,6 +138,8 @@ def check_api_version(apiversion, codegen_dir):
# broken on OSX 10.11, make sure its not optimized away
("volatile int r = __builtin_cpu_supports", '"sse"',
"stdio.h", "__BUILTIN_CPU_SUPPORTS"),
+ ("volatile int r = __builtin_cpu_supports", '"avx512f"',
+ "stdio.h", "__BUILTIN_CPU_SUPPORTS_AVX512F"),
# MMX only needed for icc, but some clangs don't have it
("_m_from_int64", '0', "emmintrin.h"),
("_mm_load_ps", '(float*)0', "xmmintrin.h"), # SSE
</patch> | [] | [] |