
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
google/multiberts-seed_4-step_1000k | google | bert | 8 | 33 | transformers | 0 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['multiberts', 'multiberts-seed_4', 'multiberts-seed_4-step_1000k'] | false | true | true | 3,527 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 4, Step 1000k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #4, captured at step 1000k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4-step_1000k')
model = TFBertModel.from_pretrained("google/multiberts-seed_4-step_1000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4-step_1000k')
model = BertModel.from_pretrained("google/multiberts-seed_4-step_1000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
| 4285762bf791210792aadcc46a504ed0 |
ajtamayoh/NER_ehealth_Spanish_mBERT_fine_tuned | ajtamayoh | bert | 14 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,386 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NER_ehealth_Spanish_mBERT_fine_tuned
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6563
- Precision: 0.8094
- Recall: 0.8330
- F1: 0.8210
- Accuracy: 0.9051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 100 | 0.5335 | 0.8018 | 0.8307 | 0.8160 | 0.9047 |
| No log | 2.0 | 200 | 0.5034 | 0.8110 | 0.8253 | 0.8181 | 0.9067 |
| No log | 3.0 | 300 | 0.5632 | 0.7932 | 0.8230 | 0.8078 | 0.9038 |
| No log | 4.0 | 400 | 0.5904 | 0.8004 | 0.8299 | 0.8149 | 0.9027 |
| 0.017 | 5.0 | 500 | 0.5958 | 0.7993 | 0.8330 | 0.8158 | 0.9071 |
| 0.017 | 6.0 | 600 | 0.6168 | 0.7980 | 0.8352 | 0.8162 | 0.9022 |
| 0.017 | 7.0 | 700 | 0.6219 | 0.8079 | 0.8314 | 0.8195 | 0.9062 |
| 0.017 | 8.0 | 800 | 0.6441 | 0.8046 | 0.8299 | 0.8171 | 0.9038 |
| 0.017 | 9.0 | 900 | 0.6338 | 0.8086 | 0.8253 | 0.8168 | 0.9051 |
| 0.0066 | 10.0 | 1000 | 0.6482 | 0.8021 | 0.8261 | 0.8139 | 0.9029 |
| 0.0066 | 11.0 | 1100 | 0.6578 | 0.8039 | 0.8291 | 0.8163 | 0.9038 |
| 0.0066 | 12.0 | 1200 | 0.6563 | 0.8094 | 0.8330 | 0.8210 | 0.9051 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 2e99b273e09ef1abea549261ae7f52fb |
jonatasgrosman/exp_w2v2t_fr_wav2vec2_s227 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['fr'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'fr'] | false | true | true | 456 | false | # exp_w2v2t_fr_wav2vec2_s227
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 2831799ebf9edcdb62fa1f29f9f9ac5d |
PabloZubeldia/distilbert-base-uncased-finetuned-tweets | PabloZubeldia | distilbert | 24 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,553 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-tweets
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2703
- Accuracy: 0.9068
- F1: 0.9081
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3212 | 1.0 | 143 | 0.2487 | 0.8989 | 0.8991 |
| 0.2031 | 2.0 | 286 | 0.2268 | 0.9077 | 0.9074 |
| 0.1474 | 3.0 | 429 | 0.2385 | 0.9094 | 0.9107 |
| 0.1061 | 4.0 | 572 | 0.2516 | 0.9103 | 0.9111 |
| 0.0804 | 5.0 | 715 | 0.2703 | 0.9068 | 0.9081 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 930663fede03e36c860572151020e87a |
DOOGLAK/Tagged_One_250v5_NER_Model_3Epochs_AUGMENTED | DOOGLAK | bert | 13 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['tagged_one250v5_wikigold_split'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,565 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Tagged_One_250v5_NER_Model_3Epochs_AUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the tagged_one250v5_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3623
- Precision: 0.5500
- Recall: 0.4923
- F1: 0.5196
- Accuracy: 0.8950
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 91 | 0.3950 | 0.2800 | 0.2138 | 0.2424 | 0.8558 |
| No log | 2.0 | 182 | 0.3633 | 0.4938 | 0.4306 | 0.4601 | 0.8887 |
| No log | 3.0 | 273 | 0.3623 | 0.5500 | 0.4923 | 0.5196 | 0.8950 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
| 99f1f86f32061ea33e81a2f56508090b |
Khalsuu/english-filipino-wav2vec2-l-xls-r-test-06 | Khalsuu | wav2vec2 | 13 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['filipino_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,187 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# english-filipino-wav2vec2-l-xls-r-test-06
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) on the filipino_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5806
- Wer: 0.6568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0031 | 2.09 | 400 | 1.2366 | 0.8780 |
| 0.9084 | 4.19 | 800 | 1.0653 | 0.8081 |
| 0.6484 | 6.28 | 1200 | 1.1648 | 0.8258 |
| 0.5335 | 8.38 | 1600 | 1.0903 | 0.7542 |
| 0.4359 | 10.47 | 2000 | 0.9466 | 0.7058 |
| 0.3629 | 12.57 | 2400 | 0.9266 | 0.7048 |
| 0.3057 | 14.66 | 2800 | 1.0879 | 0.7018 |
| 0.2477 | 16.75 | 3200 | 1.1113 | 0.7022 |
| 0.208 | 18.85 | 3600 | 1.1345 | 0.6742 |
| 0.1781 | 20.94 | 4000 | 1.3117 | 0.6974 |
| 0.1465 | 23.04 | 4400 | 1.3248 | 0.6916 |
| 0.1288 | 25.13 | 4800 | 1.4306 | 0.6523 |
| 0.1108 | 27.23 | 5200 | 1.5155 | 0.6685 |
| 0.099 | 29.32 | 5600 | 1.5806 | 0.6568 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| 6c50bb99da5b8b391bbaec9d697c1232 |
mqy/mt5-small-finetuned-18jan-4 | mqy | mt5 | 15 | 4 | transformers | 0 | summarization | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization', 'generated_from_trainer'] | true | true | true | 2,152 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-18jan-4
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6070
- Rouge1: 5.8518
- Rouge2: 0.3333
- Rougel: 5.8423
- Rougelsum: 5.7268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 7.6303 | 1.0 | 60 | 3.0842 | 6.1768 | 1.2345 | 6.2047 | 6.1838 |
| 3.8899 | 2.0 | 120 | 2.7540 | 7.9407 | 1.0 | 7.8852 | 7.9087 |
| 3.4335 | 3.0 | 180 | 2.7391 | 8.5431 | 0.5667 | 8.5448 | 8.4406 |
| 3.2524 | 4.0 | 240 | 2.6775 | 8.7375 | 0.4167 | 8.6926 | 8.569 |
| 3.0853 | 5.0 | 300 | 2.6776 | 7.7823 | 0.1667 | 7.7548 | 7.6573 |
| 2.974 | 6.0 | 360 | 2.6641 | 8.375 | 0.1667 | 8.3333 | 8.2167 |
| 2.9018 | 7.0 | 420 | 2.6233 | 7.2137 | 0.3333 | 7.147 | 7.0595 |
| 2.859 | 8.0 | 480 | 2.6238 | 6.6125 | 0.4167 | 6.656 | 6.4595 |
| 2.8123 | 9.0 | 540 | 2.5961 | 6.4262 | 0.3333 | 6.3682 | 6.2131 |
| 2.7843 | 10.0 | 600 | 2.6070 | 5.8518 | 0.3333 | 5.8423 | 5.7268 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| fe6bf9f509391e9766194257746c0028 |
mqy/mt5-small-finetuned-12feb-1 | mqy | mt5 | 17 | 0 | transformers | 0 | summarization | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization', 'generated_from_trainer'] | true | true | true | 1,904 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-12feb-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4285
- Rouge1: 18.23
- Rouge2: 5.42
- Rougel: 18.09
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 3.0346 | 1.0 | 311 | 2.4880 | 17.19 | 5.28 | 17.06 |
| 2.8943 | 2.0 | 622 | 2.4751 | 17.77 | 5.18 | 17.59 |
| 2.8397 | 3.0 | 933 | 2.4719 | 17.65 | 5.38 | 17.55 |
| 2.806 | 4.0 | 1244 | 2.4614 | 18.26 | 5.23 | 18.03 |
| 2.7842 | 5.0 | 1555 | 2.4464 | 18.08 | 5.51 | 17.96 |
| 2.7855 | 6.0 | 1866 | 2.4437 | 17.9 | 5.37 | 17.8 |
| 2.7796 | 7.0 | 2177 | 2.4270 | 18.07 | 5.38 | 17.95 |
| 2.7951 | 8.0 | 2488 | 2.4267 | 17.96 | 5.36 | 17.85 |
| 2.7864 | 9.0 | 2799 | 2.4285 | 18.23 | 5.42 | 18.09 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 9b6560da7f4ae4395a9443934980224e |
burakyldrm/wav2vec2-full-small_gpu_deneme4 | burakyldrm | wav2vec2 | 15 | 8 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,087 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-full-small_gpu_deneme4
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
| fff0164b615714fe587a80fc6c799223 |
jonatasgrosman/exp_w2v2t_it_unispeech-sat_s306 | jonatasgrosman | unispeech-sat | 10 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['it'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'it'] | false | true | true | 463 | false | # exp_w2v2t_it_unispeech-sat_s306
Fine-tuned [microsoft/unispeech-sat-large](https://huggingface.co/microsoft/unispeech-sat-large) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| a1286de1106a94d18ff8bf8a96b12cbd |
fulviodan/ddpm-butterflies-128 | fulviodan | null | 13 | 3 | diffusers | 0 | null | false | false | false | apache-2.0 | ['en'] | ['huggan/smithsonian_butterflies_subset'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,231 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/fulviodan/ddpm-butterflies-128/tensorboard?#scalars)
| dc27bd8ec5d6c47110b97d2dd507f948 |
Arnold/wav2vec2-large-xlsr-hausa2-demo-colab | Arnold | wav2vec2 | 18 | 11 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,556 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-hausa2-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2993
- Wer: 0.4826
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9.6e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 13
- gradient_accumulation_steps: 3
- total_train_batch_size: 36
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 6.1549 | 12.5 | 400 | 2.7289 | 1.0 |
| 2.0566 | 25.0 | 800 | 0.4582 | 0.6768 |
| 0.4423 | 37.5 | 1200 | 0.3037 | 0.5138 |
| 0.2991 | 50.0 | 1600 | 0.2993 | 0.4826 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| 898ae311392f4a39d1148bcb3d08be09 |
Helsinki-NLP/opus-mt-kqn-sv | Helsinki-NLP | marian | 10 | 7 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-kqn-sv
* source languages: kqn
* target languages: sv
* OPUS readme: [kqn-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/kqn-sv/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/kqn-sv/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/kqn-sv/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/kqn-sv/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.kqn.sv | 23.3 | 0.409 |
| e86dc333cf9326f5c640871f3c0df897 |
IMSyPP/hate_speech_en | IMSyPP | bert | 7 | 1,747 | transformers | 5 | text-classification | true | false | false | mit | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 652 | false |
# Hate Speech Classifier for Social Media Content in English Language
A monolingual model for hate speech classification of social media content in English language. The model was trained on 103190 YouTube comments and tested on an independent test set of 20554 YouTube comments. It is based on English BERT base pre-trained language model.
## Tokenizer
During training the text was preprocessed using the original English BERT base tokenizer. We suggest the same tokenizer is used for inference.
## Model output
The model classifies each input into one of four distinct classes:
* 0 - acceptable
* 1 - inappropriate
* 2 - offensive
* 3 - violent | a547308e307eecba97e5b065d552b3e8 |
Avrik/abstract-anim-spritesheets | Avrik | null | 22 | 44 | diffusers | 16 | text-to-image | false | false | false | creativeml-openrail-m | ['en'] | null | null | 3 | 0 | 3 | 0 | 2 | 2 | 0 | ['stable-diffusion', 'text-to-image', 'image-to-image'] | false | true | true | 2,246 | false | # Abstract Animation Sprite Sheets
An experimental Dreambooth model trained on individual frames of looping 3D animations that were then laid out on a 4x4 grid. Generates sprite sheets that can create very interesting abstract animations.
Use the token **AbstrAnm spritesheet**. Size must be set at 512x512 or your outputs may not work properly.
**Example prompt:** <i>AbstrAnm spritesheet, animation of a red glowing orb in the sky, highly detailed, fog, atmosphere, glow, sprites, animated, abstract</i>
<br>
**Negative prompt:** <i>high contrast, text, overlay</i>
<br>
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 8
Feel free to experiment with other types of prompts and/or model merges.

You can also upscale it 4x to produce 512x512 animations. Used SD Upscale from AUTOMATIC1111's web UI to add more sharpness and detail.

Discovered it's actually quite flexible and could even animate less abstract concepts.

**Prompt 1:** <i>AbstrAnm spritesheet, animation of magical swirling clouds in the clear blue sky, floating in crystal clear water, circular, sunny, timelapse, lens flare, nature, 35mm lens shot, photorealistic, sprites, animated, art by Greg Rutkowski</i>
<br>
**Negative prompt:** <i>text, overlay, abstract, boring, empty, barren, simple background</i>
<br>
Steps: 25, Sampler: DPM++ 2S a, CFG scale: 10
**Prompt 2:** <i>AbstrAnm spritesheet, animation of a beautiful flower blowing in the wind, serene, pink, sunny, timelapse, lens flare, nature, 35mm lens shot, photorealistic, sprites, animated, art by Greg Rutkowski</i>
**Negative prompt:** <i>text, overlay, abstract, boring, empty, barren, simple background</i>
<br>
Steps: 25, Sampler: DPM++ 2S a, CFG scale: 10
Some issues with this model:
- May not loop seamlessly
- Tends to be too noisy
- Sprites aren't usually perfect squares
- Small size and short animation (could experiment with training on larger resolutions in the future) | 4b27bce4148f90dcdad8f6cc1859912e |
fahadtouseef/wav2vec2-base-timit-demo-colab_3 | fahadtouseef | wav2vec2 | 12 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,670 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab_3
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1942
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 4.2975 | 3.52 | 500 | 3.1771 | 1.0 |
| 3.1468 | 7.04 | 1000 | 3.1917 | 1.0 |
| 3.147 | 10.56 | 1500 | 3.1784 | 1.0 |
| 3.1467 | 14.08 | 2000 | 3.1850 | 1.0 |
| 3.1446 | 17.61 | 2500 | 3.2022 | 1.0 |
| 3.1445 | 21.13 | 3000 | 3.2196 | 1.0 |
| 3.1445 | 24.65 | 3500 | 3.2003 | 1.0 |
| 3.1443 | 28.17 | 4000 | 3.1942 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| d45cdc5ff710ad38df692dd048cbc979 |
rajat99/Fine_Tuning_XLSR_300M_testing_6_model | rajat99 | wav2vec2 | 9 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,349 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Fine_Tuning_XLSR_300M_testing_6_model
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2263
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 5.466 | 23.53 | 400 | 3.2263 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| e7d04393e4cea72629c5891105c8850f |
Helsinki-NLP/opus-mt-de-nso | Helsinki-NLP | marian | 10 | 7 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-de-nso
* source languages: de
* target languages: nso
* OPUS readme: [de-nso](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-nso/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-nso/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-nso/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-nso/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.de.nso | 31.1 | 0.519 |
| 5d82ae29ce4508767cbf2358b7b2f5a7 |
edugp/kenlm | edugp | null | 167 | 0 | null | 9 | null | false | false | false | mit | ['es', 'af', 'ar', 'arz', 'as', 'bn', 'fr', 'sw', 'eu', 'ca', 'zh', 'en', 'hi', 'ur', 'id', 'pt', 'vi', 'gu', 'kn', 'ml', 'mr', 'ta', 'te', 'yo'] | ['wikipedia', 'oscar'] | null | 0 | 0 | 0 | 0 | 2 | 1 | 1 | ['kenlm', 'perplexity', 'n-gram', 'kneser-ney', 'bigscience'] | false | true | true | 2,467 | false |
# KenLM models
This repo contains several KenLM models trained on different tokenized datasets and languages.
KenLM models are probabilistic n-gram languge models that models. One use case of these models consist on fast perplexity estimation for [filtering or sampling large datasets](https://huggingface.co/bertin-project/bertin-roberta-base-spanish). For example, one could use a KenLM model trained on French Wikipedia to run inference on a large dataset and filter out samples that are very unlike to appear on Wikipedia (high perplexity), or very simple non-informative sentences that could appear repeatedly (low perplexity).
At the root of this repo you will find different directories named after the dataset models were trained on (e.g. `wikipedia`, `oscar`). Within each directory, you will find several models trained on different language subsets of the dataset (e.g. `en (English)`, `es (Spanish)`, `fr (French)`). For each language you will find three different files
* `{language}.arpa.bin`: The trained KenLM model binary
* `{language}.sp.model`: The trained SentencePiece model used for tokenization
* `{language}.sp.vocab`: The vocabulary file for the SentencePiece model
The models have been trained using some of the preprocessing steps from [cc_net](https://github.com/facebookresearch/cc_net), in particular replacing numbers with zeros and normalizing punctuation. So, it is important to keep the default values for the parameters: `lower_case`, `remove_accents`, `normalize_numbers` and `punctuation` when using the pre-trained models in order to replicate the same pre-processing steps at inference time.
# Dependencies
* KenLM: `pip install https://github.com/kpu/kenlm/archive/master.zip`
* SentencePiece: `pip install sentencepiece`
# Example:
```
from model import KenlmModel
# Load model trained on English wikipedia
model = KenlmModel.from_pretrained("wikipedia", "en")
# Get perplexity
model.get_perplexity("I am very perplexed")
# 341.3 (low perplexity, since sentence style is formal and with no grammar mistakes)
model.get_perplexity("im hella trippin")
# 46793.5 (high perplexity, since the sentence is colloquial and contains grammar mistakes)
```
In the example above we see that, since Wikipedia is a collection of encyclopedic articles, a KenLM model trained on it will naturally give lower perplexity scores to sentences with formal language and no grammar mistakes than colloquial sentences with grammar mistakes. | a07f4937d88c6260c98058dceb7f5f34 |
NimaBoscarino/efficientformer-l7-300 | NimaBoscarino | null | 5 | 0 | timm | 0 | image-classification | false | false | false | apache-2.0 | ['en'] | ['imagenet-1k'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['mobile', 'vison', 'image-classification'] | false | true | true | 3,704 | false |
# EfficientFormer-L7
## Table of Contents
- [EfficientFormer-L7](#-model_id--defaultmymodelname-true)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [How to Get Started with the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Direct Use](#direct-use)
- [Downstream Use](#downstream-use)
- [Misuse and Out-of-scope Use](#misuse-and-out-of-scope-use)
- [Limitations and Biases](#limitations-and-biases)
- [Training](#training)
- [Training Data](#training-data)
- [Training Procedure](#training-procedure)
- [Evaluation Results](#evaluation-results)
- [Environmental Impact](#environmental-impact)
- [Citation Information](#citation-information)
<model_details>
## Model Details
<!-- Give an overview of your model, the relevant research paper, who trained it, etc. -->
EfficientFormer-L7, developed by [Snap Research](https://github.com/snap-research), is one of three EfficientFormer models. The EfficientFormer models were released as part of an effort to prove that properly designed transformers can reach extremely low latency on mobile devices while maintaining high performance.
This checkpoint of EfficientFormer-L7 was trained for 300 epochs.
- Developed by: Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren
- Language(s): English
- License: This model is licensed under the apache-2.0 license
- Resources for more information:
- [Research Paper](https://arxiv.org/abs/2206.01191)
- [GitHub Repo](https://github.com/snap-research/EfficientFormer/)
</model_details>
<how_to_start>
## How to Get Started with the Model
Use the code below to get started with the model.
```python
# A nice code snippet here that describes how to use the model...
```
</how_to_start>
<uses>
## Uses
#### Direct Use
This model can be used for image classification and semantic segmentation. On mobile devices (the model was tested on iPhone 12), the CoreML checkpoints will perform these tasks with low latency.
<Limitations_and_Biases>
## Limitations and Biases
Though most designs in EfficientFormer are general-purposed, e.g., dimension- consistent design and 4D block with CONV-BN fusion, the actual speed of EfficientFormer may vary on other platforms. For instance, if GeLU is not well supported while HardSwish is efficiently implemented on specific hardware and compiler, the operator may need to be modified accordingly. The proposed latency-driven slimming is simple and fast. However, better results may be achieved if search cost is not a concern and an enumeration-based brute search is performed.
Since the model was trained on Imagenet-1K, the [biases embedded in that dataset](https://huggingface.co/datasets/imagenet-1k#considerations-for-using-the-data) will be reflected in the EfficientFormer models.
</Limitations_and_Biases>
<Training>
## Training
#### Training Data
This model was trained on ImageNet-1K.
See the [data card](https://huggingface.co/datasets/imagenet-1k) for additional information.
#### Training Procedure
* Parameters: 82.1 M
* GMACs: 10.2
* Train. Epochs: 300
Trained on a cluster with NVIDIA A100 and V100 GPUs.
</Training>
<Eval_Results>
## Evaluation Results
Top-1 Accuracy: 83.3% on ImageNet 10K
Latency: 3.0 ms
</Eval_Results>
<Cite>
## Citation Information
```bibtex
@article{li2022efficientformer,
title={EfficientFormer: Vision Transformers at MobileNet Speed},
author={Li, Yanyu and Yuan, Geng and Wen, Yang and Hu, Eric and Evangelidis, Georgios and Tulyakov, Sergey and Wang, Yanzhi and Ren, Jian},
journal={arXiv preprint arXiv:2206.01191},
year={2022}
}
```
</Cite> | 1d63eaf4c91a9f3db544afe686fb5bee |
SirVeggie/mixes | SirVeggie | null | 8 | 0 | null | 5 | null | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 4,723 | false |
# Model mixes
Custom models created by combining different models together.
You can and should influence the style of these models by mentioning the keywords of the artists included at a sufficiently high weight:\
For example (m_wlop illustration style:1.3)
## Symbol legend
```
A + B = weighted sum
A + (B - C) = add difference
@ 0.5 = merge strength/multiplier
```
Models marked with ★ are recommended.
## 1-berry
First step of berry mix. (not uploaded, but used in most mixes)
```
novel + (F222 - sd1.4) @ 1.0
```
## anymix ★
Mix of the models based on anything v3.
```
A: wlop-any + nixeu-any @ 0.5
B: ross-any + robutts-any @ 0.5
C: A + B @ 0.5
1-berry + C @ 0.5
```
## diffmix ★
Similar to anymix, but using add differential for the first level merges. Specifics have been forgotten.
Guweiz and Greg might be included - if I recall correctly - in addition to the models included in anymix.
## anydiff ★★
Mix anymix and diffmix at @0.5 (not included in the files)
## megamix
Weighted sum merge between all of my models at equal proportions, including both waifu diffusion and anything v3 versions of the same model.
Artists included are Wlop (m_wlop), Nixeu (m_nixeu), RossDraws (m_ross), Cutesexyrobutts (m_robutts), Guweiz (m_guweiz) and Grzegorz Rutkowski (m_greg).
## smoothmix ★
A semi-realistic model with smooth details.
A complex merge that I forgot the details of. Includes probably 10-20 different models from various sources.
## different-v3-c ★★★
```
smooth-diff = smoothmix + (diffmix - novel) @ 1.0
hd-ross = hd-18 + (ross - anything) @ 1.0
anymix-hardlight = anymix + (hardlight - anything) @ 1.0
#### Merge Block Weighted ####
model_0 : - smooth.safetensors
model_1 : diffmix.safetensors
base_alpha : 0.8
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\1-different.ckpt
weights : 0,0,0,0,0,0,0,0,0,0,0,0,0.85,0.05,0.02,0.01,0.01,0.02,0.05,0.1,0.2,0.4,0.6,0.8,1
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : 1-different.ckpt
model_1 : smooth-diff.ckpt
base_alpha : 0.1
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\2-different.ckpt
weights : 0,0,0,0,0,0,0,0,0,0,0,0,0.2,0.15,0.25,0.5,0.7,0.8,0.6,0.2,0.05,0.01,0,0,0
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : 2-different.ckpt
model_1 : protogenX53Photorealism_10.safetensors
base_alpha : 0.1
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\3-different.ckpt
weights : 0.2,0.2,0.2,0.2,0.25,0.25,0.3,0.4,0.4,0.3,0.2,0.1,0.2,0,0,0,0,0,0,0,0,0,0,0,0
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : 3-different.ckpt
model_1 : protogenV22Anime_22.safetensors
base_alpha : 0.1
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\4-different.ckpt
weights : 0.75,0.5,0.3,0.15,0.08,0.04,0.02,0.01,0.01,0.01,0.01,0.01,0.1,0,0,0,0,0,0,0,0,0,0,0,0
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : 4-different.ckpt
model_1 : hd-ross.ckpt
base_alpha : 0.1
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\different-v1.ckpt
weights : 0,0,0,0,0,0.1,0.21,0.28,0.3,0.26,0.18,0.1,0.05,0.1,0.18,0.22,0.23,0.2,0.12,0,0,0,0,0,0
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : different-v1.ckpt
model_1 : anymix-hardlight.ckpt
base_alpha : 0.2
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\different-v1-x.ckpt
weights : 0.05,0.12,0.19,0.2,0.17,0.12,0.06,0.05,0.07,0.08,0.11,0.15,0.25,0.25,0.18,0.11,0.05,0.08,0.12,0.14,0.15,0.13,0.11,0.09,0.1
skip ids : 0 : 0:None, 1:Skip, 2:Reset
#### Merge Block Weighted ####
model_0 : different-v1-x.ckpt
model_1 : AbyssOrangeMix2_nsfw.safetensors
base_alpha : 0.1
output_file: S:\Library\Files\Tools\Super SD 2.0\models\Stable-diffusion\different-v3-c.ckpt
weights : 0.5,0.4,0.3,0.2,0.2,0.2,0.2,0.2,0.25,0.3,0.35,0.4,0.45,0.4,0.35,0.3,0.25,0.2,0.15,0.1,0.05,0,0,0,0
skip ids : 0 : 0:None, 1:Skip, 2:Reset
```
## Links to models
https://huggingface.co/SirVeggie/wlop\
https://huggingface.co/SirVeggie/nixeu\
https://huggingface.co/SirVeggie/ross_draws\
https://huggingface.co/SirVeggie/cutesexyrobutts\
https://huggingface.co/SirVeggie/guweiz\
https://huggingface.co/SirVeggie/greg_rutkowski
https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release\
https://huggingface.co/darkstorm2150/Protogen_x5.3_Official_Release\
https://huggingface.co/WarriorMama777/OrangeMixs#model-detail--merge-recipes | 3f9447ac19e9fe5f398271b4765e43d2 |
gsdf/Replicant | gsdf | null | 11 | 0 | diffusers | 24 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers'] | false | true | true | 6,595 | false | # Please enable hires. fix when using it.
Replicant is built by merging several models with fine-tuning WD1.4 and photorealistic SD2.0 models that works with danbooru tags.I trained 4 models to merge and prepared several LoRa models for tuning.As with SD1.x, merging individually trained models is better quality than training many concepts at once.This model is a workflow test and is not good enough. WD1.4 seems to vary greatly in quality with/without Hires. fix.In Replicant, the difference in quality is more noticeable because of the detailed drawings.So I recommend enabling Hires.fix for use.
# Example
Denoising strength 0.6 is a bit large. I like 0.57 better.
The optimal CFG Scale value should also be examined.
Hands often multiply. When this happens, increase the value of "extra hands".

((masterpiece, best quality)), 1girl, flower, solo, dress, holding, sky, cloud, hat, outdoors, bangs, bouquet, rose, expressionless, blush, pink hair, flower field, red flower, pink eyes, white dress, looking at viewer, midium hair, holding flower, small breasts, red rose, holding bouquet, sun hat, white headwear, depth of field
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, skirt, shoes, solo, jacket, holding, alley, sitting, can, sneakers, hood, bag, hoodie, squatting, bangs, shirt, black hair, black skirt, short hair, white jacket, looking away, white footwear, full body, red eyes, long sleeves, open jacket, open clothes, holding can,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra legs, extra hands, fewer digits , long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes,drinking
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, blood, solo, wings, halo, dress, socks, angel, long hair, shoes, standing, ribbon, long hair, blue eyes, angel wings, blood on clothes, white hair, full body, white wings, black footwear, white dress, feathered wings, white sock, white background, long sleeves, simple background,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra legs, extra hands, fewer digits , long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 384x576, Denoising strength: 0.57, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, car, solo, shorts, jacket, bangs, sitting, shirt, shoes, hairclip, socks, sneakers, denim, sidelocks, motor vehicle, long hair, ground vehicle,brown hair, looking at viewer, white shirt, black jacket, long sleeves, sports car, vehicle focus, aqua eyes, white socks, blue shorts, open clothes, black footwear, denim shorts, open jacket
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 384x576, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, solo, twintails, lollipop, smile, ahoge, hairclip, bow, holding, ribbon, frills, blush, shirt, :d, stuffed toy, pink hair, stuffed animal, red nails, hair ornament, open mouth, looking at viewer, stuffed bunny, nail polish, short sleeves, object hug, puffy sleeves, hair between eyes, upper body, light blue eyes, puffy short sleeves, holding stuffed toy, hair bow, white bow, doll hug, hair ribbon, streaked hair, white shirt
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 512x512, Denoising strength: 0.57, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, solo, tail, barefoot, skirt, sleeping, lying, grass, shirt, outdoors, socks, flower, long hair, on side, animal ears, blonde hair, cat tail, closed eyes, blue skirt, white shirt, cat ears, school uniform, dappled sunlight, short sleeves, bare legs, closed mouth, full body, pleated skirt
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, car, building, gun, weapon, outdoors, solo, military, day, city, standing, serious, pants, rifle, holding, jacket, motor vehicle, ground vehicle, brown hair, assault rifle, long hair, vehicle focus, holding gun, holding weapon, black footwear, military vehicle, full body, depth of field,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent | 22fc35ea63a98a789b7ef833037c49d7 |
leokai/distilroberta-base-wikitextepoch_50 | leokai | roberta | 6 | 2 | transformers | 0 | fill-mask | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,757 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-wikitextepoch_50
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.9729 | 1.0 | 2145 | 1.7725 |
| 1.9158 | 2.0 | 4290 | 1.7521 |
| 1.8479 | 3.0 | 6435 | 1.7376 |
| 1.8081 | 4.0 | 8580 | 1.7272 |
| 1.7966 | 5.0 | 10725 | 1.7018 |
| 1.7284 | 6.0 | 12870 | 1.7010 |
| 1.7198 | 7.0 | 15015 | 1.6868 |
| 1.6985 | 8.0 | 17160 | 1.6879 |
| 1.6712 | 9.0 | 19305 | 1.6930 |
| 1.6489 | 10.0 | 21450 | 1.6594 |
| 1.6643 | 11.0 | 23595 | 1.6856 |
| 1.6215 | 12.0 | 25740 | 1.6816 |
| 1.6125 | 13.0 | 27885 | 1.6714 |
| 1.5936 | 14.0 | 30030 | 1.6760 |
| 1.5745 | 15.0 | 32175 | 1.6660 |
| 1.572 | 16.0 | 34320 | 1.6690 |
| 1.5614 | 17.0 | 36465 | 1.6807 |
| 1.558 | 18.0 | 38610 | 1.6711 |
| 1.5305 | 19.0 | 40755 | 1.6446 |
| 1.5021 | 20.0 | 42900 | 1.6573 |
| 1.4923 | 21.0 | 45045 | 1.6648 |
| 1.5086 | 22.0 | 47190 | 1.6757 |
| 1.4895 | 23.0 | 49335 | 1.6525 |
| 1.4918 | 24.0 | 51480 | 1.6577 |
| 1.4642 | 25.0 | 53625 | 1.6633 |
| 1.4604 | 26.0 | 55770 | 1.6462 |
| 1.4644 | 27.0 | 57915 | 1.6509 |
| 1.4633 | 28.0 | 60060 | 1.6417 |
| 1.4188 | 29.0 | 62205 | 1.6519 |
| 1.4066 | 30.0 | 64350 | 1.6363 |
| 1.409 | 31.0 | 66495 | 1.6419 |
| 1.4029 | 32.0 | 68640 | 1.6510 |
| 1.4013 | 33.0 | 70785 | 1.6522 |
| 1.3939 | 34.0 | 72930 | 1.6498 |
| 1.3648 | 35.0 | 75075 | 1.6423 |
| 1.3682 | 36.0 | 77220 | 1.6504 |
| 1.3603 | 37.0 | 79365 | 1.6511 |
| 1.3621 | 38.0 | 81510 | 1.6533 |
| 1.3783 | 39.0 | 83655 | 1.6426 |
| 1.3707 | 40.0 | 85800 | 1.6542 |
| 1.3628 | 41.0 | 87945 | 1.6671 |
| 1.3359 | 42.0 | 90090 | 1.6394 |
| 1.3433 | 43.0 | 92235 | 1.6409 |
| 1.3525 | 44.0 | 94380 | 1.6366 |
| 1.3312 | 45.0 | 96525 | 1.6408 |
| 1.3389 | 46.0 | 98670 | 1.6225 |
| 1.3323 | 47.0 | 100815 | 1.6309 |
| 1.3294 | 48.0 | 102960 | 1.6151 |
| 1.3356 | 49.0 | 105105 | 1.6374 |
| 1.3285 | 50.0 | 107250 | 1.6360 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
| 7bcac475ce8cbc81eaf835ed180d9f71 |
cemsubakan/cnn14-esc50 | cemsubakan | null | 7 | 4 | null | 0 | null | false | false | false | apache-2.0 | ['en'] | ['ESC50'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['Sound Classification', 'CNN14'] | false | true | true | 2,570 | false |
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# CNN14 Trained on VGGSound dataset with SimCLR and Fine Tuned on ESC50
This repository provides all the necessary tools to perform audip classification with [CNN14 model](https://arxiv.org/abs/1912.10211) model, implemented with SpeechBrain. For a better experience we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The encoder is first trained with SimCLR on the VGGGSound dataset, and then fine tuned on ESC50 folds 1,2,3.
| Release | Classification Accuracy Valid | Classification Accuracy Test |
|:-------------:|:--------------:|:--------------:|
| 26-11-22 | 90% | 82% |
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
#### Referencing This Pretrained Model
The encoder is originally trained for our [paper](https://arxiv.org/pdf/2205.07390.pdf). You can reference our paper if you use this model for your research.
```bibtex
@inproceedings{wang2022CRL,
title={Learning Representations for New Sound Classes With Continual Self-Supervised Learning},
author={Zhepei Wang, Cem Subakan, Xilin Jiang, Junkai Wu, Efthymios Tzinis, Mirco Ravanelli, Paris Smaragdis},
year={2022},
booktitle={Accepted to IEEE Signal Processing Letters}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/ | e944b495c9e72a23881adb0a7de73b19 |
ArBert/bert-base-uncased-finetuned-ner | ArBert | bert | 12 | 4 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,533 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-ner
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0905
- Precision: 0.9068
- Recall: 0.9200
- F1: 0.9133
- Accuracy: 0.9787
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1266 | 1.0 | 1123 | 0.0952 | 0.8939 | 0.8869 | 0.8904 | 0.9742 |
| 0.0741 | 2.0 | 2246 | 0.0866 | 0.8936 | 0.9247 | 0.9089 | 0.9774 |
| 0.0496 | 3.0 | 3369 | 0.0905 | 0.9068 | 0.9200 | 0.9133 | 0.9787 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| 5a466f5a017335b3f0a7df182392be0d |
Helsinki-NLP/opus-mt-en-itc | Helsinki-NLP | marian | 11 | 8 | transformers | 1 | translation | true | true | false | apache-2.0 | ['en', 'it', 'ca', 'rm', 'es', 'ro', 'gl', 'sc', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'itc'] | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 5,233 | false |
### eng-itc
* source group: English
* target group: Italic languages
* OPUS readme: [eng-itc](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-itc/README.md)
* model: transformer
* source language(s): eng
* target language(s): arg ast cat cos egl ext fra frm_Latn gcf_Latn glg hat ind ita lad lad_Latn lat_Latn lij lld_Latn lmo max_Latn mfe min mwl oci pap pms por roh ron scn spa tmw_Latn vec wln zlm_Latn zsm_Latn
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-itc/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-itc/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-itc/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-enro-engron.eng.ron | 27.1 | 0.565 |
| newsdiscussdev2015-enfr-engfra.eng.fra | 29.9 | 0.574 |
| newsdiscusstest2015-enfr-engfra.eng.fra | 35.3 | 0.609 |
| newssyscomb2009-engfra.eng.fra | 27.7 | 0.567 |
| newssyscomb2009-engita.eng.ita | 28.6 | 0.586 |
| newssyscomb2009-engspa.eng.spa | 29.8 | 0.569 |
| news-test2008-engfra.eng.fra | 25.0 | 0.536 |
| news-test2008-engspa.eng.spa | 27.1 | 0.548 |
| newstest2009-engfra.eng.fra | 26.7 | 0.557 |
| newstest2009-engita.eng.ita | 28.9 | 0.583 |
| newstest2009-engspa.eng.spa | 28.9 | 0.567 |
| newstest2010-engfra.eng.fra | 29.6 | 0.574 |
| newstest2010-engspa.eng.spa | 33.8 | 0.598 |
| newstest2011-engfra.eng.fra | 30.9 | 0.590 |
| newstest2011-engspa.eng.spa | 34.8 | 0.598 |
| newstest2012-engfra.eng.fra | 29.1 | 0.574 |
| newstest2012-engspa.eng.spa | 34.9 | 0.600 |
| newstest2013-engfra.eng.fra | 30.1 | 0.567 |
| newstest2013-engspa.eng.spa | 31.8 | 0.576 |
| newstest2016-enro-engron.eng.ron | 25.9 | 0.548 |
| Tatoeba-test.eng-arg.eng.arg | 1.6 | 0.120 |
| Tatoeba-test.eng-ast.eng.ast | 17.2 | 0.389 |
| Tatoeba-test.eng-cat.eng.cat | 47.6 | 0.668 |
| Tatoeba-test.eng-cos.eng.cos | 4.3 | 0.287 |
| Tatoeba-test.eng-egl.eng.egl | 0.9 | 0.101 |
| Tatoeba-test.eng-ext.eng.ext | 8.7 | 0.287 |
| Tatoeba-test.eng-fra.eng.fra | 44.9 | 0.635 |
| Tatoeba-test.eng-frm.eng.frm | 1.0 | 0.225 |
| Tatoeba-test.eng-gcf.eng.gcf | 0.7 | 0.115 |
| Tatoeba-test.eng-glg.eng.glg | 44.9 | 0.648 |
| Tatoeba-test.eng-hat.eng.hat | 30.9 | 0.533 |
| Tatoeba-test.eng-ita.eng.ita | 45.4 | 0.673 |
| Tatoeba-test.eng-lad.eng.lad | 5.6 | 0.279 |
| Tatoeba-test.eng-lat.eng.lat | 12.1 | 0.380 |
| Tatoeba-test.eng-lij.eng.lij | 1.4 | 0.183 |
| Tatoeba-test.eng-lld.eng.lld | 0.5 | 0.199 |
| Tatoeba-test.eng-lmo.eng.lmo | 0.7 | 0.187 |
| Tatoeba-test.eng-mfe.eng.mfe | 83.6 | 0.909 |
| Tatoeba-test.eng-msa.eng.msa | 31.3 | 0.549 |
| Tatoeba-test.eng.multi | 38.0 | 0.588 |
| Tatoeba-test.eng-mwl.eng.mwl | 2.7 | 0.322 |
| Tatoeba-test.eng-oci.eng.oci | 8.2 | 0.293 |
| Tatoeba-test.eng-pap.eng.pap | 46.7 | 0.663 |
| Tatoeba-test.eng-pms.eng.pms | 2.1 | 0.194 |
| Tatoeba-test.eng-por.eng.por | 41.2 | 0.635 |
| Tatoeba-test.eng-roh.eng.roh | 2.6 | 0.237 |
| Tatoeba-test.eng-ron.eng.ron | 40.6 | 0.632 |
| Tatoeba-test.eng-scn.eng.scn | 1.6 | 0.181 |
| Tatoeba-test.eng-spa.eng.spa | 49.5 | 0.685 |
| Tatoeba-test.eng-vec.eng.vec | 1.6 | 0.223 |
| Tatoeba-test.eng-wln.eng.wln | 7.1 | 0.250 |
### System Info:
- hf_name: eng-itc
- source_languages: eng
- target_languages: itc
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-itc/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'it', 'ca', 'rm', 'es', 'ro', 'gl', 'sc', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'itc']
- src_constituents: {'eng'}
- tgt_constituents: {'ita', 'cat', 'roh', 'spa', 'pap', 'bjn', 'lmo', 'mwl', 'lij', 'lat_Latn', 'lad_Latn', 'pcd', 'lat_Grek', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'srd', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-itc/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-itc/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: itc
- short_pair: en-itc
- chrF2_score: 0.588
- bleu: 38.0
- brevity_penalty: 0.9670000000000001
- ref_len: 73951.0
- src_name: English
- tgt_name: Italic languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: itc
- prefer_old: False
- long_pair: eng-itc
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 582bc4d60fc0f2ac280aff045e7638a9 |
Helsinki-NLP/opus-mt-tr-az | Helsinki-NLP | marian | 11 | 28 | transformers | 1 | translation | true | true | false | apache-2.0 | ['tr', 'az'] | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 1,997 | false |
### tur-aze
* source group: Turkish
* target group: Azerbaijani
* OPUS readme: [tur-aze](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tur-aze/README.md)
* model: transformer-align
* source language(s): tur
* target language(s): aze_Latn
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm4k,spm4k)
* download original weights: [opus-2020-06-16.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-aze/opus-2020-06-16.zip)
* test set translations: [opus-2020-06-16.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-aze/opus-2020-06-16.test.txt)
* test set scores: [opus-2020-06-16.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-aze/opus-2020-06-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.tur.aze | 27.7 | 0.551 |
### System Info:
- hf_name: tur-aze
- source_languages: tur
- target_languages: aze
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tur-aze/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['tr', 'az']
- src_constituents: {'tur'}
- tgt_constituents: {'aze_Latn'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm4k,spm4k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/tur-aze/opus-2020-06-16.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/tur-aze/opus-2020-06-16.test.txt
- src_alpha3: tur
- tgt_alpha3: aze
- short_pair: tr-az
- chrF2_score: 0.551
- bleu: 27.7
- brevity_penalty: 1.0
- ref_len: 5436.0
- src_name: Turkish
- tgt_name: Azerbaijani
- train_date: 2020-06-16
- src_alpha2: tr
- tgt_alpha2: az
- prefer_old: False
- long_pair: tur-aze
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 83b4ded85f8f36f3eb2bb59456790697 |
DrishtiSharma/lwg_chebakia | DrishtiSharma | null | 4 | 0 | transformers | 0 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['huggan', 'gan'] | false | true | true | 775 | false |
# MyModelName
## Model description
Describe the model here (what it does, what it's used for, etc.)
## Intended uses & limitations
#### How to use
```python
# You can include sample code which will be formatted
```
#### Limitations and bias
Provide examples of latent issues and potential remediations.
## Training data
Describe the data you used to train the model.
If you initialized it with pre-trained weights, add a link to the pre-trained model card or repository with description of the pre-training data.
## Training procedure
Preprocessing, hardware used, hyperparameters...
## Eval results
## Generated Images
You can embed local or remote images using ``
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020}
}
``` | a6e2b485983a99e6ad784e4da1cc69ad |
Sounak/bert-large-finetuned | Sounak | bert | 8 | 3 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,413 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Sounak/bert-large-finetuned
This model is a fine-tuned version of [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.7634
- Validation Loss: 1.6843
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 157, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.7634 | 1.6843 | 0 |
### Framework versions
- Transformers 4.19.2
- TensorFlow 2.9.1
- Datasets 2.2.2
- Tokenizers 0.12.1
| 6e6c6349af641ecc064f5931f78225b3 |
Lemswasabi/wav2vec2-base-luxembourgish-4h-with-lm | Lemswasabi | wav2vec2 | 14 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | mit | ['lb'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'generated_from_trainer'] | false | true | true | 1,810 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
## Model description
We pre-trained a wav2vec 2.0 base model on 842h of unlabelled Luxembourgish speech
collected from [RTL.lu](https://www.rtl.lu/). Then the model was fine-tuned on 4h of labelled
Luxembourgish Speech from the same domain. Additionally, we rescore the output transcription
with a 5-gram language model trained on text corpora from RTL.lu and the Luxembourgish parliament.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 12
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
## Citation
This model is a result of our paper `IMPROVING LUXEMBOURGISH SPEECH RECOGNITION WITH CROSS-LINGUAL SPEECH REPRESENTATIONS` submitted to the [IEEE SLT 2022 workshop](https://slt2022.org/)
```
@misc{lb-wav2vec2,
author = {Nguyen, Le Minh and Nayak, Shekhar and Coler, Matt.},
keywords = {Luxembourgish, multilingual speech recognition, language modelling, wav2vec 2.0 XLSR-53, under-resourced language},
title = {IMPROVING LUXEMBOURGISH SPEECH RECOGNITION WITH CROSS-LINGUAL SPEECH REPRESENTATIONS},
year = {2022},
copyright = {2023 IEEE}
}
``` | 0fe3f510417ccd3f78dfcdf1b2ed2c03 |
ali2066/finetuned_token_itr0_3e-05_all_16_02_2022-20_12_04 | ali2066 | distilbert | 13 | 10 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,796 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_token_itr0_3e-05_all_16_02_2022-20_12_04
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1620
- Precision: 0.3509
- Recall: 0.3793
- F1: 0.3646
- Accuracy: 0.9468
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 38 | 0.2997 | 0.1125 | 0.2057 | 0.1454 | 0.8669 |
| No log | 2.0 | 76 | 0.2620 | 0.1928 | 0.2849 | 0.2300 | 0.8899 |
| No log | 3.0 | 114 | 0.2497 | 0.1923 | 0.2906 | 0.2314 | 0.8918 |
| No log | 4.0 | 152 | 0.2474 | 0.1819 | 0.3377 | 0.2365 | 0.8905 |
| No log | 5.0 | 190 | 0.2418 | 0.2128 | 0.3264 | 0.2576 | 0.8997 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
| e8fdbd38ea2daf07cb68a1056a4e7e93 |
BatuhanYilmaz/dummy-model | BatuhanYilmaz | camembert | 4 | 2 | transformers | 0 | fill-mask | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 822 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# dummy-model
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.7.0
- Datasets 1.17.0
- Tokenizers 0.10.3
| ebbbab8e6fe4f894d488bd5864f09a10 |
tucan9389/distilbert-base-uncased-finetuned-squad | tucan9389 | distilbert | 12 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,285 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1560
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2252 | 1.0 | 5533 | 1.1671 |
| 0.9494 | 2.0 | 11066 | 1.1279 |
| 0.7696 | 3.0 | 16599 | 1.1560 |
### Framework versions
- Transformers 4.12.4
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
| e32cd619dd700a951c49f20c6623b5c0 |
elliotthwang/mt5-small-finetuned-tradition-zh | elliotthwang | mt5 | 16 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | ['xlsum'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,802 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-tradition-zh
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9218
- Rouge1: 5.7806
- Rouge2: 1.266
- Rougel: 5.761
- Rougelsum: 5.7833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| 4.542 | 1.0 | 2336 | 3.1979 | 4.8334 | 1.025 | 4.8142 | 4.8326 |
| 3.7542 | 2.0 | 4672 | 3.0662 | 5.2155 | 1.0978 | 5.2025 | 5.2158 |
| 3.5706 | 3.0 | 7008 | 3.0070 | 5.5471 | 1.3397 | 5.5386 | 5.5391 |
| 3.4668 | 4.0 | 9344 | 2.9537 | 5.5865 | 1.1558 | 5.5816 | 5.5964 |
| 3.4082 | 5.0 | 11680 | 2.9391 | 5.8061 | 1.3462 | 5.7944 | 5.812 |
| 3.375 | 6.0 | 14016 | 2.9218 | 5.7806 | 1.266 | 5.761 | 5.7833 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| c3ac2f23cad9b3bdea266e0766021ef3 |
tomekkorbak/hopeful_newton | tomekkorbak | null | 2 | 0 | null | 0 | null | false | false | false | mit | ['en'] | ['tomekkorbak/pii-pile-chunk3-0-50000', 'tomekkorbak/pii-pile-chunk3-50000-100000', 'tomekkorbak/pii-pile-chunk3-100000-150000', 'tomekkorbak/pii-pile-chunk3-150000-200000', 'tomekkorbak/pii-pile-chunk3-200000-250000', 'tomekkorbak/pii-pile-chunk3-250000-300000', 'tomekkorbak/pii-pile-chunk3-300000-350000', 'tomekkorbak/pii-pile-chunk3-350000-400000', 'tomekkorbak/pii-pile-chunk3-400000-450000', 'tomekkorbak/pii-pile-chunk3-450000-500000', 'tomekkorbak/pii-pile-chunk3-500000-550000', 'tomekkorbak/pii-pile-chunk3-550000-600000', 'tomekkorbak/pii-pile-chunk3-600000-650000', 'tomekkorbak/pii-pile-chunk3-650000-700000', 'tomekkorbak/pii-pile-chunk3-700000-750000', 'tomekkorbak/pii-pile-chunk3-750000-800000', 'tomekkorbak/pii-pile-chunk3-800000-850000', 'tomekkorbak/pii-pile-chunk3-850000-900000', 'tomekkorbak/pii-pile-chunk3-900000-950000', 'tomekkorbak/pii-pile-chunk3-950000-1000000', 'tomekkorbak/pii-pile-chunk3-1000000-1050000', 'tomekkorbak/pii-pile-chunk3-1050000-1100000', 'tomekkorbak/pii-pile-chunk3-1100000-1150000', 'tomekkorbak/pii-pile-chunk3-1150000-1200000', 'tomekkorbak/pii-pile-chunk3-1200000-1250000', 'tomekkorbak/pii-pile-chunk3-1250000-1300000', 'tomekkorbak/pii-pile-chunk3-1300000-1350000', 'tomekkorbak/pii-pile-chunk3-1350000-1400000', 'tomekkorbak/pii-pile-chunk3-1400000-1450000', 'tomekkorbak/pii-pile-chunk3-1450000-1500000', 'tomekkorbak/pii-pile-chunk3-1500000-1550000', 'tomekkorbak/pii-pile-chunk3-1550000-1600000', 'tomekkorbak/pii-pile-chunk3-1600000-1650000', 'tomekkorbak/pii-pile-chunk3-1650000-1700000', 'tomekkorbak/pii-pile-chunk3-1700000-1750000', 'tomekkorbak/pii-pile-chunk3-1750000-1800000', 'tomekkorbak/pii-pile-chunk3-1800000-1850000', 'tomekkorbak/pii-pile-chunk3-1850000-1900000', 'tomekkorbak/pii-pile-chunk3-1900000-1950000'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 8,009 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hopeful_newton
This model was trained from scratch on the tomekkorbak/pii-pile-chunk3-0-50000, the tomekkorbak/pii-pile-chunk3-50000-100000, the tomekkorbak/pii-pile-chunk3-100000-150000, the tomekkorbak/pii-pile-chunk3-150000-200000, the tomekkorbak/pii-pile-chunk3-200000-250000, the tomekkorbak/pii-pile-chunk3-250000-300000, the tomekkorbak/pii-pile-chunk3-300000-350000, the tomekkorbak/pii-pile-chunk3-350000-400000, the tomekkorbak/pii-pile-chunk3-400000-450000, the tomekkorbak/pii-pile-chunk3-450000-500000, the tomekkorbak/pii-pile-chunk3-500000-550000, the tomekkorbak/pii-pile-chunk3-550000-600000, the tomekkorbak/pii-pile-chunk3-600000-650000, the tomekkorbak/pii-pile-chunk3-650000-700000, the tomekkorbak/pii-pile-chunk3-700000-750000, the tomekkorbak/pii-pile-chunk3-750000-800000, the tomekkorbak/pii-pile-chunk3-800000-850000, the tomekkorbak/pii-pile-chunk3-850000-900000, the tomekkorbak/pii-pile-chunk3-900000-950000, the tomekkorbak/pii-pile-chunk3-950000-1000000, the tomekkorbak/pii-pile-chunk3-1000000-1050000, the tomekkorbak/pii-pile-chunk3-1050000-1100000, the tomekkorbak/pii-pile-chunk3-1100000-1150000, the tomekkorbak/pii-pile-chunk3-1150000-1200000, the tomekkorbak/pii-pile-chunk3-1200000-1250000, the tomekkorbak/pii-pile-chunk3-1250000-1300000, the tomekkorbak/pii-pile-chunk3-1300000-1350000, the tomekkorbak/pii-pile-chunk3-1350000-1400000, the tomekkorbak/pii-pile-chunk3-1400000-1450000, the tomekkorbak/pii-pile-chunk3-1450000-1500000, the tomekkorbak/pii-pile-chunk3-1500000-1550000, the tomekkorbak/pii-pile-chunk3-1550000-1600000, the tomekkorbak/pii-pile-chunk3-1600000-1650000, the tomekkorbak/pii-pile-chunk3-1650000-1700000, the tomekkorbak/pii-pile-chunk3-1700000-1750000, the tomekkorbak/pii-pile-chunk3-1750000-1800000, the tomekkorbak/pii-pile-chunk3-1800000-1850000, the tomekkorbak/pii-pile-chunk3-1850000-1900000 and the tomekkorbak/pii-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 3147
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/pii-pile-chunk3-0-50000',
'tomekkorbak/pii-pile-chunk3-50000-100000',
'tomekkorbak/pii-pile-chunk3-100000-150000',
'tomekkorbak/pii-pile-chunk3-150000-200000',
'tomekkorbak/pii-pile-chunk3-200000-250000',
'tomekkorbak/pii-pile-chunk3-250000-300000',
'tomekkorbak/pii-pile-chunk3-300000-350000',
'tomekkorbak/pii-pile-chunk3-350000-400000',
'tomekkorbak/pii-pile-chunk3-400000-450000',
'tomekkorbak/pii-pile-chunk3-450000-500000',
'tomekkorbak/pii-pile-chunk3-500000-550000',
'tomekkorbak/pii-pile-chunk3-550000-600000',
'tomekkorbak/pii-pile-chunk3-600000-650000',
'tomekkorbak/pii-pile-chunk3-650000-700000',
'tomekkorbak/pii-pile-chunk3-700000-750000',
'tomekkorbak/pii-pile-chunk3-750000-800000',
'tomekkorbak/pii-pile-chunk3-800000-850000',
'tomekkorbak/pii-pile-chunk3-850000-900000',
'tomekkorbak/pii-pile-chunk3-900000-950000',
'tomekkorbak/pii-pile-chunk3-950000-1000000',
'tomekkorbak/pii-pile-chunk3-1000000-1050000',
'tomekkorbak/pii-pile-chunk3-1050000-1100000',
'tomekkorbak/pii-pile-chunk3-1100000-1150000',
'tomekkorbak/pii-pile-chunk3-1150000-1200000',
'tomekkorbak/pii-pile-chunk3-1200000-1250000',
'tomekkorbak/pii-pile-chunk3-1250000-1300000',
'tomekkorbak/pii-pile-chunk3-1300000-1350000',
'tomekkorbak/pii-pile-chunk3-1350000-1400000',
'tomekkorbak/pii-pile-chunk3-1400000-1450000',
'tomekkorbak/pii-pile-chunk3-1450000-1500000',
'tomekkorbak/pii-pile-chunk3-1500000-1550000',
'tomekkorbak/pii-pile-chunk3-1550000-1600000',
'tomekkorbak/pii-pile-chunk3-1600000-1650000',
'tomekkorbak/pii-pile-chunk3-1650000-1700000',
'tomekkorbak/pii-pile-chunk3-1700000-1750000',
'tomekkorbak/pii-pile-chunk3-1750000-1800000',
'tomekkorbak/pii-pile-chunk3-1800000-1850000',
'tomekkorbak/pii-pile-chunk3-1850000-1900000',
'tomekkorbak/pii-pile-chunk3-1900000-1950000'],
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'every_n_steps': 32,
'force_call_on': [25177],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 2048}],
'scorer_config': {}},
'kl_gpt3_callback': {'every_n_steps': 32,
'force_call_on': [25177],
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': '9e6c78543a6ff1e4089002c38864d5a9cf71ec90',
'value_head_config': {'is_detached': False}},
'path_or_name': 'tomekkorbak/nervous_wozniak'},
'objective': {'alpha': 1, 'beta': 10, 'name': 'AWR'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 512,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'hopeful_newton',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output2',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 3346,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/1cgjg57y | 40fa81d3952f09a1a9d01a888751dd05 |
google/mt5-small | google | mt5 | 10 | 193,292 | transformers | 37 | text2text-generation | true | true | true | apache-2.0 | ['multilingual', 'af', 'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'ceb', 'co', 'cs', 'cy', 'da', 'de', 'el', 'en', 'eo', 'es', 'et', 'eu', 'fa', 'fi', 'fil', 'fr', 'fy', 'ga', 'gd', 'gl', 'gu', 'ha', 'haw', 'hi', 'hmn', 'ht', 'hu', 'hy', 'ig', 'is', 'it', 'iw', 'ja', 'jv', 'ka', 'kk', 'km', 'kn', 'ko', 'ku', 'ky', 'la', 'lb', 'lo', 'lt', 'lv', 'mg', 'mi', 'mk', 'ml', 'mn', 'mr', 'ms', 'mt', 'my', 'ne', 'nl', False, 'ny', 'pa', 'pl', 'ps', 'pt', 'ro', 'ru', 'sd', 'si', 'sk', 'sl', 'sm', 'sn', 'so', 'sq', 'sr', 'st', 'su', 'sv', 'sw', 'ta', 'te', 'tg', 'th', 'tr', 'uk', 'und', 'ur', 'uz', 'vi', 'xh', 'yi', 'yo', 'zh', 'zu'] | ['mc4'] | null | 2 | 0 | 1 | 1 | 0 | 0 | 0 | [] | false | true | true | 2,246 | false |
[Google's mT5](https://github.com/google-research/multilingual-t5)
mT5 is pretrained on the [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) corpus, covering 101 languages:
Afrikaans, Albanian, Amharic, Arabic, Armenian, Azerbaijani, Basque, Belarusian, Bengali, Bulgarian, Burmese, Catalan, Cebuano, Chichewa, Chinese, Corsican, Czech, Danish, Dutch, English, Esperanto, Estonian, Filipino, Finnish, French, Galician, Georgian, German, Greek, Gujarati, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hmong, Hungarian, Icelandic, Igbo, Indonesian, Irish, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish, Kyrgyz, Lao, Latin, Latvian, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Mongolian, Nepali, Norwegian, Pashto, Persian, Polish, Portuguese, Punjabi, Romanian, Russian, Samoan, Scottish Gaelic, Serbian, Shona, Sindhi, Sinhala, Slovak, Slovenian, Somali, Sotho, Spanish, Sundanese, Swahili, Swedish, Tajik, Tamil, Telugu, Thai, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Welsh, West Frisian, Xhosa, Yiddish, Yoruba, Zulu.
**Note**: mT5 was only pre-trained on mC4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
Pretraining Dataset: [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual)
Other Community Checkpoints: [here](https://huggingface.co/models?search=mt5)
Paper: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
Authors: *Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel*
## Abstract
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available. | 8ece6e015d555d9189ab3b98c4314480 |
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_data_aug_cola_128 | gokuls | mobilebert | 17 | 0 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,717 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_data_aug_cola_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7034
- Matthews Correlation: 0.1046
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:-----:|:---------------:|:--------------------:|
| 0.6386 | 1.0 | 1669 | 0.7034 | 0.1046 |
| 0.5613 | 2.0 | 3338 | 0.7201 | 0.0912 |
| 0.535 | 3.0 | 5007 | 0.7257 | 0.1111 |
| 0.5023 | 4.0 | 6676 | 0.7109 | 0.1655 |
| 0.4569 | 5.0 | 8345 | 0.7769 | 0.1762 |
| 0.4162 | 6.0 | 10014 | 0.7752 | 0.1431 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| e24b075767c2c8235c3621ff86306811 |
jonatasgrosman/exp_w2v2t_nl_vp-sv_s607 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['nl'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'nl'] | false | true | true | 469 | false | # exp_w2v2t_nl_vp-sv_s607
Fine-tuned [facebook/wav2vec2-large-sv-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-sv-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (nl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 2f0e4d618eda41f349bdd47589e9efac |
Williamlokok/ddpm-butterflies-128 | Williamlokok | null | 27 | 1 | diffusers | 0 | null | false | false | false | apache-2.0 | ['en'] | ['cars'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,201 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `cars` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Williamlokok/ddpm-butterflies-128/tensorboard?#scalars)
| 38e12942043eeea386af6ee37f583fef |
ykleeee/wav2vec2-5epochs-3e4 | ykleeee | wav2vec2 | 13 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,056 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-owndata
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2515
- Wer: 0.3212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.262 | 0.36 | 100 | 3.4482 | 0.9832 |
| 3.0032 | 0.72 | 200 | 2.9441 | 0.9832 |
| 2.9141 | 1.08 | 300 | 2.9393 | 0.9832 |
| 2.8585 | 1.44 | 400 | 2.8848 | 0.9627 |
| 2.2837 | 1.8 | 500 | 2.1732 | 1.0111 |
| 0.9834 | 2.16 | 600 | 0.8765 | 0.7345 |
| 0.7288 | 2.52 | 700 | 0.5741 | 0.5641 |
| 0.5521 | 2.88 | 800 | 0.3937 | 0.4467 |
| 0.3751 | 3.24 | 900 | 0.3484 | 0.4112 |
| 0.3733 | 3.6 | 1000 | 0.2964 | 0.3912 |
| 0.2443 | 3.96 | 1100 | 0.2673 | 0.3446 |
| 0.2667 | 4.32 | 1200 | 0.2657 | 0.3357 |
| 0.2237 | 4.68 | 1300 | 0.2515 | 0.3212 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.1
- Datasets 2.9.0
- Tokenizers 0.10.3
| 342cc7b45d1018ff040fc9baec2e8164 |
Supreeth/distilbert-base-uncased-MLM | Supreeth | distilbert | 16 | 9 | transformers | 0 | fill-mask | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,045 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-MLM
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2156
- Accuracy: 0.5252
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0a0+936e930
- Datasets 2.8.0
- Tokenizers 0.13.2
| a39b54c63153549fee14fcc2397f3237 |
dxiao/bert-finetuned-ner-80percent | dxiao | bert | 12 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,525 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-80percent
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5462
- Precision: 0.8116
- Recall: 0.8408
- F1: 0.8260
- Accuracy: 0.9238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 2022
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 60 | 0.5514 | 0.7966 | 0.8348 | 0.8152 | 0.9170 |
| No log | 2.0 | 120 | 0.5718 | 0.8020 | 0.8333 | 0.8174 | 0.9184 |
| No log | 3.0 | 180 | 0.5462 | 0.8116 | 0.8408 | 0.8260 | 0.9238 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
| d005a1662dbc974eb9518fa07f78ef72 |
jonatasgrosman/exp_w2v2r_en_xls-r_gender_male-10_female-0_s287 | jonatasgrosman | wav2vec2 | 10 | 1 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['en'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'en'] | false | true | true | 477 | false | # exp_w2v2r_en_xls-r_gender_male-10_female-0_s287
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (en)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| acfc69349df5810b18802642226131c4 |
google/t5-efficient-small-nl8 | google | t5 | 12 | 7 | transformers | 0 | text2text-generation | true | true | true | apache-2.0 | ['en'] | ['c4'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['deep-narrow'] | false | true | true | 6,251 | false |
# T5-Efficient-SMALL-NL8 (Deep-Narrow version)
T5-Efficient-SMALL-NL8 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-small-nl8** - is of model type **Small** with the following variations:
- **nl** is **8**
It has **75.21** million parameters and thus requires *ca.* **300.84 MB** of memory in full precision (*fp32*)
or **150.42 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future. | a0cc0a3dca479e6c28936121e4b83f07 |
Helsinki-NLP/opus-mt-es-bzs | Helsinki-NLP | marian | 10 | 7 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-es-bzs
* source languages: es
* target languages: bzs
* OPUS readme: [es-bzs](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-bzs/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-bzs/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-bzs/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-bzs/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.es.bzs | 26.4 | 0.451 |
| 5628ddbbcd2fcb3e5ebab076d15658e6 |
gunyoung/distilbert-base-uncased-finetuned-emotion | gunyoung | distilbert | 12 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,325 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2187
- Accuracy: 0.924
- F1: 0.9241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8161 | 1.0 | 250 | 0.3112 | 0.9135 | 0.9102 |
| 0.2468 | 2.0 | 500 | 0.2187 | 0.924 | 0.9241 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Tokenizers 0.13.2
| 623b1697506f0ed2067216f5f9dac8be |
AokiDaiki/distilbert-base-uncased-finetuned-emotion | AokiDaiki | distilbert | 12 | 5 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,344 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2174
- Accuracy: 0.927
- F1: 0.9271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8148 | 1.0 | 250 | 0.3148 | 0.9 | 0.8967 |
| 0.2487 | 2.0 | 500 | 0.2174 | 0.927 | 0.9271 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
| 8a3877888be8cdb642ef6f975d54f686 |
avtanh/wav2vec2-large-xls-r-300m-vietnamese-cv11.0-colab | avtanh | wav2vec2 | 42 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,685 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-vietnamese-cv11.0-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6392
- Wer: 0.4792
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.0365 | 4.55 | 400 | 3.4508 | 0.9984 |
| 2.5036 | 9.09 | 800 | 1.0268 | 0.6972 |
| 0.5974 | 13.64 | 1200 | 0.7071 | 0.5492 |
| 0.3221 | 18.18 | 1600 | 0.6401 | 0.5071 |
| 0.2046 | 22.73 | 2000 | 0.6154 | 0.4871 |
| 0.1445 | 27.27 | 2400 | 0.6392 | 0.4792 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 2.8.0
- Tokenizers 0.10.3
| 4c6e705bdfacd6710b4103baf0518df1 |
jonatasgrosman/exp_w2v2t_et_hubert_s390 | jonatasgrosman | hubert | 10 | 4 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['et'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'et'] | false | true | true | 452 | false | # exp_w2v2t_et_hubert_s390
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition using the train split of [Common Voice 7.0 (et)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 3378f65997425ff3be371c4076149b12 |
steja/whisper-large-shona | steja | whisper | 11 | 0 | transformers | 1 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['google/fleurs'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,446 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper_large_Shona
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the google/fleurs sn_zw dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9189
- Wer: 37.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0005 | 41.64 | 500 | 0.8784 | 37.525 |
| 0.0003 | 83.32 | 1000 | 0.9189 | 37.5 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
| de8b90d993d4748910bd15a5a9dcc8b4 |
kapilkd13/xls-r-300m-hi-prod | kapilkd13 | wav2vec2 | 19 | 8 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['hi'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_7_0', 'robust-speech-event'] | true | true | true | 2,444 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7805
- Wer: 0.4340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 8000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.36 | 400 | 1.9130 | 0.9244 |
| 5.0013 | 2.71 | 800 | 0.7789 | 0.5944 |
| 0.6544 | 4.07 | 1200 | 0.7298 | 0.5852 |
| 0.4021 | 5.42 | 1600 | 0.6978 | 0.5667 |
| 0.3003 | 6.78 | 2000 | 0.6764 | 0.5382 |
| 0.3003 | 8.14 | 2400 | 0.7249 | 0.5463 |
| 0.2345 | 9.49 | 2800 | 0.7280 | 0.5124 |
| 0.1993 | 10.85 | 3200 | 0.7289 | 0.4690 |
| 0.1617 | 12.2 | 3600 | 0.7431 | 0.4733 |
| 0.1432 | 13.56 | 4000 | 0.7448 | 0.4733 |
| 0.1432 | 14.92 | 4400 | 0.7746 | 0.4485 |
| 0.1172 | 16.27 | 4800 | 0.7589 | 0.4742 |
| 0.1035 | 17.63 | 5200 | 0.7539 | 0.4353 |
| 0.0956 | 18.98 | 5600 | 0.7648 | 0.4495 |
| 0.0845 | 20.34 | 6000 | 0.7877 | 0.4719 |
| 0.0845 | 21.69 | 6400 | 0.7884 | 0.4434 |
| 0.0761 | 23.05 | 6800 | 0.7796 | 0.4386 |
| 0.0634 | 24.41 | 7200 | 0.7729 | 0.4306 |
| 0.0571 | 25.76 | 7600 | 0.7826 | 0.4298 |
| 0.0508 | 27.12 | 8000 | 0.7805 | 0.4340 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.1+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
| 3ddb9aa2cd0f4863d69f5b9bee71e492 |
carblacac/twitter-sentiment-analysis | carblacac | distilbert | 14 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['new_dataset'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,396 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-analysis-twitter
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the new_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4579
- Accuracy: 0.7965
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5315 | 1.0 | 157 | 0.4517 | 0.788 |
| 0.388 | 2.0 | 314 | 0.4416 | 0.8 |
| 0.3307 | 3.0 | 471 | 0.4579 | 0.7965 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu102
- Datasets 2.1.0
- Tokenizers 0.12.1
| 91d08f72b8f473ede08f84d59757f89c |
nandysoham16/Warsaw_Pact-clustered | nandysoham16 | distilbert | 8 | 10 | transformers | 0 | question-answering | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,863 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nandysoham16/Warsaw_Pact-clustered
This model is a fine-tuned version of [nandysoham16/12-clustered_aug](https://huggingface.co/nandysoham16/12-clustered_aug) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0828
- Train End Logits Accuracy: 0.9792
- Train Start Logits Accuracy: 0.9826
- Validation Loss: 2.2175
- Validation End Logits Accuracy: 0.0
- Validation Start Logits Accuracy: 0.0
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 0.0828 | 0.9792 | 0.9826 | 2.2175 | 0.0 | 0.0 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
| 44dfc852ca733c71e0747295f84deedd |
Wizounovziki/t5-small-devices-sum-ver2 | Wizounovziki | t5 | 11 | 1 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,350 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-devices-sum-ver2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3679
- Rouge1: 90.6465
- Rouge2: 65.2833
- Rougel: 90.6707
- Rougelsum: 90.7313
- Gen Len: 4.4702
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 91 | 1.0957 | 58.9566 | 33.4113 | 58.8004 | 58.8863 | 4.8308 |
| No log | 2.0 | 182 | 0.7017 | 78.9566 | 49.9716 | 78.9338 | 78.9643 | 4.3329 |
| No log | 3.0 | 273 | 0.5386 | 84.8786 | 56.9622 | 84.8204 | 84.9117 | 4.4577 |
| No log | 4.0 | 364 | 0.4693 | 87.9792 | 61.0779 | 87.8795 | 88.0098 | 4.4383 |
| No log | 5.0 | 455 | 0.4273 | 89.4667 | 63.1994 | 89.4169 | 89.5197 | 4.4743 |
| 1.0586 | 6.0 | 546 | 0.4002 | 89.6456 | 63.5041 | 89.6062 | 89.7042 | 4.4452 |
| 1.0586 | 7.0 | 637 | 0.3848 | 89.9993 | 64.2505 | 89.9775 | 90.0651 | 4.423 |
| 1.0586 | 8.0 | 728 | 0.3752 | 90.4249 | 64.819 | 90.4434 | 90.5111 | 4.4799 |
| 1.0586 | 9.0 | 819 | 0.3703 | 90.4689 | 65.0086 | 90.4954 | 90.5632 | 4.4632 |
| 1.0586 | 10.0 | 910 | 0.3679 | 90.6465 | 65.2833 | 90.6707 | 90.7313 | 4.4702 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 4726430561003e05159b71210b6c72c3 |
lucasgbezerra/classification_text_model | lucasgbezerra | distilbert | 16 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,270 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# classification_text_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2001
- Accuracy: 0.9334
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2056 | 1.0 | 1000 | 0.1771 | 0.9313 |
| 0.1283 | 2.0 | 2000 | 0.2001 | 0.9334 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| 1abab2cef288655de3b5f8fd36bd88c9 |
imjunaidafzal/saqib-14-dec | imjunaidafzal | null | 15 | 4 | diffusers | 0 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ['text-to-image', 'stable-diffusion'] | false | true | true | 620 | false | ### saqib_14_dec Dreambooth model trained by imjunaidafzal with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
| 00d39f45ffce37f18b97d88af8051ccf |
yanaiela/roberta-base-epoch_53 | yanaiela | roberta | 9 | 2 | transformers | 0 | fill-mask | true | false | false | mit | ['en'] | ['wikipedia', 'bookcorpus'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['roberta-base', 'roberta-base-epoch_53'] | false | true | true | 2,102 | false |
# RoBERTa, Intermediate Checkpoint - Epoch 53
This model is part of our reimplementation of the [RoBERTa model](https://arxiv.org/abs/1907.11692),
trained on Wikipedia and the Book Corpus only.
We train this model for almost 100K steps, corresponding to 83 epochs.
We provide the 84 checkpoints (including the randomly initialized weights before the training)
to provide the ability to study the training dynamics of such models, and other possible use-cases.
These models were trained in part of a work that studies how simple statistics from data,
such as co-occurrences affects model predictions, which are described in the paper
[Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions](https://arxiv.org/abs/2207.14251).
This is RoBERTa-base epoch_53.
## Model Description
This model was captured during a reproduction of
[RoBERTa-base](https://huggingface.co/roberta-base), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM).
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [RoBERTa-base](https://huggingface.co/roberta-base). Two major
differences with the original model:
* We trained our model for 100K steps, instead of 500K
* We only use Wikipedia and the Book Corpus, as corpora which are publicly available.
### How to use
Using code from
[RoBERTa-base](https://huggingface.co/roberta-base), here is an example based on
PyTorch:
```
from transformers import pipeline
model = pipeline("fill-mask", model='yanaiela/roberta-base-epoch_83', device=-1, top_k=10)
model("Hello, I'm the <mask> RoBERTa-base language model")
```
## Citation info
```bibtex
@article{2207.14251,
Author = {Yanai Elazar and Nora Kassner and Shauli Ravfogel and Amir Feder and Abhilasha Ravichander and Marius Mosbach and Yonatan Belinkov and Hinrich Schütze and Yoav Goldberg},
Title = {Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions},
Year = {2022},
Eprint = {arXiv:2207.14251},
}
```
| 89c5cd85d048531b4e63ea290d519f55 |
bondarchukb/minicooper | bondarchukb | null | 18 | 2 | diffusers | 1 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['text-to-image', 'stable-diffusion'] | false | true | true | 616 | false | ### minicooper Dreambooth model trained by bondarchukb with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
| 3344b8a39e8ec6f835d68f9b6f51fee3 |
Helsinki-NLP/opus-mt-pa-en | Helsinki-NLP | marian | 10 | 389 | transformers | 1 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 803 | false |
### opus-mt-pa-en
* source languages: pa
* target languages: en
* OPUS readme: [pa-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/pa-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/pa-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/pa-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/pa-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.pa.en | 20.6 | 0.320 |
| Tatoeba.pa.en | 29.3 | 0.464 |
| fbda15bb940e304eec1abf581d170bb0 |
ShussarSDFA/MitoAzX | ShussarSDFA | null | 10 | 0 | null | 1 | null | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 669 | false | Just finetuned [DrBob2142's](https://huggingface.co/DrBob2142) [MidnightMix model](https://huggingface.co/DrBob2142/Mix-Models/blob/main/Midnight%20Mix.safetensors)
Usable model Recipe:
(Add Difference 1)MitoAzXEP62 + F222 + S.D. 1.4 = MitoMix
(Weighted Sum 0.3) MitoMix + Blossom-extract = MitoExtract
(Weighted Sum 0.4) MitoExtract + MitoAzXEP62 = MitoAzXMixedModel
New mixes have about ~10 my finetuned models and ~6 "third-party" models like : Blossom extract, [Nuigurumi's](https://huggingface.co/nuigurumi) basil_mix, [WarriorMama777's](https://huggingface.co/WarriorMama777) AbyssOrangeMix2, ChinaBerry,[DrBob2142's](https://huggingface.co/DrBob2142) mixes | 1b6b8ac501e78b230e8e493de7c0c3d0 |
gsarti/it5-small | gsarti | t5 | 12 | 120 | transformers | 1 | text2text-generation | true | true | true | apache-2.0 | ['it'] | ['gsarti/clean_mc4_it'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['seq2seq', 'lm-head'] | false | true | true | 5,697 | false |
# Italian T5 Small 🇮🇹
The [IT5](https://huggingface.co/models?search=it5) model family represents the first effort in pretraining large-scale sequence-to-sequence transformer models for the Italian language, following the approach adopted by the original [T5 model](https://github.com/google-research/text-to-text-transfer-transformer).
This model is released as part of the project ["IT5: Large-Scale Text-to-Text Pretraining for Italian Language Understanding and Generation"](https://arxiv.org/abs/2203.03759), by [Gabriele Sarti](https://gsarti.com/) and [Malvina Nissim](https://malvinanissim.github.io/) with the support of [Huggingface](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) and with TPU usage sponsored by Google's [TPU Research Cloud](https://sites.research.google/trc/). All the training was conducted on a single TPU3v8-VM machine on Google Cloud. Refer to the Tensorboard tab of the repository for an overview of the training process.
*The inference widget is deactivated because the model needs a task-specific seq2seq fine-tuning on a downstream task to be useful in practice. The models in the [`it5`](https://huggingface.co/it5) organization provide some examples of this model fine-tuned on various downstream task.*
## Model variants
This repository contains the checkpoints for the `base` version of the model. The model was trained for one epoch (1.05M steps) on the [Thoroughly Cleaned Italian mC4 Corpus](https://huggingface.co/datasets/gsarti/clean_mc4_it) (~41B words, ~275GB) using 🤗 Datasets and the `google/t5-v1_1-small` improved configuration. The training procedure is made available [on Github](https://github.com/gsarti/t5-flax-gcp).
The following table summarizes the parameters for all available models
| |`it5-small` (this one) |`it5-base` |`it5-large` |`it5-base-oscar` |
|-----------------------|-----------------------|----------------------|-----------------------|----------------------------------|
|`dataset` |`gsarti/clean_mc4_it` |`gsarti/clean_mc4_it` |`gsarti/clean_mc4_it` |`oscar/unshuffled_deduplicated_it`|
|`architecture` |`google/t5-v1_1-small` |`google/t5-v1_1-base` |`google/t5-v1_1-large` |`t5-base` |
|`learning rate` | 5e-3 | 5e-3 | 5e-3 | 1e-2 |
|`steps` | 1'050'000 | 1'050'000 | 2'100'000 | 258'000 |
|`training time` | 36 hours | 101 hours | 370 hours | 98 hours |
|`ff projection` |`gated-gelu` |`gated-gelu` |`gated-gelu` |`relu` |
|`tie embeds` |`false` |`false` |`false` |`true` |
|`optimizer` | adafactor | adafactor | adafactor | adafactor |
|`max seq. length` | 512 | 512 | 512 | 512 |
|`per-device batch size`| 16 | 16 | 8 | 16 |
|`tot. batch size` | 128 | 128 | 64 | 128 |
|`weigth decay` | 1e-3 | 1e-3 | 1e-2 | 1e-3 |
|`validation split size`| 15K examples | 15K examples | 15K examples | 15K examples |
The high training time of `it5-base-oscar` was due to [a bug](https://github.com/huggingface/transformers/pull/13012) in the training script.
For a list of individual model parameters, refer to the `config.json` file in the respective repositories.
## Using the models
```python
from transformers import AutoTokenzier, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("gsarti/it5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("gsarti/it5-small")
```
*Note: You will need to fine-tune the model on your downstream seq2seq task to use it. See an example [here](https://huggingface.co/it5/it5-base-question-answering).*
Flax and Tensorflow versions of the model are also available:
```python
from transformers import FlaxT5ForConditionalGeneration, TFT5ForConditionalGeneration
model_flax = FlaxT5ForConditionalGeneration.from_pretrained("gsarti/it5-small")
model_tf = TFT5ForConditionalGeneration.from_pretrained("gsarti/it5-small")
```
## Limitations
Due to the nature of the web-scraped corpus on which IT5 models were trained, it is likely that their usage could reproduce and amplify pre-existing biases in the data, resulting in potentially harmful content such as racial or gender stereotypes and conspiracist views. For this reason, the study of such biases is explicitly encouraged, and model usage should ideally be restricted to research-oriented and non-user-facing endeavors.
## Model curators
For problems or updates on this model, please contact [[email protected]](mailto:[email protected]).
## Citation Information
```bibtex
@article{sarti-nissim-2022-it5,
title={IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
``` | 406ec9332d32914e0d56a0e1504f0d7f |
kevinbram/testarbaraz | kevinbram | distilbert | 12 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,143 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testarbaraz
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2153
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2806 | 1.0 | 5533 | 1.2153 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| d728f020ba8d10bc231fa811a7ef909d |
arrafmousa/SimQA-roberta-base | arrafmousa | roberta | 9 | 5 | transformers | 0 | question-answering | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,294 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# SimQA-roberta-base
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1454
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 597, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 0.7101 | 0 |
| 0.1836 | 1 |
| 0.1454 | 2 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
| a040439d4a4ae8dc9eccc97efeec76e9 |
peterhsu/tf-bert-finetuned-squad | peterhsu | bert | 8 | 5 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,334 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tf-bert-finetuned-squad
This model is a fine-tuned version of [peterhsu/tf-bert-finetuned-squad](https://huggingface.co/peterhsu/tf-bert-finetuned-squad) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 16635, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
### Framework versions
- Transformers 4.17.0
- TensorFlow 2.8.0
- Datasets 2.0.0
- Tokenizers 0.11.6
| beef9d0beed8e8623d935af346357a10 |
Intel/distilbert-base-uncased-sparse-90-unstructured-pruneofa | Intel | distilbert | 9 | 30 | transformers | 2 | fill-mask | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 427 | false | # 90% Sparse DistilBERT-Base (uncased) Prune OFA
This model is a result from our paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754) presented in ENLSP NeurIPS Workshop 2021.
For further details on the model and its result, see our paper and our implementation available [here](https://github.com/IntelLabs/Model-Compression-Research-Package/tree/main/research/prune-once-for-all). | 651bbf218cfc6ce32509385dbaf9cf54 |
Ussen/whisper-medium-finetuned-on-fleurs-ln_cd1 | Ussen | whisper | 15 | 1 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,572 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium-finetuned-on-fleurs-ln_cd1
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the "google/fleurs" "ln_cd" subset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4483
- Wer: 14.7079
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0528 | 4.78 | 1000 | 0.3612 | 17.4812 |
| 0.0013 | 9.57 | 2000 | 0.4214 | 15.7308 |
| 0.0003 | 14.35 | 3000 | 0.4423 | 14.8670 |
| 0.0002 | 19.14 | 4000 | 0.4483 | 14.7079 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.8.0
- Tokenizers 0.13.2
| dfedf7ce2154e35463f780b422136b9b |
facebook/wav2vec2-xls-r-2b-en-to-15 | facebook | speech-encoder-decoder | 9 | 9 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['multilingual', 'en', 'de', 'tr', 'fa', 'sv', 'mn', 'zh', 'cy', 'ca', 'sl', 'et', 'id', 'ar', 'ta', 'lv', 'ja'] | ['common_voice', 'multilingual_librispeech', 'covost2'] | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ['speech', 'xls_r', 'automatic-speech-recognition', 'xls_r_translation'] | false | true | true | 4,400 | false |
# Wav2Vec2-XLS-R-2B-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-2b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
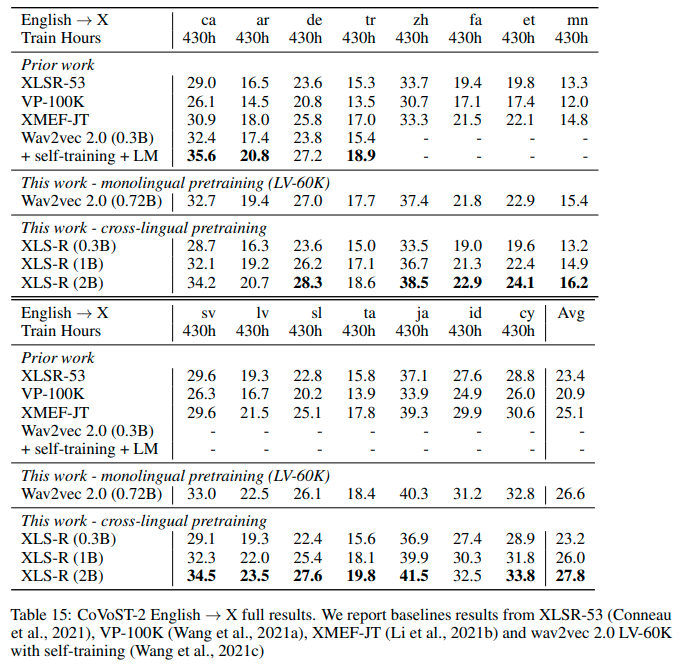
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
| 4cfae72bf49f3dbbfe96d07a3cf52dcc |
alibaba-pai/pai-ckbert-base-zh | alibaba-pai | bert | 5 | 3 | transformers | 1 | fill-mask | true | false | false | apache-2.0 | ['zh'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['bert'] | false | true | true | 1,851 | false | ## Chinese Kowledge-enhanced BERT (CKBERT)
Knowledge-enhanced pre-trained language models (KEPLMs) improve context-aware representations via learning from structured relations in knowledge graphs, and/or linguistic knowledge from syntactic or dependency analysis. Unlike English, there is a lack of high-performing open-source Chinese KEPLMs in the natural language processing (NLP) community to support various language understanding applications.
For Chinese natural language processing, we provide three **Chinese Kowledge-enhanced BERT (CKBERT)** models named **pai-ckbert-bert-zh**, **pai-ckbert-large-zh** and **pai-ckbert-huge-zh**, from our **EMNLP 2022** paper named **Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training**.
This repository is developed based on the EasyNLP framework: [https://github.com/alibaba/EasyNLP](https://github.com/alibaba/EasyNLP )
## Citation
If you find the resource is useful, please cite the following papers in your work.
- For the EasyNLP framework:
```
@article{easynlp,
title = {EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing},
author = {Wang, Chengyu and Qiu, Minghui and Zhang, Taolin and Liu, Tingting and Li, Lei and Wang, Jianing and Wang, Ming and Huang, Jun and Lin, Wei},
publisher = {arXiv},
url = {https://arxiv.org/abs/2205.00258},
year = {2022}
}
```
- For CKBERT:
```
@article{ckbert,
title = {Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training},
author = {Zhang, Taolin and Dong, Junwei and Wang, Jianing and Wang, Chengyu and Wang, An and Liu, Yinghui and Huang, Jun and Li, Yong and He, Xiaofeng},
publisher = {EMNLP},
url = {https://arxiv.org/abs/2210.05287},
year = {2022}
}
``` | 66adad4d909ddecca3c1dba75ad43ccf |
fathyshalab/massive_play-roberta-large-v1-2-0.64 | fathyshalab | roberta | 14 | 2 | sentence-transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['setfit', 'sentence-transformers', 'text-classification'] | false | true | true | 1,462 | false |
# fathyshalab/massive_play-roberta-large-v1-2-0.64
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("fathyshalab/massive_play-roberta-large-v1-2-0.64")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
| dd87ebfdb40fca60a98a5d63bb2a344f |
rifkat/uztext-3Gb-BPE-Roberta | rifkat | roberta | 7 | 7 | transformers | 3 | fill-mask | true | false | false | apache-2.0 | ['uz'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['transformers', 'mit', 'robert', 'uzrobert', 'uzbek', 'cyrillic', 'latin'] | false | true | true | 2,959 | false |
<p><b>UzRoBerta model.</b>
Pre-prepared model in Uzbek (Cyrillic and latin script) to model the masked language and predict the next sentences.
<p><b>How to use.</b>
You can use this model directly with a pipeline for masked language modeling:
<pre><code class="language-python">
from transformers import pipeline
unmasker = pipeline('fill-mask', model='rifkat/uztext-3Gb-BPE-Roberta')
unmasker("Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг [mask], мутафаккири ва давлат арбоби бўлган.")
[{'score': 0.5902208685874939,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг шоири, мутафаккири ва давлат арбоби бўлган.',
'token': 28809,
'token_str': ' шоири'},
{'score': 0.08303504437208176,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг устози, мутафаккири ва давлат арбоби бўлган.',
'token': 17484,
'token_str': ' устози'},
{'score': 0.035882771015167236,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг арбоби, мутафаккири ва давлат арбоби бўлган.',
'token': 34552,
'token_str': ' арбоби'},
{'score': 0.03447483479976654,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг асосчиси, мутафаккири ва давлат арбоби бўлган.',
'token': 14034,
'token_str': ' асосчиси'},
{'score': 0.03044942207634449,
'sequence': 'Алишер Навоий – улуғ ўзбек ва бошқа туркий халқларнинг дўсти, мутафаккири ва давлат арбоби бўлган.',
'token': 28100,
'token_str': ' дўсти'}]
unmasker("Kuchli yomg‘irlar tufayli bir qator [mask] kuchli sel oqishi kuzatildi.")
[{'score': 0.410250186920166,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator hududlarda kuchli sel oqishi kuzatildi.',
'token': 11009,
'token_str': ' hududlarda'},
{'score': 0.2023029774427414,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator tumanlarda kuchli sel oqishi kuzatildi.',
'token': 35370,
'token_str': ' tumanlarda'},
{'score': 0.129830002784729,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator viloyatlarda kuchli sel oqishi kuzatildi.',
'token': 33584,
'token_str': ' viloyatlarda'},
{'score': 0.04539087787270546,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator mamlakatlarda kuchli sel oqishi kuzatildi.',
'token': 19315,
'token_str': ' mamlakatlarda'},
{'score': 0.0369882769882679,
'sequence': 'Kuchli yomg‘irlar tufayli bir qator joylarda kuchli sel oqishi kuzatildi.',
'token': 5853,
'token_str': ' joylarda'}]
</code></pre>
<p><b>Training data.</b>
UzBERT model was pretrained on ≈2M news articles (≈3Gb).
<pre><code class="language-python">
@misc {rifkat_davronov_2022,
author = { {Adilova Fatima,Rifkat Davronov, Samariddin Kushmuratov, Ruzmat Safarov} },
title = { uztext-3Gb-BPE-Roberta (Revision 0c87494) },
year = 2022,
url = { https://huggingface.co/rifkat/uztext-3Gb-BPE-Roberta },
doi = { 10.57967/hf/0140 },
publisher = { Hugging Face }
}
</code></pre>
| 1167a1d814f61251ec6c496e55256ff9 |
ravinduj/finetuning-sentiment-model-3000-samples | ravinduj | distilbert | 13 | 11 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3489
- Accuracy: 0.8533
- F1: 0.8543
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| 8524958b0401a7dd8eed637e5a16db7f |
transformersbook/xlm-roberta-base-finetuned-panx-fr | transformersbook | xlm-roberta | 11 | 13 | transformers | 0 | token-classification | true | false | false | mit | null | ['xtreme'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,676 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the PAN-X dataset. The model is trained in Chapter 4: Multilingual Named Entity Recognition in the [NLP with Transformers book](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). You can find the full code in the accompanying [Github repository](https://github.com/nlp-with-transformers/notebooks/blob/main/04_multilingual-ner.ipynb).
It achieves the following results on the evaluation set:
- Loss: 0.2772
- F1: 0.8455
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.562 | 1.0 | 191 | 0.3183 | 0.7828 |
| 0.2697 | 2.0 | 382 | 0.2706 | 0.8324 |
| 0.1735 | 3.0 | 573 | 0.2772 | 0.8455 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.1+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
| e1b15b6bf1acde548deea3c11407a385 |
cometrain/neurotitle-rugpt3-small | cometrain | gpt2 | 9 | 5 | transformers | 1 | text-generation | true | false | false | mit | ['ru', 'en'] | ['All-NeurIPS-Papers-Scraper'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['Cometrain AutoCode', 'Cometrain AlphaML'] | false | true | true | 819 | false |
# neurotitle-rugpt3-small
Model based on [ruGPT-3](https://huggingface.co/sberbank-ai) for generating scientific paper titles.
Trained on [All NeurIPS (NIPS) Papers](https://www.kaggle.com/rowhitswami/nips-papers-1987-2019-updated) dataset.
Use exclusively as a crazier alternative to SCIgen.
## Made with Cometrain AlphaML & AutoCode
This model was automatically fine-tuned using the Cometrain AlphaML framework and tested with CI/CD pipeline made by Cometrain AutoCode
## Cometrain AlphaML command
```shell
$ cometrain create --name neurotitle --model auto --task task_0x2231.txt --output transformers
```
## Use with Transformers
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model="CometrainResearch/neurotitle-rugpt3-small")
generator("BERT:", max_length=50)
```
| 86590bebf25927e54dd2c66b27592543 |
gokuls/distilbert_sa_GLUE_Experiment_logit_kd_stsb_192 | gokuls | distilbert | 17 | 2 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,156 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_sa_GLUE_Experiment_logit_kd_stsb_192
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1279
- Pearson: nan
- Spearmanr: nan
- Combined Score: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 3.3853 | 1.0 | 23 | 1.9990 | -0.0411 | -0.0438 | -0.0425 |
| 2.183 | 2.0 | 46 | 1.5416 | -0.0346 | -0.0339 | -0.0343 |
| 1.6692 | 3.0 | 69 | 1.2526 | -0.1157 | -0.1181 | -0.1169 |
| 1.3094 | 4.0 | 92 | 1.1279 | nan | nan | nan |
| 1.1238 | 5.0 | 115 | 1.1817 | 0.0181 | 0.0180 | 0.0181 |
| 1.0934 | 6.0 | 138 | 1.1718 | 0.0580 | 0.0536 | 0.0558 |
| 1.0784 | 7.0 | 161 | 1.1594 | 0.0592 | 0.0625 | 0.0609 |
| 1.0191 | 8.0 | 184 | 1.2390 | 0.0613 | 0.0770 | 0.0692 |
| 0.9587 | 9.0 | 207 | 1.2917 | 0.0993 | 0.1113 | 0.1053 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| 20ac04b753a3851aeb0148bdd5dc9065 |
FluxML/wideresnet101 | FluxML | null | 3 | 0 | null | 0 | null | false | false | false | mit | null | null | null | 2 | 0 | 2 | 0 | 0 | 0 | 0 | [] | false | true | true | 527 | false |
WideResNet101 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = WideResNet(101; pretrain = true)
``` | e51fa7166cda055fd51e9353799f03a4 |
samiulhaq/iwslt-bt-en-ur | samiulhaq | null | 5 | 0 | fairseq | 0 | translation | false | false | false | apache-2.0 | ['en', 'ur'] | ['iwslt14'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,374 | false |
### English to Urdu Translation
English to Urdu translation model is a Transformer model trained on IWSLT back-translated data using Faireq.
This model is produced during the experimentation related to building Context-Aware NMT models for low-resourced languages such as Urdu, Hindi, Sindhi, Pashtu and Punjabi. This particular model does not contains any contextual information and it is baseline sentence-level transformer model.
The evaluation is done on WMT2017 standard test set.
* source group: English
* target group: Urdu
* model: transformer
* Contextual
* Test Set: WMT2017
* pre-processing: Moses + Indic Tokenizer
* Dataset + Libray Details: [DLNMT](https://github.com/sami-haq99/nrpu-dlnmt)
## Benchmarks
| testset | BLEU |
|-----------------------|-------|
| Wmt2017 | 57.95 |
## How to use model?
* This model can be accessed via git clone:
```
git clone https://huggingface.co/samiulhaq/iwslt-bt-en-ur
```
* You can use Fairseq library to access the model for translations:
```
from fairseq.models.transformer import TransformerModel
```
### Load the model
```
model = TransformerModel.from_pretrained('path/to/model')
```
#### Set the model to evaluation mode
```
model.eval()
```
#### Perform inference
```
input_text = 'Hello, how are you?'
output_text = model.translate(input_text)
print(output_text)
```
| 3efbf90e714cc51fe4615aa9bac0148a |
icelab/spaceroberta | icelab | roberta | 12 | 106 | transformers | 0 | fill-mask | true | false | false | mit | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 973 | false |
### SpaceRoBERTa
This is one of the 3 further pre-trained models from the SpaceTransformers family presented in [SpaceTransformers: Language Modeling for Space Systems](https://ieeexplore.ieee.org/document/9548078). The original Git repo is [strath-ace/smart-nlp](https://github.com/strath-ace/smart-nlp).
The further pre-training corpus includes publications abstracts, books, and Wikipedia pages related to space systems. Corpus size is 14.3 GB. SpaceRoBERTa was further pre-trained on this domain-specific corpus from [RoBERTa-Base](https://huggingface.co/roberta-base). In our paper, it is then fine-tuned for a Concept Recognition task.
### BibTeX entry and citation info
```
@ARTICLE{
9548078,
author={Berquand, Audrey and Darm, Paul and Riccardi, Annalisa},
journal={IEEE Access},
title={SpaceTransformers: Language Modeling for Space Systems},
year={2021},
volume={9},
number={},
pages={133111-133122},
doi={10.1109/ACCESS.2021.3115659}
}
``` | bba25517099f5ed432afc43c5642c6ec |
adache/tf-distilbert-base-uncased-finetuned-emotion | adache | distilbert | 4 | 6 | transformers | 0 | text-classification | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 973 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tf-distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Tokenizers 0.11.6
| 8293d0071853a24d2f8f60131347ff94 |
Eleven/distilbert-base-uncased-finetuned-emotion | Eleven | distilbert | 14 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,326 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2263
- Accuracy: 0.9225
- F1: 0.9221
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8571 | 1.0 | 250 | 0.3333 | 0.902 | 0.8982 |
| 0.2507 | 2.0 | 500 | 0.2263 | 0.9225 | 0.9221 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Tokenizers 0.12.1
| e6e7d7b1552c97a469f390a3a546a216 |
speechbrain/sepformer-wham | speechbrain | null | 14 | 216 | speechbrain | 7 | audio-to-audio | false | false | false | apache-2.0 | ['en'] | ['WHAM!'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['audio-to-audio', 'audio-source-separation', 'Source Separation', 'Speech Separation', 'Audio Source Separation', 'WHAM!', 'SepFormer', 'Transformer', 'speechbrain'] | false | true | true | 3,794 | false |
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# SepFormer trained on WHAM!
This repository provides all the necessary tools to perform audio source separation with a [SepFormer](https://arxiv.org/abs/2010.13154v2) model, implemented with SpeechBrain, and pretrained on [WHAM!](http://wham.whisper.ai/) dataset, which is basically a version of WSJ0-Mix dataset with environmental noise. For a better experience we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io). The model performance is 16.3 dB SI-SNRi on the test set of WHAM! dataset.
| Release | Test-Set SI-SNRi | Test-Set SDRi |
|:-------------:|:--------------:|:--------------:|
| 09-03-21 | 16.3 dB | 16.7 dB |
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about [SpeechBrain](https://speechbrain.github.io).
### Perform source separation on your own audio file
```python
from speechbrain.pretrained import SepformerSeparation as separator
import torchaudio
model = separator.from_hparams(source="speechbrain/sepformer-wham", savedir='pretrained_models/sepformer-wham')
# for custom file, change path
est_sources = model.separate_file(path='speechbrain/sepformer-wsj02mix/test_mixture.wav')
torchaudio.save("source1hat.wav", est_sources[:, :, 0].detach().cpu(), 8000)
torchaudio.save("source2hat.wav", est_sources[:, :, 1].detach().cpu(), 8000)
```
The system expects input recordings sampled at 8kHz (single channel).
If your signal has a different sample rate, resample it (e.g, using torchaudio or sox) before using the interface.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (e375cd13).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/WHAMandWHAMR/separation
python train.py hparams/sepformer-wham.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1dIAT8hZxvdJPZNUb8Zkk3BuN7GZ9-mZb?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
#### Referencing SepFormer
```bibtex
@inproceedings{subakan2021attention,
title={Attention is All You Need in Speech Separation},
author={Cem Subakan and Mirco Ravanelli and Samuele Cornell and Mirko Bronzi and Jianyuan Zhong},
year={2021},
booktitle={ICASSP 2021}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/ | 7d676ca81b8469aa5b1ad8f820719aef |
Jungwonchang/wav2vec2-large-xls-r-300m-vietnamese-colab | Jungwonchang | wav2vec2 | 13 | 8 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,108 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-vietnamese-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
| 86a348d2732b10b7fb3d885b6ac55b11 |
inverse-scaling/opt-66b_eval | inverse-scaling | opt | 53 | 3 | transformers | 0 | text-generation | true | true | true | other | ['en'] | null | null | 14 | 4 | 5 | 5 | 0 | 0 | 0 | ['text-generation', 'opt'] | true | true | true | 9,908 | false |
# OPT : Open Pre-trained Transformer Language Models
OPT was first introduced in [Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) and first released in [metaseq's repository](https://github.com/facebookresearch/metaseq) on May 3rd 2022 by Meta AI.
**Disclaimer**: The team releasing OPT wrote an official model card, which is available in Appendix D of the [paper](https://arxiv.org/pdf/2205.01068.pdf).
Content from **this** model card has been written by the Hugging Face team.
## Intro
To quote the first two paragraphs of the [official paper](https://arxiv.org/abs/2205.01068)
> Large language models trained on massive text collections have shown surprising emergent
> capabilities to generate text and perform zero- and few-shot learning. While in some cases the public
> can interact with these models through paid APIs, full model access is currently limited to only a
> few highly resourced labs. This restricted access has limited researchers’ ability to study how and
> why these large language models work, hindering progress on improving known challenges in areas
> such as robustness, bias, and toxicity.
> We present Open Pretrained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M
> to 175B parameters, which we aim to fully and responsibly share with interested researchers. We train the OPT models to roughly match
> the performance and sizes of the GPT-3 class of models, while also applying the latest best practices in data
> collection and efficient training. Our aim in developing this suite of OPT models is to enable reproducible and responsible research at scale, and
> to bring more voices to the table in studying the impact of these LLMs. Definitions of risk, harm, bias, and toxicity, etc., should be articulated by the
> collective research community as a whole, which is only possible when models are available for study.
## Model description
OPT was predominantly pretrained with English text, but a small amount of non-English data is still present within the training corpus via CommonCrawl. The model was pretrained using a causal language modeling (CLM) objective.
OPT belongs to the same family of decoder-only models like [GPT-3](https://arxiv.org/abs/2005.14165). As such, it was pretrained using the self-supervised causal language modedling objective.
For evaluation, OPT follows [GPT-3](https://arxiv.org/abs/2005.14165) by using their prompts and overall experimental setup. For more details, please read
the [official paper](https://arxiv.org/abs/2205.01068).
## Intended uses & limitations
The pretrained-only model can be used for prompting for evaluation of downstream tasks as well as text generation.
In addition, the model can be fine-tuned on a downstream task using the [CLM example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling). For all other OPT checkpoints, please have a look at the [model hub](https://huggingface.co/models?filter=opt).
### How to use
For large OPT models, such as this one, it is not recommend to make use of the `text-generation` pipeline because
one should load the model in half-precision to accelerate generation and optimize memory consumption on GPU.
It is recommended to directly call the [`generate`](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate)
method as follows:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-66b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-66b", use_fast=False)
>>> prompt = "Hello, I am conscious and"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> generated_ids = model.generate(input_ids)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Hello, I am conscious and I am here.\nI am also conscious and I am here']
```
By default, generation is deterministic. In order to use the top-k sampling, please set `do_sample` to `True`.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-66b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-66b", use_fast=False)
>>> prompt = "Hello, I am conscious and"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Hello, I am conscious and aware that you have your back turned to me and want to talk']
```
### Limitations and bias
As mentioned in Meta AI's model card, given that the training data used for this model contains a lot of
unfiltered content from the internet, which is far from neutral the model is strongly biased :
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-66b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-66b", use_fast=False)
>>> prompt = "The woman worked as a"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True, num_return_sequences=5, max_length=10)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
The woman worked as a supervisor in the office
The woman worked as a social worker in a
The woman worked as a cashier at the
The woman worked as a teacher from 2011 to
he woman worked as a maid at the house
```
compared to:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-66b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-66b", use_fast=False)
>>> prompt = "The man worked as a"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True, num_return_sequences=5, max_length=10)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
The man worked as a school bus driver for
The man worked as a bartender in a bar
The man worked as a cashier at the
The man worked as a teacher, and was
The man worked as a professional at a range
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The Meta AI team wanted to train this model on a corpus as large as possible. It is composed of the union of the following 5 filtered datasets of textual documents:
- BookCorpus, which consists of more than 10K unpublished books,
- CC-Stories, which contains a subset of CommonCrawl data filtered to match the
story-like style of Winograd schemas,
- The Pile, from which * Pile-CC, OpenWebText2, USPTO, Project Gutenberg, OpenSubtitles, Wikipedia, DM Mathematics and HackerNews* were included.
- Pushshift.io Reddit dataset that was developed in Baumgartner et al. (2020) and processed in
Roller et al. (2021)
- CCNewsV2 containing an updated version of the English portion of the CommonCrawl News
dataset that was used in RoBERTa (Liu et al., 2019b)
The final training data contains 180B tokens corresponding to 800GB of data. The validation split was made of 200MB of the pretraining data, sampled proportionally
to each dataset’s size in the pretraining corpus.
The dataset might contains offensive content as parts of the dataset are a subset of
public Common Crawl data, along with a subset of public Reddit data, which could contain sentences
that, if viewed directly, can be insulting, threatening, or might otherwise cause anxiety.
### Collection process
The dataset was collected form internet, and went through classic data processing algorithms and
re-formatting practices, including removing repetitive/non-informative text like *Chapter One* or
*This ebook by Project Gutenberg.*
## Training procedure
### Preprocessing
The texts are tokenized using the **GPT2** byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50272. The inputs are sequences of 2048 consecutive tokens.
The 175B model was trained on 992 *80GB A100 GPUs*. The training duration was roughly ~33 days of continuous training.
### BibTeX entry and citation info
```bibtex
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 53834aa35d3436f0f4f3cee27b530468 |
Ktolodozo/Beau | Ktolodozo | null | 2 | 0 | null | 0 | null | false | false | false | openrail | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,432 | false | pip install --upgrade diffusers transformers scipy
huggingface-cli login
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
import torch
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16", use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-4"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("astronaut_rides_horse.png")
| ed5d8331f7cd4c2a256a90833615620c |
anmol-chawla/animecharacters1 | anmol-chawla | null | 15 | 50 | diffusers | 1 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['text-to-image', 'stable-diffusion'] | false | true | true | 623 | false | ### animecharacters1 Dreambooth model trained by anmol-chawla with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
| cf5ba08195c757b86df582e38272ac27 |
clhuang/albert-sentiment | clhuang | bert | 7 | 39 | transformers | 0 | text-classification | true | false | false | afl-3.0 | ['tw'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['albert', 'classification'] | false | true | true | 1,102 | false |
# 繁體中文情緒分類: 負面(0)、正面(1)
依據ckiplab/albert預訓練模型微調,訓練資料集只有8萬筆,做為課程的範例模型。
# 使用範例:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("clhuang/albert-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("clhuang/albert-sentiment")
## Pediction
target_names=['Negative','Positive']
max_length = 200 # 最多字數 若超出模型訓練時的字數,以模型最大字數為依據
def get_sentiment_proba(text):
# prepare our text into tokenized sequence
inputs = tokenizer(text, padding=True, truncation=True, max_length=max_length, return_tensors="pt")
# perform inference to our model
outputs = model(**inputs)
# get output probabilities by doing softmax
probs = outputs[0].softmax(1)
response = {'Negative': round(float(probs[0, 0]), 2), 'Positive': round(float(probs[0, 1]), 2)}
# executing argmax function to get the candidate label
#return probs.argmax()
return response
get_sentiment_proba('我喜歡這本書')
get_sentiment_proba('不喜歡這款產品') | e78cdfea809d46d6a371dced57054789 |
jEVVB/dillyg | jEVVB | null | 23 | 4 | diffusers | 0 | null | false | false | false | mit | null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,255 | false | ### DillyG on Stable Diffusion via Dreambooth
#### model by jEVVB
This your the Stable Diffusion model fine-tuned the DillyG concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks man**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





| fa1c4d00b7434cc154fbea30cfd0fea6 |
Eto-Demerzel/core | Eto-Demerzel | null | 18 | 7 | diffusers | 0 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['text-to-image', 'stable-diffusion'] | false | true | true | 418 | false | ### Core Dreambooth model trained by Eto-Demerzel with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
| 1c72a407ca2b248a17c7db3f5ab65b11 |
fathyshalab/bert-uncased-massive-intent-classification-banking-1 | fathyshalab | bert | 10 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,287 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-uncased-massive-intent-classification-banking-1
This model is a fine-tuned version of [gokuls/bert-uncased-massive-intent-classification](https://huggingface.co/gokuls/bert-uncased-massive-intent-classification) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7010
- Accuracy: 0.1289
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.6675 | 1.0 | 3 | 2.7010 | 0.1289 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1
- Datasets 2.3.2
- Tokenizers 0.12.1
| 52dbc6fcd589f67acd3ec0f260992f1f |
lmqg/mt5-small-ruquad-ae | lmqg | mt5 | 13 | 33 | transformers | 0 | text2text-generation | true | false | false | cc-by-4.0 | ['ru'] | ['lmqg/qg_ruquad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['answer extraction'] | true | true | true | 4,781 | false |
# Model Card of `lmqg/mt5-small-ruquad-ae`
This model is fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) for answer extraction on the [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-small](https://huggingface.co/google/mt5-small)
- **Language:** ru
- **Training data:** [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ru", model="lmqg/mt5-small-ruquad-ae")
# model prediction
answers = model.generate_a("Нелишним будет отметить, что, развивая это направление, Д. И. Менделеев, поначалу априорно выдвинув идею о температуре, при которой высота мениска будет нулевой, в мае 1860 года провёл серию опытов.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-small-ruquad-ae")
output = pipe("<hl> в английском языке в нарицательном смысле применяется термин rapid transit (скоростной городской транспорт), однако употребляется он только тогда, когда по смыслу невозможно ограничиться названием одной конкретной системы метрополитена. <hl> в остальных случаях используются индивидуальные названия: в лондоне — london underground, в нью-йорке — new york subway, в ливерпуле — merseyrail, в вашингтоне — washington metrorail, в сан-франциско — bart и т. п. в некоторых городах применяется название метро (англ. metro) для систем, по своему характеру близких к метро, или для всего городского транспорта (собственно метро и наземный пассажирский транспорт (в том числе автобусы и трамваи)) в совокупности.")
```
## Evaluation
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-ruquad-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_ruquad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:-----------------------------------------------------------------|
| AnswerExactMatch | 33 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| AnswerF1Score | 56.62 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| BERTScore | 80.96 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| Bleu_1 | 28.5 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| Bleu_2 | 24.12 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| Bleu_3 | 20.13 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| Bleu_4 | 16.37 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| METEOR | 34.93 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| MoverScore | 68.52 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
| ROUGE_L | 44.12 | default | [lmqg/qg_ruquad](https://huggingface.co/datasets/lmqg/qg_ruquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_ruquad
- dataset_name: default
- input_types: ['paragraph_sentence']
- output_types: ['answer']
- prefix_types: None
- model: google/mt5-small
- max_length: 512
- max_length_output: 32
- epoch: 5
- batch: 32
- lr: 0.001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 2
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-small-ruquad-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
| d9e7c45da6cf3806479f6d0566a4d6c4 |
juancopi81/mt5-small-finetuned-amazon-en-es | juancopi81 | mt5 | 8 | 1 | transformers | 0 | text2text-generation | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,645 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# juancopi81/mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.1238
- Validation Loss: 3.4046
- Epoch: 7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5.6e-05, 'decay_steps': 9672, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 10.2166 | 4.4331 | 0 |
| 6.0386 | 3.8849 | 1 |
| 5.2369 | 3.6628 | 2 |
| 4.7882 | 3.5569 | 3 |
| 4.5111 | 3.4850 | 4 |
| 4.3250 | 3.4330 | 5 |
| 4.1930 | 3.4163 | 6 |
| 4.1238 | 3.4046 | 7 |
### Framework versions
- Transformers 4.19.3
- TensorFlow 2.8.2
- Datasets 2.2.2
- Tokenizers 0.12.1
| 0067fdd4b5adb6ebd04b4e8916d2fdf9 |
mrizalf7/indobert-qa-finetuned-small-squad-indonesian-rizal | mrizalf7 | bert | 24 | 4 | transformers | 0 | question-answering | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,355 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-finetuned-small-squad-indonesian-rizal
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the small-squad indonesian dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3344
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2921 | 1.0 | 2700 | 2.1491 |
| 1.0084 | 2.0 | 5400 | 2.1961 |
| 0.814 | 3.0 | 8100 | 2.3344 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
| 7bd5cd4add89492baafa410541024bfc |
sd-dreambooth-library/mertgunhan | sd-dreambooth-library | null | 35 | 9 | diffusers | 0 | null | false | false | false | mit | null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 3,074 | false | ### mertgunhan on Stable Diffusion via Dreambooth trained on the [fast-DreamBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
#### model by teragron
This your the Stable Diffusion model fine-tuned the mertgunhan concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt(s)`: **mertgunhan**
You can also train your own concepts and upload them to the library by using [the fast-DremaBooth.ipynb by TheLastBen](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:
mertgunhan
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
| 33056975faea85d3c016cf1ab7590ed5 |
freedomtw/stable_diffusion_tflite | freedomtw | null | 13 | 0 | null | 0 | null | false | false | false | openrail | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['tflite', 'stable_diffusion'] | false | true | true | 1,045 | false |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Stable Diffusion TFLite models
# Model Details
converted from [Keras CV Stable Diffusion](https://github.com/keras-team/keras-cv/tree/master/keras_cv/models/stable_diffusion)
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s) (NLP):** English
- **License:** The CreativeML OpenRAIL M license is an Open RAIL M license, adapted from the work that BigScience and the RAIL Initiative are jointly carrying in the area of responsible AI licensing. See also the article about the BLOOM Open RAIL license on which our license is based.
## Model Sources
<!-- Provide the basic links for the model. -->
- **conversion script:** https://github.com/freedomtan/keras_cv_stable_diffusion_to_tflite
- **converted from:** https://github.com/keras-team/keras-cv/tree/master/keras_cv/models/stable_diffusion | 6dd5ae0f80d809d34b2cc2b7a872318d |
tmobaggins/marian-finetuned-kde4-en-to-es | tmobaggins | marian | 15 | 3 | transformers | 0 | translation | true | false | false | apache-2.0 | null | ['kde4'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation', 'generated_from_trainer'] | true | true | true | 987 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-es
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-es](https://huggingface.co/Helsinki-NLP/opus-mt-en-es) on the kde4 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| 96128110c7f5b55917d71434cb48556d |
Helsinki-NLP/opus-mt-bzs-fr | Helsinki-NLP | marian | 10 | 9 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-bzs-fr
* source languages: bzs
* target languages: fr
* OPUS readme: [bzs-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/bzs-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/bzs-fr/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/bzs-fr/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/bzs-fr/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.bzs.fr | 30.0 | 0.479 |
| e6749702aae9923e2c363f019f47a8b4 |
jonatasgrosman/exp_w2v2r_es_vp-100k_age_teens-8_sixties-2_s130 | jonatasgrosman | wav2vec2 | 10 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['es'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'es'] | false | true | true | 497 | false | # exp_w2v2r_es_vp-100k_age_teens-8_sixties-2_s130
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| a0570e11ab6a617213ca0518e9f0960d |
MrPotato/ner-bert-multilingual-uncased-geocite | MrPotato | bert | 12 | 12 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 997 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ner-bert-multilingual-uncased-geocite
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 6b19250876c982ff49535f5f05f118a5 |
espnet/kamo-naoyuki_librispeech_asr_train_asr_conformer5_raw_bpe5000_frontend-truncated-55c091 | espnet | null | 31 | 0 | espnet | 0 | automatic-speech-recognition | false | false | false | cc-by-4.0 | ['en'] | ['librispeech'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['espnet', 'audio', 'automatic-speech-recognition'] | false | true | true | 1,983 | false | ## Example ESPnet2 ASR model
### `kamo-naoyuki/librispeech_asr_train_asr_conformer5_raw_bpe5000_frontend_confn_fft400_frontend_confhop_length160_scheduler_confwarmup_steps25000_batch_bins140000000_optim_conflr0.0015_initnone_sp_valid.acc.ave`
♻️ Imported from https://zenodo.org/record/4543003/
This model was trained by kamo-naoyuki using librispeech/asr1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 1e4ee85e628a444c8768897dc7cded4b |
Helsinki-NLP/opus-mt-it-lt | Helsinki-NLP | marian | 11 | 14 | transformers | 0 | translation | true | true | false | apache-2.0 | ['it', 'lt'] | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 2,004 | false |
### ita-lit
* source group: Italian
* target group: Lithuanian
* OPUS readme: [ita-lit](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-lit/README.md)
* model: transformer-align
* source language(s): ita
* target language(s): lit
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-lit/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-lit/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-lit/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ita.lit | 38.1 | 0.652 |
### System Info:
- hf_name: ita-lit
- source_languages: ita
- target_languages: lit
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-lit/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['it', 'lt']
- src_constituents: {'ita'}
- tgt_constituents: {'lit'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-lit/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-lit/opus-2020-06-17.test.txt
- src_alpha3: ita
- tgt_alpha3: lit
- short_pair: it-lt
- chrF2_score: 0.652
- bleu: 38.1
- brevity_penalty: 0.9590000000000001
- ref_len: 1321.0
- src_name: Italian
- tgt_name: Lithuanian
- train_date: 2020-06-17
- src_alpha2: it
- tgt_alpha2: lt
- prefer_old: False
- long_pair: ita-lit
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 206f48917be024ba438fb7fc8b1310d7 |
vvincentt/roberta-base-squad2 | vvincentt | bert | 12 | 4 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 952 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-squad2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 86abf34a29980f2220aa5ecfd70b273a |